
Les progrès de l'apprentissage automatique pour le traitement du langage naturel se sont considérablement accélérés au cours des dernières années. Les modèles ont quitté les laboratoires de recherche et sont devenus le fondement des principaux produits numériques. Une bonne illustration de cela est l' annonce récente que le modèle BERT est devenu le principal composant derrière la recherche de Google . Google estime que cette étape (c'est-à-dire l'introduction d'un modèle avancé de compréhension du langage naturel dans le moteur de recherche) représente "la plus grande percée des cinq dernières années et l'une des plus importantes de l'histoire des moteurs de recherche".
– BERT' . , , , , .
, Colab.
: SST2
SST2, , ( 1), ( 0):

:
– , ( , ) 1 ( ), 0 ( ). :

:
, , 768. , .
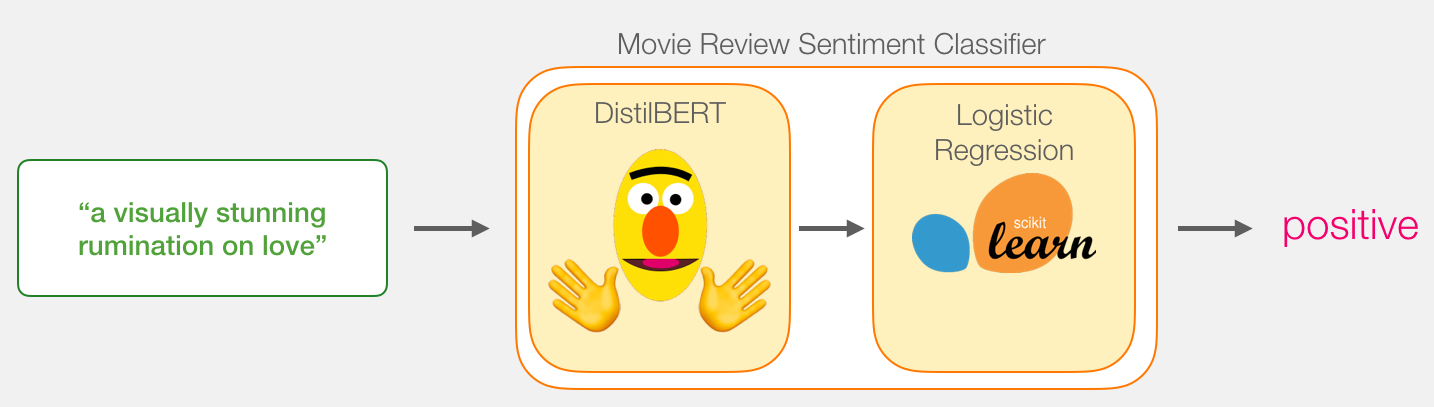
, BERT, ELMO ( NLP ): ( [CLS]).
, , . DistilBERT', . , , «» BERT', . , , BERT , [CLS] . , , . , , BERT .
transformers DistilBERT', .
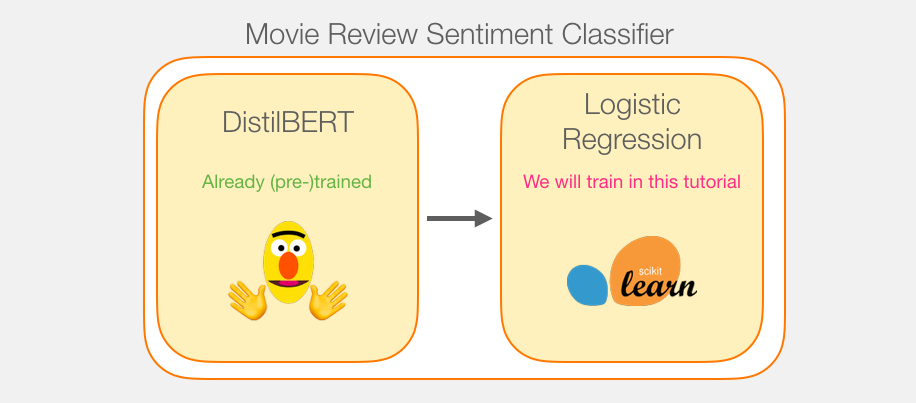
, . DistilBERT' 2 .

