Prélude
Il s'agit du deuxième des quatre articles d'une série qui donnera un aperçu de la mécanique et de la conception des pointeurs, des piles, des tas, de l'analyse d'échappement et de la sémantique Go / Value. Ce post est sur les tas et l'analyse des échappées.Table des matières:- Mécanique du langage sur piles et pointeurs ( traduction )
- Mécanique du langage sur l'analyse d'échappement
- Mécanique du langage sur le profilage de la mémoire
- Philosophie de conception sur les données et la sémantique
introduction
Dans le premier article de cette série, j'ai parlé des bases de la mécanique des pointeurs en utilisant un exemple dans lequel la valeur est répartie sur la pile entre les goroutines. Je ne vous ai pas montré ce qui se passe lorsque vous divisez la valeur sur la pile. Pour comprendre cela, vous devez vous renseigner sur un autre domaine de la mémoire où les valeurs peuvent être: sur le «tas». Avec cette connaissance, vous pouvez commencer à étudier "l'analyse d'échappement".L'analyse d'échappement est un processus que le compilateur utilise pour déterminer le placement des valeurs créées par votre programme. En particulier, le compilateur effectue une analyse de code statique pour déterminer si la valeur peut être placée sur le cadre de pile pour la fonction qui la construit, ou si la valeur doit être "échappée" dans le tas. Il n'y a pas un seul mot-clé ou fonction dans Go que vous pouvez utiliser pour indiquer au compilateur la décision à prendre. Seule la façon dont vous écrivez votre code conditionnellement vous permet d'influencer cette décision.Des tas
Un tas est une deuxième zone de mémoire, en plus de la pile, utilisée pour stocker des valeurs. Le tas n'est pas autonettoyant comme les piles, donc l'utilisation de cette mémoire est plus coûteuse. Tout d'abord, les coûts sont associés au ramasse-miettes (GC), qui doit garder cette zone propre. Lorsque le GC démarre, il utilise 25% de la puissance disponible de votre processeur. De plus, il peut potentiellement créer des microsecondes de retards «stop the world». L'avantage d'avoir un GC est que vous n'avez pas à vous soucier de la gestion de la mémoire de tas qui a toujours été complexe et sujette aux erreurs.Les valeurs du tas provoquent des allocations de mémoire dans Go. Ces allocations exercent une pression sur le GC, car chaque valeur du tas à laquelle le pointeur ne fait plus référence doit être supprimée. Plus vous devez vérifier et supprimer de valeurs, plus le GC doit faire de travail à chaque démarrage. Par conséquent, l'algorithme de stimulation travaille constamment pour équilibrer la taille du tas et la vitesse d'exécution.Partage de pile
Dans Go, aucun goroutine n'est autorisé à avoir un pointeur pointant vers une mémoire sur la pile d'un autre goroutine. Cela est dû au fait que la mémoire de la pile pour les goroutines peut être remplacée par un nouveau bloc de mémoire lorsque la pile doit augmenter ou diminuer. Si au moment de l'exécution, vous deviez suivre les pointeurs vers la pile dans un autre goroutine, vous auriez à gérer trop, et le retard de "stop the world" lors de la mise à jour des pointeurs vers ces piles serait stupéfiant.Voici un exemple d'une pile qui est remplacée plusieurs fois en raison de la croissance. Regardez la sortie dans les lignes 2 et 6. Vous verrez deux fois les changements d'adresse de la valeur de chaîne à l'intérieur du cadre de pile principal.play.golang.org/p/pxn5u4EBSIMécanique d'échappement
Chaque fois qu'une valeur est partagée en dehors de la région du cadre de pile d'une fonction, elle est placée (ou allouée) dans un segment de mémoire. La tâche des algorithmes d'analyse d'échappement est de trouver de telles situations et de maintenir le niveau d'intégrité dans le programme. L'intégrité consiste à garantir que l'accès à toute valeur est toujours précis, cohérent et efficace.Jetez un œil à cet exemple pour apprendre les mécanismes de base de l'analyse d'échappement.play.golang.org/p/Y_VZxYteKOListing 101 package main
