Bonjour à tous. OTUS a ouvert le recrutement d'un nouveau groupe au cours «Plateforme d'infrastructure basée sur Kubernetes» , dans le cadre de cela, nous avons préparé une traduction de matériel intéressant sur le sujet.
Vous faites peut-être partie de ceux qui utilisent terraform pour Infrastructure en tant que code, et vous vous demandez comment l'utiliser de manière plus productive et plus sûre. En général, récemment, cela a dérangé de nombreuses personnes. Nous écrivons tous la configuration et le code à l'aide de différents outils et langages et passons beaucoup de temps à les rendre plus lisibles, extensibles et évolutifs. Peut-être que le problème est en nous-mêmes?Le code écrit doit créer de la valeur ou résoudre un problème, tout en étant réutilisable pour la déduplication. En règle générale, ce type de discussion se termine par «Utilisons des modules» . Nous utilisons tous des modules terraform, non? Je pourrais écrire de nombreuses histoires avec des problèmes dus à une modularité excessive, mais c'est une histoire complètement différente, et je ne le ferai pas.
Peut-être que le problème est en nous-mêmes?Le code écrit doit créer de la valeur ou résoudre un problème, tout en étant réutilisable pour la déduplication. En règle générale, ce type de discussion se termine par «Utilisons des modules» . Nous utilisons tous des modules terraform, non? Je pourrais écrire de nombreuses histoires avec des problèmes dus à une modularité excessive, mais c'est une histoire complètement différente, et je ne le ferai pas. Non je ne le ferais pas. N'insistez pas, non ... D'accord, peut-être plus tard.Il existe une pratique bien connue: étiqueter le code lors de l'utilisation de modules pour verrouiller le module racine, afin de garantir son fonctionnement même lors de la modification du code du module. Cette approche devrait devenir un principe d'équipe dans lequel les modules appropriés sont étiquetés et utilisés de manière appropriée.... mais qu'en est-il des dépendances? Que faire si j'ai 120 modules dans 120 référentiels différents et que le changement d'un module affecte 20 autres modules. Est-ce à dire que nous devons faire 20 + 1 pull demandes? Si le nombre minimum d'évaluateurs est de 2, cela signifie 21 x 2 = 44la revue. Sérieusement! Nous paralysons simplement la commande en «changeant un module» et tout le monde commencera à envoyer des mèmes ou des gifs du Seigneur des Anneaux, et le reste de la journée sera perdu.
Non je ne le ferais pas. N'insistez pas, non ... D'accord, peut-être plus tard.Il existe une pratique bien connue: étiqueter le code lors de l'utilisation de modules pour verrouiller le module racine, afin de garantir son fonctionnement même lors de la modification du code du module. Cette approche devrait devenir un principe d'équipe dans lequel les modules appropriés sont étiquetés et utilisés de manière appropriée.... mais qu'en est-il des dépendances? Que faire si j'ai 120 modules dans 120 référentiels différents et que le changement d'un module affecte 20 autres modules. Est-ce à dire que nous devons faire 20 + 1 pull demandes? Si le nombre minimum d'évaluateurs est de 2, cela signifie 21 x 2 = 44la revue. Sérieusement! Nous paralysons simplement la commande en «changeant un module» et tout le monde commencera à envoyer des mèmes ou des gifs du Seigneur des Anneaux, et le reste de la journée sera perdu. Un PR pour informer tout le monde, un PR pour rassembler tout le monde, enchaîner et plonger dans l'obscuritéEst-ce que ça vaut le coup de travailler? Faut-il réduire le nombre d'examinateurs? Ou, peut-être, faites une exception pour les modules et n'exigez pas de RP si le changement a un impact important. Vraiment? Voulez-vous marcher aveuglément dans une forêt sombre et profonde? Ou les rassembler, percer et plonger dans les ténèbres ?Non, ne modifiez pas l'ordre de l'examen. Si vous pensez que travailler avec PR est juste, alors respectez-le. Si vous avez des pipelines intelligents ou que vous insistez pour maîtriser, restez avec cette approche.Dans ce cas, le problème n'est pas «comment travaillez-vous» , mais «quelle est la structure de vos dépôts git» .
Un PR pour informer tout le monde, un PR pour rassembler tout le monde, enchaîner et plonger dans l'obscuritéEst-ce que ça vaut le coup de travailler? Faut-il réduire le nombre d'examinateurs? Ou, peut-être, faites une exception pour les modules et n'exigez pas de RP si le changement a un impact important. Vraiment? Voulez-vous marcher aveuglément dans une forêt sombre et profonde? Ou les rassembler, percer et plonger dans les ténèbres ?Non, ne modifiez pas l'ordre de l'examen. Si vous pensez que travailler avec PR est juste, alors respectez-le. Si vous avez des pipelines intelligents ou que vous insistez pour maîtriser, restez avec cette approche.Dans ce cas, le problème n'est pas «comment travaillez-vous» , mais «quelle est la structure de vos dépôts git» . Ceci est similaire à ce que j'ai ressenti lorsque j'ai appliqué la suggestion ci-dessous pour la première fois.Revenons à l'essentiel. Quelles sont les exigences générales pour un référentiel avec des modules terraform?
Ceci est similaire à ce que j'ai ressenti lorsque j'ai appliqué la suggestion ci-dessous pour la première fois.Revenons à l'essentiel. Quelles sont les exigences générales pour un référentiel avec des modules terraform?- Il doit être balisé pour qu'il n'y ait pas de changements de rupture.
- Tout changement doit pouvoir être testé.
- Les changements doivent passer par un examen mutuel.
Ensuite, je suggère ce qui suit - NE PAS utiliser de micro-référentiels pour les modules terraform. Utilisez un référentiel mono .- Vous pouvez baliser l'intégralité du référentiel en cas de changement / exigence
- Tout changement, PR ou push peut être testé.
- Tout changement peut passer par l'examen.
