Très souvent, pour mes 15 années d'expérience en tant que développeur de logiciels et chef d'équipe, je rencontre la même chose. La programmation se transforme en religion - rarement quelqu'un essaie d'introduire une technologie basée sur un choix raisonnable, raisonnablement, en tenant compte des restrictions, de la portabilité, de l'évaluation du degré d'attachement au vendeur, du prix réel, des perspectives de la technologie et de la liberté de licence. Les développeurs vont à des conférences ou lisent des articles - commencez à faire du battage médiatique, et leurs directeurs et directeurs informatiques sont nourris non seulement avec des histoires d'un brillant avenir agile lors d'événements, de visionnaires divers, de ventes et de consultants. Et il s'avère que les technologies étaient dans le projet, ne tenant pas compte de la commodité du développement et de la mise en œuvre, des exigences non fonctionnelles du projet, mais parce qu'il est hype et que Google se sert lui-même,amazon recommande (bien que leurs postes vacants indiquent qu'ils ne l'utilisent pas souvent eux-mêmes) ou la décision la plus élevée a été prise par la direction de l'entreprise pour mettre en œuvre "this".
Ce qui affecte le choix de la base de données
De mon point de vue, lors du choix d'une base de données, je dois résoudre au moins les compromis suivants:- traitement des transactions en temps réel ou traitement analytique en ligne
- évolutif verticalement ou horizontalement
- dans le cas d'une base distribuée - cohérence des données / disponibilité / résistance de séparation (théorème CAP)
- un schéma de données spécifique et des restrictions dans la base de données ou le stockage qui ne nécessitent pas de schéma de données
- modèle de données - valeur-clé, hiérarchique, graphique, document ou relationnel
- une logique de traitement au plus proche des données ou de tous les traitements dans l'application
- travailler principalement en RAM ou avec un sous-système de disque
- solution universelle ou spécialisée
- nous utilisons l'expertise existante sur une base de données qui n'est pas particulièrement adaptée aux exigences du projet ou nous en développons une nouvelle dans une formation appropriée mais pas familière, «sang et sueur» (il en va de même non seulement pour le développement, mais aussi pour l'exploitation)
- intégré ou dans un autre processus / réseau
- hipster ou rétrograde
Souvent, nous obtenons un «cadeau» pour la solution mise en œuvre:- Langage de requête «étranger»
- la seule API native pour travailler avec la base de données, ce qui compliquera la transition vers d'autres bases de données (temps, effort d'équipe et budget du projet ont été dépensés)
