Rebonjour! En prévision du début du cours «Architecte logiciel», nous avons préparé une traduction d'un autre matériel intéressant.
Ces dernières années, la popularité de l'architecture de microservices a augmenté. Il existe de nombreuses ressources qui vous apprennent comment l'implémenter correctement, mais très souvent, les gens en parlent comme d'un pool d'argent. Il existe de nombreux arguments contre l'utilisation des microservices, mais le plus important d'entre eux est que ce type d'architecture est lourde de complexité incertaine, dont le niveau dépend de la façon dont vous gérez la relation entre vos services et vos équipes. Vous pouvez trouver beaucoup de littérature qui expliquera pourquoi (peut-être) dans votre cas, les microservices ne seront pas le meilleur choix.Chez letgo, nous avons migré d'un monolithe vers des microservices pour satisfaire le besoin d'évolutivité, et nous avons immédiatement été convaincus de son effet bénéfique sur le travail des équipes. Lorsqu'ils sont utilisés correctement, les microservices nous ont donné plusieurs avantages, à savoir:- : , . ( ..) . ( ) Users.
- : , . . , , , , . .
-
Toutes les architectures de microservices ne sont pas pilotées par les événements. Certaines personnes préconisent une communication synchrone entre les services dans cette architecture en utilisant HTTP (gRPC, REST, etc.). Chez letgo, nous essayons de ne pas suivre ce modèle et d'associer de manière asynchrone nos services aux événements de domaine . Voici les raisons pour lesquelles nous faisons cela:- : . , DDoS . , DDoS . , . .
(bulkheads) – , , .- : . , , , , . , , API, , , , . Users , Chat.
Sur cette base, chez letgo, nous essayons d'adhérer à la communication asynchrone entre les services, et la synchronisation ne fonctionne que dans des cas exceptionnels comme MVP. Nous le faisons parce que nous voulons que chaque service génère ses propres entités en fonction des événements de domaine publiés par d'autres services dans notre Message Bus.À notre avis, le succès ou l'échec de la mise en œuvre d'une architecture de microservices dépend de la façon dont vous gérez sa complexité inhérente et de la façon dont vos services interagissent les uns avec les autres. La division du code sans transférer l'infrastructure de communication en asynchrone transformera votre application en un monolithe distribué.
Architecture événementielle au letgo
Aujourd'hui, je veux partager un exemple de la façon dont nous utilisons les événements de domaine et la communication asynchrone au letgo: notre entité Utilisateur existe dans de nombreux services, mais sa création et sa modification sont initialement traitées par le service Utilisateurs. Dans la base de données du service Utilisateurs, nous stockons de nombreuses données, telles que le nom, l'adresse e-mail, l'avatar, le pays, etc. Dans notre service Chat, nous avons également un concept d'utilisateur, mais nous n'avons pas besoin des données que possède l'entité Utilisateur du service Utilisateurs. Le nom, l'avatar et l'ID de l'utilisateur (lien vers le profil) sont affichés dans la liste des boîtes de dialogue. Nous disons que dans un chat, il n'y a qu'une projection de l'entité utilisateur, qui contient des données partielles. En fait, dans le chat, nous ne parlons pas d'utilisateurs, nous les appelons des «locuteurs». Cette projection fait référence au service Chat et est basée sur les événements que Chat reçoit du service Utilisateurs.Nous faisons de même avec les annonces. Dans le service Produits, nous stockons n images de chaque liste, mais dans la vue liste des boîtes de dialogue, nous en montrons une principale, donc notre projection de Produits à Chat ne nécessite qu'une seule image au lieu de n.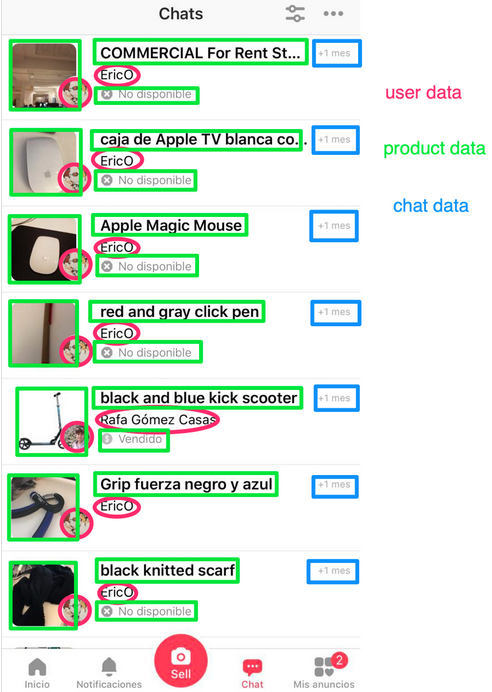 Consultez une liste de dialogues dans notre chat. Il montre quel service spécifique sur le backend fournit des informations.Si vous regardez à nouveau la liste des boîtes de dialogue, vous verrez que presque toutes les données que nous affichons ne sont pas créées par le service Chat, mais en font partie, car les projections Utilisateur et Chat appartiennent à Chat. Il existe un compromis entre l'accessibilité et la cohérence des projections, dont nous ne parlerons pas dans cet article, mais je dirai seulement qu'il est clairement plus facile de mettre à l'échelle de nombreuses petites bases de données qu'une seule grande.
Consultez une liste de dialogues dans notre chat. Il montre quel service spécifique sur le backend fournit des informations.Si vous regardez à nouveau la liste des boîtes de dialogue, vous verrez que presque toutes les données que nous affichons ne sont pas créées par le service Chat, mais en font partie, car les projections Utilisateur et Chat appartiennent à Chat. Il existe un compromis entre l'accessibilité et la cohérence des projections, dont nous ne parlerons pas dans cet article, mais je dirai seulement qu'il est clairement plus facile de mettre à l'échelle de nombreuses petites bases de données qu'une seule grande.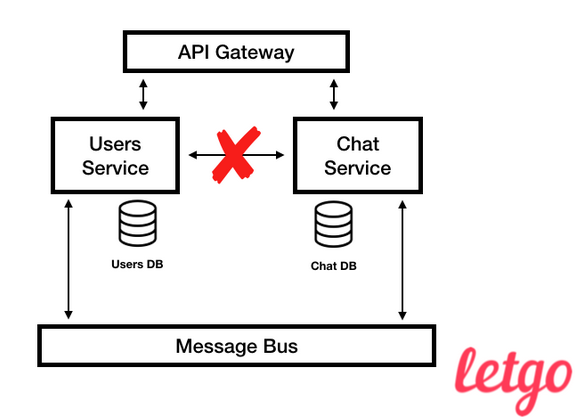 Vue simplifiée de l'architecture letgo
Vue simplifiée de l'architecture letgoAntipatterns
Certaines solutions intuitives sont souvent devenues des erreurs. Voici une liste des contre-modèles les plus importants que nous avons rencontrés dans notre architecture liée au domaine.1. Événements épaisNous essayons de rendre nos événements de domaine aussi petits que possible tout en ne perdant pas leur valeur de domaine. Nous aurions dû être prudents lors de la refactorisation des bases de code héritées avec de grandes entités et le passage à l'architecture d'événements. De telles entités peuvent nous conduire à de gros événements, mais comme nos événements de domaine se sont transformés en contrat public, nous devions les rendre aussi simples que possible. Dans ce cas, le refactoring est mieux vu de côté. Pour commencer, nous concevons nos événements en utilisant la technique de l' événement tempêtepuis refactoriser le code de service pour l'adapter à nos événements.Nous devons également être plus prudents avec le problème «produit et utilisateur»: de nombreux systèmes utilisent des entités produit et utilisateur, et ces entités, en règle générale, tirent toute la logique derrière elles, ce qui signifie que tous les événements de domaine leur sont associés.2. Les événements comme intentions Unévénement de domaine, par définition, est un événement qui s'est déjà produit. Si vous publiez quelque chose sur le bus de messages pour demander ce qui s'est passé dans un autre service, vous exécutez probablement une commande asynchrone plutôt que de créer un événement de domaine. En règle générale, nous nous référons aux événements de domaine passés: ser_registered , product_publishedetc. Moins un service connaît l'autre, mieux c'est. L'utilisation d'événements en tant que commandes relie les services et augmente la probabilité qu'un changement dans un service affecte d'autres services.3. Absence de sérialisation ou de compression indépendante Lessystèmes de sérialisation et de compression des événements dans notre domaine ne devraient pas dépendre du langage de programmation. Vous n'avez même pas besoin de savoir dans quelle langue les services aux consommateurs sont écrits. C'est pourquoi nous pouvons utiliser des sérialiseurs Java ou PHP, par exemple. Laissez votre équipe passer du temps à discuter et à choisir un sérialiseur, car le changer à l'avenir sera difficile et long. Chez letgo, nous utilisons JSON, mais il existe de nombreux autres formats de sérialisation avec de bonnes performances.4. Absence de structure standardLorsque nous avons commencé à porter le backend letgo vers une architecture orientée événement, nous nous sommes mis d'accord sur une structure commune pour les événements de domaine. Cela ressemble à ceci:{
“data”: {
“id”: [uuid], // event id.
“type”: “user_registered”,
“attributes”: {
“id”: [uuid], // aggregate/entity id, in this case user_id
“user_name”: “John Doe”,
…
}
},
“meta” : {
“created_at”: timestamp, // when was the event created?
“host”: “users-service” // where was the event created?
…
}
}
Avoir une structure commune pour nos événements de domaine nous permet d'intégrer rapidement des services et d'implémenter certaines bibliothèques avec des abstractions.5. Absence de validation du schémaLors de la sérialisation, letgo a rencontré des problèmes avec les langages de programmation sans typage fort.
{
“null_value_one”: null, // thank god
“null_value_two”: “null”,
“null_value_three”: “”,
}
Une culture de test bien établie qui garantit la sérialisation de nos événements et une compréhension du fonctionnement de la bibliothèque de sérialisation aident à y faire face. Chez letgo, nous passons à Avro et au registre des schémas de conflits, ce qui nous fournit un point unique pour déterminer la structure des événements de notre domaine et évite les erreurs de ce type, ainsi qu'une documentation obsolète.6. Événements du domaine anémiqueComme je l'ai déjà dit, et comme son nom l'indique, les événements de domaine doivent avoir une valeur au niveau du domaine. Tout comme nous essayons d'éviter l'incohérence des états dans nos entités, nous devons éviter cela dans les événements de domaine. Illustrons cela avec l'exemple suivant: le produit de notre système a une géolocalisation avec latitude et longitude, qui sont stockées dans deux champs différents de la table produits du service Produits. Tous les produits peuvent être "déplacés", nous aurons donc des événements de domaine pour présenter cette mise à jour. Auparavant, pour cela, nous avions deux événements: product_latitude_updated et product_longitude_updated , ce qui n'avait pas beaucoup de sens si vous n'étiez pas une tour sur un échiquier. Dans ce cas, les événements product_location_updated auront plus de sens.ou product_moved . Une tour est une pièce d'échecs. On l'appelait autrefois une tournée. Une tour ne peut se déplacer verticalement ou horizontalement à travers un certain nombre de champs inoccupés.7. Manque d'outils de débogageChez letgo, nous produisons des milliers d'événements de domaine par minute. Tous ces événements deviennent une ressource extrêmement utile pour comprendre ce qui se passe dans notre système, enregistrer l'activité des utilisateurs ou même reconstruire l'état d'un système à un moment précis à l'aide de la recherche d'événements. Nous devons utiliser habilement cette ressource, et pour cela, nous avons besoin d'outils pour vérifier et déboguer nos événements. Des demandes telles que «montrez-moi tous les événements générés par John Doe au cours des 3 dernières heures» peuvent également être utiles pour détecter la fraude. À ces fins, nous avons développé quelques outils sur ElasticSearch, Kibana et S3.8. Absence de suivi des événementsNous pouvons utiliser des événements de domaine pour tester la santé du système. Lorsque nous déployons quelque chose (ce qui se produit plusieurs fois par jour selon le service), nous avons besoin d'outils pour vérifier rapidement le bon fonctionnement. Par exemple, si nous déployons une nouvelle version du service Produits en production et constatons une diminution du nombre d'événements product_published20%, il est sûr de dire que nous avons cassé quelque chose. Nous utilisons actuellement InfluxDB, Grafana et Prometheus pour y parvenir avec des fonctions dérivées. Si vous vous souvenez du cours de mathématiques, vous comprendrez que la dérivée de la fonction f (x) au point x est égale à la tangente de la pente de la tangente dessinée sur le graphique de la fonction à ce point. Si vous avez une fonction pour publier la vitesse d'un événement spécifique dans un domaine et que vous en prenez un dérivé, vous verrez les pics de cette fonction et vous pouvez définir des notifications en fonction d'eux. En utilisant ces notifications, vous pouvez éviter des phrases telles que «prévenez-moi si nous publions moins de 200 événements par seconde pendant 5 minutes» et concentrez-vous sur un changement significatif de la vitesse de publication.