 J'ai de la force!D'accord, mais quelle sera la structure de ce référentiel? Au cours des quatre dernières années, j'ai eu de nombreux échecs liés à cela, et je suis arrivé à la conclusion qu'un répertoire séparé pour le module serait la meilleure solution.
J'ai de la force!D'accord, mais quelle sera la structure de ce référentiel? Au cours des quatre dernières années, j'ai eu de nombreux échecs liés à cela, et je suis arrivé à la conclusion qu'un répertoire séparé pour le module serait la meilleure solution.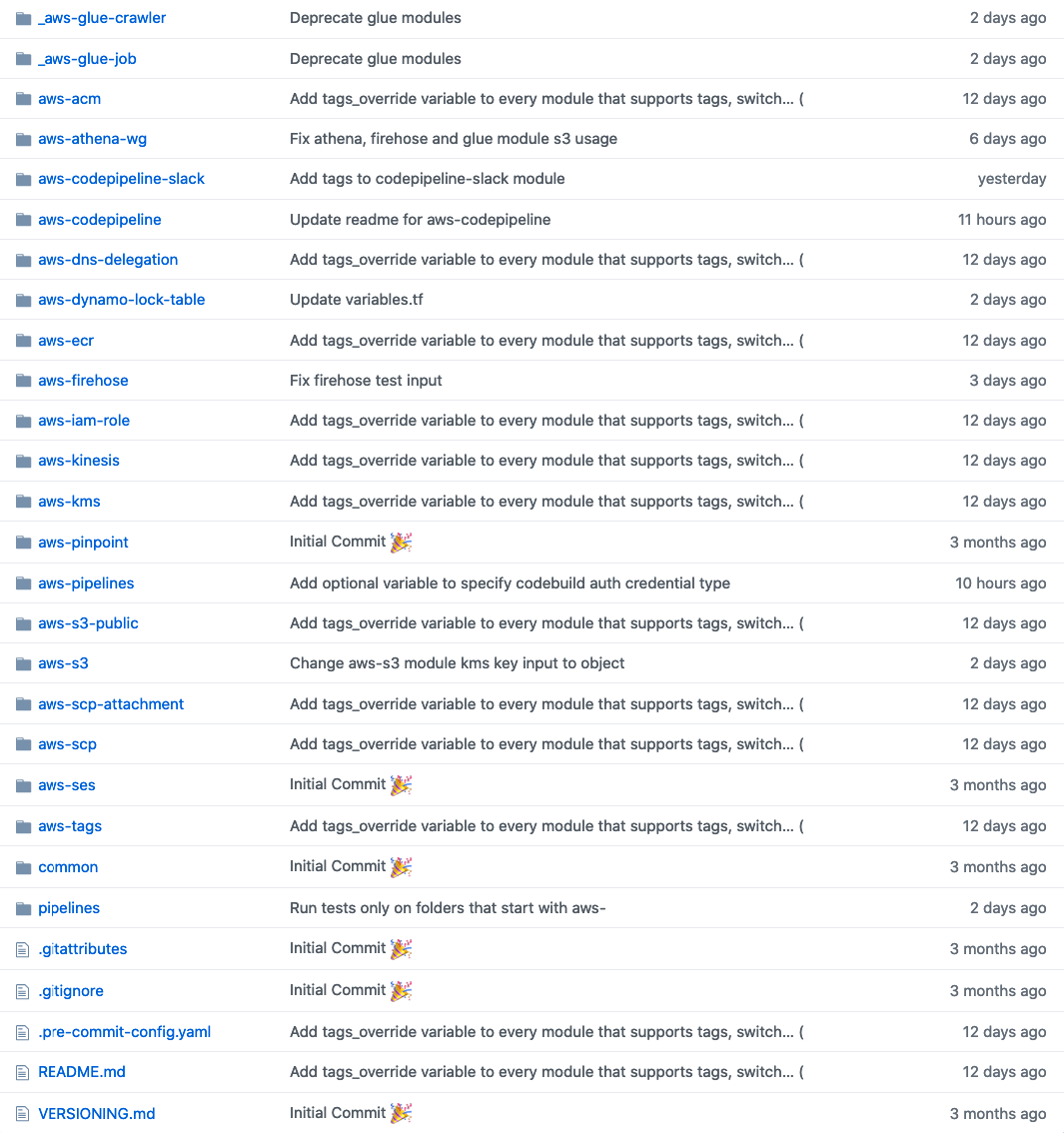 Exemple de structure de répertoires pour un référentiel mono. Voir le changement de tags_override?Ainsi, un changement de module qui affecte 20 autres modules n'est que de 1 PR ! Même si vous ajoutez 5 critiques à ce PR, la revue sera très rapide par rapport aux micro-référentiels. Si vous utilisez Github, c'est encore mieux! Vous pouvez utiliser CODEOWNERS pour les modules qui ont des mainteneurs / propriétaires, et toute modification de ces modules DOIT être approuvée par ce propriétaire.Génial, mais comment utiliser un tel module, qui se trouve dans le répertoire mono-repository?Facile:
Exemple de structure de répertoires pour un référentiel mono. Voir le changement de tags_override?Ainsi, un changement de module qui affecte 20 autres modules n'est que de 1 PR ! Même si vous ajoutez 5 critiques à ce PR, la revue sera très rapide par rapport aux micro-référentiels. Si vous utilisez Github, c'est encore mieux! Vous pouvez utiliser CODEOWNERS pour les modules qui ont des mainteneurs / propriétaires, et toute modification de ces modules DOIT être approuvée par ce propriétaire.Génial, mais comment utiliser un tel module, qui se trouve dans le répertoire mono-repository?Facile:module "from_mono_repo" {
source = "git::ssh://.../<org>/<repo>.git//<my_module_dir>"
...