- indisponibilité de pilotes pour d'autres plates-formes / langues / systèmes d'exploitation
- manque de codes sources, de descriptions du format des données sur le disque (ou interdiction des licences de reverse engineering, notamment Oracle avec le buggy Coherence)
- croissance des coûts de licence d'année en année
- propre écosystème et difficulté à trouver des spécialistes
- , ,
La mise à l'échelle horizontale des systèmes est assez complexe et nécessite l'expertise de l'équipe. Les développeurs expérimentés sont assez chers sur le marché, les applications distribuées sont plus difficiles à développer, déboguer et tester. Par conséquent, s'il est possible de changer le serveur pour un serveur plus puissant et la quantité de données autorisée par le système, ils le font souvent. Désormais, les serveurs peuvent contenir des téraoctets de RAM et des centaines de cœurs de processeur. Ainsi, comme jamais auparavant, il devient important d'utiliser toutes les ressources du serveur aussi efficacement que possible. Le coût des licences de base de données est également important, et si elles sont vendues par des cœurs de processeur, le budget d'exploitation, même avec une mise à l'échelle verticale, peut coûter autant qu'un programme spatial de superpuissance. Par conséquent, il est important de garder cela à l'esprit afin de ne pas être en mesure de faire évoluer les performances de la base de données en raison des licences.Il est clair qu'avec l'aide du marketing, ils essaieront de vous convaincre que seule la solution d'une certaine entreprise résoudra tous vos problèmes (mais ils ne disent pas combien de nouveaux apparaîtront). Il n'y a pas de base de données idéale qui convienne à tout le monde et convient à tout.Donc, dans un avenir prévisible, nous continuerons à prendre en charge plusieurs bases de données différentes pour traiter les mêmes données pour différents types de requêtes dans différents systèmes. Pas de solutions pour Data Fabric sans mise en cache des données, Data Lake ne peut pas encore être comparé à des bases de données avec une architecture de masse parallèle en termes de performances et d'optimalité des requêtes. Les données transactionnelles seront toujours stockées dans PostgreSQL, Oracle, MS SQL Server, les requêtes analytiques dans Citus, Greenplum, Snowflake, Redshift, Vertica, Impala, Teradata et les marécages de données brutes dans HDFS / S3 / ADLS (Azure) seront gérés par Dremio , Redshift Spectrum, Apache Spark, Presto.Mais les solutions répertoriées ci-dessus sont mal adaptées à l'analyse de données de séries chronologiques avec un temps de réponse faible. Selon sa popularité à travailler avec des données de séries chronologiques, il est maintenant dans les favoris d'InfluxDB. Dans le créneau des bases de données en mémoire, kdb + et memSQL gardent leur place.QuestDB
Qu'est-ce qui peut opposer toutes ces solutions open source QuestDB avec une licence Apache?- Une tentative de tirer le meilleur parti du matériel pour effectuer des requêtes analytiques - vectorisation des fonctions d'agrégation, travailler avec des données via des fichiers mappés en mémoire
- SQL comme langage des requêtes DML et des opérations DDL pour gérer la structure de la base de données
- prise en charge des tables de jointure spécifiques aux séries chronologiques DB
- prise en charge des fonctions de fenêtre et d'agrégation dans SQL
- la possibilité d'incorporer une base de données dans une application sur la JVM
- JVM, ServiceLoader
- Influx DB line protocol (ILP) UDP Telegraf. «What makes QuestDB faster than InfluxDB»
- PostgreSql 11 PostgreSQL: JDBC, ODBC psql
- web - REST endpoint , SQL json
- ,
- zero-GC API, .
- ( )
- 64 Windows, Linux, OSX, ARM Linux FreeBSD
- , open source,
Lorsque cette base de données peut vous être utile - si vous développez des systèmes financiers sur la JVM avec une faible latence et que vous avez besoin d'une solution pour l'analyse de données en RAM. En remplacement de kdb + en raison du coût des licences. Si vous collectez des métriques selon le protocole Influx / Telegraf, mais les performances et la convivialité de travailler avec InfluxDB ne sont pas satisfaisantes. Si votre projet s'exécute sur la JVM et que vous avez besoin d'une base de données intégrée pour stocker des métriques ou des données d'application qui sont uniquement ajoutées et non mises à jour.La nouvelle version 4.2.0 avec prise en charge des instructions SIMD a provoqué une vague de commentaires sur Reddit . Pour que les fans participent au concours de la connaissance du matériel moderne et de sa programmation efficace, je recommande de discuter avec l'auteur de la base de données (bluestreak01) dans les commentaires!Opérations SIMD
L'équipe de projet a effectué un test sur des données synthétiques et a comparé QuestDB 4.2.0 avec kdb 4.0 pour agréger un milliard de valeurs, en exploitant les instructions SIMD des processeurs.Sur la plate-forme Intel 8850H: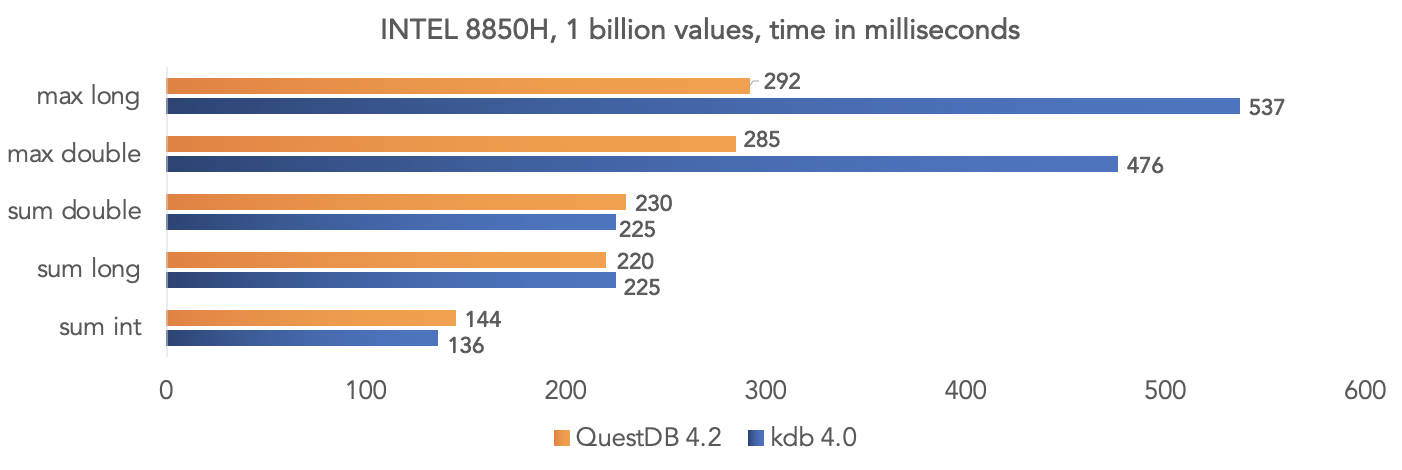 Sur la plate-forme AMD Ryzen 3900X:
Sur la plate-forme AMD Ryzen 3900X: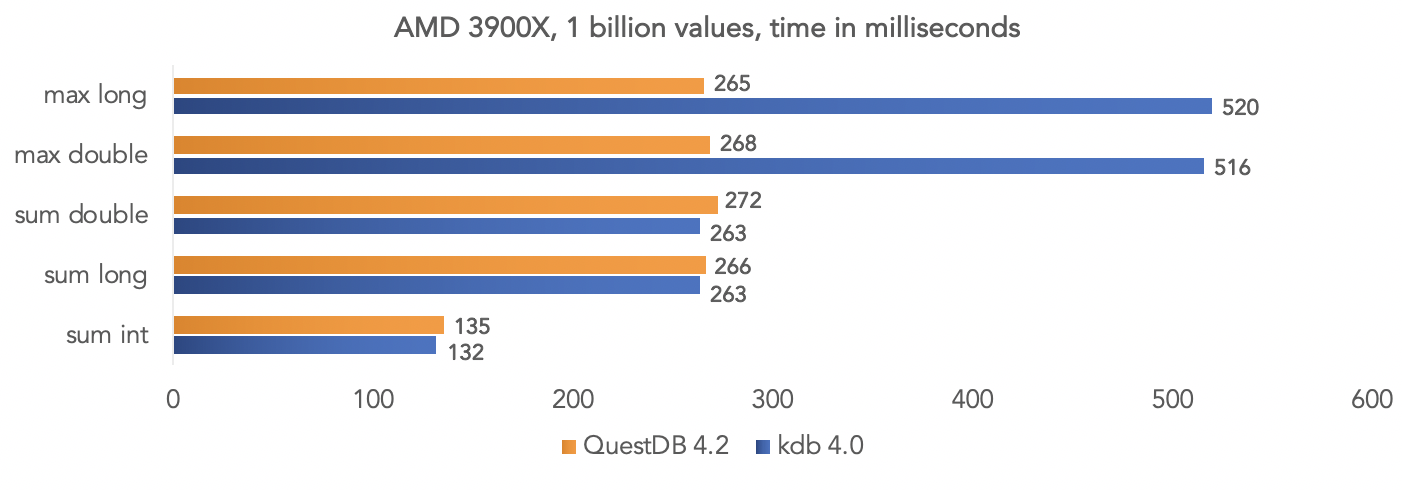 Il est clair que ce sont tous des tests dans un «vide», mais vous pouvez comparer vos données si votre projet utilise kdb et partager les résultats avec la communauté.
