Que dois-je faire si je veux écrire beaucoup de «faits» dans la base de données d'un volume beaucoup plus important qu'il ne peut en supporter? Tout d'abord, bien sûr, nous amenons les données sous une forme normale plus économique et obtenons des «dictionnaires», que nous écrirons une fois . Mais comment le faire le plus efficacement possible?C'est exactement la question à laquelle nous avons été confrontés lors du développement de la surveillance et de l'analyse des journaux du serveur PostgreSQL , lorsque d'autres méthodes d'optimisation de l'enregistrement dans la base de données ont été épuisées.Nous réserverons immédiatement que nos collecteurs exécutent Node.js , nous n'interagissons donc en aucune façon avec les registres et les caches de processeur. Et l'option d'utiliser "cent" ou des services / bases de données de mise en cache externes donne trop de retard pour les flux entrants de plusieurs centaines de Mbps .Par conséquent, nous essayons de tout mettre en cache dans la RAM , en particulier dans la mémoire du processus JavaScript. Comment organiser cela plus efficacement, et nous irons plus loin.Mise en cache de la disponibilité
Notre tâche principale est de nous assurer que la seule instance d'un objet pénètre dans la base de données. Ce sont les textes originaux répétés à plusieurs reprises des requêtes SQL, les modèles de plans pour leur mise en œuvre , les nœuds de ces plans - en bref, certains blocs de texte .Historiquement, comme identifiant, nous avons utilisé une UUIDvaleur-, qui a été obtenue à la suite du calcul direct du hachage MD5 à partir du texte de l'objet. Après cela, nous vérifions la disponibilité d'un tel hachage dans le "dictionnaire" local dans la mémoire de processus , et s'il n'est pas là, alors seulement nous écrivons dans la base de données dans la table "dictionnaire".Autrement dit, nous n'avons pas besoin de stocker la valeur de texte d'origine elle-même (et cela prend parfois des dizaines de kilo-octets) - le simple fait de la présence du hachage correspondant dans le dictionnaire suffit .Dictionnaire clé
Un tel dictionnaire peut être conservé Arrayet utilisé Array.includes()pour vérifier la disponibilité, mais cela est assez redondant - la recherche se dégrade (au moins dans les versions précédentes de V8) de façon linéaire par rapport à la taille du tableau, O (N). Et dans les implémentations modernes, malgré toutes les optimisations, il perd à une vitesse de 2-3%.Par conséquent, dans l'ère pré-ES6, le stockage était la solution traditionnelle Object, avec des valeurs stockées comme clés. Mais tout le monde a attribué aux valeurs des clés ce qu'il voulait - par exemple Boolean:var dict = {};
function has(key) {
return dict[key] !== undefined;
}
function add(key) {
dict[key] = true;
}
