 Internet regorge d'articles sur les modèles de langage basés sur N grammes. En même temps, il y a assez peu de bibliothèques prêtes à travailler.Il y a KenLM , SriLM et IRSTLM . Ils sont populaires et utilisés dans de nombreux grands projets. Mais il y a des problèmes:
Internet regorge d'articles sur les modèles de langage basés sur N grammes. En même temps, il y a assez peu de bibliothèques prêtes à travailler.Il y a KenLM , SriLM et IRSTLM . Ils sont populaires et utilisés dans de nombreux grands projets. Mais il y a des problèmes:- Les bibliothèques sont vieilles, ne se développent pas.
- Mauvaise prise en charge de la langue russe.
- Travailler uniquement avec du texte propre et spécialement préparé
- Mauvais support pour UTF-8. Par exemple, SriLM avec l'indicateur tolower rompt l'encodage.
KenLM
se démarque un peu de la liste . Il est régulièrement pris en charge et n'a aucun problème avec UTF-8, mais il est également exigeant sur la qualité du texte.Une fois, j'avais besoin d'une bibliothèque pour construire un modèle de langage. Après de nombreux essais et erreurs, je suis arrivé à la conclusion que la préparation d'un ensemble de données pour l'enseignement d'un modèle de langage est trop compliquée et un processus long. Surtout si c'est russe ! Mais je voulais en quelque sorte tout automatiser.Dans ses recherches, il est parti de la bibliothèque SriLM . Je noterai tout de suite qu'il ne s'agit pas d'un emprunt de code ou d' un fork SriLM . Tout le code est écrit entièrement à partir de zéro.Un petit exemple de texte:
! .
L'absence d'espace entre les phrases est une faute de frappe assez courante. Une telle erreur est difficile à trouver dans une grande quantité de données, alors qu'elle casse le tokenizer.Après le traitement, le N-gramme suivant apparaîtra dans le modèle de langage:
-0.3009452 !
Bien sûr, il existe de nombreux autres problèmes, fautes de frappe, caractères spéciaux, abréviations, diverses formules mathématiques ... Tout cela doit être géré correctement.ANYKS LM ( ALM )
La bibliothèque ne prend en charge que les systèmes d'exploitation Linux , MacOS X et FreeBSD . Je n'ai pas Windows et aucun support n'est prévu.Brève description des fonctionnalités
- Prise en charge d'UTF-8 sans dépendances tierces.
- Prise en charge des formats de données: Arpa, Vocab, séquence de cartes, N-grammes, dictionnaire binaire alm.
- : Kneser-Nay, Modified Kneser-Nay, Witten-Bell, Additive, Good-Turing, Absolute discounting.
- , , , .
- , N-, N- , N-.
- — N-, .
- : , -.
- N- — N-, backoff .
- N- backoff-.
- , : , , , , Python3.
- « », .
- 〈unk〉 .
- N- Python3.
- , .
- . : , , .
- Contrairement à d'autres modèles de langue, ALM est garanti de collecter tous les N-grammes à partir du texte, quelle que soit leur longueur (sauf pour Kneser-Nay modifié). Il est également possible d'enregistrer tous les N-grammes rares, même s'ils ne se sont réunis qu'une seule fois.
Parmi les formats de modèle de langage standard, seul le format ARPA est pris en charge . Honnêtement, je ne vois aucune raison de soutenir l'ensemble du zoo dans toutes sortes de formats.Le format ARPA est sensible à la casse et c'est également un problème certain.Parfois, il est utile de connaître uniquement la présence de données spécifiques dans le N-gramme. Par exemple, vous devez comprendre la présence de nombres dans le N-gramme, et leur signification n'est pas si importante.Exemple:
, 2
En conséquence, le N-gramme entre dans le modèle de langage:
-0.09521468 2
Le numéro spécifique, dans ce cas, n'a pas d'importance. La vente en magasin peut aller de 1 à 3 et autant de jours que vous le souhaitez.Pour résoudre ce problème, ALM utilise la tokenisation de classe.Jetons pris en charge
Standard:〈s〉 - Jeton du début de la phrase〈/s〉 - Jeton de la fin de la phrase〈unk〉 - Jeton d'un mot inconnuNon standard:〈url〉 - Jeton de l'adresse URL〈num〉 - Jeton de chiffres (arabe ou romain)〈date〉 - Jeton de date (18 juillet 2004 | 18/07/2004)〈time〉 - Jeton horaire (15:44:56)〈abbr〉 - Jeton d'abréviation (1er | 2ème | 20ème)〉 anum〉 - Pseudo -Token nombres (T34 | 895-M-86 | 39km)〈math〉 - Jeton d'opérations mathématiques (+ | - | = | / | * | ^)〈range〉 - Jeton de la plage de nombres (1-2 | 100-200 | 300- 400)〈aprox〉- Un jeton de nombre approximatif (~ 93 | ~ 95,86 | 10 ~ 20)〉score〉 - Un jeton de compte numérique (4: 3 | 01:04)〈dimen〉 - Jeton global (200x300 | 1920x1080)〈fract〉 - Un jeton de fraction fraction (5/20 | 192/864)〉punct〉 - Jeton de caractère de ponctuation (. | ... |, |! |? |: |;)〈Specl〉 - Jeton de caractère spécial (~ | @ | # | No. |% | & | $ | § | ±)〈isolat〉 - Jeton de symbole d'isolement ("| '|" | "|„ | “|` | (|) | [|] | {|})Bien sûr, la prise en charge de chacun des jetons peut être désactivée si ces N-grammes sont nécessaires.Si vous devez traiter d'autres balises (par exemple, vous devez trouver les noms de pays dans le texte), ALM prend en charge la connexion de scripts externes en Python3.Un exemple de script de détection de jeton:
def init():
"""
:
"""
def run(token, word):
"""
:
@token
@word
"""
if token and (token == "<usa>"):
if word and (word.lower() == ""): return "ok"
elif token and (token == "<russia>"):
if word and (word.lower() == ""): return "ok"
return "no"
Un tel script ajoute deux autres balises à la liste des balises standard: 〈usa〉 et 〈russia〉 .En plus du script de détection des jetons, il existe un support pour un script de prétraitement des mots traités. Ce script peut changer le mot avant d'ajouter le mot au modèle de langue.Un exemple de script de traitement de texte:
def init():
"""
:
"""
def run(word, context):
"""
:
@word
@context
"""
return word
Une telle approche peut être utile s'il est nécessaire d'assembler un modèle de langage composé de lemmes ou de tiges .Formats de texte du modèle de langage pris en charge par ALM
ARPA:
\data\
ngram 1=52
ngram 2=68
ngram 3=15
\1-grams:
-1.807052 1- -0.30103
-1.807052 2 -0.30103
-1.807052 3~4 -0.30103
-2.332414 -0.394770
-3.185530 -0.311249
-3.055896 -0.441649
-1.150508 </s>
-99 <s> -0.3309932
-2.112406 <unk>
-1.807052 T358 -0.30103
-1.807052 VII -0.30103
-1.503878 -0.39794
-1.807052 -0.30103
-1.62953 -0.30103
...
\2-grams:
-0.29431 1-
-0.29431 2
-0.29431 3~4
-0.8407791 <s>
-1.328447 -0.477121
...
\3-grams:
-0.09521468
-0.166590
...
\end\
ARPA est le format de texte standard pour le modèle de langage en langage naturel utilisé par Sphinx / CMU et Kaldi .NGRAMMES:
\data\
ad=1
cw=23832
unq=9390
ngram 1=9905
ngram 2=21907
ngram 3=306
\1-grams:
<s> 2022 | 1
<num> 117 | 1
<unk> 19 | 1
<abbr> 16 | 1
<range> 7 | 1
</s> 2022 | 1
244 | 1
244 | 1
11 | 1
762 | 1
112 | 1
224 | 1
1 | 1
86 | 1
978 | 1
396 | 1
108 | 1
77 | 1
32 | 1
...
\2-grams:
<s> <num> 7 | 1
<s> <unk> 1 | 1
<s> 84 | 1
<s> 83 | 1
<s> 57 | 1
82 | 1
11 | 1
24 | 1
18 | 1
31 | 1
45 | 1
97 | 1
71 | 1
...
\3-grams:
<s> <num> </s> 3 | 1
<s> 6 | 1
<s> 4 | 1
<s> 2 | 1
<s> 3 | 1
2 | 1
</s> 2 | 1
2 | 1
2 | 1
2 | 1
2 | 1
2 | 1
</s> 2 | 1
</s> 3 | 1
2 | 1
...
