Cet article sera utile à ceux qui viennent de se familiariser avec l'architecture des microservices et le service Apache Kafka. Le matériel ne prétend pas être un tutoriel détaillé, mais vous aidera à démarrer rapidement avec cette technologie. Je vais vous expliquer comment installer et configurer Kafka sur Windows 10. Nous allons également créer un projet en utilisant Intellij IDEA et Spring Boot.Pourquoi?
Les difficultés à comprendre divers outils sont souvent associées au fait que le développeur n'a jamais rencontré de situations dans lesquelles ces outils peuvent être nécessaires. Avec Kafka, c'est exactement la même chose. Nous décrivons la situation dans laquelle cette technologie sera utile. Si vous avez une architecture d'application monolithique, vous n'avez bien sûr pas besoin de Kafka. Tout change avec le passage aux microservices. En fait, chaque microservice est un programme distinct qui remplit l'une ou l'autre fonction et qui peut être lancé indépendamment des autres microservices. Les microservices peuvent être comparés aux employés du bureau, qui sont assis à des bureaux séparés et résolvent indépendamment leur problème. Le travail d'une telle équipe répartie est impensable sans coordination centrale.Les employés devraient pouvoir échanger des messages et les résultats de leur travail. Apache Kafka pour microservices est conçu pour résoudre ce problème.Apache Kafka est un courtier de messages. Avec lui, les microservices peuvent interagir les uns avec les autres, envoyant et recevant des informations importantes. La question se pose, pourquoi ne pas utiliser le POST-reqest régulier à ces fins, dans le corps duquel vous pouvez transférer les données nécessaires et obtenir la réponse de la même manière? Cette approche présente un certain nombre d'inconvénients évidents. Par exemple, un producteur (un service qui envoie un message) ne peut envoyer des données que sous la forme d'une réponse en réponse à une demande d'un consommateur (un service qui reçoit des données). Supposons qu'un consommateur envoie une demande POST et que le producteur y réponde. Pour le moment, pour une raison quelconque, le consommateur ne peut accepter la réponse. Qu'adviendra-t-il des données? Ils seront perdus. Le consommateur devra à nouveau envoyer une demande et espérer que les données qu'il souhaite recevoir n'ont pas changé pendant cette période,et le producteur est toujours prêt à accepter la demande.Apache Kafka résout ce problème et bien d'autres qui surviennent lors de l'échange de messages entre microservices. Il ne sera pas inutile de rappeler que l'échange de données ininterrompu et pratique est l'un des problèmes clés qui doivent être résolus pour assurer le fonctionnement stable de l'architecture de microservice.Installer et configurer ZooKeeper et Apache Kafka sur Windows 10
