salut! Je m'appelle Eugene, je suis développeur Python. Au cours de la dernière année et demie, notre équipe a commencé à appliquer activement les principes de l'architecture propre, en s'éloignant du modèle MVC classique. Et aujourd'hui, je parlerai de la façon dont nous en sommes arrivés là, de ce que cela nous donne et pourquoi le transfert direct d'approches d'autres PL n'est pas toujours une bonne solution.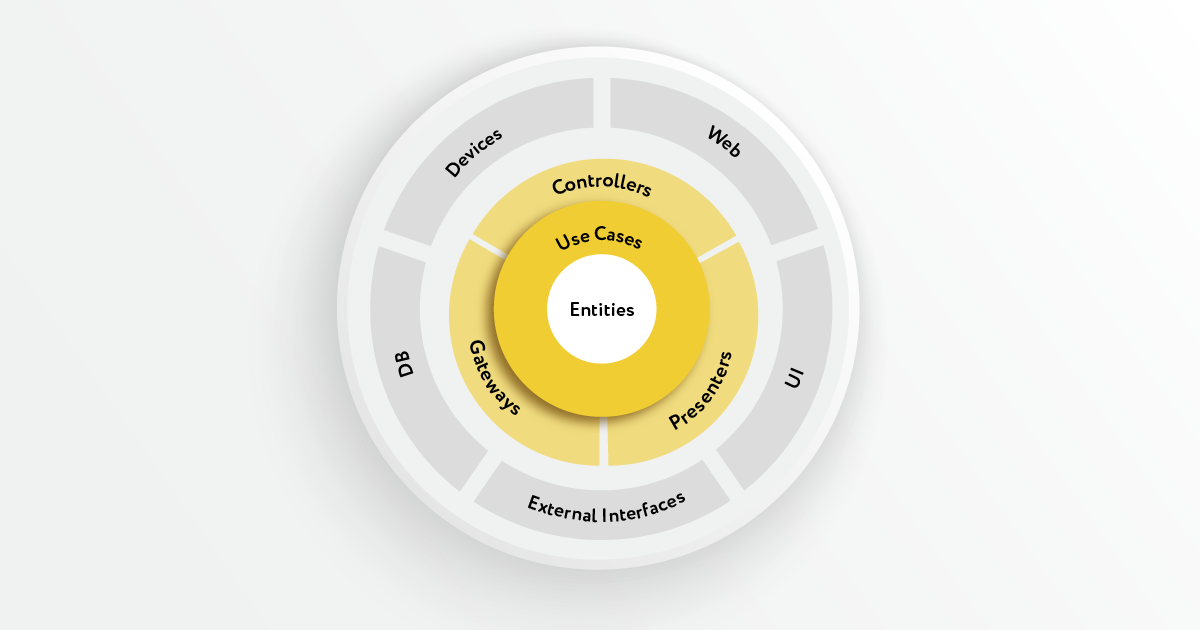 Python est mon principal outil de développement depuis plus de sept ans maintenant. Quand ils me demandent ce que j'aime le plus chez lui, je réponds que c'est son excellente lisibilité . La première connaissance a commencé par la lecture du livre «Programmer un esprit collectif» . Je m'intéressais aux algorithmes qui y sont décrits, mais tous les exemples étaient dans un langage qui ne m'était pas encore familier à l'époque. Ce n'était pas habituel (Python n'était pas encore courant dans l'apprentissage automatique), les listes étaient souvent écrites en pseudo-code ou en utilisant des diagrammes. Mais après une brève introduction à la langue, j'ai apprécié sa concision: tout était facile et clair, rien de superflu et de distrayant, seulement l'essence même du processus décrit. Le principal mérite de cela est la conception étonnante de la langue, le sucre syntaxique très intuitif. Cette expressivité a toujours été appréciée dans la communauté. Qu'est-ce que « importer ça », nécessairement présent sur les premières pages de tout manuel: il ressemble à un surveillant invisible, évalue constamment vos actions. Sur les forums, il valait la peine pour un débutant d'utiliser CamelCase dans le nom de la variable dans la liste, donc immédiatement l'angle de discussion s'est déplacé vers l'idiome du code proposé avec des références à PEP8.
