Que dit-on au dieu de la mort? - Pas aujourd'hui.
Sirio Trout, série télévisée Game of Thrones.Dans quelle mesure le coronavirus COVID-19 est-il dangereux? Combien de personnes mourront du coronavirus dans le monde? Et combien - en Russie? Des mesures sévères prises pour lutter contre les coronavirus dans la plupart des pays du monde sont-elles vraiment nécessaires? Qu'est-ce qui causera le plus de dommages: la mort de personnes à cause du coronavirus ou le déclin économique causé par des mesures restrictives?Pour répondre à ces questions pressantes, il est nécessaire d'effectuer une modélisation mathématique et de prévoir les dommages causés par les coronavirus pour des pays individuels et pour le monde dans son ensemble. La construction de telles prévisions est consacrée à cet article.Pour rendre le matériel accessible à tous les lecteurs, au début de l'article, nous nous concentrerons sur l'analyse qualitative et les belles images. Et à la fin, pour ceux qui sont intéressés, nous donnerons le code source pour les calculs effectués en Python.
UFO Care Minute
La pandémie COVID-19, une infection respiratoire aiguë potentiellement grave causée par le coronavirus SARS-CoV-2 (2019-nCoV), a été officiellement annoncée dans le monde. Il y a beaucoup d'informations sur Habré sur ce sujet - rappelez-vous toujours qu'il peut être à la fois fiable / utile, et vice versa.
Nous vous invitons à critiquer toute information publiée.
Lavez-vous les mains, prenez soin de vos proches, restez à la maison dans la mesure du possible et travaillez à distance.
Lire les publications sur: coronavirus | travail à distance
Ne compter que la mort
Notez que nous évaluerons les dommages causés par COVID-19 dans le nombre de décès humains associés à cette maladie. Une grande partie de l'article sera consacrée à la prévision du nombre de décès par coronavirus. Nous avons généralement refusé de prendre en compte le nombre de patients atteints de coronavirus et de prédire leur nombre. Il y a plusieurs raisons à cela. L'essentiel est qu'il est impossible de comparer les statistiques sur le nombre de cas de COVID-19 dans différents pays. Dans certains pays, les méthodes de test rapide sont beaucoup plus disponibles que dans d'autres. Dans certains pays, un dépistage quasi universel de la population est effectué, tandis que dans d'autres, seules les personnes présentant des symptômes sévères sont contrôlées. Étant donné que dans un nombre important de cas, la maladie est presque asymptomatique, nous constatons une énorme propagation du nombre de décès chez les patients: de moins de 0,5% à plus de 3,5%.Très probablement, la dispersion des données de mortalité est largement due à la détection de cas de COVID-19.Les statistiques de mortalité dans ce cas semblent beaucoup plus fiables. Naturellement, nous pouvons faire face à la fois à une sous-estimation du nombre de décès, lorsque la cause du décès n'est pas indiquée par le coronavirus, mais par une maladie concomitante, et vice versa, par une surestimation, lorsque COVID-19 est diagnostiqué incorrectement, et qu'une personne décède, par exemple, d'une grippe saisonnière. Cependant, nous pouvons nous attendre à ce que les statistiques sur les décès soient plus fiables, car une maladie asymptomatique avec un haut degré de probabilité peut généralement passer par l'attention de spécialistes, et les médecins sont obligés d'analyser chaque cas de décès.Nous notons également que les dommages réels à la société sont causés par la mort de ses membres, et non par une maladie bénigne qui passe relativement rapidement.Pensiez-vous que le monde est gouverné par un exposant? Et non!
Dès que nous commençons à prévoir le nombre de décès, nous rencontrons immédiatement le premier mythe: des dizaines voire des centaines de millions de personnes mourront du coronavirus. Ce mythe repose sur la conviction que le monde est dirigé par un exposant. Jetez un œil au tableau.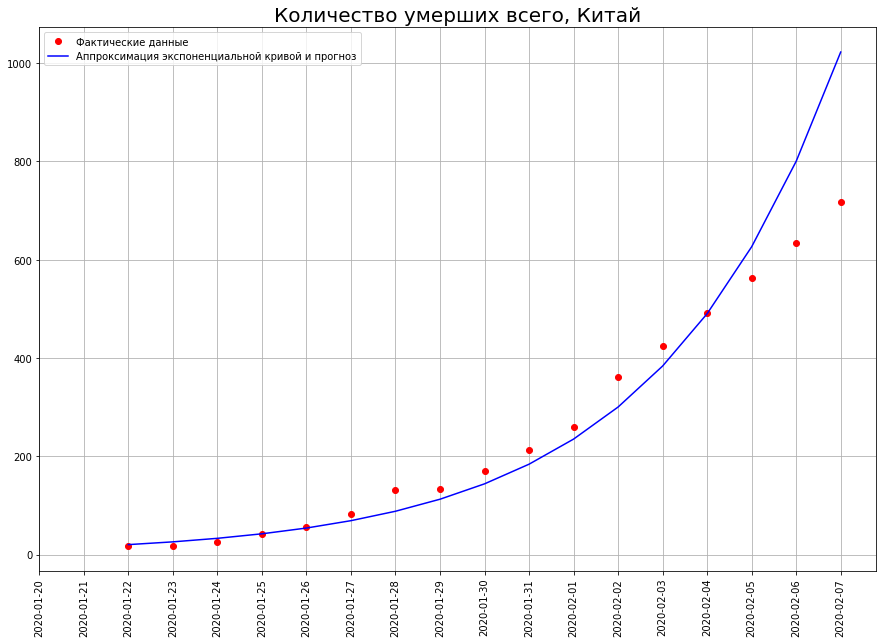 Il montre le nombre de décès dus à COVID-19 en Chine au 7 février. Si nous construisons une prévision basée sur ce graphique en utilisant une fonction exponentielle, nous obtenons que d'ici le 29 février, 50 millions de personnes auraient dû mourir en Chine!
Il montre le nombre de décès dus à COVID-19 en Chine au 7 février. Si nous construisons une prévision basée sur ce graphique en utilisant une fonction exponentielle, nous obtenons que d'ici le 29 février, 50 millions de personnes auraient dû mourir en Chine! Et combien sont vraiment morts? 2837 personnes. Pourquoi une telle différence colossale?Le fait est que le monde n'est pas dirigé par un exposant, mais par une courbe logistique.Contrairement à l'exposant, la courbe logistique ne passe pas seulement à l'école, mais même dans les meilleures universités techniques (par exemple, au département de physique de l'Université d'État de Moscou et à la PhysTech). Par conséquent, les physiciens et les techniciens en général n'en ont souvent aucune idée.Néanmoins, un grand nombre de phénomènes en économie, biologie, sociologie, science et technologie se développent en parfaite adéquation avec ce modèle mathématique. Examinons-le de plus près. Elle est là. Le temps est tracé sur l'axe des x, et sur y le nombre qui caractérise les phénomènes étudiés par nous (dans notre cas, le nombre de décès par coronavirus).