DistilBERT'. Scikit Learn. , , :
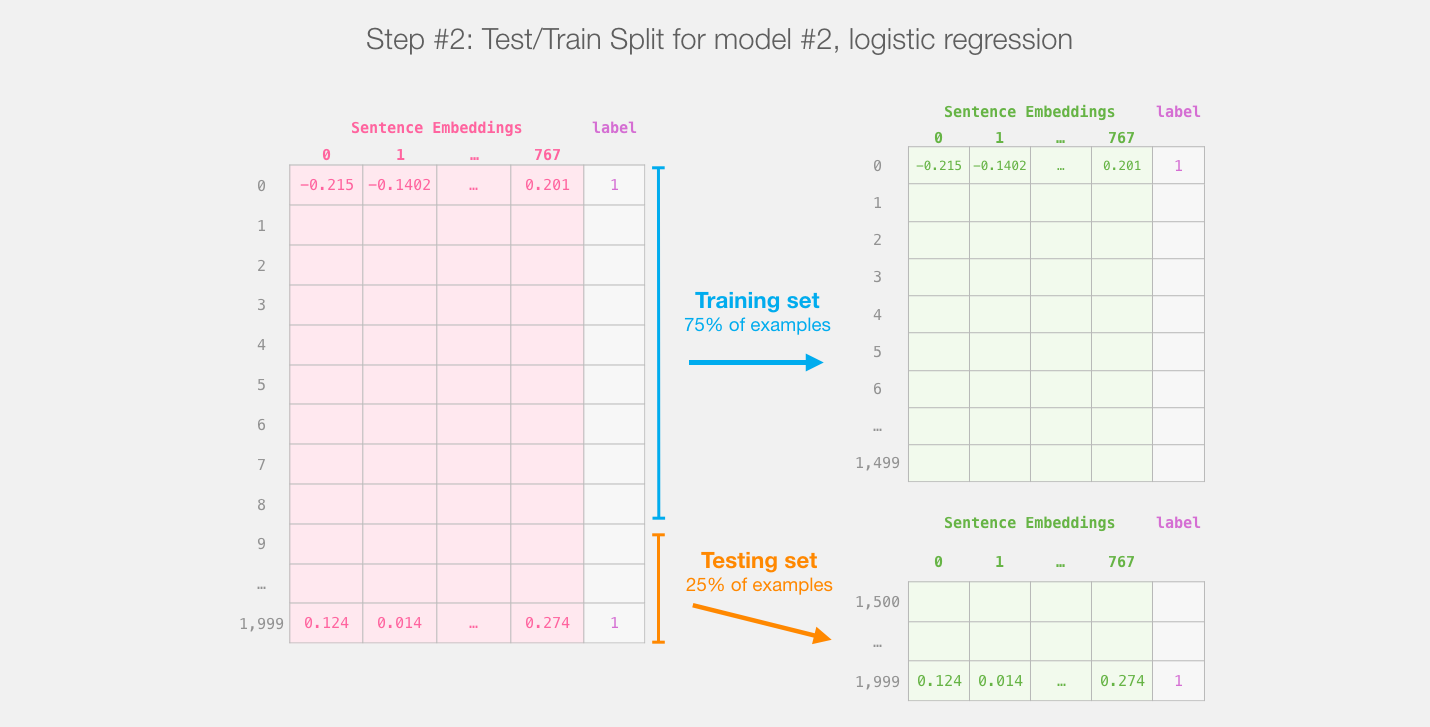
distilBERT' ( #1) , ( #2). , sklearn , , 75% ,
:

, , , .
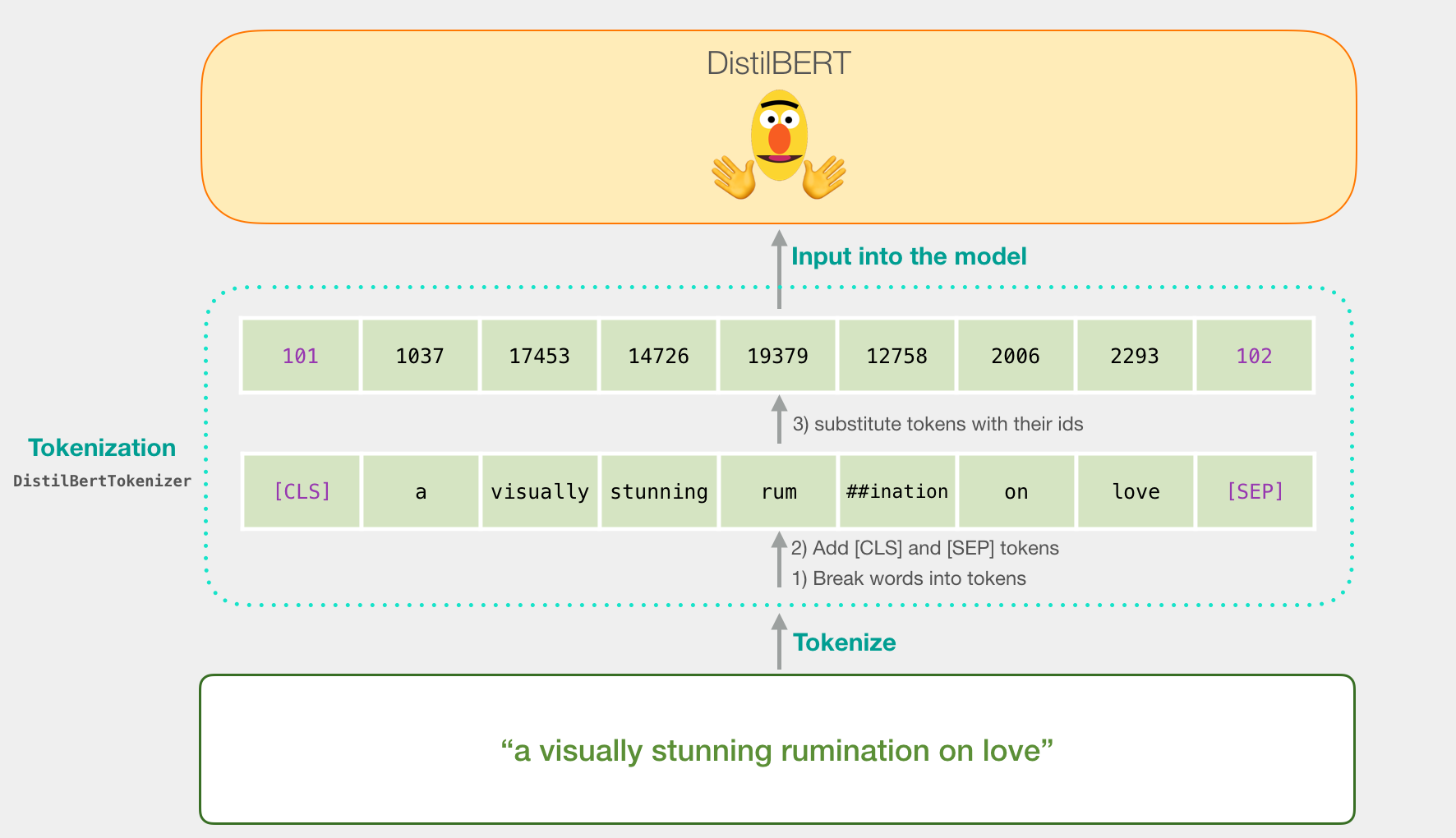
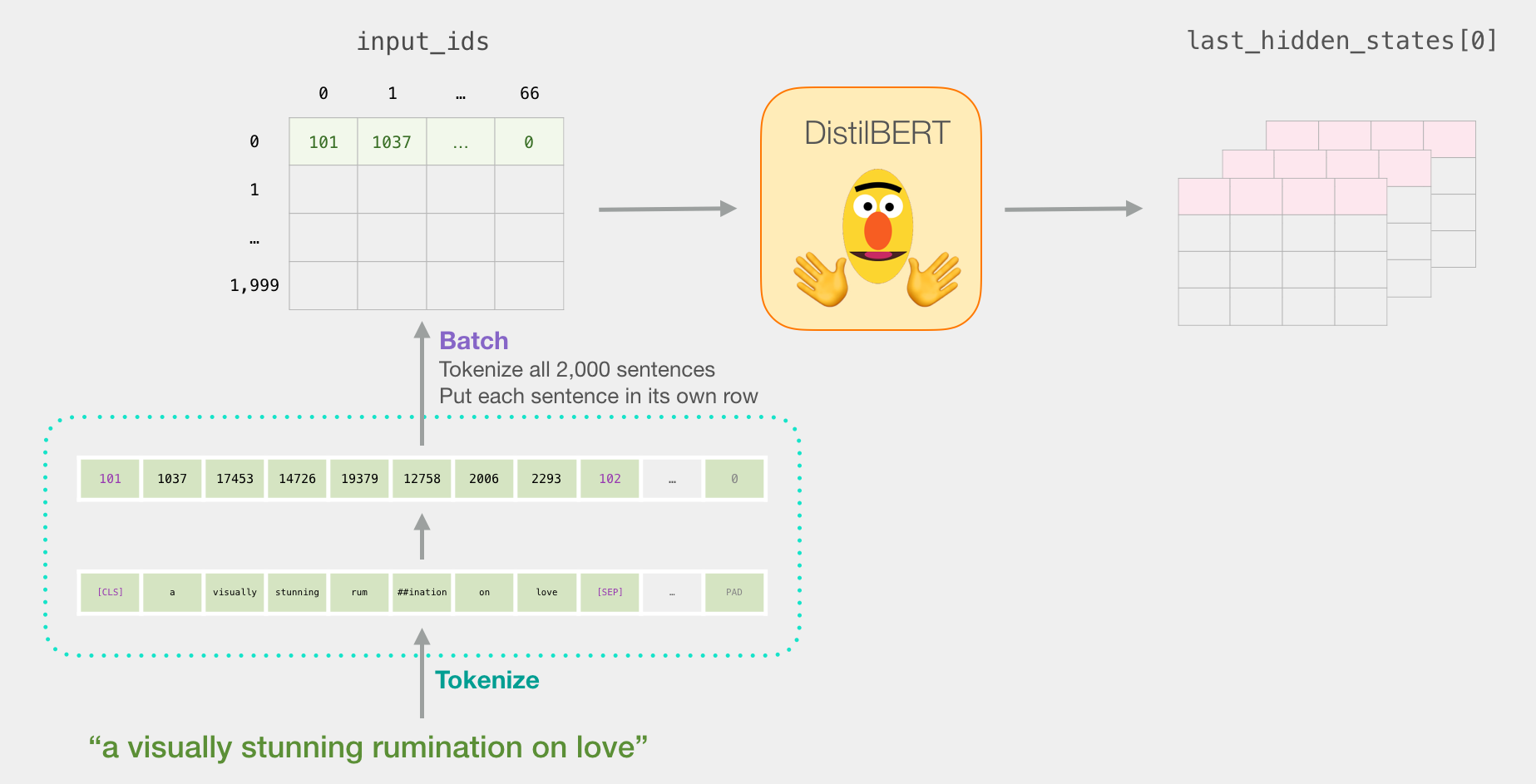
«a visually stunning rumination on love». BERT' , . , ( [CLS] [SEP] ).

