Après tous les calculs présentés dans ce et cette publication, on peut se plonger dans l'analyse statistique et tenir compte de la méthode des moindres carrés. À cet effet, la bibliothèque de modèles de statistiques est utilisée, ce qui permet aux utilisateurs d'examiner les données, d'évaluer les modèles statistiques et d'effectuer des tests statistiques. Cet article et cet article ont été pris comme base . La description de la fonction utilisée en anglais est disponible sur le lien suivant .Tout d'abord, un peu de théorie:À propos de la régression linéaire
La régression linéaire est utilisée comme modèle prédictif lorsqu'une relation linéaire est supposée entre la variable dépendante (la variable que nous essayons de prédire) et la variable indépendante (la variable et / ou les variables utilisées pour la prédiction).Dans le cas le plus simple, lors de l'examen, une variable est utilisée sur la base de laquelle nous essayons de prédire une autre. La formule dans ce cas est la suivante:Y = C + M * X- Y = variable dépendante (résultat / prévision / estimation)
- C = Constante (ordonnée à l'origine)
- M = Pente de la droite de régression (pente ou gradient de la droite estimée; c'est la quantité par laquelle Y augmente en moyenne si on augmente X d'une unité)
- X = variable indépendante (prédicteur utilisé dans la prévision Y)
En fait, il peut également exister une relation entre la variable dépendante et plusieurs variables indépendantes. Pour ces types de modèles (en supposant la linéarité), nous pouvons utiliser une régression linéaire multiple de la forme suivante:Y = C + M1X1 + M2X2 + ...Ratio bêta
Beaucoup de choses ont déjà été écrites sur ce coefficient, par exemple, sur cette pageBrièvement, si vous n'entrez pas dans les détails, vous pouvez le caractériser comme suit:Actions avec un coefficient bêta:- zéro indique aucune corrélation entre l'action et l'indice
- l'unité indique que l'action a la même volatilité que l'indice
- plus d'un - indique une rentabilité (et donc des risques) du titre supérieure à celle de l'indice
- moins d'un - stock moins volatil que l'indice
En d'autres termes, si le stock augmente de 14%, alors que le marché n'a augmenté que de 10%, le coefficient bêta du stock sera de 1,4. En règle générale, les marchés avec un bêta plus élevé peuvent offrir de meilleures conditions de récompense (et donc de risque).
Entraine toi
Le code Python suivant inclut un exemple de régression linéaire, où la variable d'entrée est le rendement de l'indice de la Bourse de Moscou et la variable estimée est le rendement des actions Aeroflot.Afin d'éviter d'avoir à se rappeler comment télécharger les données et amener les données sous la forme nécessaire au calcul, le code est donné à partir du moment où les données sont téléchargées et jusqu'à ce que les résultats soient obtenus. Voici la syntaxe complète pour effectuer une régression linéaire en Python à l'aide de modèles de statistiques:
import pandas as pd
import yfinance as yf
import numpy as np
import matplotlib.pyplot as plt
import statsmodels.api as sm
ticker = ['AFLT.ME','IMOEX.ME']
stock = yf.download(ticker)
all_adj_close = stock[['Adj Close']]
all_returns = np.log(all_adj_close / all_adj_close.shift(1))
aflt_returns = all_returns['Adj Close'][['AFLT.ME']].fillna(0)
moex_returns = all_returns['Adj Close'][['IMOEX.ME']].fillna(0)
return_data = pd.concat([aflt_returns, moex_returns], axis=1)[1:]
return_data.columns = ['AFLT.ME', 'IMOEX.ME']
X = sm.add_constant(return_data['IMOEX.ME'])
y = return_data['AFLT.ME']
model_moex = sm.OLS(y,X).fit()
print(model_moex.summary())
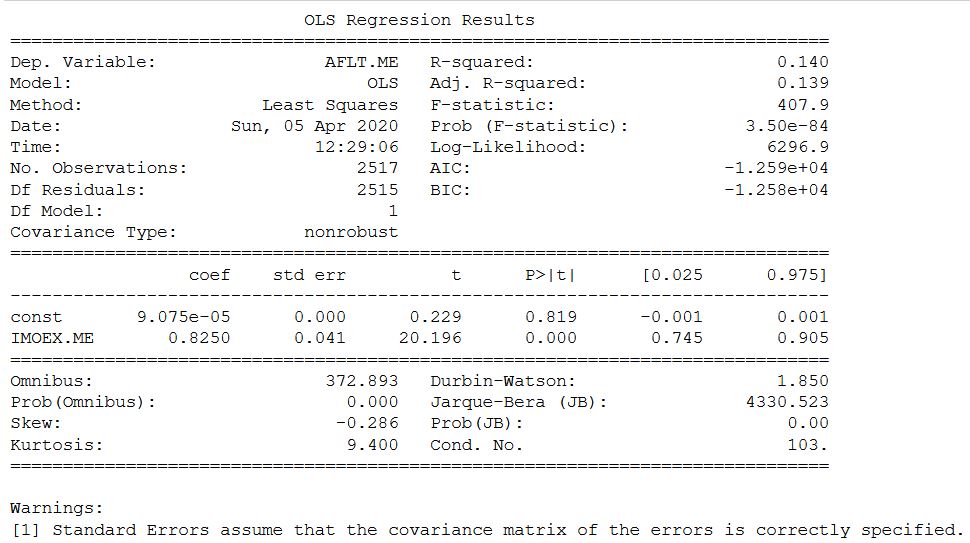 Sur le site Web de Yahoo, le coefficient bêta de Mosbirzhi diffère légèrement à la hausse. Mais je dois honnêtement admettre que le calcul de certaines autres actions de la bourse russe a montré des différences plus importantes, mais dans l'intervalle.