\end\
Ngrams - format de texte non standard du modèle de langue, est une modification du format ARPA .La description:- ad - Nombre de documents dans l'enceinte
- cw - Le nombre de mots dans tous les documents du corpus
- unq - Nombre de mots uniques collectés
VOCAB:
\data\
ad=1
cw=23832
unq=9390
\words:
33 244 | 1 | 0.010238 | 0.000000 | -3.581616
34 11 | 1 | 0.000462 | 0.000000 | -6.680889
35 762 | 1 | 0.031974 | 0.000000 | -2.442838
40 12 | 1 | 0.000504 | 0.000000 | -6.593878
330344 47 | 1 | 0.001972 | 0.000000 | -5.228637
335190 17 | 1 | 0.000713 | 0.000000 | -6.245571
335192 1 | 1 | 0.000042 | 0.000000 | -9.078785
335202 22 | 1 | 0.000923 | 0.000000 | -5.987742
335206 7 | 1 | 0.000294 | 0.000000 | -7.132874
335207 29 | 1 | 0.001217 | 0.000000 | -5.711489
2282019644 1 | 1 | 0.000042 | 0.000000 | -9.078785
2282345502 10 | 1 | 0.000420 | 0.000000 | -6.776199
2282416889 2 | 1 | 0.000084 | 0.000000 | -8.385637
3009239976 1 | 1 | 0.000042 | 0.000000 | -9.078785
3009763109 1 | 1 | 0.000042 | 0.000000 | -9.078785
3013240091 1 | 1 | 0.000042 | 0.000000 | -9.078785
3014009989 1 | 1 | 0.000042 | 0.000000 | -9.078785
3015727462 2 | 1 | 0.000084 | 0.000000 | -8.385637
3025113549 1 | 1 | 0.000042 | 0.000000 | -9.078785
3049820849 1 | 1 | 0.000042 | 0.000000 | -9.078785
3061388599 1 | 1 | 0.000042 | 0.000000 | -9.078785
3063804798 1 | 1 | 0.000042 | 0.000000 | -9.078785
3071212736 1 | 1 | 0.000042 | 0.000000 | -9.078785
3074971025 1 | 1 | 0.000042 | 0.000000 | -9.078785
3075044360 1 | 1 | 0.000042 | 0.000000 | -9.078785
3123271427 1 | 1 | 0.000042 | 0.000000 | -9.078785
3123322362 1 | 1 | 0.000042 | 0.000000 | -9.078785
3126399411 1 | 1 | 0.000042 | 0.000000 | -9.078785
…
Vocab est un format de dictionnaire de texte non standard dans le modèle de langue.La description:- oc - occurrence de cas
- dc - occurrence dans les documents
- tf - (term frequency — ) — . , , : [tf = oc / cw]
- idf - (inverse document frequency — ) — , , : [idf = log(ad / dc)]
- tf-idf - : [tf-idf = tf * idf]
- wltf - , : [wltf = 1 + log(tf * dc)]
MAP:
1:{2022,1,0}|42:{57,1,0}|279603:{2,1,0}
1:{2022,1,0}|42:{57,1,0}|320749:{2,1,0}
1:{2022,1,0}|42:{57,1,0}|351283:{2,1,0}
1:{2022,1,0}|42:{57,1,0}|379815:{3,1,0}
1:{2022,1,0}|42:{57,1,0}|26122748:{3,1,0}
1:{2022,1,0}|44:{6,1,0}
1:{2022,1,0}|48:{1,1,0}
1:{2022,1,0}|51:{11,1,0}|335967:{3,1,0}
1:{2022,1,0}|53:{14,1,0}|371327:{3,1,0}
1:{2022,1,0}|53:{14,1,0}|40260976:{7,1,0}
1:{2022,1,0}|65:{68,1,0}|34:{2,1,0}
1:{2022,1,0}|65:{68,1,0}|3277:{3,1,0}
1:{2022,1,0}|65:{68,1,0}|278003:{2,1,0}
1:{2022,1,0}|65:{68,1,0}|320749:{2,1,0}
1:{2022,1,0}|65:{68,1,0}|11353430797:{2,1,0}
1:{2022,1,0}|65:{68,1,0}|34270133320:{2,1,0}
1:{2022,1,0}|65:{68,1,0}|51652356484:{2,1,0}
1:{2022,1,0}|65:{68,1,0}|66967237546:{2,1,0}
1:{2022,1,0}|2842:{11,1,0}|42:{7,1,0}
…
Carte - le contenu du fichier a une signification purement technique. Utilisé conjointement avec le fichier vocab , vous pouvez combiner plusieurs modèles de langage, modifier, stocker, distribuer et exporter vers n'importe quel format ( arpa , ngrams , alm binaire ).Formats de fichier texte d'aide pris en charge par ALM
Souvent, lors de l'assemblage d'un modèle de langage, des fautes de frappe sont rencontrées dans le texte, qui sont des substitutions de lettres (avec des lettres visuellement similaires d'un autre alphabet).ALM résout ce problème avec un fichier avec des lettres d'aspect similaire.p
c
o
t
k
e
a
h
x
b
m
Si, lors de l'enseignement d'un modèle de langage, lors du transfert de fichiers avec une liste de domaines et d'abréviations de premier niveau, ALM peut vous aider à détecter plus précisément les balises de classe 〈url〉 et 〈abbr〉 .Fichier de liste des abréviations:
…
Fichier de liste des zones de domaine:
ru
su
cc
net
com
org
info
…
Pour une détection plus précise du jeton 〈url〉 , vous devez ajouter vos zones de domaine de premier niveau (toutes les zones de domaine de l'exemple sont déjà préinstallées) .Conteneur binaire du modèle de langage ALM
Pour créer un conteneur binaire pour le modèle de langage, vous devez créer un fichier JSON avec une description de vos paramètres.Options JSON:
{
"aes": 128,
"name": "Name dictionary",
"author": "Name author",
"lictype": "License type",
"lictext": "License text",
"contacts": "Contacts data",
"password": "Password if needed",
"copyright": "Copyright author"
}
La description:- aes - Taille de cryptage AES (128, 192, 256) bits
- name - Nom du dictionnaire
- auteur - Dictionnaire auteur
- lictype - Type de licence
- lictext - Texte de licence
- contacts - Coordonnées de l' auteur
- mot de passe - Mot de passe de cryptage (si nécessaire), le cryptage est effectué uniquement lors de la définition d'un mot de passe
- copyright - Copyright du propriétaire du dictionnaire
Tous les paramètres sont facultatifs à l'exception du nom du conteneur.Exemples de bibliothèques ALM
Opération Tokenizer
Le tokenizer reçoit du texte à l'entrée et génère du JSON à la sortie.$ echo 'Hello World?' | ./alm -alphabet "abcdefghijklmnopqrstuvwxyz" -method tokens
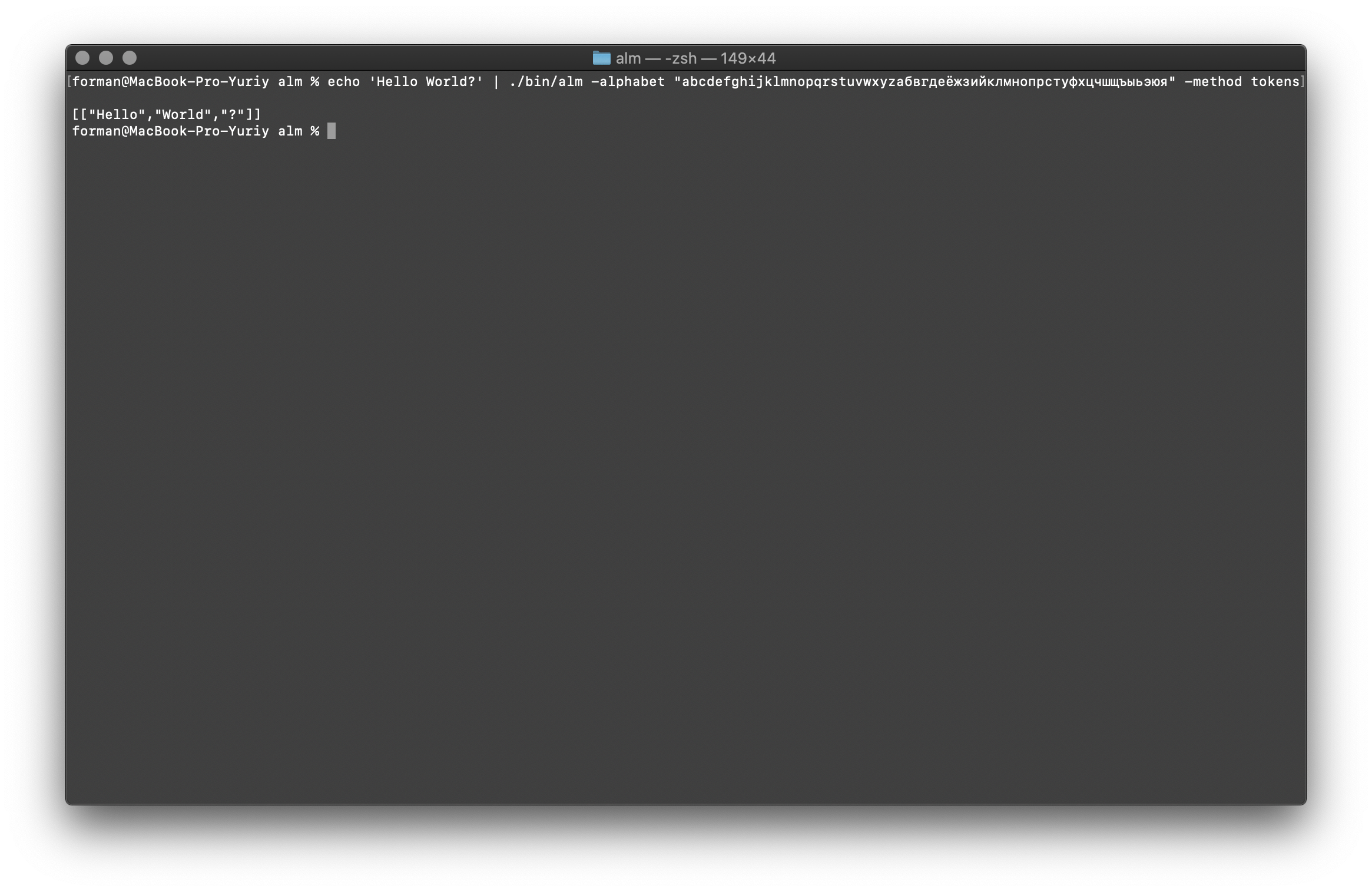 Tester:
Tester:Hello World?