Et combien sont vraiment morts? 2837 personnes. Pourquoi une telle différence colossale?Le fait est que le monde n'est pas dirigé par un exposant, mais par une courbe logistique.Contrairement à l'exposant, la courbe logistique ne passe pas seulement à l'école, mais même dans les meilleures universités techniques (par exemple, au département de physique de l'Université d'État de Moscou et à la PhysTech). Par conséquent, les physiciens et les techniciens en général n'en ont souvent aucune idée.Néanmoins, un grand nombre de phénomènes en économie, biologie, sociologie, science et technologie se développent en parfaite adéquation avec ce modèle mathématique. Examinons-le de plus près. Elle est là. Le temps est tracé sur l'axe des x, et sur y le nombre qui caractérise les phénomènes étudiés par nous (dans notre cas, le nombre de décès par coronavirus).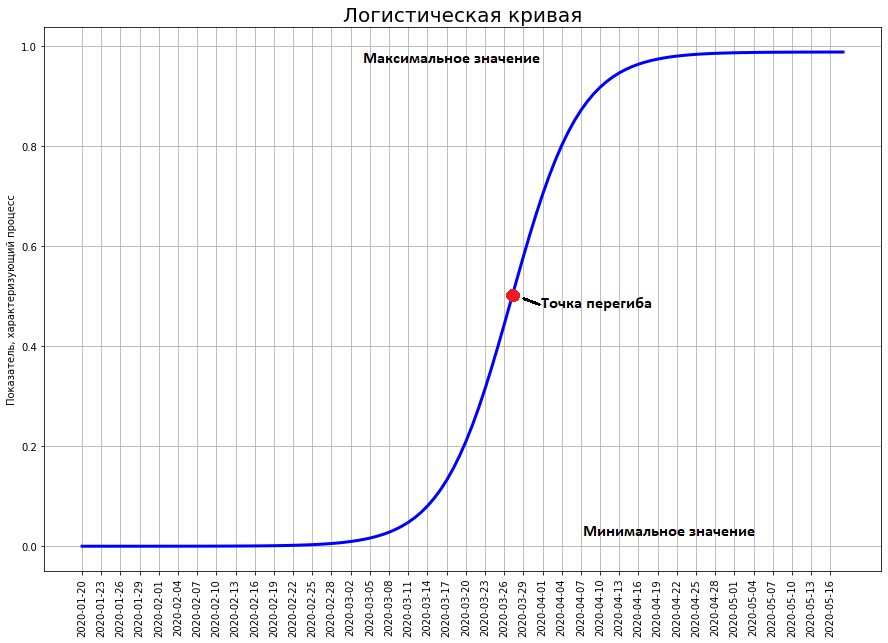
Courbe insidieuse qui rompt tout le battage médiatique
La courbe logistique montre la transition entre deux états stables. L'état inférieur est traditionnellement considéré comme égal à zéro. L'état supérieur est le maximum que, en principe, le phénomène étudié peut atteindre. La courbe s'approche de sa fermeture arbitrairement, mais n'atteint jamais sa valeur maximale.Le point le plus important de la courbe est le point d'inflexion. Il est situé exactement au milieu entre le minimum et le maximum. C'est à ce stade que le taux de croissance maximum de la courbe. Mais une inflexion s'y produit. À ce stade, la croissance de la courbe ne fait qu'accélérer. Après - ne se fane que.D'habitude au début, personne ne remarque un certain phénomène (car le coronavirus n'a été remarqué que fin janvier). À ce stade, la valeur de la courbe est proche de zéro. Progressivement, le phénomène prend de l'ampleur, ils commencent à le remarquer, un battage médiatique se crée autour de lui. Le battage médiatique peut être à la fois positif (comme, par exemple, au moment du vol de Gagarine, les gens du monde entier sont tombés malades avec l’espace) et négatif (la situation avec le coronavirus actuel). Au moment du battage médiatique, tout le monde prédit que le phénomène prendra des proportions incroyables et bouleversera le monde. Ainsi, au moment du vol de Gagarine, même les professionnels pensaient que la conquête du système solaire aurait lieu au XXe siècle. Et ils ne s'attendaient pas du tout à ce que tous les succès de l'astronautique se terminent en 1969 avec l'atterrissage d'un homme sur la lune.C'est au moment du battage médiatique maximum que la courbe atteint la moitié de son futur maximum. Puis la croissance s'estompe et le phénomène ne justifie complètement pas les espoirs placés (ainsi que les craintes).Courbe logistique chinoise
Voyons ce qui s'est passé en Chine.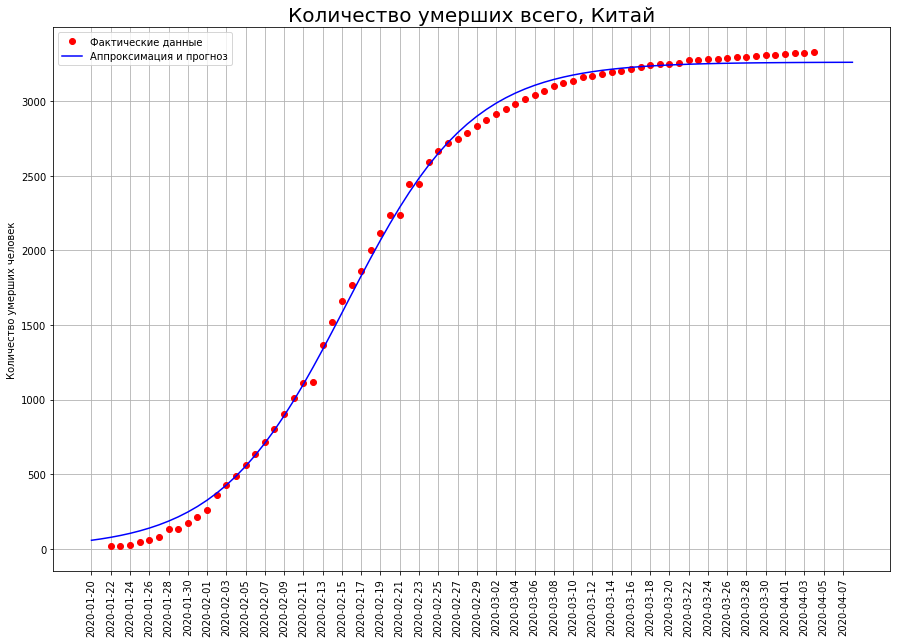 Dans le graphique ci-dessous, les points rouges indiquent le nombre de décès dus au virus à une date donnée. La courbe bleue est une courbe logistique approximative des données réelles. On voit que les données y tombent presque parfaitement. Le graphique ci-dessous montre le nombre de décès survenus à une date précise. En fait, c'est la différence entre les valeurs de la courbe logistique d'aujourd'hui et d'hier. D'un point de vue mathématique, il s'agit de la première dérivée de la courbe logistique.
Dans le graphique ci-dessous, les points rouges indiquent le nombre de décès dus au virus à une date donnée. La courbe bleue est une courbe logistique approximative des données réelles. On voit que les données y tombent presque parfaitement. Le graphique ci-dessous montre le nombre de décès survenus à une date précise. En fait, c'est la différence entre les valeurs de la courbe logistique d'aujourd'hui et d'hier. D'un point de vue mathématique, il s'agit de la première dérivée de la courbe logistique.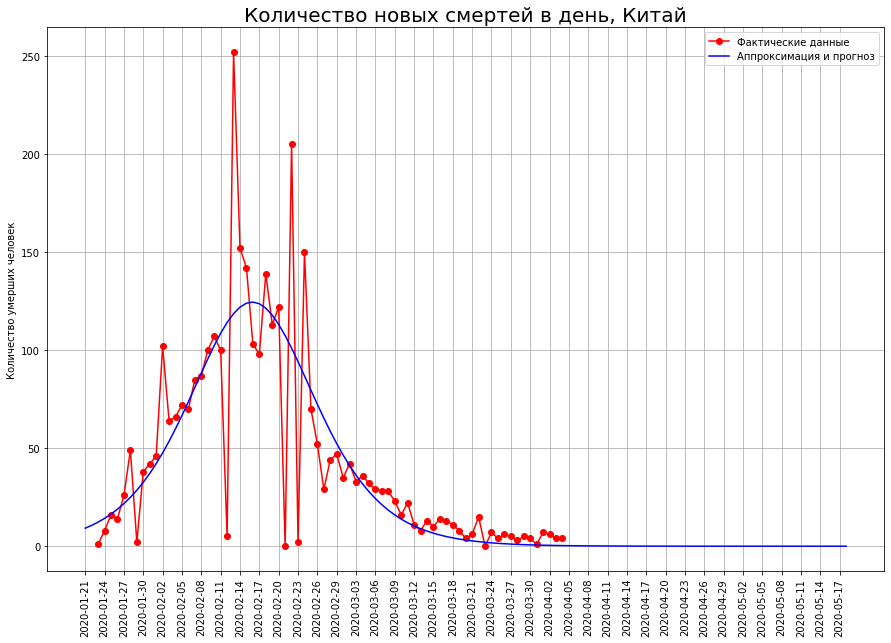 On voit qu'au début le nombre de nouveaux décès augmente de façon quasi exponentielle. Puis la croissance commence à ralentir, la courbe des nouveaux décès atteint un maximum au point d'inflexion, lorsque la courbe logistique atteint la moitié de sa valeur maximale. Ensuite, le nombre de nouveaux décès diminue et se précipite à zéro. Les points rouges indiquent de nouveaux décès, la courbe bleue est la dérivée de la courbe logistique les rapprochant.Notez que la courbe logistique est symétrique par rapport au point de son inflexion, et sa dérivée première est relative à la ligne verticale passant par ce point. On note également que les données réelles se situent idéalement sur la courbe logistique, mais elles «dansent» par rapport à sa dérivée première. Le fait est que le taux de mortalité en un point est sujet à une forte dispersion, et le taux de mortalité total est la somme de ces indicateurs. Il est lissé conformément au théorème de la limite centrale.Ainsi, nous voyons que la courbe logistique peut être utilisée efficacement pour prédire les décès par coronavirus. Une propriété importante ici est sa symétrie. Lorsque le point d'inflexion est atteint, nous pouvons restaurer l'autre moitié avec une grande précision à partir d'une moitié de la courbe.À son tour, afin de déterminer si le point d'inflexion est atteint, il vous suffit de regarder le graphique de la dérivée première. Dès qu'il est descendu - le point correspondant a été atteint.