Sur le site Web de Yahoo, le coefficient bêta de Mosbirzhi diffère légèrement à la hausse. Mais je dois honnêtement admettre que le calcul de certaines autres actions de la bourse russe a montré des différences plus importantes, mais dans l'intervalle.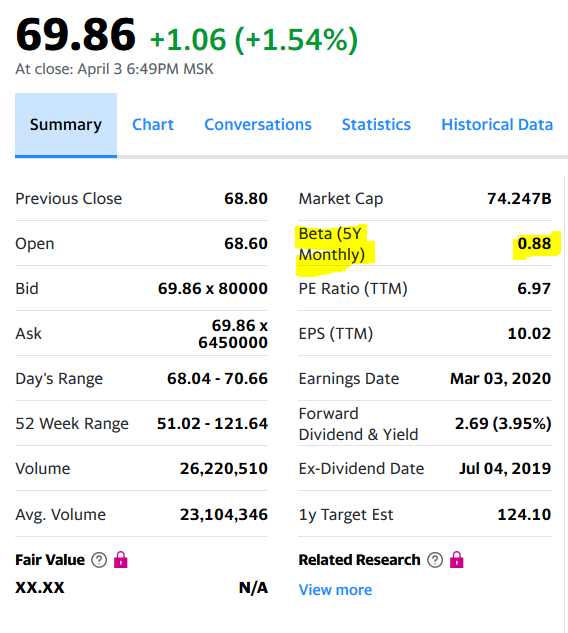 Même analyse pour l'action FB et l'indice SP500. Ici, le calcul, comme dans l'original, s'effectue à travers le rendement mensuel.
Même analyse pour l'action FB et l'indice SP500. Ici, le calcul, comme dans l'original, s'effectue à travers le rendement mensuel.sp_500 = yf.download('^GSPC')
fb = yf.download('FB')
fb = fb.resample('BM').apply(lambda x: x[-1])
sp_500 = sp_500.resample('BM').apply(lambda x: x[-1])
monthly_prices = pd.concat([fb['Close'], sp_500['Close']], axis=1)
monthly_prices.columns = ['FB', '^GSPC']
monthly_returns = monthly_prices.pct_change(1)
clean_monthly_returns = monthly_returns.dropna(axis=0)
X = clean_monthly_returns['^GSPC']
y = clean_monthly_returns['FB']
X1 = sm.add_constant(X)
model_fb_sp_500 = sm.OLS(y, X1)
results_fb_sp_500 = model_fb_sp_500.fit()
print(results_fb_sp_500.summary())
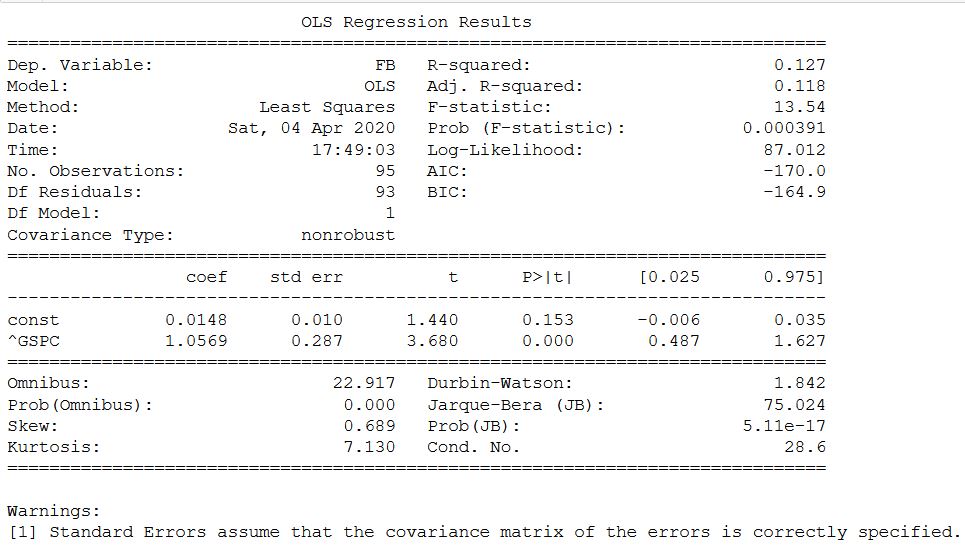
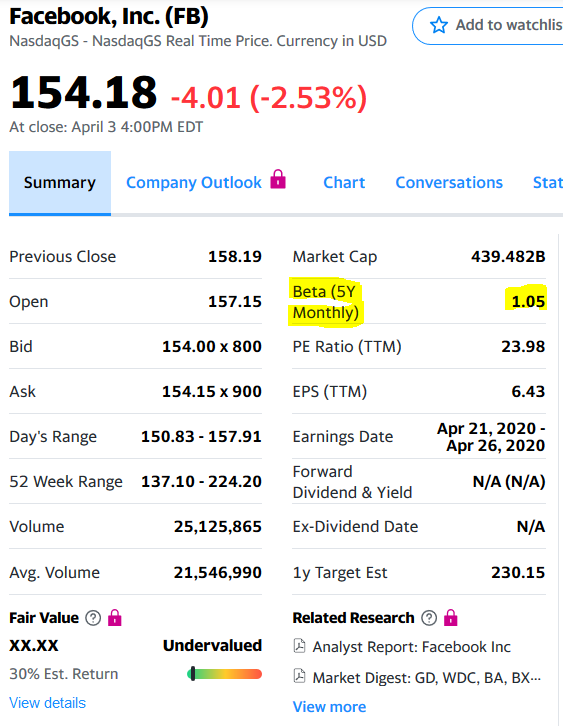 Dans ce cas, tout coïncidait et confirmait la possibilité d'utiliser des modèles statistiques pour déterminer le coefficient bêta.Eh bien, et en bonus - si vous voulez n'obtenir que de la beta - vous voulez laisser le coefficient et le reste des statistiques de côté, alors un autre code est proposé pour le calculer:
Dans ce cas, tout coïncidait et confirmait la possibilité d'utiliser des modèles statistiques pour déterminer le coefficient bêta.Eh bien, et en bonus - si vous voulez n'obtenir que de la beta - vous voulez laisser le coefficient et le reste des statistiques de côté, alors un autre code est proposé pour le calculer:from scipy import stats
slope, intercept, r_value, p_value, std_err = stats.linregress(X, y)
print(slope)
1.0568997978702754
Certes, cela ne signifie pas que toutes les autres valeurs obtenues doivent être ignorées, mais la connaissance des statistiques sera nécessaire pour les comprendre. Je vais donner un petit extrait des valeurs obtenues:- R au carré, qui est le coefficient de détermination et prend des valeurs de 0 à 1. Plus la valeur du coefficient est proche de 1, plus la dépendance est forte;
- Adj. R au carré - R au carré ajusté en fonction du nombre d'observations et du nombre de degrés de liberté;
- std err - erreur standard d'estimation de coefficient;
- P> | t | - valeur p Une valeur inférieure à 0,05 est considérée comme statistiquement significative;
- 0,025 et 0,975 sont les valeurs inférieures et supérieures de l'intervalle de confiance.
- etc.
C'est tout pour le moment. Bien sûr, il est intéressant de rechercher une relation entre différentes valeurs afin de prédire l'autre à travers l'une et d'obtenir un profit. Dans l'une des sources étrangères, l'indice a été prédit grâce au taux d'intérêt et au taux de chômage. Mais si la variation du taux d'intérêt en Russie peut être prise sur le site Web de la Banque centrale, je continue de chercher d'autres. Malheureusement, le site Web de Rosstat n'a pas pu trouver les sites pertinents. Il s'agit de la publication finale dans les articles de l'analyse financière générale.