Au cours des 10 années d'existence d'ivi, nous avons construit une base de données de 90 000 vidéos de différentes longueurs, tailles et qualités. Des centaines de nouvelles apparaissent chaque semaine. Nous avons des gigaoctets de métadonnées, qui sont utiles pour les recommandations, simplifient la navigation du service et la mise en place de la publicité. Mais nous avons commencé à extraire des informations directement de la vidéo il y a seulement deux ans.Dans cet article, je vais vous expliquer comment nous analysons les films en éléments structurels et pourquoi nous en avons besoin. À la fin, il y a un lien vers le référentiel Github avec le code de l'algorithme et des exemples.
En quoi consiste une vidéo?
Le clip vidéo a une structure hiérarchique. Il s'agit de vidéo numérique, donc au niveau le plus bas se trouvent des pixels , des points colorés qui composent une image fixe.Les images fixes sont appelées cadres - elles se remplacent et créent un effet de mouvement. Lors de l'installation, les cadres sont découpés en groupes qui, selon les instructions du réalisateur, sont interchangés et collés. La séquence de cadres d'un assemblage collé à un autre en anglais est appelée le terme plan. Malheureusement, la terminologie russe échoue, car de tels groupes sont également appelés cadres. Afin de ne pas être confus, utilisons le terme anglais. Entrez simplement la version en langue russe: "shot" .Les plans sont regroupés par signification, ils sont appelés scènes.La scène se caractérise par l'unité du lieu, du temps et des personnages.Nous pouvons facilement obtenir des images individuelles et même des pixels de ces images, car les algorithmes de codage vidéo numérique sont ainsi organisés. Ces informations sont nécessaires à la reproduction.Les bordures de plans et de scènes sont beaucoup plus difficiles à obtenir. Les sources des programmes d'installation peuvent aider, mais elles ne sont pas disponibles pour nous.Heureusement, les algorithmes peuvent le faire, mais pas de manière parfaitement précise. Je vais vous parler de l'algorithme de division en scènes.
Lors de l'installation, les cadres sont découpés en groupes qui, selon les instructions du réalisateur, sont interchangés et collés. La séquence de cadres d'un assemblage collé à un autre en anglais est appelée le terme plan. Malheureusement, la terminologie russe échoue, car de tels groupes sont également appelés cadres. Afin de ne pas être confus, utilisons le terme anglais. Entrez simplement la version en langue russe: "shot" .Les plans sont regroupés par signification, ils sont appelés scènes.La scène se caractérise par l'unité du lieu, du temps et des personnages.Nous pouvons facilement obtenir des images individuelles et même des pixels de ces images, car les algorithmes de codage vidéo numérique sont ainsi organisés. Ces informations sont nécessaires à la reproduction.Les bordures de plans et de scènes sont beaucoup plus difficiles à obtenir. Les sources des programmes d'installation peuvent aider, mais elles ne sont pas disponibles pour nous.Heureusement, les algorithmes peuvent le faire, mais pas de manière parfaitement précise. Je vais vous parler de l'algorithme de division en scènes.Pourquoi avons nous besoin de ça?
Nous résolvons le problème de recherche à l'intérieur de la vidéo et voulons tester automatiquement chaque scène de chaque film sur ivi. La division en scènes est une partie importante de ce pipeline.Pour savoir où commencent et finissent les scènes, vous devez créer des bandes-annonces synthétiques. Nous avons déjà un algorithme qui les génère, mais jusqu'à présent, la détection de scène n'y est pas utilisée.Le système de recommandation est également utile pour le fractionnement en scènes. On en obtient des signes qui décrivent quels films les utilisateurs aiment dans la structure.Quelles sont les approches pour résoudre le problème?
Le problème est résolu de deux côtés:- Ils prennent toute la vidéo et recherchent les limites des scènes.
- Tout d'abord, ils divisent la vidéo en plans, puis les combinent en scènes.
Nous sommes allés dans la deuxième voie, car c'est plus facile à formaliser, et il y a des articles scientifiques sur ce sujet. Nous savons déjà comment diviser la vidéo en plans. Reste à rassembler ces plans en scènes.La première chose que vous voulez essayer est le clustering. Prenez les photos, transformez-les en vecteurs, puis divisez les vecteurs en groupes classiques à l'aide d'algorithmes de clustering classiques. Le principal inconvénient de cette approche: elle ne tient pas compte du fait que les plans et les scènes se succèdent. Un plan d'une autre scène ne peut pas se tenir entre deux plans d'une scène, et avec le regroupement, cela est possible.En 2016, Daniel Rothman et ses collègues IBM ont proposé un algorithme qui prend en compte la structure temporelle et a formulé la combinaison de plans en scènes comme une tâche de regroupement séquentiel optimal:
Le principal inconvénient de cette approche: elle ne tient pas compte du fait que les plans et les scènes se succèdent. Un plan d'une autre scène ne peut pas se tenir entre deux plans d'une scène, et avec le regroupement, cela est possible.En 2016, Daniel Rothman et ses collègues IBM ont proposé un algorithme qui prend en compte la structure temporelle et a formulé la combinaison de plans en scènes comme une tâche de regroupement séquentiel optimal:- étant donné une séquence de coups
- besoin de le diviser en segments afin que cette séparation soit optimale.
Qu'est-ce qu'une séparation optimale?
Pour l'instant, nous supposons que étant donné, c'est-à-dire que le nombre de scènes est connu. Seules leurs frontières sont inconnues.De toute évidence, une sorte de métrique est nécessaire. Trois métriques ont été inventées, elles sont basées sur l'idée de distances par paires entre les prises de vue.Les étapes préparatoires sont les suivantes:- Nous transformons les tirs en vecteurs (un histogramme ou les sorties de l'avant-dernière couche d'un réseau neuronal)
- Trouver les distances par paires entre les vecteurs (euclidienne, cosinus ou autre)
- Nous obtenons une matrice carrée où chaque élément est la distance entre les tirs et .
 Cette matrice est symétrique, et sur la diagonale principale, elle aura toujours des zéros, car la distance du vecteur à lui-même est nulle.Des carrés sombres sont tracés le long de la diagonale - des zones où les tirs voisins sont similaires les uns aux autres, en conséquence moins de distance.Si nous choisissons de bonnes intégrations qui reflètent la sémantique des plans et choisissons une bonne fonction de distance, alors ces carrés sont les scènes. Trouvez les bordures des carrés - nous trouverons les bordures des scènes.En regardant la matrice, des collègues israéliens ont formulé trois critères pour un partitionnement optimal:
Cette matrice est symétrique, et sur la diagonale principale, elle aura toujours des zéros, car la distance du vecteur à lui-même est nulle.Des carrés sombres sont tracés le long de la diagonale - des zones où les tirs voisins sont similaires les uns aux autres, en conséquence moins de distance.Si nous choisissons de bonnes intégrations qui reflètent la sémantique des plans et choisissons une bonne fonction de distance, alors ces carrés sont les scènes. Trouvez les bordures des carrés - nous trouverons les bordures des scènes.En regardant la matrice, des collègues israéliens ont formulé trois critères pour un partitionnement optimal:
Est le vecteur de bordure de scène.Lequel des critères de partitionnement optimal choisir?
Une bonne fonction de perte pour une tâche de regroupement séquentiel optimal a deux propriétés:- Si le film se compose d'une scène, alors partout où nous essayons de le diviser en deux parties, la valeur de la fonction sera toujours la même.
- Si elle est correctement divisée en scènes, la valeur sera inférieure à sinon correctement.
Il s'avère et ne respectent pas ces exigences, mais faire face. Pour illustrer cela, nous allons mener deux expériences.Dans la première expérience, nous allons créer une matrice synthétique de distances par paires, en la remplissant d'un bruit uniforme. Si nous essayons de diviser en deux scènes, nous obtenons l'image suivante: dit qu'au milieu de la vidéo il y a un changement de scènes, ce qui n'est en fait pas vrai. Àsauts anormaux si la partition est placée au début ou à la fin de la vidéo. Seulementse comporte au besoin.Dans la deuxième expérience, nous ferons la même matrice avec un bruit uniforme, mais en soustrayant deux carrés, comme si nous avions deux scènes légèrement différentes l'une de l'autre.
dit qu'au milieu de la vidéo il y a un changement de scènes, ce qui n'est en fait pas vrai. Àsauts anormaux si la partition est placée au début ou à la fin de la vidéo. Seulementse comporte au besoin.Dans la deuxième expérience, nous ferons la même matrice avec un bruit uniforme, mais en soustrayant deux carrés, comme si nous avions deux scènes légèrement différentes l'une de l'autre.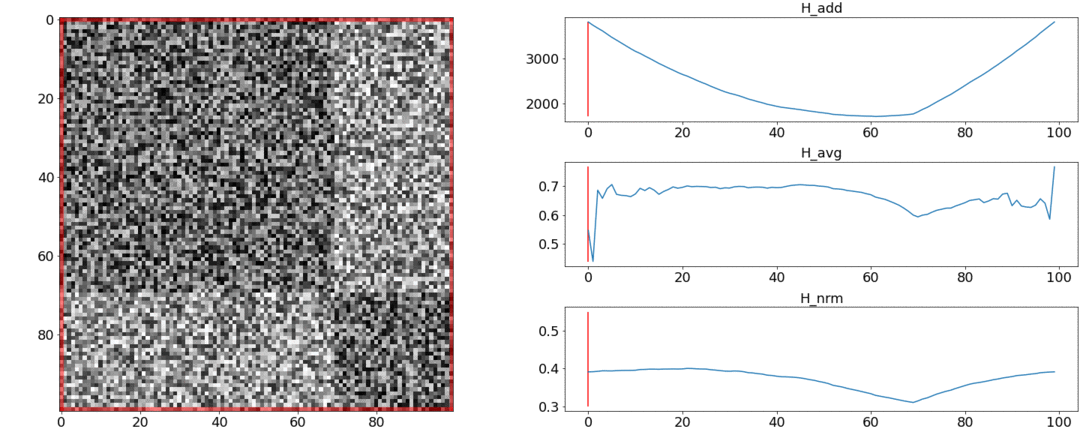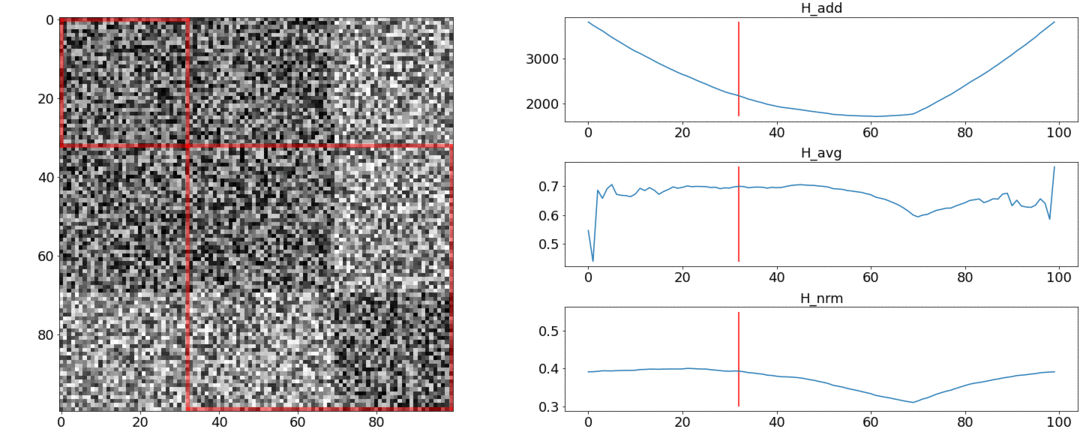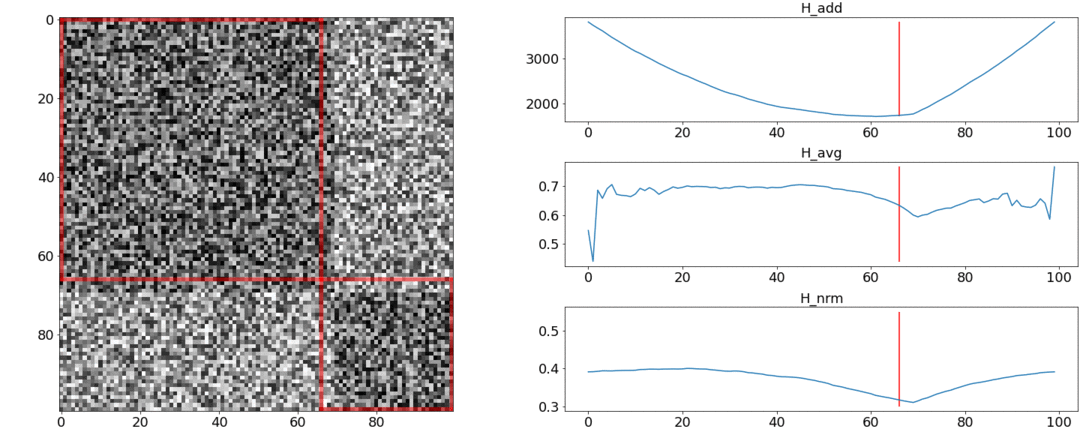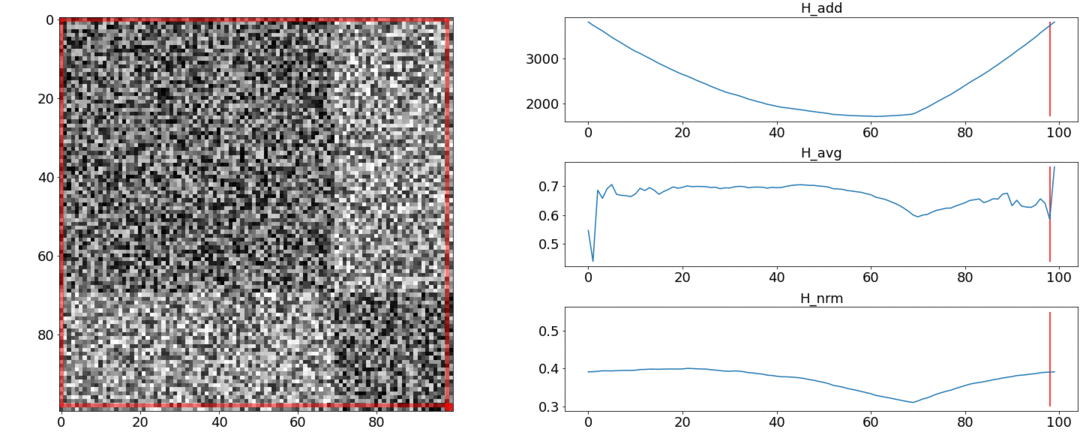 Pour détecter ce collage, la fonction doit prendre une valeur minimale lorsque. Mais un minimum encore plus près du milieu du segment, tandis que - Au début. À un minimum clair est visible à .Les tests montrent également que la répartition la plus précise est obtenue en utilisant. Il semble que vous deviez le prendre et tout ira bien. Mais regardons d'abord la complexité de l'algorithme d'optimisation.Daniel Rothman et son groupe ont suggéré de rechercher un partitionnement optimal en utilisant la programmation dynamique . La tâche est divisée en sous-tâches de manière récursive et résolue à son tour. Cette méthode donne un optimum global, mais pour le trouver, vous devez itérer sur chaquetoutes les combinaisons de partitions du 0e au Ne plans et choisissez le meilleur. Ici - le nombre de scènes, et - le nombre de coups.Aucune optimisation des réglages et des accélérations fonctionnera à temps . ÀIl existe un autre paramètre pour l'énumération - la zone de la partition, et à chaque étape, vous devez vérifier toutes ses valeurs. En conséquence, le temps passe à.Nous avons réussi à apporter des améliorations et à accélérer l'optimisation en utilisant la technique de mémorisation - en mettant en cache les résultats de la récursivité en mémoire afin de ne pas lire la même chose plusieurs fois. Mais, comme le montrent les tests ci-dessous, une forte augmentation de vitesse n'a pas été atteinte.
Pour détecter ce collage, la fonction doit prendre une valeur minimale lorsque. Mais un minimum encore plus près du milieu du segment, tandis que - Au début. À un minimum clair est visible à .Les tests montrent également que la répartition la plus précise est obtenue en utilisant. Il semble que vous deviez le prendre et tout ira bien. Mais regardons d'abord la complexité de l'algorithme d'optimisation.Daniel Rothman et son groupe ont suggéré de rechercher un partitionnement optimal en utilisant la programmation dynamique . La tâche est divisée en sous-tâches de manière récursive et résolue à son tour. Cette méthode donne un optimum global, mais pour le trouver, vous devez itérer sur chaquetoutes les combinaisons de partitions du 0e au Ne plans et choisissez le meilleur. Ici - le nombre de scènes, et - le nombre de coups.Aucune optimisation des réglages et des accélérations fonctionnera à temps . ÀIl existe un autre paramètre pour l'énumération - la zone de la partition, et à chaque étape, vous devez vérifier toutes ses valeurs. En conséquence, le temps passe à.Nous avons réussi à apporter des améliorations et à accélérer l'optimisation en utilisant la technique de mémorisation - en mettant en cache les résultats de la récursivité en mémoire afin de ne pas lire la même chose plusieurs fois. Mais, comme le montrent les tests ci-dessous, une forte augmentation de vitesse n'a pas été atteinte.Comment estimer le nombre de scènes?
Un groupe d'IBM a suggéré qu'étant donné que de nombreuses lignes de la matrice dépendent linéairement, le nombre de groupes carrés le long de la diagonale sera approximativement égal au rang de la matrice.Pour l'obtenir et en même temps filtrer le bruit, il faut une décomposition singulière de la matrice.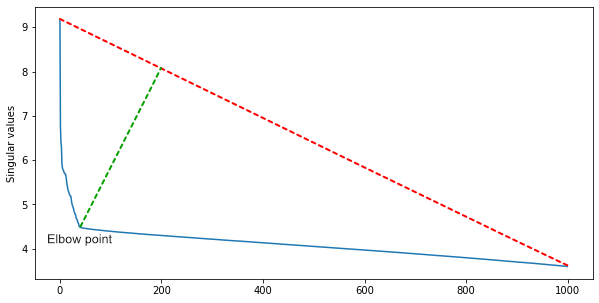 Parmi les valeurs singulières, triées par ordre décroissant, nous trouvons le point du coude - celui à partir duquel la diminution des valeurs décélère fortement. L'index du point du coude est le nombre approximatif de scènes dans un film.Pour une première approximation, cela suffit, mais vous pouvez compléter l'algorithme avec de l'heuristique pour différents genres de cinéma. Dans les films d'action, il y a plus de scènes et moins dans un essai.
Parmi les valeurs singulières, triées par ordre décroissant, nous trouvons le point du coude - celui à partir duquel la diminution des valeurs décélère fortement. L'index du point du coude est le nombre approximatif de scènes dans un film.Pour une première approximation, cela suffit, mais vous pouvez compléter l'algorithme avec de l'heuristique pour différents genres de cinéma. Dans les films d'action, il y a plus de scènes et moins dans un essai.Les tests
Nous voulions comprendre deux choses:- La différence de vitesse est-elle si dramatique?
- Combien de précision souffre-t-il lors de l'utilisation d'un algorithme plus rapide?
Les tests ont été divisés en deux groupes: les données synthétiques et réelles. Sur des tests synthétiques, la qualité et la vitesse des deux algorithmes ont été comparées, et sur des vrais, ils ont mesuré la qualité de l'algorithme le plus rapide. Des tests de vitesse ont été effectués sur le MacBook Pro 2017, Intel Core i5 2,3 GHz, LPDDR3 16 Go 2133 MHz.Tests de qualité synthétique
Nous avons généré 999 matrices de distances par paires dont la taille varie de 12 à 122 plans, les avons réparties au hasard en 2 à 10 scènes et ajouté un bruit normal par le dessus.Pour chaque matrice, les partitions optimales ont été trouvées en termes de et , puis compté les métriques de précision, de rappel, de F1 et d'IoU.Nous considérons la précision et le rappel pour l'intervalle en utilisant les formules suivantes:
Nous considérons F1 comme d'habitude, en substituant la précision et le rappel d'intervalle:
Pour comparer les segments prédits et vrais dans le film, pour chacun des prédits, nous trouvons le vrai segment avec la plus grande intersection et considérons la métrique pour cette paire.Voici les résultats: Optimisation des fonctions gagné dans toutes les métriques, comme dans les tests des auteurs de l'algorithme.
Optimisation des fonctions gagné dans toutes les métriques, comme dans les tests des auteurs de l'algorithme.Tests de vitesse synthétiques
Pour tester la vitesse, nous avons effectué d'autres tests synthétiques. La première est de savoir comment le temps d'exécution de l'algorithme dépend du nombre de prises de vue.avec un nombre fixe de scènes: le test a confirmé un bilan théorique: temps d'optimisation croît de façon polynomiale avec la croissance par rapport au temps linéaire à .Si vous fixez le nombre de prises de vue et augmenter progressivement le nombre de scènes , nous obtenons une image plus intéressante. Au début, le temps devrait s'accroître, mais ensuite il commence à chuter. Le fait est que le nombre de dénominateurs possibles (formule) que nous devons vérifier proportionnellement au nombre de façons dont nous pouvons briser segments sur . Il est calculé en utilisant la combinaison de par :
le test a confirmé un bilan théorique: temps d'optimisation croît de façon polynomiale avec la croissance par rapport au temps linéaire à .Si vous fixez le nombre de prises de vue et augmenter progressivement le nombre de scènes , nous obtenons une image plus intéressante. Au début, le temps devrait s'accroître, mais ensuite il commence à chuter. Le fait est que le nombre de dénominateurs possibles (formule) que nous devons vérifier proportionnellement au nombre de façons dont nous pouvons briser segments sur . Il est calculé en utilisant la combinaison de par :
Avec croissance le nombre de combinaisons augmente d'abord, puis diminue à l'approche . Cela semble être cool, mais le nombre de scènes sera rarement égal au nombre de plans et prendra toujours une valeur telle qu'il existe de nombreuses combinaisons. Dans les "Avengers" déjà mentionnés 2700 plans et 105 scènes. Nombre de combinaisons:
Cela semble être cool, mais le nombre de scènes sera rarement égal au nombre de plans et prendra toujours une valeur telle qu'il existe de nombreuses combinaisons. Dans les "Avengers" déjà mentionnés 2700 plans et 105 scènes. Nombre de combinaisons:
Pour être sûr que tout a été bien compris et non empêtré dans la notation des articles originaux, nous avons écrit une lettre à Daniel Rothman. Il a confirmé que très lent à optimiser et ne convient pas aux vidéos de plus de 10 minutes, et donne en pratique des résultats acceptables.Tests de données réelles
Nous avons donc choisi une métrique , qui, bien qu'un peu moins précis, fonctionne beaucoup plus rapidement. Nous avons maintenant besoin de métriques, à partir desquelles nous nous appuierons sur la recherche d'un meilleur algorithme.Pour le test, nous avons sélectionné 20 films de différents genres et années. Le balisage s'est fait en cinq étapes:- :
- , .
- . « ?»
- CV. — , .
- , « ».
Voilà à quoi ressemble le scribbler et l'écran de l'inspecteur: et c'est ainsi que les 300 premiers plans du film "Avengers: Infinity War" sont divisés en scènes. À gauche, les scènes réelles et à droite, celles prédites par l'algorithme:
et c'est ainsi que les 300 premiers plans du film "Avengers: Infinity War" sont divisés en scènes. À gauche, les scènes réelles et à droite, celles prédites par l'algorithme: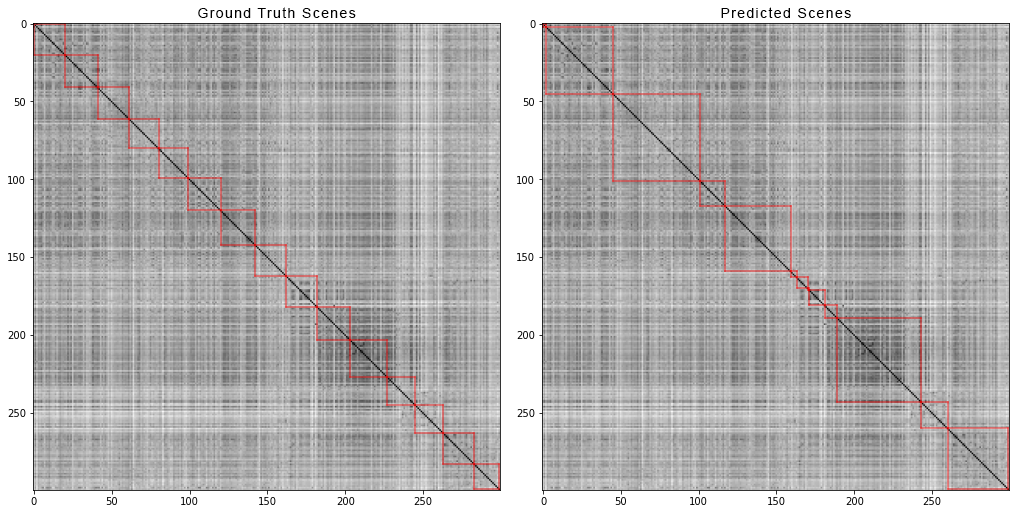 pour obtenir la matrice de distance par paire, nous avons fait ce qui suit:Pour chaque vidéo de l'ensemble de données, nous avons généré des matrices de distances par paires et, tout comme pour les données synthétiques, nous avons calculé quatre métriques. Voici les chiffres qui sont sortis:
pour obtenir la matrice de distance par paire, nous avons fait ce qui suit:Pour chaque vidéo de l'ensemble de données, nous avons généré des matrices de distances par paires et, tout comme pour les données synthétiques, nous avons calculé quatre métriques. Voici les chiffres qui sont sortis:- Précision : 0,4861919030708739
- Rappel : 0,8225937459424839
- F1 : 0,513676858711775
- IoU : 0,37560909807842874
Et alors?
Nous avons une ligne de base qui ne fonctionne pas parfaitement, mais maintenant vous pouvez la construire pendant que nous recherchons des méthodes plus précises.Certains des autres plans:- Essayez d'autres architectures CNN pour l'extraction de fonctionnalités.
- Essayez d'autres mesures de distance entre les prises de vue.
- Essayez d'autres méthodes d'optimisation , par exemple, les algorithmes génétiques.
- Essayez de réduire la décomposition de l'ensemble du film en parties distinctes sur lesquelles remplit dans un délai raisonnable, et comparer quelle sera la perte de qualité.
Le code des méthodes et des expériences sur les données synthétiques a été publié sur Github . Vous pouvez toucher et essayer de vous accélérer. Les likes et les demandes de pull sont les bienvenus.Salut tout le monde, à bientôt dans les prochains articles!