Résultat:[
["Hello","World","?"]
]
Essayons quelque chose de plus difficile ...$ echo ' ??? ....' | ./alm -alphabet "abcdefghijklmnopqrstuvwxyz" -method tokens
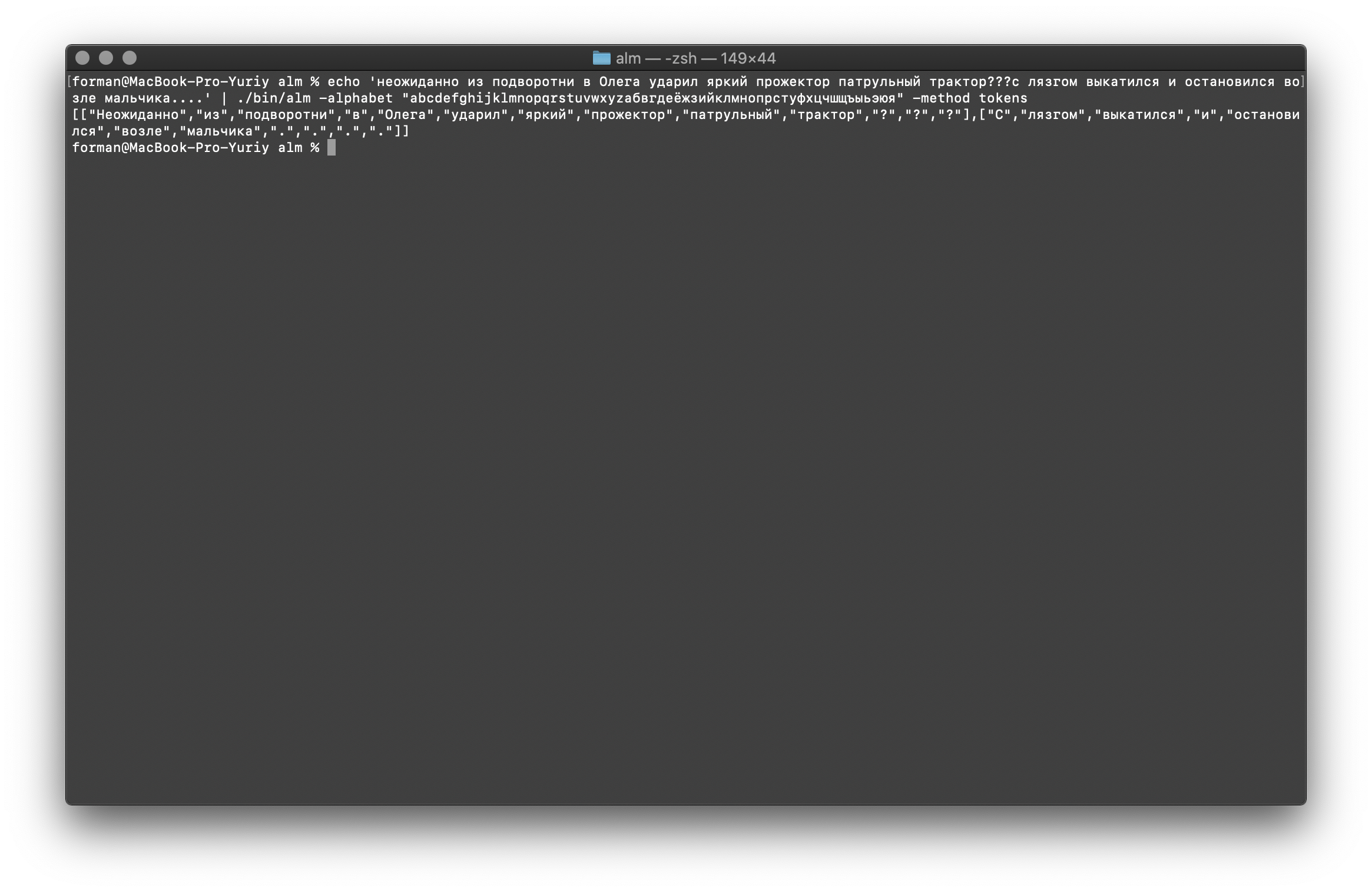 Tester:
Tester: ??? ....
Résultat:[
[
"",
"",
"",
"",
"",
"",
"",
"",
"",
"",
"?",
"?",
"?"
],[
"",
"",
"",
"",
"",
"",
"",
".",
".",
".",
"."
]
]
Comme vous pouvez le voir, le tokenizer a fonctionné correctement et a corrigé les erreurs de base.Modifiez un peu le texte et voyez le résultat.$ echo ' ... .' | ./alm -alphabet "abcdefghijklmnopqrstuvwxyz" -method tokens
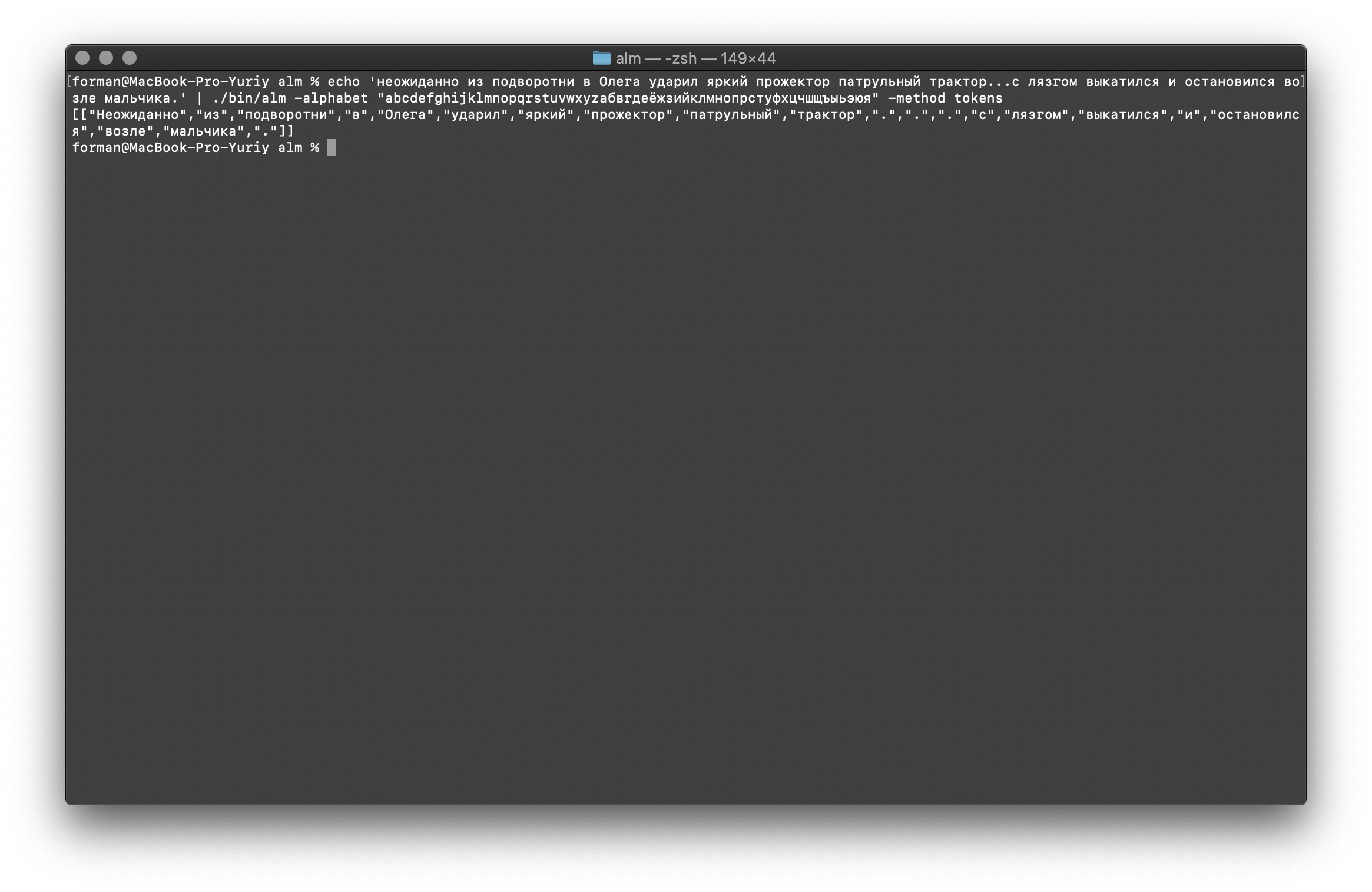 Tester:
Tester: ... .