02
03 type user struct {
04 name string
05 email string
06 }
07
08 func main() {
09 u1 := createUserV1()
10 u2 := createUserV2()
11
12 println("u1", &u1, "u2", &u2)
13 }
14
15
16 func createUserV1() user {
17 u := user{
18 name: "Bill",
19 email: "bill@ardanlabs.com",
20 }
21
22 println("V1", &u)
23 return u
24 }
25
26
27 func createUserV2() *user {
28 u := user{
29 name: "Bill",
30 email: "bill@ardanlabs.com",
31 }
32
33 println("V2", &u)
34 return &u
35 }
J'utilise la directive go: noinline pour que le compilateur n'incorpore pas de code pour ces fonctions directement dans main. L'incorporation supprimera les appels de fonction et compliquera cet exemple. Je parlerai des effets secondaires de l'intégration dans le prochain post.Le listing 1 montre un programme avec deux fonctions différentes qui créent une valeur de type user et la renvoient à l'appelant. La première version de la fonction utilise la sémantique de la valeur lors du retour.Listing 216 func createUserV1() user {
17 u := user{
18 name: "Bill",
19 email: "bill@ardanlabs.com",
20 }
21
22 println("V1", &u)
23 return u
24 }
J'ai dit que la fonction utilise la sémantique des valeurs lors du retour, car une valeur de type user créée par cette fonction est copiée et transmise à la pile des appels. Cela signifie que la fonction appelante reçoit une copie de la valeur elle-même.Vous pouvez voir la création d'une valeur de type utilisateur, exécutée sur les lignes 17 à 20. Ensuite, sur la ligne 23, une copie de la valeur est transmise à la pile des appels et renvoyée à l'appelant. Après avoir renvoyé la fonction, la pile se présente comme suit.Image 1 Dans la figure 1, vous pouvez voir qu'une valeur de type user existe dans les deux trames après avoir appelé createUserV1. Dans la deuxième version de la fonction, la sémantique du pointeur est utilisée pour retourner.Listing 3
Dans la figure 1, vous pouvez voir qu'une valeur de type user existe dans les deux trames après avoir appelé createUserV1. Dans la deuxième version de la fonction, la sémantique du pointeur est utilisée pour retourner.Listing 327 func createUserV2() *user {
28 u := user{
29 name: "Bill",
30 email: "bill@ardanlabs.com",
31 }
32
33 println("V2", &u)
34 return &u
35 }
J'ai dit qu'une fonction utilise la sémantique du pointeur lors du retour, car une valeur de type user créée par cette fonction est partagée par la pile d'appels. Cela signifie que la fonction appelante reçoit une copie de l'adresse où se trouvent les valeurs.Vous pouvez voir le même littéral structurel qui est utilisé dans les lignes 28 à 31 pour créer une valeur de type utilisateur, mais à la ligne 34, le retour de la fonction est différent. Au lieu de transmettre une copie de la valeur à la pile d'appels, une copie de l'adresse de la valeur est transmise. Sur cette base, vous pourriez penser qu'après l'appel, la pile ressemble à ceci.Image 2 Si ce que vous voyez sur la figure 2 se produit réellement, vous aurez un problème d'intégrité. Un pointeur pointe vers une pile d'appels à la mémoire qui n'est plus valide. La prochaine fois que la fonction sera appelée, la mémoire indiquée sera reformatée et réinitialisée.C'est là que l'analyse d'échappement commence à maintenir l'intégrité. Dans ce cas, le compilateur déterminera qu'il n'est pas sûr de créer une valeur de type user dans le cadre de pile createUserV2, donc il créera à la place une valeur sur le tas. Cela se produira immédiatement lors de la construction de la ligne 28.
