La compression des en-têtes standard est apparue dans HTTP / 2, mais le corps des valeurs URI, Cookie, User-Agent peut encore être de plusieurs dizaines de kilo-octets et nécessite une tokenisation, une recherche et une comparaison des sous-chaînes. La tâche devient critique si un analyseur HTTP doit gérer un trafic malveillant important. Les bibliothèques standard fournissent des outils de traitement de chaînes étendus, mais les chaînes HTTP ont leurs propres spécificités. C'est pour cette spécificité que l'analyseur HTTP Tempesta FW a été développé. Ses performances sont plusieurs fois supérieures à celles des solutions Open Source modernes et surpassent les plus rapides d'entre elles.Alexander Krizhanovsky (krizhanovsky) fondateur et architecte système Tempesta Technologies, expert en calcul haute performance sous Linux / x86-64. Alexander parlera des particularités de la structure des chaînes HTTP, expliquera pourquoi les bibliothèques standard sont mal adaptées pour les traiter et présentera la solution Tempesta FW.Sous la coupe: comment HTTP Flood transforme votre analyseur HTTP en goulot d'étranglement, problèmes x86-64 avec des erreurs de prédiction de branche, la mise en cache et la mémoire insuffisante sur les tâches typiques de l'analyseur HTTP, comparaison FSM avec sauts directs, optimisation GCC, vectorisation automatique, strspn () - et des algorithmes de type strcasecmp () pour les chaînes HTTP, SSE, AVX2 et les attaques par filtrage par injection utilisant AVX2.Chez Tempesta Technologies, nous développons des logiciels personnalisés: nous nous spécialisons dans des domaines complexes liés à la haute performance. Nous sommes particulièrement fiers du développement du cœur de la première version WAF de Positive Technologies. Le Web Application Firewall (WAF) est un proxy HTTP: il traite une analyse très approfondie du trafic HTTP pour les attaques (Web et DDoS). Nous en avons écrit le premier noyau.En plus de la consultation, nous développons Tempesta FW - il s'agit d'Application Delivery Controller (ADC). Nous allons parler de lui.Contrôleur de livraison d'applications
Application Delivery Controller est un proxy HTTP avec des fonctionnalités améliorées. Mais je vais parler d'une fonctionnalité liée à la sécurité - le filtrage des attaques DDoS et Web. Je mentionnerai également les limitations, et je montrerai le travail et les fonctions avec des exemples de code.
Performance
Tempesta FW est intégré au noyau Linux TCP / IP Stack. Grâce à cela et à un certain nombre d'autres optimisations, c'est très rapide - il peut traiter 1,8 million de requêtes par seconde sur du matériel bon marché. Ceci est 3 fois plus rapide que Nginx à la charge maximale et est également rapide par rapport à l' approche de contournement du noyau.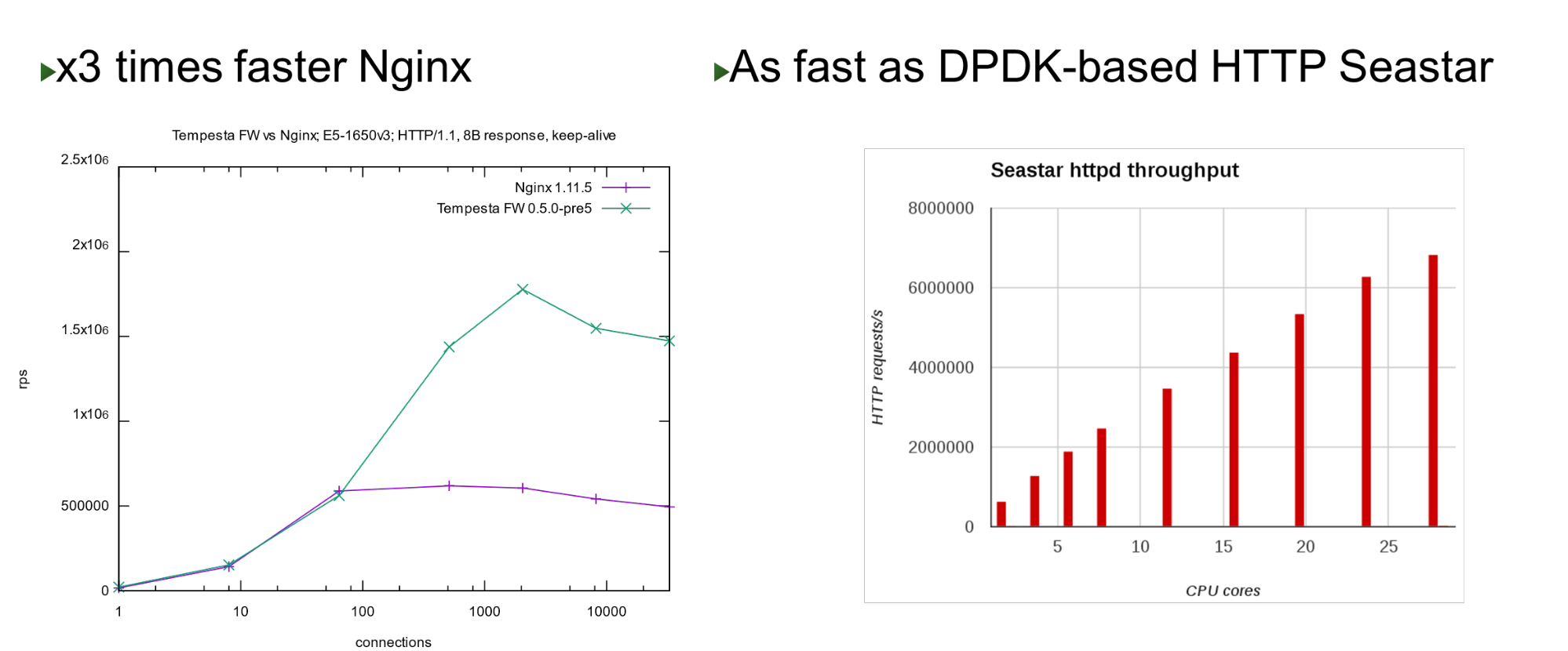 Sur un petit nombre de cœurs, il affiche des performances similaires avec le projet Seastar, qui est utilisé dans ScyllaDB (écrit en DPDK).
Sur un petit nombre de cœurs, il affiche des performances similaires avec le projet Seastar, qui est utilisé dans ScyllaDB (écrit en DPDK).Problème
Le projet est né lorsque nous avons commencé à travailler sur PT AF - en 2013. Ce WAF était basé sur un accélérateur HTTP Open Source populaire. Nginx, HAProxy, Varnish ou Apache Traffic sont de bons accélérateurs HTTP: ils fournissent du contenu fin, mettent en cache, modifient, mais aucun d'entre eux n'est conçu pour le traitement et le filtrage massifs du trafic .Par conséquent, nous avons pensé que s'il existe un pare-feu au niveau du réseau, pourquoi ne pas poursuivre cette idée et l'intégrer dans la pile TCP / IP en tant que pare-feu au niveau de l'application? En fait, il s'est avéré que Tempesta FW - un hybride d'accélérateur HTTP et de pare-feu .Remarque: Nginx sera utilisé comme exemple dans le rapport car il s'agit d'un serveur Web simple et populaire. Au lieu de cela, il pourrait y avoir tout autre serveur HTTP Open Source.HTTP
Regardons notre requête HTTP (HTTP / (1, ~ 2))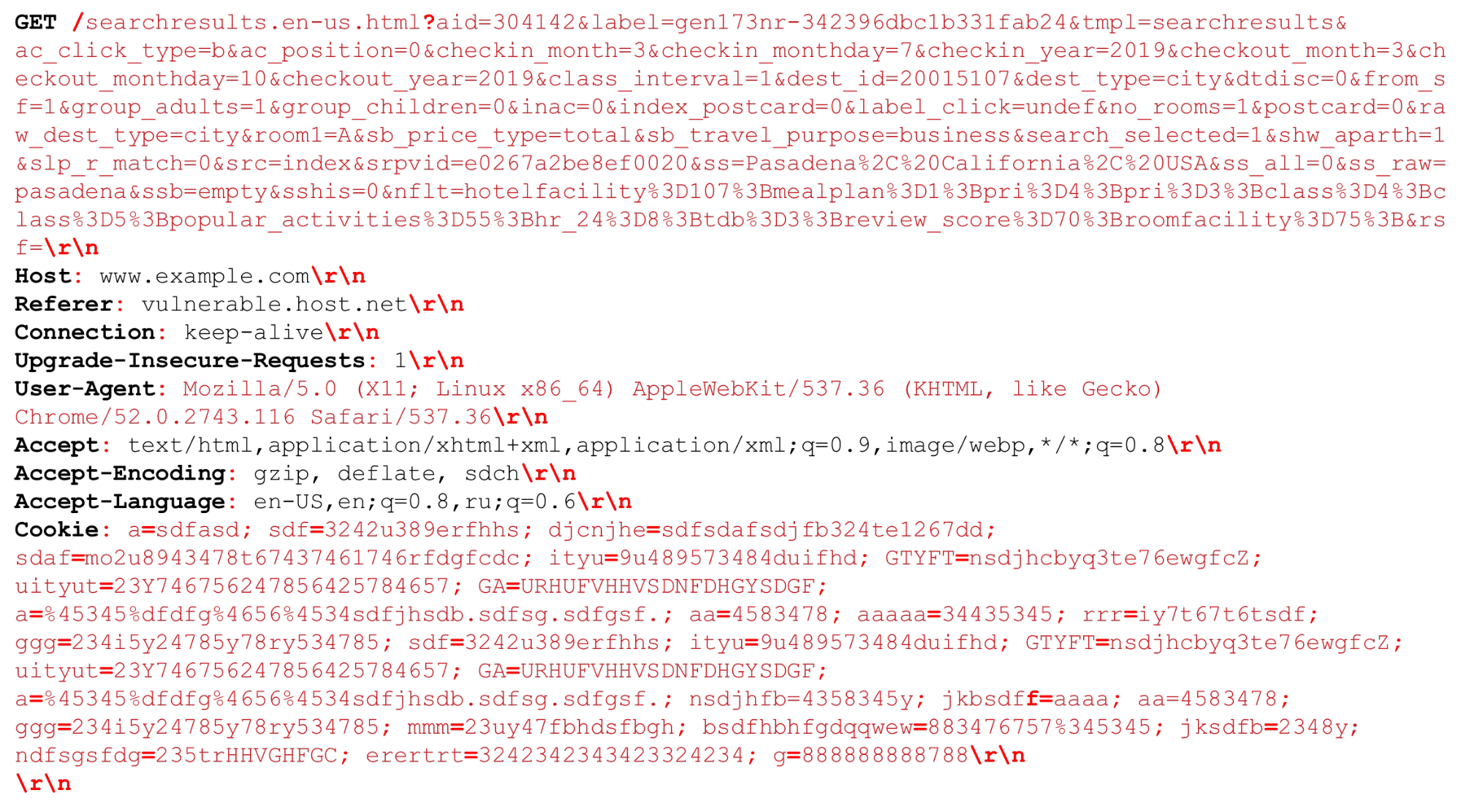 Nous pouvons avoir un URI très grand. Les séparateurs qui sont importants au moment de l'analyse HTTP sont mis en évidence en rouge gras . Je vais mettre en évidence les fonctionnalités: grandes chaînes de plusieurs kilo-octets, ainsi que différents délimiteurs, par exemple, des "points-virgules" supplémentaires que nous devons analyser, ou la séquence "\ r \ n".Un petit mot sur HTTP / 2 doit également être dit.
