Bonjour à tous! L'autre jour, dans le cadre de la plateforme éducative OTUS, un nouveau cours est lancé: «Architecture and Design Patterns» . Dans le cadre du début, nous avons organisé une leçon traditionnelle ouverte . Il a étudié les caractéristiques d'une application monolithique, d'architectures multi-niveaux et sans serveur. Nous avons examiné en détail le système événementiel, le système orienté services et l'architecture de microservices. L'enseignant est Matvey Kalinin , spécialiste avec plus de 20 ans d'expérience en programmation et auteur du cours «Architecture and Design Patterns».
L'enseignant est Matvey Kalinin , spécialiste avec plus de 20 ans d'expérience en programmation et auteur du cours «Architecture and Design Patterns».Un peu d'histoire
Au départ, les programmes ont vraiment résolu la tâche fixée pour eux-mêmes et étaient assez isolés. Mais au fil du temps, les programmes se sont développés et les gens ont commencé à comprendre que la complexité émergente du fonctionnel commençait à affecter la vitesse des améliorations, la fiabilité et la résistance à divers types de complications.En effet, lorsque nous avons un ou deux programmes identiques et qui ne changent pas, écrire ces programmes et assurer leur interaction n'est pas difficile. Mais quand il y en a de plus en plus, les problèmes ne peuvent être évités, et peu importe le type de progiciel impliqué.Aujourd'hui, la plupart des applications sont distribuées. Ils se composent de plusieurs modules et sont interconnectés par des messages système. Autrement dit, un conglomérat assez important de programmes interagissant les uns avec les autres est obtenu. Et pour qu'ils interagissent avec succès, nous devons considérer:- réponse rapide;
- largeur de bande
- performance en termes d'une unité de ressource;
- capacité à évoluer;
- capacités d'intégration;
- caractéristiques des plates-formes utilisées;
- caractéristiques des processus opérationnels existants;
- et beaucoup plus…
En même temps, on ne peut s'empêcher de rappeler la citation suivante:«Le code de programme correct ne nécessite pas de gros coûts de main-d'œuvre pour sa création et sa maintenance. Les modifications sont effectuées rapidement et facilement. Les erreurs sont peu nombreuses. Les coûts de main-d'œuvre sont minimes, tandis que la fonctionnalité et la flexibilité sont maximales . »
Robert Cecil Martin
C'est-à-dire qu'en écrivant le programme idéalement une fois (s'il est bien écrit), les améliorations seront minimes. Comment y parvenir et lier l'un à l'autre? Pour répondre à cette question, nous nous tournons vers l'histoire.?
Nous avons donc réalisé que nous devons structurer correctement le produit logiciel. Mais quel est le but de l'architecture logicielle? Et de toute façon, pourquoi avons-nous utilisé l'expression «les jambes grandissent» dans le titre de cet article?Le fait est que lorsque vous démarrez la programmation, vous savez déjà ce que vous voulez construire. Au départ, tout commence par un processus métier. Il y a une commande et un client qui décrit (au moins en mots) comment son système devrait fonctionner. Et au début, ce système n'existe que sous la forme qu'il décrit. Ensuite, ce processus est officialisé et décrit, mais c'est encore la moitié de la bataille, car le développement se poursuit. Et le développeur doit convertir ce processus en produit logiciel, ce qui devrait ...Ensuite, il est temps de rappeler une autre citation:"Le but de l'architecture logicielle est de réduire le travail humain requis pour créer et maintenir un système."
Robert Cecil Martin
Il ne faut pas s'étonner que le but soit formé par de telles phrases générales. Le fait est que l'architecture vit dans des idées abstraites. Pourquoi? Parce que la personne engagée dans l'architecture logicielle transforme la vision d'un client professionnel en vision d'un développeur . Et si nous parlons de l'architecte de l'équipe de développement et de l'architecte d'entreprise, alors chacun d'eux a un objectif différent, mais tous deux s'efforcent d'une seule chose : réduire les coûts de main-d'œuvre humaine.Dans ce contexte, il est intéressant de regarder les valeurs des logiciels:- Le code répond aux exigences du processus opérationnel;
- il y a la possibilité d'un changement rapide de comportement.