Si ce que vous voyez sur la figure 2 se produit réellement, vous aurez un problème d'intégrité. Un pointeur pointe vers une pile d'appels à la mémoire qui n'est plus valide. La prochaine fois que la fonction sera appelée, la mémoire indiquée sera reformatée et réinitialisée.C'est là que l'analyse d'échappement commence à maintenir l'intégrité. Dans ce cas, le compilateur déterminera qu'il n'est pas sûr de créer une valeur de type user dans le cadre de pile createUserV2, donc il créera à la place une valeur sur le tas. Cela se produira immédiatement lors de la construction de la ligne 28.Lisibilité
Comme vous l'avez appris dans un article précédent, une fonction a un accès direct à la mémoire à l'intérieur de son cadre via le pointeur de cadre, mais l'accès à la mémoire à l'extérieur du cadre nécessite un accès indirect. Cela signifie que l'accès aux valeurs qui tombent dans le tas doit également se faire indirectement via un pointeur.N'oubliez pas à quoi ressemble le code createUserV2.Listing 427 func createUserV2() *user {
28 u := user{
29 name: "Bill",
30 email: "bill@ardanlabs.com",
31 }
32
33 println("V2", &u)
34 return &u
35 }
La syntaxe masque ce qui se passe réellement dans ce code. La variable u déclarée à la ligne 28 représente une valeur de type utilisateur. La construction dans Go ne vous indique pas exactement où la valeur est stockée en mémoire, donc avant l'instruction de retour à la ligne 34, vous ne savez pas que la valeur sera stockée. Cela signifie que bien que u représente une valeur de type utilisateur, l'accès à cette valeur doit se faire via un pointeur.Vous pouvez visualiser une pile qui ressemble à ceci après un appel de fonction.Image 3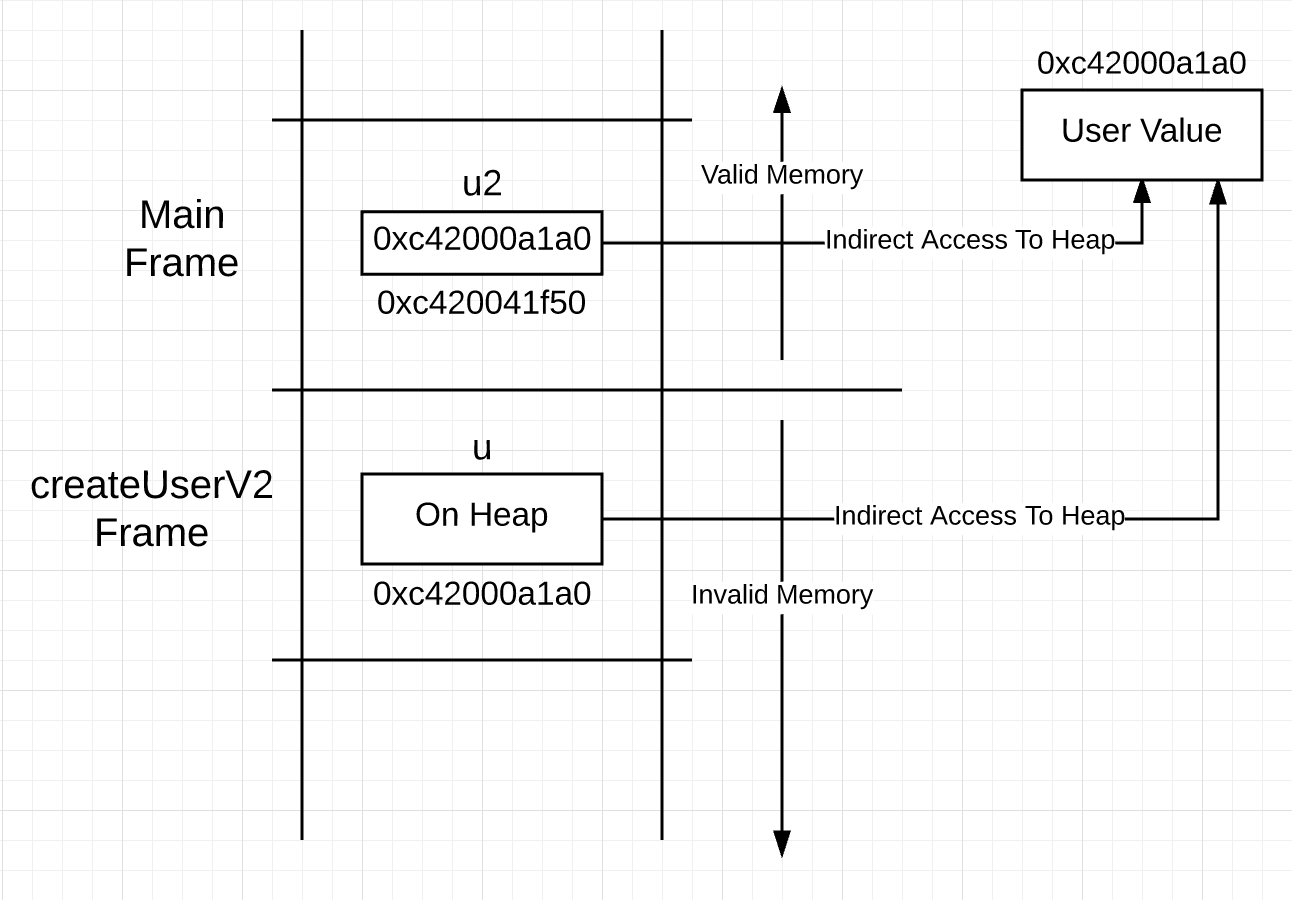 La variable u dans le cadre de pile pour createUserV2 représente la valeur sur le tas, pas sur la pile. Cela signifie que l'utilisation de u pour accéder à une valeur nécessite l'accès à un pointeur, pas l'accès direct suggéré par la syntaxe. Vous pourriez penser, pourquoi ne pas créer immédiatement un pointeur, car l'accès à la valeur qu'il représente nécessite toujours l'utilisation d'un pointeur?Listing 5
La variable u dans le cadre de pile pour createUserV2 représente la valeur sur le tas, pas sur la pile. Cela signifie que l'utilisation de u pour accéder à une valeur nécessite l'accès à un pointeur, pas l'accès direct suggéré par la syntaxe. Vous pourriez penser, pourquoi ne pas créer immédiatement un pointeur, car l'accès à la valeur qu'il représente nécessite toujours l'utilisation d'un pointeur?Listing 527 func createUserV2() *user {
28 u := &user{
29 name: "Bill",
30 email: "bill@ardanlabs.com",
31 }
32
33 println("V2", u)
34 return u
35 }
Si vous le faites, vous perdrez la lisibilité, ce que vous ne pourriez pas perdre dans votre code. Éloignez-vous du corps de fonction pendant une seconde et concentrez-vous uniquement sur le retour.Listing 634 return u
35 }
De quoi parle ce retour? Tout ce qu'il dit, c'est qu'une copie de u est poussée sur la pile des appels. En attendant, que vous indique return lorsque vous utilisez l'opérateur &?Listing 734 return &u