Python est mon principal outil de développement depuis plus de sept ans maintenant. Quand ils me demandent ce que j'aime le plus chez lui, je réponds que c'est son excellente lisibilité . La première connaissance a commencé par la lecture du livre «Programmer un esprit collectif» . Je m'intéressais aux algorithmes qui y sont décrits, mais tous les exemples étaient dans un langage qui ne m'était pas encore familier à l'époque. Ce n'était pas habituel (Python n'était pas encore courant dans l'apprentissage automatique), les listes étaient souvent écrites en pseudo-code ou en utilisant des diagrammes. Mais après une brève introduction à la langue, j'ai apprécié sa concision: tout était facile et clair, rien de superflu et de distrayant, seulement l'essence même du processus décrit. Le principal mérite de cela est la conception étonnante de la langue, le sucre syntaxique très intuitif. Cette expressivité a toujours été appréciée dans la communauté. Qu'est-ce que « importer ça », nécessairement présent sur les premières pages de tout manuel: il ressemble à un surveillant invisible, évalue constamment vos actions. Sur les forums, il valait la peine pour un débutant d'utiliser CamelCase dans le nom de la variable dans la liste, donc immédiatement l'angle de discussion s'est déplacé vers l'idiome du code proposé avec des références à PEP8.La poursuite de l'élégance et le dynamisme puissant du langage ont créé de nombreuses bibliothèques avec une API vraiment délicieuse.
Néanmoins, Python, bien que puissant, n'est qu'un outil qui vous permet d'écrire du code expressif et auto-documenté, mais il ne garantit pas cela , pas plus que la conformité PEP8. Lorsque notre boutique en ligne apparemment simple sur Django commence à gagner de l'argent et, par conséquent, à augmenter les fonctionnalités, à un moment donné, nous réalisons que ce n'est pas si simple, et même effectuer des changements de base nécessite de plus en plus d'efforts, et plus important encore, cette tendance s'accentue. Que s'est-il passé et quand tout s'est mal passé?Mauvais code
Le mauvais code n'est pas celui qui ne suit pas PEP8 ou ne répond pas aux exigences de complexité cyclomatique. Un mauvais code est, tout d'abord, des dépendances incontrôlées , ce qui conduit au fait qu'un changement à un endroit du programme entraîne des changements imprévisibles dans d'autres parties. Nous perdons le contrôle du code; l'extension des fonctionnalités nécessite une étude détaillée du projet. Un tel code perd de sa souplesse et, pour ainsi dire, résiste aux changements, tandis que le programme lui-même devient «fragile». Architecture épurée
L'architecture choisie de l'application devrait éviter ce problème, et nous ne sommes pas les premiers à le rencontrer: il y a eu une discussion au sein de la communauté Java sur la création d'une conception d'application optimale depuis longtemps.En 2000, Robert Martin (également connu sous le nom d'Oncle Bob) dans son article « Principles of Design and Design » a réuni cinq principes pour la conception d'applications OOP sous l'acronyme mémorable SOLID. Ces principes ont été bien reçus par la communauté et vont bien au-delà de l'écosystème Java. Néanmoins, ils sont de nature très abstraite. Plus tard, il y a eu plusieurs tentatives pour développer une conception d'application générale basée sur les principes SOLID. Ceux-ci incluent: «Architecture hexagonale», «Ports et adaptateurs», «Architecture bulbeuse» et ils ont tous beaucoup en commun, bien que différents détails de mise en œuvre. Et en 2012, un article a été publié par le même Robert Martin, où il a proposé sa propre version intitulée « Architecture propre ».