Dans les processeurs Intel x86 modernes, le pipeline peut être divisé en 2 parties: Front End et Back End.Front End est chargé de charger le code de la mémoire et de le décoder en micro-opérations.Le back-end est responsable de l'exécution des micro-opérations à partir du front-end. Étant donné que ces micro-opérations peuvent être effectuées par le noyau dans le désordre, le back-end garantit également que le résultat de ces micro-opérations correspond strictement à l'ordre dans lequel elles vont dans le code.Dans la plupart des cas, une utilisation inefficace de Front End'a n'a pas d'effet notable sur les performances. La bande passante maximale sur la plupart des processeurs Intel est de 4 micro-opérations par cycle, par conséquent, par exemple, pour un code lié à la mémoire / L3, le processeur ne pourra pas l'utiliser complètement.Pro relativement nouveau Ice Lake, Ice Lake 4 5 . , , .
Cependant, dans certains cas, la différence de performances peut être assez importante. Sous la coupe se trouve une analyse de l'impact du cache de micro-opération sur les performances.Le contenu de l'article
- Environnement
- Présentation des processeurs Intel Front End'a
- Cache µop de l'analyse de la bande passante maximale -> IDQ
- Exemple
Environnement
Pour toutes les mesures de cet article seront utilisées i7-8550U Kaby Lake, HT activé / Ubuntu 18.04/Linux Kernel 5.3.0-45-generic. Dans ce cas, un tel environnement peut être important, car chaque modèle de CPU a son propre événement de performance. En particulier, pour les microarchitectures plus anciennes que Sandy Bridge, certains des événements utilisés à l'avenir n'ont tout simplement aucun sens.Présentation des processeurs Intel Front End'a
L'organisation de la chaîne de montage de haut niveau est accessible au public et est publiée dans la documentation officielle d'Intel sur l'optimisation des logiciels . Une description plus détaillée de certaines des fonctionnalités qui sont omises de la documentation officielle peut être trouvée dans d'autres sources réputées, telles que Agner Fog ou Travis Downs . Ainsi, par exemple, le schéma de pipeline d'assemblage pour Skylake dans la documentation Intel ressemble à ceci: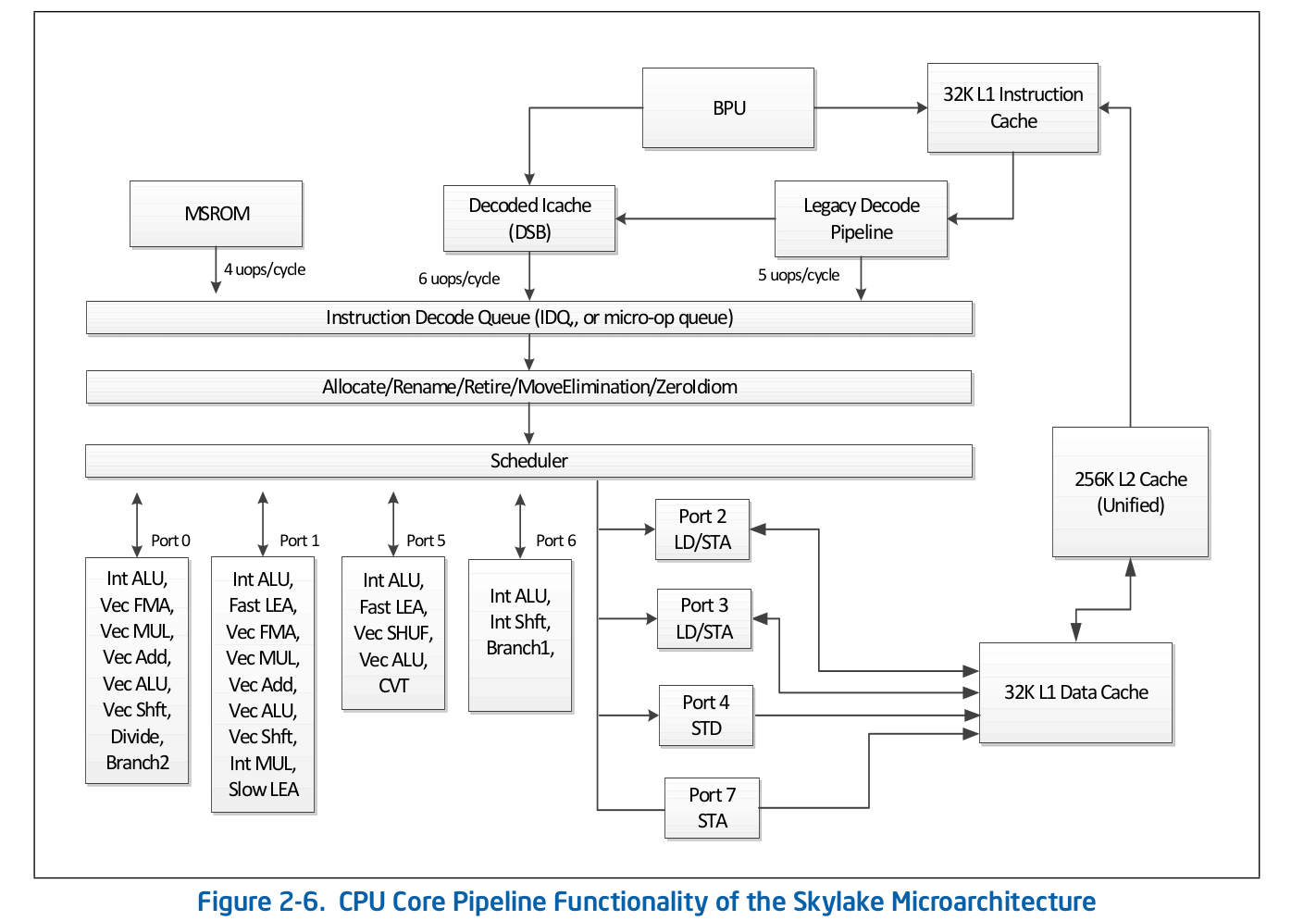 Examinons de plus près la partie supérieure de ce schéma - Front End.
Examinons de plus près la partie supérieure de ce schéma - Front End. Legacy Decode Pipeline est responsable du décodage du code dans les micro-opérations. Il se compose des éléments suivants:
Legacy Decode Pipeline est responsable du décodage du code dans les micro-opérations. Il se compose des éléments suivants:- Unité de récupération d'instructions - IFU
- Cache d'instructions de premier niveau - L1i
- Cache d'adresse de traduction du journal d'instructions - ITLB
- Préfecteur instructeur
- Instructions de pré-décodeur
- File d'attente d'instructions pré-décodées
- Décodeurs d'instructions pré-décodés à micro-opération
