Étant donné que j'ai rencontré des difficultés importantes pour trouver une explication du mécanisme de propagation arrière de l'erreur que j'aimerais, j'ai décidé d'écrire mon propre article sur la propagation arrière de l'erreur en utilisant l'algorithme Word2Vec. Mon objectif est d'expliquer l'essence de l'algorithme à l'aide d'un réseau neuronal simple mais non trivial. De plus, word2vec est devenu si populaire dans la communauté NLP qu'il sera utile de s'y concentrer.
Cet article est lié à un autre article plus pratique que je recommande de lire, il traite de l'implémentation directe de word2vec en python. Dans cet article, nous nous concentrerons principalement sur la partie théorique.
Commençons par les choses nécessaires à une véritable compréhension de la rétropropagation. En plus des concepts de l'apprentissage automatique, tels que la fonction de perte et la descente de gradient, deux autres composants mathématiques sont utiles:
Si vous connaissez ces concepts, d'autres considérations seront simples. Si vous ne les maîtrisez pas encore, vous pouvez toujours comprendre les bases de la rétropropagation.
Tout d'abord, je veux définir le concept de rétropropagation, si le sens n'est pas assez clair, il sera divulgué plus en détail dans les paragraphes suivants.
1. Qu'est-ce qu'un algorithme de rétropropagation?
