Bonjour à tous. Avant le début du cours Python Neural Networks, nous avons préparé pour vous une traduction d'un autre matériel intéressant.
Nous sommes heureux de vous présenter PyCaret , une bibliothèque d'apprentissage machine Python open source pour l'apprentissage et le déploiement de modèles avec et sans professeur dans un environnement low-code. PyCaret vous permet de passer de la préparation des données au déploiement du modèle en quelques secondes dans l'environnement de notebook que vous choisissez.Par rapport aux autres bibliothèques d'apprentissage automatique ouvertes, PyCaret est une alternative low-code qui peut remplacer des centaines de lignes de code avec seulement quelques mots. La vitesse des expériences plus efficaces augmentera de façon exponentielle. PyCaret est essentiellement un shell Python sur plusieurs bibliothèques d'apprentissage automatique telles que scikit-learn , XGBoost , Microsoft LightGBM , spaCyet plein d'autres.PyCaret est simple et facile à utiliser. Toutes les opérations effectuées par PyCaret sont séquentiellement stockées dans un pipeline entièrement prêt pour le déploiement. Qu'il s'agisse d'ajouter des valeurs manquantes, de convertir des données catégorielles, des fonctionnalités d'ingénierie ou d'optimiser des hyperparamètres, PyCaret peut automatiser tout cela. Pour en savoir un peu plus sur PyCaret, regardez cette courte vidéo .Débuter avec PyCaret
La première version stable de PyCaret version 1.0.0 peut être installée à l'aide de pip. Utilisez l'interface de ligne de commande ou l'environnement de bloc-notes et exécutez la commande ci-dessous pour installer PyCaret.pip install pycaret
