La traduction de l'article a été préparée spécialement pour les étudiants du cours «Bases de données» .
Ce que vous ignoriez peut-être sur la génération de nombres aléatoires sysbenchSysbench est un outil de test de performances populaire. Il a été écrit à l'origine par Peter Zaitsev au début des années 2000 et est devenu la norme de facto pour les tests et l'analyse comparative. Il est actuellement pris en charge par Alexei Kopytov et est publié sur Github à l' adresse .Cependant, j'ai remarqué que, malgré sa large distribution, il y a des moments inconnus pour beaucoup dans sysbench. Par exemple, la possibilité de modifier facilement les tests MySQL en utilisant Lua ou de configurer les paramètres du générateur de nombres aléatoires intégré.De quoi parle l'article?
J'ai écrit cet article pour montrer à quel point il est facile de personnaliser sysbench selon vos besoins. Il existe de nombreuses façons d'étendre les fonctionnalités de sysbench, et l'une d'elles consiste à configurer la génération d'identificateurs aléatoires (ID).Par défaut, sysbench propose cinq options différentes pour générer des nombres aléatoires. Mais très souvent (en fait, presque jamais), aucun d'entre eux n'est explicitement indiqué, et encore moins souvent vous pouvez voir les paramètres de génération (pour les options où ils sont disponibles).Si vous avez une question: «Et pourquoi devrais-je être intéressé par cela? Après tout, les valeurs par défaut sont tout à fait appropriées », alors cet article est conçu pour vous aider à comprendre pourquoi ce n'est pas toujours le cas.commençons
Quels sont les moyens de générer des nombres aléatoires dans sysbench? Les éléments suivants sont actuellement implémentés (vous pouvez facilement les voir grâce à l'option --help):- Spécial (distribution spéciale)
- Gaussien (distribution gaussienne)
- Pareto (distribution Pareto)
- Zipfian (distribution Zipf)
- Uniforme (distribution uniforme)
Par défaut, Special est utilisé avec les paramètres suivants:rand-spec-iter = 12 - nombre d'itérations pour une distribution spécialerand-spec-pct = 1 - pourcentage de toute la plage dans laquelle les valeurs «spéciales» tombent avec une distribution spécialerand-spec-res = 75 - pourcentage de valeurs «spéciales» à utiliser dans une distribution spéciale
Comme j'aime les tests et les scripts simples et faciles à reproduire, toutes les données suivantes seront collectées à l'aide des commandes sysbench suivantes:- sysbench ./src/lua/oltp_read.lua -mysql_storage_engine = innodb –db-driver = mysql –tables = 10 –table_size = 100 prepare
- sysbench ./src/lua/oltp_read_write.lua –db-driver=mysql –tables=10 –table_size=100 –skip_trx=off –report-interval=1 –mysql-ignore-errors=all –mysql_storage_engine=innodb –auto_inc=on –histogram –stats_format=csv –db-ps-mode=disable –threads=10 –time=60 –rand-type=XXX run
N'hésitez pas à vous expérimenter. La description et les données du script peuvent être trouvées ici .Pourquoi sysbench utilise-t-il un générateur de nombres aléatoires? L'un des objectifs est de générer des ID qui seront utilisés dans les requêtes. Ainsi, dans notre exemple, des nombres entre 1 et 100 seront générés, en tenant compte de la création de 10 tables avec 100 lignes dans chacune.Que faire si vous exécutez sysbench comme décrit ci-dessus et ne changez que -rand-type?J'ai exécuté ce script et utilisé le journal général pour collecter et analyser la fréquence des valeurs d'ID générées. Voici le résultat: Uniformespécial Zipfian Pareto Gaussian
On peut voir que ce paramètre est important, non? Après tout, sysbench fait exactement ce que nous attendions de lui.



 Examinons de plus près chacune des distributions.
Examinons de plus près chacune des distributions.Spécial
Special est utilisé par défaut, donc si vous ne spécifiez PAS de type rand, sysbench utilisera special. Special utilise un nombre très limité de valeurs ID. Dans notre exemple, nous pouvons voir que les valeurs 50-51 sont principalement utilisées, les valeurs restantes entre 44-56 sont extrêmement rares, tandis que d'autres ne sont pratiquement pas utilisées. Veuillez noter que les valeurs sélectionnées se situent au milieu de la plage disponible de 1-100.Dans ce cas, le pic est d'environ deux ID représentant 2% de l'échantillon. Si j'augmente le nombre d'enregistrements à un million, le pic restera, mais ce sera à 7493, soit 0,74% de l'échantillon. Comme cela sera plus restrictif, le nombre de pages sera probablement supérieur à un.Uniforme (distribution uniforme)
Comme son nom l'indique, si nous utilisons Uniform, toutes les valeurs seront utilisées pour l'ID, et la distribution sera ... uniforme.Zipfian (distribution Zipf)
La distribution Zipf, parfois appelée distribution zêta, est une distribution discrète couramment utilisée en linguistique, en assurance et en modélisation d'événements rares. Dans ce cas, sysbench utilisera des nombres commençant par le plus petit (1) et réduira très rapidement la fréquence d'utilisation, en passant à de plus grands nombres.Pareto (Pareto)
Pareto applique la règle «80-20» . Dans ce cas, les identifiants générés seront encore moins étalés et seront plus concentrés dans un petit segment. Dans notre exemple, 52% de tous les identifiants avaient une valeur de 1 et 73% des valeurs étaient dans les 10 premiers nombres.Gaussien (distribution gaussienne)
La distribution gaussienne (distribution normale) est bien connue et familière . Il est principalement utilisé dans les statistiques et les prévisions autour d'un facteur central. Dans ce cas, les ID utilisés sont distribués le long de la courbe en forme de cloche, en commençant par la valeur moyenne, puis en diminuant lentement vers les bords.À quoi ça sert?