Dans le cadre d'un réseau neuronal, les seuls paramètres impliqués dans l'entraînement du réseau, c'est-à-dire pour minimiser la fonction de perte, sont les poids (ici je veux dire les poids au sens large, y compris les déplacements). Les poids changent à chaque itération jusqu'à atteindre le minimum de la fonction de perte.
, — , , .
, , .
, , , , w1 w2.

1. .
, w1 w2 .
, . , ∂ L / ∂ w 1 ∂ L / ∂ w 2, , . η, .
2. Word2Vec
word2vec, , , . , word2vec, NLP.
, word2vec [N, 3], N - , . , , '', , ( ), , ''. , word2vec .
word2vec : (CBOW) (skip-gram). , CBOW, , skip-gram.
. , woed2vec .
3. CBOW
CBOW . , :
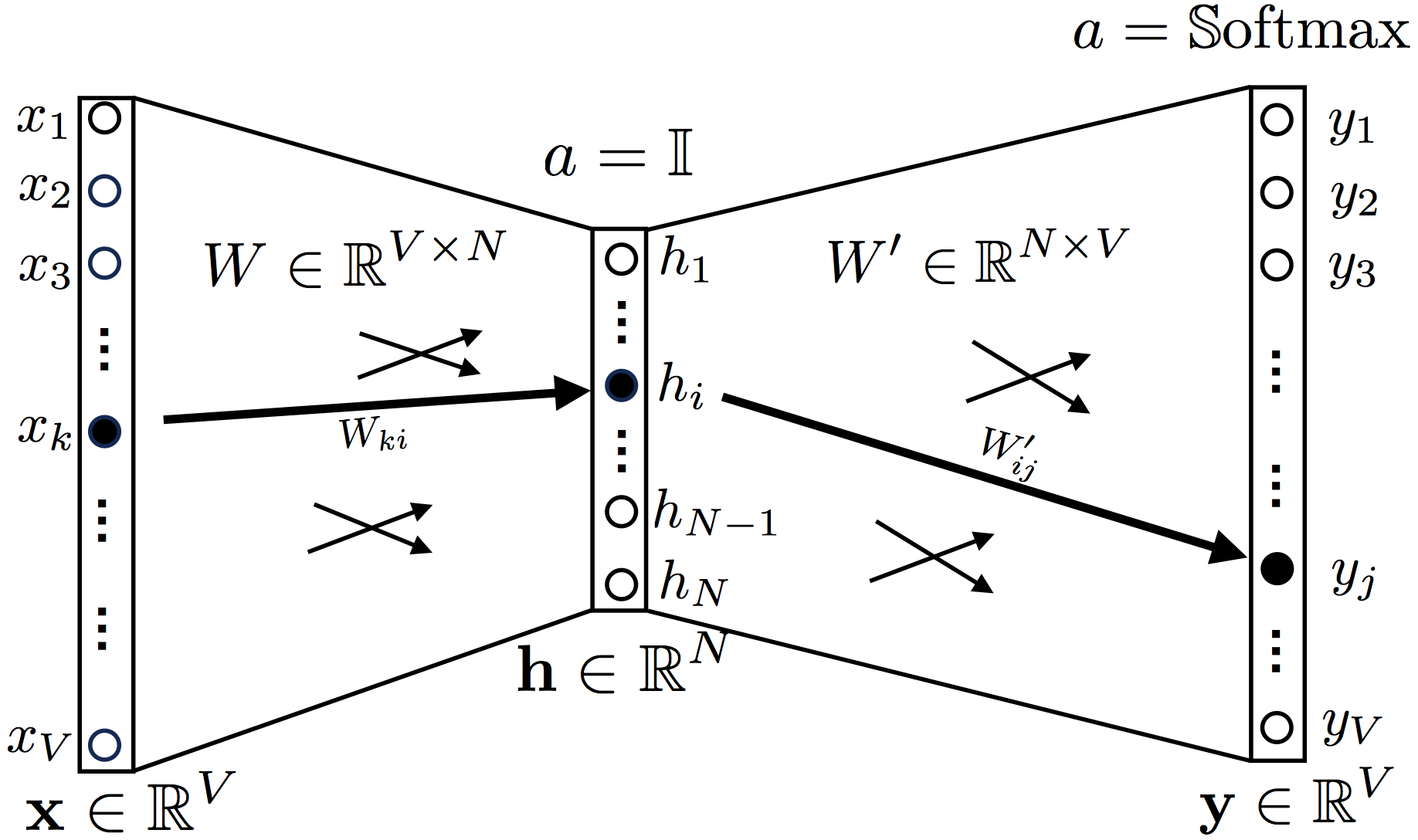
2. Continuous Bag-of-Words
, ,
a = 1 (identity function, , ).
Softmax.
one hot encoding , , , , , 1.
: ['', '', '', '', '', '']
