Bonjour cher Khabrovites, dans ce petit exemple, je veux montrer comment vous pouvez analyser une page, dont les données sont chargées à l'aide de widgets javascript. De plus, même si la page de cet exemple est facile à enregistrer, vous ne pouvez toujours pas analyser toutes les photos nécessaires à cause de ces widgets. Dans ce cas, j'utilise cian.ru comme exemple , qui a son propre api , que je n'utiliserai pas, à la place j'utiliserai Selenium. Je ne travaille pas sur cian.ru, j'utilise simplement ce site à titre d'exemple. Le code de l'analyseur est simple et conçu pour les débutants.
Une brève introduction - quand à mon loisir j'ai regardé des exemples de réparations dans cian.ru, j'ai pensé que ce serait bien d'enregistrer les photos que j'aimais, mais les enregistrer manuellement serait long, d'ailleurs ce n'est pas notre méthode, alors j'ai décidé d'écrire ceci analyseur.
L'analyseur est écrit en python3 à partir de la distribution de binaire Anaconda , Selenium et chromedriver, que j'ai installé séparément de ces liens. (Et bien sûr, le navigateur Google Chrome doit être installé sur le système )
Ci-dessous le code complet de l'analyseur, puis j'analyserai les points principaux séparément.
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.common.exceptions import NoSuchElementException
import chromedriver_binary
import urllib
import time
print('start...')
site = "https://www.cian.ru/sale/flat/222059642/"
chrome_options = Options()
chrome_options.add_argument("--headless")
driver = webdriver.Chrome(options=chrome_options)
driver.get(site)
i = 0
while True:
try:
url = driver.find_element_by_xpath("//div[contains(@class, 'fotorama__active')]/img").get_attribute('src')
except NoSuchElementException:
break
i += 1
print(i, url)
driver.find_element_by_xpath("//div[@class='fotorama__arr fotorama__arr--next']").click()
name = url.split('/')[-1]
urllib.request.urlretrieve(url, name)
time.sleep(2)
print('done.')
https://www.cian.ru/sale/flat/222059642/ . driver get. , Headless Chrome, .. webdriver.Chrome() --headless, , , chrome_options , .
site = "https://www.cian.ru/sale/flat/222059642/"
chrome_options = Options()
chrome_options.add_argument("--headless")
driver = webdriver.Chrome(options=chrome_options)
driver.get(site)
, , , .. "next".
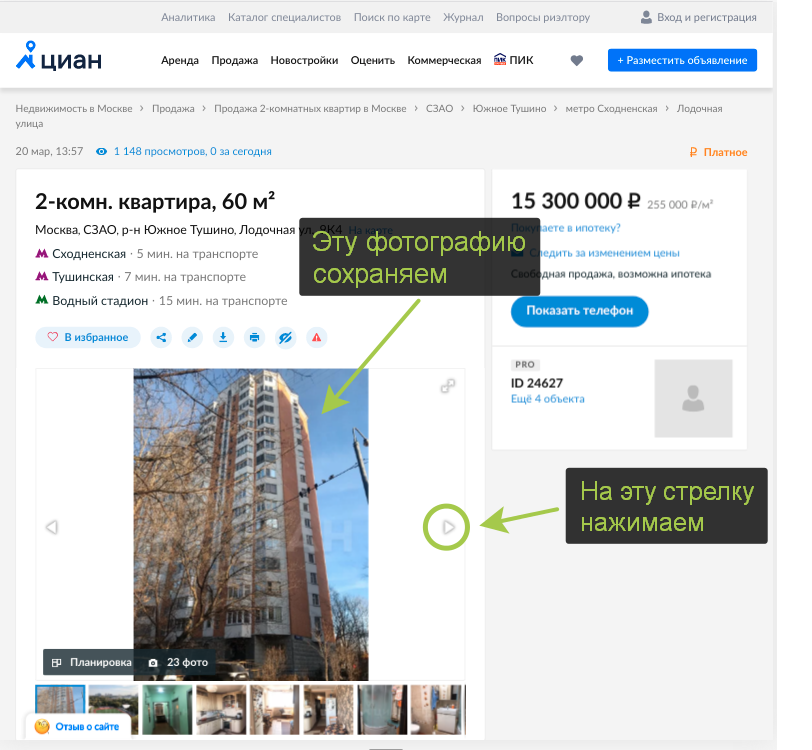
url , try/except NoSuchElementException, , Selenium .
try:
url = driver.find_element_by_xpath("//div[contains(@class, 'fotorama__active')]/img").get_attribute('src')
except NoSuchElementException:
break
.
driver.find_element_by_xpath("//div[@class='fotorama__arr fotorama__arr--next']").click()
urllib.
name = url.split('/')[-1]
urllib.request.urlretrieve(url, name)
, . ( Selenium)
time.sleep(2)
Selenium, , , - .
.