Nous pouvons avoir un URI très grand. Les séparateurs qui sont importants au moment de l'analyse HTTP sont mis en évidence en rouge gras . Je vais mettre en évidence les fonctionnalités: grandes chaînes de plusieurs kilo-octets, ainsi que différents délimiteurs, par exemple, des "points-virgules" supplémentaires que nous devons analyser, ou la séquence "\ r \ n".Un petit mot sur HTTP / 2 doit également être dit.Fonctionnalités HTTP / 2
HTTP / 2 est un mélange de chaînes et de données binaires . Ce mélange consiste davantage à optimiser la bande passante d'une connexion qu'à économiser les ressources du serveur.HTTP / 2 dans HPACK utilise une table dynamique . La première requête du client n'est pas optimisée, elle n'est pas dans le tableau. Vous devez l'analyser pour qu'il soit ajouté à la table. Si HTTP / 2 DDoS vient à vous, ce sera juste le cas. Dans le cas normal, HTTP / 2 est un protocole binaire, mais vous devez toujours analyser le texte: noms d'en-tête de texte, données.Encodage Huffman. Il s'agit d'un codage simple, mais Huffman est monstrueusement difficile à programmer rapidement pour la compression: le codage Huffman franchit la limite d'octets, vous ne pouvez pas utiliser d'extensions vectorielles et vous devez passer par octets. Vous ne pourrez pas traiter rapidement les données en 32 ou 16 octets.Les cookies, User-Agent, Referer, URI peuvent être très volumineux . Tout d'abord, supprimez Huffman, puis envoyez-le à un analyseur HTTP normal, comme dans HTTP / 1. Bien que cela soit autorisé par le RFC, il n'est pas recommandé de compresser les cookies, car il s'agit de données confidentielles - vous ne devez pas donner à l'attaquant des informations sur leur taille.Traitement HTTP lent . Tous les serveurs HTTP décodent d'abord HTTP / 2, puis envoient ces lignes à l'analyseur HTTP / 1 que HTTP / 1 utilise déjà.Quel est le problème avec l'analyse HTTP / 1?- Vous devez programmer rapidement la machine d'état.
- Vous devez traiter rapidement des lignes consécutives.
Le trafic malveillant cible la partie la plus lente (la plus faible) du processus. Par conséquent, si nous voulons faire un filtre, nous devons faire attention aux pièces lentes afin qu'elles fonctionnent également rapidement.Profil Nginx
Regardons le profil nginx sous le déluge HTTP. Désactivez le journal d'accès pour que le système de fichiers ne ralentisse pas. Quand même une page d'index régulière est demandée, l'analyseur monte en haut.Gauche - "Profil plat". Fait intéressant, l'endroit le plus chaud n'est pas beaucoup plus lourd que le suivant, et après cela, le profil descend en douceur. Cela signifie, par exemple, qu'optimiser deux fois la première fonction n'aidera pas à améliorer considérablement les performances. C'est pourquoi nous n'avons pas optimisé le même Nginx, mais avons fait un nouveau projet qui améliorera les performances de toute la queue du profil.Comment les analyseurs HTTP réguliers sont encodés
Habituellement, nous avons une boucle ( while) qui longe la ligne et deux variables: state ( state) et current data ( str_ptr).Nous entrons dans le cycle (1) et regardons l'état actuel (vérifier l'état). Nous passons aux données reçues (symbole 'b') et implémentons une logique. On passe au deuxième état (2). Aller à la fin
Aller à la fin switch(3) - il s'agit de la deuxième transition par rapport au début de notre code et, éventuellement, de la deuxième absence dans le cache d'instructions. Ensuite, nous allons au début while(4), mangeons le caractère suivant ... ... et recherchons à nouveau l'état dans les instructions à l'intérieur
... et recherchons à nouveau l'état dans les instructions à l'intérieur case 2:.Lorsqu'une variable a déjà reçu une statevaleur2, nous pourrions simplement passer à l'instruction suivante. Mais au lieu de cela, ils ont remonté et redescendu. Nous «coupons les cercles» par code au lieu de simplement descendre. Les analyseurs normaux ne produisent pas, par exemple, Ragel un analyseur avec des transitions directes.
Analyseur HTTP Nginx
Quelques mots sur l'analyseur nginx et son environnement.Nginx fonctionne avec l'API socket normale - les données qui vont à l'adaptateur sont copiées dans l'espace utilisateur. En conséquence, nous avons un gros morceau de données dans lequel nous recherchons ce dont nous avons besoin.Nginx utilise un algorithme qui fonctionne en deux passes: d'abord il recherche la longueur, puis il vérifie. Dans la première étape, il scanne la chaîne à la recherche de jetons, recherche le premier jeton («essai»). Sur le second, il tokens, vérifie la fin de la requête ( Get) et démarre switch, selon la taille du token.for (p = b->pos; p < b->last; p++) {
...
switch (state) {
...
case sw_method:
if (ch == ' ') {
m = r->request_start;
switch (p - m) {
case 3:
if (ngx_str3_cmp(m, 'G', 'E', 'T', ' ')) {
...
}
if ((ch < 'A' || ch > 'Z') && ch != '_' && ch != '-')
return NGX_HTTP_PARSE_INVALID_METHOD;
break;
...
«Get» est toujours dans le même bloc de données . Tempesta FW fonctionne avec zéro copie. Cela signifie que les données peuvent avoir une taille complètement arbitraire: 1 octet ou 1000 octets chacune. Ce "mécanisme" ne nous convient pas.Voyons comment cela fonctionne switchdans GCC.Gcc
Table de recherche . À gauche se trouve un exemple typique d'énumération: commencez par 0, puis des étiquettes consécutives, 26 constantes, puis du code qui traite tout cela. À droite, le code généré par le compilateur. Tout d'abord, comparez la variable
Tout d'abord, comparez la variable statedu registre EAX avec une constante. Ensuite, nous présentons toutes les étiquettes sous la forme d'un tableau séquentiel de pointeurs de 8 octets (table de correspondance). Sur cette instruction, nous transmettons le décalage dans ce tableau - c'est un double déréférencement des pointeurs. En bas à droite se trouve le code vers lequel nous sommes passés de ce tableau.Il s'avère que le déréférencement double de la mémoire: si nous avons reçu des données secrètes, alors par octets nous trouvons l'adresse dans le tableau et allons à ce pointeur. Il est important de savoir que dans la vie, c'est encore pire que dans l'exemple - pour la table de recherche, le compilateur génèrele code est plus compliqué dans le cas d'un script pour une attaque Spectre.Recherche binaire . Le cas suivant n'est switchpas avec des constantes séquentielles, mais avec des constantes arbitraires. Le code est le même, mais maintenant GCC ne peut pas compiler un si grand tableau et utiliser des constantes comme index du tableau. Il passe à la recherche binaire. Sur la droite, nous voyons une comparaison séquentielle, le passage à l'adresse et la poursuite de la comparaison - la recherche binaire se fait par code.Analyseur HTTP Nginx. Voyons ce qu'est la machine à états nginx. Il a 9 kilo-octets de code - c'est trois fois moins que le cache de premier niveau sur la machine sur laquelle les tests ont été lancés (comme sur la plupart des processeurs x86-64).