}
module "from_mono_repo_with_tags" {
source = "git::ssh://..../<org>/<repo>.git//<mod_dir>?ref=1.2.4"
...
}
module "from_micro_repo" {
source = "git::ssh://.../<org>/<mod_repo>.git"
...
}
module "from_micro_repo_with_tags" {
source = "git::ssh://.../<org>/<mod_repo>.git?ref=1.2.4"
...
}
Quels sont les inconvénients de ce type de structure? Eh bien, si vous essayez de tester «chaque module» avec PR / change, vous pouvez obtenir 1,5 heures de pipelines CI. Vous devez trouver les modules modifiés dans PR. Je le fais comme ça:changed_modules=$(git diff --name-only $(git rev-parse origin/master) HEAD | cut -d "/" -f1 | grep ^aws- | uniq)
Il existe un autre inconvénient: chaque fois que vous exécutez «terraform init», il charge l'intégralité du référentiel dans le répertoire .terraform. Mais je n'ai jamais eu de problème avec cela, car j'exécute mes canaux dans des conteneurs AWS CodeBuild évolutifs. Si vous utilisez Jenkins et des esclaves Jenkins persistants, vous pouvez avoir ce problème. Ne nous fais pas pleurer.Avec un mono-référentiel, vous avez toujours tous les avantages des micro-référentiels, mais en prime, vous réduisez le coût de maintenance de vos modules.Honnêtement, après avoir travaillé dans ce mode, la proposition d'utiliser des micro-référentiels pour les modules terraform devrait être considérée comme un crime.Super, qu'en est-il des tests unitaires? En avez-vous vraiment besoin? ... En général, qu'entendez-vous exactement par tests unitaires. Allez-vous vraiment vérifier si la ressource AWS est créée correctement? À qui incombe cette responsabilité: terraform ou une API qui gère la création de ressources? Peut-être devrions-nous nous concentrer davantage sur les tests négatifs et l'idempotence du code .Pour vérifier l'idempotence du code, terraform fournit un excellent paramètre appelé
Ne nous fais pas pleurer.Avec un mono-référentiel, vous avez toujours tous les avantages des micro-référentiels, mais en prime, vous réduisez le coût de maintenance de vos modules.Honnêtement, après avoir travaillé dans ce mode, la proposition d'utiliser des micro-référentiels pour les modules terraform devrait être considérée comme un crime.Super, qu'en est-il des tests unitaires? En avez-vous vraiment besoin? ... En général, qu'entendez-vous exactement par tests unitaires. Allez-vous vraiment vérifier si la ressource AWS est créée correctement? À qui incombe cette responsabilité: terraform ou une API qui gère la création de ressources? Peut-être devrions-nous nous concentrer davantage sur les tests négatifs et l'idempotence du code .Pour vérifier l'idempotence du code, terraform fournit un excellent paramètre appelé -detailed-exitcode. Exécutez simplement:> terraform plan -detailed-exitcode
Après cela, courez terraform applyet c'est tout. Au moins, vous serez sûr que votre code est idempotent et ne crée pas de nouvelles ressources en raison d'une chaîne aléatoire ou autre chose.Qu'en est-il des tests négatifs? Qu'est-ce que les tests négatifs en général? En fait, ce n'est pas très différent des tests unitaires, mais vous faites attention aux situations négatives.Par exemple, personne n'est autorisé à créer un compartiment S3 non chiffré et public .Ainsi, au lieu de vérifier si un compartiment S3 est réellement en cours de création, vous, en fait, en fonction d'un ensemble de stratégies, vérifiez si votre code crée une ressource. Comment faire? Terraform Enterprise fournit un excellent outil pour cela, Sentinel .... mais il existe également des alternatives open source. Actuellement, il existe de nombreux outils pour l'analyse statique du code HCL. Ces outils, basés sur les meilleures pratiques courantes, ne vous permettront pas de faire quoi que ce soit de indésirable, mais que se passe-t-il s'il n'a pas le test dont vous avez besoin ... ou, pire encore, si votre situation est légèrement différente. Par exemple, vous souhaitez autoriser la publication de certains compartiments S3 en fonction de certaines conditions, qui constitueront en fait un bogue de sécurité pour ces outils.C'est là que la conformité terraform apparaît. Cet outil vous permettra non seulement d'écrire vos propres tests dans lesquels vous pourrez déterminer ce que vous voulez comme politique de votre entreprise, mais aussi de séparer la sécurité et le développement en déplaçant la sécurité vers la gauche. Cela semble assez controversé, non? Non. Tandis que? Logo de conformité TerraformTout d'abord, la conformité Terraform utilise Behavior Driven Development (BDD).