, . Word2vec .

:
tokenizer.encode("a visually stunning rumination on love", add_special_tokens=True)
DistilBERT'.
BERT, ELMO ( NLP ), :
DistilBERT
DistilBERT' , BERT'. , 768 .
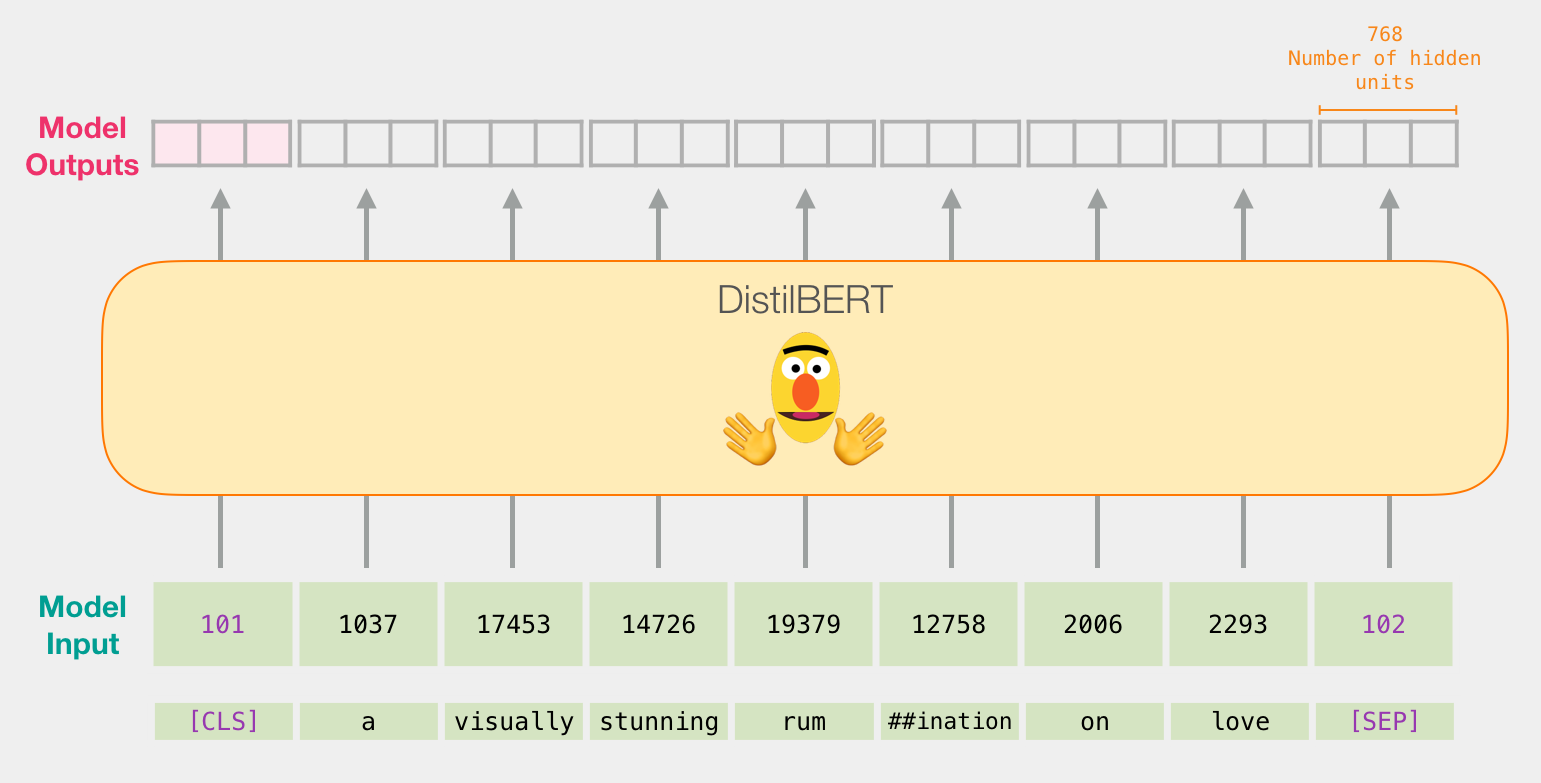
, , ( [CLS] ). .
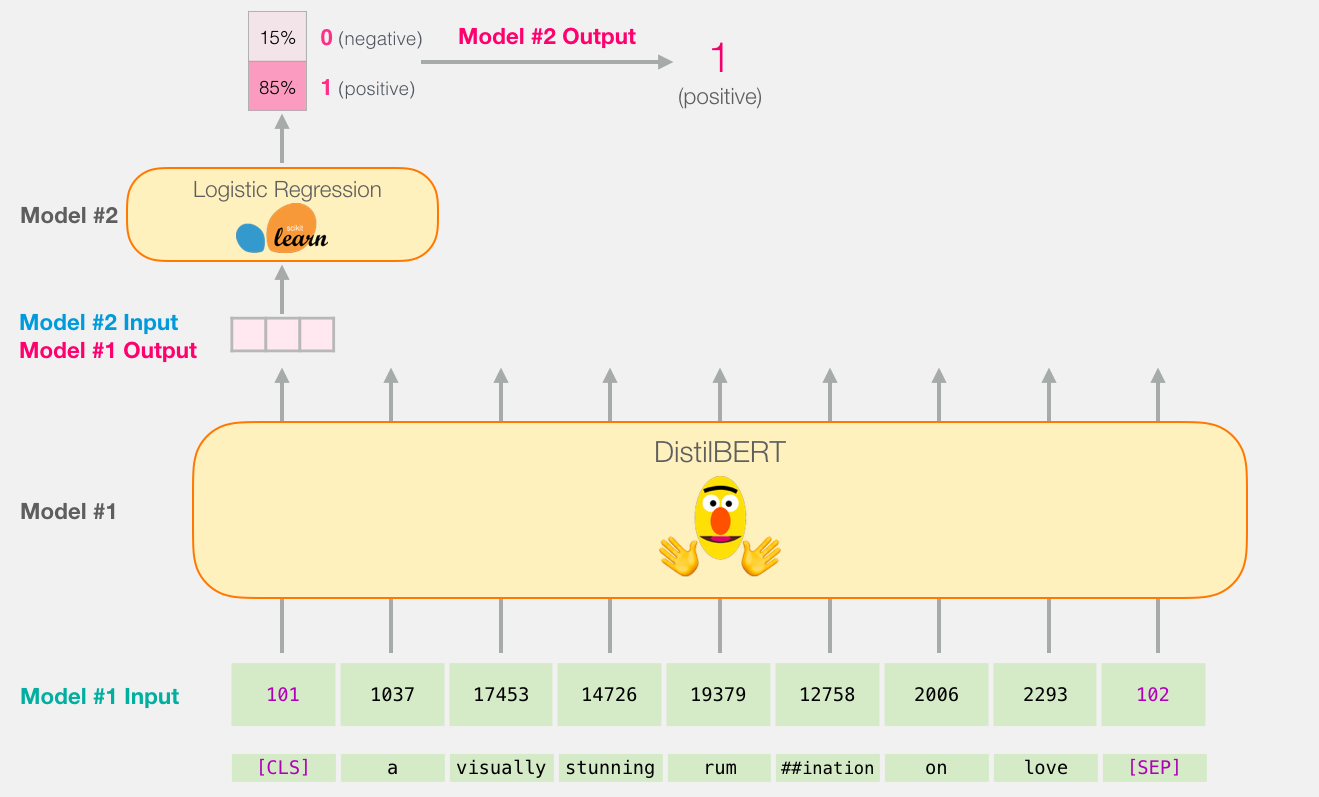
, , . :
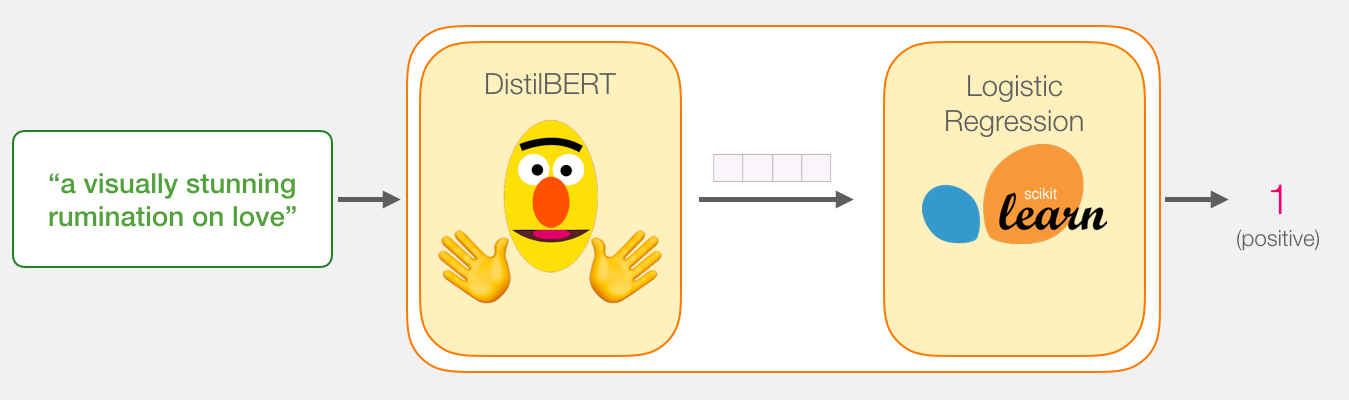
, .
. Colab github.
:
import numpy as np
import pandas as pd
import torch
import transformers as ppb
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import train_test_split
github, pandas:
df = pd.read_csv('https://github.com/clairett/pytorch-sentiment-classification/raw/master/data/SST2/train.tsv', delimiter='\t', header=None)
df.head() , 5 , :
df.head()

