 Bonjour mes amis!Cet article explique certains concepts de la théorie de la musique sur lesquels l'API Web Audio (WAA) fonctionne. Connaissant ces concepts, vous pouvez prendre des décisions éclairées lors de la conception audio dans une application. Cet article ne fera pas de vous un ingénieur du son expérimenté, mais il vous aidera à comprendre pourquoi WAA fonctionne ainsi.
Bonjour mes amis!Cet article explique certains concepts de la théorie de la musique sur lesquels l'API Web Audio (WAA) fonctionne. Connaissant ces concepts, vous pouvez prendre des décisions éclairées lors de la conception audio dans une application. Cet article ne fera pas de vous un ingénieur du son expérimenté, mais il vous aidera à comprendre pourquoi WAA fonctionne ainsi.Circuit audio
L'essence de WAA est d'effectuer certaines opérations avec du son dans un contexte audio. Cette API a été spécialement conçue pour le routage modulaire. Les opérations de base avec le son sont des nœuds audio, interconnectés et formant un diagramme de routage (graphe de routage audio). Plusieurs sources - avec différents types de canaux - sont traitées dans un même contexte. Cette conception modulaire offre la flexibilité nécessaire pour créer des fonctions complexes avec des effets dynamiques.Les nœuds audio sont interconnectés via des entrées et des sorties, forment une chaîne qui commence à partir d'une ou plusieurs sources, traverse un ou plusieurs nœuds et se termine à la destination. En principe, vous pouvez vous passer d'une destination, par exemple, si nous voulons simplement visualiser certaines données audio. Un flux de travail audio Web typique ressemble à ceci:- Créer un contexte audio
- Dans le contexte, créez des sources - telles que <audio>, un oscillateur (générateur de sons) ou un flux
- Créez des nœuds d'effets tels que la réverbération , le filtre biquad, le panoramique ou le compresseur
- Sélectionnez une destination pour l'audio, comme des haut-parleurs sur l'ordinateur d'un utilisateur
- Établir une connexion entre les sources via des effets vers une destination

Désignation de canal
Le nombre de canaux audio disponibles est souvent indiqué au format numérique, par exemple 2.0 ou 5.1. C'est ce qu'on appelle la désignation du canal. Le premier chiffre indique la gamme complète de fréquences que le signal comprend. Le deuxième chiffre indique le nombre de canaux réservés aux sorties d'effet basse fréquence - subwoofers .Chaque entrée ou sortie se compose d'un ou plusieurs canaux construits selon un certain circuit audio. Il existe différentes structures de canaux discrets tels que mono, stéréo, quad, 5.1, etc.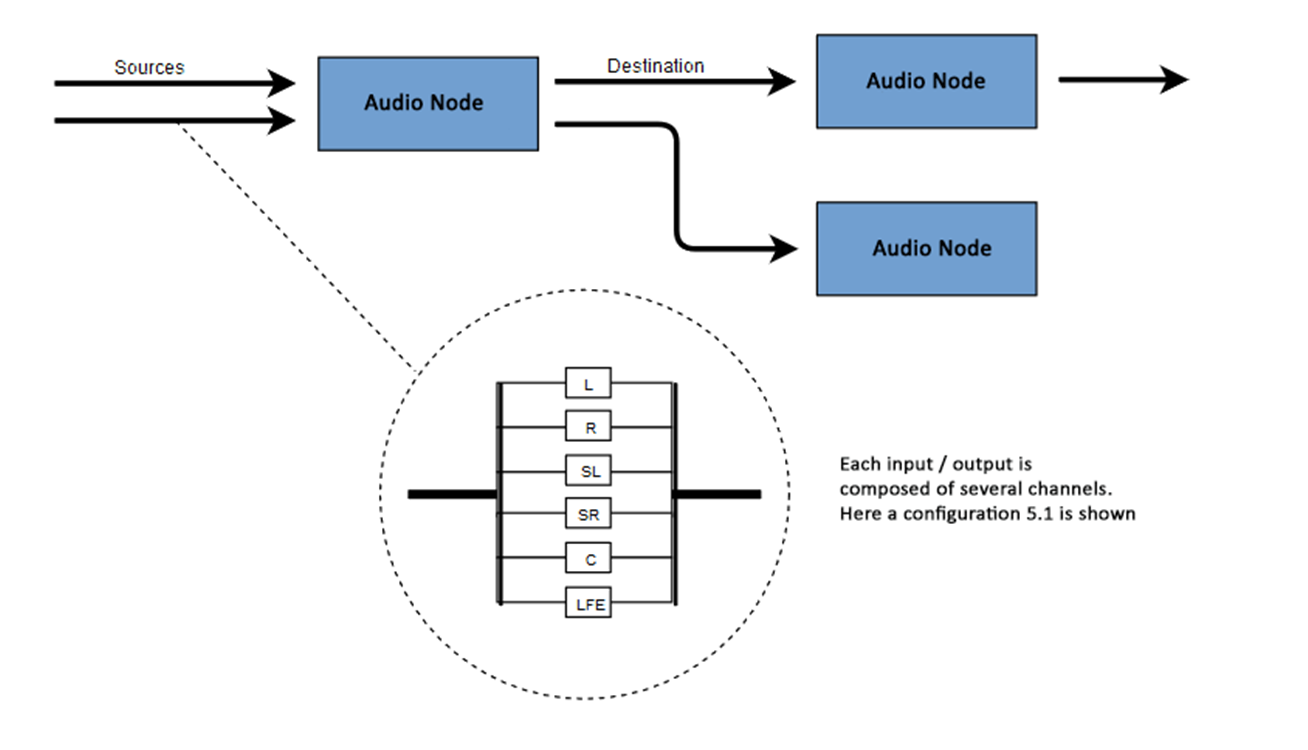 Les sources audio peuvent être obtenues de plusieurs façons. Le son peut être:
Les sources audio peuvent être obtenues de plusieurs façons. Le son peut être:- Généré par JavaScript via un nœud audio (tel qu'un oscillateur)
- Créé à partir de données brutes en utilisant PCM (Pulse Code Modulation)
- Dérivé d'éléments multimédias HTML (tels que <video> ou <audio>)
- Dérivé d'un flux multimédia WebRTC (comme une webcam ou un microphone)