Il est clair que ce sont tous des tests dans un «vide», mais vous pouvez comparer vos données si votre projet utilise kdb et partager les résultats avec la communauté.Exécution de l'image de la base de données Docker
La base de données est publiée sur dockerhub avec chaque version. Plus de détails sont décrits dans la documentation du projet .Obtenez l'image QuestDB:docker pull questdb/questdb
Nous lançons:docker run --rm -it -p 9000:9000 -p 8812:8812 questdb/questdb
Après cela, vous pouvez vous connecter en utilisant le protocole PostgreSQL au port 8812, la console Web est disponible sur le port 9000.Accès jdbc
Selon notre projet, nous ajoutons le pilote PostrgreSQL jdbc org.postgresql: postgresql: 42.2.12 , pour ce test j'utilise mon module QuestDB pour les testcontainers . Le test est disponible sur github avec le script de build:import org.junit.jupiter.api.Test;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.Statement;
import static org.assertj.core.api.Assertions.*;
public class QuestDbDriverTest {
@Test
void containerIsUpTestByJdbcInvocation() throws Exception {
try (Connection connection = DriverManager.getConnection("jdbc:tc:questdb:///?user=admin&password=quest")){
try (Statement statement = connection.createStatement()){
try (ResultSet resultSet = statement.executeQuery("select 42 from long_sequence(1)")){
resultSet.next();
assertThat(resultSet.getInt(1)).isEqualTo(42);
}
}
}
}
}
L'exécution de docker entraîne une surcharge supplémentaire, et cela peut être évité en implémentant simplement org.questdb: core: jar: 4.2.0 en tant que dépendance du projet et en exécutant io.questdb.ServerMain:import io.questdb.ServerMain;
import org.junit.jupiter.api.Test;
import org.junit.jupiter.api.io.TempDir;
import java.nio.file.Path;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.Statement;
public class QuestDbJdbcTest {
@Test
void embeddedServerStartTest(@TempDir Path tempDir) throws Exception{
ServerMain.main(new String[]{"-d", tempDir.toString()});
try (DriverManager.getConnection("jdbc:postgresql://localhost:8812/", "admin", "quest")){
try (Statement statement = connection.createStatement()){
try (ResultSet resultSet = statement.executeQuery("select 42 from long_sequence(1)")){
resultSet.next();
assertThat(resultSet.getInt(1)).isEqualTo(42);
}
}
}
}
}
Intégration dans une application Java
Mais c'est le moyen le plus rapide de travailler avec la base de données à l'aide de l'API Java inprocess:import io.questdb.cairo.CairoEngine;
import io.questdb.cairo.DefaultCairoConfiguration;
import io.questdb.griffin.CompiledQuery;
import io.questdb.griffin.SqlCompiler;