Mais il est bien évident que nous stockons clairement l'excédent ici - la valeur même de la clé dont personne n'a besoin. Mais que se passe-t-il s'il n'est pas stocké du tout? Ainsi, l' objet Set est apparu .Les tests montrent que la recherche avec aide est Set.has()environ 20-25% plus rapide que la vérification des clés c Object. Mais ce n'est pas son seul avantage. Étant donné que nous stockons moins, nous devons donc avoir besoin de moins de mémoire - et cela affecte directement les performances en ce qui concerne des centaines de milliers de ces clés.Ainsi, Objectdans laquelle il y a 100 clés UUID dans une représentation de texte, il occupe 6216 octets en mémoire :
Setavec le même contenu - 2632 octets :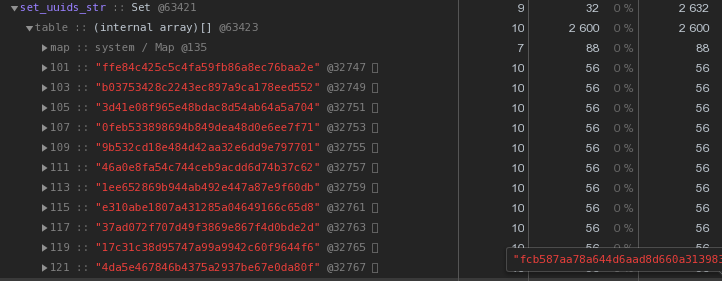 Autrement dit, il
Autrement dit, il Setfonctionne plus rapidement et prend en même temps2,5 fois moins de mémoire - le gagnant est évident.Nous optimisons le stockage des clés UUID
En général, dans la nature des systèmes distribués, les clés UUID sont assez courantes - dans notre VLSI, elles sont, au minimum, utilisées pour identifier les documents et les réglementations dans la gestion électronique des documents , les personnes dans la messagerie , ...Maintenant, regardons de plus près l'image ci-dessus - chaque UUID est la clé stockée dans la représentation hexadécimale "nous coûte" 56 octets de mémoire . Mais nous en avons des centaines de milliers, il est donc raisonnable de demander: "Est-il possible d'en avoir moins?"Tout d'abord, rappelez-vous que l'UUID est un identifiant de 16 octets. Essentiellement un morceau de données binaires. Et pour la transmission par e-mail, par exemple, les données binaires sont encodées en base64 - essayez de les appliquer:let str = Buffer.from(uuidstr, 'hex').toString('base64');
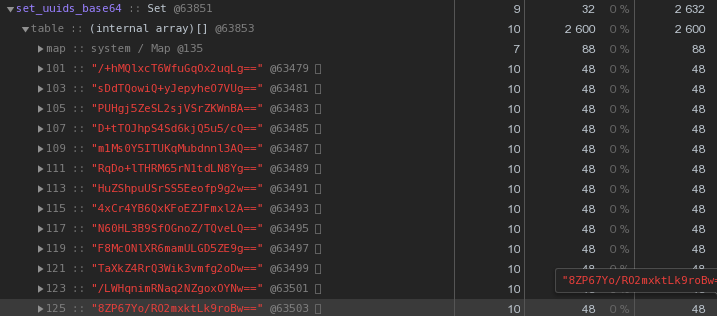 Déjà 48 octets chacun est mieux, mais imparfait. Essayons de traduire la représentation hexadécimale directement en chaîne:
Déjà 48 octets chacun est mieux, mais imparfait. Essayons de traduire la représentation hexadécimale directement en chaîne:let str = Buffer.from(uuidstr, 'hex').toString('binary');
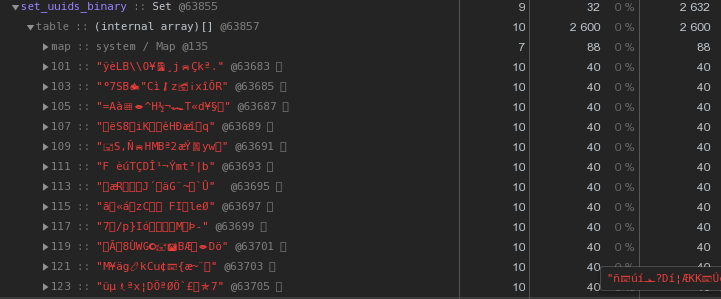 Au lieu de 56 octets par clé - 40 octets, économisez près de 30% !
Au lieu de 56 octets par clé - 40 octets, économisez près de 30% !Maître, travailleur - où stocker les dictionnaires?
Considérant que les données de vocabulaire des travailleurs se croisent assez fortement, nous avons fait le stockage des dictionnaires et les écrire dans la base de données dans le processus maître, et le transfert des données des travailleurs via le mécanisme de message IPC .Cependant, une grande partie du temps du maître a été consacrée à channel.onread- c'est-à-dire au traitement de la réception des paquets contenant des informations de "dictionnaire" provenant des processus enfants: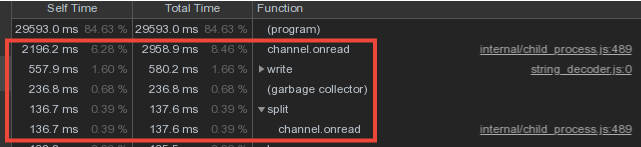