Chacune des options ci-dessus a son propre usage et peut être regroupée par objectif. Pareto et Focus spécial sur les points chauds. Dans ce cas, l'application utilise encore et encore la même page / donnée. C'est peut-être ce dont nous avons besoin, mais nous devons comprendre ce que nous faisons et ne pas faire d'erreurs ici.Par exemple, si nous testons les performances de la compression de page InnoDB pendant la lecture, nous devons éviter d'utiliser la valeur par défaut de Special ou Pareto. Si nous avons un ensemble de données de 1 To et un pool de mémoire tampon de 30 Go et que nous demandons la même page plusieurs fois, cette page sera déjà lue sur le disque et sera disponible non compressée en mémoire.Bref, un tel test est une perte de temps et d'efforts.La même chose si nous devons vérifier les performances de l'enregistrement. Écrire la même page encore et encore n'est pas la meilleure option.Qu'en est-il des tests de performances?Encore une fois, nous voulons tester les performances, mais dans quel cas? Il est important de comprendre que la méthode de génération de nombres aléatoires affecte considérablement les résultats du test. Et vos «défauts assez bons» peuvent conduire à des conclusions erronées.Les graphiques suivants montrent différentes latences en fonction du type de rand (type de test, temps, paramètres supplémentaires et le nombre de threads sont les mêmes partout).De type à type, les délais sont sensiblement différents: ici, je lisais et j'écrivais, et les données étaient extraites du schéma de performances (
ici, je lisais et j'écrivais, et les données étaient extraites du schéma de performances (sys.schema_table_statistics) Comme prévu, Pareto et Special prennent beaucoup plus de temps que d'autres, ce qui fait que le système (MySQL-InnoDB) souffre artificiellement de la concurrence dans un «point chaud».La modification du type rand affecte non seulement le délai, mais également le nombre de lignes traitées, comme indiqué par le schéma de performances.
 Compte tenu de tout ce qui précède, il est important de comprendre ce que nous essayons d'évaluer et de tester.Si mon objectif est de tester les performances du système à tous les niveaux, je préférerais peut-être utiliser Uniform, qui chargera également l'ensemble de données / le serveur de base de données / le système et sera plus susceptible de répartir uniformément la lecture / la charge / l'écriture.Si mon travail consiste à travailler avec des points chauds, alors Pareto et Special sont probablement le bon choix.Mais n'utilisez pas aveuglément les valeurs par défaut. Ils peuvent vous convenir, mais ils sont souvent destinés aux cas extrêmes. D'après mon expérience, vous pouvez souvent ajuster les paramètres pour obtenir le résultat dont vous avez besoin.Par exemple, vous souhaitez utiliser les valeurs du milieu en élargissant l'intervalle de sorte qu'il n'y ait pas de pic pointu (spécial par défaut) ou de cloche (gaussien).Vous pouvez configurer Special pour obtenir quelque chose comme ceci:
Compte tenu de tout ce qui précède, il est important de comprendre ce que nous essayons d'évaluer et de tester.Si mon objectif est de tester les performances du système à tous les niveaux, je préférerais peut-être utiliser Uniform, qui chargera également l'ensemble de données / le serveur de base de données / le système et sera plus susceptible de répartir uniformément la lecture / la charge / l'écriture.Si mon travail consiste à travailler avec des points chauds, alors Pareto et Special sont probablement le bon choix.Mais n'utilisez pas aveuglément les valeurs par défaut. Ils peuvent vous convenir, mais ils sont souvent destinés aux cas extrêmes. D'après mon expérience, vous pouvez souvent ajuster les paramètres pour obtenir le résultat dont vous avez besoin.Par exemple, vous souhaitez utiliser les valeurs du milieu en élargissant l'intervalle de sorte qu'il n'y ait pas de pic pointu (spécial par défaut) ou de cloche (gaussien).Vous pouvez configurer Special pour obtenir quelque chose comme ceci: dans ce cas, les ID sont toujours à proximité et il y a de la concurrence. Mais l'influence d'un «point chaud» est moindre, donc les conflits possibles seront désormais avec plusieurs identifiants, qui, selon le nombre d'enregistrements sur une page, peuvent être sur plusieurs pages.Un autre exemple est le partitionnement. Par exemple, comment vérifier le fonctionnement de votre système avec les partitions, en vous concentrant sur les dernières données, en archivant les anciennes?Facile! Rappelez-vous le tableau de distribution de Pareto? Vous pouvez le changer selon vos besoins.
