
J'ai récemment mené une étude dans laquelle il était nécessaire de traiter plusieurs centaines de milliers d'ensembles de données d'entrée. Pour chaque ensemble - effectuez quelques calculs, collectez les résultats de tous les calculs ensemble et sélectionnez le "meilleur" selon certains critères. En substance, c'est le buste de bruteforce. La même chose se produit lors de la sélection des paramètres des modèles ML à l'aide de GridSearch.
Cependant, à partir d'un moment donné, la taille des calculs peut devenir trop grande pour un ordinateur, même si vous l'exécutez dans plusieurs processus à l'aide de joblib. Ou, pour être plus précis, cela devient trop long pour un expérimentateur impatient.
Et comme dans un appartement moderne, vous pouvez désormais trouver plus d'un ordinateur "sous-chargé", et la tâche est clairement adaptée au parallélisme de masse - il est temps d'assembler votre cluster domestique et d'exécuter de telles tâches dessus.
La bibliothèque Dask ( https://dask.org/ ) est parfaite pour construire un "cluster domestique" . Il est facile à installer et peu exigeant sur les nœuds, ce qui réduit considérablement le "niveau d'entrée" dans le cluster computing.
Pour configurer votre cluster, vous avez besoin sur tous les ordinateurs:
- installer l'interpréteur python
- dask
- (scheduler) (worker)
, , — , .
(https://docs.dask.org/) . , .
python
Dask pickle, , python.
3.6 3.7 , . 3.8 - pickle.
" ", , , .
Dask
Dask pip conda
pip install dask distributed bokeh
dask, bokeh , , "-" dask dashboard.
. .
gcc, :
- MacOS xcode
- docker image docker-worker, "" ,
python:3.6-slim-buster . , python:3.6.
dask
- . . — .
$ dask-scheduler
- , .
$ dask-worker schedulerhost:8786 --nprocs 4 --nthreads 1 --memory-limit 1GB --death-timeout 120 -name MyWorker --local-directory /tmp/
nprocs / nthreads — , , . GIL -, - , numpy. .memory-limit — , . — - , . , .death-timeout — , - , . -. , , .name — -, . , "" -.local-directory — ,
- Windows
, dask-worker . , , dask-worker .
" " . NSSM (https://www.nssm.cc/).
NSSM, , , . , , - . NSSM .
NSSM . " "
Firewall
firewall: -.
, , -, — . , — . , , .
- . , .
Dask
:
from dask.distributed import Client
client = Client('scheduler_host:port')
— "" , .
, , . pandas, numpy, scikit-learn, tensorflow.
, .
, ? — pip
def install_packages():
try:
import sys, subprocess
subprocess.check_call([sys.executable, '-m', 'pip', 'install', 'mypackage'])
return (0)
except:
return (1)
from dask.distributed import Client
client = Client('scheduler:8786')
client.run(install_packages)
, , . . "" , , .
, , — .
, , Dask .
. Client upload_file(). , .
- , zip.
from dask.distributed import Client
import numpy as np
from my_module import foo
from my_package import bar
def zoo(x)
return (x**2 + 2*x + 1)
x = np.random.rand(1000000)
client = Client('scheduler:8786')
# .
#
r3 = client.map(zoo, x)
# foo bar ,
#
client.upload_file('my_module.py')
client.upload_file('my_package.zip')
#
r1 = client.map(foo, x)
r2 = client.map(bar, x)
joblib
joblib . joblib — :
joblib
from joblib import Parallel, delayed
...
res = Parallel(n_jobs=-1)(delayed(my_proc)(c, ref_data) for c in candidates)
joblib + dask
from joblib import Parallel, delayed, parallel_backend
from dask.distributed import Client
...
client = Client('scheduler:8786')
with parallel_backend('dask'):
res = Parallel(n_jobs=-1)(delayed(my_proc)(c, ref_data) for c in candidates)
, , . , — :

16 , .

— 10-20 , 200.
, - .
from joblib import Parallel, delayed, parallel_backend
from dask.distributed import Client
...
client = Client('scheduler:8786')
with parallel_backend('dask', scatter = [ref_data]):
res = Parallel(n_jobs=-1, batch_size=<N>, pre_dispatch='3*n_jobs')(delayed(my_proc)(c, ref_data) for c in candidates)
batch_size. — , , .
pre_dispatch.