On voit qu'au début le nombre de nouveaux décès augmente de façon quasi exponentielle. Puis la croissance commence à ralentir, la courbe des nouveaux décès atteint un maximum au point d'inflexion, lorsque la courbe logistique atteint la moitié de sa valeur maximale. Ensuite, le nombre de nouveaux décès diminue et se précipite à zéro. Les points rouges indiquent de nouveaux décès, la courbe bleue est la dérivée de la courbe logistique les rapprochant.Notez que la courbe logistique est symétrique par rapport au point de son inflexion, et sa dérivée première est relative à la ligne verticale passant par ce point. On note également que les données réelles se situent idéalement sur la courbe logistique, mais elles «dansent» par rapport à sa dérivée première. Le fait est que le taux de mortalité en un point est sujet à une forte dispersion, et le taux de mortalité total est la somme de ces indicateurs. Il est lissé conformément au théorème de la limite centrale.Ainsi, nous voyons que la courbe logistique peut être utilisée efficacement pour prédire les décès par coronavirus. Une propriété importante ici est sa symétrie. Lorsque le point d'inflexion est atteint, nous pouvons restaurer l'autre moitié avec une grande précision à partir d'une moitié de la courbe.À son tour, afin de déterminer si le point d'inflexion est atteint, il vous suffit de regarder le graphique de la dérivée première. Dès qu'il est descendu - le point correspondant a été atteint.Comment finira la catastrophe italienne?
Tournons notre vision des trois pays vers la lettre «I»: l'Italie, l'Iran et l'Espagne. En regardant les courbes de mortalité à une date précise, nous voyons que, très probablement, le pic de la catastrophe s'est passé là-bas, et il est temps de faire le point.

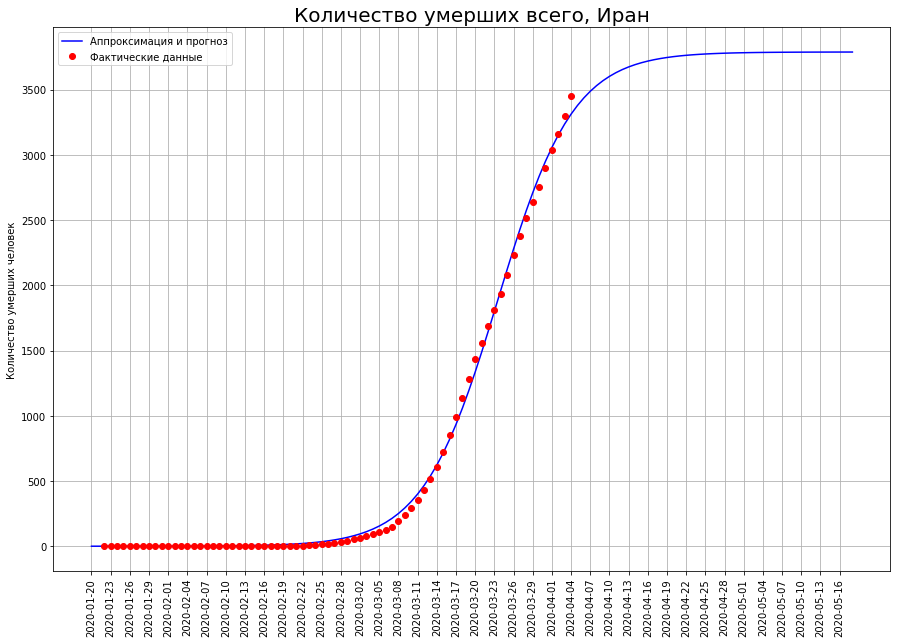
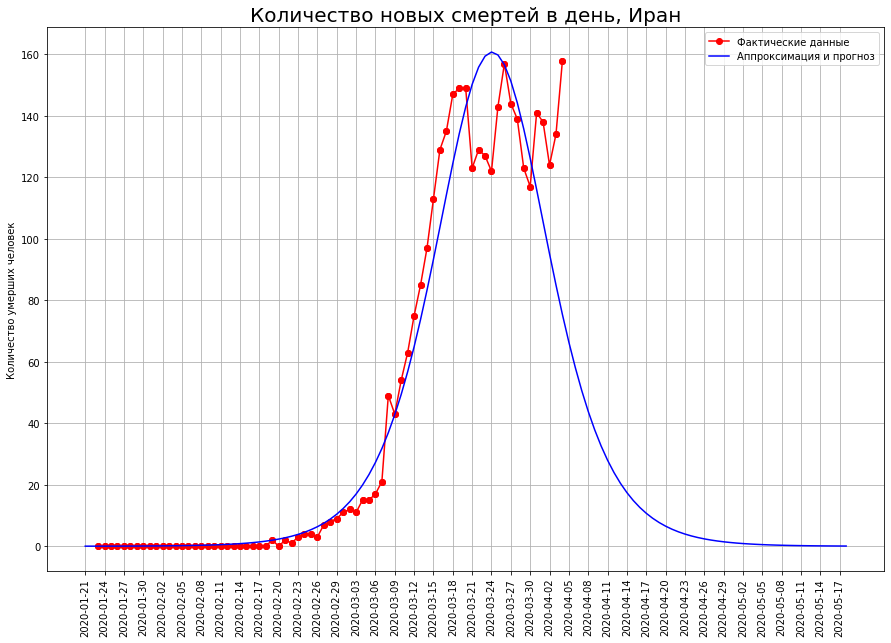
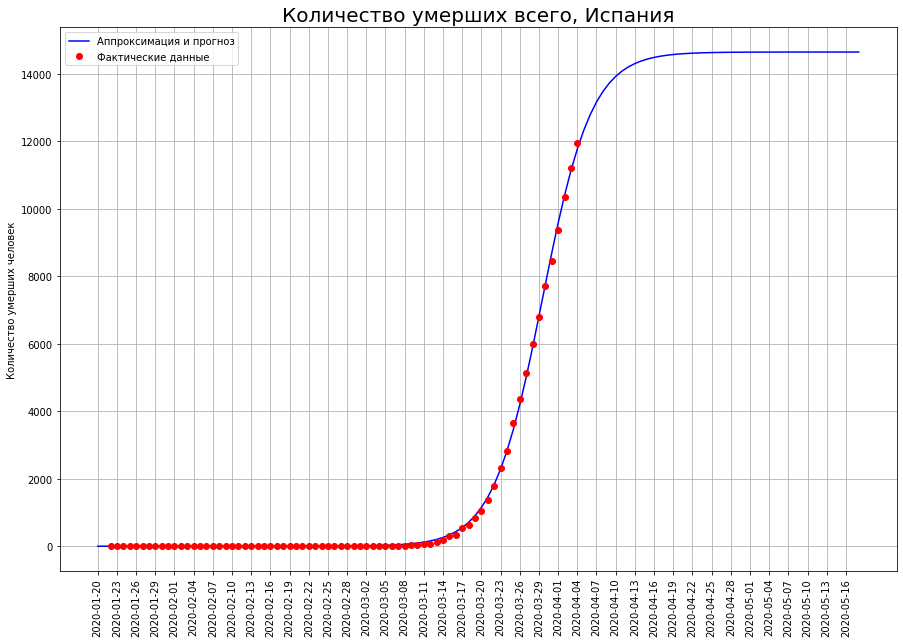
 Selon nos prévisions, seul COVID-19 mourra:en Italie - environ 19 000 personnes,en Iran - environ 4 000 personnes,en Espagne - environ 15 000 personnes.