Sur la droite, nous voyons une comparaison séquentielle, le passage à l'adresse et la poursuite de la comparaison - la recherche binaire se fait par code.Analyseur HTTP Nginx. Voyons ce qu'est la machine à états nginx. Il a 9 kilo-octets de code - c'est trois fois moins que le cache de premier niveau sur la machine sur laquelle les tests ont été lancés (comme sur la plupart des processeurs x86-64).$ nm -S /opt/nginx-1.11.5/sbin/nginx
| grep http_parse | cut -d' ' -f 2
| perl -le '$a += hex($_) while (<>); print $a'
9220
$ getconf LEVEL1_ICACHE_SIZE
32768
$ grep -c 'case sw_' src/http/ngx_http_parse.c
84
L'analyseur d'en-tête nginx ngx_http_parse_header_line ()est un simple tokenizer. Il ne fait rien avec les valeurs des en-têtes et leurs noms, mais met simplement les jetons des en-têtes HTTP dans un hachage. Si vous avez besoin d'une valeur d'en-tête, scannez le tableau d'en-tête et répétez l'analyse.Nous devons vérifier strictement les noms et les valeurs des en-têtes pour des raisons de sécurité .Tempesta FW: validation de chaîne de chaînes HTTP
Notre machine d'état est d'un ordre de grandeur plus puissant: nous faisons la validation d'en-tête RFC et immédiatement, dans l'analyseur, nous traitons presque tout. Si nginx a 80 états, alors nous en avons 520, et il y en a plus. Si nous continuions switch, ce serait 10 fois plus grand.Nous avons des E / S sans copie - des morceaux de différentes tailles peuvent couper des données à différents endroits. différents morceaux peuvent couper nos données. Dans les E / S à copie nulle, par exemple, «GET» peut (rarement) apparaître comme «GET», «GE» et «T» ou «G», «E» et «T», vous devez donc stocker l'état entre les éléments de données . Nous supprimons pratiquement les coûts d'E / S, mais dans le profil, cela vole - tout va mal. Le grand analyseur HTTP est l'un des endroits les plus critiques du projet.$ grep -c '__FSM_STATE\|__FSM_TX\|__FSM_METH_MOVE\|__TFW_HTTP_PARSE_' http_parser.c
520
7.64% [tempesta_fw] [k] tfw_http_parse_req
2.79% [e1000] [k] e1000_xmit_frame
2.32% [tempesta_fw] [k] __tfw_strspn_simd
2.31% [tempesta_fw] [k] __tfw_http_msg_add_str_data
1.60% [tempesta_fw] [k] __new_pgfrag
1.58% [kernel] [k] skb_release_data
1.55% [tempesta_fw] [k] __str_grow_tree
1.41% [kernel] [k] __inet_lookup_established
1.35% [tempesta_fw] [k] tfw_cache_do_action
1.35% [tempesta_fw] [k] __tfw_strcmpspn
Que faire pour améliorer cette situation?Parrainages directs FSM
La première chose que nous faisons n'est pas d'utiliser une boucle, mais des transitions directes par labels ( go to) . Les générateurs d'analyseurs normaux comme Ragel le font. Nous codons chacun de nos états avec une étiquette en
Nous codons chacun de nos états avec une étiquette en switchet une étiquette en C avec le même nom . Chaque fois que nous voulons y aller, nous trouvons une étiquette switchou accédons au même état directement à partir du code. La première fois que nous traversons switch, puis à l'intérieur, nous allons directement à l'étiquette souhaitée.Inconvénient : lorsque nous voulons passer à l'état suivant, nous devons immédiatement évaluer si nous avons encore des données disponibles (car des E / S à copie nulle). Conditionner le corpsforIl est copié dans chaque état: au lieu d'une condition dans un FSM standard avec interrupteur, nous en avons 500 selon le nombre d'états. Générer du code pour chaque état n'est pas génial.Dans le cas de grandes machines d'état, car foravec un grand switchintérieur, GTC répète également la condition forplusieurs fois dans le code.Remplacez par switchdes transitions directes. L'optimisation suivante consiste à ne pas l'utiliser switchet à basculer pour diriger les sauts vers les méta-adresses enregistrées. Nous voulons aller immédiatement au point souhaité dès que nous entrons dans la fonction. GCC vous permet de le faire. GCC a une extension standard qui peut vous aider. Nous prenons le nom de l'étiquette (le voici
GCC a une extension standard qui peut vous aider. Nous prenons le nom de l'étiquette (le voici from) et attribuons son adresse à une variable C via une double esperluette (&&). Maintenant, nous pouvons faire une instruction de saut directjmpà l'adresse de cette étiquette avec goto.Voyons ce qui en sort.Performances de conversion directe
Sur un petit nombre d'états, le générateur de code de transition directe est même un peu plus lent que la normale switch. Mais pour les grandes machines d'état, la productivité double. Si la machine d'état est petite, il vaut mieux utiliser celle habituelle switch.$ grep -m 2 'model name\|bugs' /proc/cpuinfo
model name : Intel(R) Core(TM) i7-6500U CPU @ 2.50GHz
bugs : cpu_meltdown spectre_v1 spectre_v2 spec_store_bypass l1tf
$ gcc --version|head -1
gcc (GCC) 8.2.1 20181105 (Red Hat 8.2.1-5)
States Switch-driven automaton Goto-driven automaton
7 header_line: 139ms header_line: 156ms
27 request_line: 210ms request_line: 186ms
406 big_header_line: 1406ms goto_big_header_line: 727ms
Remarque: le code Tempesta est plus compliqué que les exemples. GitHub a toutes les références afin que vous puissiez tout voir en détail. Le code de l'analyseur d'origine est disponible sur le lien (analyseur HTTP principal). En plus de cela, dans Tempesta FW, il y a des analyseurs plus petits qui utilisent FSM plus facilement.Pourquoi les transitions directes peuvent être plus lentes
Dans la machine d'état, nous passons par beaucoup de code, donc (attendu) il y aura beaucoup de mauvaises prédictions de branche. Réalisons le «profilage» en fonction de la prédiction des ratés de branchement:perf record -e branch-misses -g ./http_benchmark
406 states: switch - 38% on switch(),
direct jumps - 13% on header value parsing
7,27 states: switch - <18% switch(), up to 40% for()
direct jumps – up to 46% on header & URI parsing
Sur une grande machine d'état avec 406 états, nous passons 38% du temps à traiter les transitions switch. Sur une machine à états avec des transitions directes, les hotspots sont une analyse de ligne. L'analyse d'une chaîne dans chaque état comprend la vérification de la condition de fin de chaîne: la condition fordans la machine d'état activée switch.perf stat -e L1-icache-load-misses ./http_benchmark
Switch-driven automaton Goto-driven automaton
big FSM code size: 29156 49202
L1-icache-load-misses: 4M 2M
Ensuite, examinons le profilage des deux types de machine d'état par les événements du cache d'instructions L1 manqués - près de 30 kilo-octets pour switchet 50 kilo-octets pour les sauts directs (plus que le cache des instructions de premier niveau).Il semble que si nous ne rentrons pas dans le cache, il devrait y avoir beaucoup de ratés de cache pour une telle machine d'état. Mais non, ils sont 2 fois moins. C'est parce que le cache fonctionne mieux: nous travaillons avec le code de manière séquentielle et réussissons à extraire les données des anciens caches.Le compilateur change l'ordre du code
Lorsque nous programmons le code de la machine à états go to, nous avons d'abord les états qui seront appelés en premier lors de la réception des données: la méthode HTTP, l'URI, puis les en-têtes HTTP. Il semble logique que le code soit chargé dans le cache du processeur de manière séquentielle, de haut en bas, tout comme nous parcourons les données. Mais c'est complètement faux. Si vous regardez le code assembleur, vous verrez des choses incroyables. À gauche se trouve ce que nous avons programmé: nous analysons d'abord les méthodes
À gauche se trouve ce que nous avons programmé: nous analysons d'abord les méthodes GET, POSTpuis quelque part bien en dessous de la méthode improbable UNLOCK. Par conséquent, nous nous attendons à voir l'analyse GETet au début de l'assembleur POST, puis UNLOCK. Mais tout est tout à fait le contraire: GETau milieu, POSTà la fin et UNLOCKau - dessus.En effet, le compilateur ne comprend pas comment les données nous parviennent. Il distribue le code selon sa photo de beau code. Pour qu'il puisse organiser le code dans le bon ordre, nous devons utiliser la barrière du compilateur .La barrière du compilateur est un mannequin d'assemblage par lequel le compilateur ne se réordonnera pas. En plaçant simplement ces barrières, nous avons amélioré la productivité de 4% .STATE(sw_method) {
...