Résultat:[
[
"",
"",
"",
"",
"",
"",
"",
"",
"",
"",
".",
".",
".",
"",
"",
"",
"",
"",
"",
"",
"."
]
]
Comme vous pouvez le voir, le résultat a changé. Maintenant, essayez autre chose.$ echo ' 5–7 . : 1 . ( +37–38°), 5–10 . – ( +12–15°) ..»| |()' | ./alm -alphabet "abcdefghijklmnopqrstuvwxyz" -method tokens
 Tester:
Tester: 5–7 . : 1 . ( +37–38°), 5–10 . – ( +12–15°) ..»| |()
Résultat:[
[
"",
"",
"",
"",
"5–7",
".",
"",
"",
"",
"",
"",
"",
"",
"",
"",
"",
"",
"",
"",
":",
"1",
".",
"",
"",
"(",
"+37–38°",
")",
",",
"",
"5–10",
".",
"–",
"",
"",
"(",
"+12–15°",
")",
"",
"..",
"»",
"|",
"|",
"(",
")"
]
]
Regroupez tout dans le texte
Tout d'abord, restaurez le premier test.$ echo '[["Hello","World","?"]]' | ./alm -alphabet "abcdefghijklmnopqrstuvwxyz" -method tokens
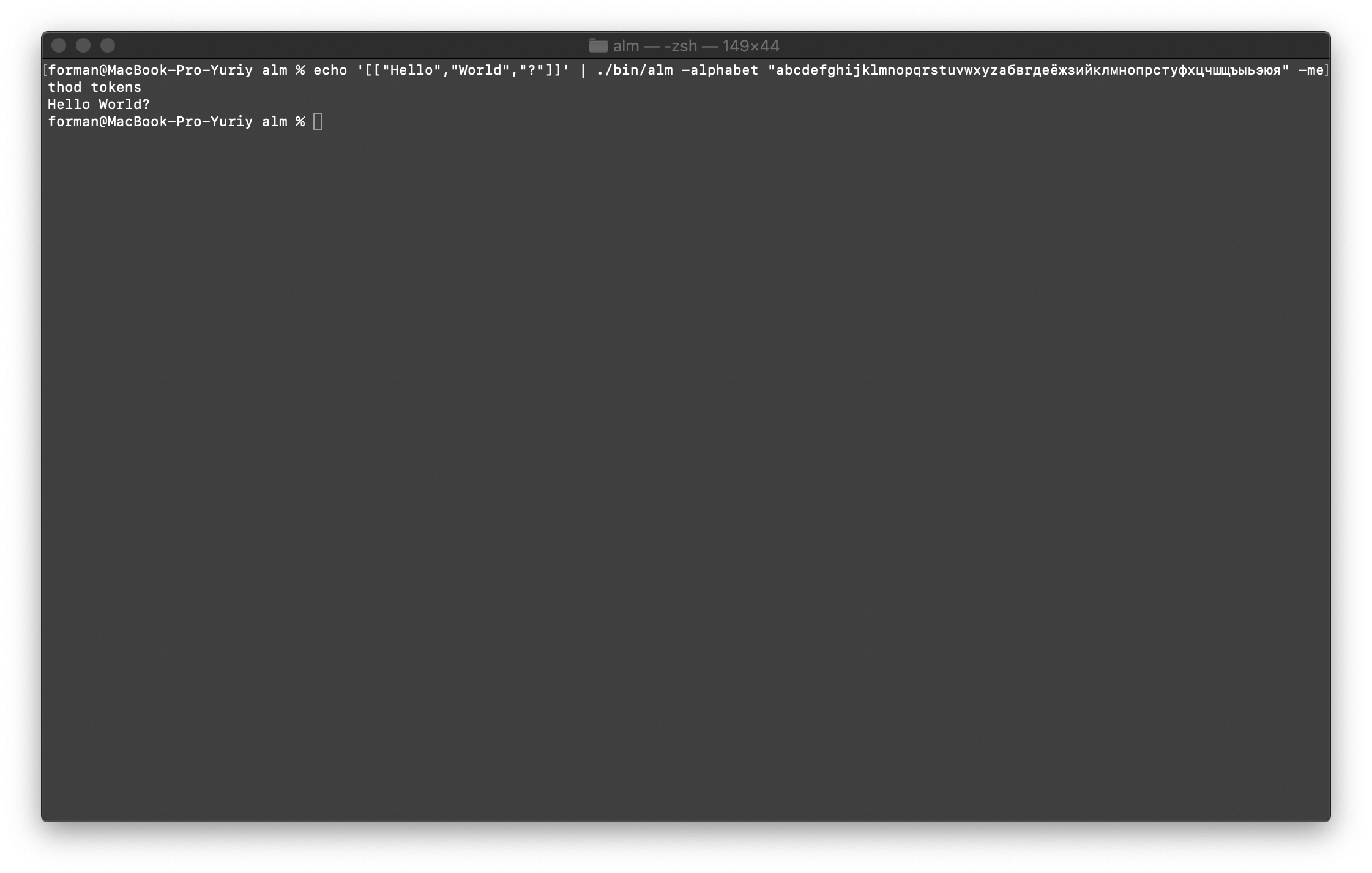 Tester:
Tester:[["Hello","World","?"]]
Résultat:Hello World?
Nous allons maintenant restaurer le test le plus complexe.$ echo '[["","","","","","","","","","","?","?","?"],["","","","","","","",".",".",".","."]]' | ./alm -alphabet "abcdefghijklmnopqrstuvwxyz" -method tokens
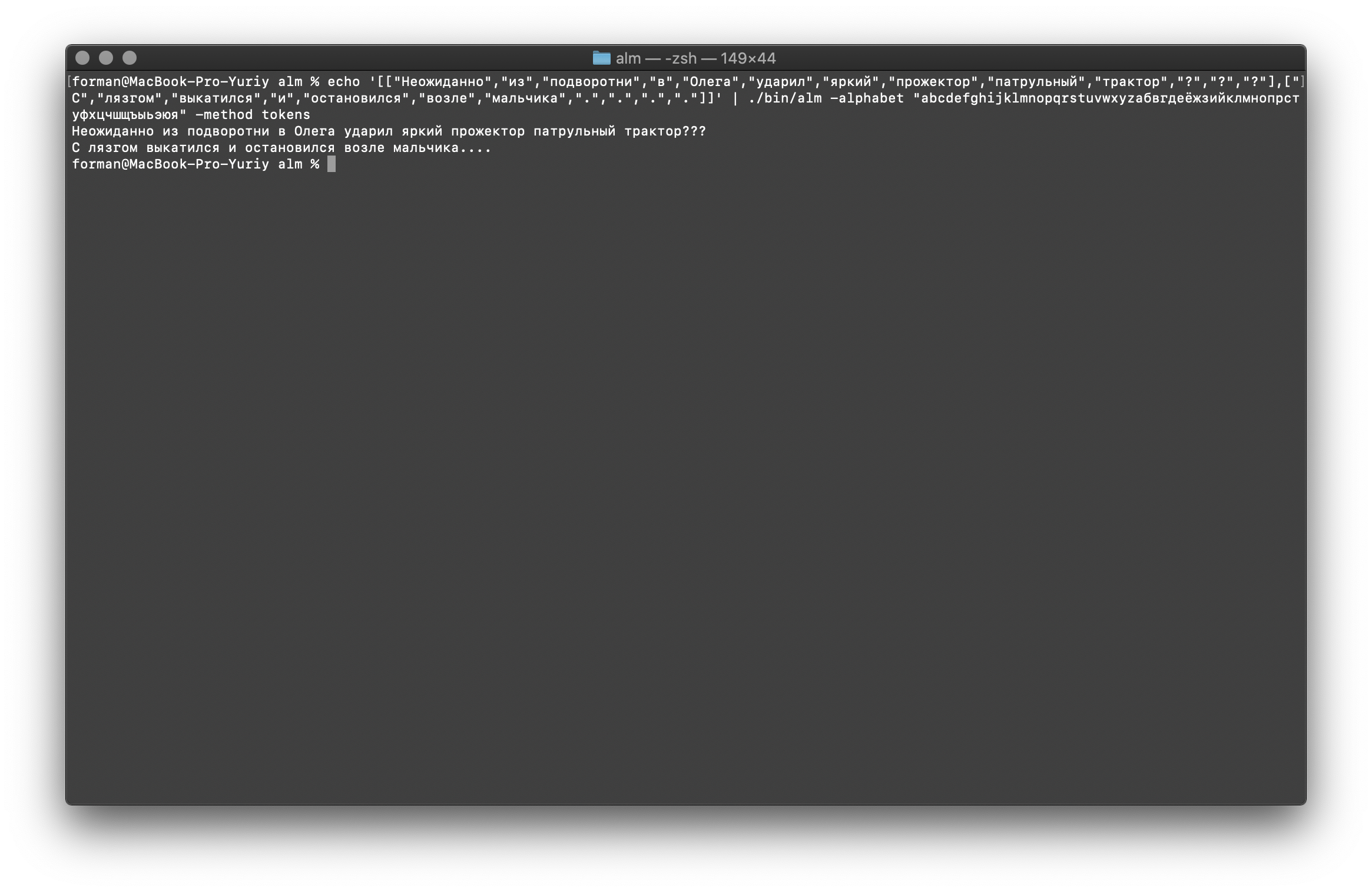 Tester:
Tester:[["","","","","","","","","","","?","?","?"],["","","","","","","",".",".",".","."]]