Logo de conformité TerraformTout d'abord, la conformité Terraform utilise Behavior Driven Development (BDD).Feature: Ensure that we have encryption everywhere.
Scenario: Reject if an S3 bucket is not encrypted
Given I have aws_s3_bucket defined
Then it must contain server_side_encryption_configuration
Vérifiez si le cryptage est activé.Si cela ne vous suffit pas, vous pouvez écrire plus en détail:Feature: Ensure that we have encryption everywhere.
Scenario: Reject if an S3 bucket is not encrypted with KMS
Given I have aws_s3_bucket defined
Then it must contain server_side_encryption_configuration
And it must contain rule
And it must contain apply_server_side_encryption_by_default
And it must contain sse_algorithm
And its value must match the "aws:kms" regex
Nous allons plus loin et vérifions que KMS est utilisé pour le chiffrement.Le code terraform pour ce test:resource "aws_kms_key" "mykey" {
description = "This key is used to encrypt bucket objects"
deletion_window_in_days = 10
}
resource "aws_s3_bucket" "mybucket" {
bucket = "mybucket"
server_side_encryption_configuration {
rule {
apply_server_side_encryption_by_default {
kms_master_key_id = "${aws_kms_key.mykey.arn}"
sse_algorithm = "aws:kms"
}
}
}
}
Ainsi, les tests sont compris par TOUT littéralement dans votre organisation. Ici, vous pouvez déléguer l'écriture de ces tests à un service de sécurité ou à des développeurs disposant de connaissances suffisantes en matière de sécurité. Cet outil vous permet également de stocker des fichiers BDD dans un autre référentiel. Cela aidera à différencier les responsabilités lorsque les changements dans le code et les changements dans les politiques de sécurité associés à votre code seront deux entités différentes. Il peut s'agir d'équipes différentes avec des cycles de vie différents. Incroyable non? Eh bien, du moins pour moi, ça l'était.Pour plus d'informations sur la conformité terraform, consultez cette présentation .Nous avons résolu de nombreux