MATCH(NGX_HTTP_GET, "GET ");
MATCH(NGX_HTTP_POST, "POST");
__asm__ __volatile__("": : :"memory");
...
METH_MOVE(Req_MethU, 'N', Req_MethUn);
METH_MOVE(Req_MethUn, 'L', Req_MethUnl);
METH_MOVE(Req_MethUnl, 'O', Req_MethUnlo);
METH_MOVE(Req_MethUnlo, 'C', Req_MethUnloc);
METH_MOVE_finish(Req_MethUnloc, 'K', NGX_HTTP_UNLOCK)
Composez le code à votre façon
Puisque le compilateur n'organise pas les données comme nous le voulons, nous ferons une optimisation guidée par le profileur (optimisation sous le contrôle du profileur). L'optimisation guidée par le profileur (PGO) est le nombre total d'échantillons, pas une séquence d'appels. Par exemple, un URI reçoit plus d'échantillons qu'une analyse de méthode, il positionnera donc le code de traitement URI avant de traiter la méthode.Comment ça fonctionne? Nous allons écrire le code, exécuter les benchmarks dessus, donner le résultat du profilage au compilateur, et il générera le code optimal pour nos charges. Mais le problème est qu'il compile simplement les sections de code les plus chaudes, mais ne suit pas la dépendance temporelle. Si le plus grand URI de la charge, ce sera l'endroit le plus chaud. L'URI montera en haut de la fonction et PGO ne montrera pas que le nom de la méthode est toujours avant l'URI. Par conséquent, PGO ne fonctionne pas.Req_Method: {
if (likely(PI(p) == CHAR4_INT('G', 'E', 'T', ' '))) {
...
goto Req_Uri;
}
if (likely(PI(p) == CHAR4_INT('P', 'O', 'S', 'T'))) {
...
goto Req_UriSpace;
}
goto Req_Meth_SlowPath;
}
...
Req_Uri:
...
Req_Meth_SlowPath:
...
Qu'est-ce qui fonctionne?likely/ unlikely macros (pour le code du noyau Linux, les intrinsèques GCC sont disponibles dans l'espace utilisateur __builtin_expect()). Ils disent quel code placer plus près. Par exemple, il est probable que le corps de la demande devrait être immédiatement derrière if. Ensuite, la prélecture du code (la prélecture du processeur) sélectionnera ce code et tout sera rapide. L'image montre le début de la méthode d'analyse, la fin et la barrière. Nous ne nous attendions pas à voir le code derrière la barrière. Il semble que cela ne devrait pas être le cas - nous avons érigé une barrière.Mais que se passe-t-il en réalité? Le compilateur voit la
L'image montre le début de la méthode d'analyse, la fin et la barrière. Nous ne nous attendions pas à voir le code derrière la barrière. Il semble que cela ne devrait pas être le cas - nous avons érigé une barrière.Mais que se passe-t-il en réalité? Le compilateur voit la likelycondition - il est très probable que nous entrions dans le corps de la condition et là nous basculerons vers un saut inconditionnel vers l'étiquetteReq_Uri. Il s'avère que le code qui se trouve après notre condition n'est pas traité dans le "hot path". Le compilateur déplace le code sous l'étiquette derrière if, malgré la barrière, car la condition de code actif est remplie.Pour ce n'était pas le cas, GCC a une extension: les attributs hotet coldles étiquettes. Ils disent quelle étiquette est chaude (le plus probable) et laquelle est froide (le moins probable). Ici, nous convenons de ce qui est le
Ici, nous convenons de ce qui est le GETplus probable POSTet nous le laissons likely. Sous cette condition, le traitement URI augmente et POSTdescend en dessous. Tous les autres codes de la machine d'état la moins probable restent en dessous car l'étiquette est froide.Ambigu -O3
Regardons l'optimisation du compilateur. La première chose qui vient à l'esprit est d'utiliser non pas O2, mais O3 - cela devrait être plus rapide. Mais ce n'est pas le cas - O3 génère parfois un code pire. O3 est une collection de quelques optimisations . Si nous les ajoutons à O2 séparément, nous obtenons différentes options: certaines optimisations aident, d'autres interfèrent. Pour notre code spécifique, nous sélectionnons uniquement les optimisations qui génèrent mieux le code. Nous laissons le meilleur résultat - voici 1 820 secondes par rapport à 1 838 et 1 858.Certaines options sont surlignées en vert - il s'agit de la vectorisation automatique.
O3 est une collection de quelques optimisations . Si nous les ajoutons à O2 séparément, nous obtenons différentes options: certaines optimisations aident, d'autres interfèrent. Pour notre code spécifique, nous sélectionnons uniquement les optimisations qui génèrent mieux le code. Nous laissons le meilleur résultat - voici 1 820 secondes par rapport à 1 838 et 1 858.Certaines options sont surlignées en vert - il s'agit de la vectorisation automatique.Autovectorisation
Un exemple de cycle du guide GCC .int a[256], b[256], c[256];
void foo () {
for (int i = 0; i < 256; i++)
a[i] = b[i] + c[i];
}
Si nous avons un tableau variable qui se répète, nous pouvons optimiser le cycle - décomposer en vecteurs. Par défaut, l'auto- vectorisation est activée au troisième niveau d'optimisation -O3 : GCC génère du code vectoriel là où il le peut. Mais tout le code ne peut pas être vectorisé automatiquement (même s'il est vectorisé en principe).Nous pouvons activer l'option GCC -fopt-info-vec-all, qui montre ce qui a été vectorisé et ce qui ne l'est pas. Nous obtenons que pour notre benchmark, rien n'est vectorisé, mais le code est toujours généré pire. Par conséquent, la vectorisation ne fonctionne pas toujours: elle ralentit parfois le code. Mais nous pouvons toujours voir ce qui a été vectorisé et ce qui ne l'est pas, et désactiver la vectorisation, si nécessaire.Alignement: comment comparer une chaîne avec GET?
Nous faisons un petit hack, comme dans nginx: nous n'analysons pas les lignes par octets, mais calculons intet comparons les lignes avec elles.#define CHAR4_INT(a, b, c, d) ((d << 24) | (c << 16) | (b << 8) | a)
if (p == CHAR4_INT('G', 'E', 'T', ' ')))
Nous savons que s'il n'est intpas aligné, il ralentit 2-3 fois. Nous avons écrit une petite référence qui le prouve.$ ./int_align
Unaligned access = 6.20482
Aligned access = 2.87012
Read four bytes = 2.45249
Essayez ensuite de vous aligner int. Nous allons regarder, si l'adresse est intalignée, puis comparer par int, sinon, octets. (((long)(p) & 3)
? ((unsigned int)((p)[0]) | ((unsigned int)((p)[1]) << 8)
| ((unsigned int)((p)[2]) << 16) | ((unsigned int)((p)[3]) << 24))
: *(unsigned int *)(p));
Mais il s'avère que cette approche fonctionne moins bien:full request line: no difference
method only: unaligned - 214ms
aligned - 231ms
bytes - 216ms
En bref: il existe une différence entre le code de référence isolé, non optimisable, et le code de l'analyseur en ligne, qui perd son optimisation en raison de la grande quantité de code. Il n'y avait aucune pénalité dans le profilage.Remarque: une discussion détaillée des raisons pour lesquelles cela se produit dans notre tâche peut être lue sur GitHub .Pourquoi les chaînes HTTP sont-elles importantes pour nous?
Par exemple, il s'agit d'un URI normal: si vous êtes assez pointilleux sur l'hôtel, allez dans Réservation et définissez des filtres, obtenez un URI de plus d'un kilo-octet.Nginx a une machine d'analyse assez massive sur
si vous êtes assez pointilleux sur l'hôtel, allez dans Réservation et définissez des filtres, obtenez un URI de plus d'un kilo-octet.Nginx a une machine d'analyse assez massive sur switch/ case. Ça ne marche pas très vite. De plus, dans le cas de Tempesta FW, nous devons non seulement analyser l'URI, mais également le vérifier pour les injections.case sw_check_uri:
if (usual[ch >> 5] & (1U << (ch & 0x1f)))
break;
switch (ch) {
case '/':
r->uri_ext = NULL;
state = sw_after_slash_in_uri;
break;
case '.':
r->uri_ext = p + 1;
break;
case ' ':
r->uri_end = p;
state = sw_check_uri_http_09;
break;
case CR:
r->uri_end = p;
r->http_minor = 9;
state = sw_almost_done;
break;
case LF:
r->uri_end = p;
r->http_minor = 9;
goto done;
case '%':
r->quoted_uri = 1;
...
Un autre URI: /redir_lang.jsp?lang=foobar%0d%0aContent-Length:%200%0d%0a% 0d% 0aHTTP / 1.1% 20200% 20OK% 0d% 0aContent-Type:% 20text /html% 0d% 0aContent -Longueur:% 2019% 0d% 0a% 0d% 0aShazam </html>.Il ressemble au premier, mais il a une injection. Vous devrez creuser suffisamment pour comprendre cela. Lançonsun test : prenez le premier URI, alimentez wrk, réglez-le sur nginx et voyez que l'analyse de nginx devient très chaude. Si lors de la précédente requête d'index standard, il était clair que l'analyseur est déjà en haut, il devient encore plus chaud.