Si vous utilisez des ordinateurs portables Azure ou Google Colab , exécutez la commande suivante:!pip install pycaret
Lorsque vous installez PyCaret, toutes les dépendances seront installées automatiquement. Vous pouvez consulter la liste des dépendances ici .Rien de plus simple
Procédure pas à pas
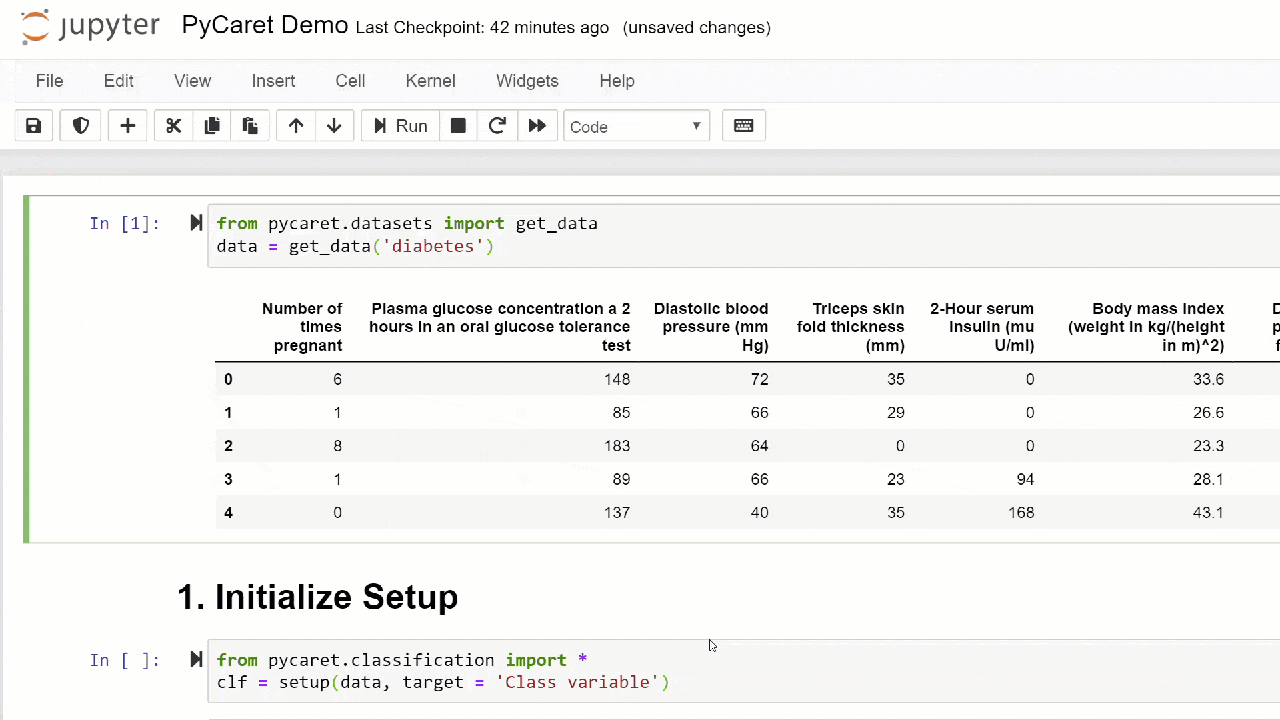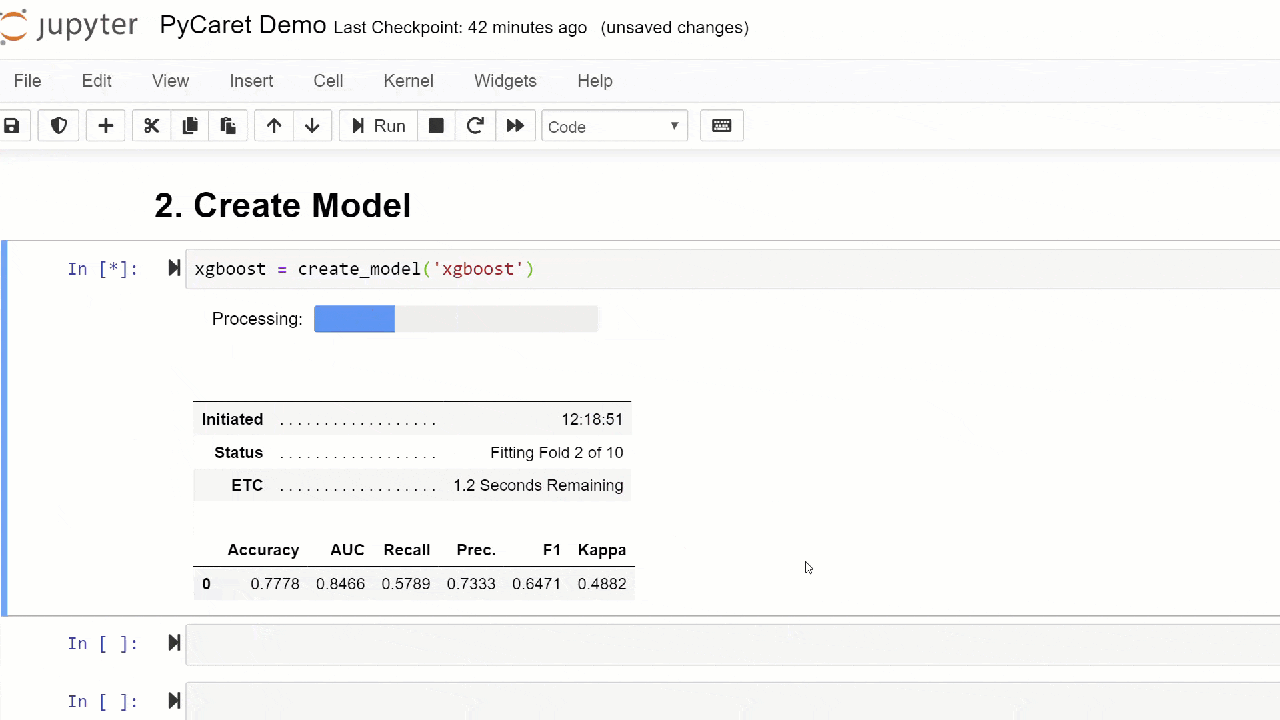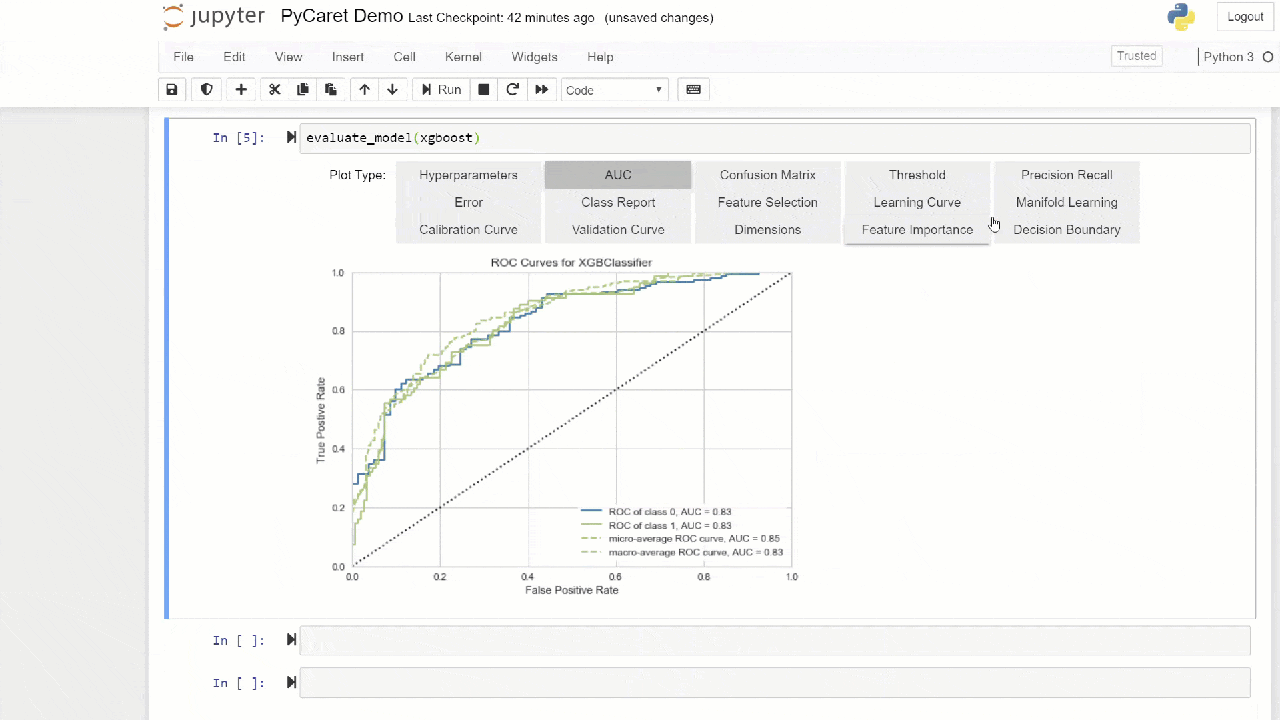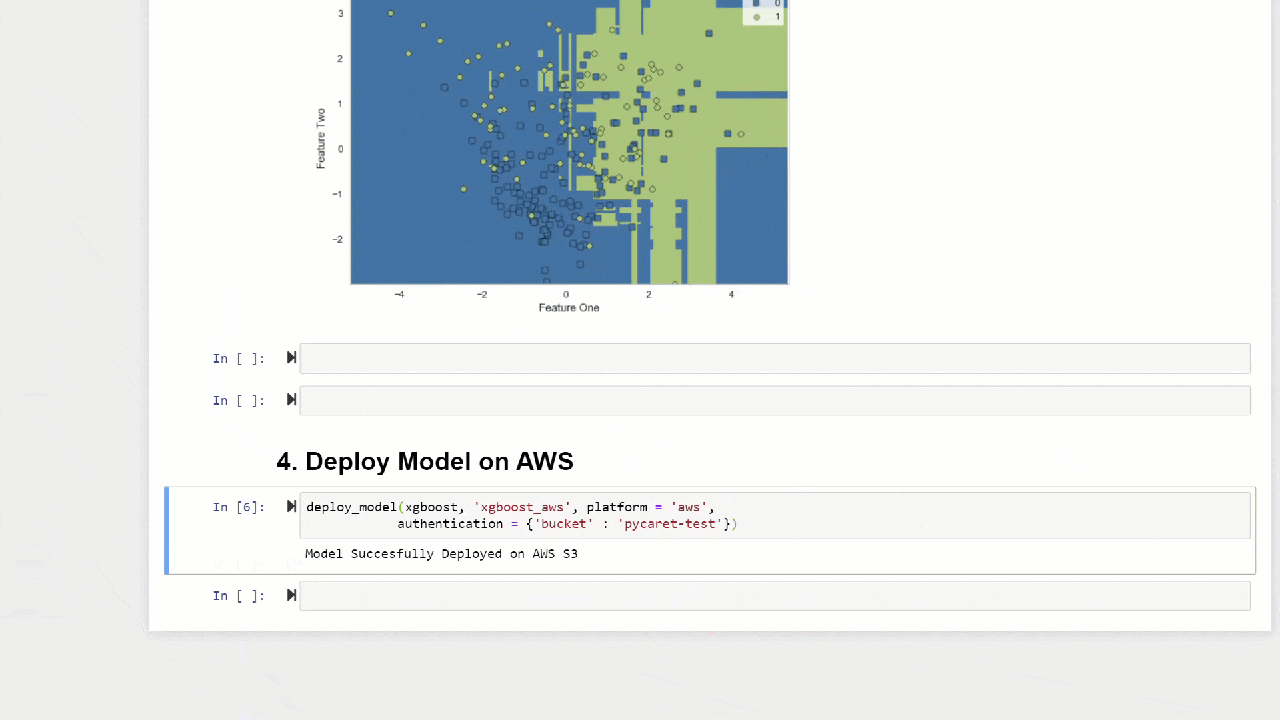
1. Acquisition de donnéesDans cette procédure pas à pas, nous utiliserons un ensemble de données sur le diabète, notre objectif est de prédire le résultat du patient (en binaire 0 ou 1) en fonction de plusieurs facteurs tels que la pression, le niveau d'insuline sanguine, l'âge, etc. . Cet ensemble de données est disponible sur le référentiel PyCaret GitHub . La façon la plus simple d'importer le jeu de données directement à partir du référentiel est d'utiliser la fonction à get_datapartir des modules pycaret.datasets.from pycaret.datasets import get_data
diabetes = get_data('diabetes')
 PyCaret peut fonctionner directement avec les trames de données pandas2. Configuration de l'environnementToute expérience avec l'apprentissage automatique dans PyCaret commence par la configuration de l'environnement en important le module nécessaire et en l'initialisant
PyCaret peut fonctionner directement avec les trames de données pandas2. Configuration de l'environnementToute expérience avec l'apprentissage automatique dans PyCaret commence par la configuration de l'environnement en important le module nécessaire et en l'initialisant setup(). Le module qui sera utilisé dans cet exemple est pycaret.classification .Après avoir importé le module, il est setup()initialisé en définissant une trame de données ( «diabète» ) et une variable cible ( «variable de classe» ).from pycaret.classification import *
