Il y a quelque temps, j'ai commencé un voyage incroyable dans le monde du compilateur JIT afin de trouver des endroits où vous pouvez mettre la main et accélérer quelque chose, car Au cours du travail principal, une petite quantité de connaissances en LLVM et ses optimisations s'est accumulée. Dans cet article, je voudrais partager une liste de mes améliorations dans JIT (dans .NET, il s'appelle RyuJIT en l'honneur d'un dragon ou d'un anime - je ne l'ai pas compris), dont la plupart ont déjà atteint master et seront disponibles dans .NET (Core) 5 Mes optimisations affectent différentes phases de JIT, ce qui peut être illustré de manière très schématique comme suit: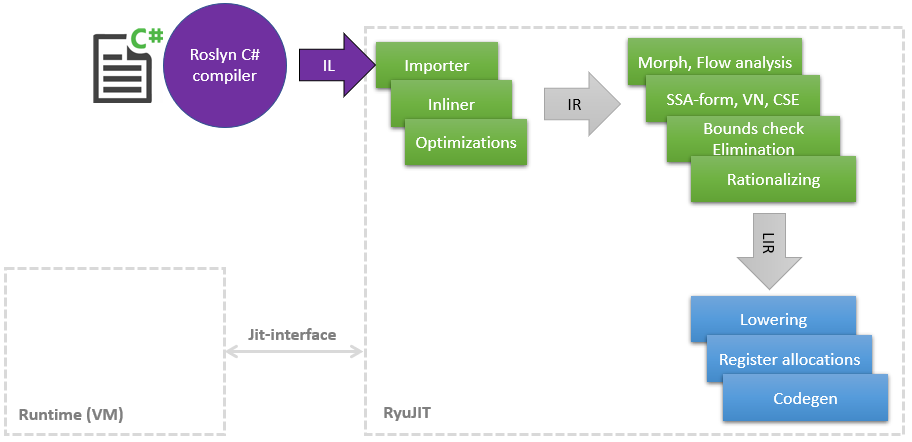 Comme le montre le diagramme, JIT est un module distinct lié à l' interface Jit étroite , par lequel JIT consulte sur certaines choses, par exemple, est- il possiblelancer une classe à l'autre. Plus tard le JIT compile la méthode dans Tier1, plus le runtime peut fournir d'informations, par exemple, que les
Comme le montre le diagramme, JIT est un module distinct lié à l' interface Jit étroite , par lequel JIT consulte sur certaines choses, par exemple, est- il possiblelancer une classe à l'autre. Plus tard le JIT compile la méthode dans Tier1, plus le runtime peut fournir d'informations, par exemple, que les static readonlychamps peuvent être remplacés par une constante, car la classe est déjà initialisée statiquement.Commençons donc par la liste.PR # 1817 : Optimisations de boxing / unboxing dans la correspondance de modèles
Phase: importateur Laplupart des nouvelles fonctionnalités C # pèchent souvent en insérant des opcodes CIL box / unbox . Il s'agit d'une opération très coûteuse, qui consiste essentiellement à allouer un nouvel objet sur le tas, à y copier la valeur de la pile, puis à charger également le GC à la fin. Il existe déjà un certain nombre d'optimisations dans JIT pour ce cas, mais j'ai trouvé une correspondance de modèle manquante en C # 8, par exemple:public static int Case1<T>(T o)
{
if (o is int x)
return x;
return 0;
}
public static int Case2<T>(T o) => o is int n ? n : 42;
public static int Case3<T>(T o)
{
return o switch
{
int n => n,
string str => str.Length,
_ => 0
};
}
Et voyons l'asm-codegen avant mon optimisation (par exemple, pour la spécialisation int) pour les trois méthodes: Et maintenant après mon amélioration:
Et maintenant après mon amélioration: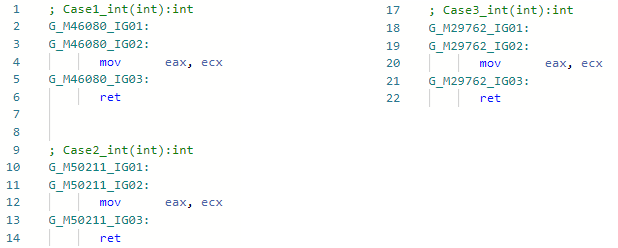 Le fait est que l'optimisation a trouvé des modèles de code IL
Le fait est que l'optimisation a trouvé des modèles de code ILbox !!T
isinst Type1
unbox.any Type2
lors de l'importation et de la possession d'informations sur les types, j'ai pu simplement ignorer ces opcodes et ne pas insérer boxing-anboxing. Soit dit en passant, j'ai également implémenté la même optimisation dans Mono. Ci-après, un lien vers Pull-Request est contenu dans l'en-tête de la description d'optimisation.PR # 1157 typeof (T) .IsValueType ⇨ vrai / faux