Résultat: ???
….
Comme vous pouvez le voir, le tokenizer a pu restaurer le texte initialement rompu.Continuez.$ echo '[["","","","","","","","","","",".",".",".","","","","","","","","."]]' | ./alm -alphabet "abcdefghijklmnopqrstuvwxyz" -method tokens
 Tester:
Tester:[["","","","","","","","","","",".",".",".","","","","","","","","."]]
Résultat: ... .
Et enfin, cochez l'option la plus difficile.$ echo '[["","","","","5–7",".","","","","","","","","","","","","","",":","1",".","","","(","+37–38°",")",",","","5–10",".","–","","","(","+12–15°",")","","..","»","|","|","(",")"]]' | ./alm -alphabet "abcdefghijklmnopqrstuvwxyz" -method tokens
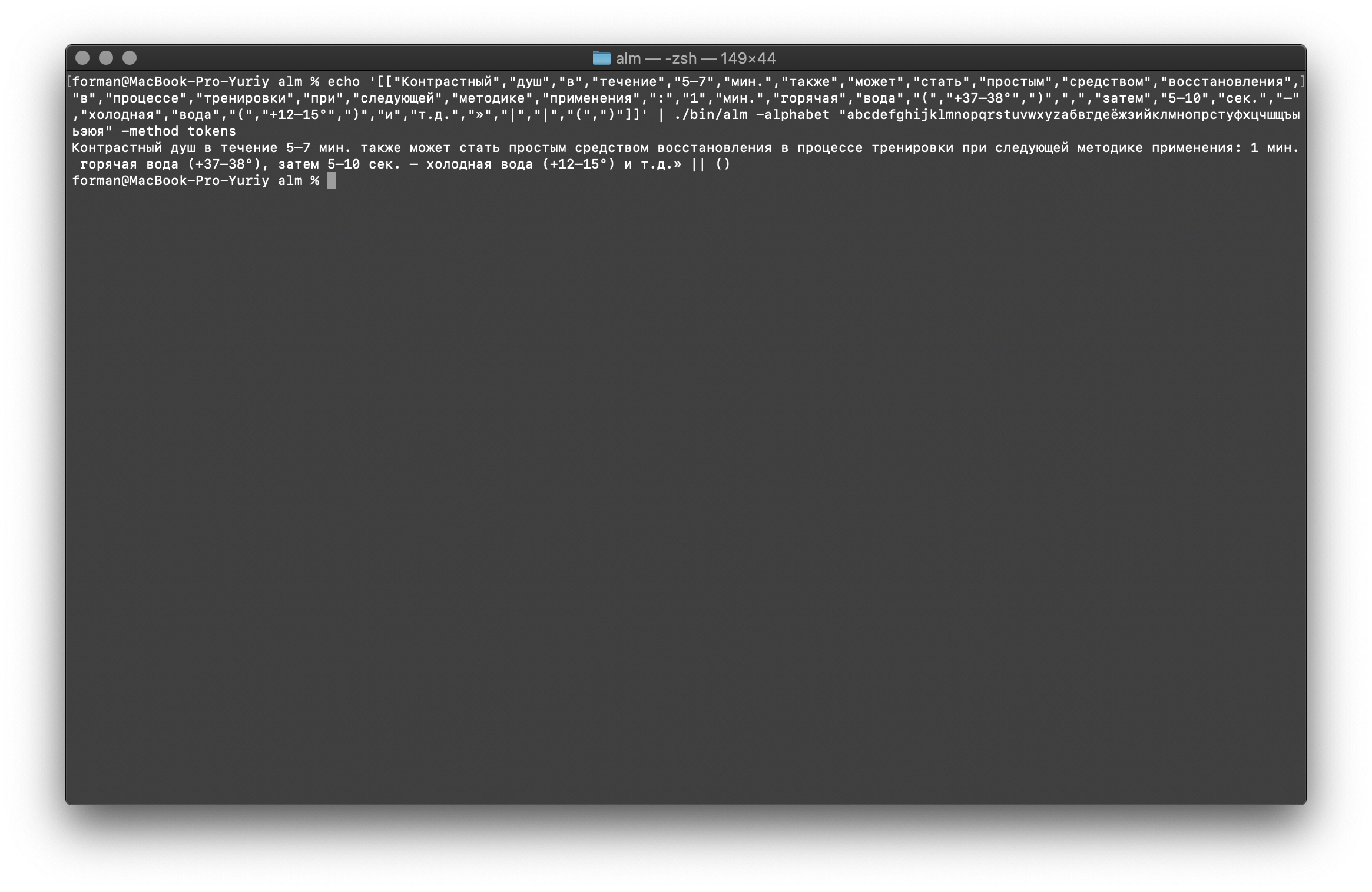 Tester:
Tester:[["","","","","5–7",".","","","","","","","","","","","","","",":","1",".","","","(","+37–38°",")",",","","5–10",".","–","","","(","+12–15°",")","","..","»","|","|","(",")"]]
Résultat: 5–7 . : 1 . (+37–38°), 5–10 . – (+12–15°) ..» || ()
Comme le montrent les résultats obtenus, le tokenizer peut corriger la plupart des erreurs de conception de texte.Formation sur le modèle linguistique
$ ./alm -alphabet "abcdefghijklmnopqrstuvwxyz" -size 3 -smoothing wittenbell -method train -debug 1 -w-arpa ./lm.arpa -w-map ./lm.map -w-vocab ./lm.vocab -w-ngram ./lm.ngrams -allow-unk -interpolate -corpus ./text.txt -threads 0 -train-segments
Je décrirai les paramètres d'assemblage plus en détail.- taille - La taille de longueur de N-grammes (la taille est fixée à 3 grammes )
- smoothing - Algorithme de lissage (algorithme sélectionné par Witten-Bell )
- méthode - Méthode de travail (méthode spécifiée pour la formation )
- debug - Mode de débogage (l'indicateur d'état d'apprentissage est défini)
- w-arpa — ARPA
- w-map — MAP
- w-vocab — VOCAB
- w-ngram — NGRAM
- allow-unk — 〈unk〉
- interpolate —
- corpus — . ,
- threads - Utilisez le multithreading pour la formation (0 - pour la formation, tous les cœurs de processeur disponibles seront donnés,> 0 le nombre de cœurs participant à la formation)
- segments de train - Le bâtiment de formation sera segmenté uniformément sur tous les noyaux
Plus d'informations peuvent être obtenues en utilisant l'indicateur [-help] .
Calcul de la perplexité
$ echo " ??? ...." | ./alm -alphabet "abcdefghijklmnopqrstuvwxyz" -method ppl -debug 2 -r-arpa ./lm.arpa -confidence -threads 0
 Tester:
Tester: ??? ….
