J'ai récemment expliqué comment utiliser les recettes standard pour augmenter les performances des requêtes SQL «lues» à partir d'une base de données PostgreSQL. Aujourd'hui, nous allons parler de la façon dont vous pouvez rendre l'enregistrement dans la base de données plus efficace sans utiliser de «rebondissements» dans la configuration - simplement en organisant correctement les flux de données.#1. Partitionnement
Un article sur comment et pourquoi cela vaut la peine d'organiser le partitionnement appliqué «en théorie» a déjà été publié, nous nous concentrerons ici sur la pratique de l'utilisation de certaines approches dans le cadre de notre service de surveillance pour des centaines de serveurs PostgreSQL ."Des cas d'autrefois ..."
Initialement, comme tout MVP, notre projet a démarré sous une charge assez faible - la surveillance n'a été effectuée que pour les dix serveurs les plus critiques, toutes les tables étaient relativement compactes ... l'une des tables avec une taille de 1,5 To , nous avons réalisé que bien qu'il soit possible de vivre comme ça, c'est très gênant.Les temps étaient presque épiques, différentes variantes de PostgreSQL 9.x étaient pertinentes, donc toutes les partitions devaient être effectuées «manuellement» - via l' héritage de table et les déclencheurs de routage dynamique EXECUTE.La solution résultante s'est avérée suffisamment universelle pour pouvoir la traduire dans toutes les tables:PG10:
Mais le partitionnement par héritage n'a pas été historiquement bien adapté pour travailler avec un flux d'écriture actif ou un grand nombre de sections enfants. Par exemple, vous vous souvenez peut-être que l'algorithme de sélection de la section souhaitée avait une complexité quadratique , qu'il fonctionne avec plus de 100 sections, vous comprenez comment ...Dans PG10, cette situation a été grandement optimisée en implémentant la prise en charge du partitionnement natif . Par conséquent, nous avons immédiatement essayé de l'appliquer immédiatement après la migration du stockage, mais ...Comme il s'est avéré après avoir déterré le manuel, la table nativement partitionnée dans cette version:- ne prend pas en charge la description des index
- ne prend pas en charge les déclencheurs
