Bonjour chers abonnés! Vous savez probablement déjà que nous avons lancé un nouveau cours, «Vision par ordinateur», qui commencera les cours dans les prochains jours. En prévision du début des cours, nous avons préparé une autre traduction intéressante pour l'immersion dans le monde du CV.
Mon hobby est de jouer à des jeux de société, et comme je suis un peu familier avec les réseaux de neurones convolutionnels, j'ai décidé de créer une application qui peut battre une personne dans un jeu de cartes. Je voulais construire un modèle à partir de zéro en utilisant mon propre ensemble de données et voir à quel point cela fonctionne avec un petit ensemble de données. J'ai décidé de commencer par le simple jeu Dobble (également connu sous le nom de Spot it!).Si vous ne savez pas ce qu'est Dobble, je rappellerai brièvement les règles du jeu: Dobble est un jeu de reconnaissance de formes simple dans lequel les joueurs essaient de trouver une image représentée simultanément sur deux cartes. Chaque carte du jeu Dobble original contient huit personnages différents, et sur différentes cartes, ils sont de tailles différentes. Deux cartes ont un seul symbole commun. Si vous trouvez d'abord le symbole, prenez une carte. Lorsque le jeu de 55 cartes se termine, celui avec le plus de cartes gagne. Essayez-le par vous-même: quel symbole est commun à ces deux cartes?
Essayez-le par vous-même: quel symbole est commun à ces deux cartes?Où commencer?
La première étape de la résolution de toute tâche d'analyse de données consiste à collecter des données. J'ai pris six photos de chaque carte au téléphone. Au total, 330 photos se sont avérées. Vous en voyez quatre ci-dessous. Vous vous demandez peut-être si cela suffit pour créer un bon réseau de neurones convolutionnels? Nous y reviendrons!
Traitement d'image
OK, les données que nous avons, quelle est la prochaine étape? Probablement la partie la plus importante sur la voie du succès: le traitement d'image. Nous devons obtenir des personnages de chaque image. Quelques difficultés nous attendent ici. Sur les photos ci-dessus, on remarque que certains personnages sont plus difficiles à distinguer que d'autres: le bonhomme de neige et le fantôme (sur la troisième photo) et l'aiguille (sur la quatrième) de couleurs claires, et les taches (sur la deuxième photo) et le point d'exclamation (sur la quatrième photo) sont constitués de plusieurs parties . Pour traiter les caractères clairs, nous ajouterons du contraste. Après cela, nous allons redimensionner et enregistrer l'image.Ajouter du contraste
Pour ajouter du contraste, nous utilisons l'espace colorimétrique Lab. L est la légèreté, a est la composante chromatique dans la gamme du vert au magenta, et b est la composante chromatique dans la gamme du bleu au jaune. Nous pouvons facilement extraire ces composants en utilisant OpenCV :import cv2
import imutils
imgname = 'picture1'
image = cv2.imread(f’{imgname}.jpg’)
lab = cv2.cvtColor(image, cv2.COLOR_BGR2LAB)
l, a, b = cv2.split(lab)
 De gauche à droite: l'image d'origine, le composant de luminosité, le composant a et le composant bMaintenant, nous ajoutons du contraste au composant de luminosité, combinons à nouveau tous les composants ensemble et convertissons en une image normale:
De gauche à droite: l'image d'origine, le composant de luminosité, le composant a et le composant bMaintenant, nous ajoutons du contraste au composant de luminosité, combinons à nouveau tous les composants ensemble et convertissons en une image normale:clahe = cv2.createCLAHE(clipLimit=3.0, tileGridSize=(8,8))
cl = clahe.apply(l)
limg = cv2.merge((cl,a,b))
final = cv2.cvtColor(limg, cv2.COLOR_LAB2BGR)
 De gauche à droite: l'image d'origine, la composante de luminosité, l'image avec un contraste élevé et l'image reconvertie en RVB
De gauche à droite: l'image d'origine, la composante de luminosité, l'image avec un contraste élevé et l'image reconvertie en RVBChangement de taille
Maintenant, redimensionnez et enregistrez l'image:resized = cv2.resize(final, (800, 800))
# save the image
cv2.imwrite(f'{imgname}processed.jpg', blurred)
Terminé!Reconnaissance des cartes et des caractères
Maintenant que l'image est traitée, nous pouvons détecter une carte dans l'image. En utilisant OpenCV, nous recherchons des contours externes. Ensuite, nous convertissons l'image en demi-teintes, sélectionnons la valeur de seuil (dans notre cas, 190) pour créer une image en noir et blanc et recherchons un chemin. Le code:image = cv2.imread(f’{imgname}processed.jpg’)
gray = cv2.cvtColor(image, cv2.COLOR_RGB2GRAY)
thresh = cv2.threshold(gray, 190, 255, cv2.THRESH_BINARY)[1]
# find contours
cnts = cv2.findContours(thresh.copy(), cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
cnts = imutils.grab_contours(cnts)
output = image.copy()
# draw contours on image
for c in cnts:
cv2.drawContours(output, [c], -1, (255, 0, 0), 3)
 Image traitée convertie en demi-teintes en utilisant le seuil et en sélectionnant les contours externesSi nous trions les contours externes par zone, nous trouverons le contour avec la plus grande zone - ce sera notre carte. Pour extraire les caractères, nous pouvons créer un fond blanc.