La première chose que vous devez savoir pour commencer est qu'Apache Kafka s'exécute en plus du service ZooKeeper. ZooKeeper est un service de configuration et de synchronisation distribué, et c'est tout ce que nous devons savoir à ce sujet dans ce contexte. Nous devons le télécharger, le configurer et l'exécuter avant de commencer avec Kafka. Avant de commencer à travailler avec ZooKeeper, assurez-vous que JRE est installé et configuré.Vous pouvez télécharger la dernière version de ZooKeeper sur le site officiel .Nous extrayons les fichiers de l'archive ZooKeeper téléchargée dans un dossier sur le disque.Dans le dossier zookeeper avec le numéro de version, nous trouvons le dossier conf et le fichier «zoo_sample.cfg». Copiez-le et changez le nom de la copie en «zoo.cfg». Ouvrez le fichier de copie et recherchez-y la ligne dataDir = / tmp / zookeeper. Dans cette ligne, nous écrivons le chemin complet de notre dossier zookeeper-x.x.x. Cela ressemble à ceci pour moi: dataDir = C: \\ ZooKeeper \\ zookeeper-3.6.0
Copiez-le et changez le nom de la copie en «zoo.cfg». Ouvrez le fichier de copie et recherchez-y la ligne dataDir = / tmp / zookeeper. Dans cette ligne, nous écrivons le chemin complet de notre dossier zookeeper-x.x.x. Cela ressemble à ceci pour moi: dataDir = C: \\ ZooKeeper \\ zookeeper-3.6.0 Maintenant, nous ajoutons la variable d'environnement système: ZOOKEEPER_HOME = C: \ ZooKeeper \ zookeeper-3.4.9 et à la fin de la variable système Path, ajoutez l'entrée:;% ZOOKEEPER_HOME % \ poubelle;Exécutez la ligne de commande et écrivez la commande:
Maintenant, nous ajoutons la variable d'environnement système: ZOOKEEPER_HOME = C: \ ZooKeeper \ zookeeper-3.4.9 et à la fin de la variable système Path, ajoutez l'entrée:;% ZOOKEEPER_HOME % \ poubelle;Exécutez la ligne de commande et écrivez la commande:zkserver
Si tout est fait correctement, vous verrez quelque chose comme ce qui suit.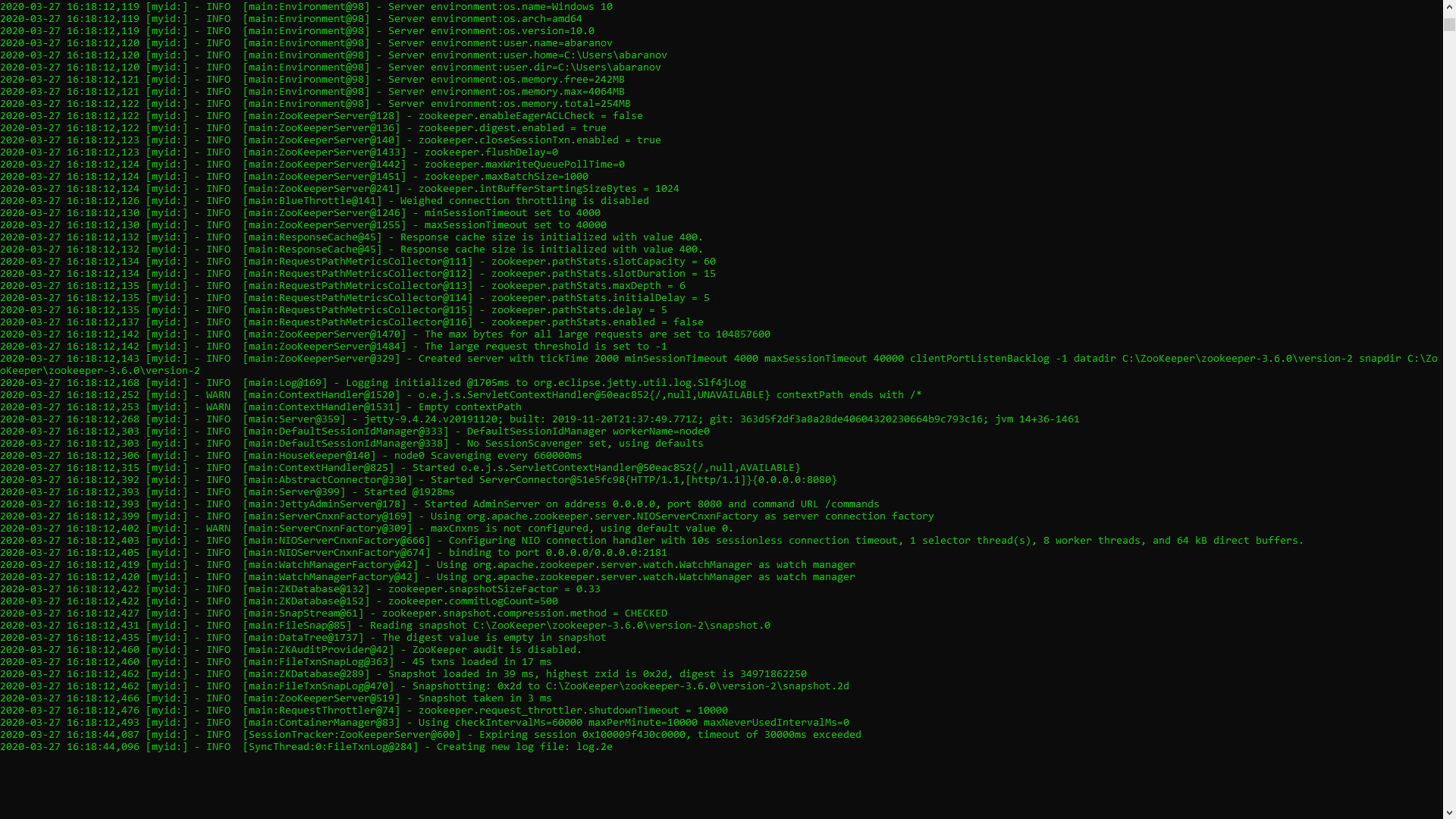 Cela signifie que ZooKeeper a démarré normalement. Nous procédons directement à l'installation et à la configuration du serveur Apache Kafka. Téléchargez la dernière version sur le site officiel et extrayez le contenu de l'archive: kafka.apache.org/downloadsDans le dossier avec Kafka, nous trouvons le dossier config, nous y trouvons le fichier server.properties et l'ouvrons.
Cela signifie que ZooKeeper a démarré normalement. Nous procédons directement à l'installation et à la configuration du serveur Apache Kafka. Téléchargez la dernière version sur le site officiel et extrayez le contenu de l'archive: kafka.apache.org/downloadsDans le dossier avec Kafka, nous trouvons le dossier config, nous y trouvons le fichier server.properties et l'ouvrons. Nous trouvons la ligne log.dirs = / tmp / kafka-logs et y indiquons le chemin où Kafka enregistrera les journaux: log.dirs = c: / kafka / kafka-logs.