Selon nos prévisions, seul COVID-19 mourra:en Italie - environ 19 000 personnes,en Iran - environ 4 000 personnes,en Espagne - environ 15 000 personnes.À mi-chemin de la mortalité finale
L'épidémie en Allemagne semble avoir atteint son apogée et le nombre total de décès par coronavirus dans ce pays sera d'environ 2,6 mille personnes.
 Dans des pays comme les Pays-Bas, la Suisse et la Belgique, la modélisation mathématique montre que l'épidémie est à un point d'inflexion. Si tel est le cas, alors le nombre attendu de décès en eux:aux Pays-Bas - environ 2,5 mille personnes,en Suisse - environ 1,1 mille personnes,en Belgique - environ 2,2 mille personnes.
Dans des pays comme les Pays-Bas, la Suisse et la Belgique, la modélisation mathématique montre que l'épidémie est à un point d'inflexion. Si tel est le cas, alors le nombre attendu de décès en eux:aux Pays-Bas - environ 2,5 mille personnes,en Suisse - environ 1,1 mille personnes,en Belgique - environ 2,2 mille personnes.



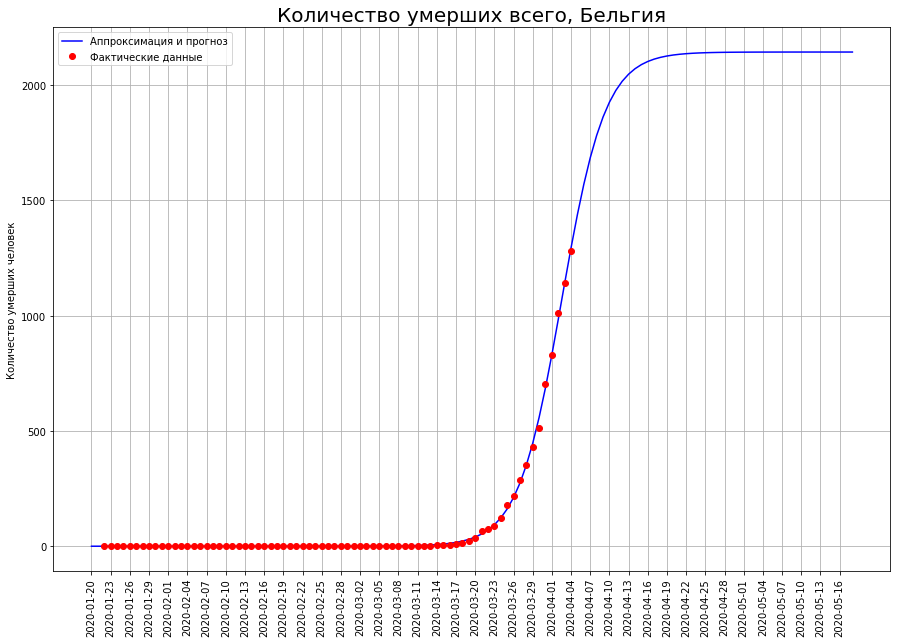
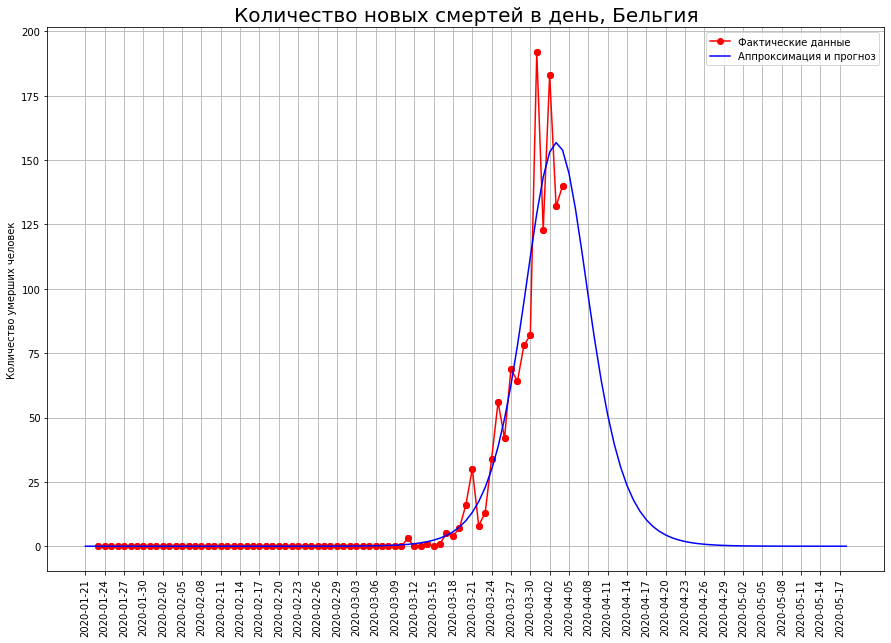
Pour quelqu'un, ce n'est que le début
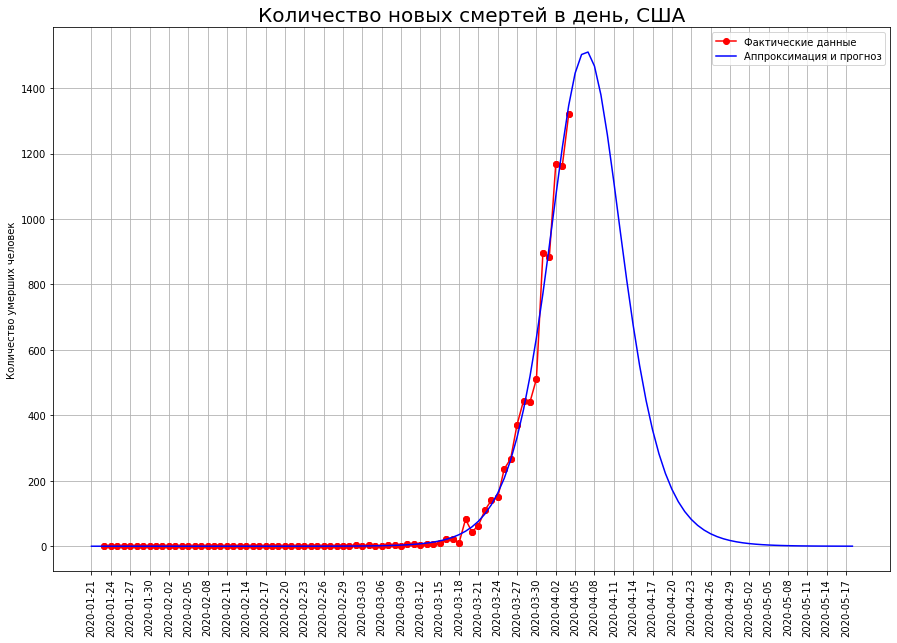
Aux États-Unis, le point d'inflexion n'a pas encore été franchi, de sorte que les prévisions à leur sujet peuvent être considérablement ajustées. Actuellement, c'est 23 mille personnes.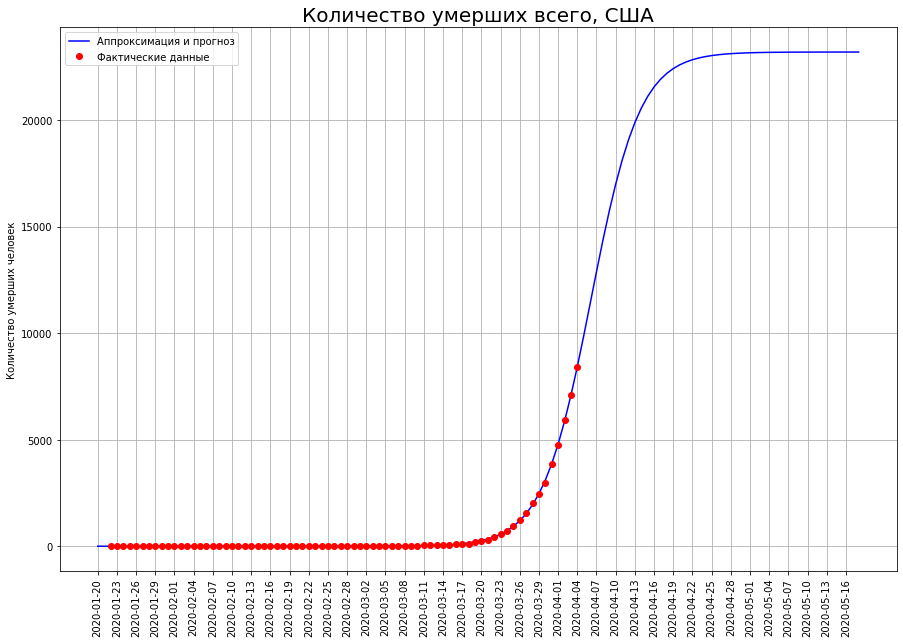
Le Royaume-Uni est-il un nouvel épicentre de la tragédie?