Et ici, la question se pose: pourquoi est-il plus important, le fonctionnement du système ou la simplicité de le changer ? Pour y répondre, regardons le programme du point de vue de l'utilité:s'il existe un programme fonctionnant correctement qui ne permet pas de modifications, un tel programme finira par devenir non pertinent - lorsque les exigences changeront.Si le programme ne fonctionne pas correctement, mais que des modifications peuvent y être apportées, il peut alors être effectué pour fonctionner correctement dans le cadre de l'évolution des exigences. Ce programme restera toujours utile.Paradigmes (modèles) de programmation
Selon vous, quel est le modèle de programmation le plus célèbre (le tout premier)? Bien sûr, un monolithe . Il convient ici encore de revenir un instant sur 1968 et de rappeler Edsger Dijkstra, qui a montré que l'utilisation galopante des transitions (instructions goto) nuit à la structure du programme. Il a suggéré de remplacer les transitions par des constructions plus compréhensibles if / then / else et do / while / until.Maintenant, les instructions de goto peuvent être vues moins souvent. Mais avant, les instructions de goto étaient très courantes. En général, il s'agit d'une forme de mal, car lorsque vous voyez le code dans lequel se trouve une instruction goto, vous avez le sentiment que vous ne trouverez peut-être pas le point où il va. Et le plus goto, le plus compliqué, c'est-à-dire que nous obtenons le code spaghetti. Nous appelons maintenant ce code «spaghetti», où, par exemple, 20 ifs imbriqués et, éventuellement, un goto. Ce n'est pas non plus un code très clair. Imaginez que vous êtes passés à 10-15 et que vous essayez de comprendre comment fonctionne le cycle - c'est ce que Dijkstra avait en tête.Le code spaghetti est un programme mal structuré, déroutant et difficile à comprendre qui contient de nombreuses instructions goto (en particulier des sauts), des exceptions et d'autres constructions qui altèrent la structure. En général, un contre-modèle de programmation bien connu et assez courant. Un tel programme prend beaucoup de temps à comprendre, à soutenir et à tester.Programmation structurelle
Il y avait des langages de programmation, ils ont réalisé certains objectifs. Jusqu'à un certain point, la structure des programmes n'a pas beaucoup affecté la mise en œuvre. Mais les programmes se développent, entre eux de nombreux liens se nouent. Et à un moment donné, une personne a estimé qu'il était important de regrouper l'algorithme dans une structure facile à lire et à tester. Des changements ont commencé au niveau de la structure du programme. Autrement dit, non seulement le programme lui-même devait satisfaire le résultat, mais la structure du programme devait également répondre à un certain critère.Ainsi, nous sommes passés en douceur à la programmation structurelle . Selon lui, le programme est construit sans utiliser l'opérateur goto et se compose de trois structures de contrôle de base:- séquence,
- ramification
- cycle.
Des sous-programmes sont utilisés, le développement lui-même s'effectue étape par étape, de haut en bas.Et encore une fois, en 1966 ... Cette année, Ole-Johan Dahl et Kristen Nyugor ont remarqué que dans le langage ALGOL, il est possible de déplacer le cadre de la pile d'appels de fonctions vers la mémoire dynamique (tas), afin que les variables locales déclarées à l'intérieur de la fonction puissent être enregistrées après en sortir. En conséquence, la fonction est devenue le constructeur de la classe, les variables locales en variables d'instance et les fonctions imbriquées en méthodes. Cela a conduit à la découverte du polymorphisme grâce à l'utilisation stricte de pointeurs de fonction.Programmation orientée objet
Comme vous le savez tous, dans la POO, les programmes sont représentés comme une collection d'objets, chacun étant une instance d'une classe particulière, et les classes forment une hiérarchie d'héritage.Principes de base de la structuration:- abstraction;
- héritage;
- polymorphisme.
Vous pouvez regarder tous ces principes sous un autre angle. Robert Martin a développé les principes de SOLID, qui, d'une part, déterminent comment un programmeur travaille avec les abstractions, et d'autre part, forment le processus de polymorphisme et d'héritage.Programmation impérative
Un programme impératif est similaire aux ordres qu'un ordinateur doit exécuter. Ces programmes se caractérisent par:- les instructions sont écrites dans le code source du programme;
- les instructions doivent être suivies séquentiellement;
- les données obtenues lors de l'exécution d'instructions précédentes peuvent être lues de la mémoire par des instructions ultérieures;
- les données obtenues en exécutant l'instruction peuvent être écrites en mémoire.
Aussi un design très ancien. Les principales caractéristiques des langues impératives:- utilisation de variables nommées;
- utilisation de l'opérateur d'affectation;
- utilisation d'expressions composées;
- utilisation de routines.