Si lors de la précédente requête d'index standard, il était clair que l'analyseur est déjà en haut, il devient encore plus chaud.8.62% nginx [.] ngx_http_parse_request_line
2.52% nginx [.] ngx_http_parse_header_line
1.42% nginx [.] ngx_palloc
0.90% [kernel] [k] copy_user_enhanced_fast_string
0.85% nginx [.] ngx_strstrn
0.78% libc-2.24.so [.] _int_malloc
0.69% nginx [.] ngx_hash_find
0.66% [kernel] [k] tcp_recvmsg
Quelle est la particularité des chaînes HTTP? Il existe différents séparateurs ' : 'et ' , ', et même la fin des lignes, qui peuvent être à deux octets \r\nou à un octet \n, ce qui a été discuté au début. Il n'y a pas de terminaison 0 des lignes C - pour des raisons de sécurité, nous voulons vérifier plus précisément ce qui nous arrive. Nous avons deux fonctions standard qui aident dans l'analyseur.strspn: vérifie l'alphabet, les caractères disponibles dans une chaîne, compile dynamiquement un alphabet valide, bien qu'il soit connu au stade de la compilation du programme.strcasecmp(). Il n'y a pas besoin de convertir cas de comparer xavec Foo:. Dans la plupart des cas strcasecmp(), seule la conformité / non-conformité est requise pour , et vous n'avez pas besoin de connaître la position dans la ligne.
Ils travaillent lentement. Voyons les repères et comprenons ce qui ne va pas avec eux.Analyseurs rapides
Il y a plusieurs analyseurs.Nginx est l'analyseur le plus simple, l'analyseur. Il vérifie strictement la conformité RFC. Il existe également des analyseurs PicoHTTPParser (H2O) et Cloudflare. Ils traitent les données plus rapidement, mais peuvent ignorer les caractères qui ne sont pas autorisés par le RFC.PCMESTRI. Les analyseurs utilisent plusieurs approches différentes. La première est l'instruction PCMESTRI, qui est utilisée dans l'analyseur Pico.Nous définissons des plages dans les instructions. Malheureusement, nous pouvons charger 16 caractères ou 8 plages. Si la plage se compose d'un seul caractère - répétez simplement. En raison de cette limitation, l'analyseur Pico ne peut pas entièrement vérifier la conformité RFC, car le RFC a plus de 8 plages à cet emplacement. Nous chargeons l'alphabet dans le registre, chargeons la chaîne, exécutons l'instruction. A la sortie, on voit rapidement s'il y a une coïncidence ou non.AVX2 - Approche CloudFlare. L'analyseur CloudFlare, utilisant AVX2, traite 32 octets d'une chaîne à la fois, au lieu de 16 octets avec un analyseur Pico. L'analyse est meilleure dans CloudFlare car elle a été transférée vers AVX2.
Nous chargeons l'alphabet dans le registre, chargeons la chaîne, exécutons l'instruction. A la sortie, on voit rapidement s'il y a une coïncidence ou non.AVX2 - Approche CloudFlare. L'analyseur CloudFlare, utilisant AVX2, traite 32 octets d'une chaîne à la fois, au lieu de 16 octets avec un analyseur Pico. L'analyse est meilleure dans CloudFlare car elle a été transférée vers AVX2. Nous vérifions tous les caractères dans un espace de la table ASCII, tous les caractères sont supérieurs à 128 et prenons la plage entre eux. Le code simple est rapide.Comparez PCMESTRI et AVX2. Pour nous, la limite actuelle est de 1500. Il s'agit de la taille maximale du colis qui nous vient. Nous voyons que le code AVX2 sur les mégadonnées est beaucoup plus rapide que l'analyseur Pico. Mais cela fonctionne plus lentement sur les petites données, car les instructions sont plus lourdes dans AVX2.
Nous vérifions tous les caractères dans un espace de la table ASCII, tous les caractères sont supérieurs à 128 et prenons la plage entre eux. Le code simple est rapide.Comparez PCMESTRI et AVX2. Pour nous, la limite actuelle est de 1500. Il s'agit de la taille maximale du colis qui nous vient. Nous voyons que le code AVX2 sur les mégadonnées est beaucoup plus rapide que l'analyseur Pico. Mais cela fonctionne plus lentement sur les petites données, car les instructions sont plus lourdes dans AVX2. Comparable à
Comparable àstrspn. Si nous décidons d'utiliser strspn, les choses empirent, en particulier sur les mégadonnées. Dans l'analyseur "combat" ne peut pas être utilisé strspn.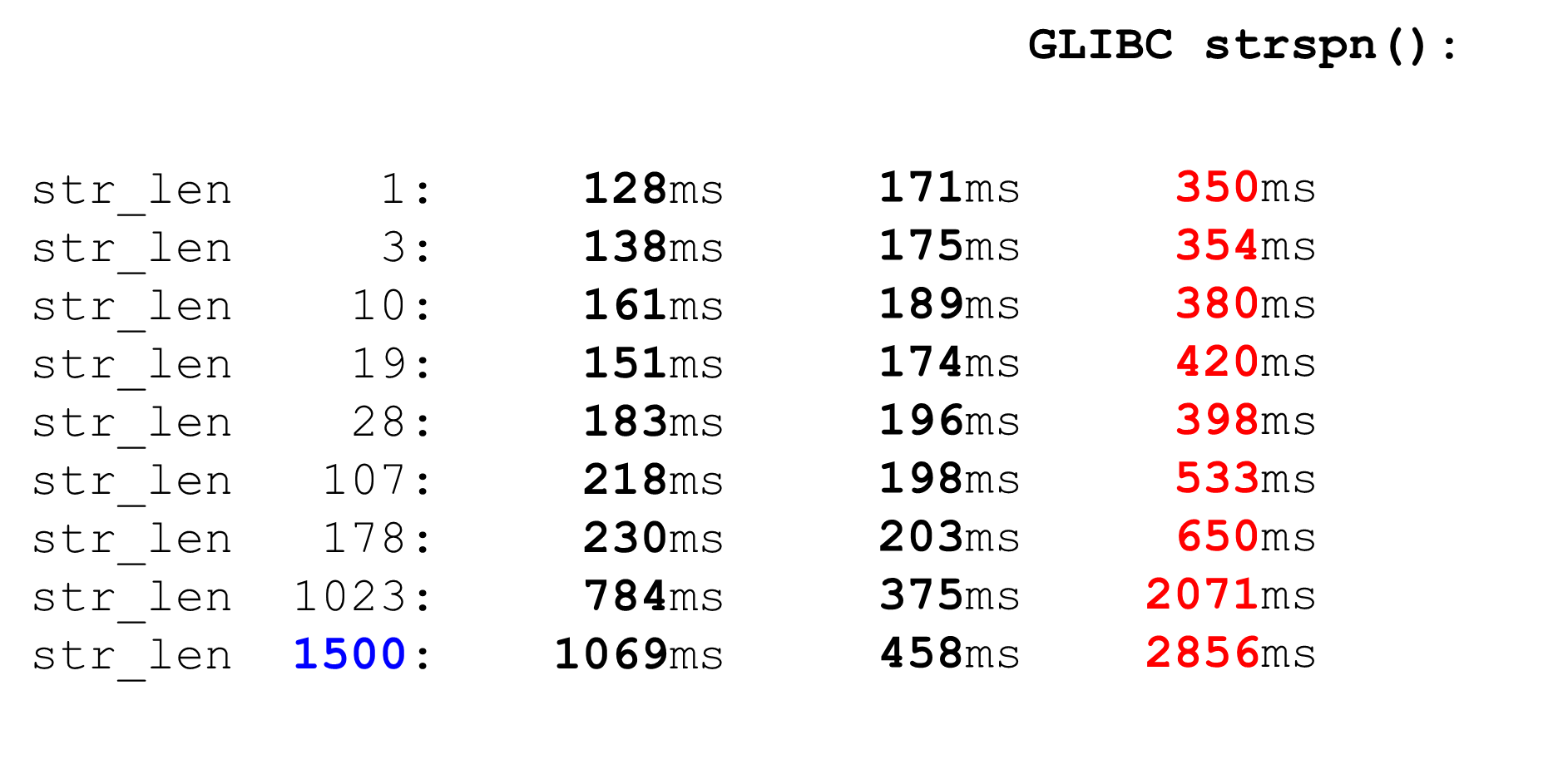
L'allumeur Tempesta est plus rapide et plus précis
Notre analyseur de vitesse est comme ces deux-là. Sur les petites données, il est aussi rapide qu'un analyseur Pico, sur les gros comme CloudFlare. Cependant, il n'ignore pas les caractères non valides. Comment l'analyseur est-il organisé? Nous, en tant que nginx, définissons un tableau d'octets et vérifions les données d'entrée par celui-ci - c'est le prologue de la fonction. Ici, nous ne travaillons qu'avec des termes courts, nous l'utilisons
Comment l'analyseur est-il organisé? Nous, en tant que nginx, définissons un tableau d'octets et vérifions les données d'entrée par celui-ci - c'est le prologue de la fonction. Ici, nous ne travaillons qu'avec des termes courts, nous l'utilisons likelycar une mauvaise prédiction de branche est plus douloureuse pour les lignes courtes que pour les lignes longues. Nous reprenons ce code. Nous avons une limite de 4 à cause de la dernière ligne - nous devons écrire une condition assez puissante. Si nous traitons plus de 4 octets, la condition sera plus difficile et le code plus lent.static const unsigned char uri_a[] __attribute__((aligned(64))) = {
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 1, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
...