Phase: importateurIci, j'ai formé JIT à remplacer immédiatement Type.IsValueType par une constante si possible. C'est un moins le défi et la capacité de couper des conditions entières et des branches à l'avenir, un exemple:void Foo<T>()
{
if (!typeof(T).IsValueType)
Console.WriteLine("not a valuetype");
}
Et voyons le codegen pour la spécialisation Foo <int> avant l'amélioration: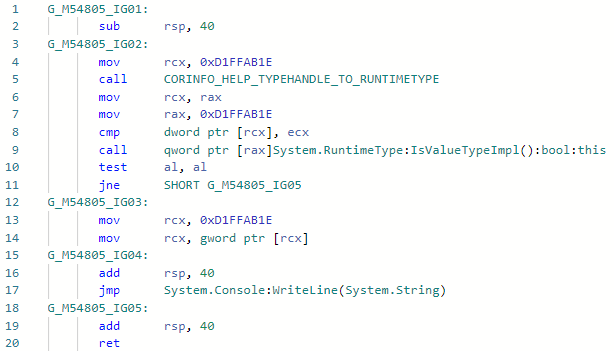 Et après l'amélioration: la
Et après l'amélioration: la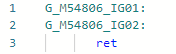 même chose peut être faite avec d'autres propriétés Type si nécessaire.
même chose peut être faite avec d'autres propriétés Type si nécessaire.PR # 1157 typeof(T1).IsAssignableFrom(typeof(T2)) ⇨ true/false
Phase: importateurPresque la même chose - vous pouvez maintenant vérifier la hiérarchie dans les méthodes génériques sans craindre qu'elle ne soit pas optimisée, par exemple:void Foo<T1, T2>()
{
if (!typeof(T1).IsAssignableFrom(typeof(T2)))
Console.WriteLine("T1 is not assignable from T2");
}
De la même manière, elle sera remplacée par une constante true/falseet la condition pourra être supprimée entièrement. Dans de telles optimisations, bien sûr, ce n'est pas sans cas d'angle que vous devez toujours vous souvenir: System .__ Canon génériques partagés, tableaux, variabilité co (ntr), nullables, objets COM, etc.PR # 1378 "Hello".Length ⇨ 5
Phase: importateurMalgré le fait que l'optimisation soit aussi évidente et simple que possible, j'ai dû beaucoup transpirer pour l'implémenter dans JIT-e. Le fait est que JIT ne connaissait pas le contenu de la chaîne, il a vu les littéraux de chaîne ( GT_CNS_STR ), mais ne savait rien du contenu spécifique des chaînes. J'ai dû l'aider en contactant VM (pour étendre l'interface JIT susmentionnée), et l'optimisation elle-même est essentiellement quelques lignes de code . Il y a beaucoup de cas d'utilisateurs, en plus des cas évidents, tels que: str.IndexOf("foo") + "foo".Lengthaux cas non évidents dans lesquels l'inline est impliqué (je vous rappelle: Roslyn ne traite pas de l'inline, donc cette optimisation y serait inefficace, comme tout le reste), un exemple:bool Validate(string str) => str.Length > 0 && str.Length <= 100;
bool Test() => Validate("Hello");
Regardons le codegen pour Test ( Validate est en ligne):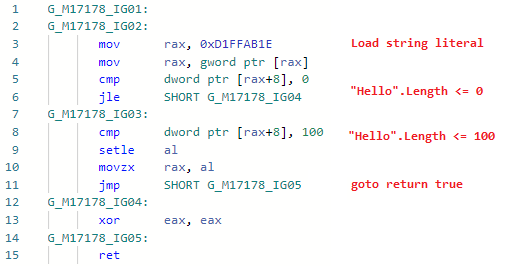 et maintenant le codegen après avoir ajouté l'optimisation:
et maintenant le codegen après avoir ajouté l'optimisation: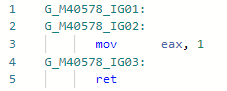 i.e. aligner la méthode, remplacer les variables par des littéraux de chaîne, remplacer .Length des littéraux par des longueurs de chaîne réelles, replier les constantes, supprimer le code mort. Soit dit en passant, puisque JIT peut désormais vérifier le contenu d'une chaîne, des portes se sont ouvertes pour d'autres optimisations liées aux littéraux de chaîne. L'optimisation elle-même a été mentionnée dans l'annonce du premier aperçu de .NET 5.0: devblogs.microsoft.com/dotnet/announcing-net-5-0-preview-1 dans la section Améliorations de la qualité du code dans RyuJIT .
i.e. aligner la méthode, remplacer les variables par des littéraux de chaîne, remplacer .Length des littéraux par des longueurs de chaîne réelles, replier les constantes, supprimer le code mort. Soit dit en passant, puisque JIT peut désormais vérifier le contenu d'une chaîne, des portes se sont ouvertes pour d'autres optimisations liées aux littéraux de chaîne. L'optimisation elle-même a été mentionnée dans l'annonce du premier aperçu de .NET 5.0: devblogs.microsoft.com/dotnet/announcing-net-5-0-preview-1 dans la section Améliorations de la qualité du code dans RyuJIT .PR # 1644: Optimisation des vérifications liées.
Phase: élimination de la vérification des limitesPour beaucoup, ce n'est pas un secret que chaque fois que vous accédez à un tableau par index, le JIT insère pour vous un contrôle que le tableau ne va pas au-delà et lève une exception si cela se produit - dans le cas d'une logique erronée, vous ne pouvez pas pour lire la mémoire aléatoire, obtenir de la valeur et continuer.int Foo(int[] array, int index)
{
return array[index];
}
Une telle vérification est utile, mais elle peut grandement affecter les performances: d'une part, elle ajoute une opération de comparaison et rend votre code non ramifié, et d'autre part, elle ajoute un code d'appel d'exception à votre méthode avec toutes les conséquences. Cependant, dans de nombreux cas, le JIT peut supprimer ces contrôles s'il peut se prouver que l'index ne dépassera jamais cela, ou qu'il existe déjà un autre contrôle et qu'un ajout supplémentaire n'est plus nécessaire - Élimination des contrôles de limites (plage). J'ai trouvé plusieurs cas dans lesquels il ne pouvait pas faire face et les ai corrigés (et à l'avenir, je prévois d'autres améliorations de cette phase).var item = array[index & mask];
Ici, dans ce code, je dis à JIT qui & masklimite essentiellement l'indice d'en haut à une valeur mask, c'est-à-dire si la valeur masket la longueur du tableau sont connues de JIT , vous ne pouvez pas insérer de contrôle lié. Il en va de même pour les opérations%, (& x >> y). Un exemple d'utilisation de cette optimisation dans aspnetcore .De plus, si nous savons que dans notre tableau, par exemple, il y a 256 éléments ou plus, alors si notre indexeur inconnu est du type octet, peu importe ses efforts, il ne pourra jamais sortir des limites. PR: github.com/dotnet/coreclr/pull/25912PR # 24584: x / 2 ⇨ x * 0.5
Phase: MorphC de ce PR et a commencé ma plongée incroyable dans le monde des optimisations JIT. L'opération "division" est plus lente que l'opération "multiplication" (et si pour les entiers et en général - un ordre de grandeur). Fonctionne pour des constantes uniquement égales à la puissance de deux, par exemple:static float DivideBy2(float x) => x / 2;
Codegen avant optimisation: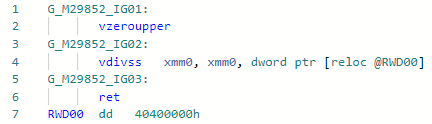 et après:
et après: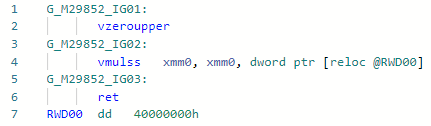 si nous comparons ces deux instructions pour Haswell, alors tout deviendra clair:
si nous comparons ces deux instructions pour Haswell, alors tout deviendra clair:vdivss (Latency: 10-20, R.Throughput: 7-14)
vmulss (Latency: 5, R.Throughput: 0.5)
Cela sera suivi par des optimisations qui sont encore au stade de la révision du code et non par le fait qu'elles seront acceptées.PR # 31978: Math.Pow(x, 2) ⇨ x * x
Phase: importateurTout est simple ici: au lieu d'appeler pow (f) pour un cas assez populaire, lorsque le degré est constant 2 (enfin, c'est gratuit pour 1, -1, 0), vous pouvez le développer en un simple x * x. Vous pouvez développer d'autres degrés, mais pour cela, vous devez attendre la mise en œuvre du mode «mathématique rapide» dans .NET, dans lequel la spécification IEEE-754 peut être négligée pour des raisons de performances. Exemple:static float Pow2(float x) => MathF.Pow(x, 2);
