Flant a un certain nombre de développements Open Source, principalement pour Kubernetes, et Loghouse est l'un des plus populaires. Il s'agit de notre outil de journalisation central dans K8s, qui a été introduit il y a plus de 2 ans. Comme nous l'avons mentionné dans un récent article sur les journaux , il a nécessité un raffinement et sa pertinence n'a fait qu'augmenter avec le temps. Aujourd'hui, nous sommes heureux de présenter une nouvelle version de loghouse - v0.3.0 . Détails sur elle - sous la coupe.
Comme nous l'avons mentionné dans un récent article sur les journaux , il a nécessité un raffinement et sa pertinence n'a fait qu'augmenter avec le temps. Aujourd'hui, nous sommes heureux de présenter une nouvelle version de loghouse - v0.3.0 . Détails sur elle - sous la coupe.désavantages
Nous avons utilisé Loghouse dans de nombreux clusters Kubernetes pendant tout ce temps, et en général, cette solution convient à la fois à nous-mêmes et aux différents clients auxquels nous fournissons également un accès.Ses principaux avantages sont son interface simple et intuitive, la possibilité d'exécuter des requêtes SQL, une bonne compression et une faible consommation de ressources lors de l'insertion de données dans la base de données, ainsi qu'une faible surcharge pendant le stockage.Les problèmes les plus douloureux dans la maison en rondins pendant le fonctionnement:- utilisation de tables de partition jointes par une table de fusion;
- absence de tampon qui atténuerait les rafales de journaux;
- Gemme de panneau Web obsolète et potentiellement vulnérable
- fluentd obsolète (loghouse -fluentd: le dernier n'a pas démarré en raison d'un jeu de gemmes problématique).
En outre, un nombre important de problèmes se sont accumulés sur GitHub , que je voudrais également résoudre.Changements majeurs dans la loghouse 0.3.0
En fait, nous avons accumulé suffisamment de changements, mais nous soulignerons les plus importants. Ils peuvent être divisés en 3 groupes principaux:- améliorer le stockage des journaux et le schéma de la base de données;
- amélioration de la collecte des journaux;
- l'apparition de la surveillance.
1. Améliorations du stockage des journaux et de la conception de la base de données
Innovations clés:- Les schémas de stockage des journaux ont changé, la transition vers une table unique et le rejet des tables de partition sont terminés .