exp1 = setup(diabetes, target = 'Class variable')
 Tout le prétraitement a lieu en
Tout le prétraitement a lieu en setup(). En utilisant plus de 20 fonctions pour préparer les données avant l'apprentissage automatique, PyCaret crée un pipeline de transformations basé sur les paramètres définis dans la fonction setup(). Il crée automatiquement toutes les dépendances dans le pipeline, vous n'avez donc pas besoin de contrôler manuellement l'exécution séquentielle des transformations sur un test ou un nouvel ensemble de données (invisible).Le pipeline PyCaret peut être facilement transféré d'un environnement à un autre ou déployé en production. Ci-dessous, vous pouvez vous familiariser avec les fonctionnalités de prétraitement disponibles dans PyCaret depuis la première version.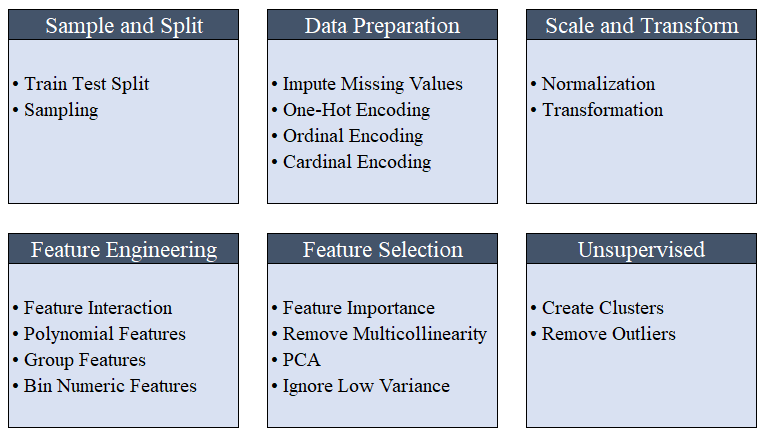 Les étapes de prétraitement des données sont obligatoires pour l'apprentissage automatique, telles que l'ajout de valeurs manquantes, le codage des variables de qualité, les étiquettes de codage (oui ou non à 1 ou 0) et le fractionnement du test de train, sont effectués automatiquement lors de l'initialisation
Les étapes de prétraitement des données sont obligatoires pour l'apprentissage automatique, telles que l'ajout de valeurs manquantes, le codage des variables de qualité, les étiquettes de codage (oui ou non à 1 ou 0) et le fractionnement du test de train, sont effectués automatiquement lors de l'initialisation setup(). Vous pouvez en savoir plus sur les fonctionnalités de prétraitement dans PyCaret ici .3. Comparaison des modèlesIl s'agit de la première étape qu'il est recommandé d'effectuer lors de la formation des enseignants ( classification ou régression ). Cette fonction forme tous les modèles de la bibliothèque de modèles et compare l'indicateur estimé entre eux en utilisant la validation croisée pour les blocs K (10 blocs par défaut). Les indicateurs estimés sont utilisés comme suit:- Pour la classification: précision, ASC, rappel, précision, F1, Kappa
- Pour la régression: MAE, MSE, RMSE, R2, RMSLE, MAPE
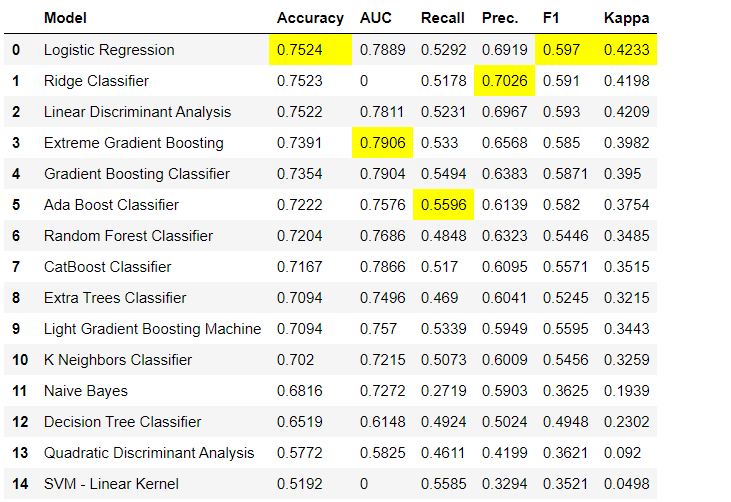 Par défaut, les métriques sont évaluées à l'aide d'une validation croisée sur 10 blocs. Le nombre de blocs peut être modifié en modifiant la valeur du paramètre
Par défaut, les métriques sont évaluées à l'aide d'une validation croisée sur 10 blocs. Le nombre de blocs peut être modifié en modifiant la valeur du paramètre fold.Le tableau par défaut est trié par «Précision» de la valeur la plus élevée à la plus faible. L'ordre de tri peut également être modifié à l'aide de l'option sort.4. Création d'un modèleLa création d'un modèle dans n'importe quel module PyCaret est si simple qu'il vous suffit de l'écrire create_model. La fonction prend un paramètre en entrée, c'est-à-dire le nom du modèle est passé sous forme de chaîne. Cette fonction renvoie un tableau avec des scores validés de manière croisée et un objet modèle entraîné.adaboost = create_model('ada')
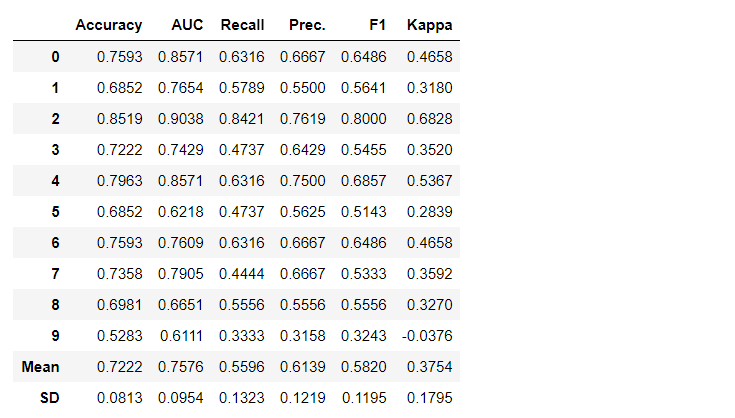 La variable "adaboost" stocke l'objet du modèle entraîné, qui renvoie une fonction
La variable "adaboost" stocke l'objet du modèle entraîné, qui renvoie une fonction create_modelqui, sous le capot, est un évaluateur scikit-learn. L'accès aux attributs source de l'objet formé peut être obtenu en utilisant la fonction period ( . )après la variable. Vous pouvez trouver un exemple d'utilisation ci-dessous. PyCaret possède plus de 60 algorithmes open source prêts à l'emploi. Une liste complète des évaluateurs / modèles disponibles dans PyCaret peut être trouvée ici .5. Configuration du modèleLa fonction est
PyCaret possède plus de 60 algorithmes open source prêts à l'emploi. Une liste complète des évaluateurs / modèles disponibles dans PyCaret peut être trouvée ici .5. Configuration du modèleLa fonction est tune_modelutilisée pour configurer automatiquement les hyperparamètres du modèle d'apprentissage automatique. PyCaret utiliserandom grid searchdans un espace de recherche spécifique. La fonction renvoie un tableau avec des estimations validées de façon croisée et un objet d'un modèle entraîné.tuned_adaboost = tune_model('ada')
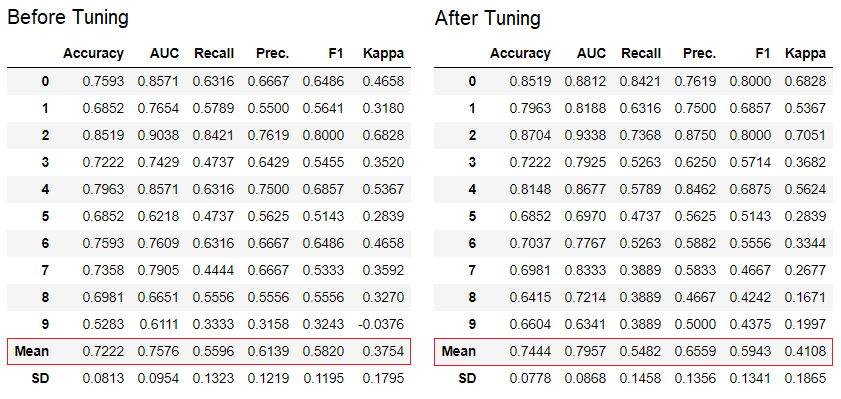 La fonction
La fonction tune_modeldes modules d'apprentissage non destinés aux enseignants tels que pycaret.nlp , pycaret.clustering et pycaret.anomaly peut être utilisée conjointement avec les modules d'apprentissage des enseignants. Par exemple, le module PNL de PyCaret peut être utilisé pour ajuster un paramètre number of topicsen évaluant une fonction objective ou une fonction de perte à partir d'un modèle avec un enseignant, comme «Précision» ou «R2».6. Ensemble de modèlesLa fonction est ensemble_modelutilisée pour créer un ensemble de modèles formés. À l'entrée, il prend un paramètre - l'objet du modèle formé. La fonction renvoie un tableau avec des estimations validées de façon croisée et un objet d'un modèle entraîné.
