Lors de l'écriture d'applications en Python, les mappeurs objet-relationnels (ORM) sont souvent utilisés pour travailler avec des bases de données. SQLALchemy, PonyORM et le mappeur relationnel-objet inclus avec Django sont des exemples d'ORM. Lors du choix de l'ORM, ses performances jouent un rôle assez important.
Sur Habr, et sur Internet dans son ensemble, il n'est pas possible de trouver un seul test de performance. À titre d'exemple de référence ORM python de qualité, vous pouvez utiliser la référence ORM Tortoise ( lien vers le référentiel ). Cette référence analyse la vitesse de six ORM pour onze types différents de requêtes SQL.
En général, le benchmark de tortue permet d'évaluer la vitesse d'exécution des requêtes à l'aide de différents ORM, mais je vois un problème avec cette approche de test. Les ORM sont souvent utilisés dans les applications Web où plusieurs utilisateurs peuvent envoyer des demandes différentes en même temps, mais je n'ai pas trouvé de référence unique qui évalue les performances d'ORM dans de telles conditions. À la suite de cela, j'ai décidé d'écrire mon benchmark et de comparer PonyORM et SQLAlchemy avec lui. Comme base, j'ai pris le benchmark TPC-C.
La société TPC depuis 1988, développe des tests, destinés au traitement des données. Ils sont depuis longtemps devenus un standard de l'industrie et sont utilisés par presque tous les fournisseurs d'équipement sur divers échantillons de matériel et de logiciels. La principale caractéristique de ces tests est qu'ils visent à tester sous une charge énorme dans des conditions aussi proches que possible des conditions réelles.
TPC-C simule un réseau d'entrepôt. Il comprend une combinaison de cinq transactions exécutées simultanément de types et de complexité différents. La base de données comprend neuf tables avec un grand nombre d'enregistrements. Les performances du test TPC-C sont mesurées en transactions par minute.
J'ai décidé de tester deux ORM Python (SQLALchemy et PonyORM) en utilisant la méthode de test TPC-C adaptée à cette tâche. Le but du test est d'évaluer la vitesse de traitement des transactions lorsque plusieurs utilisateurs virtuels accèdent à la base de données en même temps.
Description du test
Dans le test que j'ai écrit, une base de données est d'abord créée et remplie, qui est une base de données d'un réseau d'entrepôts. Le schéma de la base de données ressemble à ceci :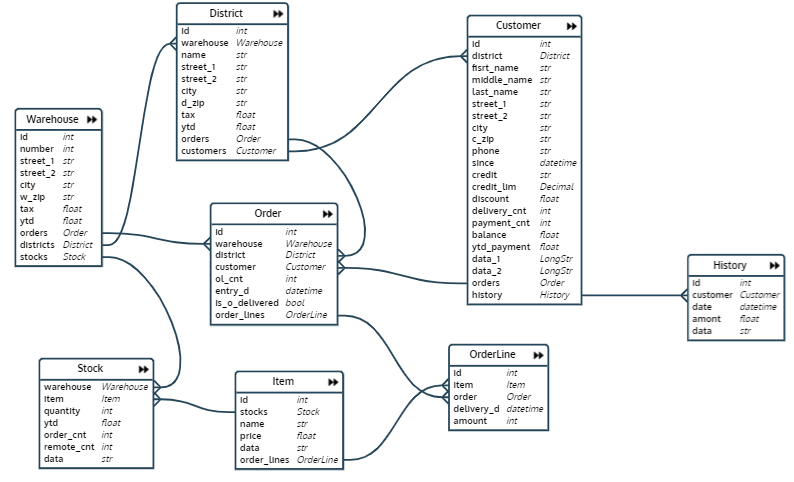
La base de données comprend huit relations:
- Entrepôt - entrepôt
- Quartier - zone d'entrepôt
- Commande - Commande
- OrderLine - ligne de commande (poste de commande)
- Stock - quantité d'un certain produit dans un entrepôt spécifique
- Article - article
- Client - client
- Historique - Historique des paiements clients
, e . . , :
- new_order ( ) — 45%
- payment ( ) — 43%
- order_status ( ) — 4%
- delivery ( ) — 4%
- stock_level ( ) — 4%
, TPC-C.
TPC-C , , ORM, . 64+ , .