Nous trouvons la ligne log.dirs = / tmp / kafka-logs et y indiquons le chemin où Kafka enregistrera les journaux: log.dirs = c: / kafka / kafka-logs.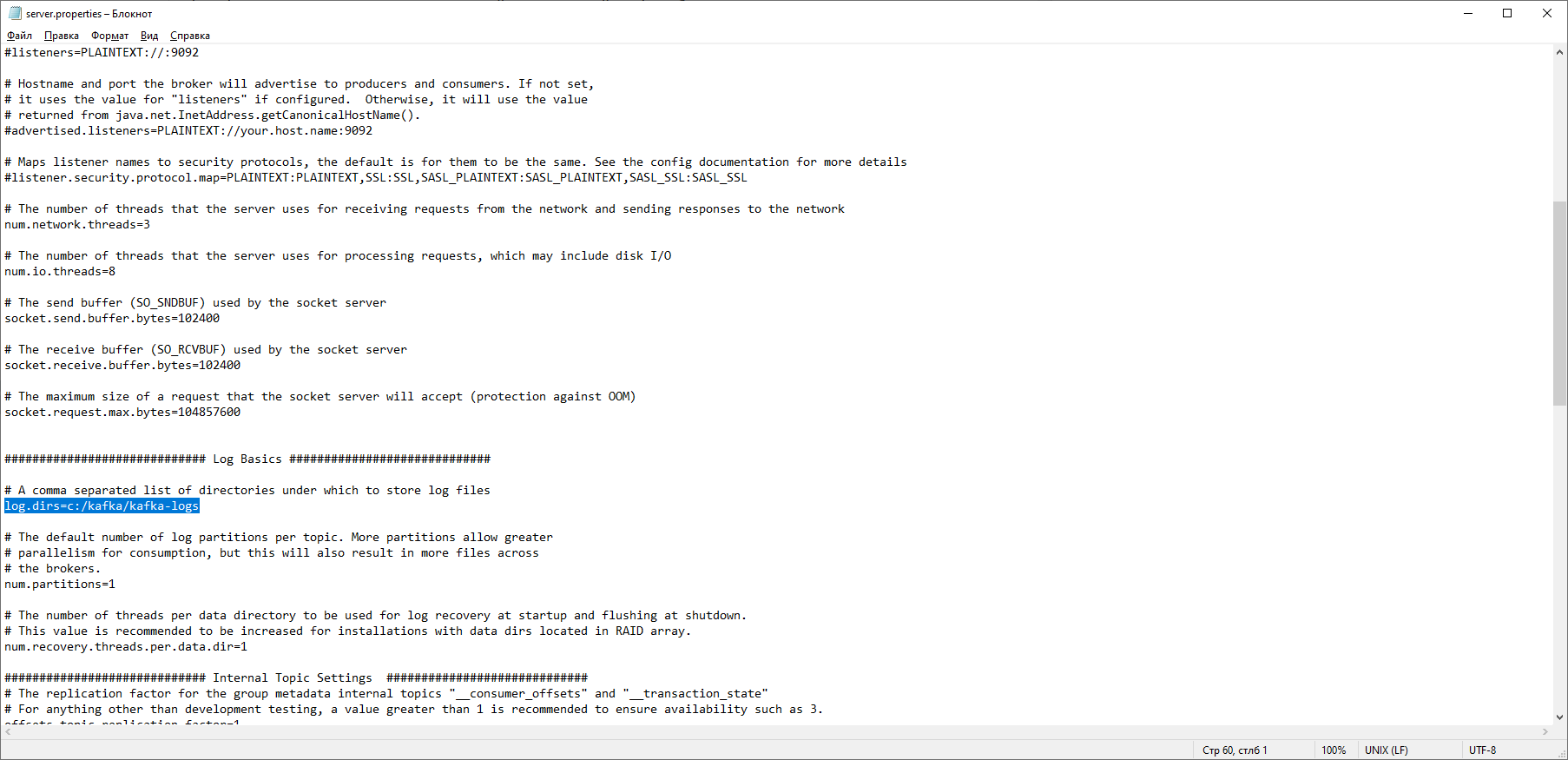 Dans le même dossier, modifiez le fichier zookeeper.properties. Nous changeons la ligne dataDir = / tmp / zookeeper en dataDir = c: / kafka / zookeeper-data, sans oublier d'indiquer le chemin vers votre dossier Kafka après le nom du disque. Si vous avez tout fait correctement, vous pouvez exécuter ZooKeeper et Kafka.
Dans le même dossier, modifiez le fichier zookeeper.properties. Nous changeons la ligne dataDir = / tmp / zookeeper en dataDir = c: / kafka / zookeeper-data, sans oublier d'indiquer le chemin vers votre dossier Kafka après le nom du disque. Si vous avez tout fait correctement, vous pouvez exécuter ZooKeeper et Kafka. Pour certains, il peut être désagréable de constater qu'il n'y a pas d'interface graphique pour contrôler Kafka. C'est peut-être parce que le service est conçu pour les nerds durs travaillant exclusivement avec la console. D'une manière ou d'une autre, pour exécuter Kafka, nous avons besoin d'une ligne de commande.Vous devez d'abord démarrer ZooKeeper. Dans le dossier avec le kafka, nous trouvons le dossier bin / windows, dans celui-ci, nous trouvons le fichier pour démarrer le service zookeeper-server-start.bat, cliquez dessus. Rien ne se passe? Il devrait en être ainsi. Ouvrez la console dans ce dossier et écrivez:
Pour certains, il peut être désagréable de constater qu'il n'y a pas d'interface graphique pour contrôler Kafka. C'est peut-être parce que le service est conçu pour les nerds durs travaillant exclusivement avec la console. D'une manière ou d'une autre, pour exécuter Kafka, nous avons besoin d'une ligne de commande.Vous devez d'abord démarrer ZooKeeper. Dans le dossier avec le kafka, nous trouvons le dossier bin / windows, dans celui-ci, nous trouvons le fichier pour démarrer le service zookeeper-server-start.bat, cliquez dessus. Rien ne se passe? Il devrait en être ainsi. Ouvrez la console dans ce dossier et écrivez: start zookeeper-server-start.bat
Ça ne marche plus? C’est la norme. En effet, zookeeper-server-start.bat nécessite les paramètres spécifiés dans le fichier zookeeper.properties, qui, nous le rappelons, se trouve dans le dossier config pour son travail. Nous écrivons à la console:start zookeeper-server-start.bat c:\kafka\config\zookeeper.properties
