Vous avez peut-être été confronté à la tâche du calcul parallèle sur des trames de données pandas. Ce problème peut être résolu à la fois par Python natif et à l'aide d'une merveilleuse bibliothèque - pandarallel. Dans cet article, je montrerai comment cette bibliothèque vous permet de traiter vos données en utilisant toutes les capacités disponibles.
La bibliothèque vous permet de ne pas penser au nombre de threads, de créer des processus et fournit une interface interactive pour suivre les progrès.
Installation
pip install pandas jupyter pandarallel requests tqdm
Comme vous pouvez le voir, j'installe également tqdm. Avec cela, je démontrerai clairement la différence de vitesse d'exécution de code dans une approche séquentielle et parallèle.
Personnalisation
import pandas as pd
import requests
from tqdm import tqdm
tqdm.pandas()
from pandarallel import pandarallel
pandarallel.initialize(progress_bar=True)
Vous pouvez trouver la liste complète des paramètres dans la documentation pandarallel.
Créer un bloc de données
Pour les expériences, créez un bloc de données simple - 100 lignes, 1 colonne.
df = pd.DataFrame(
[i for i in range(100)],
columns=["sample_column"]
)

Exemple d'une tâche adaptée à la parallélisation
Comme nous le savons, la solution de tous les problèmes ne peut pas être mise en parallèle. Un exemple simple d'une tâche appropriée consiste à appeler une source externe, telle qu'une API ou une base de données. Dans la fonction ci-dessous, j'appelle une API qui me renvoie un mot aléatoire. Mon objectif est d'ajouter une colonne avec des mots dérivés de cette API au bloc de données.
def function_to_apply(i):
r = requests.get(f'https://random-word-api.herokuapp.com/word').json()
return r[0]
df["sample-word"] = df.sample_column.progress_apply(function_to_apply)
, tqdm, — progress_apply apply. , , progress bar.

"" 35 .
, parallel_apply:
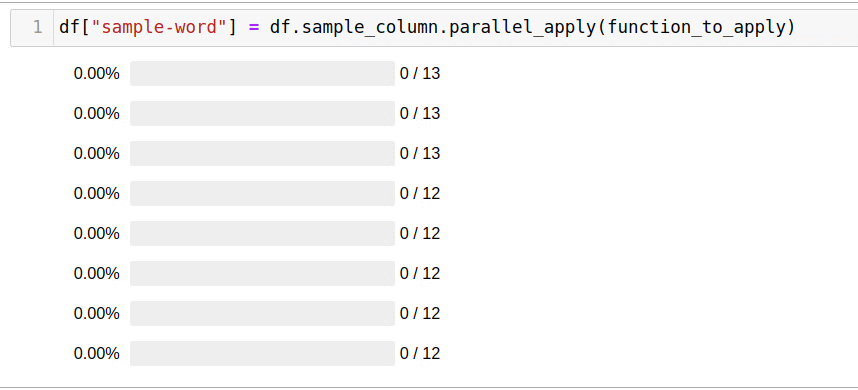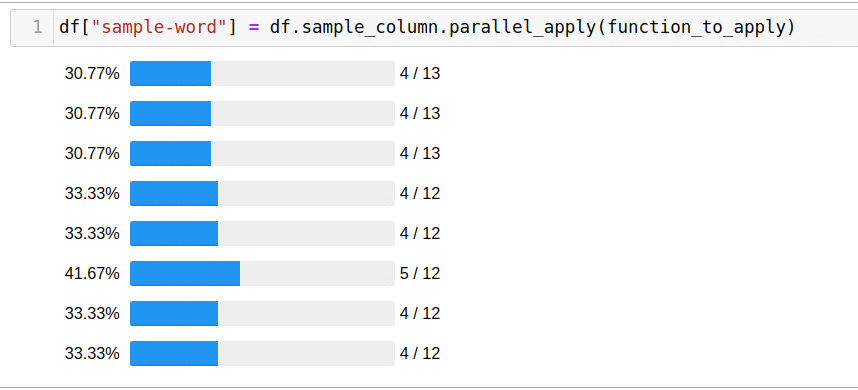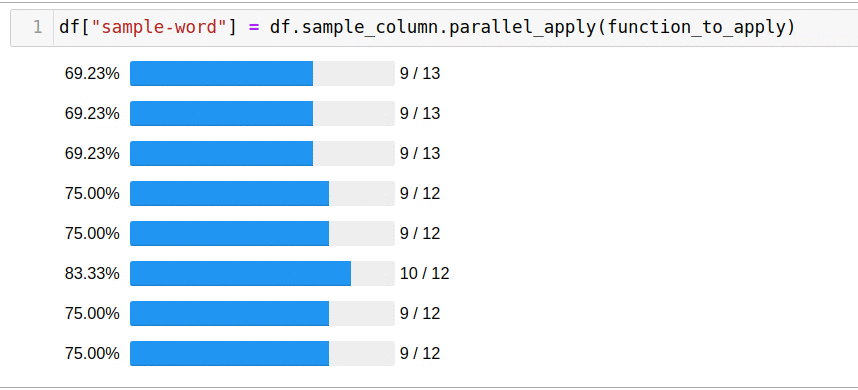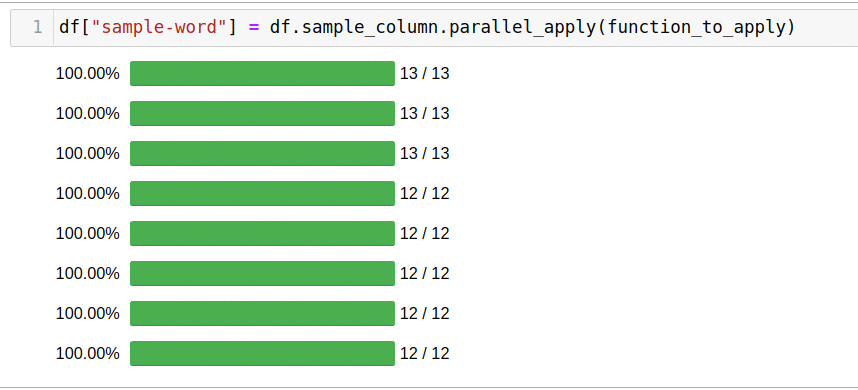
df["sample-word"] = df.sample_column.parallel_apply(function_to_apply)
5 .
pandas , pandarallel, Github .

! — .