Bonjour, habrozhiteli! Alors que nos nouvelles sont imprimées dans une imprimerie et que le bureau est dans un endroit éloigné, nous avons décidé de partager un extrait du livre de Paul et Harvey Daytel «Python: Intelligence artificielle, Big Data et Cloud Computing»Étude de cas: Apprentissage automatique sans enseignant, partie 2 - Clustering moyen K
Dans cette section, peut-être le plus simple des algorithmes d'apprentissage automatique sans professeur sera présenté - le clustering en utilisant la méthode k moyenne. L'algorithme analyse les échantillons non étiquetés et tente de les combiner en grappes. Expliquons que k dans la «méthode k signifie» représente le nombre de grappes dans lesquelles les données sont censées être divisées.L'algorithme distribue les échantillons à un nombre prédéterminé de clusters en utilisant des métriques de distance similaires à celles de l'algorithme de clustering de k voisins les plus proches. Chaque cluster est regroupé autour d'un centroïde - le point central du cluster. Initialement, l'algorithme sélectionne k centroïdes aléatoires parmi les échantillons d'ensembles de données, après quoi les échantillons restants sont répartis entre les grappes avec le centroïde le plus proche. Ensuite, un recalcul itératif des centroïdes est effectué, et les échantillons sont redistribués entre les grappes jusqu'à ce que la distance d'un centroïde donné aux échantillons inclus dans sa grappe soit minimisée pour toutes les grappes. À la suite de l'algorithme, un tableau unidimensionnel d'étiquettes est créé qui désigne le cluster auquel appartient chaque échantillon, ainsi qu'un tableau bidimensionnel de centroïdes représentant le centre de chaque cluster.Iris Dataset
Nous travaillerons avec l'ensemble de données Iris populaire inclus avec scikit-learn. Cet ensemble est souvent analysé lors de la classification et du clustering. Bien que l'ensemble de données soit étiqueté, nous n'utiliserons pas ces étiquettes pour illustrer le clustering. Des étiquettes seront ensuite utilisées pour déterminer dans quelle mesure l'algorithme de moyenne k regroupe les échantillons.Le jeu de données Iris est un jeu de données jouet car il ne comprend que 150 échantillons et quatre attributs. L'ensemble de données décrit 50 échantillons de trois types de fleurs d'iris - Iris setosa, Iris versicolor et Iris virginica (voir photos ci-dessous). Caractéristiques des échantillons: longueur du lobe externe du périanthe (longueur du sépale), largeur du lobe externe du périanthe (largeur du sépale), longueur du lobe interne du périanthe (longueur des pétales) et largeur du lobe interne du périanthe (largeur des pétales), mesurées en centimètres.14.7.1. Télécharger Iris Dataset
Démarrez IPython avec la commande ipython --matplotlib, puis utilisez la fonction load_iris du module sklearn.datasets pour obtenir l'objet Bunch avec l'ensemble de données:In [1]: from sklearn.datasets import load_iris
In [2]: iris = load_iris()
L'attribut DESCR de l'objet Bunch indique que l'ensemble de données se compose de 150 échantillons Nombre d'instances, chacun ayant quatre Nombre d'attributs. Il n'y a aucune valeur manquante dans l'ensemble de données. Les échantillons sont classés avec des nombres entiers 0, 1 et 2, représentant Iris setosa, Iris versicolor et Iris virginica, respectivement. Nous ignorons les labels et confions la détermination des classes d'échantillons à l'algorithme de clustering en utilisant la méthode k moyennes. Informations clés du DESCR en gras:In [3]: print(iris.DESCR)
.. _iris_dataset:
Iris plants dataset
--------------------
**Data Set Characteristics:**
:Number of Instances: 150 (50 in each of three classes)
:Number of Attributes: 4 numeric, predictive attributes and the class
:Attribute Information:
- sepal length in cm
- sepal width in cm
- petal length in cm
- petal width in cm
- class:
- Iris-Setosa
- Iris-Versicolour
- Iris-Virginica
:Summary Statistics:
============== ==== ==== ======= ===== ====================
Min Max Mean SD Class Correlation
============== ==== ==== ======= ===== ====================
sepal length: 4.3 7.9 5.84 0.83 0.7826
sepal width: 2.0 4.4 3.05 0.43 -0.4194
petal length: 1.0 6.9 3.76 1.76 0.9490 (high!)
petal width: 0.1 2.5 1.20 0.76 0.9565 (high!)
============== ==== ==== ======= ===== ====================
:Missing Attribute Values: None
:Class Distribution: 33.3% for each of 3 classes.
:Creator: R.A. Fisher
:Donor: Michael Marshall (MARSHALL%PLU@io.arc.nasa.gov)
:Date: July, 1988
...