- ne peut être lui-même un "descendant"
- ne supporte pas
INSERT ... ON CONFLICT - ne peut pas générer automatiquement la section
Se faisant péniblement un râteau sur le front, nous nous sommes rendu compte que nous ne pouvions pas nous passer de modifier l'application, et avons reporté la recherche pour six mois.PG10: deuxième chance
Nous avons donc commencé à résoudre les problèmes tour à tour:- Comme les déclencheurs
ON CONFLICTse sont avérés nécessaires à certains endroits, nous avons créé une table proxy intermédiaire pour les résoudre . - Nous nous sommes débarrassés du «routage» dans les déclencheurs - c'est-à-dire de
EXECUTE. - Ils ont sorti une table de modèle séparée avec tous les indices afin qu'ils ne soient même pas présents sur la table proxy.
Enfin, après tout cela, la table principale a déjà été partitionnée nativement. La création d'une nouvelle section est restée dans la conscience de l'application.Dictionnaires «sciage»
Comme dans tout système analytique, nous avions également des «faits» et des «coupures» (dictionnaires). Dans notre cas, à ce titre se trouvaient, par exemple, le corps du «modèle» du même type de requêtes lentes ou le texte de la requête elle-même.Nos "faits" ont été longtemps cloisonnés par jours, nous avons donc calmement supprimé les sections obsolètes, et cela ne nous a pas dérangés (logs!). Mais avec les dictionnaires, le problèmes'est avéré ... Pour ne pas dire qu'il y en avait beaucoup, mais environ 100 To de "faits" se sont avérés être un dictionnaire pour 2,5 To . Vous ne pouvez pas supprimer facilement quoi que ce soit d'une telle table, vous ne la presserez pas en temps voulu et l'écriture y deviendra progressivement plus lente.Cela ressemble à un dictionnaire ... chaque entrée doit être présentée exactement une fois ... et c'est vrai, mais! .. Personne ne nous dérange d'avoir un dictionnaire séparé pour chaque jour ! Oui, cela apporte une certaine redondance, mais cela vous permet de:- écriture / lecture plus rapide en raison de la plus petite taille de section
- consommer moins de mémoire en travaillant avec des index plus compacts
- stocker moins de données en raison de la possibilité de supprimer rapidement obsolète