import io.questdb.griffin.SqlExecutionContextImpl;
import org.junit.jupiter.api.Test;
import org.junit.jupiter.api.io.TempDir;
import java.nio.file.Path;
public class TruncateExecuteTest {
@Test
void truncate(@TempDir Path tempDir) throws Exception{
SqlExecutionContextImpl executionContext = new SqlExecutionContextImpl();
DefaultCairoConfiguration configuration = new DefaultCairoConfiguration(tempDir.toAbsolutePath().toString());
try (CairoEngine engine = new CairoEngine(configuration)) {
try (SqlCompiler compiler = new SqlCompiler(engine)) {
CompiledQuery createTable = compiler.compile("create table tr_table(id long,name string)", executionContext);
compiler.compile("truncate table tr_table", executionContext);
}
}
}
}
Console Web
Le projet comprend une console Web pour interroger QuestDB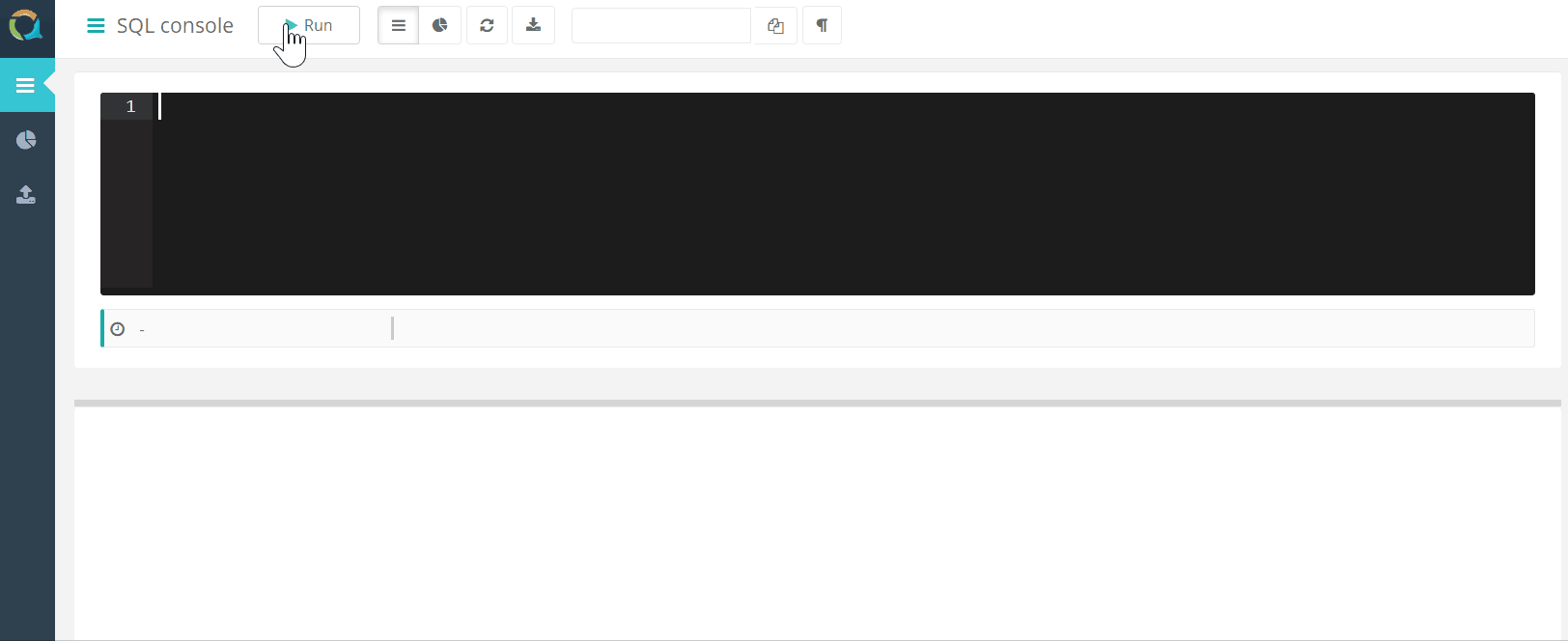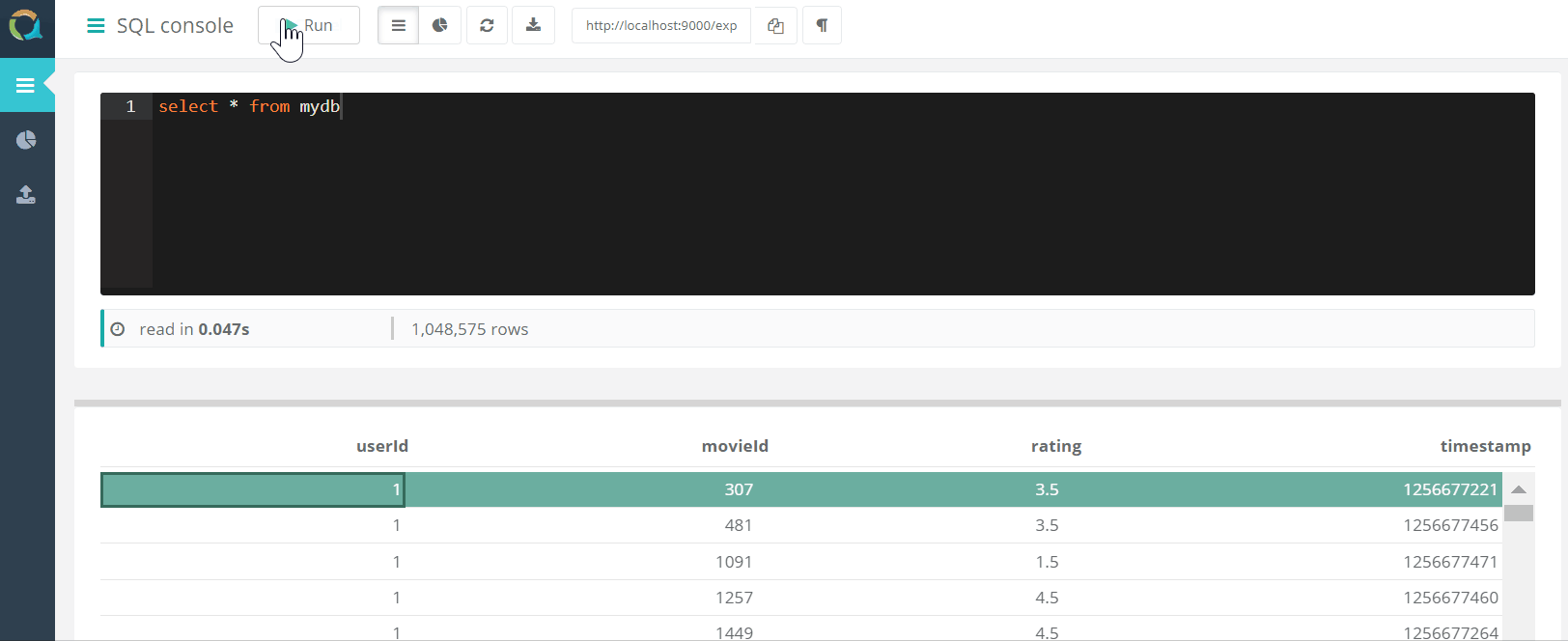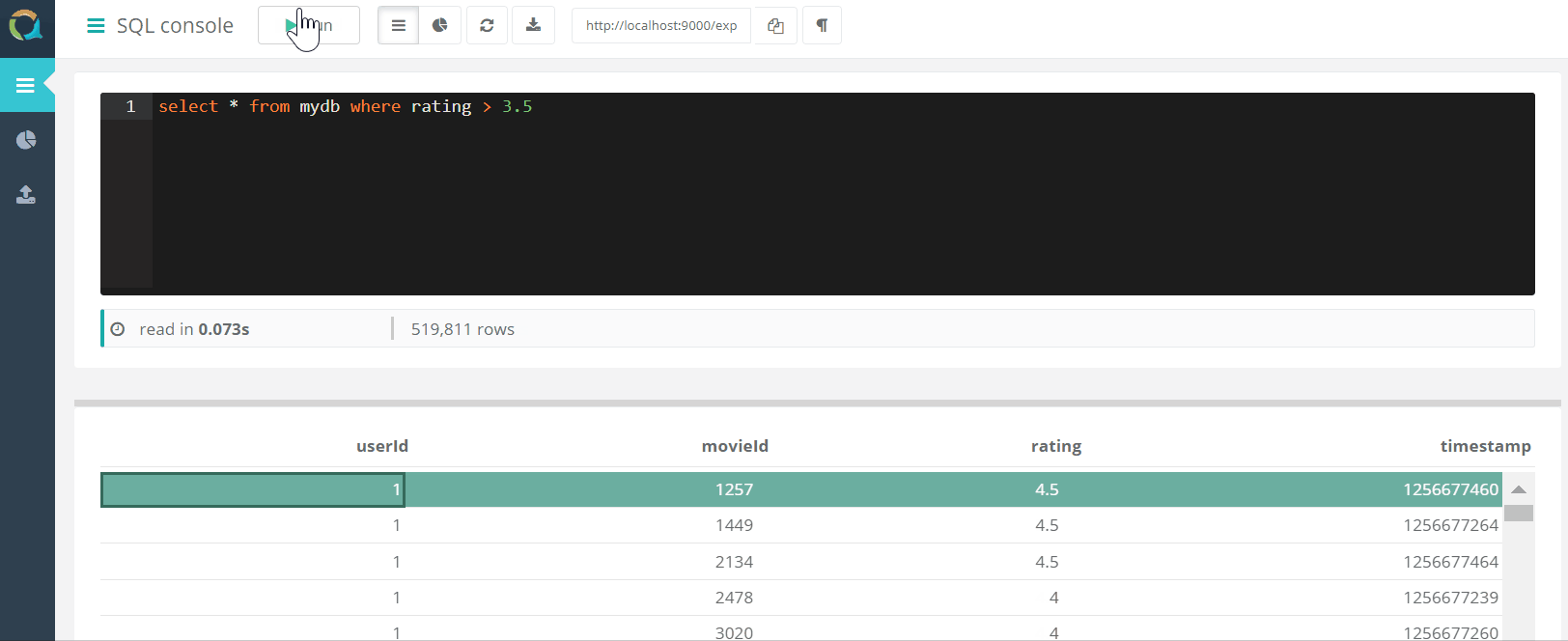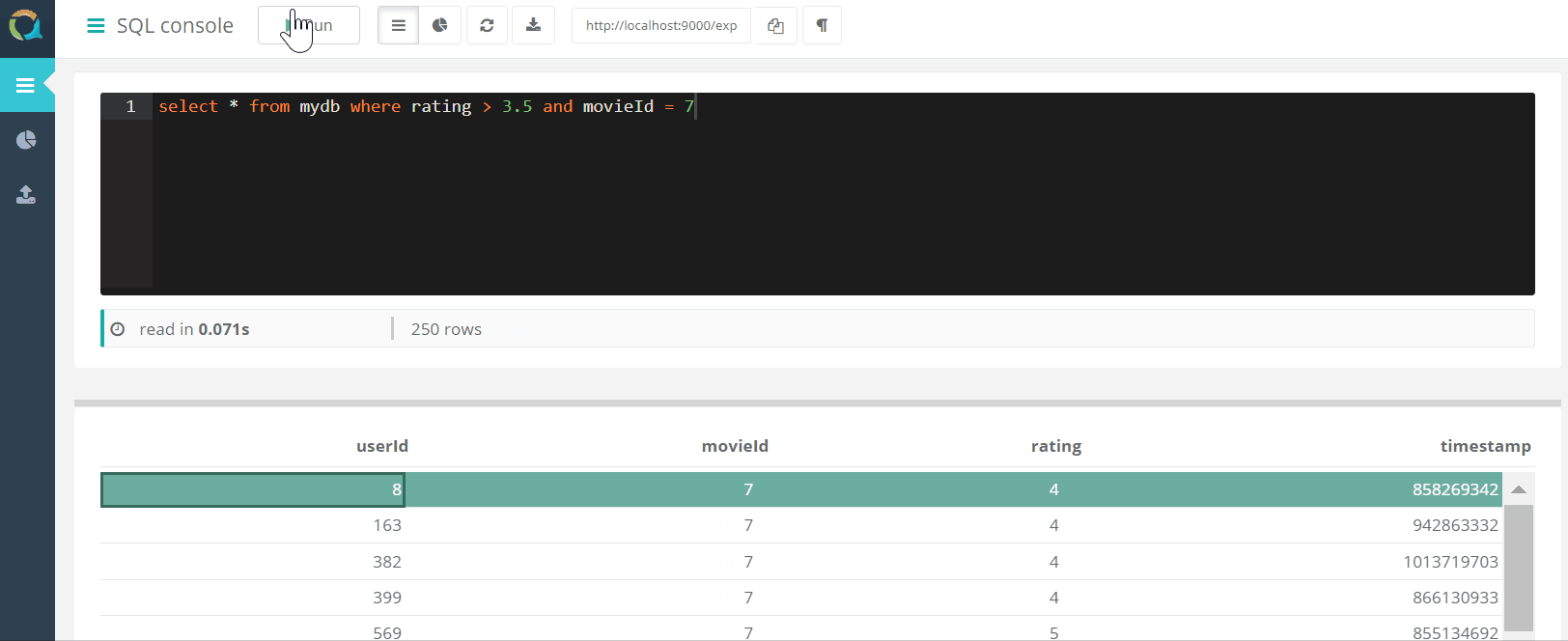 ET télécharger des données vers une base de données au format csv via un navigateur.
ET télécharger des données vers une base de données au format csv via un navigateur.
Avez-vous besoin d'une autre base de données?