dt = create_model('dt')
dt_bagged = ensemble_model(dt)
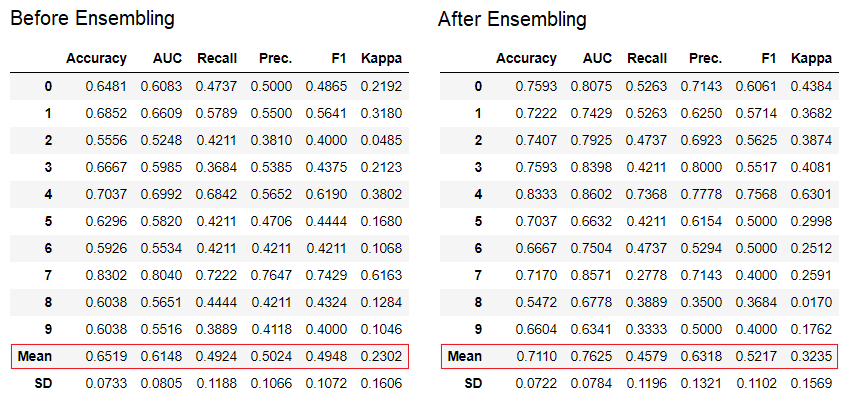 La méthode "bagging" est utilisée lors de la création de l'ensemble par défaut, elle peut être changée en "boosting" en utilisant le paramètre
La méthode "bagging" est utilisée lors de la création de l'ensemble par défaut, elle peut être changée en "boosting" en utilisant le paramètre methodde la fonction ensemble_model.PyCaret fournit également des fonctions blend_modelset stack_models pour combiner plusieurs modèles formés.7. Visualisation du modèle:vous pouvez évaluer les performances et diagnostiquer un modèle d'apprentissage automatique formé à l'aide de la fonction plot_model. Il prend l'objet du modèle formé et le type de graphique sous la forme d'une chaîne.
adaboost = create_model('ada')
plot_model(adaboost, plot = 'auc')
plot_model(adaboost, plot = 'boundary')
plot_model(adaboost, plot = 'pr')
plot_model(adaboost, plot = 'vc')
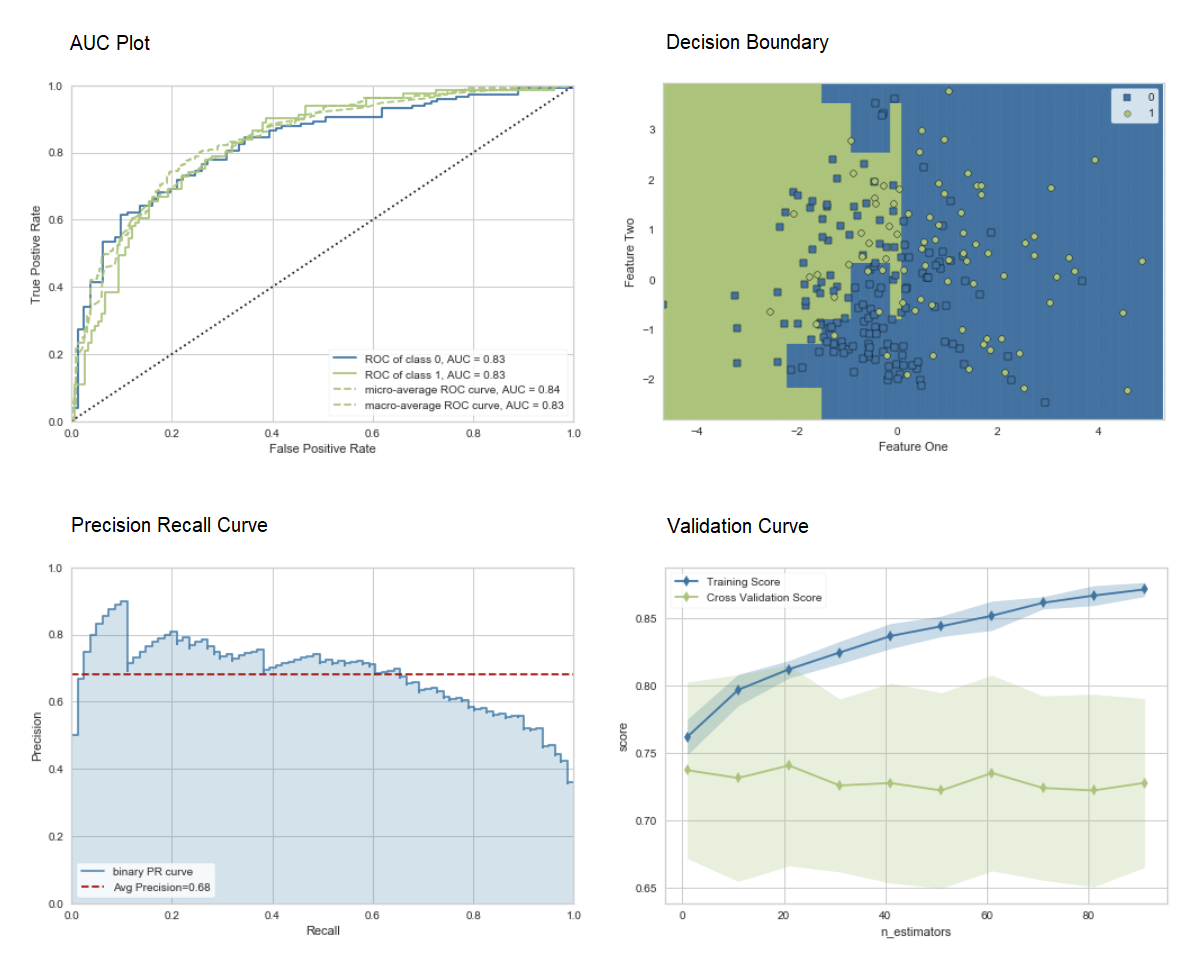 Ici, vous pouvez en savoir plus sur la visualisation dans PyCaret.Vous pouvez également utiliser la fonction