Image traitée convertie en demi-teintes en utilisant le seuil et en sélectionnant les contours externesSi nous trions les contours externes par zone, nous trouverons le contour avec la plus grande zone - ce sera notre carte. Pour extraire les caractères, nous pouvons créer un fond blanc.# sort by area, grab the biggest one
cnts = sorted(cnts, key=cv2.contourArea, reverse=True)[0]
# create mask with the biggest contour
mask = np.zeros(gray.shape,np.uint8)
mask = cv2.drawContours(mask, [cnts], -1, 255, cv2.FILLED)
# card in foreground
fg_masked = cv2.bitwise_and(image, image, mask=mask)
# white background (use inverted mask)
mask = cv2.bitwise_not(mask)
bk = np.full(image.shape, 255, dtype=np.uint8)
bk_masked = cv2.bitwise_and(bk, bk, mask=mask)
# combine back- and foreground
final = cv2.bitwise_or(fg_masked, bk_masked)
 Masque, arrière-plan, image de premier plan, image finaleIl est maintenant temps de reconnaître les caractères! Nous pouvons utiliser l'image résultante pour détecter à nouveau les contours externes, ces contours seront des symboles. Si nous créons un carré autour de chaque symbole, nous pouvons extraire cette zone. Ici, le code est un peu plus long:
Masque, arrière-plan, image de premier plan, image finaleIl est maintenant temps de reconnaître les caractères! Nous pouvons utiliser l'image résultante pour détecter à nouveau les contours externes, ces contours seront des symboles. Si nous créons un carré autour de chaque symbole, nous pouvons extraire cette zone. Ici, le code est un peu plus long:
gray = cv2.cvtColor(final, cv2.COLOR_RGB2GRAY)
thresh = cv2.threshold(gray, 195, 255, cv2.THRESH_BINARY)[1]
thresh = cv2.bitwise_not(thresh)
cnts = cv2.findContours(thresh.copy(), cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
cnts = imutils.grab_contours(cnts)
cnts = sorted(cnts, key=cv2.contourArea, reverse=True)[:10]
i = 0
for c in cnts:
if cv2.contourArea(c) > 1000:
mask = np.zeros(gray.shape, np.uint8)
mask = cv2.drawContours(mask, [c], -1, 255, cv2.FILLED)
fg_masked = cv2.bitwise_and(image, image, mask=mask)
mask = cv2.bitwise_not(mask)
bk = np.full(image.shape, 255, dtype=np.uint8)
bk_masked = cv2.bitwise_and(bk, bk, mask=mask)
finalcont = cv2.bitwise_or(fg_masked, bk_masked)
output = finalcont.copy()
x,y,w,h = cv2.boundingRect(c)
if w < h:
x += int((w-h)/2)
w = h
else:
y += int((h-w)/2)
h = w
roi = finalcont[y:y+h, x:x+w]
roi = cv2.resize(roi, (400,400))
cv2.imwrite(f"{imgname}_icon{i}.jpg", roi)
i += 1
 Image en noir et blanc (seuillée), contours détectés, symbole fantôme et symbole coeur (caractères extraits avec des masques)
Image en noir et blanc (seuillée), contours détectés, symbole fantôme et symbole coeur (caractères extraits avec des masques)Tri des caractères
Et maintenant le plus ennuyeux! Vous devez trier les caractères. Vous aurez besoin des répertoires de formation, de test et de validation, 57 répertoires chacun (nous avons 57 caractères différents au total). La structure des dossiers est la suivante:symbols
├── test
│ ├── anchor
│ ├── apple
│ │ ...
│ └── zebra
├── train
│ ├── anchor
│ ├── apple
│ │ ...
│ └── zebra
└── validation
├── anchor
├── apple
│ ...