35 }
Grâce à l'opérateur & return, il vous indique maintenant que vous partagez la pile d'appels et par conséquent sortez dans le tas. N'oubliez pas que les pointeurs sont destinés à être utilisés ensemble et lors de la lecture du code, ils remplacent l'opérateur & par la phrase «partage». Il est très puissant en termes de lisibilité. C'est quelque chose que je ne voudrais pas perdre.Voici un autre exemple où la construction de valeurs à l'aide de la sémantique des pointeurs dégrade la lisibilité.Listing 801 var u *user
02 err := json.Unmarshal([]byte(r), &u)
03 return u, err
Pour que ce code fonctionne, lorsque vous appelez json.Unmarshal à la ligne 02, vous devez passer un pointeur vers une variable de pointeur. Un appel json.Unmarshal créera une valeur de type user et assignera son adresse à une variable pointeur. play.golang.org/p/koI8EjpeIxCe que dit ce code:01: Créez un pointeur de type utilisateur avec une valeur nulle.02: Partager la variable u avec la fonction json.Unmarshal.03: Renvoyez une copie de la variable u à l'appelant.Il n'est pas tout à fait évident qu'une valeur de type user créée par la fonction json.Unmarshal est passée à l'appelant.Comment la lisibilité change-t-elle lors de l'utilisation de la sémantique des valeurs lors de la déclaration des variables?Listing 901 var u user
02 err := json.Unmarshal([]byte(r), &u)
03 return &u, err
Ce que dit ce code:01: Créez une valeur de type utilisateur avec une valeur nulle.02: Partager la variable u avec la fonction json.Unmarshal.03: Partagez la variable u avec l'appelant.Tout est très clair. La ligne 02 divise la valeur du type utilisateur dans la pile d'appels dans json.Unmarshal, et la ligne 03 divise la valeur de la pile d'appels vers l'appelant. Ce partage entraînera le déplacement de la valeur vers le segment de mémoire.Utilisez la sémantique des valeurs lors de la création de valeurs et profitez de la lisibilité de l'opérateur & pour clarifier comment les valeurs sont séparées.Rapports du compilateur
Pour voir les décisions prises par le compilateur, vous pouvez demander au compilateur de fournir un rapport. Tout ce que vous avez à faire est d'utiliser le commutateur -gcflags avec l'option -m lors de l'appel à go build.En fait, vous pouvez utiliser 4 niveaux de -m, mais après 2 niveaux d'informations, cela devient trop. J'utiliserai 2 niveaux -m.Listing 10$ go build -gcflags "-m -m"
./main.go:16: cannot inline createUserV1: marked go:noinline
./main.go:27: cannot inline createUserV2: marked go:noinline
./main.go:8: cannot inline main: non-leaf function
./main.go:22: createUserV1 &u does not escape
./main.go:34: &u escapes to heap
./main.go:34: from ~r0 (return) at ./main.go:34
./main.go:31: moved to heap: u
./main.go:33: createUserV2 &u does not escape
./main.go:12: main &u1 does not escape
./main.go:12: main &u2 does not escape
Vous pouvez voir que le compilateur signale les décisions de vider la valeur dans le tas. Que dit le compilateur? Tout d'abord, regardez à nouveau les fonctions createUserV1 et createUserV2 pour les actualiser en mémoire.Listing 1316 func createUserV1() user {
17 u := user{
18 name: "Bill",
19 email: "bill@ardanlabs.com",
20 }
21
22 println("V1", &u)
23 return u
24 }
27 func createUserV2() *user {
28 u := user{
29 name: "Bill",
30 email: "bill@ardanlabs.com",
31 }
32
33 println("V2", &u)
34 return &u
35 }
Commençons par cette ligne dans le rapport.Listing 14./main.go:22: createUserV1 &u does not escape
Cela suggère que l'appel à la fonction println à l'intérieur de la fonction createUserV1 ne provoque pas de vidage du type utilisateur vers le tas. Ce cas a dû être vérifié car il est utilisé en conjonction avec la fonction println.Ensuite, regardez ces lignes dans le rapport.Listing 15./main.go:34: &u escapes to heap
./main.go:34: from ~r0 (return) at ./main.go:34
./main.go:31: moved to heap: u
./main.go:33: createUserV2 &u does not escape
Ces lignes indiquent que la valeur du type d'utilisateur associé à la variable u, qui a le type d'utilisateur nommé et qui est créée sur la ligne 31, est transférée dans le tas en raison du retour sur la ligne 34. La dernière ligne dit la même chose que précédemment, println appelle sur la ligne 33 ne réinitialise pas le type d'utilisateur.La lecture de ces rapports peut prêter à confusion et peut varier légèrement selon que le type de la variable en question est basé sur un type nommé ou littéral.Modifiez la variable u pour être l'utilisateur de type littéral * au lieu de l'utilisateur de type nommé, comme c'était le cas auparavant.Listing 1627 func createUserV2() *user {
28 u := &user{
29 name: "Bill",
30 email: "bill@ardanlabs.com",
31 }
32
33 println("V2", u)
34 return u
35 }
Exécutez à nouveau le rapport.Listing 17./main.go:30: &user literal escapes to heap
./main.go:30: from u (assigned) at ./main.go:28
./main.go:30: from ~r0 (return) at ./main.go:34
Le rapport indique maintenant que la valeur du type d'utilisateur référencé par la variable u, qui a le type littéral * utilisateur et créé sur la ligne 28, est transférée dans le tas en raison du retour sur la ligne 34.Conclusion
La création d'une valeur ne détermine pas où elle se trouve. Seule la façon dont la valeur est divisée déterminera ce que le compilateur fera de cette valeur. Chaque fois que vous partagez une valeur dans la pile d'appels, elle est transférée dans le tas. Il existe d'autres raisons pour lesquelles une valeur peut s'échapper de la pile. J'en parlerai dans le prochain post.Le but de ces messages est de fournir des conseils sur le choix de l'utilisation de la sémantique des valeurs ou de la sémantique des pointeurs pour tout type donné. Chaque sémantique est associée au profit et à la valeur. La sémantique des valeurs stocke les valeurs sur la pile, ce qui réduit la charge sur le GC. Cependant, il existe différentes copies de la même valeur qui doivent être stockées, suivies et conservées. La sémantique du pointeur place les valeurs dans un tas, ce qui peut exercer une pression sur le GC. Cependant, ils sont efficaces car il n'y a qu'une seule valeur qui doit être stockée, suivie et maintenue. Le point clé est l'utilisation de chaque sémantique correctement, de manière cohérente et équilibrée.