if (likely(len <= 4)) {
switch (len) {
case 0:
return 0;
case 4:
c3 = uri_a[s[3]];
case 3:
c2 = uri_a[s[2]];
case 2:
c1 = uri_a[s[1]];
case 1:
c0 = uri_a[s[0]];
}
return (c0 & c1) == 0 ? c0 : 2 + (c2 ? c2 + c3 : 0);
}
Boucle principale et grande queue. Dans le cycle de traitement principal, nous divisons les données: si elles sont suffisamment longues, nous traitons 128, 64, 32 ou 16 octets chacune. Il est logique de traiter 128 chacun: en parallèle, nous utilisons plusieurs canaux de processeur (plusieurs pipelines) et un processeur superscalaire.for ( ; unlikely(s + 128 <= end); s += 128) {
n = match_symbols_mask128_c(__C.URI_BM, s);
if (n < 128)
return s - (unsigned char *)str + n;
}
if (unlikely(s + 64 <= end)) {
n = match_symbols_mask64_c(__C.URI_BM, s);
if (n < 64)
return s - (unsigned char *)str + n;
s += 64;
}
if (unlikely(s + 32 <= end)) {
n = match_symbols_mask32_c(__C.URI_BM, s);
if (n < 32)
return s - (unsigned char *)str + n;
s += 32;
}
if (unlikely(s + 16 <= end)) {
n = match_symbols_mask16_c(__C.URI_BM128, s);
if (n < 16)
return s - (unsigned char *)str + n;
s += 16;
}
Queue. La fin de la fonction est similaire au début. Si nous avons moins de 16 octets, nous traitons 4 octets en boucle, puis pas plus de 3 octets à la fin.while (s + 4 <= end) {
c0 = uri_a[s[0]];
c1 = uri_a[s[1]];
c2 = uri_a[s[2]];
c3 = uri_a[s[3]];
if (!(c0 & c1 & c2 & c3)) {
n = s - (unsigned char *)str;
return !(c0 & c1) ? n + c0 : n + 2 + (c2 ? c2 + c3 : 0);
}
s += 4;
}
c0 = c1 = c2 = 0;
switch (end - s) {
case 3:
c2 = uri_a[s[2]];
case 2:
c1 = uri_a[s[1]];
case 1:
c0 = uri_a[s[0]];
}
n = s - (unsigned char *)str;
return !(c0 & c1) ? n + c0 : n + 2 + c2;
Nous chargeons des masques de bits et des données - c'est l'algorithme principal du corps principal de la fonction. Nous présentons un tableau ASCII (comme dans l'image) avec 16 lignes et 8 colonnes. Tout d'abord, nous codons nos lignes de table dans le premier registre de BM URI: la première et la deuxième ligne.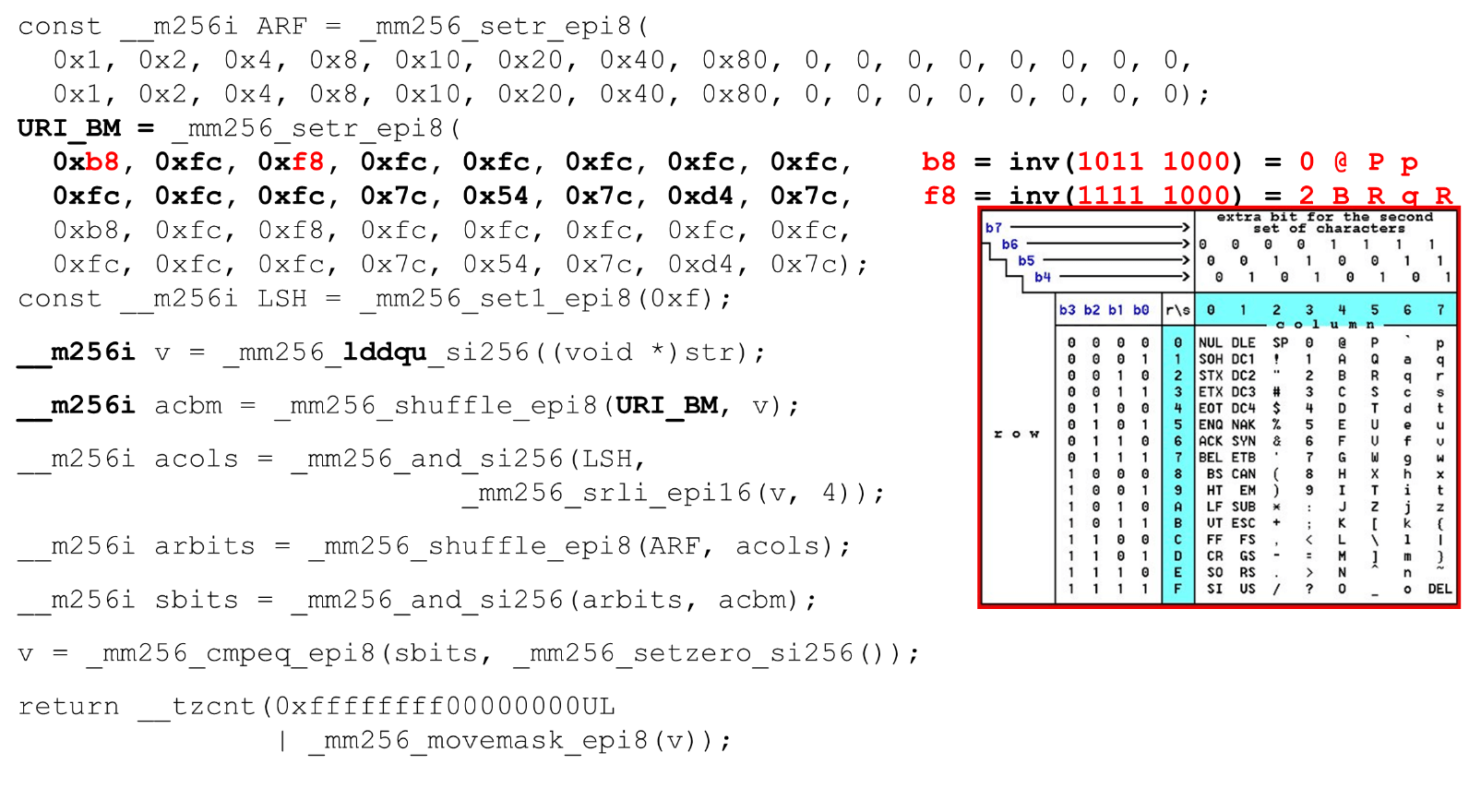 Les symboles réels que nous autorisons sont
Les symboles réels que nous autorisons sont 0 @ P pet 2 B R q R. Ils sont codés comme suit: b8 = inv(1011 1000) = 0 @ P p, f8 = inv(1111 1000) = 2 B R q R.Nous encodons dans l'ordre inverse: nous commençons à 0, le premier caractère de service n'est pas autorisé, puis les unités sont ce qui est autorisé.Définissez les masques de bits ASCII. Par exemple, une ligne entre "pr": le premier caractère de la première ligne est ASCII, le second de la deuxième ligne. Nous exécutons l'instruction shuffle, qui mélange nos lignes de table codées conformément à l'ordre de ces caractères dans l'entrée. ID de colonne pour l'entrée. Ensuite, nous plaçons les colonnes de la table ASCII dans un registre différent. Ensuite, nous «croisons» les registres de colonnes et de lignes, et nous obtenons une correspondance: notre caractère ou non.Comme les colonnes sont les 4 bits les plus significatifs de l'octet, nous nous déplaçons vers la gauche. AVX a un décalage de seulement 2 octets, donc déplacez d'abord l'octet, puis n avec notre masque pour obtenir uniquement des bits significatifs.
ID de colonne pour l'entrée. Ensuite, nous plaçons les colonnes de la table ASCII dans un registre différent. Ensuite, nous «croisons» les registres de colonnes et de lignes, et nous obtenons une correspondance: notre caractère ou non.Comme les colonnes sont les 4 bits les plus significatifs de l'octet, nous nous déplaçons vers la gauche. AVX a un décalage de seulement 2 octets, donc déplacez d'abord l'octet, puis n avec notre masque pour obtenir uniquement des bits significatifs. Disposition des colonnes ASCII Exécutez le deuxième mélange, déplacez la colonne vers les positions souhaitées. Dans les deux cas, l'octet d'entrée de la dernière colonne, donc dans la première et la deuxième position, nous obtenons la même colonne.
