Désormais, la programmation pénètre de plus en plus profondément dans tous les domaines de la vie. Et c'est peut-être devenu grâce au python très populaire maintenant. S'il y a 5 ans, pour analyser les données, vous deviez utiliser un ensemble complet d'outils divers: C # pour décharger (ou stylos), Excel, MatLab, SQL, et y "sauter" constamment, effacer, vérifier et vérifier les données. Maintenant, python, grâce à un grand nombre d'excellentes bibliothèques et modules, dans la première approximation remplace en toute sécurité tous ces outils, et en conjonction avec SQL, en général, «les montagnes peuvent être enroulées».Alors qu'est-ce que je fais. Je suis devenu intéressé à apprendre un python si populaire. Et la meilleure façon d'apprendre quelque chose, comme vous le savez, est la pratique. Et je m'intéresse aussi à l'immobilier. Et je suis tombé sur un problème intéressant à propos de l'immobilier à Moscou: classer les quartiers de Moscou en fonction du coût de location moyen d'une odnouchka moyenne? Pères, je pensais, vous avez ici la géolocalisation, le téléchargement à partir du site et l'analyse des données - une grande tâche pratique.Inspiré par les merveilleux articles ici sur Habré (à la fin de l'article j'ajouterai des liens), commençons!La tâche pour nous est de passer en revue les outils existants à l'intérieur de python, de démonter la technique - comment résoudre de tels problèmes et passer du temps avec plaisir, et pas seulement avec des avantages.- Scraping Cyan
- Trame de données unique
- Traitement des trames de données
- résultats
- Un peu sur l'utilisation des géodonnées
Scraping Cyan
A la mi-mars 2020, il était possible de collecter près de 9 mille propositions de location d'un appartement 1 pièce à Moscou sur cyan, le site affiche 54 pages. Nous travaillerons avec jupyter-notebook 6.0.1, python 3.7. Nous téléchargeons les données du site et les enregistrons dans des fichiers à l'aide de la bibliothèque de demandes .Pour que le site ne nous interdise pas, nous nous déguiserons en tant que personne en ajoutant un retard dans les demandes et en définissant un en-tête de sorte que du côté du site, nous ressemblions à une personne très intelligente faisant des demandes via un navigateur. N'oubliez pas de vérifier à chaque fois la réponse du site, sinon nous sommes soudain découverts et déjà bannis. Vous pouvez lire de plus en plus de détails sur le scraping de sites Web, par exemple ici: Web Scraping using python .Il est également pratique d'ajouter des décorateurs pour évaluer la vitesse de nos fonctions et de la journalisation. Le paramètre level = logging.INFO vous permet de spécifier le type de messages affichés dans le journal. Vous pouvez également configurer le module pour afficher le journal dans un fichier texte, pour nous, cela n'est pas nécessaire.Le codedef timer(f):
def wrap_timer(*args, **kwargs):
start = time.time()
result = f(*args, **kwargs)
delta = time.time() - start
print (f' {f.__name__} {delta} ')
return result
return wrap_timer
def log(f):
def wrap_log(*args, **kwargs):
logging.info(f" {f.__doc__}")
result = f(*args, **kwargs)
logging.info(f": {result}")
return result
return wrap_log
logging.basicConfig(level=logging.INFO)
@timer
@log
def requests_site(N):
headers = ({'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/13.0.5 Safari/605.1.15'})
pages = [106 + i for i in range(N)]
n = 0
for i in pages:
s = f"https://www.cian.ru/cat.php?deal_type=rent&engine_version=2&page={i}&offer_type=flat®ion=1&room1=1&type=-2"
response = requests.get(s, headers = headers)
if response.status_code == 200:
name = f'sheets/sheet_{i}.txt'
with open(name, 'w') as f:
f.write(response.text)
n += 1
logging.info(f" {i}")
else:
print(f" {i} response.status_code = {response.status_code}")
time.sleep(np.random.randint(7,13))
return f" {n} "
requests_site(300)
Trame de données unique
Pour gratter des pages, choisissez BeautifulSoup et lxml . Nous utilisons "belle soupe" simplement pour son nom sympa, bien qu'ils disent que lxml est plus rapide.Vous pouvez le faire magnifiquement, prendre une liste de fichiers à partir d'un dossier en utilisant la bibliothèque os , filtrer les extensions dont nous avons besoin et les parcourir. Mais nous allons vous faciliter la tâche, car nous connaissons le nombre exact de fichiers et leurs noms exacts. Sauf si nous ajoutons une décoration sous la forme d'une barre de progression, en utilisant la bibliothèque tqdmLe code
from bs4 import BeautifulSoup
import re
import pandas as pd
from dateutil.parser import parse
from datetime import datetime, date, time
def read_file(filename):
with open(filename) as input_file:
text = input_file.read()
return text
import tqdm
site_texts = []
pages = [1 + i for i in range(309)]
for i in tqdm.tqdm(pages):
name = f'sheets/sheet_{i}.txt'
site_texts.append(read_file(name))
print(f" {len(site_texts)} .")