dans ce cas, les ID sont toujours à proximité et il y a de la concurrence. Mais l'influence d'un «point chaud» est moindre, donc les conflits possibles seront désormais avec plusieurs identifiants, qui, selon le nombre d'enregistrements sur une page, peuvent être sur plusieurs pages.Un autre exemple est le partitionnement. Par exemple, comment vérifier le fonctionnement de votre système avec les partitions, en vous concentrant sur les dernières données, en archivant les anciennes?Facile! Rappelez-vous le tableau de distribution de Pareto? Vous pouvez le changer selon vos besoins. En spécifiant la valeur -rand-pareto, vous pouvez obtenir exactement ce que vous vouliez en forçant sysbench à se concentrer sur les grandes valeurs d'ID.Zipfian peut également être configuré et, bien que vous ne puissiez pas obtenir une inversion, comme c'est le cas avec Pareto, vous pouvez facilement passer d'un pic sur une valeur à une distribution plus uniforme. Un bon exemple est le suivant:
En spécifiant la valeur -rand-pareto, vous pouvez obtenir exactement ce que vous vouliez en forçant sysbench à se concentrer sur les grandes valeurs d'ID.Zipfian peut également être configuré et, bien que vous ne puissiez pas obtenir une inversion, comme c'est le cas avec Pareto, vous pouvez facilement passer d'un pic sur une valeur à une distribution plus uniforme. Un bon exemple est le suivant: La dernière chose à garder à l’esprit, et il me semble que ce sont des choses évidentes, mais il vaut mieux dire que ne pas dire que lors de la modification des paramètres de génération de nombres aléatoires, les performances changeront.Comparer la latence:
La dernière chose à garder à l’esprit, et il me semble que ce sont des choses évidentes, mais il vaut mieux dire que ne pas dire que lors de la modification des paramètres de génération de nombres aléatoires, les performances changeront.Comparer la latence: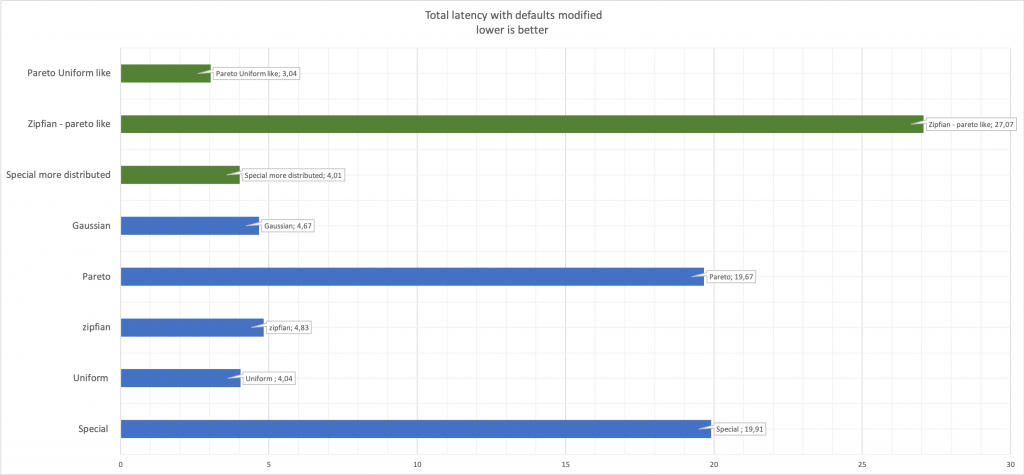 ici, le vert montre les valeurs modifiées par rapport au bleu d'origine.
ici, le vert montre les valeurs modifiées par rapport au bleu d'origine.
résultats
À ce stade, vous devez déjà comprendre à quel point il est facile de configurer la génération de nombres aléatoires dans sysbench et à quel point cela peut vous être utile. Gardez à l'esprit que ce qui précède s'applique à tous les appels, par exemple lorsque vous utilisez sysbench.rand.default:local function get_id()
return sysbench.rand.default(1, sysbench.opt.table_size)
End
Compte tenu de cela, ne copiez pas inconsciemment le code des articles d'autres personnes, mais réfléchissez et explorez ce dont vous avez besoin et comment y parvenir.Avant d'exécuter les tests, vérifiez les options de génération de nombres aléatoires pour vous assurer qu'elles sont appropriées et adaptées à vos besoins. Pour simplifier ma vie, j'utilise ce test simple . Ce test affiche des informations de distribution d'ID assez claires.Mon conseil est que vous devez comprendre vos besoins et effectuer correctement des tests / benchmarking.Références
Tout d'abord, c'est sysbench lui-même .Articles sur Zipfian:Pareto:L'article de Percona sur la façon d'écrire vos scripts dans sysbenchTous les matériaux utilisés pour cet article sont sur GitHub .
→ En savoir plus sur le cours