Cependant, nous continuons le «voyage dans le temps». Cette fois, nous reviendrons un instant en 1936 (!). Il est intéressant de noter que cette année, Alonzo Church a inventé le lambda calcul (ou λ-calcul), qui plus tard, en 1958, a formé la base du langage LISP inventé par John McCarthy. Le concept fondamental du λ-calcul est l'immuabilité, c'est-à-dire l'impossibilité de modifier les valeurs des symboles.Programmation fonctionnelle
La programmation fonctionnelle implique de faire le calcul des résultats des fonctions à partir des données source et des résultats des autres fonctions et n'implique pas un stockage explicite de l'état du programme.En fait, cela signifie qu'un langage fonctionnel n'a pas de déclaration d'affectation.Examinons la différence entre les styles impératifs et fonctionnels à l'aide d'un exemple:#
target = [] #
for item in source_list: #
trans1 = G(item) # G()
trans2 = F(trans1) # F()
target.append(trans2) #
#
compose2 = lambda A, B: lambda x: A(B(x))
target = map(compose2(F, G), source_list)
Qu'est-ce que l'architecture logicielle?
L'architecture logicielle est un ensemble de décisions concernant l'organisation d'un système logiciel.Il comprend:- sélection des éléments structurels et de leurs interfaces;
- le comportement des éléments et interfaces sélectionnés, leur interaction;
- combiner certains éléments de structure et de comportement dans des systèmes plus vastes;
- style architectural qui guide toute l'organisation.
Remarque: nous sommes d'abord arrivés à la conclusion que goto ne nous convenait pas, puis nous avons vu qu'il y avait certaines règles (encapsulation, héritage, polymorphisme), puis nous avons réalisé que ces règles ne fonctionnaient pas seulement, mais conformément à certains principes. Le quatrième point est le style architectural, et nous en reparlerons plus tard.Le but principal de l'architecture est de soutenir le cycle de vie du système. Une bonne architecture rend le système facile à apprendre, facile à développer, à entretenir et à déployer. Le but ultime est de minimiser les coûts sur la durée de vie du système et de maximiser la productivité du programmeur et plus précisément de l'équipe de développement.Au début, nous avons parlé des règles dont nous avions besoin pour écrire des programmes. Mais, en plus d'écrire des programmes, il y a aussi le support, le développement et le déploiement. Autrement dit, l'architecture ne capture pas un certain domaine de programmation, mais l'ensemble du cycle de développement.Une bonne architecture devrait fournir:- Une variété de cas d'utilisation et un fonctionnement efficace du système.
- Simplicité de la maintenance du système.
- Facilité de conception du système.
- Déploiement facile du système.
Styles architecturaux
Monolithe
Tout d'abord, parlons du monolithe bien connu . Ce style se retrouve cependant dans les petits systèmes. L'architecture monolithique signifie que votre application est un grand module connecté. Tous les composants sont conçus pour fonctionner ensemble, partager la mémoire et les ressources. Toutes les fonctions ou leur partie principale sont concentrées dans un seul processus ou conteneur, qui est divisé en couches ou bibliothèques internes. Avantages:
Avantages:- Facile à mettre en œuvre. Pas besoin de perdre du temps à penser à la communication interprocessus.
- Tests de bout en bout faciles à développer.
- Facile à déployer.
- Évoluez facilement avec Loadbalancer sur plusieurs instances de votre application.
- Facile à utiliser.
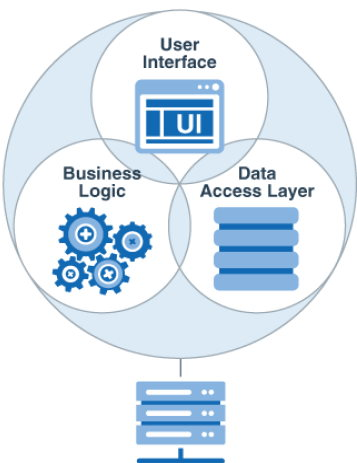 Mais maintenant, il a plus de lacunes :
Mais maintenant, il a plus de lacunes :- Une forte cohésion conduit à un enchevêtrement avec l'évolution de l'application.
- Une mise à l'échelle indépendante des composants entraîne des complications et un nouveau test complet des fonctionnalités.
- Plus difficile à comprendre.
- À mesure que la complexité augmente, le temps de développement s'allonge.
- Manque d'isolement des composants.
D'une part, le monolithe est bon, mais dès que vous commencez à le développer, des difficultés surviennent.Qu'est-ce qu'un service?