Considérez chacune des parties du pipeline de décodage hérité individuellement.Instruction Fetch Unit.Il est responsable du chargement du code, du précodage (détermination de la longueur de l'instruction et des propriétés telles que «si l'instruction est une branche») et de la livraison des instructions pré-décodées à la file d'attente.Cache d'instructions de premier niveau - L1iPour télécharger le code, l'IFU utilise L1i, le cache d'instructions de premier niveau, et L2 / LLC, le cache de deuxième niveau et le cache offcore de niveau supérieur, communs au code et aux données. Le téléchargement s'effectue en morceaux de 16 octets, également alignés sur 16 octets. Lorsque le code suivant de 16 octets est chargé dans l'ordre, un appel est effectué vers L1i et, si la ligne correspondante n'est pas trouvée, une recherche est effectuée dans L2 et, en cas d'échec, dans LLC et dans la mémoire. Avant Skylake LLC, le cache était inclusif - chaque ligne en L1 (i / d) et L2 devrait être contenue dans le LLC. Ainsi, LLC "connaissait" toutes les lignes de tous les cœurs et, dans le cas des erreurs LLC, on savait si les caches des autres cœurs contenaient la ligne requise à l'état modifié, ce qui signifie que cette ligne pouvait être chargée à partir d'un autre cœur. Skylake LLC est devenu un cache de victimes L2 non inclus, mais la taille L2 a été augmentée 4 fois. Je ne sais passi L2 est inclusif par rapport à L1i. L2non inclus en ce qui concerne L1d.Traduction d'adresses logiques d'instructions - ITLBAvant de télécharger des données depuis le cache, vous devez rechercher la ligne correspondante. Pour nles caches associatifs -way , chaque ligne peut se trouver à ndifférents endroits du cache lui-même. Pour déterminer les positions possibles dans le cache, un index est utilisé (généralement quelques bits inférieurs de l'adresse). Pour déterminer si la ligne correspond à l'adresse dont nous avons besoin, une balise est utilisée (le reste de l'adresse). Quelles adresses utiliser: physiques ou logiques - dépendent de la mise en œuvre du cache. L'utilisation d'adresses physiques nécessite une traduction d'adresse. Pour la traduction d'adresse, un tampon TLB est utilisé, qui met en cache les résultats des pages parcourues, réduisant ainsi le délai de réception d'une adresse physique à partir d'une adresse logique lors des appels suivants. Pour les instructions, il existe son propre tampon d'instructions TLB, situé séparément du Data TLB. Le noyau du processeur dispose également d'un TLB de deuxième niveau commun au code et aux données - STLB. Je ne sais pas si STLB est inclusif (selon la rumeur, il ne s'agit pas d'un cache de victime inclusif par rapport à D / I TLB). Utilisation des instructions de prélecture du logicielprefetcht1vous pouvez remonter la ligne avec le code en L2, cependant, l'enregistrement TLB correspondant ne sera tiré qu'en DTLB. Si STLB n'est pas inclusif, alors lorsque vous recherchez cette ligne avec le code dans les caches, vous obtiendrez ITLB miss -> STLB miss -> page walk (en fait, ce n'est pas si simple, car le noyau peut initier une page promenade spéculative avant qu'elle ne se produise) TLB miss). La documentation d'Intel décourage également l'utilisation des préfixes SW pour le code, Intel Software Optimization Manual / 2.5.5.4:La prélecture contrôlée par logiciel est destinée à la prélecture des données, mais pas à la prélecture du code.
Cependant, Travis D. a mentionné qu'une telle prélecture peut être très efficace (et probablement elle l'est), mais jusqu'à présent, cela n'est pas évident pour moi et pour en être convaincu, je devrai examiner séparément cette question.Préfecteur instructeurLe chargement des données dans le cache (L1d / i, L2, etc.) se produit lors de l'accès à un emplacement de mémoire non mis en cache. Cependant, si cela ne se produisait que dans de telles conditions, il en résulterait une utilisation inefficace de la bande passante du cache. Par exemple, sur Sandy Bridge pour L1d - 2 opérations de lecture, 1 écriture de 16 octets par cycle; pour L1i - 1 opération de lecture de 16 octets, le débit d'écriture n'est pas spécifié dans la documentation, Agner Fog est également introuvable. Pour résoudre ce problème, il existe des prérécupérateurs matériels qui peuvent déterminer le modèle d'accès à la mémoire et tirer les lignes nécessaires dans le cache avant que le code ne les adresse réellement. La documentation Intel définit 4 prefetchers: 2 pour L1d, 2 pour L2:- L1 DCU - Préfixe les lignes de cache série. Lecture seule en avant
- L1 IP — (. 0x5555555545a0, 0x5555555545b0, 0x5555555545c0, ...), , ,
- L2 Spatial — L2 -, 128-. LLC
- L2 Streamer — . L1 DCU «». LLC
La documentation Intel ne décrit pas le principe du préfecteur L1i. Tout ce que l'on sait, c'est que la Branch Prediction Unit (BPU) est impliquée dans ce processus, Intel Software Optimization Manual / 2.6.2: Agner Fog ne voit pas non plus de détails.La prélecture de code dans L2 / LLC est explicitement définie uniquement pour Streamer. Manuel d'optimisation / 2.5.5.4 Préfection des données:
Agner Fog ne voit pas non plus de détails.La prélecture de code dans L2 / LLC est explicitement définie uniquement pour Streamer. Manuel d'optimisation / 2.5.5.4 Préfection des données:Streamer : ce préfetcher surveille les demandes de lecture du cache L1 pour les séquences d'adresses ascendantes et descendantes. Les demandes de lecture surveillées comprennent les demandes Lache DCache lancées par les opérations de chargement et de stockage et par les pré-récupérateurs matériels, et les demandes L1 ICache pour l'extraction de code.
Pour le préfet spatial, ce n'est clairement pas précisé:Prefetcher spatial: ce prefetcher s'efforce de terminer chaque ligne de cache récupérée dans le cache L2 avec la ligne de paire qui le complète en un bloc aligné de 128 octets.
Mais cela peut être vérifié. Chacun de ces prefetchers peut être désactivé à l'aide de MSR 0x1A4, comme décrit dans le manuel Model-Specific Registers.À propos de MSR 0x1A4MSR L2 Spatial L1i. . , LLC. L2 Streamer 2.5 .
Linux msr , msr . $ sudo wrmsr -p 1 0x1a4 1 L2 Streamer 1.
Instructions de pré-décodeur Unefois le code de 16 octets suivant chargé, ils tombent dans les instructions de pré-décodeur. Sa tâche est de déterminer la longueur de l'instruction, de décoder les préfixes et de marquer si l'instruction correspondante est une branche (très probablement, il existe encore de nombreuses propriétés différentes, mais la documentation les concernant est silencieuse). Manuel d'optimisation des logiciels Intel / 2.6.2.2:The predecode unit accepts the sixteen bytes from the instruction cache or prefetch buffers and carries out the following tasks:
- Determine the length of the instructions
- Decode all prefixes associated with instructions
- Mark various properties of instructions for the decoders (for example, “is branch.”)
Une ligne d'instructions pré-décodées.Depuis l'IFU, les instructions sont ajoutées à la file d'attente d'instructions pré-encodée. Cette file d'attente est apparue depuis Nehalem, conformément à la documentation Intel, sa taille est de 18 instructions. Agner Fog mentionne également que cette file d'attente ne contient pas plus de 64 octets.Toujours dans Core2, cette file d'attente a été utilisée comme cache de boucle. Si toutes les micro-opérations du cycle sont dans la file d'attente, dans certains cas, le coût du chargement et du précodage pourrait être évité. Le détecteur de flux en boucle (LSD) peut fournir des instructions qui sont déjà dans la file d'attente jusqu'à ce que le BPU signale la fin du cycle. Agner Fog a un certain nombre de notes intéressantes concernant le LSD sur Core2:- Composé de 4 lignes de 16 octets
- Débit maximal jusqu'à 32 octets de code par cycle
À partir de Sandy Bridge, ce cache de boucle est passé de la file d'attente d'instructions pré-décodée à IDQ.Décodeurs d'instructions pré-décodées en micro-opération Apartir de la file d'attente d'instructions pré-décodées, le code est envoyé au décodage en micro-opération. Les décodeurs sont responsables du décodage - il y en a au total 4. Selon la documentation d'Intel, l'un des décodeurs peut décoder des instructions composées de 4 micro-opérations ou moins. Le reste décode les instructions consistant en une micro-opération (micro / macro fusionnée), Intel Software Optimization Manual / 2.5.2.1:There are four decoding units that decode instruction into micro-ops. The first can decode all IA-32 and Intel 64 instructions up to four micro-ops in size. The remaining three decoding units handle single-micro-op instructions. All four decoding units support the common cases of single micro-op flows including micro-fusion and macro-fusion.
Les instructions décodées dans un grand nombre de micro-opérations (par exemple rep movsb, utilisées dans l'implémentation de memcpy dans libc sur certaines tailles de mémoire copiée) proviennent de Microcode Sequencer (MS ROM). La bande passante maximale du séquenceur est de 4 micro-opérations par cycle.Comme vous pouvez le voir sur le diagramme de la chaîne de montage, le pipeline de décodage hérité peut décoder jusqu'à 5 micro-opérations par cycle sur Skylake. Sur Broadwell et les anciens, le débit de pointe du Legacy Decode Pipeline était de 4 micro-opérations par cycle.Cache de micro-opérationUne fois les instructions décodées dans des micro-opérations, à partir du pipeline de décodage hérité, elles tombent dans la file d'attente de micro-opération spéciale - Instruction Decode Queue (IDQ), ainsi que dans le soi-disant cache de micro-opération (Decoded ICache, cache µop). Le cache de micro-opération a été initialement introduit dans Sandy Bridge et est utilisé pour éviter la récupération et le décodage des instructions dans les micro-opérations, augmentant ainsi le débit de livraison des micro-opérations en IDQ - jusqu'à 6 par cycle. Après être entré dans IDQ, les micro-opérations vont au back-end pour exécution avec un débit de pointe de 4 micro-opérations par cycle.Selon la documentation d'Intel, le cache de micro-opération se compose de 32 ensembles, chaque ensemble contient 8 lignes, chaque ligne peut mettre en cache jusqu'à 6 micro opérations (micro / macro fusionnées), permettant un cache total jusqu'à 32 * 8 * 6 = 1536 micro opérations . La mise en cache de la micro-opération se produit avec une granularité de 32 octets, c'est-à-dire les micro-opérations qui suivent les instructions de différentes régions de 32 octets ne peuvent pas tomber sur une seule ligne. Cependant, jusqu'à 3 lignes de cache différentes peuvent correspondre à une région de 32 octets. Ainsi, jusqu'à 18 micro-opérations dans le cache µop peuvent correspondre à chaque région de 32 octets.Manuel d'optimisation des logiciels Intel / 2.5.5.2The Decoded ICache consists of 32 sets. Each set contains eight Ways. Each Way can hold up to six micro-ops. The Decoded ICache can ideally hold up to 1536 micro-ops. The following are some of the rules how the Decoded ICache is filled with micro-ops:
- ll micro-ops in a Way represent instructions which are statically contiguous in the code and have their EIPs within the same aligned 32-byte region.
- Up to three Ways may be dedicated to the same 32-byte aligned chunk, allowing a total of 18 micro-ops to be cached per 32-byte region of the original IA program.
- A multi micro-op instruction cannot be split across Ways.
- Up to two branches are allowed per Way.
- An instruction which turns on the MSROM consumes an entire Way.
- A non-conditional branch is the last micro-op in a Way.
- Micro-fused micro-ops (load+op and stores) are kept as one micro-op.
- A pair of macro-fused instructions is kept as one micro-op.
- Instructions with 64-bit immediate require two slots to hold the immediate.
Agner Fog mentionne également qu'une seule ligne de micro-opérations peut être téléchargée par cycle (non explicitement indiqué dans la documentation Intel, bien qu'il puisse être facilement vérifié manuellement).µop cache --> IDQ
Dans certains cas, il est très pratique d'utiliser nopdes longueurs d'un octet pour étudier le comportement de Front End . Dans le même temps, nous pouvons être sûrs que nous enquêtons sur le frontal, et non sur le blocage des ressources sur le back-end, pour une raison quelconque. Le fait est que nop, ainsi que d'autres instructions, ils sont décodés dans le pipeline de décodage hérité, mélangés dans le cache µop et envoyés à IDQ. En outre nop, ainsi que d'autres instructions, reprend la fin. La différence significative est que des ressources sur le back-end, il noputilise uniquement le tampon de réorganisation et ne nécessite pas de slot dans la station de réservation (alias Scheduler). Ainsi, immédiatement après avoir entré Reorder Buffer, il est nopprêt pour la retraite, qui sera effectuée conformément à l'ordre dans le code de programme.Pour tester le débit, déclarez une fonctionvoid test_decoded_icache(size_t iteration_count);
avec mise en œuvre sur nasm:align 32
test_decoded_icache:
;nop', 0 23
dec rdi
ja test_decoded_icache
ret
jaIl n'a pas été choisi par hasard. jaet decutiliser différents drapeaux - jalit à partir CFet ZF, decpas d' enregistrement dans les FC, si Macro Fusion ne s'applique pas. Cela se fait uniquement pour la commodité du comptage des micro-opérations dans un cycle - chaque instruction correspond à une micro-opération.Pour les mesures, nous avons besoin des événements de perf suivants:1. uops_issued.any- Utilisé pour compter les micro-opérations que Renamer prend d'IDQ.Le Guide de programmation système Intel documente cet événement comme le nombre de micro-opérations que Renamer place dans la station de réservation:Compte le nombre d'uops que la table d'allocation de ressources (RAT) envoie à la station de réservation (RS).
Cette description n'est pas complètement en corrélation avec les valeurs qui peuvent être obtenues à partir d'expériences. En particulier, ils noptombent dans ce comptoir, même si c'est un fait qu'ils ne sont pas du tout nécessaires à la station de réservation.2. uops_retired.retire_slots- le nombre total de micro-opérations retirées en tenant compte de la micro / macro-fusion3. uops_retired.stall_cycles- le nombre de ticks pour lesquels il n'y a pas eu une seule micro-opération retirée4. resource_stalls.any- le nombre de ticks de convoyeur inactif en raison de l'inaccessibilité de l'une des ressources Back EndIn Intel Software Optimization Manual / B .4.1 il existe un diagramme de contenu qui caractérise les événements décrits ci-dessus: 5.
5. idq.all_dsb_cycles_4_uops- le nombre de cycles d'horloge pour lesquels 4 (ou plus) instructions ont été fournies par le cache µop.Le fait que cette métrique prenne en compte la livraison de plus de 4 micro-opérations par cycle n'est pas décrit dans la documentation d'Intel, mais elle est très bien en accord avec les expériences.6. idq.all_dsb_cycles_any_uops- le nombre de mesures pour lesquelles au moins une micro-opération a été réalisée.7. idq.dsb_cycles- Le nombre total de ticks auxquels la livraison a été effectuée à partir du cache µop8. idq_uops_not_delivered.cycles_le_N_uop_deliv.core- Le nombre de ticks pour lesquels Renamer a effectué une Nou plusieurs micro-opérations et il n'y a eu aucun temps d'arrêt du côté arrière , N- 1, 2, 3.Nous prenons pour la recherche iteration_count = 1 << 31. Nous commençons l'analyse de ce qui se passe dans le CPU en examinant le nombre de micro-opérations et, tout d'abord, en mesurant la bande passante de retrait moyenne, c'est-à-dire uops_retired.retire_slots/uops_retired.total_cycle: Ce qui attire immédiatement votre attention, c'est l'affaissement du débit de retraite à une taille de cycle de 7 micro-opérations. Afin de comprendre quel est le problème, examinons comment la vitesse de livraison moyenne du cache µop - change
Ce qui attire immédiatement votre attention, c'est l'affaissement du débit de retraite à une taille de cycle de 7 micro-opérations. Afin de comprendre quel est le problème, examinons comment la vitesse de livraison moyenne du cache µop - change idq.all_dsb_cycles_any_uops / idq.dsb_cycles: et comment le nombre total de mesures et de mesures pour lesquelles le cache µop livré à IDQ est lié:
et comment le nombre total de mesures et de mesures pour lesquelles le cache µop livré à IDQ est lié: Ainsi, nous pouvons voir qu'avec un cycle de 6 micro-opérations, nous obtenons une efficacité Utilisation de la bande passante du cache µop - 6 micro-opérations par cycle. En raison du fait que Renamer ne peut pas prendre autant que le cache µop fournit, une partie des cycles de cache µop ne fournit rien, ce qui est clairement visible dans le graphique précédent.Avec un cycle de 7 micro-opérations, nous obtenons une forte baisse du débit du cache µop - 3,5 micro-opérations par cycle. Dans le même temps, comme le montre le graphique précédent, le cache µop est constamment en fonctionnement. Ainsi, avec un cycle de 7 micro-opérations, nous obtenons une utilisation inefficace du cache µop de bande passante. Le fait est que, comme indiqué précédemment, le cache µop par cycle peut fournir des micro-opérations à partir d'une seule ligne. En cas de micro-opérations 7 - les 6 premiers tombent sur une ligne, et le 7ème restant - sur une autre. De cette façon, nous obtenons 7 micro-opérations par 2 cycles, ou 3,5 micro-opérations par cycle.Voyons maintenant comment Renamer prend les micro-opérations d'IDQ. Pour cela, nous avons besoin
Ainsi, nous pouvons voir qu'avec un cycle de 6 micro-opérations, nous obtenons une efficacité Utilisation de la bande passante du cache µop - 6 micro-opérations par cycle. En raison du fait que Renamer ne peut pas prendre autant que le cache µop fournit, une partie des cycles de cache µop ne fournit rien, ce qui est clairement visible dans le graphique précédent.Avec un cycle de 7 micro-opérations, nous obtenons une forte baisse du débit du cache µop - 3,5 micro-opérations par cycle. Dans le même temps, comme le montre le graphique précédent, le cache µop est constamment en fonctionnement. Ainsi, avec un cycle de 7 micro-opérations, nous obtenons une utilisation inefficace du cache µop de bande passante. Le fait est que, comme indiqué précédemment, le cache µop par cycle peut fournir des micro-opérations à partir d'une seule ligne. En cas de micro-opérations 7 - les 6 premiers tombent sur une ligne, et le 7ème restant - sur une autre. De cette façon, nous obtenons 7 micro-opérations par 2 cycles, ou 3,5 micro-opérations par cycle.Voyons maintenant comment Renamer prend les micro-opérations d'IDQ. Pour cela, nous avons besoin idq_uops_not_delivered.coreet idq_uops_not_delivered.cycles_le_N_uop_deliv.core: Vous pouvez remarquer qu'avec 7 micro-opérations, seules 3 micro-opérations à la fois prennent la moitié des cycles de Renamer. De là, nous obtenons un débit de retraite d'une moyenne de 3,5 micro-opérations par cycle.Un autre point intéressant lié à cet exemple peut être vu si l'on considère le débit effectif de la retraite. Ceux. ne considérant pas
Vous pouvez remarquer qu'avec 7 micro-opérations, seules 3 micro-opérations à la fois prennent la moitié des cycles de Renamer. De là, nous obtenons un débit de retraite d'une moyenne de 3,5 micro-opérations par cycle.Un autre point intéressant lié à cet exemple peut être vu si l'on considère le débit effectif de la retraite. Ceux. ne considérant pas uops_retired.stall_cycles: On peut noter qu'avec 7 micro-opérations, toutes les 7 mesures, la retraite de 4 micro-opérations est effectuée, et chaque 8ème mesure est inactive sans micro-opérations retirées (décrochage de la retraite). Après avoir mené une série d'expériences, il a été possible de constater qu'un tel comportement était toujours observé pendant 7 microopérations, quelle que soit leur disposition 1-6, 6-1, 2-5, 5-2, 3-4, 4-3. Je ne sais pas pourquoi c'est exactement le cas, et pas, par exemple, la mise hors service de 3 micro-opérations est effectuée dans un cycle d'horloge, et 4 dans le suivant. Agner Fog mentionne que les transitions entre succursales ne peuvent utiliser qu'une partie des créneaux des postes de retraite. Peut - être que cette restriction est la raison de ce comportement de retraite.
On peut noter qu'avec 7 micro-opérations, toutes les 7 mesures, la retraite de 4 micro-opérations est effectuée, et chaque 8ème mesure est inactive sans micro-opérations retirées (décrochage de la retraite). Après avoir mené une série d'expériences, il a été possible de constater qu'un tel comportement était toujours observé pendant 7 microopérations, quelle que soit leur disposition 1-6, 6-1, 2-5, 5-2, 3-4, 4-3. Je ne sais pas pourquoi c'est exactement le cas, et pas, par exemple, la mise hors service de 3 micro-opérations est effectuée dans un cycle d'horloge, et 4 dans le suivant. Agner Fog mentionne que les transitions entre succursales ne peuvent utiliser qu'une partie des créneaux des postes de retraite. Peut - être que cette restriction est la raison de ce comportement de retraite.Exemple
Afin de comprendre si tout cela a un effet dans la pratique, considérons l'exemple légèrement plus pratique suivant qu'avec nops:Deux tableaux sont donnés unsigned. Il est nécessaire d'accumuler la somme des moyennes arithmétiques pour chaque index et de l'écrire dans le troisième tableau.Un exemple d'implémentation pourrait ressembler à ceci:
static unsigned arr1[] = { ... };
static unsigned arr2[] = { ... };
static void arithmetic_mean(unsigned *arr1, unsigned *arr2, unsigned *out, size_t sz){
unsigned sum = 0;
size_t idx = 0;
while(idx < sz){
sum += (arr1[idx] + arr2[idx]) >> 1;
out[idx] = sum;
idx++;
}
__asm__ __volatile__("" ::: "memory");
}
int main(void){
unsigned out[sizeof arr1 / sizeof(unsigned)];
for(size_t i = 0; i < 4096 * 4096; i++){
arithmetic_mean(arr1, arr2, out, sizeof arr1 / sizeof(unsigned));
}
}
Compiler avec des drapeaux gcc-Werror
-Wextra
-Wall
-pedantic
-Wno-stack-protector
-g3
-O3
-Wno-unused-result
-Wno-unused-parameter
Il est bien évident que la fonction arithmetic_meanne sera pas présente dans le code et sera insérée directement dans main:(gdb) disas main
Dump of assembler code for function main:
#...
0x00000000000005dc <+60>: nop DWORD PTR [rax+0x0]
0x00000000000005e0 <+64>: mov edx,DWORD PTR [rdi+rax*4]
0x00000000000005e3 <+67>: add edx,DWORD PTR [r8+rax*4]
0x00000000000005e7 <+71>: shr edx,1
0x00000000000005e9 <+73>: add ecx,edx
0x00000000000005eb <+75>: mov DWORD PTR [rsi+rax*4],ecx
0x00000000000005ee <+78>: add rax,0x1
0x00000000000005f2 <+82>: cmp rax,0x80
0x00000000000005f8 <+88>: jne 0x5e0 <main+64>
0x00000000000005fa <+90>: sub r9,0x1
0x00000000000005fe <+94>: jne 0x5d8 <main+56>
#...