Disposition des colonnes ASCII Exécutez le deuxième mélange, déplacez la colonne vers les positions souhaitées. Dans les deux cas, l'octet d'entrée de la dernière colonne, donc dans la première et la deuxième position, nous obtenons la même colonne.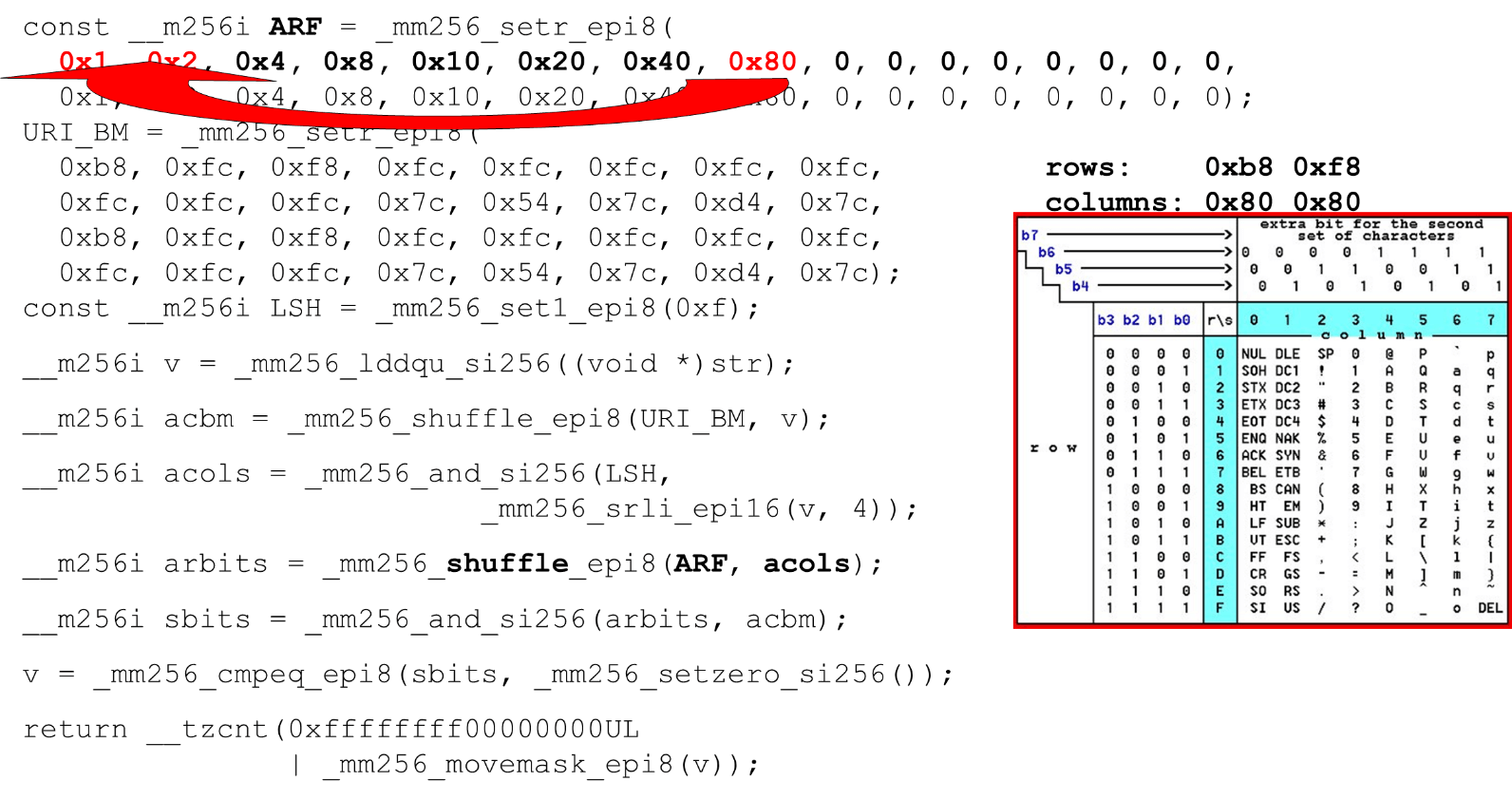 Intersection de colonnes et de rangées de masques . Nous faisons
Intersection de colonnes et de rangées de masques . Nous faisons and(«croiser» les colonnes avec des colonnes) et nous obtenons que les données d'entrée sont valides - le résultatandde l'intersection des colonnes et des lignes n'est pas zéro. Comptez le nombre de zéros à la fin. Nous collectons tout cela à partir du vecteur
Comptez le nombre de zéros à la fin. Nous collectons tout cela à partir du vecteur intet le renvoyons à la sortie - tout simplement.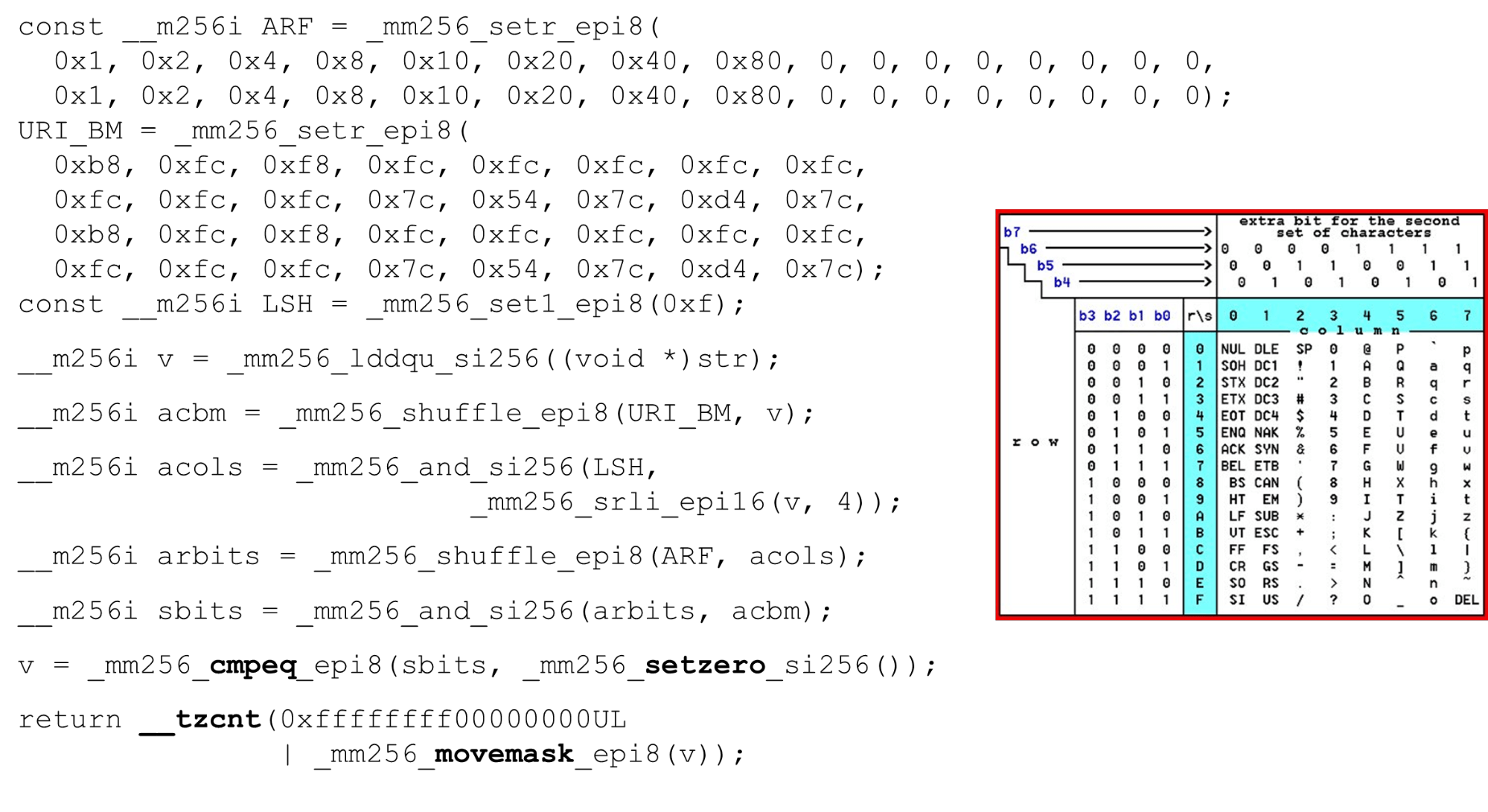 Personnalisez les alphabets. En travaillant avec la table ASCII, nous obtenons une fonctionnalité bon marché: nous utilisons des tables statiques, mais rien ne nous empêche de demander à l'utilisateur quel alphabet est disponible pour les URI, les noms et les valeurs des différents en-têtes. La demande d'URI HTTP et l'en-tête utilisent 8 alphabets (plus ou moins) pour analyser une demande HTTP. Ces tables peuvent être chargées dans le même code et comparées dans un seul alphabet spécifié par l'utilisateur, un URI valide. Sinon, c'est différent.