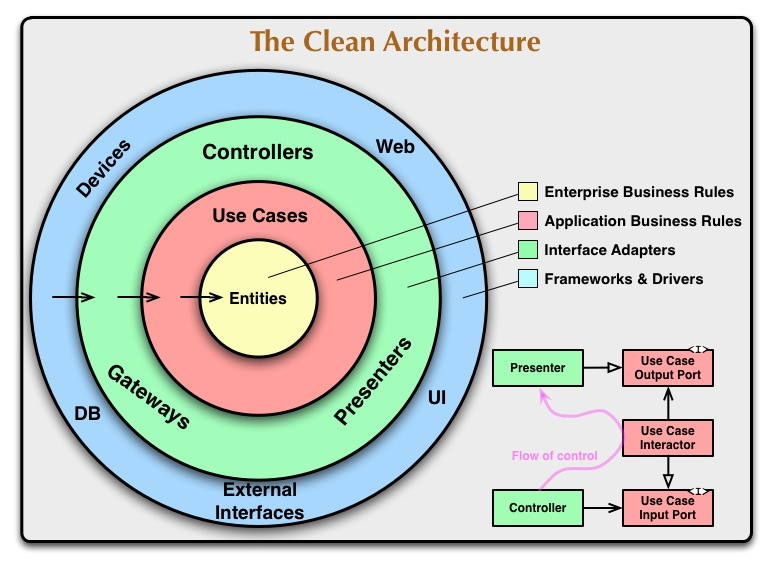 Selon Uncle Bob, l'architecture est avant tout « frontières et barrières », il faut bien comprendre les besoins et limiter les interfaces logicielles afin de ne pas perdre le contrôle de l'application. Pour ce faire, le programme est divisé en couches. En passant d'une couche à une autre, seules les données peuvent être transférées (les structures simples et les objets DTO peuvent agir comme des données ) - c'est la règle des limites. Une autre phrase la plus fréquemment citée selon laquelle «l' application devrait crier » signifie que l'élément principal de l'application n'est pas le cadre utilisé ou la technologie de stockage de données, mais ce que cette application fait réellement, quelle fonction elle remplit - la logique métier de l' application . Par conséquent, les couches n'ont pas de structure linéaire, mais ont une hiérarchie . D'où deux règles supplémentaires:
Selon Uncle Bob, l'architecture est avant tout « frontières et barrières », il faut bien comprendre les besoins et limiter les interfaces logicielles afin de ne pas perdre le contrôle de l'application. Pour ce faire, le programme est divisé en couches. En passant d'une couche à une autre, seules les données peuvent être transférées (les structures simples et les objets DTO peuvent agir comme des données ) - c'est la règle des limites. Une autre phrase la plus fréquemment citée selon laquelle «l' application devrait crier » signifie que l'élément principal de l'application n'est pas le cadre utilisé ou la technologie de stockage de données, mais ce que cette application fait réellement, quelle fonction elle remplit - la logique métier de l' application . Par conséquent, les couches n'ont pas de structure linéaire, mais ont une hiérarchie . D'où deux règles supplémentaires:- La règle de priorité pour la couche intérieure - c'est la couche intérieure qui détermine l'interface par laquelle elle interagira avec le monde extérieur;
- Règle de dépendance - Les dépendances doivent être dirigées de la couche intérieure vers l'extérieur.
La dernière règle est assez atypique dans le monde Python. Pour appliquer un scénario de logique métier complexe, vous devez toujours accéder à des services externes (par exemple, une base de données), mais pour éviter cette dépendance, la couche de logique métier doit elle-même déclarer l'interface par laquelle elle interagira avec le monde extérieur. Cette technique est appelée « inversion de dépendance » (la lettre D dans SOLID) et est largement utilisée dans les langages à typage statique. Selon Robert Martin, c'est le principal avantage de la POO .Ces trois règles sont l'essence même de l'architecture propre:- Règle de passage des frontières;
- Règle de dépendance;
- La règle de priorité de la couche intérieure.