:
- ,
- . : Stock 100 000 * W, W — , : 100 * W
- 5 . Payment ID, . ID,
- NewOrder. , , Order, NewOrder. , NewOrder. , , , , , . Order bool “is_o_delivered”, False, ,
, .
New Order
- : id id
- id
- ()
- . Item.
- , .
Payment
- : id id
- id
- .
- 1
- , ,
- .
Statut de la commande
- Transactions servies par l'ID client
- Le client et sa dernière commande sont extraits de la base de données
- Le statut est repris de la commande (livrée ou non) et des articles commandés
Livraison
- Transactions servies par l'identifiant de l'entrepôt
- L'entrepôt est demandé à la base de données par id et toutes ses sections
- Pour chaque site, la plus ancienne des commandes non livrées est prise. Dans chacun d'eux, le statut de livraison devient True
- De la base de données sont extraits les utilisateurs dont les commandes ont été livrées lors de cette transaction, et chacun augmente le compteur de livraison
Niveau de stock
- Transactions servies par l'identifiant de l'entrepôt
- L'entrepôt est demandé à la base de données par id
- Les 20 dernières commandes de cet entrepôt sont demandées à partir de la base de données
- Pour chaque article de ces commandes de la base de données, la quantité des marchandises restantes dans l'entrepôt est demandée
Résultats de test
Deux ORM participent aux tests:- SQLAlchemy Les graphiques sont représentés par une ligne bleue.
- PonyORM. Les graphiques sont représentés par la ligne jaune.
10 2 , . multiprocessing.
—
—
PostgreSQL
, TPC-C. Pony .

:
Pony — 2543 /
SQLAlchemy — 1353.4 /
ORM . .
“New Order”

Vitesse moyenne:
Pony - 3349,2 trans / min
SQLAlchemy - 1415,3 trans / min
Transaction «Paiement»
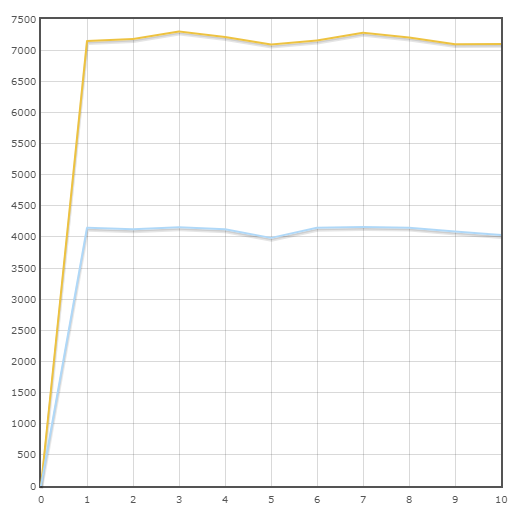
Vitesse moyenne:
Pony - 7175,3 trans / min
SQLAlchemy - 4110,6 trans / min
Transaction «État de la commande»
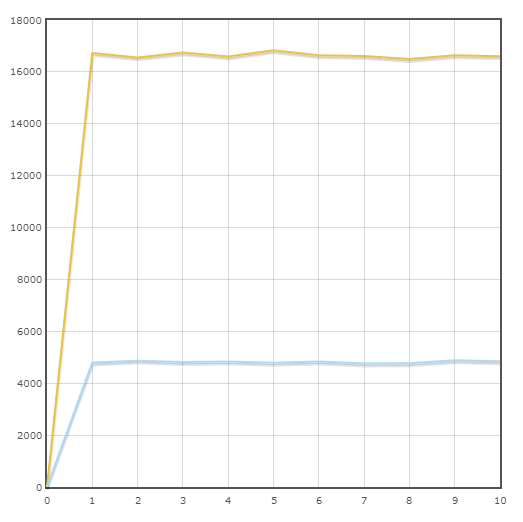
Vitesse moyenne:
Pony - 16645,6 trans / min
SQLAlchemy - 4820,8 trans / min
Transaction «Livraison»
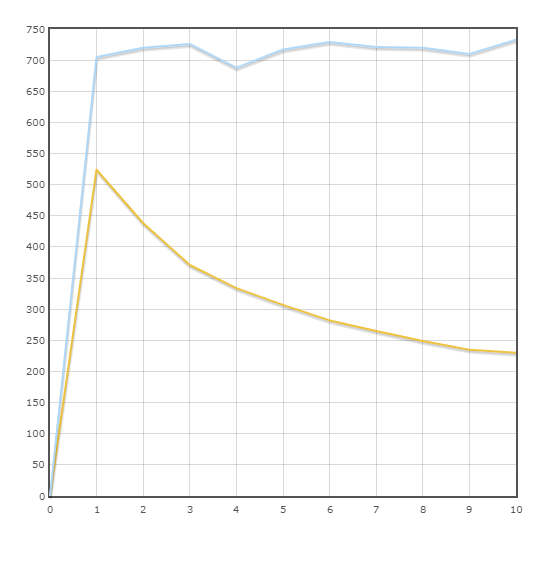
Vitesse moyenne:
SQLAlchemy - 716,9 trans / min