└── zebra
Il faudra un certain temps pour mettre les caractères extraits (plus de 2500 pièces) dans les répertoires nécessaires! J'ai du code pour créer des sous-dossiers, une suite de tests et un kit de validation sur GitHub . Peut-être que la prochaine fois, il vaut mieux faire le tri basé sur l'algorithme de clustering ...Formation au réseau neuronal convolutif
Après la partie ennuyeuse, le plaisir revient! Il est temps de créer et de former un réseau neuronal convolutionnel. Vous pouvez trouver des informations sur les réseaux de neurones convolutifs ici .Architecture du modèle
Nous avons pour tâche de classer plusieurs classes avec une seule étiquette. Pour chaque personnage, nous avons besoin d'une étiquette. C'est pourquoi nous aurons besoin d'une fonction pour activer la couche softmax de sortie avec 57 nœuds et une entropie croisée catégorielle comme fonction de perte.L'architecture du modèle final est la suivante:
from keras import layers
from keras import models
from keras import optimizers
from keras.preprocessing.image import ImageDataGenerator
import matplotlib.pyplot as plt
model = models.Sequential()
model.add(layers.Conv2D(32, (3, 3), activation='relu', input_shape=(400, 400, 3)))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(256, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(256, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.Flatten())
model.add(layers.Dropout(0.5))
model.add(layers.Dense(512, activation='relu'))
model.add(layers.Dense(57, activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer=optimizers.RMSprop(lr=1e-4), metrics=['acc'])
Augmentation des données
Pour améliorer les performances, j'ai utilisé l'augmentation des données. L'augmentation des données est le processus d'augmentation du volume et de la variété des données d'entrée. Cela peut être fait en faisant pivoter, déplacer, redimensionner, recadrer et retourner les images existantes. Keras peut facilement augmenter les données:
train_dir = 'symbols/train'
validation_dir = 'symbols/validation'
test_dir = 'symbols/test'
train_datagen = ImageDataGenerator(rescale=1./255, rotation_range=40, width_shift_range=0.1, height_shift_range=0.1, shear_range=0.1, zoom_range=0.1, horizontal_flip=True, vertical_flip=True)
test_datagen = ImageDataGenerator(rescale=1./255)
train_generator = train_datagen.flow_from_directory(train_dir, target_size=(400,400), batch_size=20, class_mode='categorical')
validation_generator = test_datagen.flow_from_directory(validation_dir, target_size=(400,400), batch_size=20, class_mode='categorical')
Si vous étiez intéressé, le fantôme augmenté ressemble à ceci: L'image originale du fantôme sur la gauche, des fantômes augmentés dans toutes les autres images
L'image originale du fantôme sur la gauche, des fantômes augmentés dans toutes les autres imagesFormation modèle
Entraînons le modèle, enregistrons-le pour l'utiliser pour les prévisions et vérifions les résultats.history = model.fit_generator(train_generator, steps_per_epoch=100, epochs=100, validation_data=validation_generator, validation_steps=50)
model.save('models/model.h5')
 Des prédictions parfaites!
Des prédictions parfaites!résultats
Le modèle de base que j'ai formé sans augmentation de données, abandons et avec moins de couches. Ce modèle a donné les résultats suivants: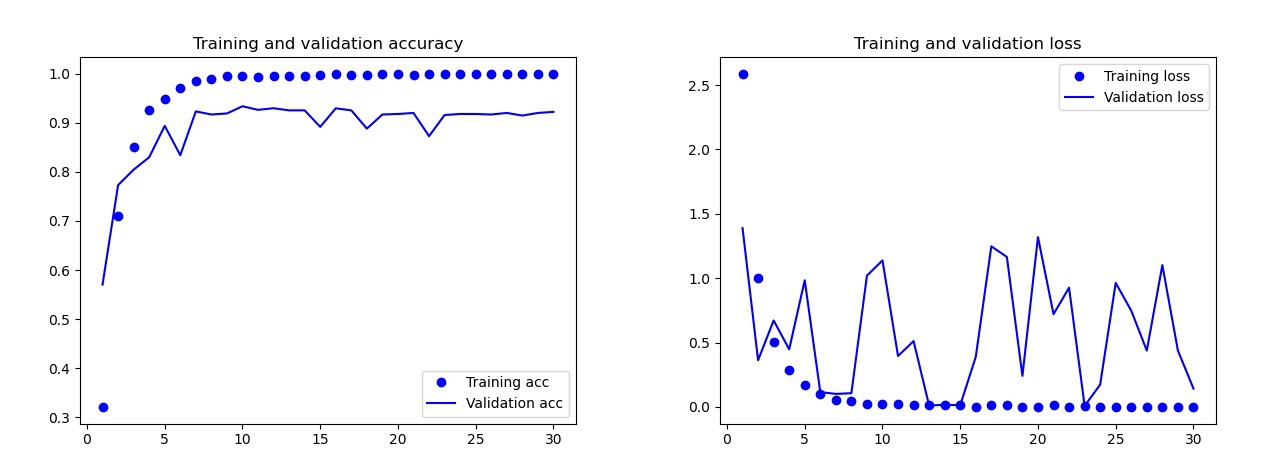 Les résultats du modèle de base Al'œil nu, il est clair que ce modèle est recyclé. Les résultats de la version finale du modèle (son code est présenté dans les sections précédentes) sont bien meilleurs. Sur le graphique ci-dessous, vous pouvez voir la précision et les pertes pendant la formation et sur l'ensemble de validation.