Les avantages de cette approche comprennent:- Facilité de test - les couches sont isolées, respectivement, elles peuvent être testées sans patch de singe, vous pouvez définir granulairement le revêtement pour différentes couches, selon le degré de leur importance;
- Facilité de modification des règles métier , car toutes sont collectées en un seul endroit, ne sont pas réparties sur le projet et ne sont pas mélangées avec du code de bas niveau;
- Indépendance vis-à-vis des agents externes : la présence d'abstractions entre la logique métier et le monde extérieur permet dans certains cas de changer de sources externes sans affecter les couches internes. Cela fonctionne si vous n'avez pas lié la logique métier aux fonctionnalités spécifiques des agents externes, par exemple, les transactions de base de données;
- , , , .
, . . , . « Clean Architecture».
Python
Il s'agit d'une théorie, des exemples d'application pratique peuvent être trouvés dans l'article original, les rapports et le livre de Robert Martin. Ils s'appuient sur plusieurs modèles de conception courants du monde Java: adaptateur, passerelle, interacteur, Fasade, référentiel, DTO , etc.Eh bien, qu'en est-il de Python? Comme je l'ai dit, le laconicisme est valorisé dans la communauté Python, ce qui a pris racine chez les autres est loin d'être ancré chez nous. La première fois que j'ai abordé ce sujet il y a trois ans, il n'y avait pas beaucoup de documents sur le thème de l'utilisation de l'architecture propre en Python, mais le premier lien dans Google était le projet Leonardo Giordani: l'auteur décrit en détail le processus de création d'une API pour un site de recherche de propriété en utilisant la méthode TDD, appliquer une architecture propre.Malheureusement, malgré l'explication scrupuleuse et en suivant tous les canons de l'oncle Bob, cet exemple est plutôt effrayant . L'API du projet consiste en une méthode: obtenir une liste avec un filtre disponible. Je pense que même pour un développeur novice, le code d'un tel projet ne prendra pas plus de 15 lignes. Mais dans ce cas, il a pris six paquets. Vous pouvez vous référer à une mise en page pas entièrement réussie, et c'est vrai, mais en tout cas, il est difficile pour quelqu'un d'expliquer l'efficacité de cette approche , en se référant à ce projet.Il y a un problème plus grave, si vous ne lisez pas l'article et que vous commencez immédiatement à étudier le projet, il est assez difficile à comprendre. Considérez la mise en œuvre de la logique métier:from rentomatic.response_objects import response_objects as res
class RoomListUseCase(object):
def __init__(self, repo):
self.repo = repo
def execute(self, request_object):
if not request_object:
return res.ResponseFailure.build_from_invalid_request_object(
request_object)
try:
rooms = self.repo.list(filters=request_object.filters)
return res.ResponseSuccess(rooms)
except Exception as exc:
return res.ResponseFailure.build_system_error(
"{}: {}".format(exc.__class__.__name__, "{}".format(exc)))
La classe RoomListUseCase qui implémente la logique métier (pas très similaire à la logique métier, non?) Du projet est initialisé par l'objet repo . Mais qu'est-ce qu'un repo ? Bien sûr, du contexte, on peut comprendre que les prises en pension met en œuvre le modèle du référentiel pour accéder aux données, si nous regardons le corps de RoomListUseCase, nous comprenons qu'il doit avoir une méthode de liste, dont l'entrée est une liste de filtres, ce qui est clair à la sortie, vous devez regarder dans ResponseSuccess. Et si le scénario est plus complexe, avec plusieurs accès à la source de données? Il s'avère que vous comprenez ce qu'est le dépôt, vous ne pouvez vous référer qu'à la mise en œuvre. Mais où est-elle située? Il se trouve dans un module séparé, qui n'est en aucun cas associé à RoomListUseCase. Ainsi, pour comprendre ce qui se passe, vous devez remonter au niveau supérieur (le niveau du framework) et voir ce qui alimente l'entrée de la classe lors de la création de l'objet.Vous pourriez penser que j'énumère les inconvénients de la frappe dynamique, mais ce n'est pas entièrement vrai. C'est un typage dynamique qui vous permet d'écrire du code expressif et compact . L'analogie avec les microservices vient à l'esprit, lorsque nous découpons un monolithe en microservices, la conception prend une rigidité supplémentaire, car tout peut être fait à l'intérieur du microservice (PL, frameworks, architecture), mais il doit respecter l'interface déclarée. Alors ici: quand nous avons divisé notre projet en couches,Les relations entre les couches doivent être cohérentes avec le contrat , tandis qu'à l'intérieur de la couche, le contrat est facultatif. Sinon, vous devez garder un contexte assez large dans votre tête. Rappelez-vous, j'ai dit que le problème avec le mauvais code était les dépendances, et donc, sans interface explicite, nous glissons à nouveau là où nous voulions nous éloigner - à l' absence de relations de cause à effet explicites .repo RoomListUseCase, execute — . - , , . - . , , , repo .