Enfin, une grande incertitude demeure pour les deux pays quant à l'atteinte du point d'inflexion. Ce sont le Royaume-Uni et la France.

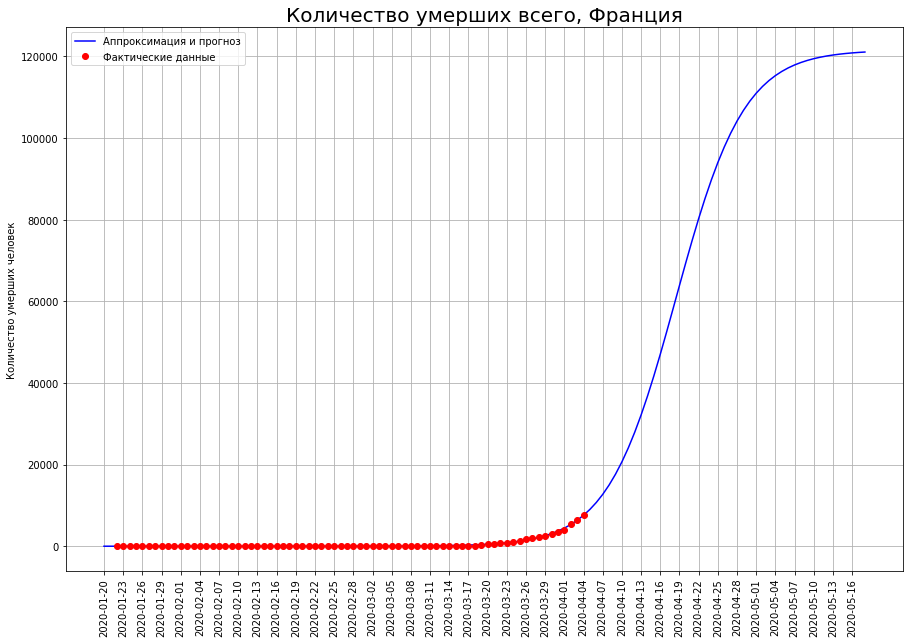
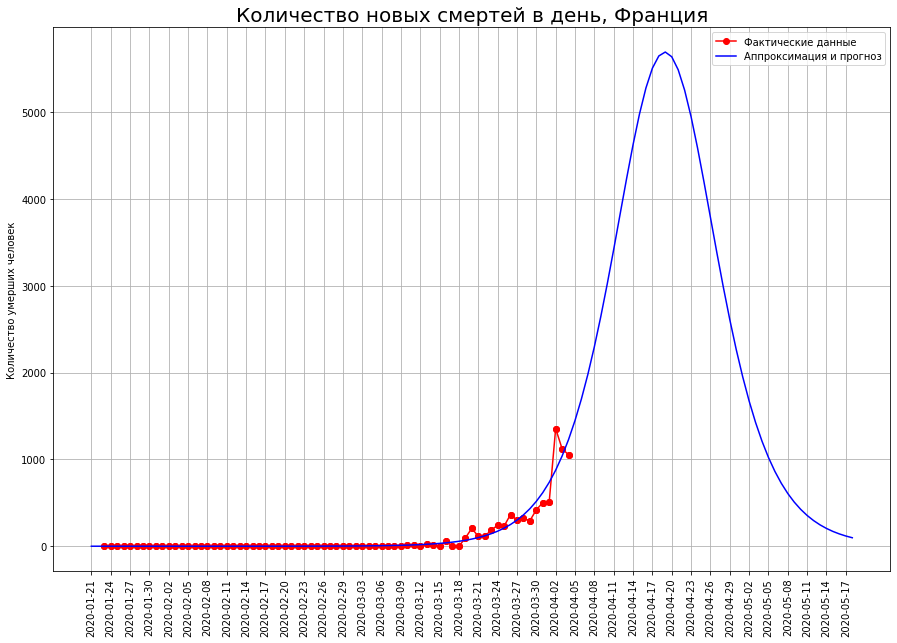 Les prévisions du nombre final de décès sur eux sont en constante augmentation. Ils comprennent actuellement:
Les prévisions du nombre final de décès sur eux sont en constante augmentation. Ils comprennent actuellement:- au Royaume-Uni - environ 33 mille personnes
- en France - environ 12 mille personnes.
L'auteur espère que ces prévisions sont le résultat de fluctuations aléatoires et qu'elles seront ajustées à la baisse dans les prochains jours.L'auteur est particulièrement préoccupé par le Royaume-Uni. Selon les données au 25 mars, l'auteur a prédit la mortalité dans ce pays au niveau de 1 000 personnes, selon les données au 01.04 - au niveau de 8 000, maintenant les prévisions indiquent 33 000. Les prévisions pour aucun autre pays n'ont une telle volatilité.Peut-être que l'épicentre de la tragédie des décès par coronavirus se déplace progressivement en Grande-Bretagne. Il est également possible que l'évolution de la situation dans le pays soit liée à la politique initialement irresponsable de Boris Johnson, qui jusqu'à récemment refusait d'imposer des restrictions strictes et espérait "une vaccination du troupeau". Dans ce cas, l'auteur espère que les citoyens, que Johnson a exprimés de manière si irrespectueuse, se souviendront de lui de cette politique lors des prochaines élections, mais plutôt extraordinaires.Prévisions pour la Russie
Étant donné que l'épidémie en Russie ne fait que commencer, il ne sera pas possible de prédire le nombre de décès en utilisant la courbe logistique. Ci-dessous, nous utiliserons une méthode de prévision différente.Et à l'échelle mondiale?
Il est temps de faire des prévisions pour le monde entier.
