Une fois qu'il est devenu intéressant quels sujets le LDA (placement latent de Dirichlet) mettrait en évidence sur les matériaux du "Live Journal". Comme on dit, il y a de l'intérêt - pas de problème.Pour commencer, un peu de la LDA sur les doigts, nous n'entrerons pas dans les détails mathématiques (toute personne intéressée - lit). Ainsi, LDA - est l'un des algorithmes les plus courants pour la modélisation de sujets. Chaque document (que ce soit un article, un livre ou toute autre source de données textuelles) est un mélange de sujets, et chaque sujet est un mélange de mots.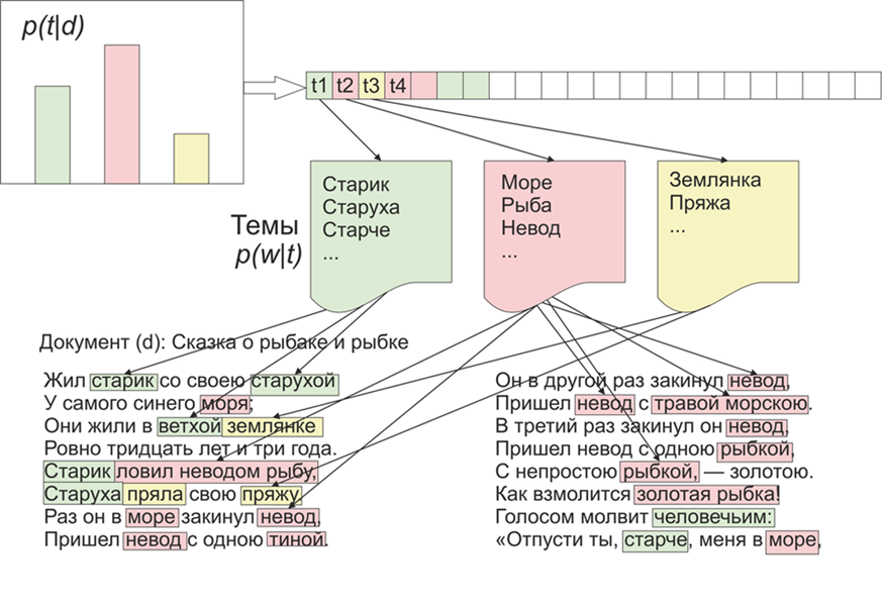 Image tirée de WikipediaAinsi, la tâche de la LDA est de trouver des groupes de mots qui forment des sujets à partir d'une collection de documents. Ensuite, en fonction des sujets, vous pouvez regrouper des textes ou simplement mettre en évidence des mots clés.Environ 1800 articles ont été reçus du site LifeJournal, tous ont été convertis au format jsonl. Je laisserai les articles non nettoyés sur le disque Yandex . Nous ferons un peu de nettoyage et de normalisation des données: jetez les commentaires, supprimez les mots vides (la liste avec le code source est disponible sur github), nous allons réduire tous les mots en orthographe minuscule, supprimer la ponctuation et les mots contenant 3 lettres ou moins. Mais l'une des principales opérations de prétraitement: la suppression de mots fréquents, en principe, peut se limiter à supprimer uniquement les mots d'arrêt, mais les mots souvent utilisés seront alors inclus dans presque tous les sujets à forte probabilité. Dans ce cas, il sera possible de post-traiter et de supprimer ces mots. Le choix t'appartient.