Ce projet est jeune et manque encore de certaines caractéristiques de l'entreprise, mais il se développe assez rapidement et plusieurs contributeurs travaillent activement sur le projet. Je suis QuestDB depuis août dernier et j'ai développé quelques extensions pour ce projet ( fonction jdbc et osquery ), et j'ai également intégré ce projet avec des conteneurs de test. Maintenant, j'essaie de résoudre mes problèmes actuels dans Dremio avec le téléchargement incrémentiel de données, le partitionnement des données et de longues transactions vers les sources de données en production en utilisant QuestDB, en le complétant avec des fonctions d'exportation de données. J'ai l'intention de partager mon expérience dans les publications suivantes. Cela me soudoie surtout que je peux déboguer mes fonctions et ma base de données sur la plateforme que je connais, écrire des tests unitaires qui s'exécutent à la vitesse de la lumière.Vous décidez en tant que développeur expérimenté. Encore une fois, QuestDB ne remplace pas les bases de données OLTP - PostgreSQL, Oracle, MS SQL Server, DB2 ou même un remplacement H2 pour les testsdans la JVM. Il s'agit d'une puissante base de données open source spécialisée prenant en charge les protocoles réseau PostgreSQL, Influx / Telegraf. Si votre scénario d'utilisation correspond aux fonctionnalités qui y sont implémentées et au scénario principal d'utilisation d'une base de données de colonnes, alors le choix est justifié!