 Bonjour, dans des articles antérieurs, nous avons découvert le travail d'ELK Stack. Et maintenant, nous allons discuter des possibilités qui peuvent être réalisées par un spécialiste de la sécurité de l'information en utilisant ces systèmes. Quels journaux peuvent et doivent être créés dans elasticsearch. Examinons quelles statistiques peuvent être obtenues en configurant des tableaux de bord et s'il y a un bénéfice à cela. Comment il est possible de mettre en œuvre l'automatisation des processus de sécurité de l'information à l'aide de la pile ELK. Nous composons l'architecture du système. En somme, la mise en œuvre de toutes les fonctionnalités est une tâche très importante et difficile, de sorte que la solution a été désignée sous un nom distinct - TS Total Sight.Actuellement, les solutions regroupant et analysant les incidents de sécurité de l'information dans un seul endroit logique gagnent en popularité. Par conséquent, un spécialiste reçoit des statistiques et une ligne de front d'actions pour améliorer l'état de sécurité d'une organisation. Nous nous sommes fixé cette tâche en utilisant la pile ELK, par conséquent, nous avons alloué la fonctionnalité principale en 4 sections:
Bonjour, dans des articles antérieurs, nous avons découvert le travail d'ELK Stack. Et maintenant, nous allons discuter des possibilités qui peuvent être réalisées par un spécialiste de la sécurité de l'information en utilisant ces systèmes. Quels journaux peuvent et doivent être créés dans elasticsearch. Examinons quelles statistiques peuvent être obtenues en configurant des tableaux de bord et s'il y a un bénéfice à cela. Comment il est possible de mettre en œuvre l'automatisation des processus de sécurité de l'information à l'aide de la pile ELK. Nous composons l'architecture du système. En somme, la mise en œuvre de toutes les fonctionnalités est une tâche très importante et difficile, de sorte que la solution a été désignée sous un nom distinct - TS Total Sight.Actuellement, les solutions regroupant et analysant les incidents de sécurité de l'information dans un seul endroit logique gagnent en popularité. Par conséquent, un spécialiste reçoit des statistiques et une ligne de front d'actions pour améliorer l'état de sécurité d'une organisation. Nous nous sommes fixé cette tâche en utilisant la pile ELK, par conséquent, nous avons alloué la fonctionnalité principale en 4 sections:- Statistiques et visualisation;
- Détection d'incident SI;
- Hiérarchisation des incidents;
- Automatisation des processus de sécurité de l'information.
Ensuite, nous considérons plus en détail séparément.Détection des incidents de sécurité
La tâche principale dans l'utilisation d'elasticsearch dans notre cas est de collecter uniquement les incidents de sécurité des informations. Il est possible de collecter les incidents de sécurité des informations à partir de n'importe quel moyen de protection s'ils prennent en charge au moins certains modes de transfert de journaux, le standard est syslog ou scp.Vous pouvez donner des exemples standard de fonctionnalités de sécurité et pas seulement où configurer la redirection de journaux:- Tout moyen de NGFW (Check Point, Fortinet);
- Tous les scanners de vulnérabilité (PT Scanner, OpenVas);
- Pare-feu d'application Web (PT AF);
- Analyseurs Netflow (Flowmon, Cisco StealthWatch);
- Serveur AD.
Après avoir configuré le transfert de journaux et les fichiers de configuration dans Logstash, vous pouvez corréler et comparer avec les incidents provenant de divers outils de sécurité. Pour ce faire, il est pratique d'utiliser des index dans lesquels nous stockons tous les incidents liés à un appareil spécifique. En d'autres termes, un index correspond à tous les incidents sur un même appareil. Il existe 2 façons d'implémenter une telle distribution.La première option consiste à configurer la configuration Logstash. Pour ce faire, il est nécessaire de dupliquer le journal de certains champs dans une unité distincte avec un autre type. Et ensuite, utilisez ce type. Dans l'exemple, les journaux sont clonés à l'aide de la lame de pare-feu Check Point IPS.filter {
if [product] == "SmartDefense" {
clone {
clones => ["CloneSmartDefense"]
add_field => {"system" => "checkpoint"}
}
}
}
Afin de sauvegarder ces événements dans un index séparé, en fonction des champs de journal, par exemple, tels que les signatures d'attaque IP de destination. Vous pouvez utiliser une construction similaire:output {
if [type] == "CloneSmartDefense"{
{
elasticsearch {
hosts => [",<IP_address_elasticsearch>:9200"]
index => "smartdefense-%{dst}"
user => "admin"
password => "password"
}
}
}
Et de cette façon, vous pouvez enregistrer tous les incidents dans l'index, par exemple, par adresse IP ou par nom de domaine de la machine. Dans ce cas, nous enregistrons dans l'index «smartdefense -% {dst}» , à l'adresse IP de la signature.Cependant, différents produits auront des champs différents pour les journaux, ce qui conduira au chaos et à une consommation de mémoire inutile. Et ici, il sera nécessaire soit soigneusement dans les paramètres de configuration de Logstash de remplacer les champs par ceux précédemment conçus, qui seront les mêmes pour tous les types d'incidents, ce qui