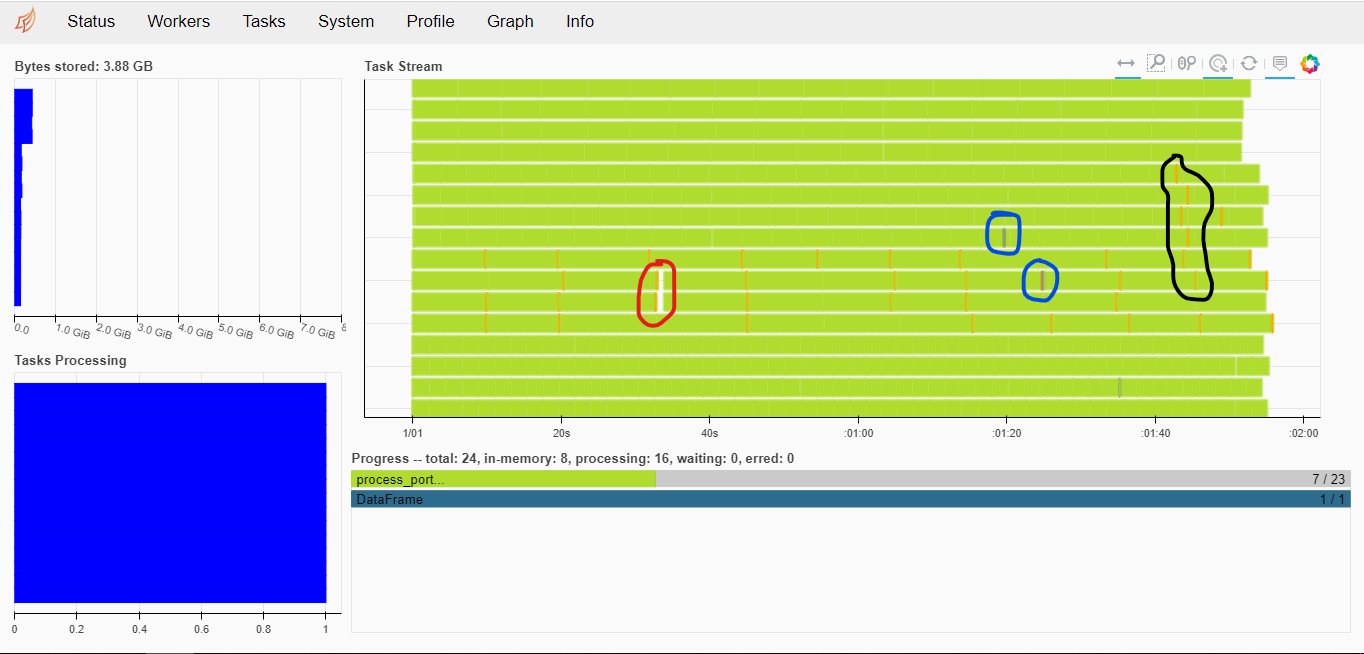
, .
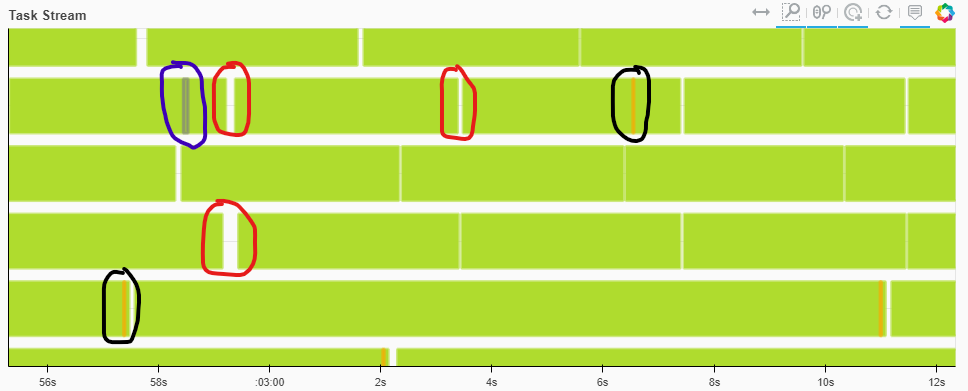
3.5-4 , . : , - , , .
, batch_size pre_dispatch . 8-10 .
, , - (, , ), scatter. .
, .
GridSearchCV
scikit-learn joblib , — dask
:
...
lr = LogisticRegression(C=1, solver="liblinear", penalty='l1', max_iter=300)
grid = {"C": 10.0 ** np.arange(-2, 3)}
cv = GridSearchCV(lr, param_grid=grid, n_jobs=-1, cv=3,
scoring='f1_weighted',
verbose=True, return_train_score=True )
client = Client('scheduler:8786')
with joblib.parallel_backend('dask'):
cv.fit(x1, y)
clf = cv.best_estimator_
print("Best params:", cv.best_params_)
print("Best score:", cv.best_score_)
:
Fitting 3 folds for each of 5 candidates, totalling 15 fits
[Parallel(n_jobs=-1)]: Using backend DaskDistributedBackend with 12 concurrent workers.