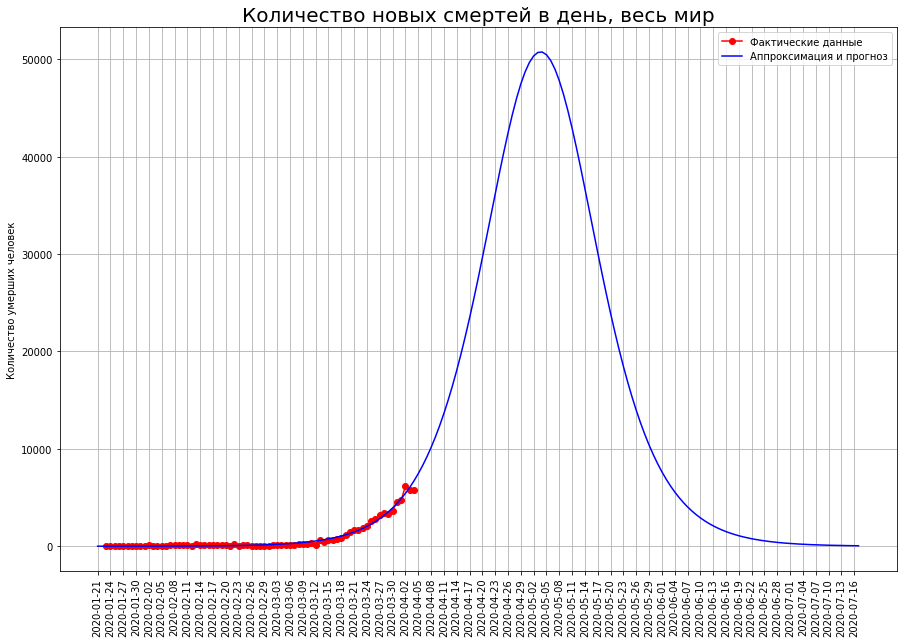 La courbe logistique que nous avons construite donne les résultats suivants: le pic de la crise aura lieu au cours des dix premiers jours de mai et l'épidémie prendra fin à la mi-juillet. Il tuera environ 1 million 800 000 personnes.Étant donné que l'épidémie à l'échelle mondiale ne fait que s'amplifier, une prévision basée sur une courbe logistique peut donner un résultat incorrect, nous allons donc utiliser une autre méthode de prévision.Prenons les pays pour lesquels nous avons fait des prévisions.
La courbe logistique que nous avons construite donne les résultats suivants: le pic de la crise aura lieu au cours des dix premiers jours de mai et l'épidémie prendra fin à la mi-juillet. Il tuera environ 1 million 800 000 personnes.Étant donné que l'épidémie à l'échelle mondiale ne fait que s'amplifier, une prévision basée sur une courbe logistique peut donner un résultat incorrect, nous allons donc utiliser une autre méthode de prévision.Prenons les pays pour lesquels nous avons fait des prévisions.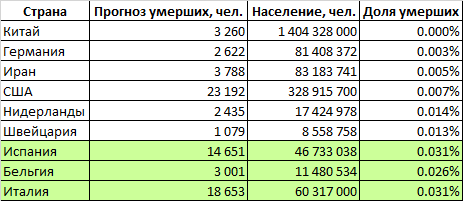 Le tableau définit la proportion de la population de ces pays qui mourra du coronavirus (la Grande-Bretagne et la France sont temporairement exclues en raison de la forte incertitude des prévisions). On voit que les deux groupes de pays sont sensiblement différents. Dans des pays comme l'Italie, l'Espagne et la Belgique, la mortalité est projetée à 0,029% de la population. Dans un groupe de pays plus prospère (Chine, Allemagne, Iran, États-Unis, Pays-Bas, Suisse), le taux de mortalité devrait être d'environ 0,007% - 4 fois plus faible.On peut supposer que le monde dans son ensemble sera caractérisé par un taux de mortalité plus élevé. Le fait est que dans notre analyse, nous avons examiné des pays relativement riches avec des gouvernements capables qui disposent à la fois de ressources financières et organisationnelles pour faire face à l'épidémie. Mais sur Terre, il existe de nombreux États qui ont des capacités beaucoup plus modestes, à la fois financièrement et organisationnellement. Beaucoup de ces pays sont très densément peuplés. On peut supposer que dans ces pays, l'épidémie fera encore plus de victimes que dans les riches Italie, Espagne et Belgique. En revanche, la proportion de la population âgée dans ces pays est plus faible, ce qui réduit la mortalité potentielle.Si nous estimons la mortalité mondiale au niveau du pire groupe de pays, alors environ 2 millions 100 000 personnes mourront dans le monde. Si vous utilisez des valeurs moyennes - alors environ 900 000.Notre prévision pessimiste du nombre de décès dans le monde, calculée sur la base de la part de la population décédée, était étonnamment proche de la prévision calculée sur la base de la courbe logistique.Ainsi, 1 à 2 millions de personnes mourront dans le monde, et le chiffre de 2 millions est plus probable.
Le tableau définit la proportion de la population de ces pays qui mourra du coronavirus (la Grande-Bretagne et la France sont temporairement exclues en raison de la forte incertitude des prévisions). On voit que les deux groupes de pays sont sensiblement différents. Dans des pays comme l'Italie, l'Espagne et la Belgique, la mortalité est projetée à 0,029% de la population. Dans un groupe de pays plus prospère (Chine, Allemagne, Iran, États-Unis, Pays-Bas, Suisse), le taux de mortalité devrait être d'environ 0,007% - 4 fois plus faible.On peut supposer que le monde dans son ensemble sera caractérisé par un taux de mortalité plus élevé. Le fait est que dans notre analyse, nous avons examiné des pays relativement riches avec des gouvernements capables qui disposent à la fois de ressources financières et organisationnelles pour faire face à l'épidémie. Mais sur Terre, il existe de nombreux États qui ont des capacités beaucoup plus modestes, à la fois financièrement et organisationnellement. Beaucoup de ces pays sont très densément peuplés. On peut supposer que dans ces pays, l'épidémie fera encore plus de victimes que dans les riches Italie, Espagne et Belgique. En revanche, la proportion de la population âgée dans ces pays est plus faible, ce qui réduit la mortalité potentielle.Si nous estimons la mortalité mondiale au niveau du pire groupe de pays, alors environ 2 millions 100 000 personnes mourront dans le monde. Si vous utilisez des valeurs moyennes - alors environ 900 000.Notre prévision pessimiste du nombre de décès dans le monde, calculée sur la base de la part de la population décédée, était étonnamment proche de la prévision calculée sur la base de la courbe logistique.Ainsi, 1 à 2 millions de personnes mourront dans le monde, et le chiffre de 2 millions est plus probable.Qu'arrivera-t-il à la mère patrie et à nous?
Quant à la Russie, avec une population de 148 millions d'habitants, la prévision optimiste (basée sur la moyenne de tous les pays sauf les trois principaux étrangers) est de 10 000 personnes. Et pessimiste (basé sur la mortalité au niveau de l'Italie, l'Espagne et la Belgique) - 40 mille.Le chiffre de 10 000 est beaucoup plus probable. Le fait est que la Russie a plusieurs facteurs favorables: faible densité de population, grandes distances entre les grandes villes, flux migratoires relativement faibles entre les régions (à l'exclusion de la région métropolitaine), caractère décisif, adéquation et opportunité des actions des autorités pour lutter contre l'épidémie. Ces facteurs permettent d'espérer éviter de développer la situation selon la version italo-espagnole-belge.Quant au calendrier de l'achèvement de l'épidémie en Russie, nous nous tournons vers le graphique ci-dessous. Sur celui-ci, nous avons représenté les courbes logistiques pour différents pays dans un graphique. Dans ce cas, nous avons normalisé toutes les courbes en hauteur afin que la valeur maximale soit de un, et avons combiné le point d'inflexion en le plaçant à zéro.Le graphique montre que l'épidémie se termine dans 40 à 60 jours. Si nous prenons le 30 mars comme point de départ, alors en Russie, l'épidémie devra prendre fin du 10 au 30 mai.Les victimes sont-elles justifiées?
