 (image prise d'ici )
(image prise d'ici )
Aujourd'hui, nous aimerions vous parler de la tâche de post-traitement des résultats de la reconnaissance des champs de texte sur la base d'une connaissance a priori du champ. Plus tôt, nous avons déjà écrit sur la méthode de correction de champ basée sur les trigrammes , qui vous permet de corriger certaines erreurs de reconnaissance des mots écrits en langues naturelles. Cependant, une partie importante des documents importants, y compris les documents d'identification, sont des champs de nature différente - dates, numéros, codes VIN des voitures, numéros TIN et SNILS, zones lisibles par machineavec leurs sommes de contrôle et plus encore. Bien qu'ils ne puissent pas être attribués aux champs d'un langage naturel, ces champs ont néanmoins souvent un modèle de langage, parfois implicite, ce qui signifie que certains algorithmes de correction peuvent également leur être appliqués. Dans cet article, nous discuterons de deux mécanismes pour les résultats de reconnaissance de post-traitement qui peuvent être utilisés pour un grand nombre de documents et de types de champs.Le modèle de langage du champ peut être conditionnellement divisé en trois composantes:- Syntaxe : règles régissant la structure d'une représentation de champ de texte. Exemple: le champ «date d'expiration du document» dans une zone lisible par machine est représenté par sept chiffres «DDDDDDD».
- : , . : “ ” - – , 3- 4- – , 5- 6- – , 7- – .
- : , . : “ ” , , “ ”.
Ayant des informations sur la structure sémantique et syntaxique du document et le champ reconnu, vous pouvez créer un algorithme spécialisé pour le post-traitement du résultat de la reconnaissance. Cependant, compte tenu de la nécessité de soutenir et de développer des systèmes de reconnaissance et de la complexité de leur développement, il est intéressant de considérer des méthodes et des outils «universels» qui permettraient, avec un minimum d'effort (de la part des développeurs), de construire un algorithme de post-traitement assez bon qui fonctionnerait avec une classe étendue. documents et champs. La méthodologie de configuration et de prise en charge d'un tel algorithme serait unifiée et seul le modèle de langage serait une composante variable de la structure de l'algorithme.Il convient de noter que le post-traitement des résultats de la reconnaissance des champs de texte n'est pas toujours utile, et parfois même nuisible: si vous avez un module de reconnaissance de ligne assez bon et que vous travaillez dans des systèmes critiques avec des documents d'identification, alors une sorte de post-traitement il est préférable de minimiser et de produire des résultats «tels quels», ou de surveiller clairement tout changement et de le signaler au client. Cependant, dans de nombreux cas, lorsque l'on sait que le document est valide et que le modèle de langage du champ est fiable, l'utilisation d'algorithmes de post-traitement peut augmenter considérablement la qualité de reconnaissance finale.Ainsi, l'article discutera de deux méthodes de post-traitement qui prétendent être universelles. Le premier est basé sur des convertisseurs finis pondérés, nécessite une description du modèle de langage sous la forme d'une machine à états finis, n'est pas très facile à utiliser, mais plus universel. La seconde est plus facile à utiliser, plus efficace, ne nécessite que l'écriture d'une fonction pour vérifier la validité de la valeur du champ, mais présente également un certain nombre d'inconvénients.Méthode de l'émetteur d'extrémité pondérée
Un beau modèle assez général qui vous permet de construire un algorithme universel pour les résultats de reconnaissance de post-traitement est décrit dans ce travail . Le modèle repose sur la structure des données des transducteurs à état fini pondéré (WFST).Les WFST sont une généralisation des machines à états finis pondérés - si une machine à états finis pondérée code une langue pondérée  (c'est-à-dire un ensemble pondéré de lignes sur un alphabet
(c'est-à-dire un ensemble pondéré de lignes sur un alphabet  ), alors WFST code une carte pondérée de la langue