Ici, vous pouvez en savoir plus sur la visualisation dans PyCaret.Vous pouvez également utiliser la fonction evaluate_modelpour afficher des graphiques à l'aide de l'interface utilisateur du bloc-notes. La fonction
La fonction plot_modeldu module pycaret.nlppeut être utilisée pour visualiser le corps des textes et des modèles thématiques sémantiques. Ici, vous pouvez en savoir plus à leur sujet.8. Interprétation du modèleLorsque les données sont non linéaires, ce qui se produit assez souvent dans la vie réelle, nous constatons invariablement que les modèles arborescents fonctionnent beaucoup mieux que les modèles gaussiens simples. Cependant, cela est dû à une perte d'interprétabilité, car les modèles arborescents ne fournissent pas de coefficients simples, comme les modèles linéaires. PyCaret implémente SHAP (SHapley Additive exPlanations ) à l'aide d'une fonction interpret_model.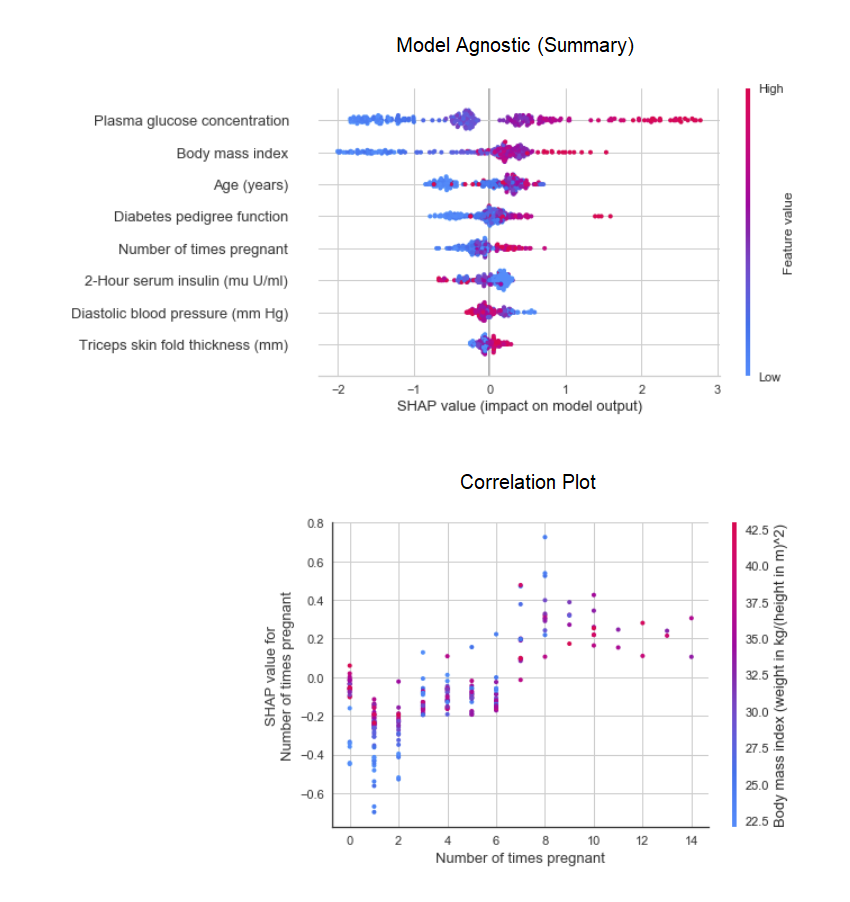 L'interprétation d'un point de données particulier dans un ensemble de données de test peut être estimée à l'aide du graphique «raison». Dans l'exemple ci-dessous, nous testons la première instance de l'ensemble de données de test.