def parse_tag(tag, tag_value, item):
key = tag
value = "None"
if item.find('div', {'class': tag_value}):
if key == 'link':
value = item.find('div', {'class': tag_value}).find('a').get('href')
elif (key == 'price' or key == 'price_meter'):
value = parse_digits(item.find('div', {'class': tag_value}).text, key)
elif key == 'pub_datetime':
value = parse_date(item.find('div', {'class': tag_value}).text)
else:
value = item.find('div', {'class': tag_value}).text
return key, value
def parse_digits(string, type_digit):
digit = 0
try:
if type_digit == 'flats_counts':
digit = int(re.sub(r" ", "", string[:string.find("")]))
elif type_digit == 'price':
digit = re.sub(r" ", "", re.sub(r"₽", "", string))
elif type_digit == 'price_meter':
digit = re.sub(r" ", "", re.sub(r"₽/²", "", string))
except:
return -1
return digit
def parse_date(string):
now = datetime.strptime("15.03.20 00:00", "%d.%m.%y %H:%M")
s = string
if string.find('') >= 0:
s = "{} {}".format(now.day, now.strftime("%b"))
s = string.replace('', s)
elif string.find('') >= 0:
s = "{} {}".format(now.day - 1, now.strftime("%b"))
s = string.replace('',s)
if (s.find('') > 0):
s = s.replace('','mar')
if (s.find('') > 0):
s = s.replace('','feb')
if (s.find('') > 0):
s = s.replace('','jan')
return parse(s).strftime('%Y-%m-%d %H:%M:%S')
def parse_text(text, index):
tag_table = '_93444fe79c--wrapper--E9jWb'
tag_items = ['_93444fe79c--card--_yguQ', '_93444fe79c--card--_yguQ']
tag_flats_counts = '_93444fe79c--totalOffers--22-FL'
tags = {
'link':('c6e8ba5398--info-section--Sfnx- c6e8ba5398--main-info--oWcMk','undefined c6e8ba5398--main-info--oWcMk'),
'desc': ('c6e8ba5398--title--2CW78','c6e8ba5398--single_title--22TGT', 'c6e8ba5398--subtitle--UTwbQ'),
'price': ('c6e8ba5398--header--1df-X', 'c6e8ba5398--header--1dF9r'),
'price_meter': 'c6e8ba5398--term--3kvtJ',
'metro': 'c6e8ba5398--underground-name--1efZ3',
'pub_datetime': 'c6e8ba5398--absolute--9uFLj',
'address': 'c6e8ba5398--address-links--1tfGW',
'square': ''
}
res = []
flats_counts = 0
soup = BeautifulSoup(text)
if soup.find('div', {'class': tag_flats_counts}):
flats_counts = parse_digits(soup.find('div', {'class': tag_flats_counts}).text, 'flats_counts')
flats_list = soup.find('div', {'class': tag_table})
if flats_list:
items = flats_list.find_all('div', {'class': tag_items})
for i, item in enumerate(items):
d = {'index': index}
index += 1
for tag in tags.keys():
tag_value = tags[tag]
key, value = parse_tag(tag, tag_value, item)
d[key] = value
results[index] = d
return flats_counts, index
from IPython.display import clear_output
sum_flats = 0
index = 0
results = {}
for i, text in enumerate(site_texts):
flats_counts, index = parse_text(text, index)
sum_flats = len(results)
clear_output(wait=True)
print(f" {i + 1} flats = {flats_counts}, {sum_flats} ")
print(f" sum_flats ({sum_flats}) = flats_counts({flats_counts})")
Une nuance intéressante est que le chiffre indiqué en haut de la page et indiquant le nombre total d'appartements trouvés sur demande diffère d'une page à l'autre. Ainsi, dans notre exemple, ces 5 402 offres sont triées par défaut, allant de 5343 à 5402, diminuant progressivement avec l'augmentation du numéro de page de la demande (mais pas selon le nombre d'annonces affichées). De plus, il a été possible de continuer à décharger des pages au-delà des limites du nombre de pages indiqué sur le site. Dans notre cas, seules 54 pages étaient proposées sur le site, mais nous avons pu décharger 309 pages, avec uniquement des annonces plus anciennes, pour un total de 8640 annonces de location d'appartements.Une enquête sur ce fait sera laissée en dehors du champ d'application de cet article.Traitement des trames de données
Nous avons donc une seule trame de données avec des données brutes sur 8640 offres. Nous effectuerons une analyse de surface des prix moyens et médians dans les quartiers, calculerons le prix moyen de location au mètre carré de l'appartement et le coût de l'appartement dans le quartier «en moyenne».Nous partirons des hypothèses suivantes pour notre étude:- Manque de répétitions: tous les appartements trouvés sont des appartements réellement existants. À la première étape, nous avons éliminé les appartements répétés à l'adresse et à la quadrature, mais si l'appartement a une quadrature ou une adresse légèrement différente, nous considérons ces options comme des appartements différents.