), alors WFST code une carte pondérée de la langue  au-dessus de l'alphabet
au-dessus de l'alphabet  dans la langue
dans la langue  au-dessus de l'alphabet
au-dessus de l'alphabet  . Une machine à états finis pondérée, prenant une chaîne
. Une machine à états finis pondérée, prenant une chaîne  sur l'alphabet , lui attribue un poids
sur l'alphabet , lui attribue un poids  , tandis que WFST, prenant une chaîne
, tandis que WFST, prenant une chaîne sur l'alphabet , lui associe un ensemble de paires (éventuellement infinies)
sur l'alphabet , lui associe un ensemble de paires (éventuellement infinies)  , où
, où  est la ligne au-dessus de l'alphabet dans laquelle la ligne est convertie , et
est la ligne au-dessus de l'alphabet dans laquelle la ligne est convertie , et  est le poids d'une telle conversion. Chaque transition du convertisseur est caractérisée par deux états (entre lesquels la transition est effectuée), les caractères d'entrée (de l'alphabet ), les caractères de sortie (de l'alphabet ) et le poids de la transition. Un caractère vide (chaîne vide) est considéré comme un élément des deux alphabets. Le poids de la conversion de chaîne
est le poids d'une telle conversion. Chaque transition du convertisseur est caractérisée par deux états (entre lesquels la transition est effectuée), les caractères d'entrée (de l'alphabet ), les caractères de sortie (de l'alphabet ) et le poids de la transition. Un caractère vide (chaîne vide) est considéré comme un élément des deux alphabets. Le poids de la conversion de chaîne  en chaîne
en chaîne  est la somme des produits des poids de transition le long de tous les chemins sur lesquels la concaténation des caractères d'entrée forme la chaîne , et la concaténation des caractères de sortie forme la chaîne, et qui transfèrent le convertisseur de l'état initial à l'un des terminaux.L'opération de composition est déterminée sur WFST, sur lequel la méthode de post-traitement est basée. Que deux transformateurs soient donnés
est la somme des produits des poids de transition le long de tous les chemins sur lesquels la concaténation des caractères d'entrée forme la chaîne , et la concaténation des caractères de sortie forme la chaîne, et qui transfèrent le convertisseur de l'état initial à l'un des terminaux.L'opération de composition est déterminée sur WFST, sur lequel la méthode de post-traitement est basée. Que deux transformateurs soient donnés  et
et  , et convertir la ligne ci - dessus
, et convertir la ligne ci - dessus  à la ligne ci - dessus
à la ligne ci - dessus  avec le poids
avec le poids  et la conversion sur la ligne
et la conversion sur la ligne  ci - dessus
ci - dessus  avec le poids
avec le poids  . Ensuite, le convertisseur
. Ensuite, le convertisseur  , appelé la composition des convertisseurs, convertit la chaîne en une chaîne avec un poids
, appelé la composition des convertisseurs, convertit la chaîne en une chaîne avec un poids . La composition des transducteurs est une opération coûteuse en calcul, mais elle peut être calculée paresseusement - les états et les transitions du transducteur résultant peuvent être construits au moment où ils doivent être consultés.L'algorithme de post-traitement du résultat de reconnaissance basé sur WFST est basé sur trois sources principales d'information - le
. La composition des transducteurs est une opération coûteuse en calcul, mais elle peut être calculée paresseusement - les états et les transitions du transducteur résultant peuvent être construits au moment où ils doivent être consultés.L'algorithme de post-traitement du résultat de reconnaissance basé sur WFST est basé sur trois sources principales d'information - le  modèle d' hypothèse , le modèle d'erreur
modèle d' hypothèse , le modèle d'erreur  et le modèle de langage
et le modèle de langage  . Les trois modèles sont présentés sous forme de transducteurs finaux pondérés:
. Les trois modèles sont présentés sous forme de transducteurs finaux pondérés:- ( WFST – , ), , . ,
 , ():
, ():  ,
,  –
–  - ,
- ,  – () .