Codegen avant optimisation: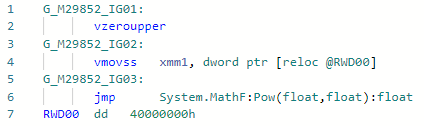 et après:
et après: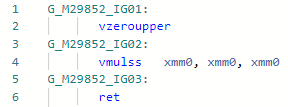
PR # 33024: x * 2 ⇨ x + x
Phase: abaissement L'optimisation du micro (nano) piphol assez simple vous permet de multiplier par 2 sans charger la constante dans le registre.static float MultiplyBy2(float x) => x * 2;
Codegen avant optimisation: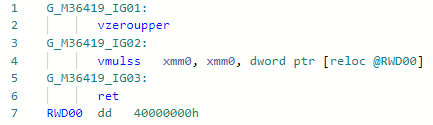 Après:
Après: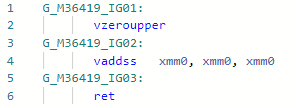 En général, l'instruction est la
En général, l'instruction est la mul(ss/sd/ps/pd)même en termes de latence et de débit que add(ss/sd/ps/pd), mais la nécessité de charger la constante «2» peut légèrement ralentir le travail. Ici, dans l'exemple du codegen ci-dessus, j'ai vaddsstout fait dans le cadre d'un registre.PR # 32368: Optimisation de la baie. Longueur / c (ou% s)
Phase: MorphIl se trouve que le champ Longueur du tableau est un type signé, et la division et le reste par une constante est beaucoup plus efficace à partir d'un type non signé (et pas seulement une puissance de deux), il suffit de comparer ce codegen: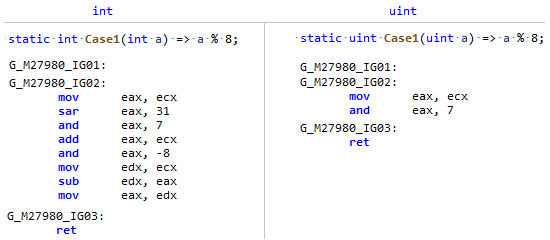 Mon PR rappelle simplement à JIT que
Mon PR rappelle simplement à JIT que Array.Lengthbien que significatif, mais en fait, la longueur du tableau NEVER ( sauf si vous êtes un anarchiste ) peut être inférieure à zéro, ce qui signifie que vous pouvez le regarder comme un nombre non signé et appliquer des optimisations comme pour uint.PR # 32716: Optimisation de comparaisons simples en code sans branche
Phase: analyse de fluxIl s'agit d'une autre classe d'optimisations qui fonctionne avec des blocs de base au lieu d'expressions en un. Ici, JIT est un peu conservateur et peut être amélioré, par exemple des insertions cmove lorsque cela est possible. J'ai commencé avec une optimisation simple pour ce cas:x = condition ? A : B;
si A et B sont des constantes et que la différence entre elles est l'unité, par exemple, condition ? 1 : 2alors nous, sachant que l'opération de comparaison en elle-même renvoie 0 ou 1, pouvons remplacer jump par add. En termes de RyuJIT, cela ressemble à ceci: je recommande de voir la description du PR lui-même, j'espère que tout y est clairement décrit.
recommande de voir la description du PR lui-même, j'espère que tout y est clairement décrit.Toutes les optimisations ne sont pas également utiles.
Les optimisations nécessitent des frais assez élevés:* Augmentation = complexité du code existant pour le support et la lecture* Bogues potentiels: tester les optimisations du compilateur est incroyablement difficile et facile de manquer quelque chose et d'obtenir une sorte de faute de segment de la part des utilisateurs.* Compilation lente* Augmenter la taille du binaire JITComme vous l'avez déjà compris, toutes les idées et tous les prototypes d'optimisations ne sont pas acceptés et il faut prouver qu'ils ont droit à la vie. L'une des façons acceptées de le prouver dans .NET est d'exécuter l'utilitaire jit-utils, qui compilera AOT un ensemble de bibliothèques (toutes BCL et corelib) et comparera le code assembleur pour toutes les méthodes avant et après les optimisations, voici comment ce rapport recherche l'optimisation"str".Length. En plus du rapport, il existe encore un certain cercle de personnes (telles que les jkotas ) qui, en un coup d'œil, peuvent évaluer l'utilité et tout pirater du haut de leur expérience et comprendre quels endroits dans .NET peuvent être un goulot d'étranglement et lesquels ne le peuvent pas. Et encore une chose: ne jugez pas l'optimisation par l'argument «personne n'écrit», «il vaudrait mieux afficher juste un avertissement dans Roslyn» - vous ne savez jamais à quoi ressemblera votre code après JIT inline tout ce qui est possible et remplit les constantes.