est également une tâche difficile.Deuxième option de mise en œuvre- il s'agit d'écrire un script ou un processus qui accédera à la base de données élastique en temps réel, extraira les incidents nécessaires et l'enregistrera dans un nouvel index, c'est une tâche difficile, mais cela vous permet de travailler avec les journaux comme bon vous semble et de corréler directement avec les incidents des autres fonctions de sécurité. Cette option vous permet de configurer le travail avec des journaux aussi utiles que possible pour votre cas avec une flexibilité maximale, mais ici, il y a un problème pour trouver un spécialiste qui peut l'implémenter.Et bien sûr, la question la plus importante, mais qu'est-ce qui peut généralement être tracé et découvert ?Il peut y avoir plusieurs options, et selon les fonctionnalités de sécurité utilisées dans votre infrastructure, quelques exemples:- NGFW . IPS . ( ) IPS, — , .
- , .
- .
La raison la plus évidente et la plus compréhensible pour laquelle vous avez besoin d'ELK Stack est le stockage et la visualisation des journaux, dans les articles précédents, il a été montré comment enregistrer des fichiers à partir de divers appareils à l'aide de Logstash. Une fois que les journaux sont passés à Elasticsearch, vous pouvez configurer des tableaux de bord, qui ont également été mentionnés dans les articles précédents , avec les informations et les statistiques nécessaires pour vous grâce à la visualisation.Exemples:- Tableau de bord des événements de prévention des menaces avec les événements les plus critiques. Ici, vous pouvez indiquer quelles signatures IPS ont été détectées, d'où elles proviennent géographiquement.
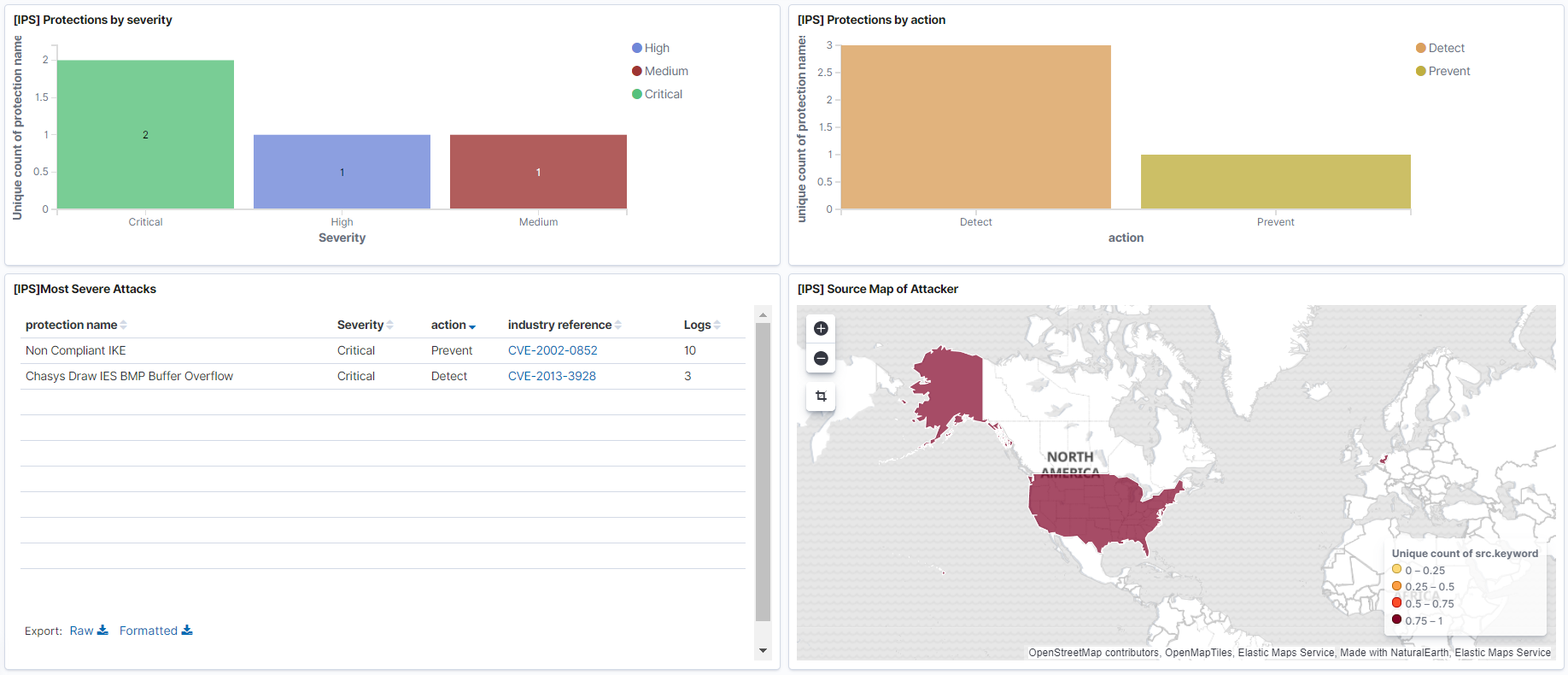
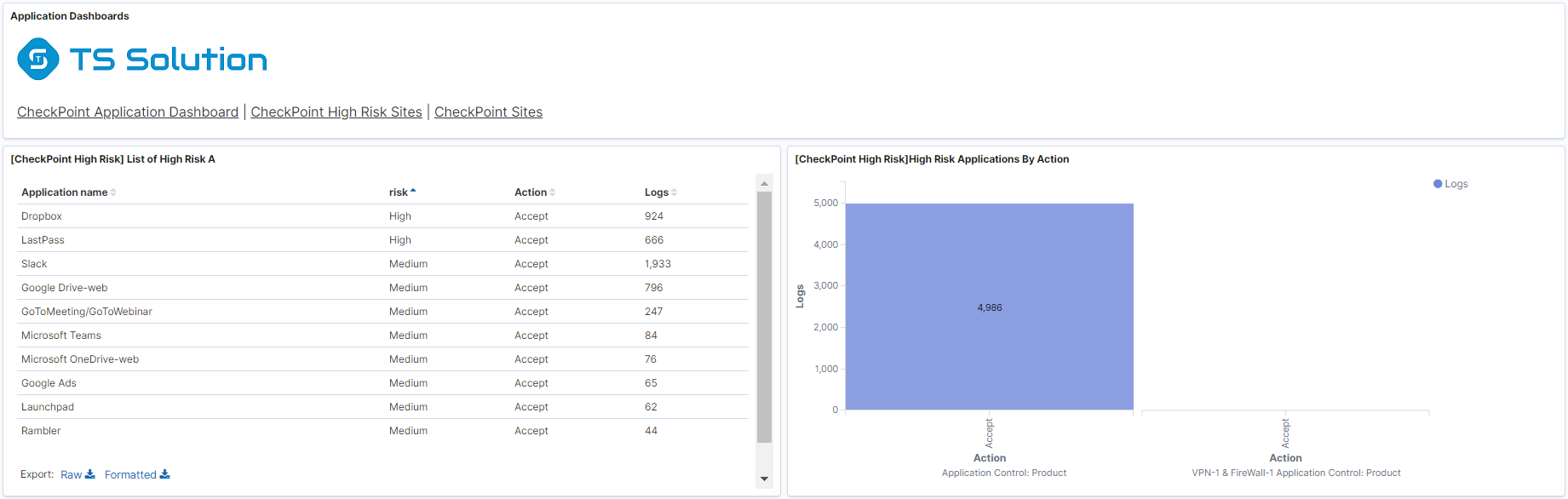
- Tableau de bord sur l'utilisation des applications les plus critiques pour lesquelles les informations peuvent fusionner.