– () .  - , :
- , :  - ,
- ,  - – ,
- – ,  -
-  -
-  . - , . , .
. - , . , .
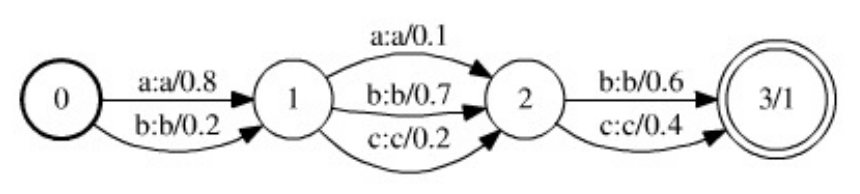
. 1. , WFST ( ). .
- , , . WFST ( ). . , .
- . .. , ( ).
Après avoir défini un modèle d'hypothèses, d'erreurs et un modèle de langage, la tâche de post-traitement des résultats de reconnaissance peut désormais se poser comme suit: considérer la composition des trois modèles  (en termes de composition WFST). Le convertisseur
(en termes de composition WFST). Le convertisseur  code toutes les conversions possibles de chaînes du modèle d'hypothèse en chaînes du modèle de langage , en appliquant aux chaînes des transformations codées dans le modèle d'erreur . De plus, le poids d'une telle transformation comprend le poids de l'hypothèse d'origine, le poids de la transformation et le poids de la chaîne résultante (dans le cas d'un modèle de langage pondéré). En conséquence, dans un tel modèle, le post-traitement optimal du résultat de reconnaissance correspondra au chemin optimal (en termes de poids) dans le convertisseurle traduire de l'initiale à l'un des états terminaux. La ligne d'entrée le long de ce chemin correspondra à l'hypothèse initiale sélectionnée et la ligne de sortie au résultat de reconnaissance corrigé. Le chemin optimal peut être recherché en utilisant des algorithmes pour trouver les chemins les plus courts dans les graphiques dirigés.Les avantages de cette approche sont sa généralité et sa flexibilité. Le modèle d'erreur, par exemple, peut être facilement développé de manière à prendre en compte la suppression et l'ajout de caractères (pour cela, il ne vaut que l'ajout de transitions avec un symbole de sortie ou d'entrée vide, respectivement, au modèle d'erreur). Cependant, ce modèle présente des inconvénients importants. Premièrement, le modèle de langage ici devrait être présenté comme un transformateur fini à pondération finie. Pour les langages complexes, un tel automate peut s'avérer assez lourd, et en cas de changement ou d'affinement du modèle de langage, il faudra le reconstruire. Il convient également de noter que la composition des trois transducteurs a en conséquence, en règle générale, un transducteur encore plus encombrant,et cette composition est calculée chaque fois que vous commencez à post-traiter un résultat de reconnaissance. En raison de l'encombrement de la composition, la recherche du chemin optimal dans la pratique doit être effectuée avec des méthodes heuristiques, telles que la recherche A *.En utilisant le modèle de vérification des grammaires, il est possible de construire un modèle plus simple de la tâche de post-traitement des résultats de reconnaissance, qui ne sera pas aussi général que le modèle basé sur WFST, mais facilement extensible et facile à implémenter.Une grammaire de vérification est une paire
code toutes les conversions possibles de chaînes du modèle d'hypothèse en chaînes du modèle de langage , en appliquant aux chaînes des transformations codées dans le modèle d'erreur . De plus, le poids d'une telle transformation comprend le poids de l'hypothèse d'origine, le poids de la transformation et le poids de la chaîne résultante (dans le cas d'un modèle de langage pondéré). En conséquence, dans un tel modèle, le post-traitement optimal du résultat de reconnaissance correspondra au chemin optimal (en termes de poids) dans le convertisseurle traduire de l'initiale à l'un des états terminaux. La ligne d'entrée le long de ce chemin correspondra à l'hypothèse initiale sélectionnée et la ligne de sortie au résultat de reconnaissance corrigé. Le chemin optimal peut être recherché en utilisant des algorithmes pour trouver les chemins les plus courts dans les graphiques dirigés.Les avantages de cette approche sont sa généralité et sa flexibilité. Le modèle d'erreur, par exemple, peut être facilement développé de manière à prendre en compte la suppression et l'ajout de caractères (pour cela, il ne vaut que l'ajout de transitions avec un symbole de sortie ou d'entrée vide, respectivement, au modèle d'erreur). Cependant, ce modèle présente des inconvénients importants. Premièrement, le modèle de langage ici devrait être présenté comme un transformateur fini à pondération finie. Pour les langages complexes, un tel automate peut s'avérer assez lourd, et en cas de changement ou d'affinement du modèle de langage, il faudra le reconstruire. Il convient également de noter que la composition des trois transducteurs a en conséquence, en règle générale, un transducteur encore plus encombrant,et cette composition est calculée chaque fois que vous commencez à post-traiter un résultat de reconnaissance. En raison de l'encombrement de la composition, la recherche du chemin optimal dans la pratique doit être effectuée avec des méthodes heuristiques, telles que la recherche A *.En utilisant le modèle de vérification des grammaires, il est possible de construire un modèle plus simple de la tâche de post-traitement des résultats de reconnaissance, qui ne sera pas aussi général que le modèle basé sur WFST, mais facilement extensible et facile à implémenter.Une grammaire de vérification est une paire  , où est l'alphabet, et
, où est l'alphabet, et  est le prédicat de l'admissibilité d'une chaîne sur l'alphabet , c'est-à-dire
est le prédicat de l'admissibilité d'une chaîne sur l'alphabet , c'est-à-dire  . Une grammaire de vérification code une certaine langue sur l'alphabet comme suit: une ligne
. Une grammaire de vérification code une certaine langue sur l'alphabet comme suit: une ligne  appartient à la langue si le prédicat prend une valeur vraie sur cette ligne. Il convient de noter que la vérification de la grammaire est un moyen plus général de représenter un modèle de langage qu'une machine à états. En effet, tout langage représenté comme une machine à états finis, peut être représenté sous la forme d'une grammaire de vérification (avec un prédicat
appartient à la langue si le prédicat prend une valeur vraie sur cette ligne. Il convient de noter que la vérification de la grammaire est un moyen plus général de représenter un modèle de langage qu'une machine à états. En effet, tout langage représenté comme une machine à états finis, peut être représenté sous la forme d'une grammaire de vérification (avec un prédicat  , où
, où  est l'ensemble des lignes acceptées par l'automate . Cependant, toutes les langues qui peuvent être représentées comme une grammaire de vérification ne sont pas représentables comme un automate fini dans le cas général (par exemple, une langue de mots de longueur illimitée sur alphabet
est l'ensemble des lignes acceptées par l'automate . Cependant, toutes les langues qui peuvent être représentées comme une grammaire de vérification ne sont pas représentables comme un automate fini dans le cas général (par exemple, une langue de mots de longueur illimitée sur alphabet  , dans lequel le nombre de caractères est
, dans lequel le nombre de caractères est  supérieur au nombre de caractères
supérieur au nombre de caractères  .)Soit le résultat de la reconnaissance (modèle d'hypothèse) donné comme une séquence de cellules(comme dans la section précédente). Par commodité, nous supposons que chaque cellule contient K alternatives et toutes les estimations alternatives prennent une valeur positive. L'évaluation (poids) de la chaîne sera considérée comme le produit des évaluations de chacun des caractères de cette chaîne. Si le modèle de langage est donné sous la forme d'une grammaire de vérification , le problème de post-traitement peut être formulé comme un problème d'optimisation discrète (maximisation) sur l'ensemble des contrôles