Et enfin, dernière question posée au début de l'article: dans quelle mesure les strictes mesures de quarantaine prises par les gouvernements de la plupart des pays du monde sont-elles justifiées?Environ 58 millions de personnes meurent chaque année dans le monde. 2 millions de personnes qui, selon une prévision pessimiste, mourront d'un coronavirus, augmenteront ce chiffre de 3,5%. D'un autre côté, la quarantaine mondiale à grande échelle menace de dégénérer en la plus grande crise économique depuis la Grande Dépression. En conséquence, des dizaines, voire des centaines de millions de personnes resteront sans travail. Les revenus de la population chuteront et beaucoup mourront de faim ou de l'impossibilité de payer les soins médicaux.Les opinions sont souvent exprimées, y compris par certains dirigeants mondiaux, qu'il serait préférable de laisser les gens à leur sort et de ne pas ruiner l'économie. Au final, de 300 à 650 000 personnes meurent chaque année de la grippe saisonnière, mais personne ne prend des mesures restrictives aussi destructrices pour l'économie.Notre modèle nous permet d'affirmer ce qui suit: COVID-19 n'est pas du tout la grippe saisonnière. Ce virus est incomparablement plus dangereux. Le fait est que le point d'inflexion de la courbe logistique n'existe pas par lui-même. Elle est fortement affectée par les conditions de l'épidémie. L'évolution d'une épidémie est décrite par une courbe logistique, mais les courbes logistiques sont une famille entière. Nous nous souvenons que le point d'inflexion est exactement la moitié du maximum de la courbe. Par conséquent, plus le pic de mortalité est tardif, plus le nombre final de décès sera élevé. Nous avons vu que près du point d'inflexion la courbe logistique croît le plus vite possible. Par conséquent, si le pic de la maladie est dépassé 10 jours plus tard, le nombre de victimes peut augmenter plusieurs fois!Les prévisions que nous avons reçues pour les points d'inflexion des courbes logistiques incluent déjà toutes les mesures de quarantaine prises par les gouvernements des pays du monde. En l'absence de telles mesures, les points d'inflexion ont été atteints beaucoup plus tard. Dans ce cas, la mortalité pourrait atteindre le niveau de 0,4-0,5% de l'ensemble de la population mondiale.Pourquoi estimons-nous le taux de mortalité d'une épidémie non maîtrisée à 0,4-0,5% de la population. Nous supposons que dans ce cas, sous une forme ou une autre, toute la population de la Terre sera malade du virus. Cependant, chez un nombre important de personnes, la maladie sera asymptomatique. Par conséquent, nous utilisons des statistiques de pays comme la Corée du Sud et l'Allemagne, qui ont réussi à organiser le plus large possible des tests de dépistage de coronavirus dans la population et à identifier la majorité des cas réels. Dans d'autres pays, à notre avis, les statistiques sont faussées précisément parce que le nombre de cas est largement sous-estimé. D'où un taux de mortalité super élevé de 3,5%.0,4-0,5% de la population mondiale est composée de 28 à 35 millions de personnes. Pour toutes les guerres que l'humanité a menées dans toute son histoire, seul le nombre de pertes dans la Seconde Guerre mondiale dépasse ce chiffre. Le fait que les gouvernements de la grande majorité des pays du monde aient fait des sacrifices économiques sans précédent pour sauver des personnes montre à quel point le prix de la vie humaine a augmenté dans le monde. Combien répandu les idées d'humanisme et la priorité des intérêts de l'individu. Et cela inspire l'auteur de la fierté de l'humanité et de l'espoir d'un avenir meilleur pour toute l'humanité.Le plus gros inconvénient de cet article
Et voici le plus gros inconvénient de cet article. Malheureusement, les statistiques classiques ne nous fournissent pas d'outils pour estimer les erreurs de prévision sur la base d'une fonction logistique. Cela est dû à la forme de la fonction, qui a une inflexion. Si cette inflexion ne l'était pas et que la courbe serait monotone, nous, avec l'aide de la transformation de Box-Cox, amènerions d'abord la fonction à une forme linéaire. Après cela, en utilisant l'équation d'erreur pour la régression linéaire, nous construirions les limites supérieure et inférieure des erreurs, puis, en utilisant la transformation Box-Cox inverse, nous obtiendrions des limites d'erreur curvilignes, sur la base desquelles nous établirions les prévisions maximale et minimale pour le nombre de décès par coronavirus.Hélas, les outils de la statistique classique ne permettent pas de construire des limites d'erreur dans le cas d'une courbe avec une flexion. Mais les méthodes d'apprentissage automatique peuvent nous être utiles. Dans le prochain article, je montrerai comment les limites des erreurs sont construites dans ce cas, et je construirai les prévisions minimales et maximales pour le nombre de décès pour chaque pays considéré ci-dessus séparément, et pour le monde entier.Et maintenant, beaucoup de code et de chiffres
Eh bien, maintenant, en fait, les mathématiques pour ceux qui veulent comprendre comment nous sommes arrivés aux conclusions énoncées ci-dessus. Ceux qui ne sont pas intéressés par des calculs ennuyeux ne peuvent pas lire plus loin.Les calculs ont été effectués en Python dans l'environnement Jupiter en utilisant des bibliothèques supplémentaires scipy, numpy, pandas, datetime. Pour la visualisation, nous avons utilisé le package matplotlib.pyplot. Les données initiales sur le nombre de décès ont été obtenues sur ce lien et prétraitées dans Excel. Information prise au 4 avril. Voici un lien vers le fichier avec les informations source .Donc, nous importons les bibliothèques, que nous utiliserons plus tard:import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
import pandas as pd
from IPython.display import display
import scipy as sp
from datetime import datetime
from scipy.optimize import minimize
Nous lisons les données source et les convertissons en un objet DataFrame. Les étiquettes de variables sont converties en un objet Timestamp. En principe, nous pourrions nous limiter à de simples tableaux numpy, mais nous utilisons un DataFrame pour la commodité de stocker des données avec leur date correspondante, et un horodatage pour la visualisation, pour afficher magnifiquement ces dates sur des graphiques.corona = pd.read_csv ('D: /coronavirus.csv',sep= ";")
corona.set_index (' Date ', inplace = True)
corona.index = pd.to_datetime (corona.index)
Ensuite, à partir d'un seul DataFrame, nous créons des variables de type Série qui correspondent à la mortalité totale dans chaque pays. X est une variable égale au nombre de jours depuis le début de l'année. Nous en aurons besoin lors des prévisions.X = corona['X']
chi = corona['China']
fr = corona['France']
ir = corona['Iran']
it = corona['Italy']
sp = corona['Spain']
uk = corona['UK']
us = corona['US']
bg = corona['Belgium']
gm = corona['Germany']
nt = corona['Netherlands']
sw = corona['Switzerland']
tot = corona['Total']
Après cela, nous calculons des tableaux numpy simples pour la mortalité à une date spécifique. Notez que la longueur d'un tel tableau est inférieure de 1 à la longueur de la variable Series correspondante.dchi = chi[1:].values - chi[:-1].values
dfr = fr[1:].values - fr[:-1].values
dit = it[1:].values - it[:-1].values
diran = ir[1:].values - ir[:-1].values
dsp = sp[1:].values - sp[:-1].values
duk = uk[1:].values - uk[:-1].values
dus = us[1:].values - us[:-1].values
dbg = bg[1:].values - bg[:-1].values