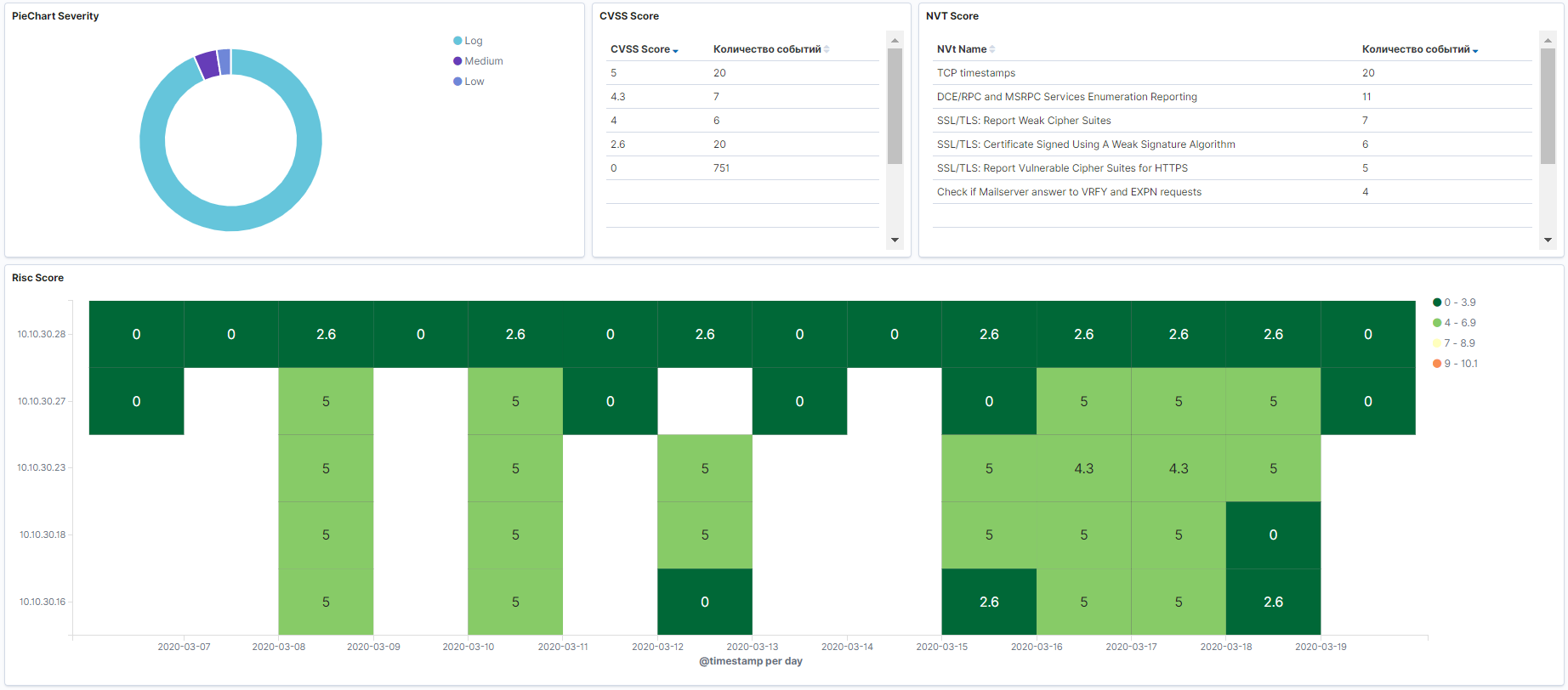
- Résultats de l'analyse à partir de n'importe quel scanner de sécurité.
- Journaux avec Active Directory par utilisateur.

- Tableau de bord de connexion VPN.
Dans ce cas, si vous configurez les tableaux de bord pour une mise à jour toutes les quelques secondes, vous pouvez obtenir un système assez pratique pour surveiller les événements en temps réel, qui peut ensuite être utilisé pour répondre rapidement aux incidents SI si vous placez les tableaux de bord sur un écran séparé.Hiérarchisation des incidents
Dans des conditions de grande infrastructure, le nombre d'incidents peut être hors des graphiques, et les spécialistes ne seront pas en mesure de gérer tous les incidents à temps. Dans ce cas, il faut tout d'abord distinguer les incidents qui constituent une grande menace. Par conséquent, le système doit prioriser les incidents en fonction de leur danger par rapport à votre infrastructure. Il est conseillé de mettre en place une alerte par mail ou télégramme de données d'événement. La hiérarchisation peut être implémentée à l'aide des outils Kibana standard en définissant la visualisation. Mais avec une notification, c'est plus difficile, par défaut, cette fonctionnalité n'est pas incluse dans la version de base d'Elasticsearch, seulement dans une version payante. Par conséquent, achetez une version payante ou, encore une fois, écrivez vous-même le processus qui en informera les spécialistes en temps réel par e-mail ou télégramme.Automatisation des processus de sécurité de l'information
Et l'une des parties les plus intéressantes est l'automatisation des actions sur les incidents de sécurité de l'information. Auparavant, nous avons implémenté cette fonctionnalité pour Splunk, un peu plus en détail, vous pouvez lire dans cet article . L'idée de base est que la politique IPS n'est jamais testée ni optimisée, bien que dans certains cas, elle soit un élément essentiel des processus de sécurité de l'information. Par exemple, un an après la mise en œuvre de NGFW et l'absence d'actions pour optimiser IPS, vous accumulerez un grand nombre de signatures avec l'action Détecter, qui ne sera pas bloquée, ce qui réduit considérablement l'état de sécurité des informations dans l'organisation. Voici quelques exemples de ce qui peut être automatisé:- IPS Detect Prevent. Prevent, , . . , NGFW REST API. , Elastcisearch API NGFW.