Données audio: ce qui est dans l' échantillon
L'échantillonnage signifie la conversion d'un signal continu en un signal discret (divisé) (analogique en numérique). En d'autres termes, une onde sonore continue, comme un concert en direct, est convertie en une séquence d'échantillons, ce qui permet à l'ordinateur de traiter l'audio en blocs séparés.Tampon audio: images, échantillons et canaux
AudioBuffer accepte le nombre de canaux comme paramètres (1 pour mono, 2 pour stéréo, etc.), la longueur - le nombre de trames d'échantillonnage à l'intérieur du tampon et la fréquence d'échantillonnage - le nombre de trames par seconde.Un échantillon est une simple valeur à virgule flottante de 32 bits (float32), qui est la valeur du flux audio à un moment donné et dans un canal particulier (gauche ou droite, etc.). Une trame ou trame d'échantillonnage est un ensemble de valeurs de tous les canaux reproduits à un certain moment: tous les échantillons de tous les canaux reproduits en même temps (deux pour la stéréo, six pour la 5.1, etc.).Le taux d'échantillonnage est le nombre d'échantillons (ou de trames, puisque tous les échantillons d'une trame sont lus en même temps), lus en une seconde, mesurés en hertz (Hz). Plus la fréquence est élevée, meilleure est la qualité sonore.Regardons les buffers mono et stéréo, d'une seconde de long, reproduits à une fréquence de 44100 Hz:- Le tampon mono aura 44100 échantillons et 44100 images. La valeur de la propriété «length» est 44100
- Le tampon stéréo aura 88 200 échantillons, mais également 44 100 images. La valeur de la propriété «length» sera 44100 - la longueur est égale au nombre d'images
 Lorsque la lecture du tampon commence, nous entendons d'abord l'image la plus à gauche de l'échantillon, puis l'image la plus proche à droite, etc. Dans le cas de la stéréo, nous entendons les deux canaux simultanément. Les trames d'échantillonnage sont indépendantes du nombre de canaux et offrent la possibilité d'un traitement audio très précis.Remarque: pour obtenir le temps en secondes à partir du nombre d'images, il est nécessaire de diviser le nombre d'images par la fréquence d'échantillonnage. Pour obtenir le nombre d'images du nombre d'échantillons, divisez ce dernier par le nombre de canaux.Exemple:
Lorsque la lecture du tampon commence, nous entendons d'abord l'image la plus à gauche de l'échantillon, puis l'image la plus proche à droite, etc. Dans le cas de la stéréo, nous entendons les deux canaux simultanément. Les trames d'échantillonnage sont indépendantes du nombre de canaux et offrent la possibilité d'un traitement audio très précis.Remarque: pour obtenir le temps en secondes à partir du nombre d'images, il est nécessaire de diviser le nombre d'images par la fréquence d'échantillonnage. Pour obtenir le nombre d'images du nombre d'échantillons, divisez ce dernier par le nombre de canaux.Exemple:let context = new AudioContext()
let buffer = context.createBuffer(2, 22050, 44100)