L'interprétation d'un point de données particulier dans un ensemble de données de test peut être estimée à l'aide du graphique «raison». Dans l'exemple ci-dessous, nous testons la première instance de l'ensemble de données de test. 9. Modèle prédictifJusqu'à présent, les résultats que nous avons obtenus étaient basés sur une validation croisée par blocs K sur un ensemble de données d'apprentissage (70% par défaut). Afin de voir les prévisions et les performances du modèle sur l'ensemble de données test / hold-out, une fonction est utilisée
9. Modèle prédictifJusqu'à présent, les résultats que nous avons obtenus étaient basés sur une validation croisée par blocs K sur un ensemble de données d'apprentissage (70% par défaut). Afin de voir les prévisions et les performances du modèle sur l'ensemble de données test / hold-out, une fonction est utilisée predict_model.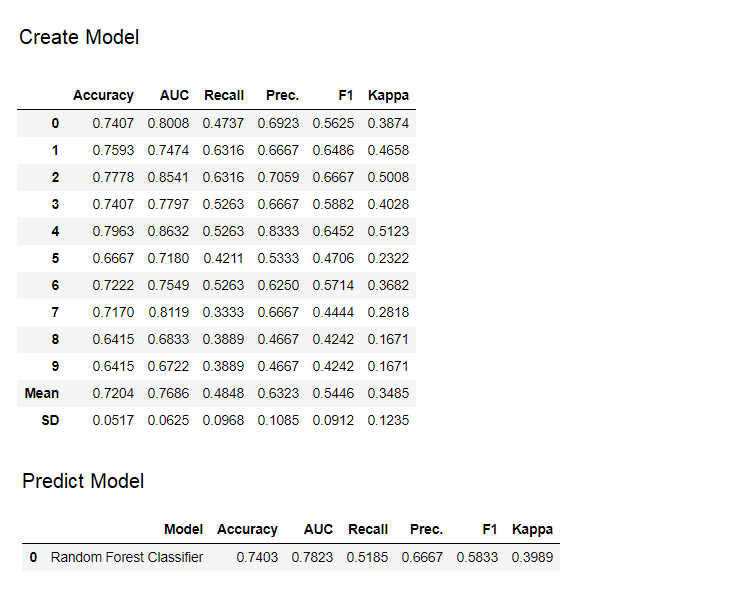 La fonction est
La fonction est predict_modelutilisée pour prévoir un ensemble de données invisible. Nous allons maintenant utiliser le même ensemble de données que nous avons utilisé pour la formation, comme proxy pour le nouvel ensemble de données invisible. En pratique, la fonctionpredict_modelsera utilisé de manière itérative, à chaque fois sur un nouvel ensemble de données invisible. La fonction
La fonction predict_modelpeut également faire des prédictions pour une chaîne séquentielle de modèles qui peuvent être créés à l'aide des fonctions stack_models et create_stacknet .La fonction predict_modelpeut également faire des prédictions directement pour les modèles hébergés sur AWS S3 à l'aide de la fonction deploy_model .10. Déployer un modèleL'une des façons d'utiliser des modèles formés pour créer des prévisions pour un nouvel ensemble de données consiste à utiliser la fonctionpredict_modeldans le même cahier / IDE où le modèle a été formé. Cependant, la génération d'une prévision pour un nouvel ensemble de données (invisible) est un processus itératif. Selon le cas d'utilisation, la fréquence des prévisions peut varier des prévisions en temps réel aux prévisions par lots. La fonction deploy_modeldans PyCaret vous permet de déployer l'ensemble du pipeline, y compris le modèle formé dans le cloud à partir de l'environnement du bloc-notes.deploy_model(model = rf, model_name = 'rf_aws', platform = 'aws',
authentication = {'bucket' : 'pycaret-test'})
11. Enregistrer le modèle / enregistrer l'expérience
Après la formation, l'ensemble du pipeline contenant toutes les transformations de prétraitement et l'objet du modèle formé peuvent être enregistrés dans un fichier pickle binaire.
adaboost = create_model('ada')
save_model(adaboost, model_name = 'ada_for_deployment')
 Vous pouvez également enregistrer l'intégralité de l'expérience, contenant toutes les sorties intermédiaires, dans un seul fichier binaire.save_experiment (experiment_name = 'my_first_experiment')
Vous pouvez également enregistrer l'intégralité de l'expérience, contenant toutes les sorties intermédiaires, dans un seul fichier binaire.save_experiment (experiment_name = 'my_first_experiment') Vous pouvez charger des modèles et des expériences enregistrés en utilisant les fonctions
Vous pouvez charger des modèles et des expériences enregistrés en utilisant les fonctions load_modelet load_experimentdisponibles à partir de tous les modules PyCaret.12. Guide suivantDans le guide suivant, nous montrerons comment utiliser le modèle d'apprentissage automatique formé dans Power BI pour générer des prédictions par lots dans un environnement de production réel.Vous pouvez également lire les blocs-notes pour débutants dans les modules suivants:Qu'est-ce qu'un pipeline de développement?
Nous travaillons activement pour améliorer PyCaret. Notre futur pipeline de développement comprend un nouveau module de prévision de séries chronologiques, l'intégration de TensorFlow et des améliorations majeures de l'évolutivité de PyCaret. Si vous souhaitez partager vos commentaires et nous aider à nous améliorer, vous pouvez remplir un formulaire sur le site ou laisser un commentaire sur notre page sur GitHub ou LinkedIn .Vous voulez en savoir plus sur un module particulier?
Depuis la première version, PyCaret 1.0.0 dispose des modules suivants disponibles. Suivez les liens ci-dessous pour vous familiariser avec la documentation et des exemples de travaux.ClassificationRégressionClusteringRecherche d'anomaliesTraitement de texte naturel (PNL)Formation aux règles associativesLiens importants
Si vous avez aimé PyCaret, mettez-nous ️ sur GitHub.Pour en savoir plus sur PyCaret, vous pouvez nous suivre sur LinkedIn et Youtube .
En savoir plus sur le cours.