Résultat:info: <s> <punct> <punct> <punct> </s>
info: p( | <s> ) = [2gram] 0.00209192 [ -2.67945500 ] / 0.99999999
info: p( | ...) = [3gram] 0.91439744 [ -0.03886500 ] / 1.00000035
info: p( | ...) = [3gram] 0.86302624 [ -0.06397600 ] / 0.99999998
info: p( | ...) = [3gram] 0.98003368 [ -0.00875900 ] / 1.00000088
info: p( | ...) = [3gram] 0.85783547 [ -0.06659600 ] / 0.99999955
info: p( | ...) = [3gram] 0.95238819 [ -0.02118600 ] / 0.99999897
info: p( | ...) = [3gram] 0.97959599 [ -0.00895300 ] / 1.00000090
info: p( | ...) = [3gram] 0.97959599 [ -0.00895300 ] / 1.00000090
info: p( | ...) = [3gram] 0.97959599 [ -0.00895300 ] / 1.00000090
info: p( | ...) = [3gram] 0.97959599 [ -0.00895300 ] / 1.00000090
info: p( <punct> | ...) = [3gram] 0.78127873 [ -0.10719400 ] / 1.00000031
info: p( <punct> | <punct> ...) = [2gram] 0.29417110 [ -0.53140000 ] / 0.99999998
info: p( <punct> | <punct> ...) = [3gram] 0.51262054 [ -0.29020400 ] / 0.99999998
info: p( </s> | <punct> ...) = [3gram] 0.45569787 [ -0.34132300 ] / 0.99999998
info: 1 sentences, 13 words, 0 OOVs
info: 0 zeroprobs, logprob= -4.18477000 ppl= 1.99027067 ppl1= 2.09848266
info: <s> <punct> <punct> <punct> <punct> </s>
info: p( | <s> ) = [2gram] 0.00809597 [ -2.09173100 ] / 0.99999999
info: p( | ...) = [3gram] 0.19675329 [ -0.70607800 ] / 0.99999972
info: p( | ...) = [3gram] 0.97959599 [ -0.00895300 ] / 1.00000090
info: p( | ...) = [3gram] 0.98007204 [ -0.00874200 ] / 0.99999931
info: p( | ...) = [3gram] 0.85785325 [ -0.06658700 ] / 1.00000018
info: p( | ...) = [3gram] 0.81482810 [ -0.08893400 ] / 1.00000027
info: p( | ...) = [3gram] 0.93507404 [ -0.02915400 ] / 1.00000058
info: p( <punct> | ...) = [3gram] 0.76391493 [ -0.11695500 ] / 0.99999971
info: p( <punct> | <punct> ...) = [2gram] 0.29417110 [ -0.53140000 ] / 0.99999998
info: p( <punct> | <punct> ...) = [3gram] 0.51262054 [ -0.29020400 ] / 0.99999998
info: p( <punct> | <punct> ...) = [3gram] 0.51262054 [ -0.29020400 ] / 0.99999998
info: p( </s> | <punct> ...) = [3gram] 0.45569787 [ -0.34132300 ] / 0.99999998
info: 1 sentences, 11 words, 0 OOVs
info: 0 zeroprobs, logprob= -4.57026500 ppl= 2.40356248 ppl1= 2.60302678
info: 2 sentences, 24 words, 0 OOVs
info: 0 zeroprobs, logprob= -8.75503500 ppl= 2.23975957 ppl1= 2.31629103
info: work time shifting: 0 seconds
Je pense qu'il n'y a rien de spécial à commenter, nous allons donc continuer.Vérification de l'existence du contexte
$ echo "<s> </s>" | ./alm -alphabet "abcdefghijklmnopqrstuvwxyz" -method checktext -debug 1 -r-arpa ./lm.arpa -confidence
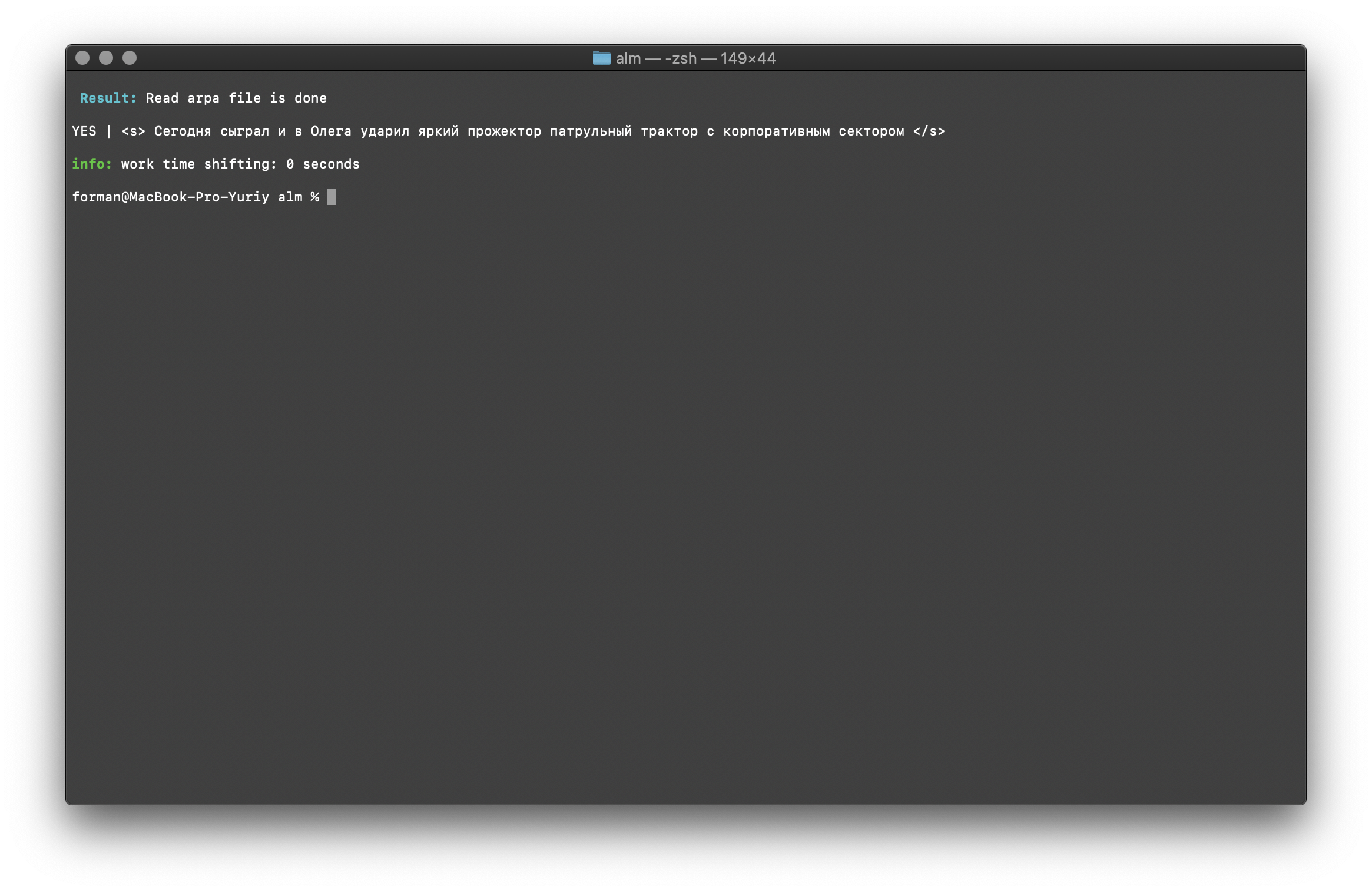 Tester:
Tester:<s> </s>
Résultat:YES | <s> </s>
Le résultat montre que le texte vérifié a le contexte correct en termes de modèle de langage assemblé.Flag [ -confidence ] - signifie que le modèle de langage sera chargé tel qu'il a été construit, sans surrénégation.Correction de la casse des mots
$ echo " ??? ...." | ./alm -alphabet "abcdefghijklmnopqrstuvwxyz" -method fixcase -debug 1 -r-arpa ./lm.arpa -confidence
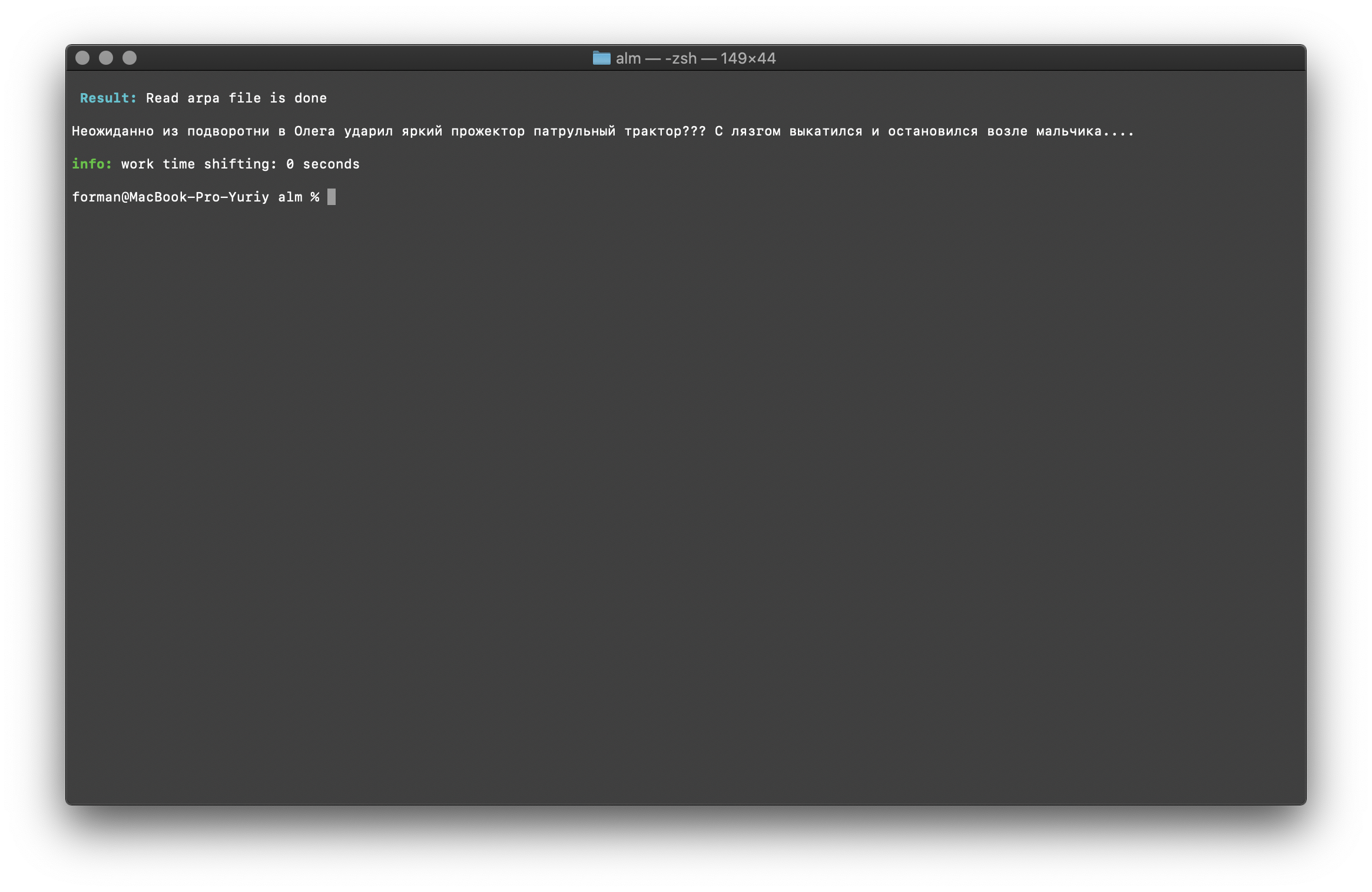 Tester:
Tester: ??? ....