- Le mécanisme de nettoyage de base intégré à ClickHouse des dernières versions a commencé à être appliqué .
- Vous pouvez maintenant utiliser une installation ClickHouse externe , même en mode cluster.
Comparez les performances des anciens et des nouveaux circuits dans un projet réel. Voici un exemple de recherche d'URL uniques dans les journaux d'application de la ressource en ligne populaire dtf.ru :SELECT
string_fields.values[indexOf(string_fields.names, 'path')] AS path,
count(*) AS count
FROM logs
WHERE (namespace = 'kube-nginx-ingress') AND ((string_fields.values[indexOf(string_fields.names, 'vhost')]) LIKE '%foobar.baz%') AND (date = '2020-02-29')
GROUP BY string_fields.values[indexOf(string_fields.names, 'path')]
ORDER BY count DESC
LIMIT 20
La sélection s'effectue sur des dizaines de millions d'enregistrements. L'ancien schéma fonctionnait en 20 secondes: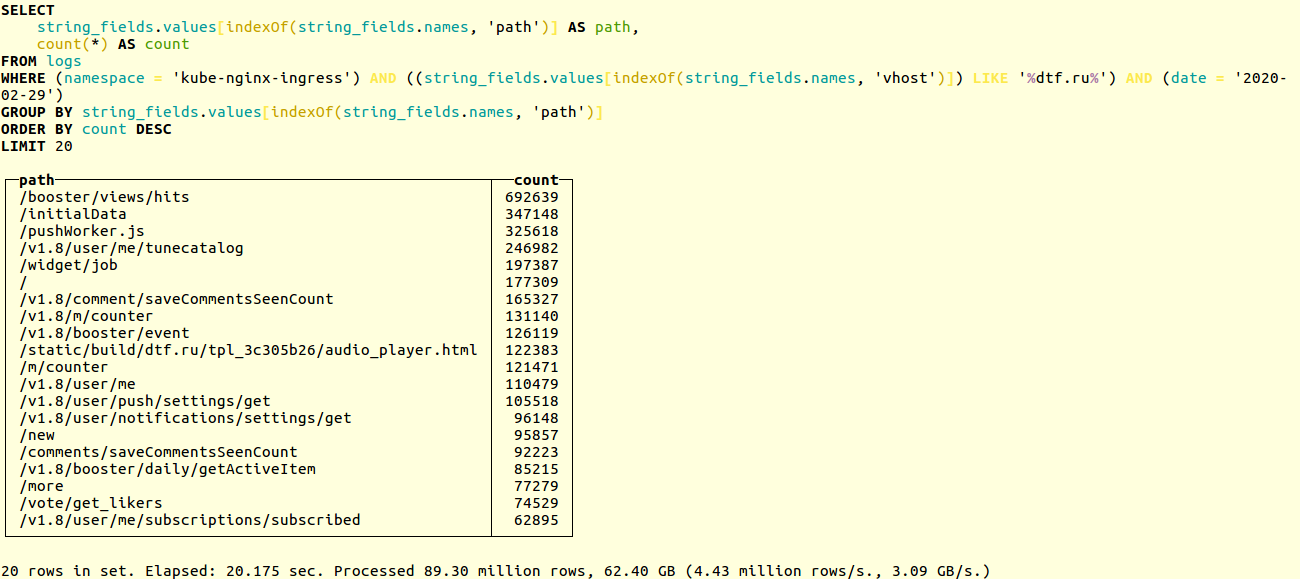 Nouveau - en 14:
Nouveau - en 14: Si vous utilisez notre Helm-chart , alors lors de la mise à jour de la loghouse, la base de données sera automatiquement migrée vers le nouveau format. Sinon, vous devrez effectuer la migration manuellement. Le processus est décrit dans la documentation . En bref, lancez simplement:
Si vous utilisez notre Helm-chart , alors lors de la mise à jour de la loghouse, la base de données sera automatiquement migrée vers le nouveau format. Sinon, vous devrez effectuer la migration manuellement. Le processus est décrit dans la documentation . En bref, lancez simplement:DO_DB_DEPLOY=true rake create_logs_tables
De plus, nous avons commencé à utiliser TTL pour les tables ClickHouse . Cela vous permet de supprimer automatiquement des données de la base de données qui sont plus anciennes que l'intervalle de temps spécifié:CREATE TABLE logs
(
....
)
ENGINE = MergeTree()
PARTITION BY (date)
ORDER BY (timestamp, nsec, namespace, container_name)
TTL date + toIntervalDay(14)
SETTINGS index_granularity = 32768;
Des exemples de schémas de base de données et de configurations pour ClickHouse, y compris un exemple de travail avec le cluster CH, peuvent être trouvés dans la documentation .Amélioration de la collecte des journaux
Innovations clés:- Un tampon a été ajouté qui est conçu pour lisser les rafales lorsqu'un grand nombre de journaux apparaissent.