problèmes de conformité à la terraform, en particulier lorsque les services de sécurité sont assez éloignés des équipes de développement et peuvent ne pas comprendre ce que font les développeurs. Vous devinez déjà ce qui se passe dans de telles organisations. Habituellement, le service de sécurité commence à bloquer tout ce qui est suspect pour eux et construit un système de sécurité basé sur la sécurité du périmètre. Oh, mon Dieu ...Dans de nombreuses situations, l'utilisation de terraform et de terraform-compliance uniquement pour les équipes qui conçoivent (ou / et accompagnent) l'infrastructure a permis de mettre ces deux équipes différentes sur la même table. Lorsque votre équipe de sécurité commence à développer quelque chose avec un retour immédiat de tous les pipelines de développement, elle obtient généralement la motivation de faire de plus en plus. Eh bien, généralement ...Par conséquent, lorsque vous utilisez terraform, nous structurons les référentiels git comme suit: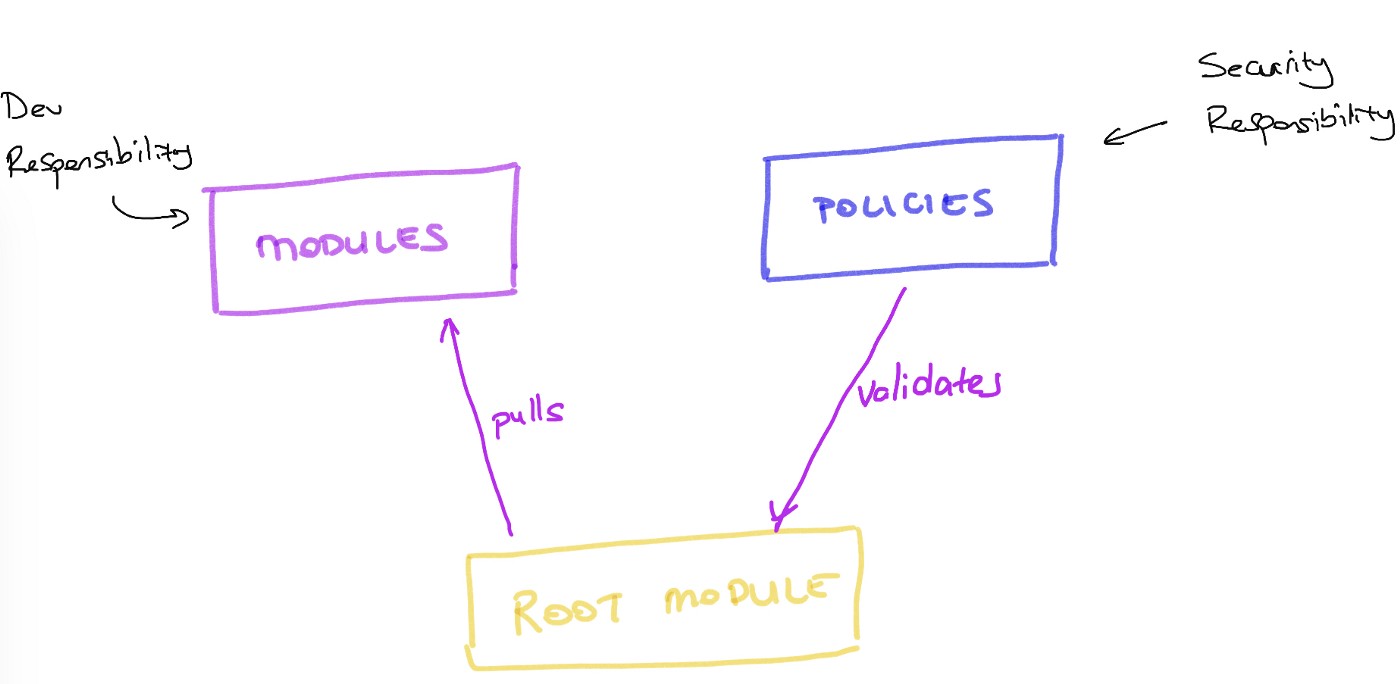 Bien sûr, c'est assez arrogant. Mais j'ai eu la chance (ou pas la chance?) De travailler avec une structure plus détaillée dans plusieurs organisations. Malheureusement, tout cela ne s'est pas très bien terminé. La fin heureuse devrait être cachée dans le numéro 3.Faites-moi savoir si vous avez des histoires de réussite avec des micro référentiels, je suis vraiment intéressé!
Bien sûr, c'est assez arrogant. Mais j'ai eu la chance (ou pas la chance?) De travailler avec une structure plus détaillée dans plusieurs organisations. Malheureusement, tout cela ne s'est pas très bien terminé. La fin heureuse devrait être cachée dans le numéro 3.Faites-moi savoir si vous avez des histoires de réussite avec des micro référentiels, je suis vraiment intéressé!
Nous vous invitons à une leçon gratuite au cours de laquelle nous examinerons les composants d'une future plateforme d'infrastructure et verrons comment livrer correctement notre application .