- — .
— «» ? ( ) , , , , . , , , . «» : . «» ( ) , .
Nous aurons besoin de:price_per_month - prix mensuel à louer sur laplace des roubles - zoneokrug - quartier, dans cette étude, l'adresse entière ne nous intéresse pasprice_meter - prix de location pour 1 mètre carréLe codedf['price_per_month'] = df['price'].str.strip('/.').astype(int)
new_desc = df["desc"].str.split(",", n = 3, expand = True)
df["square"]= new_desc[1].str.strip(' ²').astype(int)
df["floor"]= new_desc[2]
new_address = df['address'].str.split(',', n = 3, expand = True)
df['okrug'] = new_address[1].str.strip(" ")
df['price_per_meter'] = (df['price_per_month'] / df['square']).round(2)
df = df.drop(['index','metro', 'price_meter','link', 'price','desc','address','pub_datetime','floor'], axis='columns')
Nous allons maintenant «prendre soin» des émissions manuellement selon les horaires. Pour visualiser les données, regardons trois bibliothèques: matplotlib , seaborn et plotly .Histogrammes de données . Matplotlib vous permet d'afficher rapidement et facilement tous les graphiques des groupes de données qui nous intéressent, nous n'en avons pas besoin de plus. Le graphique ci-dessous, selon lequel une seule proposition à Mitino ne peut pas servir d'évaluation qualitative de l'appartement moyen, est supprimé. Une autre image intéressante dans le sud administratif Okrug: la majorité des offres (plus de 500 unités) avec une valeur locative inférieure à 1000 roubles, et une augmentation des offres (près de 300 unités) de 1700 roubles par mètre carré. À l'avenir, vous pouvez voir pourquoi cela se produit - en fouillant dans d'autres indicateurs pour ces appartements.Une seule ligne de code donne des histogrammes pour les ensembles de données groupés:hists = df['price_per_meter'].hist(by=df['okrug'], figsize=(16, 14), color = "tab:blue", grid = True)