Notez que le compilateur a aligné le code de la boucle sur 32 octets ( nop DWORD PTR [rax+0x0]), ce qui est exactement ce dont nous avons besoin. Après s'être assuré qu'il n'y a pas de resource_stalls.anyBack End (toutes les mesures sont effectuées en tenant compte du cache L1d chauffé), nous pouvons commencer à considérer les compteurs associés à la livraison à IDQ: Performance counter stats for './test_decoded_icache':
2 273 343 251 idq.all_dsb_cycles_4_uops (15,94%)
4 458 322 025 idq.all_dsb_cycles_any_uops (16,26%)
15 473 065 238 idq.dsb_uops (16,59%)
4 358 690 532 idq.dsb_cycles (16,91%)
2 528 373 243 idq_uops_not_delivered.core (16,93%)
73 728 040 idq_uops_not_delivered.cycles_0_uops_deliv.core (16,93%)
107 262 304 idq_uops_not_delivered.cycles_le_1_uop_deliv.core (16,93%)
108 454 043 idq_uops_not_delivered.cycles_le_2_uop_deliv.core (16,65%)
2 248 557 762 idq_uops_not_delivered.cycles_le_3_uop_deliv.core (16,32%)
2 385 493 805 idq_uops_not_delivered.cycles_fe_was_ok (16,00%)
15 147 004 678 uops_retired.retire_slots
4 724 790 623 uops_retired.total_cycles
1,228684264 seconds time elapsed
Notez que la mauvaise largeur de retrait dans ce cas = 15147004678/4724790623 = 3.20585733562, et aussi que seulement 3 micro-opérations prennent la moitié des horloges de Renamer.Ajoutez maintenant la promotion de boucle manuelle à l'implémentation:static void arithmetic_mean(unsigned *arr1, unsigned *arr2, unsigned *out, size_t sz){
unsigned sum = 0;
size_t idx = 0;
if(sz & 2){
sum += (arr1[idx] + arr2[idx]) >> 1;
out[idx] = sum;
idx++;
}
while(idx < sz){
sum += (arr1[idx] + arr2[idx]) >> 1;
out[idx] = sum;
idx++;
sum += (arr1[idx] + arr2[idx]) >> 1;
out[idx] = sum;
idx++;
}
__asm__ __volatile__("" ::: "memory");
}
Les compteurs de perf résultants ressemblent à:Performance counter stats for './test_decoded_icache':
2 152 818 549 idq.all_dsb_cycles_4_uops (14,79%)
3 207 203 856 idq.all_dsb_cycles_any_uops (15,25%)
12 855 932 240 idq.dsb_uops (15,70%)
3 184 814 613 idq.dsb_cycles (16,15%)
24 946 367 idq_uops_not_delivered.core (16,24%)
3 011 119 idq_uops_not_delivered.cycles_0_uops_deliv.core (16,24%)
5 239 222 idq_uops_not_delivered.cycles_le_1_uop_deliv.core (16,24%)
7 373 563 idq_uops_not_delivered.cycles_le_2_uop_deliv.core (16,24%)
7 837 764 idq_uops_not_delivered.cycles_le_3_uop_deliv.core (16,24%)
3 418 529 799 idq_uops_not_delivered.cycles_fe_was_ok (16,24%)
3 444 833 440 uops_retired.total_cycles (18,18%)
13 037 919 196 uops_retired.retire_slots (18,17%)
0,871040207 seconds time elapsed
Dans ce cas, nous avons une bande passante de retrait = 13037919196/3444833440 = 3,78477491672, ainsi qu'une utilisation efficace de la bande passante Renamer.Ainsi, non seulement nous nous sommes débarrassés d'une opération de branchement et d'un incrément dans un cycle, mais nous avons également augmenté la bande passante de retrait en utilisant efficacement le débit du cache de micro-opération, ce qui a donné une augmentation totale de 28% des performances.Notez que seule une réduction dans une opération de branchement et d'incrémentation donne une augmentation moyenne des performances de 9%.Petite remarque
Sur le CPU qui a été utilisé pour effectuer ces expériences, le LSD est désactivé. Il semble que le LSD pourrait gérer une telle situation. Pour les processeurs avec LSD activé, ces cas devront être examinés séparément.