Barrière d'écriture à double réglage
Réfléchissons maintenant une seconde - les travailleurs envoient et envoient au maître les mêmes données de vocabulaire (fondamentalement, ce sont les modèles de plan et les corps de demande répétitifs), il les analyse avec sa sueur et ... ne fait rien, car ils ont déjà été envoyés à la base de données avant !Donc, si nous Set«protégions» la base de données du réenregistrement du maître avec un dictionnaire, pourquoi ne pas utiliser la même approche pour «protéger» le maître du transfert du travailleur? ..En fait, cela a été fait et a réduit les coûts directs de maintenance du canal d'échange à trois reprises. :
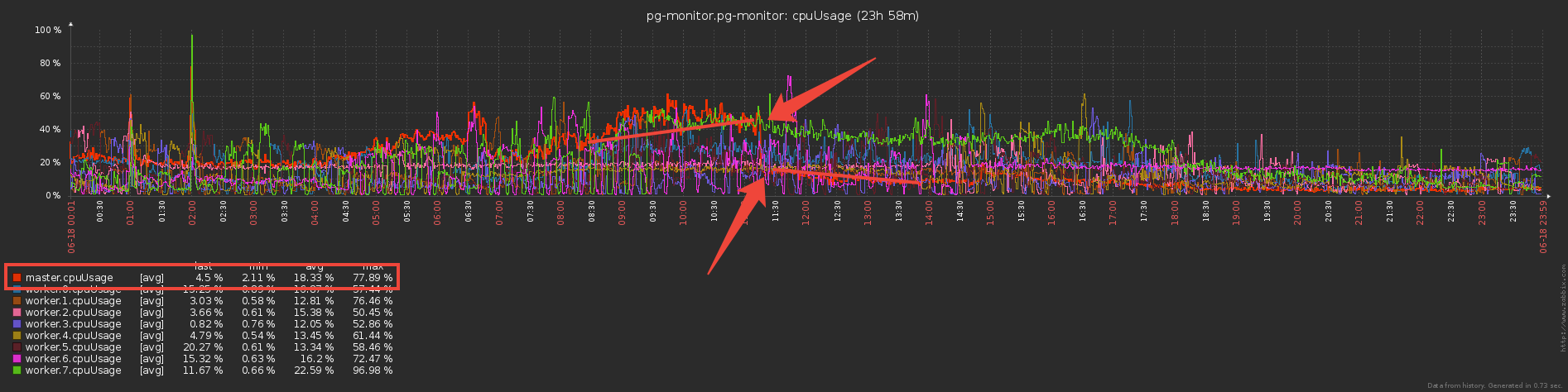 Mais maintenant, les travailleurs semblent faire plus de travail - stocker des dictionnaires et filtrer par eux? Ou pas? .. En fait, ils ont commencé à travailler beaucoup moins, car le transfert de gros volumes (même via IPC!) N'est pas bon marché.
Mais maintenant, les travailleurs semblent faire plus de travail - stocker des dictionnaires et filtrer par eux? Ou pas? .. En fait, ils ont commencé à travailler beaucoup moins, car le transfert de gros volumes (même via IPC!) N'est pas bon marché.Bon bonus
Alors que l'assistant commençait maintenant à recevoir une quantité d'informations beaucoup plus petite, il a commencé à allouer beaucoup moins de mémoire à ces conteneurs - ce qui signifie que le temps consacré au travail du garbage collector a considérablement diminué, ce qui a eu une incidence positive sur la latence du système dans son ensemble.Un tel système offre une protection contre les entrées répétées au niveau du collecteur, mais que faire si nous avons plusieurs collecteurs? Seul le déclencheur avec vous aidera ici INSERT ... ON CONFLICT DO NOTHING.Accélérez le calcul du hachage
Dans notre architecture, l'intégralité du flux de journaux d'un serveur PostgreSQL est traité par un seul travailleur.Autrement dit, un serveur est une tâche pour le travailleur. Dans le même temps, le chargement des travailleurs est équilibré par le but des tâches du serveur, de sorte que la consommation de CPU par les travailleurs de tous les collecteurs est approximativement la même. Il s'agit d'un répartiteur de services distinct.«En moyenne», chaque travailleur gère des dizaines de tâches qui produisent approximativement la même charge totale. Cependant, il existe des serveurs qui dépassent considérablement les autres en termes de nombre d'entrées de journal. Et même si le répartiteur laisse cette tâche la seule sur le travailleur, son téléchargement est beaucoup plus élevé que les autres:Nous avons supprimé le profil CPU de ce travailleur: Sur les premières lignes, le calcul des hachages MD5. Et ils sont vraiment calculés en quantité énorme - pour l'ensemble du flux d'objets entrants.
Sur les premières lignes, le calcul des hachages MD5. Et ils sont vraiment calculés en quantité énorme - pour l'ensemble du flux d'objets entrants.xxHash
Comment optimiser cette partie, hormis ces hachages, on ne peut pas?Nous avons décidé d'essayer une autre fonction de hachage - xxHash , qui implémente un algorithme de hachage non cryptographique extrêmement rapide . Et le module pour Node.js est xxhash-addon , qui utilise la dernière bibliothèque xxHash 0.7.3 avec le nouvel algorithme XXH3.Vérifiez en exécutant chaque option sur un ensemble de lignes de différentes longueurs:const crypto = require('crypto');
const { XXHash3, XXHash64 } = require('xxhash-addon');
const hasher3 = new XXHash3(0xDEADBEAF);
const hasher64 = new XXHash64(0xDEADBEAF);
const buf = Buffer.allocUnsafe(16);
const getBinFromHash = (hash) => buf.fill(hash, 'hex').toString('binary');
const funcs = {
xxhash64 : (str) => hasher64.hash(Buffer.from(str)).toString('binary')
, xxhash3 : (str) => hasher3.hash(Buffer.from(str)).toString('binary')
, md5 : (str) => getBinFromHash(crypto.createHash('md5').update(str).digest('hex'))
};
const check = (hash) => {
let log = [];
let cnt = 10000;
while (cnt--) log.push(crypto.randomBytes(cnt).toString('hex'));
console.time(hash);
log.forEach(funcs[hash]);
console.timeEnd(hash);
};
Object.keys(funcs).forEach(check);
Résultats:xxhash64 : 148.268ms
xxhash3 : 108.337ms
md5 : 317.584ms
Comme prévu , xxhash3 était beaucoup plus rapide que MD5 !Reste à vérifier la résistance aux collisions. Des sections de tables de dictionnaires sont créées chaque jour pour nous, donc en dehors des limites de la journée, nous pouvons en toute sécurité permettre l'intersection des hachages.Mais juste au cas où, nous avons vérifié avec une marge dans l'intervalle de trois jours - pas un seul conflit qui nous convient plus que suffisant.Remplacement de hachage
Mais nous ne pouvons tout simplement pas prendre et échanger d'anciens champs UUID dans les tables de dictionnaire pour un nouveau hachage, car la base de données et le frontend existant attendent que les objets continuent d'être identifiés par UUID.Par conséquent, nous ajouterons un cache supplémentaire au collecteur - pour MD5 déjà calculé. Maintenant, ce sera une carte , dans laquelle les clés sont xxhash3, les valeurs sont MD5. Pour des lignes identiques, nous ne recomptons pas le MD5 «cher», mais le prenons dans le cache:const getHashFromBin = (bin) => Buffer.from(bin, 'binary').toString('hex');
const dictmd5 = new Map();
const getmd5 = (data) => {
const hash = xxhash(data);
let md5hash = dictmd5.get(hash);
if (!md5hash) {
md5hash = md5(data);
dictmd5.set(hash, getBinFromHash(md5hash));
return md5hash;
}
return getHashFromBin(md5hash);
};
Nous supprimons le profil - la fraction du temps de calcul des hachages a considérablement diminué, bravo! Alors maintenant, nous comptons xxhash3, puis vérifions le cache MD5 et obtenons le MD5 souhaité, puis vérifions le cache du dictionnaire - si ce md5 n'est pas là, envoyez-le à la base de données pour l'écriture.Quelque chose de trop de vérifications ... Pourquoi vérifier le cache du dictionnaire si vous avez déjà vérifié le cache MD5? Il s'avère que tous les caches de dictionnaire ne sont plus nécessaires et il suffit d'avoir un seul cache - pour MD5, avec lequel toutes les opérations de base seront effectuées:
Alors maintenant, nous comptons xxhash3, puis vérifions le cache MD5 et obtenons le MD5 souhaité, puis vérifions le cache du dictionnaire - si ce md5 n'est pas là, envoyez-le à la base de données pour l'écriture.Quelque chose de trop de vérifications ... Pourquoi vérifier le cache du dictionnaire si vous avez déjà vérifié le cache MD5? Il s'avère que tous les caches de dictionnaire ne sont plus nécessaires et il suffit d'avoir un seul cache - pour MD5, avec lequel toutes les opérations de base seront effectuées: En conséquence, nous avons remplacé l'archivage dans plusieurs dictionnaires «objet» par un seul cache MD5, et l'opération gourmande en ressources du calcul de MD5 est Le hachage est effectué uniquement pour les nouvelles entrées, en utilisant le xxhash beaucoup plus efficace pour le flux entrant.remercierKilor pour vous aider à préparer l'article.
En conséquence, nous avons remplacé l'archivage dans plusieurs dictionnaires «objet» par un seul cache MD5, et l'opération gourmande en ressources du calcul de MD5 est Le hachage est effectué uniquement pour les nouvelles entrées, en utilisant le xxhash beaucoup plus efficace pour le flux entrant.remercierKilor pour vous aider à préparer l'article.