Les résultats du modèle de base Al'œil nu, il est clair que ce modèle est recyclé. Les résultats de la version finale du modèle (son code est présenté dans les sections précédentes) sont bien meilleurs. Sur le graphique ci-dessous, vous pouvez voir la précision et les pertes pendant la formation et sur l'ensemble de validation. Résultats du modèle finalSur le banc d'essai, ce modèle n'a commis qu'une seule erreur, il a reconnu la bombe comme une goutte. J'ai décidé de rester sur ce modèle, la précision sur l'ensemble de test était de 0,995.
Résultats du modèle finalSur le banc d'essai, ce modèle n'a commis qu'une seule erreur, il a reconnu la bombe comme une goutte. J'ai décidé de rester sur ce modèle, la précision sur l'ensemble de test était de 0,995.Reconnaissance d'un symbole commun sur deux cartes
Vous pouvez maintenant commencer à rechercher des symboles communs sur deux cartes. Nous utilisons deux photographies, nous allons faire des prédictions pour chaque image séparément et utiliser l'intersection d'ensembles pour savoir quel symbole est sur les deux cartes. Nous avons 3 options de travail:- Une erreur s'est produite lors de la prédiction: aucun personnage commun n'a été trouvé.
- Il y a un symbole à l'intersection (la prédiction peut être vraie ou fausse).
- Il y a plus d'un caractère à l'intersection. Dans ce cas, je choisis le symbole avec la probabilité la plus élevée (la moyenne des deux prédictions).
Le code pour prédire toute la combinaison des deux images dans les mensonges de catalogue avec GitHub de main.py.Et voici les résultats:
Conclusion
N'est-ce pas le modèle parfait? Malheureusement non. Quand j'ai pris de nouvelles photos des cartes et leur ai donné les modèles de prédiction, il y avait des problèmes avec le bonhomme de neige. Parfois, il reconnaissait l'œil ou le zèbre comme un bonhomme de neige! En conséquence, parfois les résultats étaient étranges: Eh bien, où est le bonhomme de neige ici?Ce modèle est-il meilleur que l'homme? Selon ce dont nous avons besoin: les gens reconnaissent parfaitement, mais le modèle le fait plus rapidement! J'ai remarqué le temps pendant lequel l'ordinateur fait face: j'ai donné un jeu de 55 cartes et j'ai dû obtenir un symbole commun pour chaque combinaison de deux cartes. Au total, ce sont 1485 combinaisons. L'ordinateur l'a fait en moins de 140 secondes. Il a fait quelques erreurs, mais il battra certainement n'importe qui en matière de vitesse!
Eh bien, où est le bonhomme de neige ici?Ce modèle est-il meilleur que l'homme? Selon ce dont nous avons besoin: les gens reconnaissent parfaitement, mais le modèle le fait plus rapidement! J'ai remarqué le temps pendant lequel l'ordinateur fait face: j'ai donné un jeu de 55 cartes et j'ai dû obtenir un symbole commun pour chaque combinaison de deux cartes. Au total, ce sont 1485 combinaisons. L'ordinateur l'a fait en moins de 140 secondes. Il a fait quelques erreurs, mais il battra certainement n'importe qui en matière de vitesse! Je ne pense pas qu'il soit difficile de créer un modèle 100% fonctionnel. Cela peut être réalisé grâce à une formation de transfert. Pour comprendre ce que fait le modèle, nous pourrions visualiser des couches pour l'image de test. Vous pouvez le faire la prochaine fois!
Je ne pense pas qu'il soit difficile de créer un modèle 100% fonctionnel. Cela peut être réalisé grâce à une formation de transfert. Pour comprendre ce que fait le modèle, nous pourrions visualiser des couches pour l'image de test. Vous pouvez le faire la prochaine fois!
En savoir plus sur le cours et réussir le test d'entrée