Résultat: ??? ....
Les registres du texte sont restaurés en tenant compte du contexte du modèle de langage.Les bibliothèques décrites ci-dessus pour travailler avec des modèles de langage statistique sont sensibles à la casse. Par exemple, le N-gramme « à Moscou demain pleuvra » n'est pas le même que le N-gramme « à Moscou pleuvra demain », ce sont des N-grammes complètement différents. Mais que faire si le cas doit être sensible à la casse et, en même temps, dupliquer les mêmes N-grammes est irrationnel? ALM représente tous les N-grammes en minuscules. Cela élimine la possibilité de duplication de N-grammes. ALM maintient également son classement des registres de mots dans chaque N-gramme. Lors de l'exportation au format texte d'un modèle de langue, les registres sont restaurés en fonction de leur évaluation.Vérification du nombre de N-grammes
$ echo " ??? ...." | ./alm -alphabet "abcdefghijklmnopqrstuvwxyz" -method counts -debug 1 -r-arpa ./lm.arpa -confidence
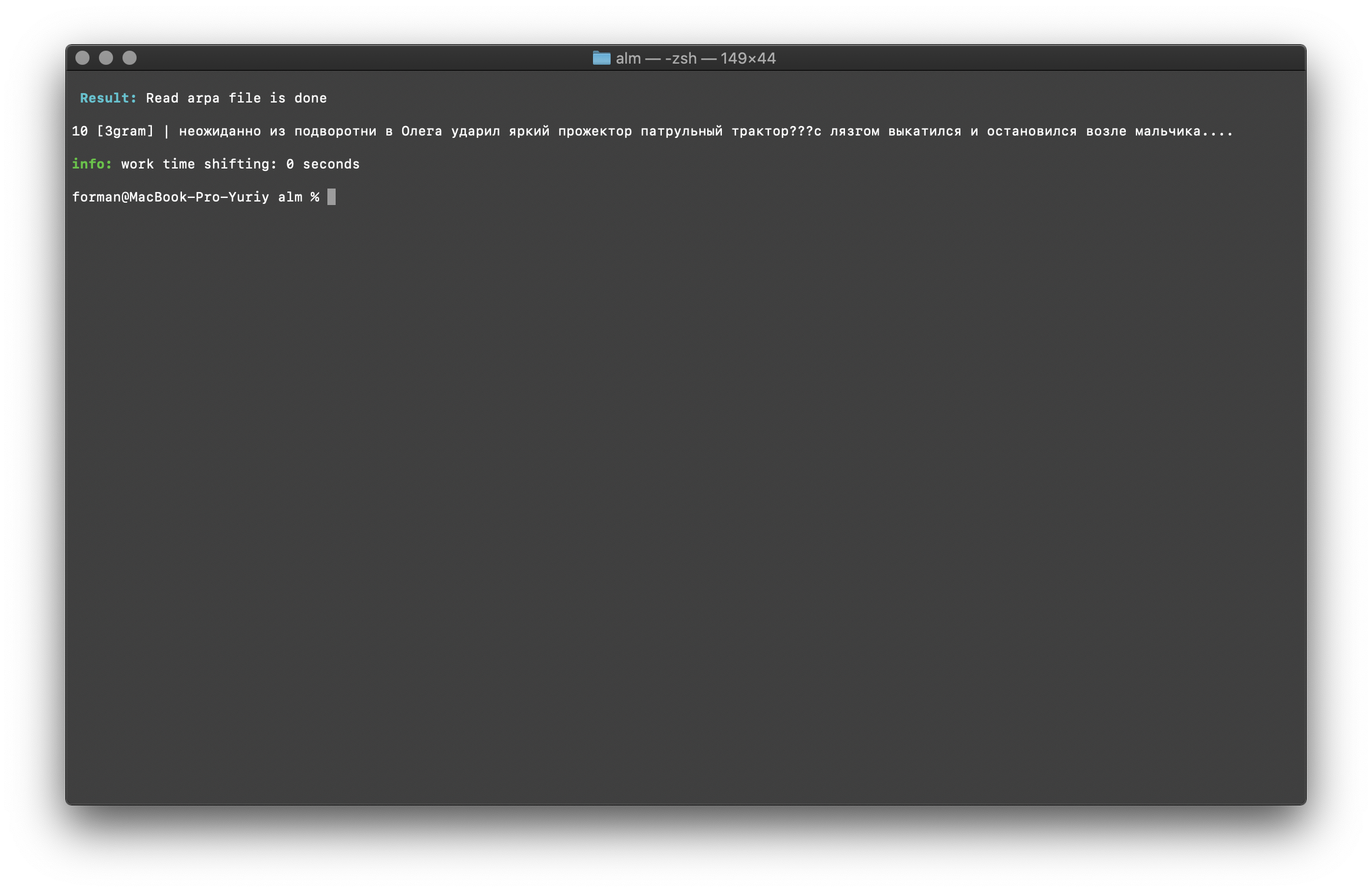 Tester:
Tester: ??? ....
Résultat:10 [3gram] |
N- , .
La vérification du nombre de N-grammes est effectuée par la taille du N-gramme dans le modèle de langue. Il est également possible de vérifier les bigrammes et les trigrammes .Bigram Check
$ echo " ??? ...." | ./alm -alphabet "abcdefghijklmnopqrstuvwxyz" -method counts -ngrams bigram -debug 1 -r-arpa ./lm.arpa -confidence
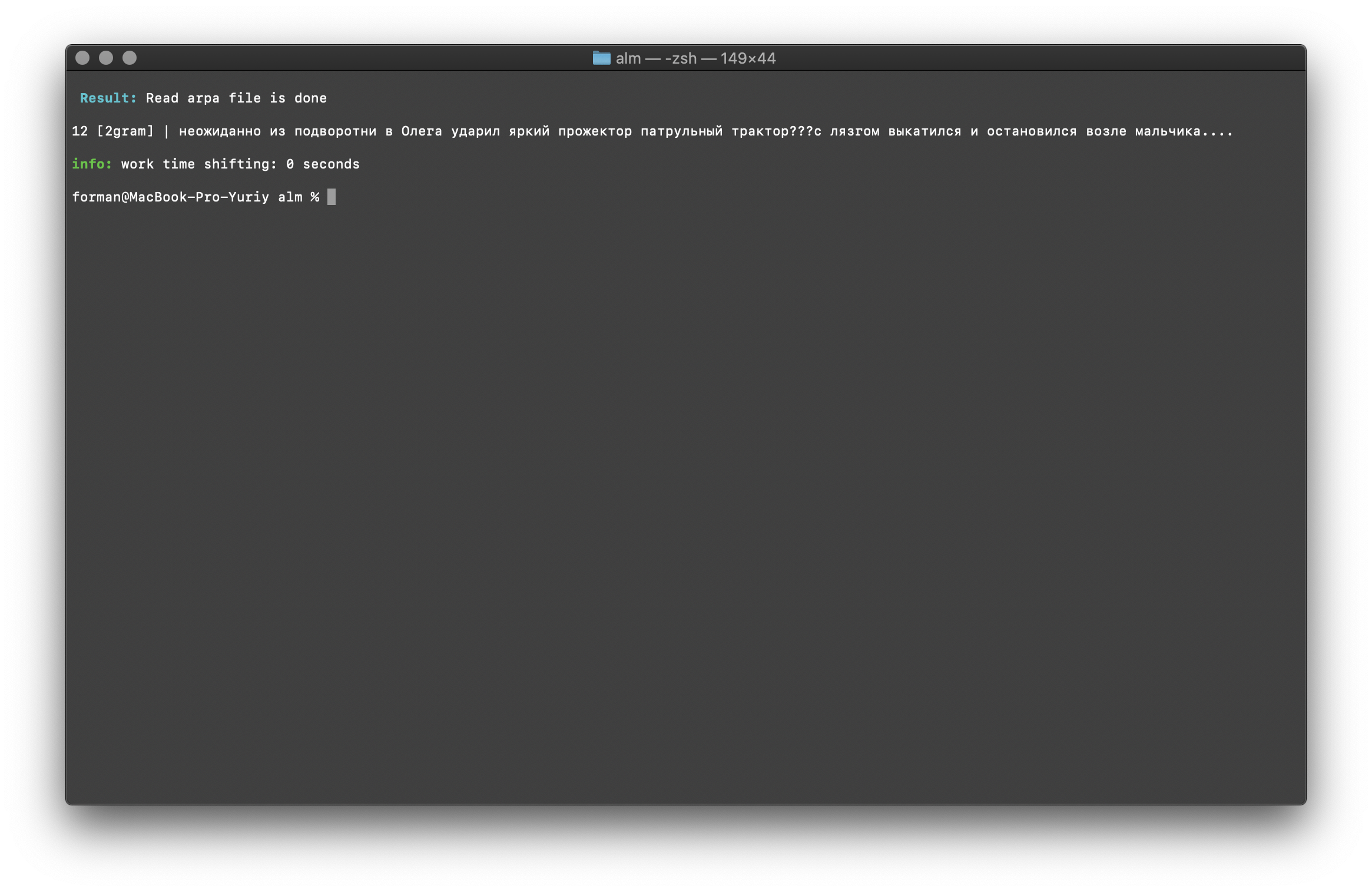 Tester:
Tester: ??? ....
Résultat:12 [2gram] | ??? ….
Vérification du trigramme
$ echo " ??? ...." | ./alm -alphabet "abcdefghijklmnopqrstuvwxyz" -method counts -ngrams trigram -debug 1 -r-arpa ./lm.arpa -confidence
Tester: ??? ....
Résultat:10 [3gram] | ??? ….
Recherche de N-grammes dans le texte
$ echo " " | ./alm -alphabet "abcdefghijklmnopqrstuvwxyz" -method find -debug 1 -r-arpa ./lm.arpa -confidence
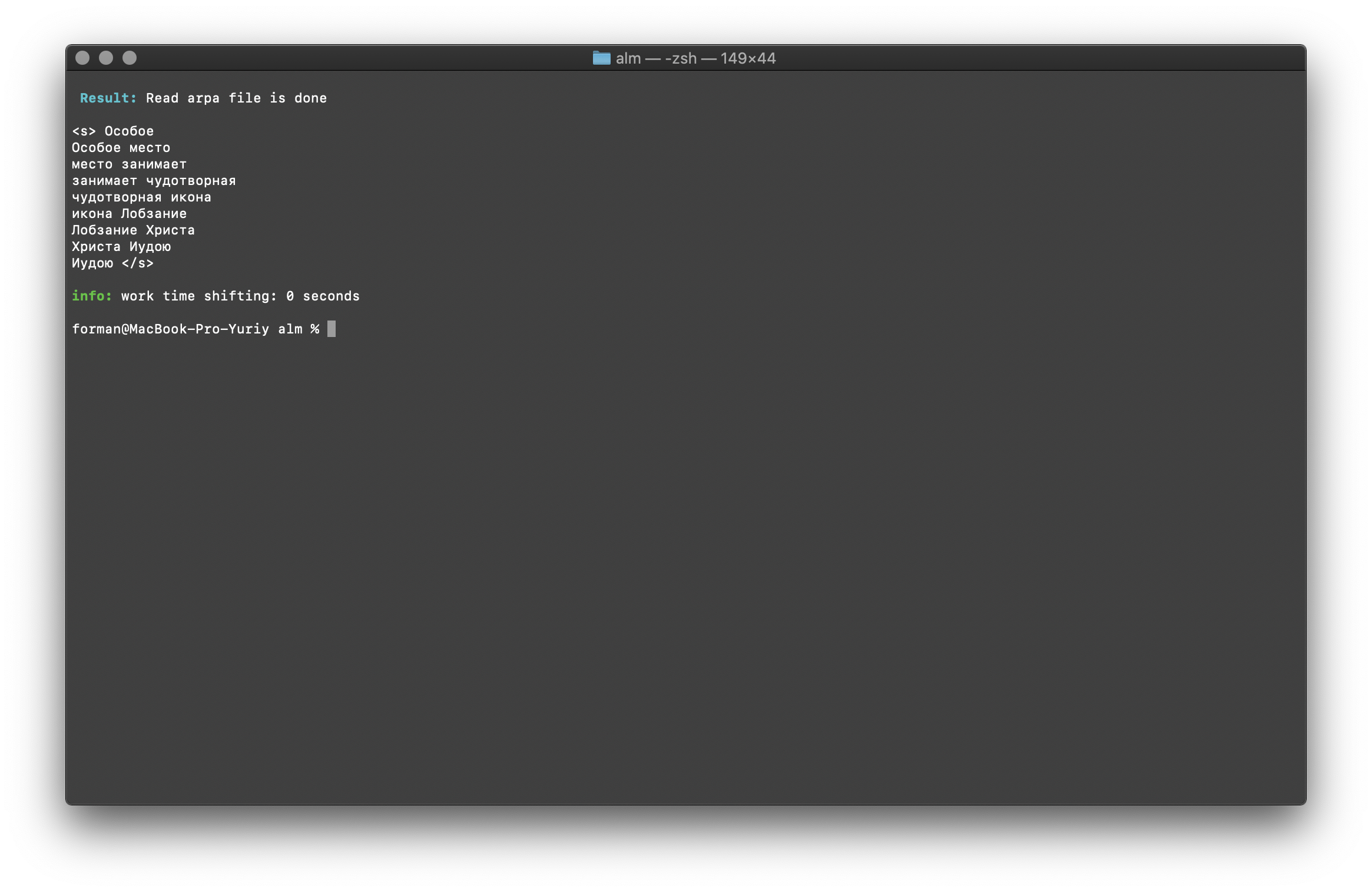 Tester:
Tester:
Résultat:<s>
</s>
Une liste de N-grammes qui se trouvent dans le texte. Il n'y a rien de spécial à expliquer ici.Variables d'environnement
Tous les paramètres peuvent être transmis via des variables d'environnement. Les variables commencent par le préfixe ALM_ et doivent être écrites en majuscules. Sinon, les noms de variables correspondent aux paramètres de l'application.Si les paramètres d'application et les variables d'environnement sont spécifiés, les paramètres d'application ont la priorité.$ export $ALM_SMOOTHING=wittenbell
$ export $ALM_W-ARPA=./lm.arpa
Ainsi, le processus d'assemblage peut être automatisé. Par exemple, via des scripts BASH.Conclusion
Je comprends qu'il existe des technologies plus prometteuses comme RnnLM ou Bert . Mais je suis sûr que les modèles statistiques en N-gramme seront pertinents pendant longtemps.Ce travail a pris beaucoup de temps et d'efforts. Il était engagé dans la bibliothèque pendant son temps libre pour le travail de base, la nuit et le week-end. Le code ne couvrait pas les tests, les erreurs et les bugs sont possibles. Je serai reconnaissant pour les tests. Je suis également ouvert aux suggestions d'amélioration et aux nouvelles fonctionnalités de la bibliothèque. ALM est distribué sous la licence MIT , ce qui vous permet de l'utiliser sans presque aucune restriction.J'espère avoir des commentaires, des critiques, des suggestions.Site de projet Référentiel de projet