Personnalisez les alphabets. En travaillant avec la table ASCII, nous obtenons une fonctionnalité bon marché: nous utilisons des tables statiques, mais rien ne nous empêche de demander à l'utilisateur quel alphabet est disponible pour les URI, les noms et les valeurs des différents en-têtes. La demande d'URI HTTP et l'en-tête utilisent 8 alphabets (plus ou moins) pour analyser une demande HTTP. Ces tables peuvent être chargées dans le même code et comparées dans un seul alphabet spécifié par l'utilisateur, un URI valide. Sinon, c'est différent.Attaques
Quelques cas où cela peut être utile.Attaque SSRF avec BlackHat'17 («Une nouvelle ère de SSRF»): http://foo@evil.com:80@google.com/- un symbole esperluette improbable. Dans certaines applications, il est utilisé, dans d'autres non. Mais si vous ne l'utilisez pas, vous pouvez l'exclure de l'alphabet valide et l'attaque sera bloquée.-Attaque RCE: «efficace est l'effectuer des attaques par injection de commandes comme», BSides'16: User-Agent: ...;echo NAELBD$((26+58))$echo(echo NAELBD)NAELBD.... L'agent utilisateur est un en-tête statique, mais il existe des cas d'attaque RCE lorsque certains sont livrés shellavec des caractères atypiques pour l'agent utilisateur. Nous nous protégeons sauf pour le signe dollar.Écrasement du chemin relatif . Le dernier cas est celui de Google en 2016. Des accolades, des deux points, sont venus à l'URI .../gallery?q=%0a{}*{background:red}/..//apis/howto_guide.html. Ce sont des caractères improbables qui peuvent être exclus de l'alphabet.strcasecmp ()
Ceci est un code assez trivial. Nous comparons également des chaînes de 32 octets, deux tableaux chacune.__m256i CASE = _mm256_set1_epi8(0x20);
__m256i A = _mm256_set1_epi8('A' – 0x80);
__m256i D = _mm256_set1_epi8('Z' - 'A' + 1 – 0x80);
__m256i sub = _mm256_sub_epi8(str1, A);
__m256i cmp_r = _mm256_cmpgt_epi8(D, sub);
__m256i lc = _mm256_and_si256(cmp_r, CASE);
__m256i vl = _mm256_or_si256(str1, lc);
__m256i eq = _mm256_cmpeq_epi8(vl, str2);
return ~_mm256_movemask_epi8(eq);
Nous ne donnons au registre qu'une seule ligne, car dans la seconde nous avons programmé les constantes dans notre analyseur en minuscules. Puisque nous avons des comparaisons significatives, nous soustrayons 128 de chaque octet (une astuce de Hacker's Delight).Nous comparons également la plage d'un caractère valide: que nous puissions nous inscrire pour cette chaîne ou non, est-ce une lettre ou non. Au moment de vérifier cela, au lieu de deux comparaisons de a à z, nous pouvons utiliser une seule comparaison (une astuce de Hacker's Delight) et passer à une constante.Performances strcasecmp ()
Tempesta est beaucoup plus rapide que GLIBC, même la nouvelle version (18 ou 19). Le code strcasecmp()utilise également AVX, mais pas la deuxième version. AVX2 est plus rapide, donc Tempesta a un code plus rapide.
FPU du noyau Linux
Nous utilisons des extensions de processeur vectoriel - elles sont disponibles dans le noyau. Les instructions vectorielles sont traitées par le module processeur FPU. Ce n'est pas le module processeur principal, pas les registres principaux, mais assez volumineux.Par conséquent, il existe une optimisation sous Linux. Si nous passons du noyau à l'espace utilisateur et vice-versa, nous ne sauvegardons pas le contexte des registres FPU (XMM, YMM, ZMM): nous changeons le contexte des seuls registres du module processeur principal. Il est supposé que le noyau du système d'exploitation ne fonctionne pas avec l'extension vectorielle du processeur. Mais si vous en avez besoin, par exemple, la cryptographie peut le faire, mais vous devez utiliser fpu_beginet fpu_endenregistrer et restaurer le contexte du registre FPU:__kernel_fpu_begin_bh();
memcpy_avx(dst, src, n);
__kernel_fpu_end_bh();
Ce sont des macros natives qui enregistrent et restaurent l'état du module processeur , qui est responsable des registres vectoriels. Ce sont des ressources assez lentes.AVX et SSE
Avant les repères de sauvegarde et de restauration du contexte FPU, quelques mots sur les opérations vectorielles. Pourquoi parfois il est logique de travailler avec un assembleur? Parfois, GCC génère du code sous-optimal. Le problème est que sur les anciens modèles de processeurs, la transition de SSE à AVX présente une pénalité importante. GCC a une nouvelle clé vzeroupper- utilisez-la pour qu'elle ne génère pas cette instruction vzeroupper, qui efface les registres et supprime cette pénalité.Vous devez utiliser cette instruction uniquement si vous travaillez avec un ancien code qui a été compilé pour SSE par un tiers. Ce n'est pas notre cas et nous pouvons jeter ces instructions en toute sécurité.FPU
Nous avons une vectorisation automatique dans le processeur. Cela signifie que dans tout code d'espace utilisateur, il y aura des opérations vectorielles. Deux processus du système utilisent des extensions de processeur vectoriel. Lorsque votre processus passe au noyau et vice-versa, vous ne perdez pas de temps à économiser et à restaurer l'état vectoriel du processeur. Mais si vous passez d'un espace utilisateur à un autre (changement de contexte), en plus du fait que les caches de premier niveau y sont désactivés, le module de changement de contexte sur FPU begin / end fonctionne également mal. L'opération est assez coûteuse - une micro-référence.Dans les microbenchmarks, tout est toujours dramatique, mais l'opération coûte très cher. Par conséquent, dans l'espace utilisateur, changez le contexte pendant longtemps. Dans le noyau, nous n'avons pas de changement de contexte, donc tout est rapide. Nous enregistrons et restaurons le processeur vectoriel une seule fois pour un ensemble de packages suffisamment volumineux.
Deux processus du système utilisent des extensions de processeur vectoriel. Lorsque votre processus passe au noyau et vice-versa, vous ne perdez pas de temps à économiser et à restaurer l'état vectoriel du processeur. Mais si vous passez d'un espace utilisateur à un autre (changement de contexte), en plus du fait que les caches de premier niveau y sont désactivés, le module de changement de contexte sur FPU begin / end fonctionne également mal. L'opération est assez coûteuse - une micro-référence.Dans les microbenchmarks, tout est toujours dramatique, mais l'opération coûte très cher. Par conséquent, dans l'espace utilisateur, changez le contexte pendant longtemps. Dans le noyau, nous n'avons pas de changement de contexte, donc tout est rapide. Nous enregistrons et restaurons le processeur vectoriel une seule fois pour un ensemble de packages suffisamment volumineux.Intelpocalypse
Au début, j'ai montré une option de table de recherche pour optimiser le code du commutateur: un long processus, énumérer, compiler la table de commutateur dans un tableau et suivre le double déréférencement du pointeur qui saute sur ce tableau. Il s'agit d'un scénario pour une attaque Spectre qui exploite l'exécution spéculative.Google a un bon article sur la façon dont le double déréférencement des pointeurs dans les compilateurs modernes est organisé en ce moment (depuis le début de 2018). Cela ne fonctionne pas très bien. Si plus tôt dans le registre, une adresse a été enregistrée et que nous sommes allés à cette adresse, nous avons maintenant un code différent.jmp *%r11
call l1
l0: pause
lfence
jmp l0
l1: mov %r11, (%rsp)
ret
Comment ça marche? On «appelle» la fonction sur l1, le processus passe à cette étiquette et on fait un hack: comme si on revenait d'une fonction (qui ne l'est pas), mais on réécrit l'adresse de retour. Lorsque nous faisons l'instruction call, nous plaçons l'adresse de retour, l'adresse actuelle sur la pile, la réécrivons avec le contenu nécessaire du registre et passons à l1. Mais le processeur, lorsque son préfet est en cours d'exécution, voit qu'il y a une fonction, puis une barrière. En conséquence, tout sera lent - il jette la prélecture et nous nous débarrassons de la vulnérabilité Spectre. Le code est lent, les performances baissent de 15%.La prochaine attaque relativement nouvelle est Meltdown.. Il est spécifique aux processus de l'espace utilisateur uniquement. La lecture de la mémoire du noyau depuis l'espace utilisateur est très pénible. L'attaque est empêchée par le Kernel Pate Table Isolation (KPTI), qui se compile dans les nouveaux noyaux par défaut. Mais KPTI est très cher, jusqu'à 30-40% de dégradation des performances ( tel que mesuré par MariaDB ).Cela est dû au fait que vous n'avez plus d'optimisation TLB paresseuse: l'espace d'adressage du noyau et du processeur est complètement séparé dans différentes tables de pages (avant, TLB paresseux continuait de mapper l'espace du noyau à la table de pages de chaque processus). C'est pénible pour l'espace utilisateur, mais pas pour Tempesta FW, qui fonctionne complètement dans le noyau.Quelques liens utiles:Saint HighLoad++ . , 6 -- ( , Saint HighLoad++) , web .
PHP Russia: 13 , . — KnowledgeConf, ++ TechLead Conf — . , , .