- Implémentation de la possibilité d' envoyer des journaux à la loghouse directement depuis l'application: via TCP et UDP, au format JSON.
La batterie loghouse dans loghouse est une nouvelle table logs_bufferajoutée au schéma de la base de données. Cette table est en mémoire, c'est-à-dire stocké dans la RAM (a un type spécial de tampon ); c'est elle qui doit lisser la charge sur la base. Merci pour l' astuce pour l'ajouter.Sovigod!L'envoi de journaux implémentés directement à loghouse depuis l'application vous permet de le faire même via netcat:echo '{"log": {"level": "info", "msg": "hello world"}}' | nc fluentd.loghouse 5170
Ces journaux peuvent être affichés dans l'espace de noms où loghouse est installé dans le flux net: Les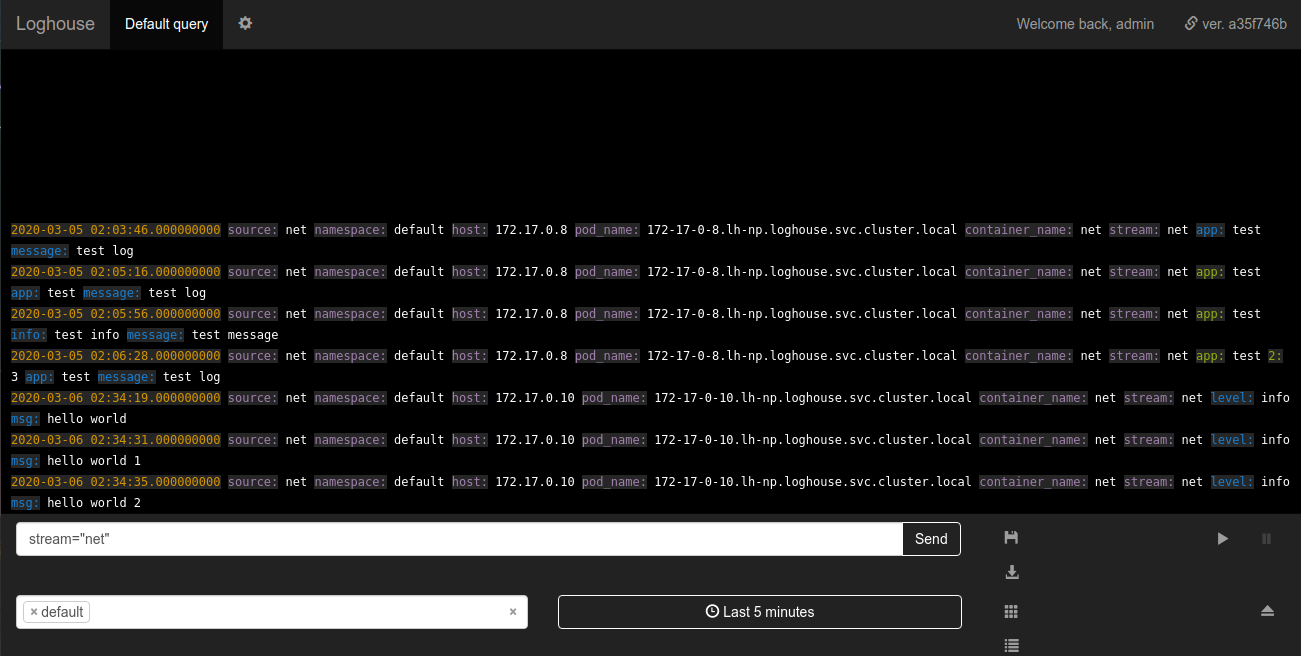 exigences pour les données à envoyer sont minimales: le message doit être un JSON valide avec un champ
exigences pour les données à envoyer sont minimales: le message doit être un JSON valide avec un champ log. Le champ log, à son tour, peut être une chaîne ou un JSON imbriqué.Surveillance du sous-système de journalisation
Une amélioration importante a été la surveillance de fluentd via Prométhée. Maintenant, la loghouse est livrée avec un panneau pour Grafana, qui affiche toutes les métriques de base, telles que:- nombre de travailleurs fluents;
- nombre d'événements envoyés à ClickHouse;
- taille du tampon libre en pourcentage.
Le code du panneau pour Grafana peut être vu dans la documentation .Le panneau pour ClickHouse est fabriqué sur la base d' un produit prêt à l'emploi - de f1yegor , pour lequel un grand merci à l'auteur.Comme vous pouvez le voir, le panneau affiche le nombre de connexions à ClickHouse, l'utilisation du tampon, l'activité des tâches d'arrière-plan et le nombre de fusions. Cela suffit pour comprendre l'état du système: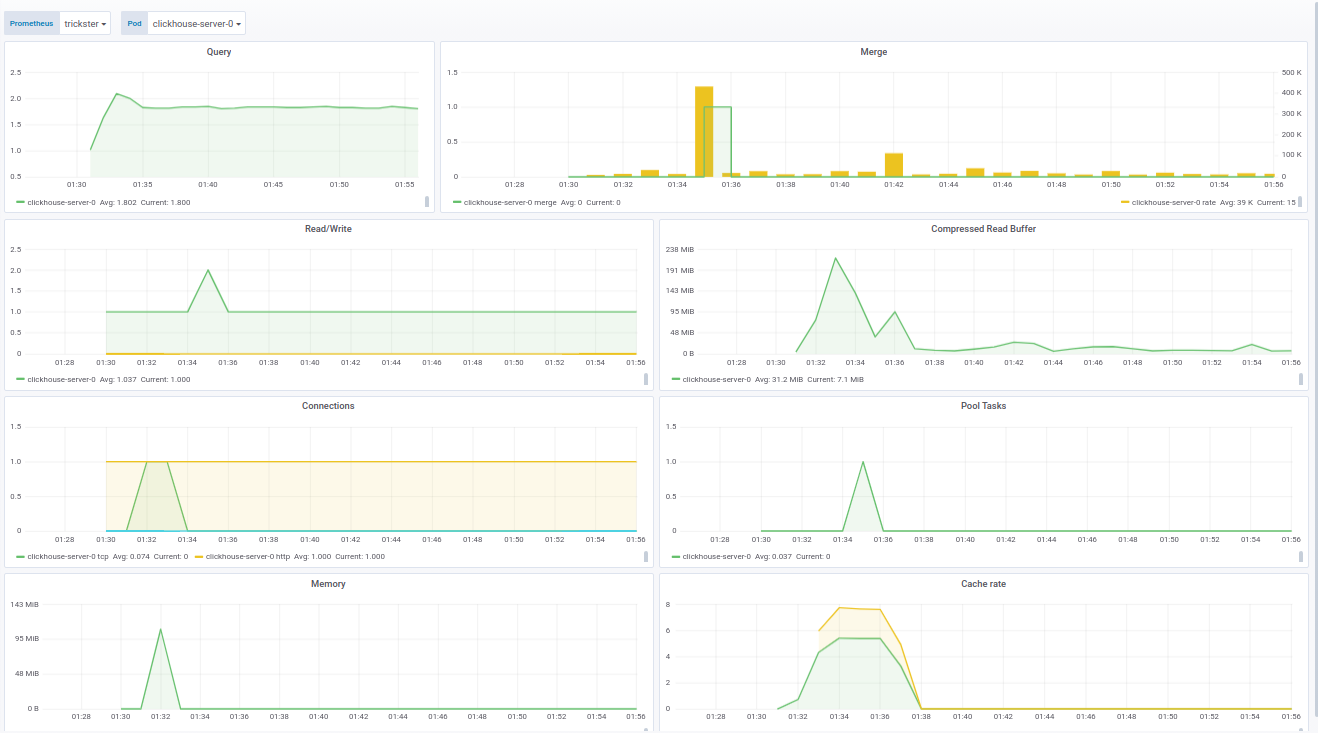 Le panneau pour fluentd montre les instances actives de fluentd. Ceci est particulièrement critique pour ceux qui ne veulent pas / ne peuvent pas perdre de journaux du tout:
Le panneau pour fluentd montre les instances actives de fluentd. Ceci est particulièrement critique pour ceux qui ne veulent pas / ne peuvent pas perdre de journaux du tout: En plus de l'état des pods, le panneau affiche la charge sur la file d'attente pour l'envoi des journaux à ClickHouse. À son tour, vous pouvez comprendre si ClickHouse gère la charge ou non. Dans les cas où le journal ne peut pas être perdu, ce paramètre devient également critique.Des exemples de panneaux sont affûtés pour notre fourniture de Prometheus Operator, cependant, ils sont facilement modifiés par le biais des variables dans les paramètres.Enfin, dans le cadre du travail de surveillance de loghouse, nous avons rassemblé une image Docker à jour avec clickhouse_exporter 0.1.0 publiée par Percona Labs, car l'auteur du clickhouse_exporter original a abandonné son référentiel.
En plus de l'état des pods, le panneau affiche la charge sur la file d'attente pour l'envoi des journaux à ClickHouse. À son tour, vous pouvez comprendre si ClickHouse gère la charge ou non. Dans les cas où le journal ne peut pas être perdu, ce paramètre devient également critique.Des exemples de panneaux sont affûtés pour notre fourniture de Prometheus Operator, cependant, ils sont facilement modifiés par le biais des variables dans les paramètres.Enfin, dans le cadre du travail de surveillance de loghouse, nous avons rassemblé une image Docker à jour avec clickhouse_exporter 0.1.0 publiée par Percona Labs, car l'auteur du clickhouse_exporter original a abandonné son référentiel.Plans futurs
- Permet de déployer un cluster ClickHouse dans Kubernetes.
- Rendez la sélection des journaux asynchrone et supprimez-la de la partie Ruby du backend.
- Ruby- , .
- , Go.
- .
C'est agréable de voir que le projet Loghouse a trouvé son public, non seulement après avoir gagné des étoiles dans GitHub (600+), mais aussi en encourageant les vrais utilisateurs à parler de leurs succès et problèmes.Ayant créé Loghouse il y a plus de 2 ans, nous n'étions pas sûrs de ses perspectives, espérant que le marché et / ou la communauté Open Source offriraient les meilleures solutions. Cependant, nous constatons aujourd'hui qu'il s'agit d'un chemin viable, que nous-mêmes choisissons et utilisons toujours sur de nombreux clusters Kubernetes desservis.Nous nous réjouissons de toute assistance pour améliorer et développer la maison en rondins. Si vous manquez quelque chose dans la loghouse - écrivez dans les commentaires. Bien sûr, nous serons également heureux d'être actifs sur GitHub .PS
Lisez aussi dans notre blog: