 La photo que vous voyez est tirée du site DeepMind et montre 57 jeux dans lesquels leur dernier développement Agent57 ( revue de l'article sur Habré ) a réussi. Le nombre 57 lui-même n'a pas été retiré du plafond - exactement autant de jeux ont été choisis en 2012 pour devenir une sorte de référence parmi les développeurs d'IA pour les jeux Atari, après quoi divers chercheurs mesurent leurs réalisations sur cet ensemble de données particulier.Dans cet article, j'essaierai d'examiner ces réalisations sous différents angles afin d'évaluer leur valeur pour les tâches appliquées et de justifier pourquoi je ne crois pas que ce soit l'avenir. Et bien oui, il y aura beaucoup de photos sous la coupe, ai-je prévenu.Dans le lien ci-dessus, les développeurs écrivent les bonnes choses, en disant que
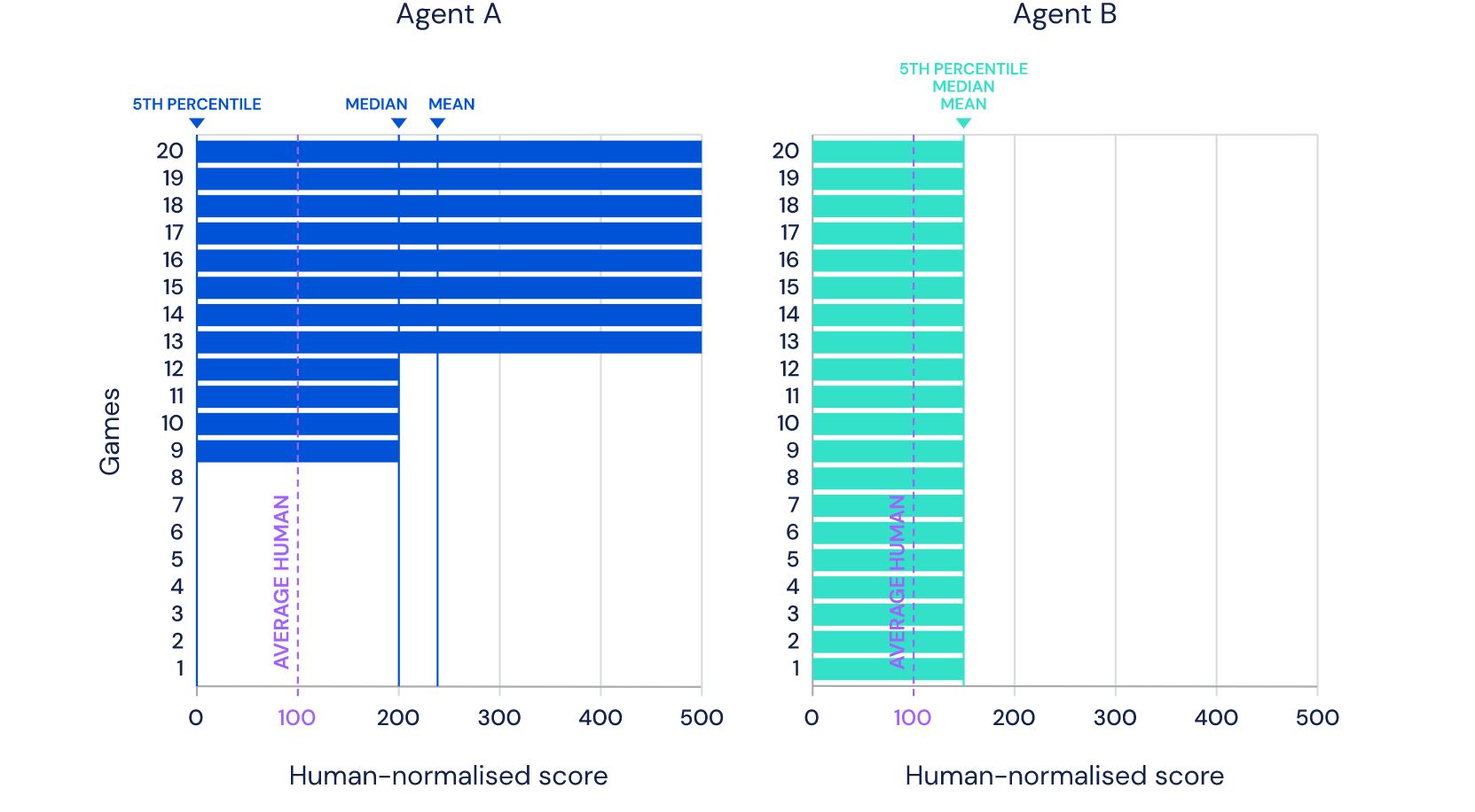
La photo que vous voyez est tirée du site DeepMind et montre 57 jeux dans lesquels leur dernier développement Agent57 ( revue de l'article sur Habré ) a réussi. Le nombre 57 lui-même n'a pas été retiré du plafond - exactement autant de jeux ont été choisis en 2012 pour devenir une sorte de référence parmi les développeurs d'IA pour les jeux Atari, après quoi divers chercheurs mesurent leurs réalisations sur cet ensemble de données particulier.Dans cet article, j'essaierai d'examiner ces réalisations sous différents angles afin d'évaluer leur valeur pour les tâches appliquées et de justifier pourquoi je ne crois pas que ce soit l'avenir. Et bien oui, il y aura beaucoup de photos sous la coupe, ai-je prévenu.Dans le lien ci-dessus, les développeurs écrivent les bonnes choses, en disant queSo although average scores have increased, until now, the number of above human games has not. As an illustrative example, consider a benchmark consisting of twenty tasks. Suppose agent A obtains a score of 500% on eight tasks, 200% on four tasks, and 0% on eight tasks (mean = 240%, median = 200%), while agent B obtains a score of 150% on all tasks (mean = median = 150%). On average, agent A performs better than agent B. However, agent B possesses a more general ability: it obtains human-level performance on more tasks than agent A.
 Ce qui sur les doigts signifie qu'avant tout le monde était mesuré dans le classement "moyen", en écartant les cas difficiles pour un ordinateur, mais maintenant ils ne les ont pris que. Et ainsi, ils ont atteint une réelle supériorité sur l'homme, et non des super-résultats sur des cas conviviaux.Mais regardons le problème plus globalement pour comprendre s'il en est ainsi. Quelle est l'interaction de l'IA DeepMind avec un jeu vidéoUn astérisque désignera ci-après les entités obtenues par un algorithme créé non pas avec l'aide de l'IA, mais avec l'aide d'experts.Avant de démonter le circuit, regardons une approche alternative:
Ce qui sur les doigts signifie qu'avant tout le monde était mesuré dans le classement "moyen", en écartant les cas difficiles pour un ordinateur, mais maintenant ils ne les ont pris que. Et ainsi, ils ont atteint une réelle supériorité sur l'homme, et non des super-résultats sur des cas conviviaux.Mais regardons le problème plus globalement pour comprendre s'il en est ainsi. Quelle est l'interaction de l'IA DeepMind avec un jeu vidéoUn astérisque désignera ci-après les entités obtenues par un algorithme créé non pas avec l'aide de l'IA, mais avec l'aide d'experts.Avant de démonter le circuit, regardons une approche alternative:Résumé vidéo- + ,

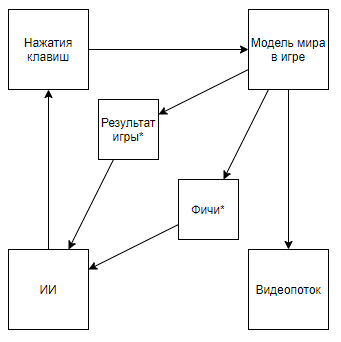 Le schéma devient comme ça. Et si vous montez sur la chaîne de l'auteur, vous pouvez trouver son application aux jeux rétro. En changeant le schéma en celui-ci, nous arrivons à la conclusion que la vitesse et l'efficacité de la formation augmentent de plusieurs ordres de grandeur, mais la valeur scientifique et technique des réalisations d'un tel voyage devient proche de 0 (et oui, je ne prends pas en compte la valeur de vulgarisation).Nous pouvons supposer que le fait est que la vidéo est lancée à partir du pipeline, mais considérons le schéma suivant (je suis sûr que quelqu'un a mis en œuvre quelque chose de similaire, mais il n'y a pas de lien à portée de main):Ce qui est mis en œuvre lorsqu'un expert qui connaît les fonctionnalités nécessaires écrit un analyseur de flux vidéo qui calcule les fonctionnalités à l'aide de pixels clés.Ou même un tel schéma:Dans un premier temps, AI1 est formé pour extraire des fonctionnalités sélectionnées par un expert de la vidéo.Et puis AI2 apprend à jouer par des fonctionnalités extraites du flux vidéo en utilisant AI1. Nous avons donc obtenu un schéma qui:
Le schéma devient comme ça. Et si vous montez sur la chaîne de l'auteur, vous pouvez trouver son application aux jeux rétro. En changeant le schéma en celui-ci, nous arrivons à la conclusion que la vitesse et l'efficacité de la formation augmentent de plusieurs ordres de grandeur, mais la valeur scientifique et technique des réalisations d'un tel voyage devient proche de 0 (et oui, je ne prends pas en compte la valeur de vulgarisation).Nous pouvons supposer que le fait est que la vidéo est lancée à partir du pipeline, mais considérons le schéma suivant (je suis sûr que quelqu'un a mis en œuvre quelque chose de similaire, mais il n'y a pas de lien à portée de main):Ce qui est mis en œuvre lorsqu'un expert qui connaît les fonctionnalités nécessaires écrit un analyseur de flux vidéo qui calcule les fonctionnalités à l'aide de pixels clés.Ou même un tel schéma:Dans un premier temps, AI1 est formé pour extraire des fonctionnalités sélectionnées par un expert de la vidéo.Et puis AI2 apprend à jouer par des fonctionnalités extraites du flux vidéo en utilisant AI1. Nous avons donc obtenu un schéma qui:- Utilise un flux vidéo et n'a pas d'accès direct au modèle du monde.