OneHot('') = [0, 0, 0, 1, 0, 0]
OneHot(['', '']) = [1, 0, 0, 1, 0, 0]
OneHot(['', '', '']) = [1, 0, 0, 0, 1, 1]
, W V × n, W ′ N × V, V — , N — ( , word2vec)
y t, , , , , .
, .
, word2vec :
"I like playing football"
CBOW (2) .
, 4 , V=4, , N=2, :
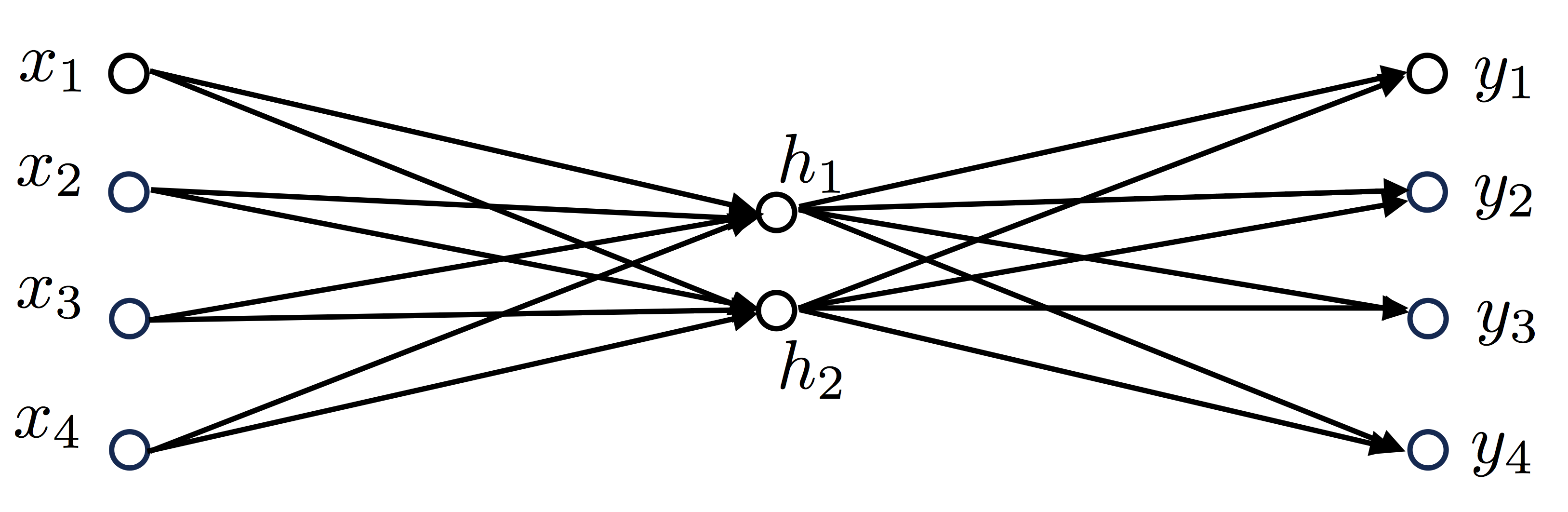
:
Vocabulary=[“I”,“like”,“playing”,“football”]
'' '' , . :

:
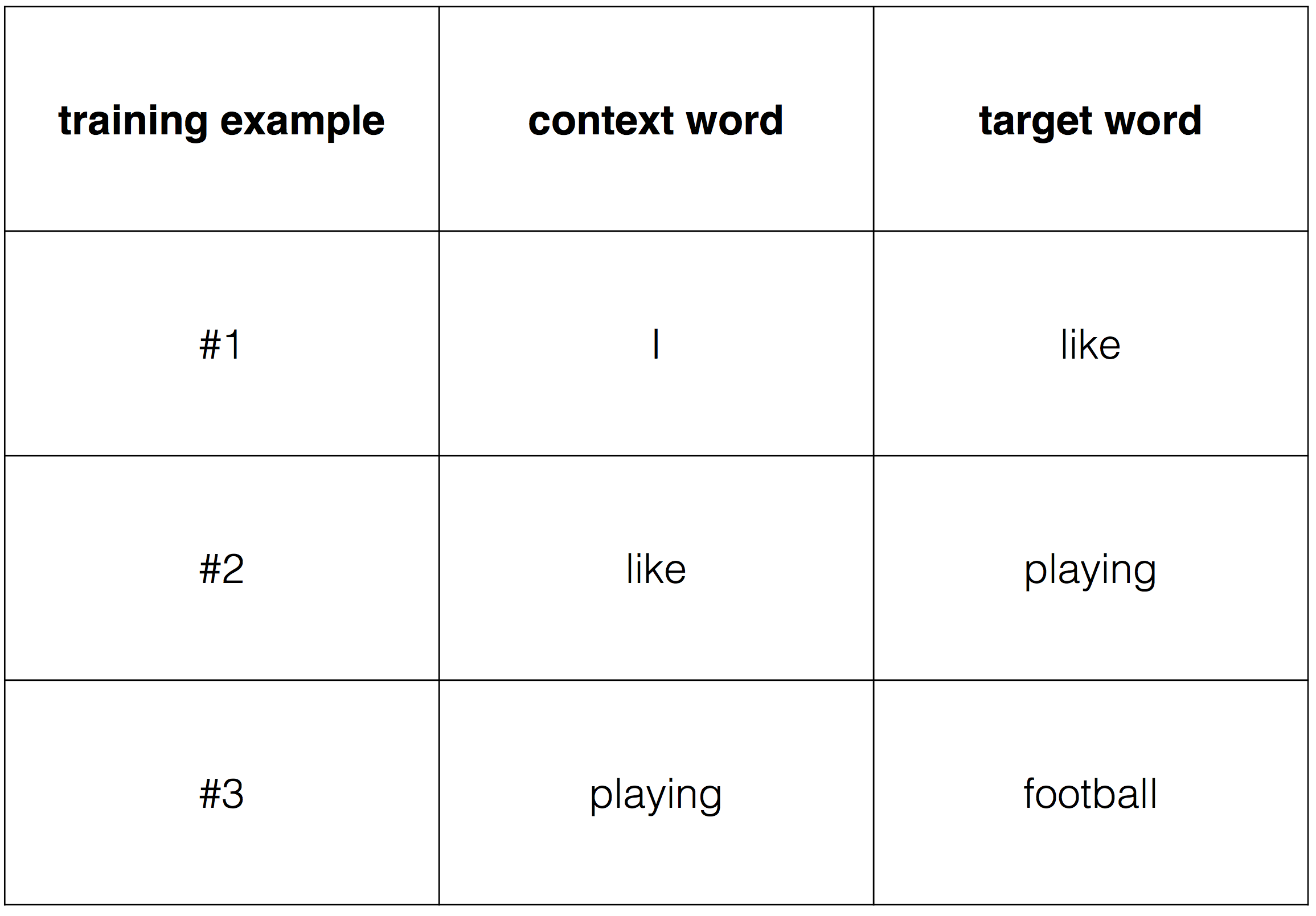
, one-hot encoding.
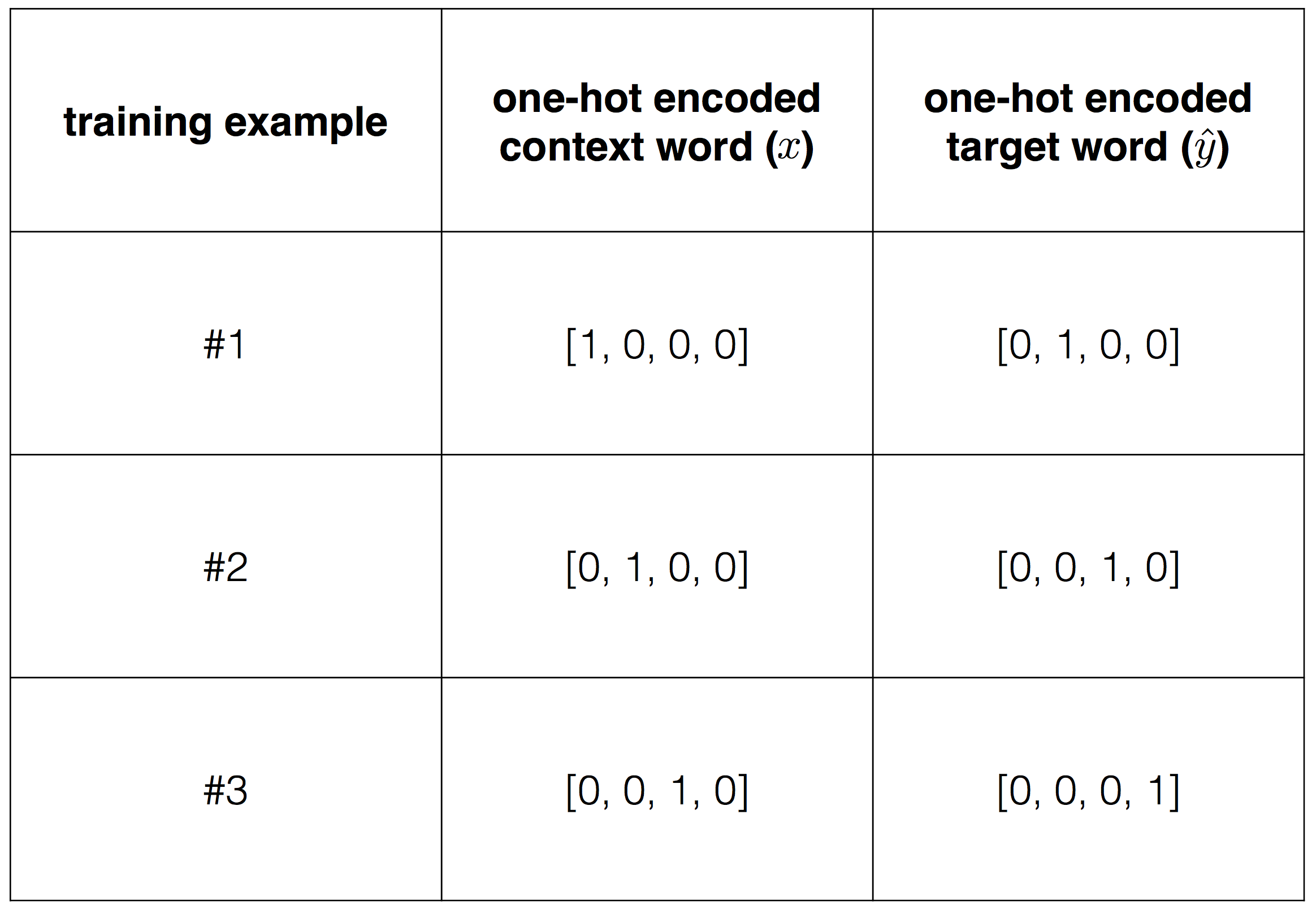
, , , . , , .
3.1 (Loss function)
1, , x:
h = W T xu = W ′ T h = W ′ T W T xy = S oftmax ( u ) = S oftmax ( W ′ T W T x )
, h — , u — , y — .
, , , (wt, wc). , onehot encoding .
, onehot wt ( ).
softmax , :
, j* — .
. (1):
.
"I like play football", , "I" "like", , x=(1,0,0,0) — "I", ˆy=(0,1,0,0), "like".
word2vec, . W 4×2
W=(−1.381187280.548493730.39389902−1.1501331−1.169676280.360780220.06676289−0.14292845)
W′ 2×4
W′=(1.39420129−0.894417570.998696670.444470370.69671796−0.233643410.21975196−0.0022673)
"I like" :
h=WTx=(−1.381187280.54849373)
u=W′Th=(−1.543507651.10720623−1.25885456−0.61514042)
y=Softmax(u)=(0.052565670.74454790.069875590.13301083)
y,
L=−logP(“like”|“I”)=−logy3=−log(0.7445479)=0.2949781.
, (1):
L=−u2+log4∑i=1ui=−1.10720623+log[exp(−1.54350765)+exp(1.10720623)+exp(−1.25885456)+exp(−0.61514042)]=0.2949781.
, "like play", , .
3.2 CBOW
, , W W` . , .
. (1) W W`. ∂L/∂W ∂L/∂W′
, . (1) W W`, u=[u1, ...., uV],
:
, (2) (3) .
(2), Wij, W, i j , uj ( yj).
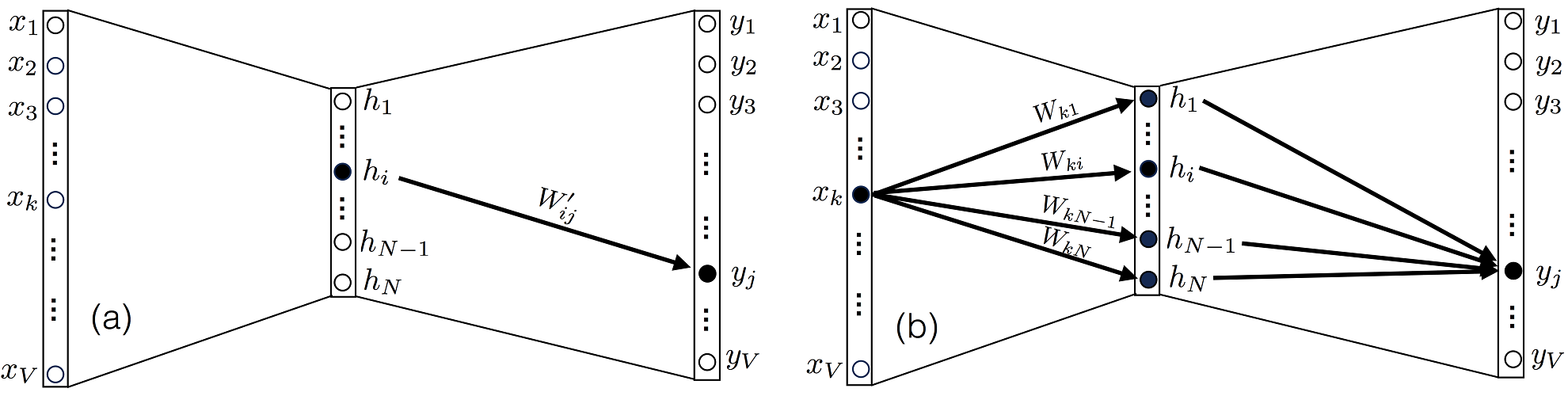
3. (a) yj hi W′ij W′. (b) , xk N Wk1…WkN W.
, ∂uk/∂W′ij, , k=j, 0.
(4):
∂L/∂uj, (5):
, δjj∗ — , , 1, , 0 .
(5) e N ( ), , , .
(4) (6):
(5) (6) (4) (7):
∂L/∂Wij, Xk, yj j W , 3(b). . ∂uk/∂Wij, uk u :
∂uk/∂Wij, l=i m=j, (8):
(5) (8) , (9):
. (7) (9) . (7)
⊗ .
(9) :
3.3
, (7) (9), , . . η>0, :
Wnew=Wold−η∂L∂WW′new=W′old−η∂L∂W′
3.4
. , . , . , . , , , .
4. CBOW
CBOW . . (4) . OneHot Encoded . word2vec. .

4. CBOW
CBOW CBOW .
h=1CWTC∑c=1x(c)=WT¯xu=W′Th=1CC∑c=1W′TWTx(c)=W′TWT¯xy= Softmax(u)=Softmax(W′TWT¯x)
, '' ¯x=∑Cc=1x(c)/C
, . :
, :
CBOW , , . W′ij
Wij:
:
(17) (18) .
(17) :
(18):
, CBOW .
⊗ .
5. Skip-gram
CBOW, , . :
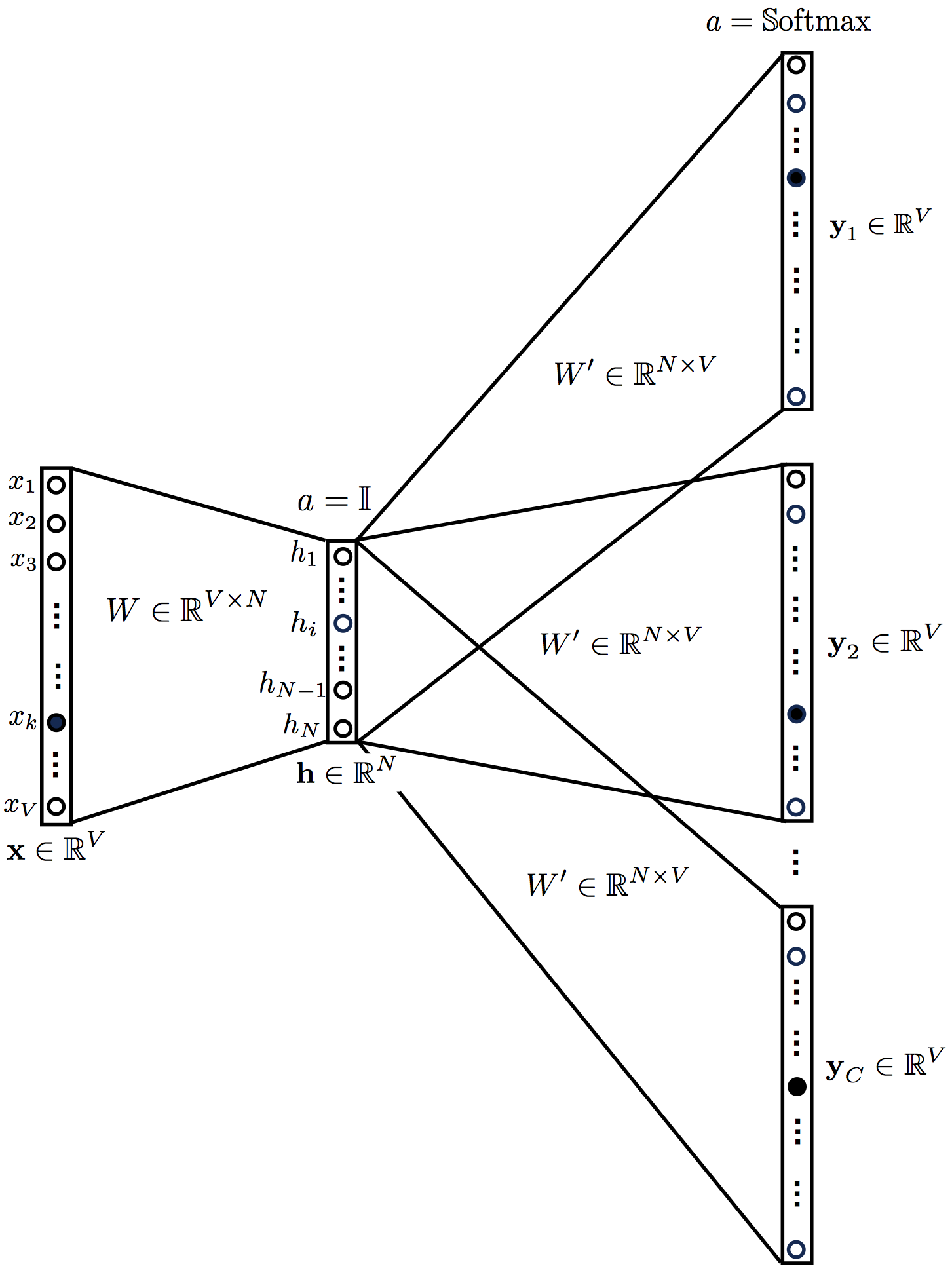
5. Skip-gram .
skip-gram :
h=WTxuc=W′Th=W′TWTxc=1,…,Cyc= Softmax(u)=Softmax(W′TWTx)c=1,…,C
( uc) , y1=y2⋯=yC. :
L=−logP(wc,1,wc,2,…,wc,C|wo)=−logC∏c=1P(wc,i|wo)=−logC∏c=1exp(uc,j∗)∑Vj=1exp(uc,j)=−C∑c=1uc,j∗+C∑c=1logV∑j=1exp(uc,j)
skip-gram C×V
:
:
∂L/∂uc,j, :
CBOW :
Wij , :
, skip-gram :
(21):
(22):
6.
word2vec. . [2] ( softmax, negative sampling), . [1].
, word2vec.
L'étape suivante consiste à implémenter ces équations dans votre langage de programmation préféré. Si vous aimez Python, j'ai déjà implémenté ces équations dans mon prochain post .
Espérons vous y voir!
Liens annexes
[1] X. Rong, Word2vec Parameter Learning Explained , arXiv: 1411.2738 (2014).
[2] T. Mikolov, K. Chen, G. Corrado, J. Dean, Efficient Estimation of Word Representations in Vector Space , arXiv: 1301.3781 (2013).