Pony - 323,5 trans / min
Transaction «Niveau de stock»
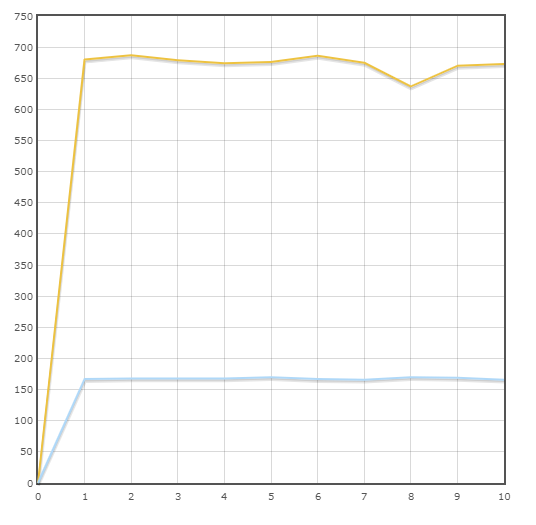
Vitesse moyenne:
Pony - 677,3 trans / min
SQLAlchemy - 167,9 trans / min
Analyse des résultats des tests
Après avoir reçu les résultats, j'ai analysé pourquoi, dans diverses situations, un ORM est plus rapide qu'un autre et suis arrivé aux conclusions suivantes:4 5 PonyORM , , SQL PonyORM Python SQL, , SQLALchemy SQL . PonyORM:
stocks = select(stock for stock in Stock
if stock.warehouse == whouse
and stock.item in items).order_by(Stock.id).for_update()
SQLAlchemy:
stocks = session.query(Stock).filter(
Stock.warehouse == whouse, Stock.item.in_(items)).order_by(text("id")).with_for_update()
SQLAlchemy Delivery , UPDATE, , .
, SQLAlchemy:
INFO:sqlalchemy.engine.base.Engine:UPDATE order_line SET delivery_d=%(delivery_d)s WHERE order_line.id = %(order_line_id)s
INFO:sqlalchemy.engine.base.Engine:(
{'delivery_d': datetime.datetime(2020, 4, 6, 14, 33, 6, 922281), 'order_line_id': 316},
{'delivery_d': datetime.datetime(2020, 4, 6, 14, 33, 6, 922272), 'order_line_id': 317},
{'delivery_d': datetime.datetime(2020, 4, 6, 14, 33, 6, 922261))
Pony Update:
SELECT "id", "delivery_d", "item", "amount", "order"
FROM "orderline"
WHERE "order" = %(p1)s
{'p1':911}
UPDATE "orderline"
SET "delivery_d" = %(p1)s
WHERE "id" = %(p2)s
AND "order" = %(p3)s
{'p1':datetime.datetime(2020, 4, 7, 17, 48, 58, 585932), 'p2':5047, 'p3':911}
UPDATE "orderline"
SET "delivery_d" = %(p1)s
WHERE "id" = %(p2)s
AND "order" = %(p3)s
{'p1':datetime.datetime(2020, 4, 7, 17, 48, 58, 585990), 'p2':5048, 'p3':911}
Sur la base des résultats de ces tests, je peux dire que Pony est beaucoup plus rapide lors de la récupération à partir de la base de données, et SQLAlchemy peut dans certains cas produire des requêtes de mise à jour beaucoup plus rapides.À l'avenir, je prévois de tester d'autres ORM (Peewee, Django) de cette manière.
Références
Code de test: lien vers le référentiel
SQLAlchemy: documentation , communauté
Pony: documentation , communauté