En général, à cette époque, j'ai abandonné l'architecture propre dans un nouveau projet, en appliquant à nouveau le MVC classique. Mais, après avoir rempli le prochain lot de cônes, il est revenu sur cette idée un an plus tard, quand, enfin, nous avons commencé à lancer des services en Python 3.5+. Comme vous le savez, il a apporté des annotations de type et des classes de données: Deux puissants outils de description d'interface. Sur la base de ceux-ci, j'ai esquissé un prototype du service, et le résultat était déjà bien meilleur: les couches ont cessé de s'effriter, malgré le fait qu'il y avait encore beaucoup de code, surtout lors de l'intégration avec le framework. Mais cela a suffi pour commencer à appliquer cette approche dans les petits projets. Peu à peu, des cadres ont commencé à apparaître qui se concentraient sur l'utilisation maximale des annotations de type: apistar (maintenant starlette), fondu. Le bundle pydantic / FastAPI est maintenant courant et l'intégration avec de tels frameworks est devenue beaucoup plus facile. Voici à quoi ressemblerait l'exemple ci-dessus de restomatic / services.py:from typing import Optional, List
from pydantic import BaseModel
class Room(BaseModel):
code: str
size: int
price: int
latitude: float
longitude: float
class RoomFilter(BaseModel):
code: Optional[str] = None
price_min: Optional[int] = None
price_max: Optional[int] = None
class RoomStorage:
def get_rooms(self, filters: RoomFilter) -> List[Room]: ...
class RoomListUseCase:
def __init__(self, repo: RoomStorage):
self.repo = repo
def show_rooms(self, filters: RoomFilter) -> List[Room]:
rooms = self.repo.get_rooms(filters=filters)
return rooms
RoomListUseCase - une classe qui implémente la logique métier du projet. Vous ne devez pas faire attention au fait que tout ce que fait la méthode show_rooms est d'appeler RoomStorage (je n'ai pas trouvé cet exemple). Dans la vie réelle, il peut également y avoir un calcul de remise, un classement d'une liste basée sur des publicités, etc. Cependant, le module est autosuffisant. Si nous voulons utiliser ce scénario dans un autre projet, nous devrons implémenter RoomStorage. Et ce qui est nécessaire pour cela est clairement visible depuis le module. Contrairement à l'exemple précédent, une telle couche est autosuffisante et, lors d'une modification, il n'est pas nécessaire de garder à l'esprit tout le contexte. A partir de dépendances non systémiques uniquement pydantiques, eh bien, cela deviendra clair dans le plug-in du framework. Pas de dépendances, une autre façon d'améliorer la lisibilité du code, et non un contexte supplémentaire, même un développeur novice pourra comprendre ce que fait ce module.Un scénario de logique métier ne doit pas nécessairement être une classe; voici un exemple d'un scénario similaire sous la forme d'une fonction:def rool_list_use_case(filters: RoomFilter, repo: RoomStorage) -> List[Room]:
rooms = repo.get_rooms(filters=filters)
return rooms
Et voici le lien avec le framework:from typing import List
from fastapi import FastAPI, Depends
from rentomatic import services, adapters
app = FastAPI()
def get_use_case() -> services.RoomListUseCase:
return services.RoomListUseCase(adapters.MemoryStorage())
@app.post("/rooms", response_model=List[services.Room])
def rooms(filters: services.RoomFilter, use_case=Depends(get_use_case)):
return use_case.show_rooms(filters)
À l'aide de la fonction get_use_case, FastAPI implémente le modèle d' injection de dépendance . Nous n'avons pas à nous soucier de la sérialisation des données, tout le travail est effectué par FastAPI en collaboration avec pydantic. Malheureusement, les données ne sont pas toujours format logique métier adapté à la diffusion en direct dans le restaurant <et, au contraire, la logique métier ne sait pas où les données se sont - avec des barres obliques, corps de la demande, les cookies, etc . Dans ce cas, le corps de la fonction room aura une certaine conversion des données d'entrée et de sortie, mais dans la plupart des cas, si nous travaillons avec l'API, une telle fonction proxy simple suffit. , , , RoomStorage. , 15 , , , .