Une tour est une pièce d'échecs. On l'appelait autrefois une tournée. Une tour ne peut se déplacer verticalement ou horizontalement à travers un certain nombre de champs inoccupés.7. Manque d'outils de débogageChez letgo, nous produisons des milliers d'événements de domaine par minute. Tous ces événements deviennent une ressource extrêmement utile pour comprendre ce qui se passe dans notre système, enregistrer l'activité des utilisateurs ou même reconstruire l'état d'un système à un moment précis à l'aide de la recherche d'événements. Nous devons utiliser habilement cette ressource, et pour cela, nous avons besoin d'outils pour vérifier et déboguer nos événements. Des demandes telles que «montrez-moi tous les événements générés par John Doe au cours des 3 dernières heures» peuvent également être utiles pour détecter la fraude. À ces fins, nous avons développé quelques outils sur ElasticSearch, Kibana et S3.8. Absence de suivi des événementsNous pouvons utiliser des événements de domaine pour tester la santé du système. Lorsque nous déployons quelque chose (ce qui se produit plusieurs fois par jour selon le service), nous avons besoin d'outils pour vérifier rapidement le bon fonctionnement. Par exemple, si nous déployons une nouvelle version du service Produits en production et constatons une diminution du nombre d'événements product_published20%, il est sûr de dire que nous avons cassé quelque chose. Nous utilisons actuellement InfluxDB, Grafana et Prometheus pour y parvenir avec des fonctions dérivées. Si vous vous souvenez du cours de mathématiques, vous comprendrez que la dérivée de la fonction f (x) au point x est égale à la tangente de la pente de la tangente dessinée sur le graphique de la fonction à ce point. Si vous avez une fonction pour publier la vitesse d'un événement spécifique dans un domaine et que vous en prenez un dérivé, vous verrez les pics de cette fonction et vous pouvez définir des notifications en fonction d'eux. En utilisant ces notifications, vous pouvez éviter des phrases telles que «prévenez-moi si nous publions moins de 200 événements par seconde pendant 5 minutes» et concentrez-vous sur un changement significatif de la vitesse de publication.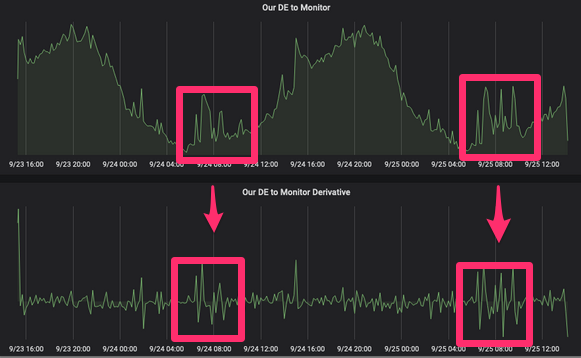 Quelque chose d'étrange s'est produit ici ... Ou peut-être que c'est juste une campagne de marketing9. L'espoir que tout ira bienNous essayons de créer des systèmes durables et de réduire le coût de leur restauration. Outre les problèmes d'infrastructure et le facteur humain, l'une des choses les plus courantes pouvant affecter l'architecture des événements est la perte d'événements. Nous avons besoin d'un plan avec lequel nous pouvons restaurer l'état correct du système en retraçant tous les événements qui ont été perdus. Ici, notre stratégie repose sur deux points:
Quelque chose d'étrange s'est produit ici ... Ou peut-être que c'est juste une campagne de marketing9. L'espoir que tout ira bienNous essayons de créer des systèmes durables et de réduire le coût de leur restauration. Outre les problèmes d'infrastructure et le facteur humain, l'une des choses les plus courantes pouvant affecter l'architecture des événements est la perte d'événements. Nous avons besoin d'un plan avec lequel nous pouvons restaurer l'état correct du système en retraçant tous les événements qui ont été perdus. Ici, notre stratégie repose sur deux points:- : , « , », - , . letgo Data, Backend.
- : - . , , , message bus . – , , . , user_registered Users, , MySQL, user_id . user_registered, , . , , - MySQL ( , 30 ). -, DynamoDB. , , , . , , , , .
10. Manque de documentation sur les événements de domaineNos événements de domaine sont devenus notre interface publique pour tous les systèmes sur le backend. Tout comme nous documentons nos API REST, nous devons également documenter les événements de domaine. Tout employé de l'organisation doit pouvoir consulter la documentation mise à jour pour chaque événement de domaine publié par chaque service. Si nous utilisons des schémas pour vérifier les événements de domaine, ils peuvent également être utilisés comme documentation.11. Résistance à la consommation de ses propres événementsVous êtes autorisé et même encouragé à utiliser vos propres événements de domaine pour créer des projections dans votre système, qui, par exemple, sont optimisées pour la lecture. Certaines équipes ont résisté à ce concept, car elles se limitaient au concept de consommation des événements d'autrui.On se revoit sur le parcours!