- IP , IP Firewall. REST API.
- Exécutez une analyse d'hôte avec un scanner de vulnérabilité si cet hôte possède un grand nombre de signatures via IPS ou d'autres outils de sécurité, s'il s'agit d'OpenVas, vous pouvez alors écrire un script qui se connectera via ssh au scanner de sécurité et commencera l'analyse.
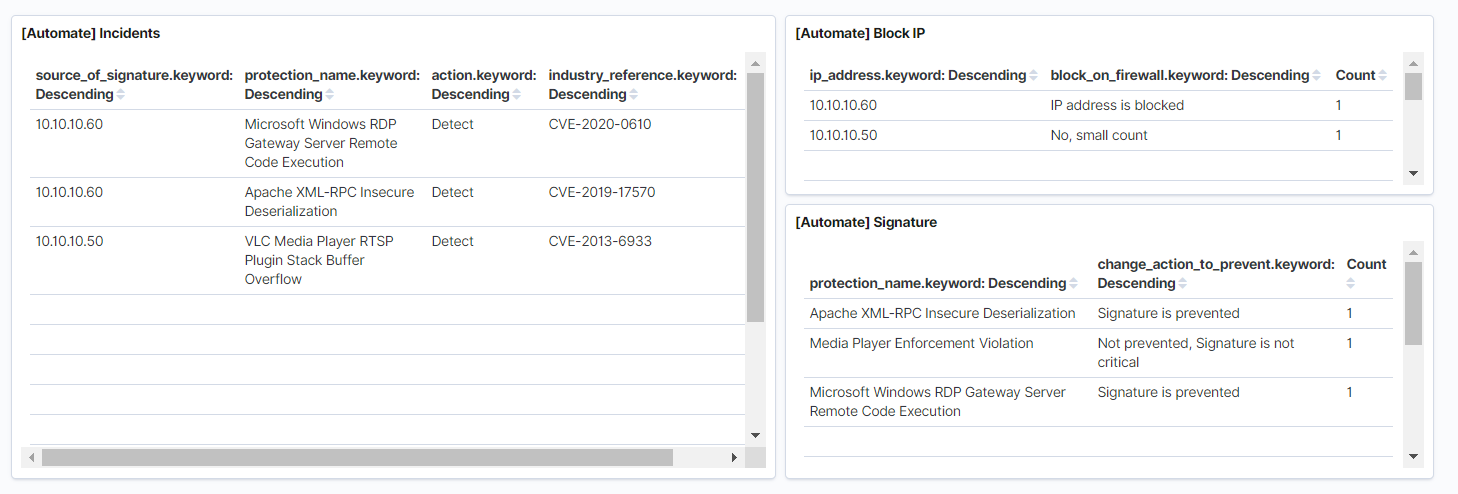
TS Total Sight
Au total, la mise en œuvre de toutes les fonctionnalités est une tâche très grande et difficile. Sans compétences en programmation, vous pouvez configurer la fonctionnalité minimale, qui peut être suffisante pour une utilisation dans le produit. Mais si vous êtes intéressé par toutes les fonctionnalités, vous pouvez faire attention à TS Total Sight. Vous pouvez trouver plus de détails sur notre site Web . En conséquence, l'ensemble du schéma de travail et d'architecture ressemblera à ceci: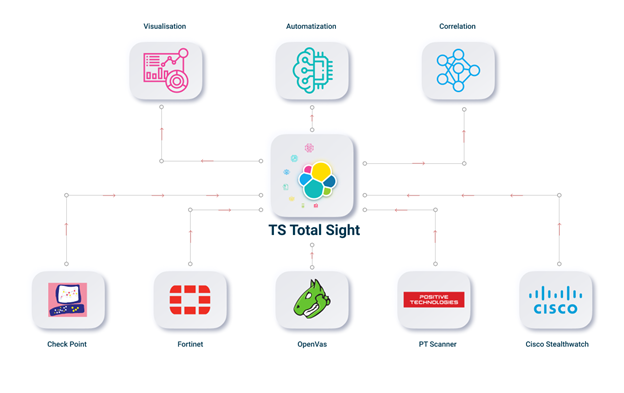
Conclusion
Nous avons examiné ce qui peut être implémenté avec ELK Stack. Dans les articles suivants, nous examinerons séparément plus en détail la fonctionnalité de TS Total Sight!Alors restez à l'écoute ( Telegram , Facebook , VK , TS Solution Blog ), Yandex.Zen .