 La dispersion des valeurs . Vous trouverez ci-dessous les graphiques utilisant les trois bibliothèques. seaborn par défaut est plus beau et plus lumineux, mais il vous permet d'afficher immédiatement les valeurs lorsque vous survolez la souris, ce qui est très pratique pour nous de sélectionner les valeurs des "valeurs aberrantes" que nous supprimerons.matplotlib
La dispersion des valeurs . Vous trouverez ci-dessous les graphiques utilisant les trois bibliothèques. seaborn par défaut est plus beau et plus lumineux, mais il vous permet d'afficher immédiatement les valeurs lorsque vous survolez la souris, ce qui est très pratique pour nous de sélectionner les valeurs des "valeurs aberrantes" que nous supprimerons.matplotlibfig, axes = plt.subplots(nrows=4,ncols=3,figsize=(15,15))
for i, (name, group) in enumerate(df_copy.groupby('okrug')):
axes = axes.flatten()
axes[i].scatter(group['price_per_meter'],group['square'], color ='blue')
axes[i].set_title(name)
axes[i].set(xlabel=' 1 ..', ylabel=', 2')
fig.tight_layout()
 seaboarn
seaboarnsns.pairplot(vars=["price_per_meter","square"], data=df_copy, hue="okrug", height=5)
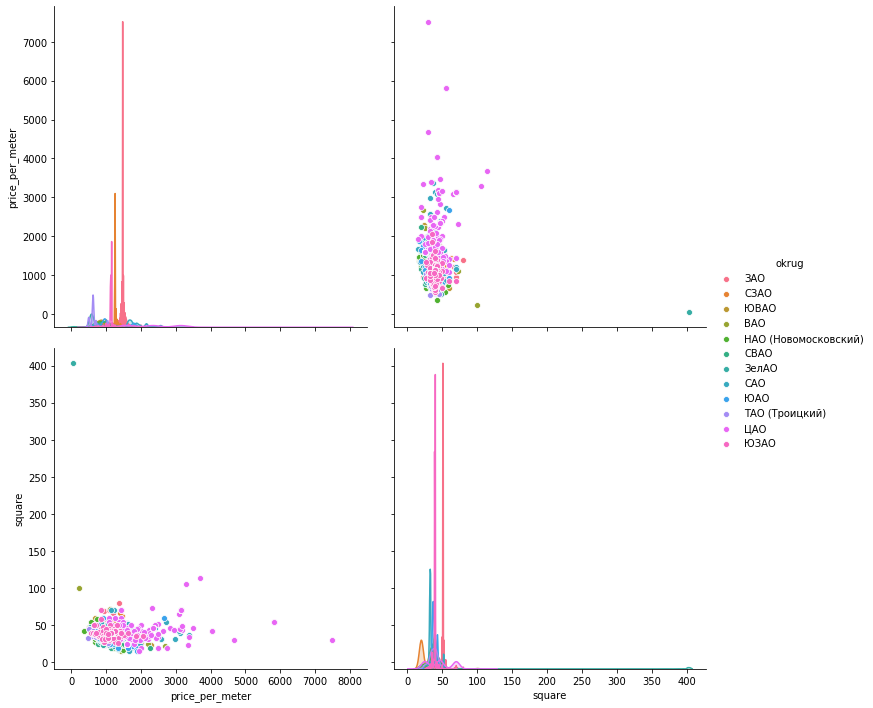 plotlyJe pense qu'il y aura assez pour exemple un district.
plotlyJe pense qu'il y aura assez pour exemple un district.import plotly.express as px
for i, (name, group) in enumerate(df_copy.groupby('okrug')):
fig = px.scatter(group, x="price_per_meter", y="square", facet_col="okrug",
width=400, height=400)
fig.update_layout(
margin=dict(l=20, r=20, t=20, b=20),
paper_bgcolor="LightSteelBlue",
)
fig.show()
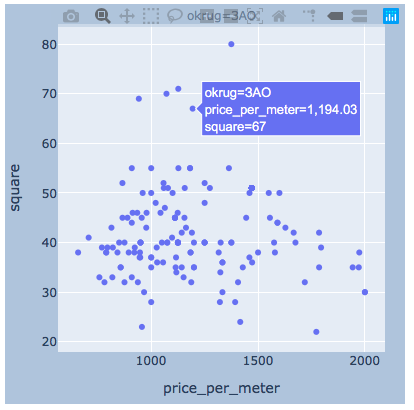
résultats
Ainsi, après avoir nettoyé les données, en supprimant les émissions de manière experte, nous avons 8602 offres «propres».Ensuite, on calcule les principales statistiques en fonction des données: moyenne, médiane, écart - type, on obtient la note suivante des districts de Moscou que le coût moyen de location pour un appartement moyen diminue: Vous pouvez dessiner de belles histogrammes en comparant, par exemple, les prix moyens et médians dans le district:
Vous pouvez dessiner de belles histogrammes en comparant, par exemple, les prix moyens et médians dans le district: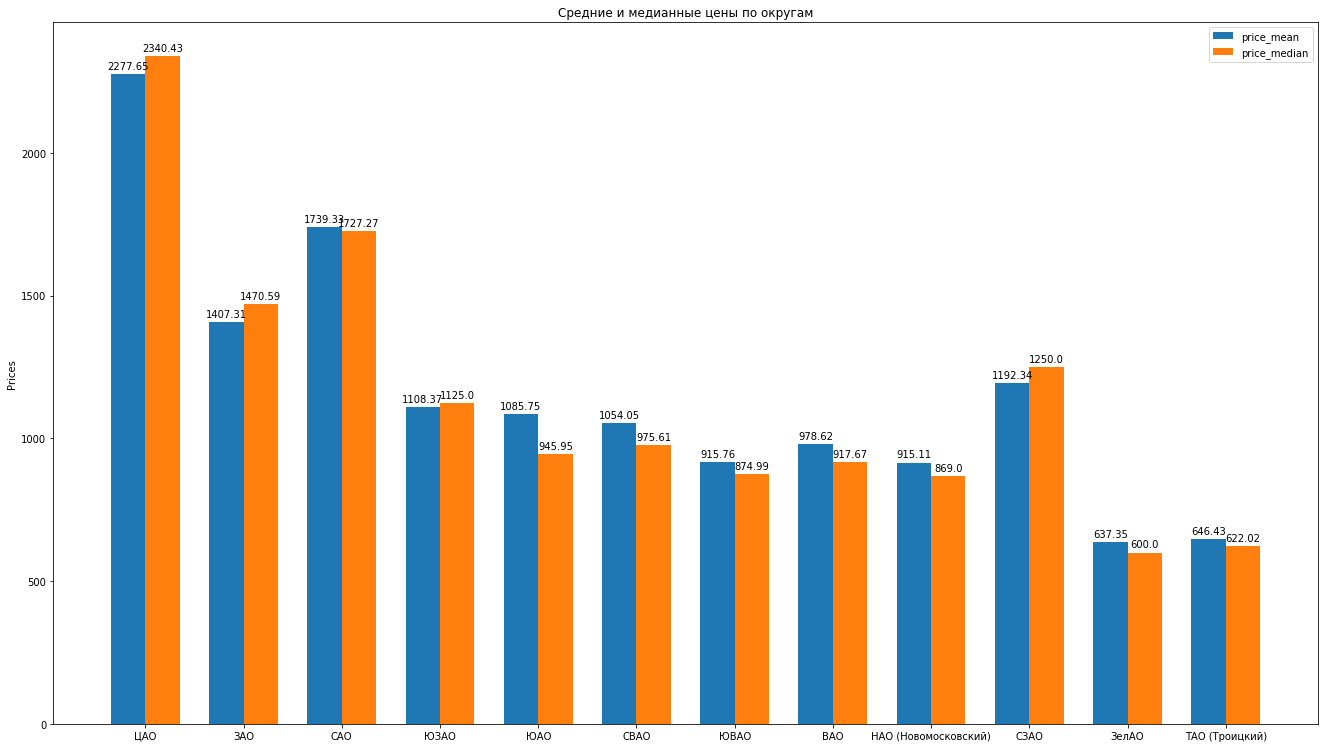 Que peut dire sur la structure des propositions d'appartements locatifs sur la base des données:
Que peut dire sur la structure des propositions d'appartements locatifs sur la base des données:- , , , . “” , ( ). , , , , , , “” . , , .
- . . « ». , «» — . . . , , , , , - , , . . .
- , “” , . , , — .
Un chapitre séparé, incroyablement intéressant et magnifique est le sujet des géodonnées, l'affichage de nos données par rapport à la carte. Vous pouvez regarder en très détail et de détail, par exemple, dans les articles:Visualisation des résultats des élections à Moscou sur une carte dans l'ordinateur portable Jupyterlikbez sur des projections cartographiques avecOpenStreetMap images comme source de géodonnéesEn
bref, OpenStreetMap est notre tout, des outils pratiques sont: geopandas , cartoframes (ils disent qu'il est déjà mort?) et le folium , que nous utiliserons.Voici à quoi ressembleront nos données sur une carte interactive.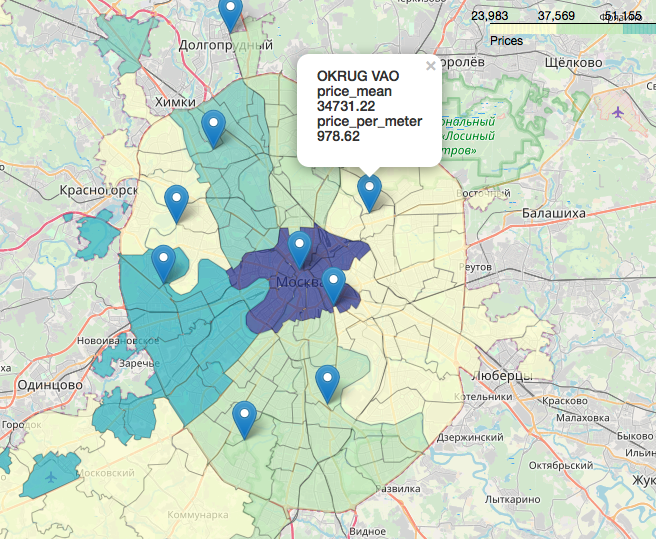 Matériaux qui se sont avérés utiles dans le travail sur l'article:J'espère que vous étiez intéressé, comme moi.Merci pour la lecture. La critique constructive est la bienvenue.Les sources et les jeux de données sont affichés sur le github ici .
Matériaux qui se sont avérés utiles dans le travail sur l'article:J'espère que vous étiez intéressé, comme moi.Merci pour la lecture. La critique constructive est la bienvenue.Les sources et les jeux de données sont affichés sur le github ici .