Maintenant, tout le monde sait ce qu'est un service. Elle peut être définie comme une ressource visible qui effectue une tâche répétitive et est décrite par une instruction externe.Les services modernes ont les caractéristiques suivantes :- les services sont orientés non pas sur les capacités informatiques, mais sur les besoins de l'entreprise;
- les services sont autosuffisants et sont décrits en termes d'interfaces, d'opérations, de sémantique, de caractéristiques dynamiques, de politiques et de propriétés du service;
- la réutilisation des services est assurée par leur planification modulaire;
- les accords de service sont conclus entre des entités appelées fournisseurs et utilisateurs et n'affectent pas la mise en œuvre des services eux-mêmes;
- au cours de son cycle de vie, les services sont hébergés et rendus visibles via les métadonnées de service, les registres et les référentiels;
- agrégation: la combinaison de processus métier et d'applications complexes pour une ou plusieurs entreprises repose sur des services faiblement couplés.
En raison des caractéristiques ci-dessus, le concept d'architecture orientée services (SOA) est né.Architecture orientée services (SOA)
SOA est un style architectural pour créer une architecture informatique d'entreprise, en utilisant les principes d'orientation des services pour établir une connexion étroite entre l'entreprise et ses systèmes d'information de support. SOA présente les caractéristiques suivantes :
SOA présente les caractéristiques suivantes :- Améliore la relation entre l'architecture d'entreprise et l'entreprise.
- Vous permet de créer des applications complexes à partir d'ensembles de services intégrés.
- Crée des processus commerciaux flexibles.
- Cela ne dépend pas d'un ensemble de technologies.
- Autonome dans le sens d'une évolution et d'un déploiement indépendants.
Un modèle de déploiement SOA comprend la veille stratégique et le développement et la veille stratégique et le développement informatique. L'assemblage consiste à programmer des services et à créer des applications complexes. L'hébergement consiste à héberger des applications et des outils d'exécution tels que les bus de services d'entreprise (ESB). Quant au manuel , il consiste à soutenir l'environnement d'exploitation, à surveiller les performances des services et à contrôler la conformité aux politiques de service.
Architecture de microservice
Il est temps de parler de l'architecture des microservices . Dans ce document, l'application se compose de petites applications de service indépendantes, chacune avec ses propres ressources. Les services interagissent entre eux pour effectuer des tâches liées à leurs opportunités commerciales. Il existe plusieurs unités de déploiement. Chaque service est déployé indépendamment. Avantages:
Avantages:- Prend en charge la modularité de l'ensemble du système.
- Les services non liés sont plus faciles à modifier pour servir différentes applications.
- Différents services peuvent appartenir à différentes équipes.
- Les services peuvent être réutilisés dans toute l'entreprise.
- Plus facile à comprendre et à tester.
- Pas lié à la technologie utilisée dans d'autres services.
- L'isolement du service augmente la fiabilité globale de toutes les fonctionnalités.
 Désavantages:
Désavantages:- Difficultés de mise en œuvre de la fonctionnalité globale (journalisation, droits d'accès, etc.).
- Il est difficile de réaliser des tests système de bout en bout.
- Fonctionnement et assistance plus difficiles.
- Il faut plus d'équipement que pour un monolithe.
- Le soutien de plusieurs équipes conduit à une coordination des interactions entre elles.
Il convient de noter que dans cette architecture, il est très difficile de faire quoi que ce soit sans DevOps.Architecture en couches
L'architecture en couches est le modèle d'architecture le plus courant. Il est également appelé architecture à n niveaux, où n est le nombre de niveaux.Le système est divisé en niveaux, dont chacun interagit avec seulement deux voisins.L'architecture n'implique aucun nombre obligatoire de niveaux - il peut y en avoir trois, quatre, cinq ou plus. Le plus souvent, des systèmes à trois niveaux sont utilisés: avec un niveau de présentation (client), un niveau logique et un niveau de données.Les couches les plus courantes sont :- couche de présentation (pour travailler avec les utilisateurs);
- couche application (service - sécurité, accès);
- couche logique métier (implémentation de domaine);
- couche d'accès aux données (représentation de l'interface avec la base de données).