- Ne repose pas sur des analyseurs de flux vidéo écrits par un expert
- Il sera formé à la fois plus facilement et plus efficacement que le développement de DeepMind
Mais ... nous arrivons à la même chose. Une telle implémentation, encore une fois, n'aura aucune valeur scientifique ou technique dans le contexte de l'application aux jeux rétro, car AI1 est une tâche résolue de longue date et très primitive pour les algorithmes modernes de traitement d'image, et AI2 est également créée très rapidement et simplement, ce qui confirme l' auteur de la vidéo ci-dessus .Alors, quelle est la valeur des algorithmes DeepMind pour les jeux Atari? Je vais essayer de résumer: la valeur est queLes algorithmes DeepMind sont capables de trouver la stratégie de comportement optimale pour les jeux avec un modèle primitif du monde MM dans des conditions où l'état du modèle mondial S (MM, t) est représenté avec des distorsions importantes par une certaine fonction de distorsion F (S (MM, t)), seule la qualité des décisions prises peut être évaluée une fonction qui reçoit une séquence de valeurs F (S (MM, t)) et de réactions d'algorithme, et cette séquence est de longueur inconnue (le jeu peut se terminer par un nombre d'étapes différent), mais vous pouvez répéter l'expérience un nombre infini de fois .Anticiper les problèmes, . S(MM, t) , , . F(S(MM, t)) , .
Essayons maintenant d'évaluer l'applicabilité d'une telle valeur pour résoudre des problèmes du monde réel qui sont en corrélation avec les outils, à savoir qu'ils représentent un état réel avec des distorsions importantes, impliquent que l'environnement réagit aux actions de l'agent, ne donne une évaluation qu'après une longue séquence de décisions, et cependant, ils permettent d'effectuer l'expérience plusieurs fois.À première vue, une application intéressante semble être un jeu d'échange. Même les indices de Google, le trahissant comme le seul indice à utiliser dans le monde réel, indiquent que le sujet est chaud.Je soulignerai immédiatement un point important - presque toutes les approches de l'analyse de marché (sans compter les approches qui analysent des objets du monde réel, tels que les parkings devant les supermarchés, les actualités, les mentions d'actions sur Twitter) peuvent être divisées en deux types. Le premier type est celui des approches représentant le marché sous forme de séries chronologiques. Deuxièmement, comme un flux d'applications.D'une manière ou d'une autre, les partisans des approches du premier type voient le marché Mais la différence fondamentale ne réside pas dans les données utilisées, mais dans le fait que, en règle générale, ceux qui analysent le marché, en tant que série chronologique, négligent leur influence sur le marché, estimant que, conditionnellement, sur l'intervalle quotidien, leurs transactions n'affecteront pas la dynamique future du marché. Alors que les partisans de la deuxième approche peuvent tous deux négliger, estimant que leur volume est insignifiant par rapport à la liquidité du marché, et considérer le marché comme un système de rétroaction, estimant que leurs actions affectent le comportement des autres acteurs (par exemple, recherche et approches liées à l'exécution optimale de gros ordres, tenue de marché, trading haute fréquence).Après avoir parcouru les résultats de la recherche, il est clair que tous les articles et publications consacrés au trading utilisant la formation par renforcement (le sujet le plus proche des succès de DeepMind) sont consacrés à la première approche. Mais une question raisonnable se pose quant à la proportionnalité de l'approche du problème.Tout d'abord, dessinons un diagramme similaire aux jeux Atari.Réalité objective, . , , , , — . , , . , , , , , . , .