Remarque: en audio numérique, 44100 Hz ou 44,1 kHz est la fréquence d'échantillonnage standard. Mais pourquoi 44,1 kHz?D'abord parce que la gamme de fréquences audibles (fréquences reconnaissables par l'oreille humaine) varie de 20 à 20 000 Hz. Selon le théorème de Kotelnikov, la fréquence d'échantillonnage devrait plus que doubler la fréquence la plus élevée du spectre du signal. Par conséquent, la fréquence d'échantillonnage doit être supérieure à 40 kHz.Deuxièmement, les signaux doivent être filtrés à l'aide d'un filtre passe-bas.avant l'échantillonnage, sinon il y aura un chevauchement des «queues» spectrales (permutation de fréquence, masquage de fréquence, repliement) et la forme du signal reconstruit sera déformée. Idéalement, un filtre passe-bas devrait passer des fréquences inférieures à 20 kHz (sans atténuation) et des fréquences supérieures à 20 kHz. En pratique, une bande de transition est nécessaire (entre la bande passante et la bande de suppression), où les fréquences sont partiellement atténuées. Un moyen plus simple et plus économique de procéder consiste à utiliser un filtre anti-changement. Pour une fréquence d'échantillonnage de 44,1 kHz, la bande de transition est de 2,05 kHz.Dans l'exemple ci-dessus, nous obtenons un tampon stéréo à deux canaux, reproduit dans un contexte audio avec une fréquence de 44100 Hz (standard), 0,5 seconde de long (22050 images / 44100 Hz = 0,5 s).let context = new AudioContext()
let buffer = context.createBuffer(1, 22050, 22050)
Dans ce cas, nous obtenons un tampon mono avec un canal, reproduit dans un contexte audio avec une fréquence de 44100 Hz, il suréchantillonnera à 44100 Hz (et augmentera les images à 44100), 1 seconde de long (44100 images / 44100 Hz = 1 s).Remarque: le rééchantillonnage audio («rééchantillonnage») est très similaire au redimensionnement («redimensionnement») des images. Supposons que nous ayons une image 16x16, mais nous voulons remplir cette zone avec une taille 32x32. Nous redimensionnons. Le résultat sera de moins bonne qualité (il peut être flou ou déchiré selon l'algorithme de zoom), mais cela fonctionne. Le rééchantillonnage audio est la même chose: nous économisons de l'espace, mais en pratique, il est peu probable d'obtenir un son de haute qualité.Tampons planaires et rayés
WAA utilise un format de tampon planaire. Les canaux gauche et droit interagissent comme suit:LLLLLLLLLLLLLLLLRRRRRRRRRRRRRRRR ( , 16 )
Dans ce cas, chaque canal fonctionne indépendamment des autres.Une alternative consiste à utiliser un format alternatif:LRLRLRLRLRLRLRLRLRLRLRLRLRLRLRLR ( , 16 )
Ce format est souvent utilisé pour le décodage MP3.WAA utilise uniquement le format plan, car il est mieux adapté au traitement du son. Le format plan est converti en alternance lorsque des données sont envoyées à la carte son pour la lecture. Lors du décodage de MP3, l'inverse est converti.Chaînes audio
Différents tampons contiennent un nombre différent de canaux: du simple mono (un canal) et stéréo (canaux gauche et droit) aux ensembles plus complexes tels que quad et 5.1 avec un nombre différent d'échantillons dans chaque canal, ce qui fournit un son plus riche (plus riche). Les canaux sont généralement représentés par des abréviations:Mélange ascendant et descendant
Lorsque le nombre de canaux en entrée et en sortie ne correspond pas, appliquez le mixage vers le haut ou vers le bas. Le mixage est contrôlé par la propriété AudioNode.channelInterpretation:Visualisation
La visualisation est basée sur la réception des données audio de sortie, telles que les données sur l'amplitude ou la fréquence, et leur traitement ultérieur en utilisant n'importe quelle technologie graphique. WAA possède un AnalyzerNode qui ne déforme pas le signal qui le traverse. Dans le même temps, il est capable d'extraire des données de l'audio et de les transférer plus loin, par exemple, dans & ltcanvas>.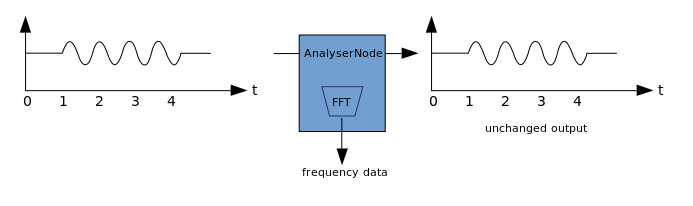 Les méthodes suivantes peuvent être utilisées pour extraire des données:
Les méthodes suivantes peuvent être utilisées pour extraire des données:- AnalyzerNode.getFloatByteFrequencyData () - copie les données de fréquence actuelles dans le Float32Array
- AnalyzerNode.getByteFrequencyData () - copie les données de fréquence actuelles dans un Uint8Array (tableau d'octets non signé)
- AnalyserNode.getFloatTimeDomainData() — Float32Array
- AnalyserNode.getByteTimeDomainData() — Uint8Array
La spatialisation audio (traitée par PannerNode et AudioListener) vous permet de simuler la position et la direction du signal à un point spécifique de l'espace, ainsi que la position de l'auditeur.La position du panoramique est décrite en utilisant des coordonnées cartésiennes pour droitiers; pour le mouvement, le vecteur vitesse nécessaire pour créer l'effet Doppler est utilisé ; pour la direction, le cône de directivité est utilisé. Ce cône peut être très volumineux dans le cas de sources sonores multidirectionnelles. La position de l'auditeur est décrite comme suit: mouvement - en utilisant le vecteur vitesse, la direction où se trouve la tête de l'auditeur - en utilisant deux vecteurs directionnels, avant et haut. Le claquement se fait au sommet de la tête et du nez de l'auditeur à angle droit.
La position de l'auditeur est décrite comme suit: mouvement - en utilisant le vecteur vitesse, la direction où se trouve la tête de l'auditeur - en utilisant deux vecteurs directionnels, avant et haut. Le claquement se fait au sommet de la tête et du nez de l'auditeur à angle droit.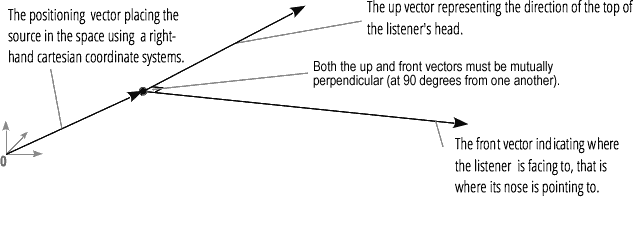
Jonction et ramification
Une connexion décrit un processus dans lequel un ChannelMergerNode reçoit plusieurs sources mono d'entrée et les combine en un seul signal de sortie multicanal.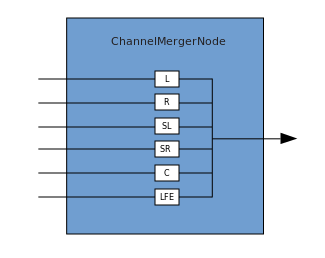 La ramification est le processus inverse (implémenté via ChannelSplitterNode).
La ramification est le processus inverse (implémenté via ChannelSplitterNode).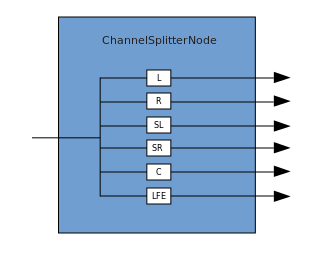 Un exemple de travail avec WAA peut être trouvé ici . Le code source de l'exemple est ici . Voici un article sur la façon dont tout cela fonctionne.Merci de votre attention.
Un exemple de travail avec WAA peut être trouvé ici . Le code source de l'exemple est ici . Voici un article sur la façon dont tout cela fonctionne.Merci de votre attention.