Vérification du nombre d'échantillons, de fonctionnalités et de valeurs cibles
Le nombre de modèles et d'attributs peut être trouvé dans l'attribut de forme du tableau de données, et le nombre de valeurs cibles peut être trouvé dans l'attribut de forme du tableau cible:In [4]: iris.data.shape
Out[4]: (150, 4)
In [5]: iris.target.shape
Out[5]: (150,)
Le tableau target_names contient les noms des étiquettes numériques du tableau. L'expression target - dtype = '<U10' signifie que ses éléments sont des chaînes de 10 caractères maximum:In [6]: iris.target_names
Out[6]: array(['setosa', 'versicolor', 'virginica'], dtype='<U10')
Le tableau feature_names contient une liste de noms de chaînes pour chaque colonne du tableau de données:In [7]: iris.feature_names
Out[7]:
['sepal length (cm)',
'sepal width (cm)',
'petal length (cm)',
'petal width (cm)']
14.7.2. Iris Dataset Research: Statistiques descriptives dans les pandas
Nous utilisons la collection DataFrame pour examiner l'ensemble de données Iris. Comme pour l'ensemble de données California Housing, nous avons défini les paramètres pandas pour formater la sortie de la colonne:In [8]: import pandas as pd
In [9]: pd.set_option('max_columns', 5)
In [10]: pd.set_option('display.width', None)
Créez une collection DataFrame avec le contenu du tableau de données, en utilisant le contenu du tableau feature_names comme noms de colonne:In [11]: iris_df = pd.DataFrame(iris.data, columns=iris.feature_names)
Ajoutez ensuite une colonne avec le nom de la vue pour chacun des échantillons. La transformation de liste dans l'extrait de code suivant utilise chaque valeur du tableau cible pour rechercher le nom correspondant dans le tableau target_names:In [12]: iris_df['species'] = [iris.target_names[i] for i in iris.target]
Nous utiliserons des pandas pour identifier plusieurs échantillons. Comme précédemment, si pandas affiche \ à droite du nom de la colonne, cela signifie que les colonnes qui seront affichées ci-dessous restent dans la sortie:In [13]: iris_df.head()
Out[13]:
sepal length (cm) sepal width (cm) petal length (cm) \
0 5.1 3.5 1.4
1 4.9 3.0 1.4
2 4.7 3.2 1.3
3 4.6 3.1 1.5
4 5.0 3.6 1.4
petal width (cm) species
0 0.2 setosa
1 0.2 setosa
2 0.2 setosa
3 0.2 setosa
4 0.2 setosa
Nous calculons quelques indicateurs de statistiques descriptives pour les colonnes numériques:In [14]: pd.set_option('precision', 2)
In [15]: iris_df.describe()
Out[15]:
sepal length (cm) sepal width (cm) petal length (cm) petal width (cm)
count 150.00 150.00 150.00 150.00
mean 5.84 3.06 3.76 1.20
std 0.83 0.44 1.77 0.76
min 4.30 2.00 1.00 0.10
25% 5.10 2.80 1.60 0.30
50% 5.80 3.00 4.35 1.30
75% 6.40 3.30 5.10 1.80
max 7.90 4.40 6.90 2.50
L'appel de la méthode décrire dans la colonne «espèce» confirme qu'elle contient trois valeurs uniques. Nous savons à l'avance que les données se composent de trois classes, qui comprennent des échantillons, bien que dans l'apprentissage automatique sans professeur, ce ne soit pas toujours le cas.In [16]: iris_df['species'].describe()
Out[16]:
count 150
unique 3
top setosa
freq 50
Name: species, dtype: object
14.7.3. Visualisation du jeu de données Pairplot
Nous allons visualiser les caractéristiques de cet ensemble de données. Une façon d'extraire des informations sur vos données est de voir comment les attributs sont liés les uns aux autres. Un ensemble de données a quatre attributs. Nous ne pourrons pas construire un diagramme de correspondance d'un attribut avec trois autres dans un diagramme. Néanmoins, il est possible de construire un diagramme sur lequel la correspondance entre les deux caractéristiques sera présentée. Fragment [20] utilise la fonction pairplot de la bibliothèque Seaborn pour créer un tableau de diagrammes dans lequel chaque entité est mappée à l'une des autres entités:In [17]: import seaborn as sns
In [18]: sns.set(font_scale=1.1)
In [19]: sns.set_style('whitegrid')
In [20]: grid = sns.pairplot(data=iris_df, vars=iris_df.columns[0:4],
...: hue='species')
...:
Arguments clés:- une collection DataFrame avec un ensemble de données tracé sur un graphique;
- vars - une séquence avec les noms des variables tracées sur le graphique. Pour une collection DataFrame, elle contient des noms de colonne. Dans ce cas, les quatre premières colonnes du DataFrame sont utilisées, représentant respectivement la longueur (largeur) du périanthe extérieur et la longueur (largeur) du périanthe intérieur;
- hue est une colonne de la collection DataFrame utilisée pour déterminer les couleurs des données tracées sur le graphique. Dans ce cas, les données sont colorées en fonction du type d'iris.
L'appel à paires précédent crée le tableau de diagramme 4 × 4 suivant: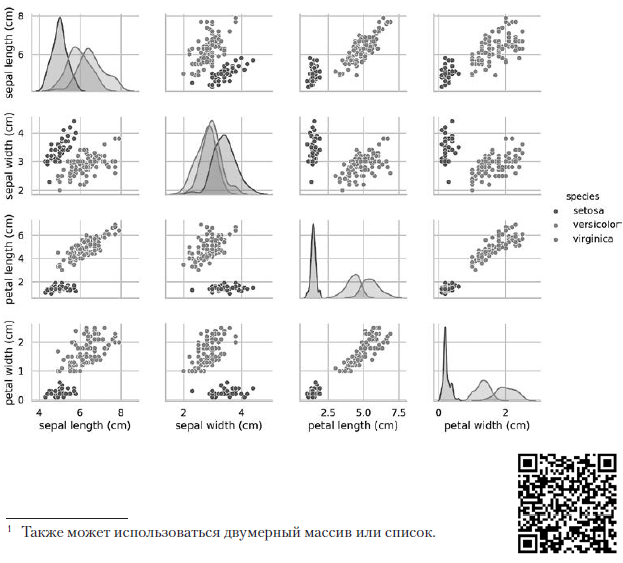 Les diagrammes sur la diagonale menant du coin supérieur gauche au coin inférieur droit montrent la distribution de l'attribut affiché dans cette colonne avec une plage de valeurs (de gauche à droite) et le nombre d'échantillons avec ces valeurs (de haut en bas) . Prenez la distribution de la longueur du périanthe externe:
Les diagrammes sur la diagonale menant du coin supérieur gauche au coin inférieur droit montrent la distribution de l'attribut affiché dans cette colonne avec une plage de valeurs (de gauche à droite) et le nombre d'échantillons avec ces valeurs (de haut en bas) . Prenez la distribution de la longueur du périanthe externe: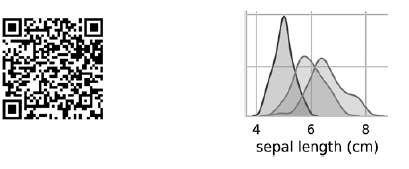 La zone ombrée la plus élevée indique que la plage de la longueur du lobe externe du périanthe (le long de l'axe x) pour l'espèce Iris setosa est d'environ 4 à 6 cm, et pour la plupart des échantillons d'Iris setosa, les valeurs se situent au milieu de cette plage (environ 5 cm). La zone ombrée à l'extrême droite indique que la plage de la longueur du lobe externe du périanthe (le long de l'axe x) pour l'espèce Iris virginica est d'environ 4 à 8,5 cm, et pour la plupart des échantillons d'Iris virginica, les valeurs sont comprises entre 6 et 7 cm.Dans d'autres diagrammes, la colonne présente les diagrammes de dispersion des données d'autres caractéristiques par rapport à la caractéristique le long de l'axe x. Dans la première colonne, dans les trois premiers diagrammes, l'axe y montre la largeur du périanthe extérieur, la longueur du périanthe intérieur et la largeur du périanthe intérieur, respectivement, et l'axe x montre la longueur du périanthe extérieur.Lorsque ce code est exécuté, une image couleur apparaît à l'écran, montrant la relation entre les différents types d'iris au niveau des caractères individuels. Fait intéressant, dans tous les diagrammes, les points bleus d'Iris setosa sont clairement séparés des points orange et verts des autres espèces; cela suggère que Iris setosa est en effet une classe distincte. Vous pouvez également remarquer que les deux autres espèces peuvent parfois être confondues, comme l'indiquent les points orange et verts qui se chevauchent. Par exemple, le diagramme de la largeur et de la longueur du lobe externe du périanthe montre que les points d'Iris versicolor et d'Iris virginica se mélangent. Cela suggère que si seules des mesures du lobe du périanthe externe sont disponibles, il sera difficile de distinguer ces deux espèces.
La zone ombrée la plus élevée indique que la plage de la longueur du lobe externe du périanthe (le long de l'axe x) pour l'espèce Iris setosa est d'environ 4 à 6 cm, et pour la plupart des échantillons d'Iris setosa, les valeurs se situent au milieu de cette plage (environ 5 cm). La zone ombrée à l'extrême droite indique que la plage de la longueur du lobe externe du périanthe (le long de l'axe x) pour l'espèce Iris virginica est d'environ 4 à 8,5 cm, et pour la plupart des échantillons d'Iris virginica, les valeurs sont comprises entre 6 et 7 cm.Dans d'autres diagrammes, la colonne présente les diagrammes de dispersion des données d'autres caractéristiques par rapport à la caractéristique le long de l'axe x. Dans la première colonne, dans les trois premiers diagrammes, l'axe y montre la largeur du périanthe extérieur, la longueur du périanthe intérieur et la largeur du périanthe intérieur, respectivement, et l'axe x montre la longueur du périanthe extérieur.Lorsque ce code est exécuté, une image couleur apparaît à l'écran, montrant la relation entre les différents types d'iris au niveau des caractères individuels. Fait intéressant, dans tous les diagrammes, les points bleus d'Iris setosa sont clairement séparés des points orange et verts des autres espèces; cela suggère que Iris setosa est en effet une classe distincte. Vous pouvez également remarquer que les deux autres espèces peuvent parfois être confondues, comme l'indiquent les points orange et verts qui se chevauchent. Par exemple, le diagramme de la largeur et de la longueur du lobe externe du périanthe montre que les points d'Iris versicolor et d'Iris virginica se mélangent. Cela suggère que si seules des mesures du lobe du périanthe externe sont disponibles, il sera difficile de distinguer ces deux espèces.Le tracé de paire de sortie donne une seule couleur
Si vous supprimez l'argument clé de teinte, la fonction pairplot utilise une seule couleur pour sortir toutes les données, car elle ne sait pas faire la distinction entre les vues dans la sortie:In [21]: grid = sns.pairplot(data=iris_df, vars=iris_df.columns[0:4])
Comme le montre le diagramme suivant, dans ce cas, les diagrammes sur la diagonale sont des histogrammes avec les distributions de toutes les valeurs de cet attribut, quel que soit le type. Lors de l'étude des diagrammes, il peut sembler qu'il n'y a que deux grappes, même si nous savons que l'ensemble de données contient trois types. Si le nombre de clusters n'est pas connu à l'avance, vous pouvez contacter un expert dans le domaine qui connaît bien les données. Un expert peut savoir qu'il existe trois types de données dans un ensemble de données; ces informations peuvent être utiles lors de l'apprentissage automatique avec des données.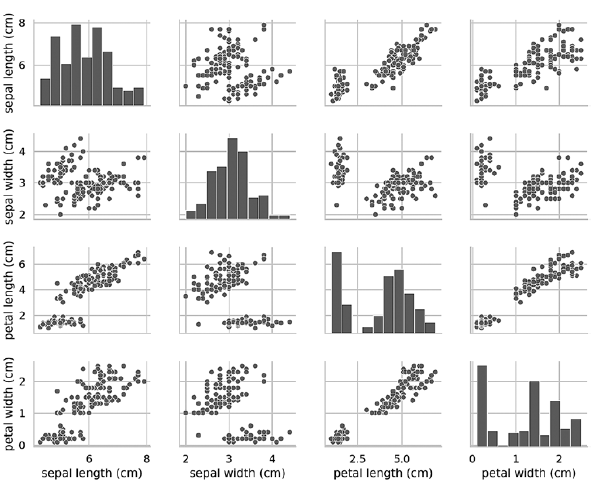 Les diagrammes Pairplot fonctionnent bien avec un petit nombre d'entités ou un sous-ensemble d'entités de sorte que le nombre de lignes et de colonnes est limité, et avec un nombre relativement petit de motifs pour que les points de données soient visibles. À mesure que le nombre de fonctionnalités et de modèles augmente, les diagrammes de dispersion des données deviennent trop petits pour lire les données. Dans les grands ensembles de données, vous pouvez tracer un sous-ensemble d'entités sur le graphique et, éventuellement, un sous-ensemble de modèles sélectionnés au hasard pour avoir une idée des données.»Plus d'informations sur le livre peuvent être trouvées et achetées sur le site Web de l'éditeur
Les diagrammes Pairplot fonctionnent bien avec un petit nombre d'entités ou un sous-ensemble d'entités de sorte que le nombre de lignes et de colonnes est limité, et avec un nombre relativement petit de motifs pour que les points de données soient visibles. À mesure que le nombre de fonctionnalités et de modèles augmente, les diagrammes de dispersion des données deviennent trop petits pour lire les données. Dans les grands ensembles de données, vous pouvez tracer un sous-ensemble d'entités sur le graphique et, éventuellement, un sous-ensemble de modèles sélectionnés au hasard pour avoir une idée des données.»Plus d'informations sur le livre peuvent être trouvées et achetées sur le site Web de l'éditeur