Il semble que tout tombe magnifiquement. Et, je soupçonne que cette similitude réchauffe également le battage médiatique. Mais, si nous clarifions un peu le schéma: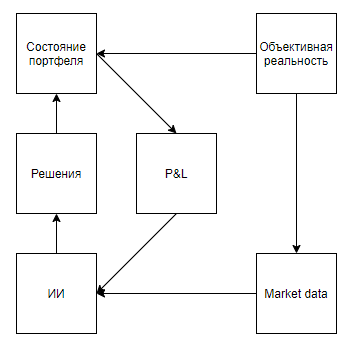
Anticiper la question des échantillons auto-générateurs, , , . , , . , , . , , , , , .
La deuxième approche (avec un flux d'applications) semble plus prometteuse. Le soi-disant verreil est souvent rempli d'applications de robots qui recherchent des fractions d'un pour cent du prix, en concurrence dans une place dans la file d'attente, et souvent en créant des applications uniquement pour faire apparaître la demande ou l'offre, et provoquer d'autres robots à des actions désavantageuses. Il semblerait, si vous en rêvez, que si vous créez un émulateur d'échange et y placez des robots HFT, qui, prenant des milliards de décisions, s'auto-apprendront, joueront avec les clones d'eux-mêmes et développeront ainsi une stratégie idéale qui tiendra compte de toutes les contre-stratégies optimales. ... Il est dommage que si quelque chose comme cela se produit, alors environ 5 personnes dans le monde le découvriront - les principes commerciaux des commerçants à haute fréquence impliquent un secret absolu, et refusant de publier des résultats même infructueux pour laisser aux ennemis une chance de marcher sur le même râteau.Je pense qu'il ne vaut surtout pas la peine de se concentrer sur l'impossibilité d'appliquer de telles approches dans le marketing, les RH, les ventes, la gestion et d'autres domaines où l'objet est une personne, car pour une application correcte, il est nécessaire de permettre à l'IA de faire des millions, voire des milliards d'expériences. Et, même si de nombreuses entreprises ont un million d'interactions avec un objet où l'IA peut prendre une décision (choisir une bannière à montrer à un client potentiel en fonction de son profil, la décision de licencier un employé), alors personne n'obtiendra un million d'expériences avec le même , qui est exactement ce qui est requis pour une application de haute qualité. Mais ce qui vaut la peine de se concentrer sur la lutte contre la fraude et la cybersécurité.Je ne sais pas, heureusement ou malheureusement, mais dans le monde moderne, de nombreuses relations économiques sont basées sur la fourniture d'une petite valeur sans obligations en échange d'une espérance de grande valeur à l'avenir, ce qui donne lieu à de nombreuses sources de gratification et à des risques de fraude.Exemples:- Le premier tour gratuit dans les agrégateurs de taxis
- Paiements de 70 $ pour CPA en jeu, pour un joueur ayant rapporté 5 $
- Testez 300 $ auprès des fournisseurs de cloud et des périodes d'essai
De plus, le potentiel de fraude du système économique moderne est soutenu par un faible degré de protection pour les transactions par carte de crédit, car les commerçants refusent souvent délibérément le même 3D Secure pour simplifier l'expérience utilisateur. Ainsi, pour les acheteurs de cartes volées pour un petit% de leur solde, cette liste peut être complétée presque indéfiniment.Le principal problème dans la lutte contre de tels cas réside dans l'incapacité de collecter un ensemble de données d'un volume suffisant - les opérations de fraude en% sont de 1 à 6 ordres de grandeur inférieures au pourcentage de bonnes opérations selon les entreprises. Il y a également un problème dans la flexibilité des fraudeurs, qui contournent facilement les algorithmes statiques, s'adaptant aux systèmes antifraude qui ont été formés par l'expérience passée.Et, il semblerait, le voici. Des algorithmes comme Agent57 lancés dans le bac à sable vous permettront de créer le fraudeur idéal, de constamment mettre à jour ses compétences et en même temps de résoudre le problème inverse - gardez l'algorithme d'identification à jour. Mais il y a une mise en garde. Gagner contre le modèle du monde intégré dans les jeux Atari n'est pas du tout la même chose que gagner à partir d'un système antifraude déjà formé sur la base du comportement de millions de joueurs, et beaucoup d'actions frauduleuses sont disproportionnées par rapport aux nombreuses actions d'un joueur dans un jeu rétro. Par exemple, même une action aussi simple que la saisie d'un identifiant sur le formulaire d'inscription comporte déjà des milliards d'options pour ce faire. En partant de quel agent utilisateur à transférer sur le serveur, et en terminant par combien de millisecondes attendre entre la saisie des deuxième et troisième caractères de connexion ...En général, je vois tout d'une manière ou d'une autre. Assez sombre. Et j'espère vraiment que je me trompe, et quelque part je n'ai pas pris en compte quelque chose dans le modèle. Je serais reconnaissant de voir des contre-exemples dans les commentaires.