.)Soit le résultat de la reconnaissance (modèle d'hypothèse) donné comme une séquence de cellules(comme dans la section précédente). Par commodité, nous supposons que chaque cellule contient K alternatives et toutes les estimations alternatives prennent une valeur positive. L'évaluation (poids) de la chaîne sera considérée comme le produit des évaluations de chacun des caractères de cette chaîne. Si le modèle de langage est donné sous la forme d'une grammaire de vérification , le problème de post-traitement peut être formulé comme un problème d'optimisation discrète (maximisation) sur l'ensemble des contrôles  (l'ensemble de toutes les lignes de longueur sur l'alphabet ) avec le prédicat d'admissibilité et fonctionnel
(l'ensemble de toutes les lignes de longueur sur l'alphabet ) avec le prédicat d'admissibilité et fonctionnel  , où
, où  est l'estimation du symbole
est l'estimation du symbole  dans la ième cellule .Tout problème d'optimisation discret (c'est-à-dire avec un ensemble fini de contrôles) peut être résolu en utilisant une énumération complète des contrôles. L'algorithme décrit parcourt efficacement les contrôles (lignes) dans l'ordre décroissant de la valeur fonctionnelle jusqu'à ce que le prédicat de validité accepte la vraie valeur. Nous définissons comme le
dans la ième cellule .Tout problème d'optimisation discret (c'est-à-dire avec un ensemble fini de contrôles) peut être résolu en utilisant une énumération complète des contrôles. L'algorithme décrit parcourt efficacement les contrôles (lignes) dans l'ordre décroissant de la valeur fonctionnelle jusqu'à ce que le prédicat de validité accepte la vraie valeur. Nous définissons comme le  nombre maximal d'itérations de l'algorithme, c'est-à-dire le nombre maximal de lignes avec l'estimation maximale sur laquelle le prédicat sera calculé.Premièrement, nous trions les alternatives par ordre décroissant d'estimations, et nous supposons en outre que pour n'importe quelle cellule, l' inégalité
nombre maximal d'itérations de l'algorithme, c'est-à-dire le nombre maximal de lignes avec l'estimation maximale sur laquelle le prédicat sera calculé.Premièrement, nous trions les alternatives par ordre décroissant d'estimations, et nous supposons en outre que pour n'importe quelle cellule, l' inégalité  pour est vraie
pour est vraie  . La position sera la séquence d'indices
. La position sera la séquence d'indices  correspondant à la ligne
correspondant à la ligne . Évaluation de la position, c.-à-d. valeur fonctionnelle dans cette position, tenez compte des évaluations des alternatives de produits correspondant aux indices inclus dans la position:
. Évaluation de la position, c.-à-d. valeur fonctionnelle dans cette position, tenez compte des évaluations des alternatives de produits correspondant aux indices inclus dans la position:  . Pour stocker des positions, vous avez besoin de la structure de données PositionBase , qui vous permet d'ajouter de nouvelles positions (avec l'obtention de leurs adresses), d'obtenir la position à l'adresse et de vérifier si la position spécifiée est ajoutée à la base de données.Dans le processus de listage des positions, nous sélectionnerons une position non visualisée avec une note maximale, puis ajouterons à la file d'attente pour examen PositionQueue toutes les positions qui peuvent être obtenues à partir de la position actuelle en ajoutant un à l'un des indices inclus dans la position. La file d'attente à considérer PositionQueue contiendra des triplets