Couches fermées
Le concept d'isolement des niveaux sépare strictement un niveau d'un autre: vous ne pouvez passer que d'un niveau à l'autre et vous ne pouvez pas passer immédiatement de plusieurs niveaux.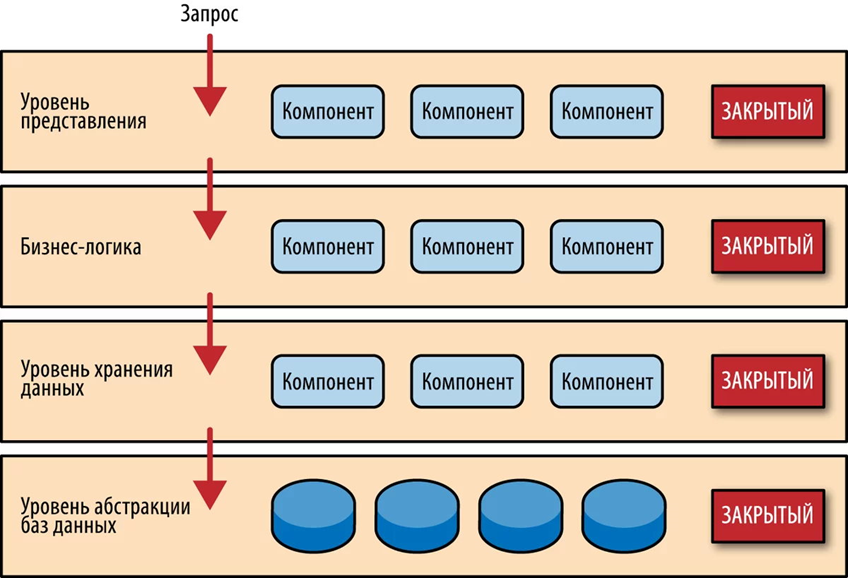
Couches ouvertes
Le système vous permet de sauter par-dessus les niveaux ouverts et de tomber sur ceux situés en dessous.
MVC
Le concept de MVC a été décrit en 1978. La version finale du concept MVC n'a été publiée qu'en 1988 dans la revue Technology Object.L'objectif principal est de séparer la logique métier (modèle) de sa visualisation (présentation, vue). Qu'est-ce que ça donne:- La possibilité de réutilisation du code est augmentée.
- l'utilisateur peut voir les mêmes données simultanément dans différents contextes.
 Le modèle fournit des données et répond aux commandes du contrôleur, en changeant son état. La vue est chargée d'afficher les données du modèle à l'utilisateur, en répondant aux modifications du modèle. Le contrôleur interprète les actions de l'utilisateur, notifiant le modèle de la nécessité de modifications.
Le modèle fournit des données et répond aux commandes du contrôleur, en changeant son état. La vue est chargée d'afficher les données du modèle à l'utilisateur, en répondant aux modifications du modèle. Le contrôleur interprète les actions de l'utilisateur, notifiant le modèle de la nécessité de modifications.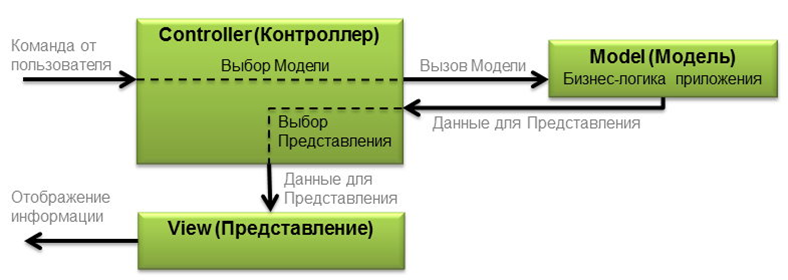
Architecture événementielle
Une autre architecture intéressante. Il est utilisé dans le développement et la mise en œuvre de systèmes qui transmettent des événements entre des éléments logiciels faiblement couplés.Se compose de composants de traitement des événements à usage unique disparates qui reçoivent et traitent les événements de manière asynchrone.Le modèle se compose de deux topologies principales - un intermédiaire et un courtier.Topologie du revendeur
Il existe des processus où le contrôle de la séquence des étapes est nécessaire. Ici, nous sommes un intermédiaire utile.Les principaux types de composants d'architecture:- files d'attente d'événements;
- médiateur d'événements;
- canaux d'événements;
- gestionnaires d'événements.
Événement Unévénement peut être défini comme un «changement d'état important». Un événement peut comprendre deux parties:- en-tête (nom de l'événement, horodatage de l'événement et type d'événement);
- corps (décrit ce qui s'est réellement passé).