Image tirée de WikipediaAinsi, la tâche de la LDA est de trouver des groupes de mots qui forment des sujets à partir d'une collection de documents. Ensuite, en fonction des sujets, vous pouvez regrouper des textes ou simplement mettre en évidence des mots clés.Environ 1800 articles ont été reçus du site LifeJournal, tous ont été convertis au format jsonl. Je laisserai les articles non nettoyés sur le disque Yandex . Nous ferons un peu de nettoyage et de normalisation des données: jetez les commentaires, supprimez les mots vides (la liste avec le code source est disponible sur github), nous allons réduire tous les mots en orthographe minuscule, supprimer la ponctuation et les mots contenant 3 lettres ou moins. Mais l'une des principales opérations de prétraitement: la suppression de mots fréquents, en principe, peut se limiter à supprimer uniquement les mots d'arrêt, mais les mots souvent utilisés seront alors inclus dans presque tous les sujets à forte probabilité. Dans ce cas, il sera possible de post-traiter et de supprimer ces mots. Le choix t'appartient.stop=open('stop.txt')
stop_words=[]
for line in stop:
stop_words.append(line)
for i in range(0,len(stop_words)):
stop_words[i]=stop_words[i][:-1]
texts=[re.split( r' [\w\.\&\?!,_\-#)(:;*%$№"\@]* ' ,texts[i])[0].replace("\n","") for i in range(0,len(texts))]
texts=[test_re(line) for line in texts]
texts=[t.lower() for t in texts]
texts = [[word for word in document.split() if word not in stop_words] for document in texts]
texts=[[word for word in document if len(word)>=3]for document in texts]
Ensuite, nous apportons tous les mots à leur forme normale: pour cela, nous utilisons la bibliothèque pymorphy2, qui peut être installée via pip.morph = pymorphy2.MorphAnalyzer()
for i in range(0,len(texts)):
for j in range(0,len(texts[i])):
texts[i][j] = morph.parse(texts[i][j])[0].normal_form
Oui, nous perdrons des informations sur la forme des mots, mais dans ce contexte, nous sommes plus intéressés par la compatibilité des mots entre eux. C'est là que notre prétraitement est terminé, il n'est pas terminé, mais il suffit de voir comment fonctionne l'algorithme LDA.De plus, le point mentionné ci-dessus, en principe, peut être omis, mais à mon avis, les résultats sont plus adéquats, encore une fois, quel sera le seuil, vous décidez, par exemple, vous pouvez créer une fonction qui dépend de la longueur moyenne des documents et de leur nombre :counter = collections.Counter()
for t in texts:
for r in t:
counter[r]+=1
limit = len(texts)/5
too_common = [w for w in counter if counter[w] > limit]
too_common=set(too_common)
texts = [[word for word in document if word not in too_common] for document in texts]
Passons directement à la formation du modèle, pour cela nous devons installer la bibliothèque gensim, qui contient un tas de petits pains sympas. Vous devez d'abord encoder tous les mots, la fonction Dictionnaire le fera pour nous, puis nous remplacerons les mots par leurs équivalents numériques. La version commentée de l'appel LDA est plus longue, car elle est mise à jour après chaque document, vous pouvez jouer avec les paramètres et sélectionner l'option appropriée.texts=preposition_text_for_lda(my_r)
dictionary = gensim.corpora.Dictionary(texts)
corpus = [dictionary.doc2bow(text) for text in texts]
lda = gensim.models.ldamodel.LdaModel(corpus=corpus, id2word=dictionary, num_topics=10)
Après le travail du programme, les sujets peuvent être consultés à l'aide de la commandelda.show_topic(i,topn=30)
, où i est le numéro du sujet et topn est le nombre de mots du sujet à afficher.Maintenant, un petit bonus pour visualiser les thèmes, pour cela, vous devez installer la bibliothèque wordcloud (comme, des utilitaires similaires sont également dans matplotlib). Ce code visualise les thèmes et les enregistre dans le dossier actuel.from wordcloud import WordCloud, STOPWORDS
for i in range(0,10):
a=lda.show_topic(i,topn=30)
wordcloud = WordCloud(
relative_scaling = 1.0,
stopwords = too_common
).generate_from_frequencies(dict(a))
wordcloud.to_file('society'+str(i)+'.png')
Et enfin, quelques exemples des sujets que j'ai obtenus:
 Expérimentez et vous pouvez obtenir des résultats encore plus significatifs.
Expérimentez et vous pouvez obtenir des résultats encore plus significatifs.