. Pour stocker des positions, vous avez besoin de la structure de données PositionBase , qui vous permet d'ajouter de nouvelles positions (avec l'obtention de leurs adresses), d'obtenir la position à l'adresse et de vérifier si la position spécifiée est ajoutée à la base de données.Dans le processus de listage des positions, nous sélectionnerons une position non visualisée avec une note maximale, puis ajouterons à la file d'attente pour examen PositionQueue toutes les positions qui peuvent être obtenues à partir de la position actuelle en ajoutant un à l'un des indices inclus dans la position. La file d'attente à considérer PositionQueue contiendra des triplets  , où
, où - évaluation de la position non
- évaluation de la position non  revue , - adresse de la position visualisée dans PositionBase à partir de laquelle cette position a été obtenue,
revue , - adresse de la position visualisée dans PositionBase à partir de laquelle cette position a été obtenue,  - index de l'élément de position avec l'adresse augmentée d'une unité pour obtenir cette position. Le positionnement d'une file d'attente PositionQueue nécessitera une structure de données qui vous permettra d'ajouter un autre triple , ainsi que de récupérer un triple avec une note maximale .Lors de la première itération de l'algorithme, il est nécessaire de considérer la position
- index de l'élément de position avec l'adresse augmentée d'une unité pour obtenir cette position. Le positionnement d'une file d'attente PositionQueue nécessitera une structure de données qui vous permettra d'ajouter un autre triple , ainsi que de récupérer un triple avec une note maximale .Lors de la première itération de l'algorithme, il est nécessaire de considérer la position  avec l'estimation maximale. Si le prédicat prend la vraie valeur sur la ligne correspondant à cette position, alors l'algorithme se termine. Sinon, la position est ajoutée à PositionBase et dansPositionQueue ajoute tous les triplets de la vue
avec l'estimation maximale. Si le prédicat prend la vraie valeur sur la ligne correspondant à cette position, alors l'algorithme se termine. Sinon, la position est ajoutée à PositionBase et dansPositionQueue ajoute tous les triplets de la vue  , pour tous
, pour tous  , où
, où  est l'adresse de la position de départ dans PositionBase . A chaque itération ultérieure de l'algorithme, le triple avec la valeur maximale de l'estimation est extrait de la PositionQueue , la position en question est restituée à l'adresse de la position et de l'indice initiaux . Si la position a déjà été ajoutée à la base de données des positions PositionBase considérées , elle est ignorée et les trois suivantes avec la valeur maximale de l'estimation sont extraites de la PositionQueue . Sinon, la valeur du prédicat est vérifiée sur la ligne correspondant à la position . Si le prédicatprend la vraie valeur sur cette ligne, puis l'algorithme se termine. Si le prédicat n'accepte pas la vraie valeur sur cette ligne, la ligne est ajoutée à PositionBase (avec l'adresse affectée
est l'adresse de la position de départ dans PositionBase . A chaque itération ultérieure de l'algorithme, le triple avec la valeur maximale de l'estimation est extrait de la PositionQueue , la position en question est restituée à l'adresse de la position et de l'indice initiaux . Si la position a déjà été ajoutée à la base de données des positions PositionBase considérées , elle est ignorée et les trois suivantes avec la valeur maximale de l'estimation sont extraites de la PositionQueue . Sinon, la valeur du prédicat est vérifiée sur la ligne correspondant à la position . Si le prédicatprend la vraie valeur sur cette ligne, puis l'algorithme se termine. Si le prédicat n'accepte pas la vraie valeur sur cette ligne, la ligne est ajoutée à PositionBase (avec l'adresse affectée  ), toutes les positions dérivées sont ajoutées à la file d'attente PositionQueue et l'itération suivante se poursuit.