[Parallel(n_jobs=-1)]: Done 8 out of 15 | elapsed: 2.0min remaining: 1.7min
[Parallel(n_jobs=-1)]: Done 15 out of 15 | elapsed: 16.1min finished
/Library/Frameworks/Python.framework/Versions/3.7/lib/python3.7/site-packages/sklearn/linear_model/_logistic.py:1539: UserWarning: 'n_jobs' > 1 does not have any effect when 'solver' is set to 'liblinear'. Got 'n_jobs' = 16.
" = {}.".format(effective_n_jobs(self.n_jobs)))
Best params: {'C': 10.0}
Best score: 0.9748830491726451
dask. -.
— .
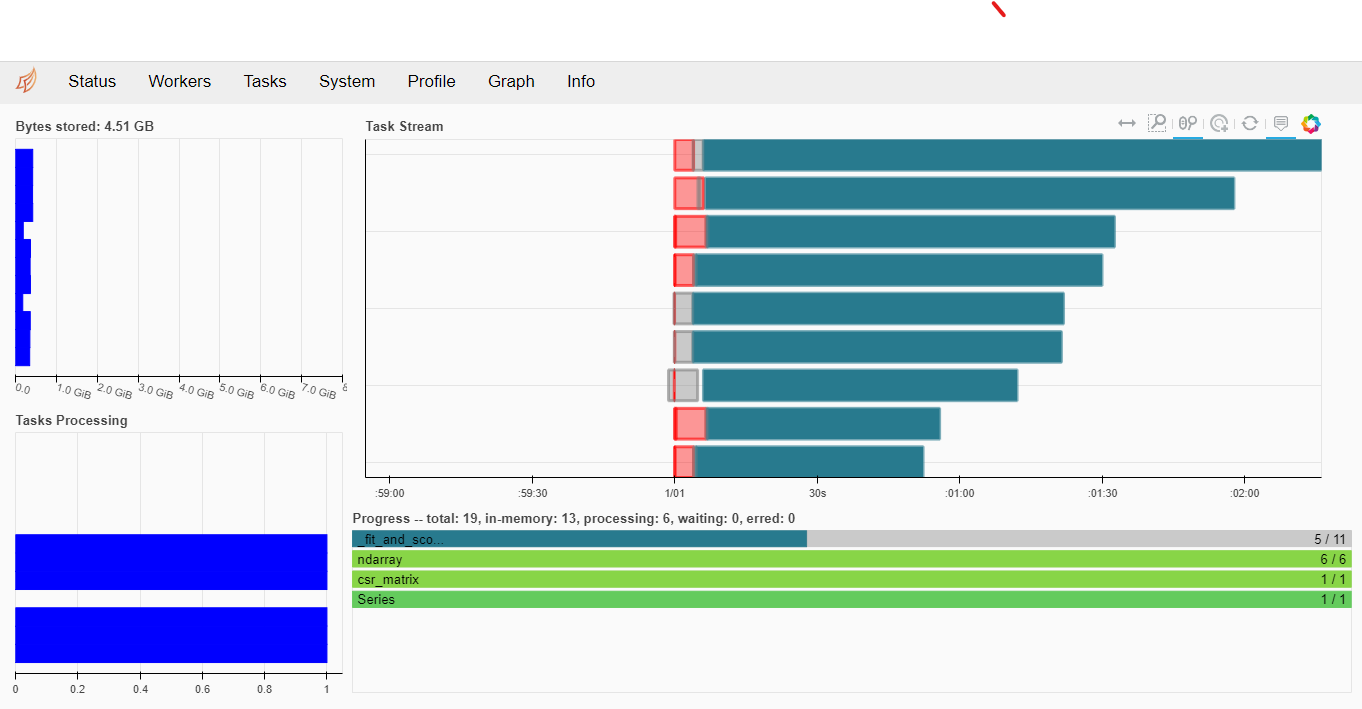
, ( ) — . — .
La bibliothèque Dask est un excellent outil de mise à l'échelle pour une classe spécifique de tâches. Même si vous n'utilisez que la base de données dask.distributed et laissez de côté les extensions spécialisées dask.dataframe, dask.array, dask.ml - vous pouvez accélérer considérablement les expériences. Dans certains cas, une accélération presque linéaire des calculs peut être obtenue.
Et tout cela est basé sur ce que vous avez déjà à la maison et est utilisé pour regarder des vidéos, faire défiler des flux d'actualités ou des jeux sans fin. Utilisez pleinement ces ressources!