Je n'ai pas intentionnellement séparé la couche de la logique métier, comme le suggère le modèle canonique de l'architecture propre. La classe Room était censée se trouver dans la couche de région de domaine d'entité représentant la région de domaine, mais pour cet exemple, cela n'est pas nécessaire. En combinant les couches Entity et UseCase, le projet ne cesse pas d'être une implémentation de Clean Architecture. Robert Martin lui-même a déclaré à plusieurs reprises que le nombre de couches peut varier à la fois vers le haut et vers le bas. Dans le même temps, le projet répond aux principaux critères de l'architecture propre:- Règle du franchissement des frontières: les modèles pydantiques, qui sont essentiellement des DTO, traversent les frontières ;
- Règle de dépendance : la couche de logique métier est indépendante des autres couches;
- La règle de priorité pour la couche interne : c'est la couche de logique métier qui définit l'interface (RoomStorage), à travers laquelle la logique métier interagit avec le monde extérieur.
Aujourd'hui, plusieurs projets de notre équipe, mis en œuvre selon l'approche décrite, travaillent sur la prod. J'essaie d'organiser même les plus petits services de cette façon. Il s'entraîne bien - des questions auxquelles je n'avais pas pensé avant de se poser. Par exemple, quelle est la logique métier ici? C'est loin d'être toujours évident, par exemple, si vous écrivez une sorte de proxy. Un autre point important est d' apprendre à penser différemment.. Lorsque nous obtenons une tâche, nous commençons généralement à penser aux cadres, aux services utilisés, à savoir s'il y aura un besoin d'une file d'attente où il est préférable de stocker ces données, qui peuvent être mises en cache. Dans l'approche dictant l'architecture propre, nous devons d'abord mettre en œuvre la logique métier et ensuite passer à la mise en œuvre de l'interaction avec l'infrastructure, car, selon Robert Martin, la tâche principale de l'architecture est de retarder le moment où la connexion avec tout La couche infrastructure fera partie intégrante de votre application.En général, je vois une perspective favorable à l'utilisation d'une architecture propre en Python. Mais la forme sera très probablement très différente de la façon dont elle est acceptée dans d'autres PL. Au cours des dernières années, j'ai vu une augmentation significative de l'intérêt pour le sujet de l'architecture dans la communauté. Ainsi, lors du dernier PyCon, il y avait plusieurs rapports sur l'utilisation du DDD, et les gars des laboratoires secs devraient être notés séparément . Dans notre entreprise, de nombreuses équipes mettent déjà en œuvre l'approche décrite à un degré ou à un autre. Nous faisons tous la même chose, nous avons grandi, nos projets ont grandi, la communauté Python doit travailler avec cela, définir le style commun et le langage qui, par exemple, est devenu une fois pour tout Django.