), toutes les positions dérivées sont ajoutées à la file d'attente PositionQueue et l'itération suivante se poursuit.FindSuitableString(M, N, K, P, C[1], ..., C[N]):
i : 1 ... N:
C[i]
( )
PositionBase PositionQueue
S_1 = {1, 1, 1, ..., 1}
P(S_1):
: S_1,
( )
S_1 PositionBase R(S_1)
i : 1 ... N:
K > 1, :
<Q * q[i][2] / q[i][1], R(S_1), i> PositionQueue
( )
( )
PositionBase M:
PositionQueue:
PositionQueue <Q, R, I> Q
S_from = PositionBase R
S_curr = {S_from[1], S_from[2], ..., S_from[I] + 1, ..., S_from[N]}
S_curr PositionBase:
:
S_curr PositionBase R(S_curr)
( )
P(S_curr):
: S_curr,
( )
i : 1 ... N:
K > S_curr[i]:
<Q * q[i][S_curr[i] + 1] / q[i][S_curr[i]],
R(S_curr),
i> PositionQueue
( )
( )
( )
( )
M
Notez que pendant les itérations, le prédicat ne sera vérifié qu'une seule fois, il n'y aura plus d' ajouts à la PositionBase , et en plus de la PositionQueue , l'extraction de la PositionQueue , ainsi qu'une recherche dans la PositionBase ne se produira pas plus d'  une fois. Si l'implémentation PositionQueue a utilisé un "bouquet" de structure de données, et pour l'organisation PositionBase en utilisant la structure de données "Bor", la complexité de l'algorithme est
une fois. Si l'implémentation PositionQueue a utilisé un "bouquet" de structure de données, et pour l'organisation PositionBase en utilisant la structure de données "Bor", la complexité de l'algorithme est  , où
, où  - trudoemost test prédicat sur la longueur de la ligne .L'inconvénient le plus important de l'algorithme basé sur la vérification des grammaires est peut-être qu'il ne peut pas traiter des hypothèses de longueurs différentes (qui peuvent survenir en raison d'erreurs de segmentation : perte ou occurrence de caractères supplémentaires, collage et découpe de caractères, etc.), tandis que les modifications d'hypothèses telles que «supprimer un caractère», «ajouter un caractère» ou même «remplacer un caractère par une paire» peuvent être encodées dans le modèle d'erreur de l'algorithme basé sur WFST.Cependant, la rapidité et la facilité d'utilisation (lorsque vous travaillez avec un nouveau type de champ, vous avez juste besoin de donner à l'algorithme accès à la fonction de validation de valeur) font de la méthode basée sur la vérification des grammaires un outil très puissant dans l'arsenal du développeur de systèmes de reconnaissance de documents. Nous utilisons cette approche pour un grand nombre de champs différents, tels que diverses dates, le numéro de carte bancaire (prédicat - vérification du code Moon ), les champs de zones de documents lisibles par machine avec des sommes de contrôle, et bien d'autres.
- trudoemost test prédicat sur la longueur de la ligne .L'inconvénient le plus important de l'algorithme basé sur la vérification des grammaires est peut-être qu'il ne peut pas traiter des hypothèses de longueurs différentes (qui peuvent survenir en raison d'erreurs de segmentation : perte ou occurrence de caractères supplémentaires, collage et découpe de caractères, etc.), tandis que les modifications d'hypothèses telles que «supprimer un caractère», «ajouter un caractère» ou même «remplacer un caractère par une paire» peuvent être encodées dans le modèle d'erreur de l'algorithme basé sur WFST.Cependant, la rapidité et la facilité d'utilisation (lorsque vous travaillez avec un nouveau type de champ, vous avez juste besoin de donner à l'algorithme accès à la fonction de validation de valeur) font de la méthode basée sur la vérification des grammaires un outil très puissant dans l'arsenal du développeur de systèmes de reconnaissance de documents. Nous utilisons cette approche pour un grand nombre de champs différents, tels que diverses dates, le numéro de carte bancaire (prédicat - vérification du code Moon ), les champs de zones de documents lisibles par machine avec des sommes de contrôle, et bien d'autres.
La publication a été préparée sur la base de l' article : Un algorithme universel pour les résultats de reconnaissance de post-traitement basé sur la validation des grammaires. K.B. Bulatov, D.P. Nikolaev, V.V. Postnikov. Actes de ISA RAS, vol. 65, n ° 4, 2015, pp. 68-73.