DistilBERT
model_class, tokenizer_class, pretrained_weights = (ppb.DistilBertModel, ppb.DistilBertTokenizer, 'distilbert-base-uncased')
tokenizer = tokenizer_class.from_pretrained(pretrained_weights)
model = model_class.from_pretrained(pretrained_weights)
. , , . . ( , 2000).
tokenized = df[0].apply((lambda x: tokenizer.encode(x, add_special_tokens=True)))
.

( Series/DataFrame pandas) . DistilBERT , 0 (padding). , ( , Python).
, /, BERT':

DistilBERT'
DistilBERT.
input_ids = torch.tensor(np.array(padded))
with torch.no_grad():
last_hidden_states = model(input_ids)
last_hidden_states DistilBERT', ( , , DistilBERT). , 2000 (.. 2000 ), 66 ( 2000 ), 278 ( DistilBERT).

BERT'
3-d . :
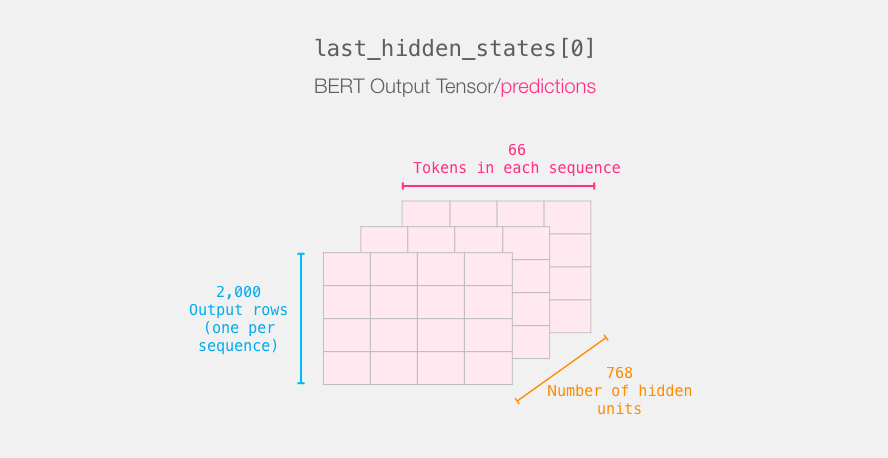
. :
BERT' [CLS]. .

, 3d , 2d :
features = last_hidden_states[0][:,0,:].numpy()
features 2d numpy, .

, BERT'
, BERT', , . 768 , .

, . BERT' [CLS] ( #0), (. ). , – , BERT/DistilBERT
, , .
labels = df[1]
train_features, test_features, train_labels, test_labels = train_test_split(features, labels)
:
.
lr_clf = LogisticRegression()
lr_clf.fit(train_features, train_labels)
, .
lr_clf.score(test_features, test_labels)
, (accuracy) – 81%.
: – 96.8. DistilBERT , – , . BERT , ( downstream task). DistilBERT' 90.7. BERT' 94.9.
Colab.
C'est tout! Une bonne première connaissance s'est produite. L'étape suivante consiste à consulter la documentation et à essayer de peaufiner vos propres mains. Vous pouvez également revenir un peu en arrière et passer de distilBERT à BERT et voir comment cela fonctionne.
Merci à Clément Delangue , Victor Sanh , et à l'équipe Huggingface qui ont fourni des commentaires sur les versions antérieures de ce guide.
Auteurs