À la suite de l'ensemble complexe de mesures , la charge du processeur a diminué de ~ 30% et du disque - de ~ 50% :Dans le même temps, nous avons continué à écrire exactement la même chose dans la base de données, juste avec moins de charge.# 2 Evolution et refactoring des bases de données
Nous avons donc décidé que pour chaque jour, nous avons notre propre section avec des données. En fait, CHECK (dt = '2018-10-12'::date)c'est la clé de partitionnement et la condition pour que l'enregistrement tombe dans une section particulière.Étant donné que tous les rapports de notre service sont construits dans le contexte d'une date spécifique, les indices des «heures non partitionnées» pour eux étaient de tous types (serveur, date , modèle de plan) , (serveur, date , nœud de plan) , ( date , classe d'erreur, Server) , ...Mais maintenant, chaque section a ses propres instances de chacun de ces index ... Et dans chaque section, la date est constante ... Il s'avère que maintenant nous sommes dans chacun de ces indexnous entrons trivialement une constante comme l'un des champs, ce qui augmente à la fois son volume et le temps de recherche, mais n'apporte aucun résultat. Eux-mêmes ont laissé un râteau, oups ...Le sens de l'optimisation est évident - il suffit de supprimer le champ date de tous les index des tables partitionnées. Avec nos volumes, le gain est d'environ 1 To / semaine !Et maintenant, notons que ce téraoctet devait encore être écrit d'une manière ou d'une autre. Autrement dit, nous devons également charger moins de disque maintenant ! Sur cette photo, l'effet obtenu du nettoyage, auquel nous avons consacré une semaine, est clairement visible: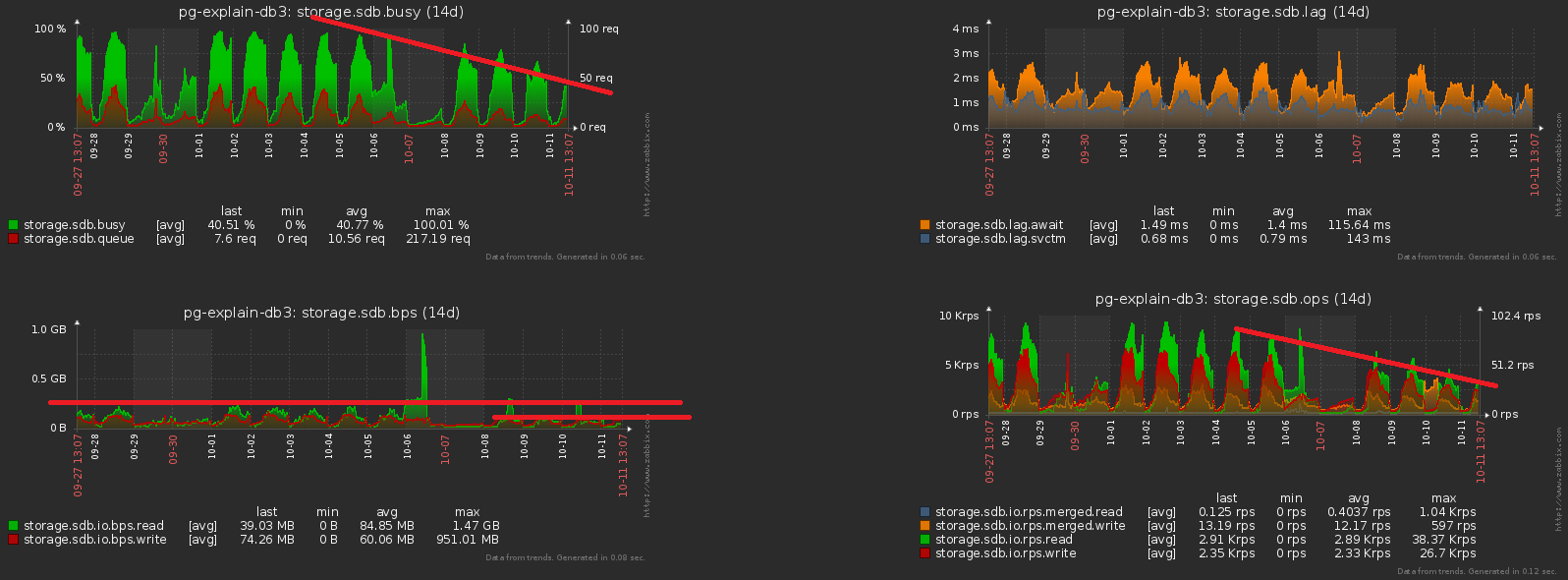
# 3 «Enduire» la charge de pointe
L'un des gros problèmes des systèmes chargés est la synchronisation excessive de certaines opérations qui ne le nécessitent pas. Parfois «parce qu’ils n’ont pas remarqué», parfois «c’était plus facile», mais tôt ou tard vous devez vous en débarrasser.Nous rapprochons l'image précédente - et nous voyons que le disque "tremble" avec une charge avec une double amplitude entre des échantillons adjacents, ce qui ne devrait évidemment pas être "statistiquement" avec autant d'opérations: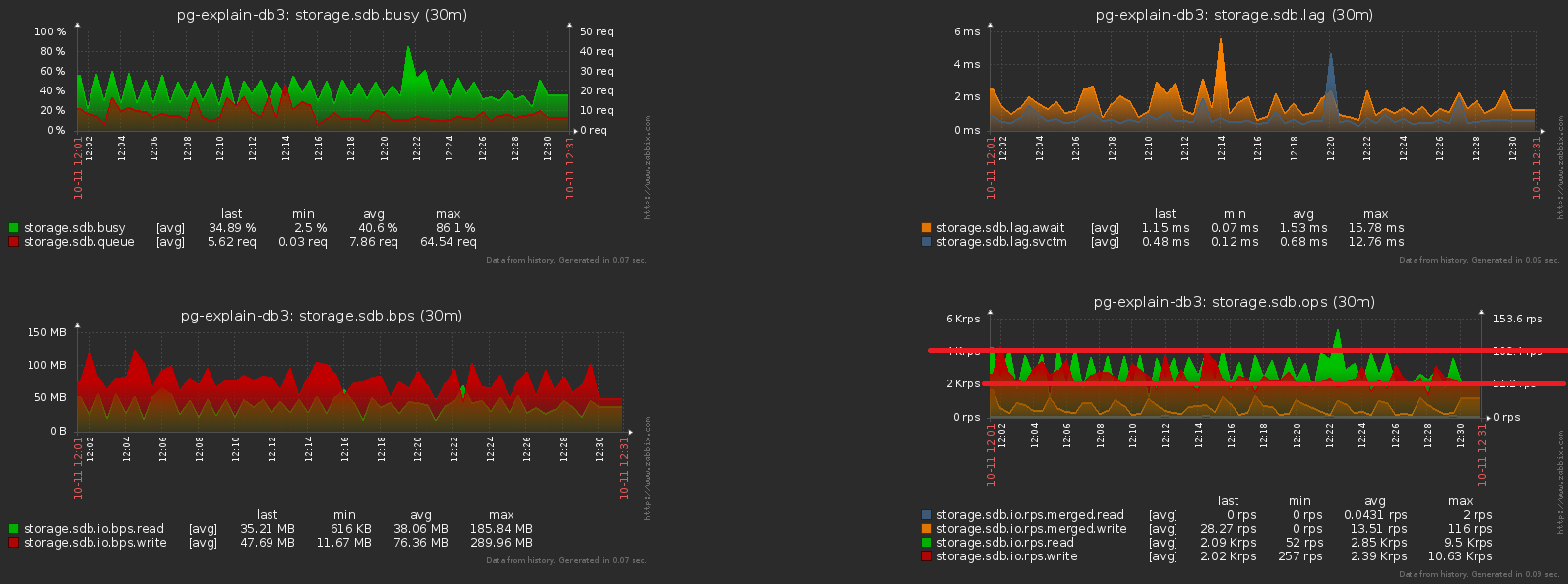 Pour y parvenir, c'est assez simple. Près de 1000 serveurs ont déjà été démarrés pour la surveillance , chacun est traité par un flux logique distinct, et chaque flux vide les informations accumulées pour les envoyer à la base de données avec une certaine fréquence, quelque chose comme ceci:
Pour y parvenir, c'est assez simple. Près de 1000 serveurs ont déjà été démarrés pour la surveillance , chacun est traité par un flux logique distinct, et chaque flux vide les informations accumulées pour les envoyer à la base de données avec une certaine fréquence, quelque chose comme ceci:setInterval(sendToDB, interval)
Le problème ici réside précisément dans le fait que tous les threads commencent à peu près au même moment , de sorte que les heures d'envoi pour eux coïncident presque toujours «au point». Oups n ° 2 ...Heureusement, cela se corrige assez facilement en ajoutant un laps de temps "aléatoire" :setInterval(sendToDB, interval * (1 + 0.1 * (Math.random() - 0.5)))
# 4. La mise en cache, ce besoin peut être
Le troisième problème traditionnel de surcharge élevée est le manque de cache là où il pourrait se trouver.Par exemple, nous avons permis d'analyser la répartition des nœuds du plan (tous ces éléments Seq Scan on users), mais avons immédiatement oublié qu'ils, dans l'ensemble, sont les mêmes, ont oublié.Non, bien sûr, rien n'est écrit dans la base de données à plusieurs reprises, ce qui coupe le déclencheur avec INSERT ... ON CONFLICT DO NOTHING. Mais les données n'atteignent pas la base de toute façon, et vous devez faire une lecture supplémentaire pour vérifier le conflit . Oups n ° 3 ...La différence dans le nombre d'enregistrements envoyés à la base de données avant / après l'activation de la mise en cache est évidente: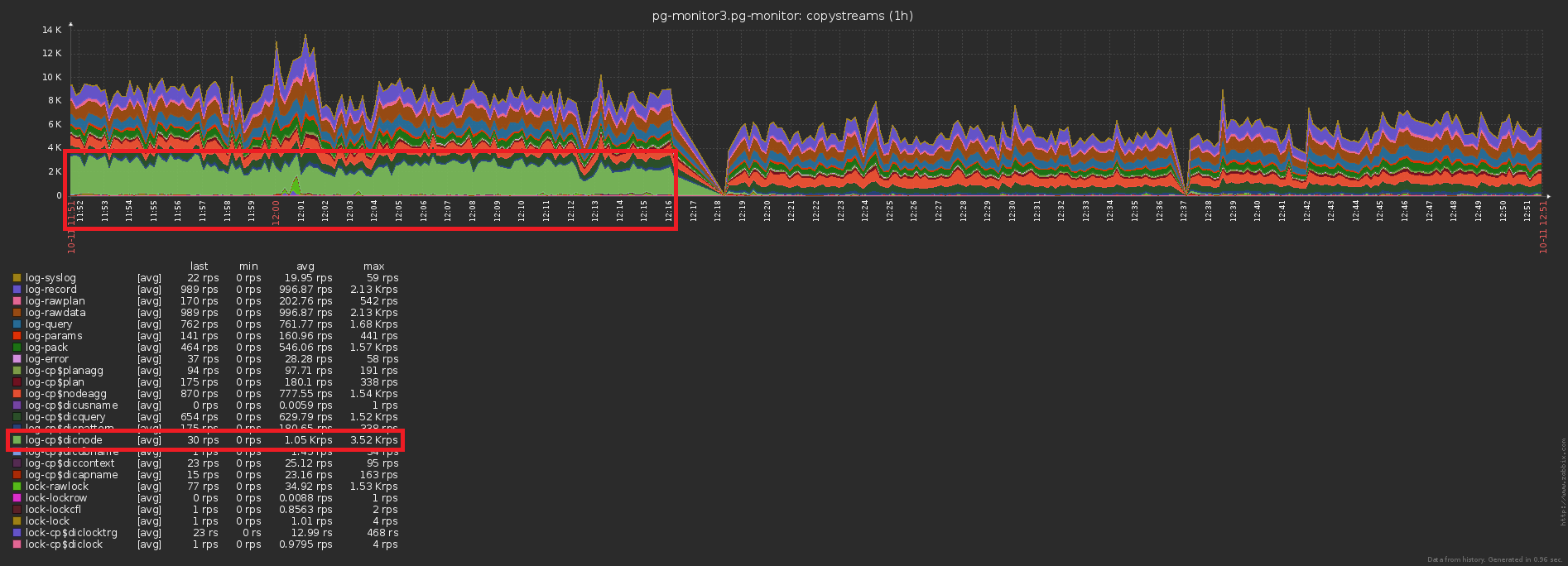 il s'agit d'une baisse concomitante de la charge de stockage:
il s'agit d'une baisse concomitante de la charge de stockage:
Total
Le téraoctet par jour semble effrayant. Si vous faites tout correctement, cela ne représente que 2 ^ 40 octets / 86400 secondes = ~ 12,5 Mo / s , que même les vis IDE de bureau tenaient. :)Mais sérieusement, même avec un «biais» décuplé de la charge pendant la journée, vous pouvez facilement répondre aux possibilités des SSD modernes.