dgm = gm[1:].values - gm[:-1].values
dnt = nt[1:].values - nt[:-1].values
dsw = sw[1:].values - sw[:-1].values
dtot = tot[1:].values - tot[:-1].values
Nous introduisons une variable supplémentaire pour la prévision. Il s'agit d'un tableau qui commence le 20 janvier et se termine dans 180 jours le 17 juillet. Nous créons également un objet Timestamp correspondant à ce tableau pour signer les axes.X_long = np.arange(20, 200)
time_long = pd.date_range('2020-01-20', periods=180)
Nous définissons la fonction resLogistic, dont l'argument d'entrée est un tableau de 3 chiffres, et la sortie est la somme des carrés de la différence entre les valeurs de la courbe logistique et le nombre réel de décès dus à l'épidémie en Chine.def resLogistic(coefficents):
A0 = coefficents[0]
A1 = coefficents[1]
A2 = coefficents[2]
teor = A0 / (1 + np.exp(A1 * (X.ravel() - A2)))
return np.sum((teor - chi) ** 2)
Le nombre de décès est pris à chaque date comme un total cumulé. La courbe logistique est déterminée par 3 composantes du vecteur d'entrée. Zéro (le nombre d'éléments de tableau en Python commence à zéro) du composant est responsable de la valeur maximale, le premier caractérise le taux de croissance de la fonction, le second - la position du point d'inflexion sur l'axe du temps.teor - le nombre de décès pour chaque jour, basé sur le vecteur de paramètre d'entrée, chi - le nombre réel de décès en Chine. La fonction renvoie la somme des différences au carré entre la valeur théorique et la valeur réelle.Maintenant, en utilisant la méthode minimiser de la bibliothèque scipy.optimize, nous trouvons un vecteur qui minimise la somme des écarts au carré. La courbe logistique construite à partir de ce vecteur est la prévision de mortalité souhaitée réalisée sur la base de la méthode des carrés minimaux.Nous ajoutons que la méthode minimiser nécessite un point de départ. Nous le sélectionnons en fonction des propriétés de la fonction logistique que nous connaissons (le maximum doit être supérieur à tout nombre empirique de décès, et le point d'inflexion doit être proche du maximum de la courbe dtot caractérisant le nombre de nouveaux décès par jour). Habituellement, les résultats de la méthode de minimisation sont indépendants du point de départ, mais il existe des exceptions.mimim.x sont les valeurs du vecteur minimisant.minim = minimize(resLogistic, [3200, -.16, 46])
minim.x
Maintenant, nous affichons sur le graphique le nombre réel de décès, approximant sa courbe de prévision logistique, et signons également l'axe du temps avec les dates.plt.figure(figsize=(15,10))
teorChi = minim.x[0] / (1 + np.exp(minim.x[1] * (X_long - minim.x[2])))
plt.plot(X,chi,'ro', label=' ')
plt.plot(X_long[:80], teorChi[:80],'b', label=' ')
plt.xticks(X_long[:80][::2], time_long.date[:80][::2], rotation='90');
plt.title(' , ', Size=20);
plt.ylabel(' ')
plt.legend()
plt.grid()
Dans le graphique inférieur, nous traçons la dérivée première de la courbe logistique sélectionnée ci-dessus (ligne bleue), ainsi que la courbe réelle des nouveaux décès (ligne rouge).plt.figure(figsize = (15,10))
plt.grid()
plt.title(' , ', Size=20);
plt.plot(X[1:], dchi, 'r', Marker='o', label=' ')
plt.xticks(X_long[1:120][::3], time_long.date[1:120][::3], rotation='90');
plt.plot(X_long[1:120], teorChi[1:120] - teorChi[:119],'b', label=' ')
plt.ylabel(' ')
plt.legend()
Nous effectuons des calculs similaires pour chacun des pays mentionnés dans l'article.Ensuite, l'auteur a écrit un code pas très beau. Il était nécessaire d'écrire une fonction pour tous les pays et de lui transmettre le nombre de décès réels via les paramètres de la méthode minimiser. Mais l'auteur n'a pas eu le temps de traiter ce mécanisme, il a donc écrit sa propre fonction pour chaque pays, et à l'intérieur de la fonction, il a lancé un appel à une variable contenant des informations sur le nombre de décès dans un pays donné.Voici les calculs pour l'Iran, l'Italie, l'Espagne et les États-Unis. Pour restaurer les calculs pour les autres pays, les lecteurs, je pense, ne seront pas difficiles.def resLogisticIr(coefficents):
A0 = coefficents[0]
A1 = coefficents[1]
A2 = coefficents[2]
teor = A0 / (1 + np.exp(A1 * (X.ravel() - A2)))
return np.sum((teor - ir) ** 2)
minim = minimize(resLogisticIr, [3200, -.16, 80])
minim.x
plt.figure(figsize=(15,10))
teorIr = minim.x[0] / (1 + np.exp(minim.x[1] * (X_long - minim.x[2])))
plt.plot(X_long[:120], teorIr[:120],'b', label=' ')
plt.xticks(X_long[:120][::3], time_long.date[:120][::3], rotation='90');
plt.title(' , ', Size=20);
plt.plot(X,ir,'ro', label=' ')
plt.grid()
plt.legend()
plt.ylabel(' ')
plt.figure(figsize = (15,10))
plt.grid()
plt.title(' , ', Size=20);
plt.plot(X[1:], diran, 'r', Marker='o', label=' ')
plt.plot(X[1:], diran, 'ro')
plt.xticks(X_long[1:120][::3], time_long.date[1:120][::3], rotation='90');
plt.plot(X_long[1:120], teorIr[1:120] - teorIr[:119],'b', label=' ')
plt.ylabel(' ')
plt.legend()
def resLogisticIt(coefficents):
A0 = coefficents[0]
A1 = coefficents[1]
A2 = coefficents[2]
teor = A0 / (1 + np.exp(A1 * (X.ravel() - A2)))
return np.sum((teor - it) ** 2)
minim = minimize(resLogisticIt, [3200, -.16, 46])
minim.x
plt.figure(figsize=(15,10))
teorIt = minim.x[0] / (1 + np.exp(minim.x[1] * (X_long - minim.x[2])))
plt.plot(X,it,'ro', label=' ')
plt.plot(X_long[:120], teorIt[:120],'b', label=' ')
plt.xticks(X_long[:120][::3], time_long.date[:120][::3], rotation='90');
plt.title(' , ', Size=20);
plt.ylabel(' ')
plt.grid()
plt.legend()
plt.figure(figsize = (15,10))
plt.grid()
plt.title(' , ', Size=20);
plt.plot(X[1:], dit, 'r', Marker='o', label=' ')
plt.xticks(X_long[1:120][::3], time_long.date[1:120][::3], rotation='90');
plt.plot(X_long[1:120], teorIt[1:120] - teorIt[:119],'b', label=' ')
plt.ylabel(' ')
plt.legend()
def resLogisticSp(coefficents):
A0 = coefficents[0]
A1 = coefficents[1]
A2 = coefficents[2]
teor = A0 / (1 + np.exp(A1 * (X.ravel() - A2)))
return np.sum((teor - sp) ** 2)
minim = minimize(resLogisticSp, [3200, -.16, 80])
minim.x
plt.figure(figsize=(15,10))
teorSp = minim.x[0] / (1 + np.exp(minim.x[1] * (X_long - minim.x[2])))
plt.plot(X_long[:120], teorSp[:120],'b', label=' ')
plt.xticks(X_long[:120][::3], time_long.date[:120][::3], rotation='90');
plt.title(' , ', Size=20);
plt.plot(X,sp,'ro', label=' ')
plt.grid()
plt.legend()
plt.ylabel(' ')
plt.figure(figsize = (15,10))
plt.grid()
plt.plot(X[1:], dsp, 'r', Marker='o', label=' ')
plt.plot(X[1:], dsp, 'ro')
plt.xticks(X_long[1:120][::3], time_long.date[1:120][::3], rotation='90');
plt.title(' , ', Size=20);
plt.plot(X_long[1:120], teorSp[1:120] - teorSp[:119],'b', label=' ')
plt.ylabel(' ')
plt.legend()
def resLogisticUs(coefficents):
A0 = coefficents[0]
A1 = coefficents[1]
A2 = coefficents[2]
teor = A0 / (1 + np.exp(A1 * (X.ravel() - A2)))
return np.sum((teor - us) ** 2)
minim = minimize(resLogisticUs, [3200, -.16, 100])
minim.x
plt.figure(figsize=(15,10))
teorUS = minim.x[0] / (1 + np.exp(minim.x[1] * (X_long - minim.x[2])))
plt.plot(X_long[:120], teorUS[:120],'b', label=' ')
plt.xticks(X_long[:120][::3], time_long.date[:120][::3], rotation='90');
plt.title(' , ', Size=20);
plt.plot(X,us,'ro', label=' ')
plt.grid()
plt.legend()
plt.ylabel(' ')
plt.figure(figsize = (15,10))
plt.grid()
plt.title(' , ', Size=20);
plt.plot(X[1:], dus, 'r', Marker='o', label=' ')
plt.plot(X[1:], dus, 'ro')
plt.xticks(X_long[1:120][::3], time_long.date[1:120][::3], rotation='90');
plt.plot(X_long[1:120], teorUS[1:120] - teorUS[:119],'b', label=' ')
plt.ylabel(' ')
plt.legend()