Maintenant, tout devrait commencer normalement. Encore une fois, ouvrez la console dans ce dossier (ne fermez pas ZooKeeper!) Et exécutez kafka:
Encore une fois, ouvrez la console dans ce dossier (ne fermez pas ZooKeeper!) Et exécutez kafka:start kafka-server-start.bat c:\kafka\config\server.properties
Afin de ne pas écrire de commandes à chaque fois sur la ligne de commande, vous pouvez utiliser l'ancienne méthode éprouvée et créer un fichier de commandes avec le contenu suivant:start C:\kafka\bin\windows\zookeeper-server-start.bat C:\kafka\config\zookeeper.properties
timeout 10
start C:\kafka\bin\windows\kafka-server-start.bat C:\kafka\config\server.properties
La ligne de timeout 10 est nécessaire pour définir une pause entre le démarrage de zookeeper et kafka. Si vous avez tout fait correctement, lorsque vous cliquez sur le fichier de commandes, deux consoles devraient s'ouvrir avec zookeeper et kafka en cours d'exécution. Nous pouvons maintenant créer un producteur de messages et un consommateur avec les paramètres nécessaires directement à partir de la ligne de commande. Mais, en pratique, il peut être nécessaire, sauf pour tester le service. Nous serons beaucoup plus intéressés par la façon de travailler avec kafka d'IDEA.Travailler avec Kafka d'IDEA
Nous écrirons l'application la plus simple possible, qui sera à la fois le producteur et le consommateur du message, puis lui ajouterons des fonctionnalités utiles. Créez un nouveau projet de printemps. Cela est plus pratique à l'aide d'un initialiseur à ressort. Ajoutez les dépendances org.springframework.kafka et spring-boot-starter-web
 Par conséquent, le fichier pom.xml devrait ressembler à ceci:
Par conséquent, le fichier pom.xml devrait ressembler à ceci: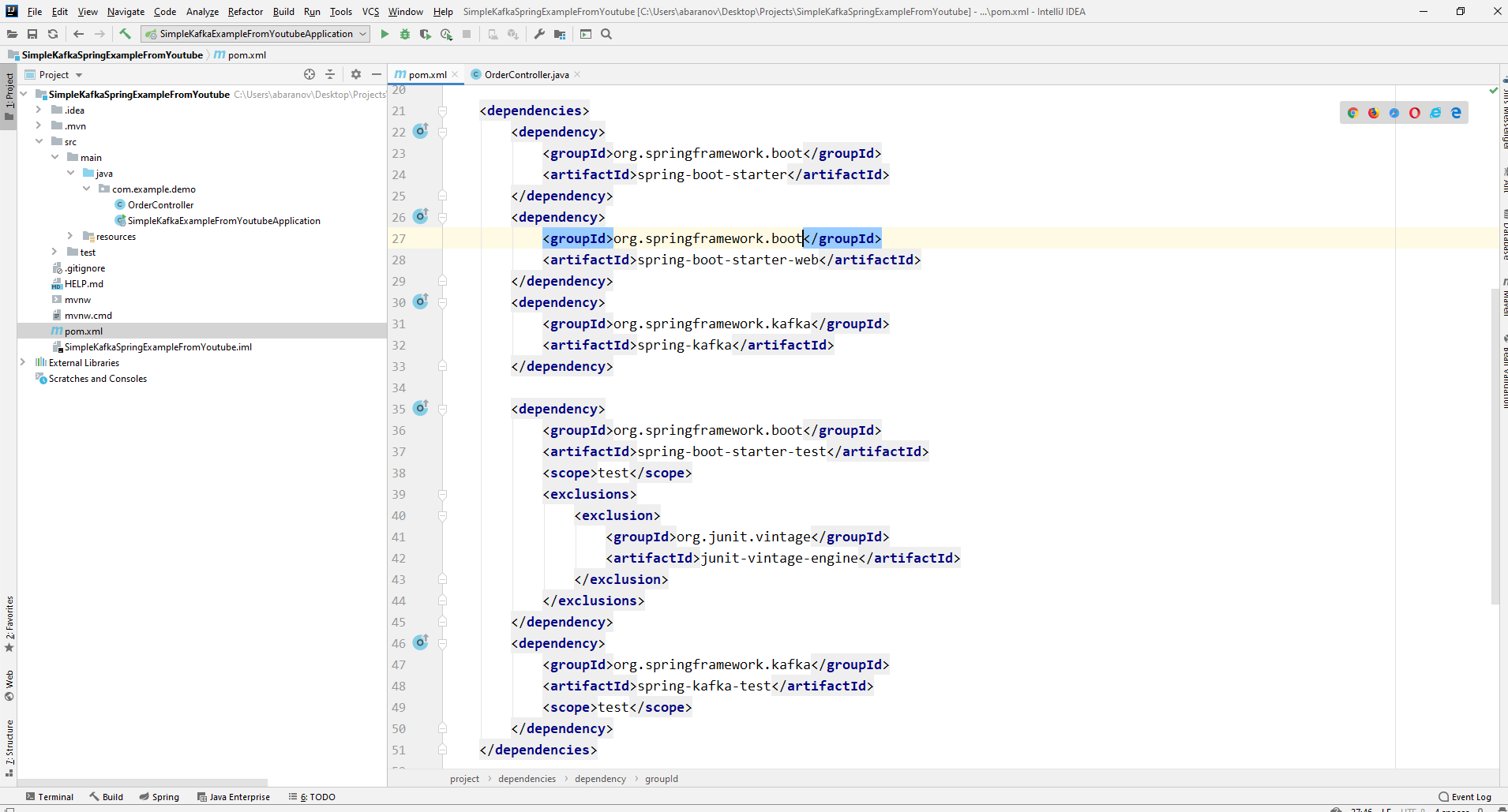 Pour envoyer des messages, nous avons besoin de l'objet KafkaTemplate <K, V>. Comme nous le voyons, l'objet est tapé. Le premier paramètre est le type de clé, le second est le message lui-même. Pour l'instant, nous indiquerons les deux paramètres sous forme de chaîne. Nous allons créer l'objet dans le contrôleur de classe. Déclarez KafkaTemplate et demandez à Spring de l'initialiser en annotantAutowired.
Pour envoyer des messages, nous avons besoin de l'objet KafkaTemplate <K, V>. Comme nous le voyons, l'objet est tapé. Le premier paramètre est le type de clé, le second est le message lui-même. Pour l'instant, nous indiquerons les deux paramètres sous forme de chaîne. Nous allons créer l'objet dans le contrôleur de classe. Déclarez KafkaTemplate et demandez à Spring de l'initialiser en annotantAutowired.@Autowired
private KafkaTemplate<String, String> kafkaTemplate;
En principe, notre producteur est prêt. Il ne reste plus qu'à y appeler la méthode send (). Il existe plusieurs versions surchargées de cette méthode. Nous utilisons dans notre projet une option avec 3 paramètres - envoyer (sujet String, clé K, données V). Étant donné que KafkaTemplate est tapé par String, la clé et les données dans la méthode d'envoi seront une chaîne. Le premier paramètre indique la rubrique, c'est-à-dire la rubrique à laquelle les messages seront envoyés et à laquelle les consommateurs peuvent s'abonner pour les recevoir. Si le sujet spécifié dans la méthode d'envoi n'existe pas, il sera créé automatiquement. Le texte complet de la classe ressemble à ceci.@RestController
@RequestMapping("msg")
public class MsgController {
@Autowired
private KafkaTemplate<String, String> kafkaTemplate;
@PostMapping
public void sendOrder(String msgId, String msg){
kafkaTemplate.send("msg", msgId, msg);
}
}
Le contrôleur est mappé sur localhost : 8080 / msg, la clé et le message lui-même sont transmis dans le corps de la demande.L'expéditeur du message est prêt, créez maintenant un écouteur. Le printemps vous permet également de le faire sans trop d'effort. Il suffit de créer une méthode et de la marquer avec l'annotation @KafkaListener, dans les paramètres dont vous ne pouvez spécifier que le sujet à écouter. Dans notre cas, cela ressemble à ceci.@KafkaListener(topics="msg")
La méthode elle-même, marquée d'annotations, peut spécifier un paramètre accepté, qui a le type de message transmis par le producteur.La classe dans laquelle le consommateur sera créé doit être marquée avec l'annotation @EnableKafka.@EnableKafka
@SpringBootApplication
public class SimpleKafkaExampleApplication {
@KafkaListener(topics="msg")
public void msgListener(String msg){
System.out.println(msg);
}
public static void main(String[] args) {
SpringApplication.run(SimpleKafkaExampleApplication.class, args);
}
}
De plus, dans le fichier de paramètres application.property, vous devez spécifier le paramètre concierge groupe-id. Si cela n'est pas fait, l'application ne démarre pas. Le paramètre est de type String et peut être n'importe quoi.spring.kafka.consumer.group-id=app.1
Notre projet de kafka le plus simple est prêt. Nous avons un expéditeur et un destinataire des messages. Il ne reste plus qu'à courir. Tout d'abord, lancez ZooKeeper et Kafka en utilisant le fichier batch que nous avons écrit précédemment, puis lancez notre application. Il est plus pratique d'envoyer une demande à l'aide de Postman. Dans le corps de la requête, n'oubliez pas de spécifier les paramètres msgId et msg. Si nous voyons une telle image dans IDEA, alors tout fonctionne: le producteur a envoyé un message, le consommateur l'a reçu et l'affiche sur la console.
Si nous voyons une telle image dans IDEA, alors tout fonctionne: le producteur a envoyé un message, le consommateur l'a reçu et l'affiche sur la console.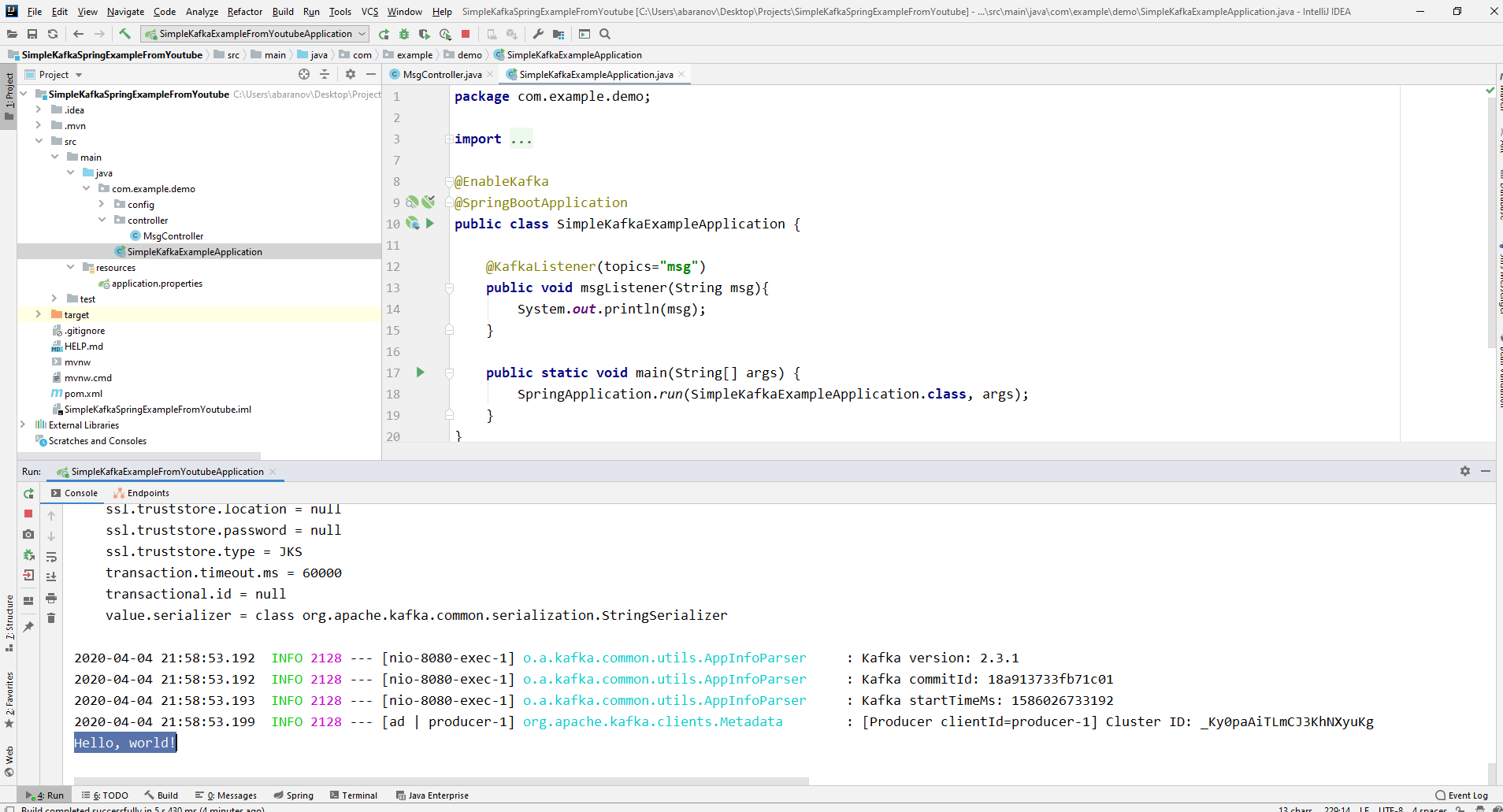
Nous compliquons le projet
Les vrais projets utilisant Kafka sont certainement plus compliqués que celui que nous avons créé. Maintenant que nous avons compris les fonctions de base du service, réfléchissez aux fonctionnalités supplémentaires qu'il offre. Pour commencer, nous améliorerons le producteur.Si vous avez ouvert la méthode send (), vous remarquerez peut-être que toutes ses variantes ont une valeur de retour de ListenableFuture <SendResult <K, V >>. Maintenant, nous ne considérerons pas en détail les capacités de cette interface. Ici, il suffira de dire qu'il est nécessaire de visualiser le résultat de l'envoi d'un message.@PostMapping
public void sendMsg(String msgId, String msg){
ListenableFuture<SendResult<String, String>> future = kafkaTemplate.send("msg", msgId, msg);
future.addCallback(System.out::println, System.err::println);
kafkaTemplate.flush();
}
La méthode addCallback () accepte deux paramètres - SuccessCallback et FailureCallback. Les deux sont des interfaces fonctionnelles. D'après le nom, vous pouvez comprendre que la méthode de la première sera appelée à la suite de l'envoi réussi du message, la seconde - à la suite d'une erreur. Maintenant, si nous exécutons le projet, nous verrons quelque chose comme ceci sur la console:SendResult [producerRecord=ProducerRecord(topic=msg, partition=null, headers=RecordHeaders(headers = [], isReadOnly = true), key=1, value=Hello, world!, timestamp=null), recordMetadata=msg-0@6]
Examinons à nouveau attentivement notre producteur. Fait intéressant, que se passe-t-il si la clé n'est pas String, mais, disons, Long, mais comme le message transmis, pire encore - une sorte de DTO compliqué? Tout d'abord, essayons de changer la clé en une valeur numérique ... Si nous spécifions Long comme clé dans le producteur, l'application démarrera normalement, mais lorsque vous essayez d'envoyer un message, une ClassCastException sera levée et il sera signalé que la classe Long ne peut pas être convertie en classe String.
Si nous spécifions Long comme clé dans le producteur, l'application démarrera normalement, mais lorsque vous essayez d'envoyer un message, une ClassCastException sera levée et il sera signalé que la classe Long ne peut pas être convertie en classe String. Si nous essayons de créer manuellement l'objet KafkaTemplate, nous verrons que l'objet d'interface ProducerFactory <K, V>, par exemple DefaultKafkaProducerFactory <>, est transmis au constructeur en tant que paramètre. Afin de créer un DefaultKafkaProducerFactory, nous devons transmettre une carte contenant ses paramètres de producteur à son constructeur. Tout le code de configuration et de création du producteur sera placé dans une classe distincte. Pour ce faire, créez le package de configuration et la classe KafkaProducerConfig.
Si nous essayons de créer manuellement l'objet KafkaTemplate, nous verrons que l'objet d'interface ProducerFactory <K, V>, par exemple DefaultKafkaProducerFactory <>, est transmis au constructeur en tant que paramètre. Afin de créer un DefaultKafkaProducerFactory, nous devons transmettre une carte contenant ses paramètres de producteur à son constructeur. Tout le code de configuration et de création du producteur sera placé dans une classe distincte. Pour ce faire, créez le package de configuration et la classe KafkaProducerConfig.@Configuration
public class KafkaProducerConfig {
private String kafkaServer="localhost:9092";
@Bean
public Map<String, Object> producerConfigs() {
Map<String, Object> props = new HashMap<>();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,
kafkaServer);
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,
LongSerializer.class);
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,
StringSerializer.class);
return props;
}
@Bean
public ProducerFactory<Long, String> producerFactory() {
return new DefaultKafkaProducerFactory<>(producerConfigs());
}
@Bean
public KafkaTemplate<Long, String> kafkaTemplate() {
return new KafkaTemplate<>(producerFactory());
}
}
Dans la méthode producteurConfigs (), créez une carte avec les configurations et spécifiez LongSerializer.class comme sérialiseur pour la clé. Nous commençons, envoyons une demande à Postman et constatons que maintenant tout fonctionne comme il se doit: le producteur envoie un message et le consommateur le reçoit.Modifions maintenant le type de la valeur transmise. Et si nous n'avons pas de classe standard de la bibliothèque Java, mais une sorte de DTO personnalisé. Disons ceci.@Data
public class UserDto {
private Long age;
private String name;
private Address address;
}
@Data
@AllArgsConstructor
public class Address {
private String country;
private String city;
private String street;
private Long homeNumber;
private Long flatNumber;
}
Pour envoyer DTO en tant que message, vous devez apporter quelques modifications à la configuration du producteur. Spécifiez JsonSerializer.class comme sérialiseur de la valeur du message et n'oubliez pas de changer le type de chaîne en UserDto partout.@Configuration
public class KafkaProducerConfig {
private String kafkaServer="localhost:9092";
@Bean
public Map<String, Object> producerConfigs() {
Map<String, Object> props = new HashMap<>();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,
kafkaServer);
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,
LongSerializer.class);
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,
JsonSerializer.class);
return props;
}
@Bean
public ProducerFactory<Long, UserDto> producerFactory() {
return new DefaultKafkaProducerFactory<>(producerConfigs());
}
@Bean
public KafkaTemplate<Long, UserDto> kafkaTemplate() {
return new KafkaTemplate<>(producerFactory());
}
}
Envoyer un message. La ligne suivante sera affichée dans la console: Maintenant, nous allons compliquer le consommateur. Avant cela, notre méthode public void msgListener (String msg), marquée avec l'annotation @KafkaListener (topics = "msg") a pris String comme paramètre et l'affichait sur la console. Et si nous voulons obtenir d'autres paramètres du message transmis, par exemple une clé ou une partition? Dans ce cas, le type de la valeur transmise doit être modifié.
Maintenant, nous allons compliquer le consommateur. Avant cela, notre méthode public void msgListener (String msg), marquée avec l'annotation @KafkaListener (topics = "msg") a pris String comme paramètre et l'affichait sur la console. Et si nous voulons obtenir d'autres paramètres du message transmis, par exemple une clé ou une partition? Dans ce cas, le type de la valeur transmise doit être modifié.@KafkaListener(topics="msg")
public void orderListener(ConsumerRecord<Long, UserDto> record){
System.out.println(record.partition());
System.out.println(record.key());
System.out.println(record.value());
}
À partir de l'objet ConsumerRecord, nous pouvons obtenir tous les paramètres qui nous intéressent.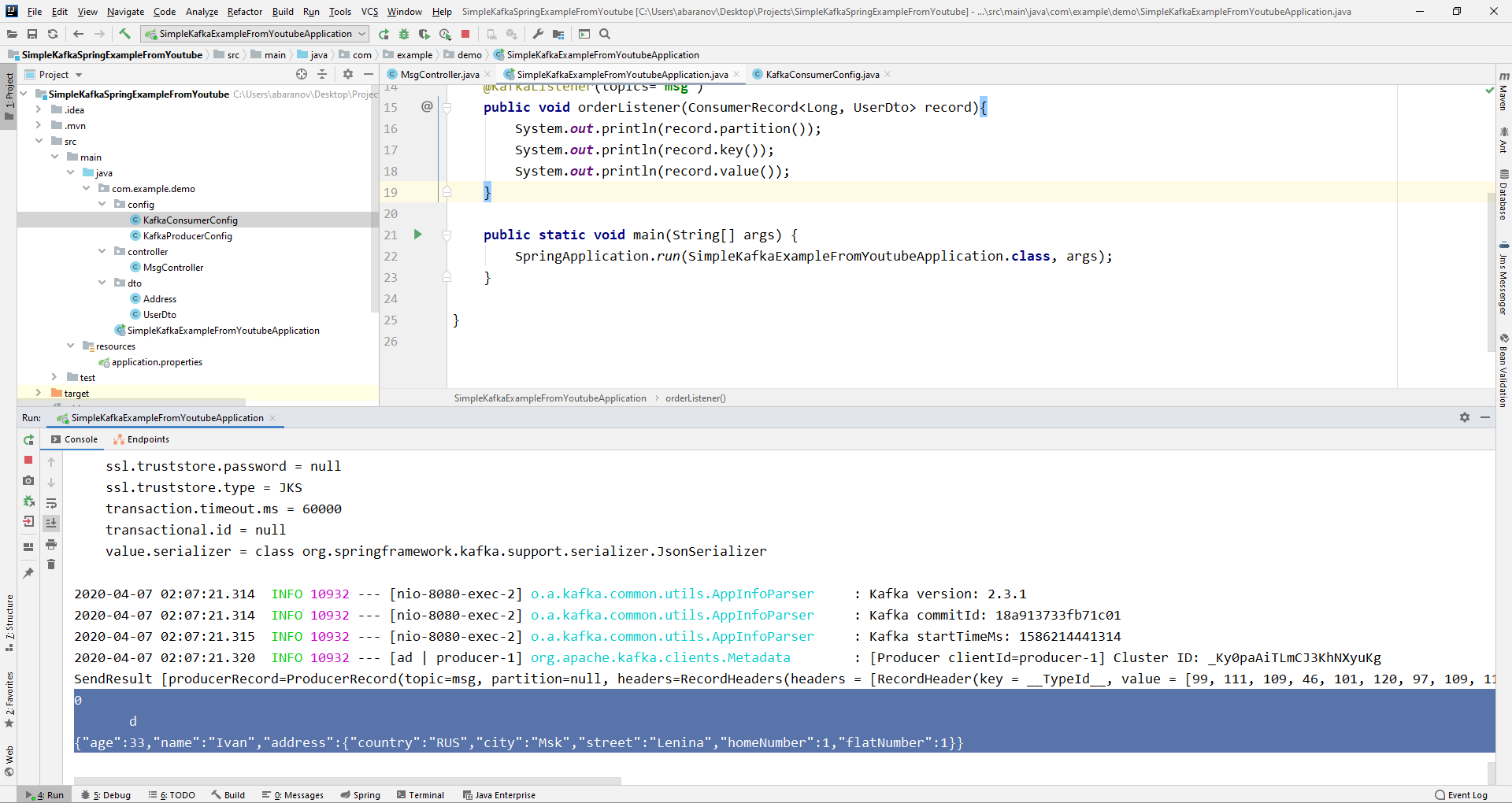 Nous voyons qu'au lieu de la clé sur la console, une sorte d'escrocs sont affichés. Cela est dû au fait que StringDeserializer est utilisé par défaut pour désérialiser la clé, et si nous voulons que la clé au format entier s'affiche correctement, nous devons la changer en LongDeserializer. Pour configurer le consommateur dans le package de configuration, créez la classe KafkaConsumerConfig.
Nous voyons qu'au lieu de la clé sur la console, une sorte d'escrocs sont affichés. Cela est dû au fait que StringDeserializer est utilisé par défaut pour désérialiser la clé, et si nous voulons que la clé au format entier s'affiche correctement, nous devons la changer en LongDeserializer. Pour configurer le consommateur dans le package de configuration, créez la classe KafkaConsumerConfig.@Configuration
public class KafkaConsumerConfig {
@Value("${spring.kafka.bootstrap-servers}")
private String kafkaServer;
@Value("${spring.kafka.consumer.group-id}")
private String kafkaGroupId;
@Bean
public Map<String, Object> consumerConfigs() {
Map<String, Object> props = new HashMap<>();
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, kafkaServer);
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, LongDeserializer.class);
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
props.put(ConsumerConfig.GROUP_ID_CONFIG, kafkaGroupId);
return props;
}
@Bean
public KafkaListenerContainerFactory<?> kafkaListenerContainerFactory() {
ConcurrentKafkaListenerContainerFactory<Long, UserDto> factory =
new ConcurrentKafkaListenerContainerFactory<>();
factory.setConsumerFactory(consumerFactory());
return factory;
}
@Bean
public ConsumerFactory<Long, UserDto> consumerFactory() {
return new DefaultKafkaConsumerFactory<>(consumerConfigs());
}
}
La classe KafkaConsumerConfig est très similaire à la KafkaProducerConfig que nous avons créée précédemment. Il existe également une carte qui contient les configurations nécessaires, par exemple, comme un désérialiseur pour la clé et la valeur. La carte créée est utilisée pour créer la ConsumerFactory <>, qui, à son tour, est nécessaire pour créer la KafkaListenerContainerFactory <?>. Un détail important: la méthode renvoyant KafkaListenerContainerFactory <?> Doit être appelée kafkaListenerContainerFactory (), sinon Spring ne pourra pas trouver le bean souhaité et le projet ne compilera pas. Nous commençons. Nous voyons que maintenant la clé est affichée comme il se doit, ce qui signifie que tout fonctionne. Bien sûr, les capacités d'Apache Kafka vont bien au-delà de celles décrites dans cet article, cependant, j'espère qu'après l'avoir lu, vous aurez une idée de ce service et, surtout, vous pourrez commencer à travailler avec lui.Lavez-vous les mains plus souvent, portez des masques, ne sortez pas sans besoin et soyez en bonne santé.
Nous voyons que maintenant la clé est affichée comme il se doit, ce qui signifie que tout fonctionne. Bien sûr, les capacités d'Apache Kafka vont bien au-delà de celles décrites dans cet article, cependant, j'espère qu'après l'avoir lu, vous aurez une idée de ce service et, surtout, vous pourrez commencer à travailler avec lui.Lavez-vous les mains plus souvent, portez des masques, ne sortez pas sans besoin et soyez en bonne santé.