Topologie du médiateurLe client envoie un événement à la file d'attente d'événements, qui est utilisée pour envoyer l'événement au médiateur.Le médiateur reçoit l'événement initial et envoie des événements asynchrones supplémentaires aux canaux d'événements pour chaque étape du processus.Les processeurs d'événements, qui écoutent les canaux d'événements, reçoivent un événement d'un intermédiaire et exécutent une certaine logique métier en traitant l'événement. Topologie du courtierLa topologie du courtier diffère de la topologie intermédiaire en ce qu'il n'y a pas de médiateur d'événement central. Le flux de messages est distribué entre les composants du processeur d'événements dans une chaîne via un courtier de messages léger (par exemple, ActiveMQ, HornetQ, etc.). Cette topologie est utile lorsqu'il existe un flux relativement simple de traitement d'événements et qu'il n'est pas nécessaire d'avoir une orchestration d'événements centralisée.Chaque composant d'un processeur d'événements est responsable du traitement d'un événement et de la publication d'un nouvel événement indiquant l'action qui vient de se terminer.
Topologie du courtierLa topologie du courtier diffère de la topologie intermédiaire en ce qu'il n'y a pas de médiateur d'événement central. Le flux de messages est distribué entre les composants du processeur d'événements dans une chaîne via un courtier de messages léger (par exemple, ActiveMQ, HornetQ, etc.). Cette topologie est utile lorsqu'il existe un flux relativement simple de traitement d'événements et qu'il n'est pas nécessaire d'avoir une orchestration d'événements centralisée.Chaque composant d'un processeur d'événements est responsable du traitement d'un événement et de la publication d'un nouvel événement indiquant l'action qui vient de se terminer. Si la première situation était asynchrone «quelque part en dessous», alors la deuxième situation est asynchrone, pourrait-on dire, complètement. Un événement génère plusieurs événements, et ils peuvent augmenter et augmenter.Les avantages architecture événementielle:
Si la première situation était asynchrone «quelque part en dessous», alors la deuxième situation est asynchrone, pourrait-on dire, complètement. Un événement génère plusieurs événements, et ils peuvent augmenter et augmenter.Les avantages architecture événementielle:- les composants sont isolés et permettent de finaliser chacun sans affecter le reste du système;
- facilité de déploiement;
- haute performance. Permet des opérations asynchrones parallèles;
- se balance bien.
Désavantages:- difficile à tester;
- difficile à développer en raison d'une asynchronie prononcée.
Architecture sans serveur
Il s'agit d'un moyen de créer et d'exécuter des applications et des services sans avoir besoin de gérer l'infrastructure. L'application fonctionne toujours sur les serveurs, mais la plateforme prend complètement le contrôle de ces serveurs.L'ensemble de l'infrastructure est pris en charge par des fournisseurs tiers et les fonctionnalités nécessaires sont proposées sous la forme de services chargés des processus d'authentification, de la messagerie, etc.La terminologie suivante est distinguée:- (Function-as-a-Service) — , .
- (Backend as a Service) — , - API, . , , , .
Si l'on considère l'architecture de «Client-serveur», alors la majeure partie de la logique du système (authentification, navigation de page, recherche, transactions) est implémentée par l'application serveur. Dans l'architecture sans serveur, tout est quelque peu différent. L'authentification est remplacée par un service BaaS tiers (service cloud prêt à l'emploi), l'accès à la base de données est également remplacé par un autre service BaaS. La logique d'application est déjà partiellement à l'intérieur du client - par exemple, le suivi de la session d'un utilisateur.Le client est déjà en passe de devenir une application d'une page. La recherche peut être effectuée via le service de recherche (FaaS - fonction en tant que service). La fonction d'achat est également isolée du client en tant que service distinct (FaaS).
Dans l'architecture sans serveur, tout est quelque peu différent. L'authentification est remplacée par un service BaaS tiers (service cloud prêt à l'emploi), l'accès à la base de données est également remplacé par un autre service BaaS. La logique d'application est déjà partiellement à l'intérieur du client - par exemple, le suivi de la session d'un utilisateur.Le client est déjà en passe de devenir une application d'une page. La recherche peut être effectuée via le service de recherche (FaaS - fonction en tant que service). La fonction d'achat est également isolée du client en tant que service distinct (FaaS). Eh bien, c'est tout, si vous êtes intéressé par les détails, regardez l'intégralité de la vidéo. Quant au nouveau cours, vous pouvez vous familiariser avec son programme ici.
Eh bien, c'est tout, si vous êtes intéressé par les détails, regardez l'intégralité de la vidéo. Quant au nouveau cours, vous pouvez vous familiariser avec son programme ici.