Bonjour, Habr! Je veux vous dire comment nous avons écrit et mis en œuvre un service de surveillance de la qualité des données. Nous avons de nombreuses sources de données: données des marchés financiers, activité de trading de nos clients, cotations et bien plus encore. Tout cela génère des milliards d'enregistrements par jour dans nos processus. L'exhaustivité et la cohérence des données commerciales sont un élément essentiel des activités d'Exness.Si vous êtes proche des problèmes d'assurance de la qualité des données et que vous souhaitez savoir comment nous avons résolu ce problème à la maison, alors bienvenue chez cat. Mon nom est Dmitry, je travaille dans une équipe qui stocke à la fois les données brutes et la transformation, l'agrégation et la fourniture de toutes les données traitées à tous les départements de l'entreprise. Nos données sont consommées par de nombreuses équipes au sein de l'entreprise, telles que Business Intelligence, Anti-Fraud, Finance, et nous les fournissons également à nos partenaires b2b.Travailler avec des données est une mission responsable et difficile, car l'arrêt d'un processus ETL peut entraîner la paralysie d'une partie des activités d'Exness. Pour résoudre les problèmes ETL, nous utilisons une variété d'outils: Les
Mon nom est Dmitry, je travaille dans une équipe qui stocke à la fois les données brutes et la transformation, l'agrégation et la fourniture de toutes les données traitées à tous les départements de l'entreprise. Nos données sont consommées par de nombreuses équipes au sein de l'entreprise, telles que Business Intelligence, Anti-Fraud, Finance, et nous les fournissons également à nos partenaires b2b.Travailler avec des données est une mission responsable et difficile, car l'arrêt d'un processus ETL peut entraîner la paralysie d'une partie des activités d'Exness. Pour résoudre les problèmes ETL, nous utilisons une variété d'outils: Les défis auxquels nous sommes confrontés tous les jours:
défis auxquels nous sommes confrontés tous les jours:- Des dizaines de millions d'enregistrements de transactions par jour;
- Des milliards d'entrées sur le marché quotidiennement (cotations, etc.);
- L'hétérogénéité des sources de données (telles que les sources externes de données de marché, les différentes plateformes de négociation);
- Fournir exactement une fois la sémantique des données importantes (transactions financières);
- Assurer l'intégrité et l'exhaustivité des données;
- Fournir des garanties que pendant la période stipulée, la transaction sera ajoutée à tous les tableaux et agrégats nécessaires.
Afin de fournir de telles garanties, il était nécessaire d'apprendre à suivre, mesurer et répondre de manière proactive aux écarts de qualité des données elles-mêmes.Compte tenu de la complexité de nos processus de collecte et de traitement des données, compte tenu de la grande vitesse de développement et de modification des processus ETL, il devient nécessaire de surveiller la qualité des données déjà au point final. Nous avons généralement une base de données Clickhouse ou PostgreSQL. Ces mesures nous indiqueront à quelle vitesse nos processus fonctionnent:SELECT server,
avg(updated - close_time)
FROM trades
WHERE close_time > subtractHours(Now(), 2)
GROUP BY server
Ils aideront à trouver des doublons dans les données (il n'y a pas de contrainte unique dans Clickhouse):SELECT SUM(count) FROM (
SELECT
COUNT(*) AS count
FROM trades
GROUP BY order_id
HAVING count > 1
)
Vous pouvez proposer une tonne de requêtes (dont beaucoup sont déjà utilisées) qui aident à surveiller la qualité des données: comparer le nombre de lignes dans la table source et la table de destination, l'heure de la dernière insertion dans la table, comparer le contenu de deux requêtes et bien plus encore.Les mesures sont des symptômes. À eux seuls, ils n'indiquent pas la cause du problème, mais nous permettent de montrer qu'il y a un problème. Ce sera un déclencheur pour l'ingénieur de prêter attention au problème et d'identifier la cause première. Analogie: si une personne a une température, alors quelque chose s'est cassé dans son corps. La température est un symptôme suffisant pour commencer à comprendre et à trouver la cause de la panne.Nous avons cherché une solution prête à l'emploi qui pourrait recueillir de telles mesures de symptômes pour nous. Nos exigences:- Prise en charge de diverses sources de données (bases de données, files d'attente, requêtes http);
- ;
- ( , );
- .
Au début de l'article, j'ai énuméré les technologies que nous utilisons dans ETL. Comme vous pouvez le constater, nous sommes partisans des solutions open source! Un exemple: nous utilisons la base de données Clickhouse orientée colonnes comme entrepôt de données principal. Notre équipe a apporté plusieurs modifications au code source de Clickhouse (principalement en corrigeant des bogues). Comme outils pour travailler avec des métriques et des séries chronologiques, nous utilisons: l'écosystème influxdb, les métriques prometheus et victoria, zabbix.À notre grande surprise, il s'est avéré qu'il n'y a pas d'outil prêt à l'emploi et pratique pour surveiller la qualité des données qui s'intègre dans les technologies que nous avons choisies. Ou regardions-nous mal?Oui, zabbix a la possibilité d'exécuter des scripts personnalisés et telegrafVous pouvez apprendre à exécuter des requêtes SQL et à transformer leurs résultats en métriques. Mais cela a nécessité une finition sérieuse et n'a pas fonctionné comme nous le voulions. Par conséquent, nous avons écrit notre propre service (démon) pour surveiller la qualité des données. Rencontrez le nerf!Caractéristiques nerveuses
Idéologiquement, le nerf peut être décrit avec la phrase suivante:Il s'agit d'un service qui, selon un calendrier, exécute des tâches hétérogènes et personnalisées pour collecter des valeurs numériques et présente les résultats sous forme de métriques pour différents systèmes de collecte de métriques.
Caractéristiques clés du programme:- Prise en charge de différents types de tâches: Query, CompareQueries, etc.;
- La possibilité d'écrire vos types de tâches en Python en tant que plugin d'exécution;
- Travailler avec différents types de ressources: Clickhouse, Postgres, etc.;
- Modélisation des métriques de données, comme dans prometheus
metric_name{label="value"} 123.3 ;
- pull prometheus;
- : crontab-style;
- WEB UI ;
- yaml ;
- Twelve-Factor App.
La tâche et la ressource sont les entités de base pour configurer et travailler avec Nerve. Tâche - une action périodique typée, à la suite de laquelle nous obtenons des mesures. Ressource - un objet qui contient une configuration et une logique spécifiques pour travailler avec une source de données spécifique. Voyons comment fonctionne le nerf avec un exemple.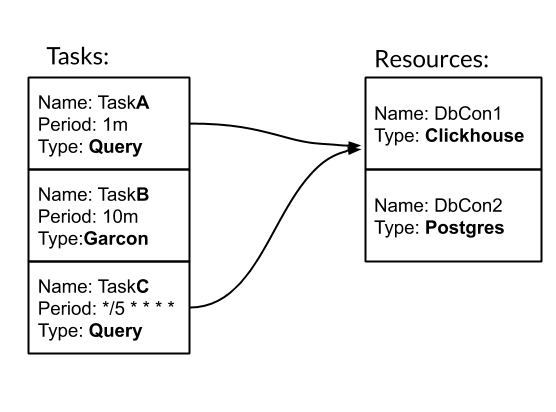 Nous avons trois tâches. Deux d'entre eux sont de type Requête - Requête SQL. L'un est de type Garcon - il s'agit d'une tâche personnalisée qui va à l'un de nos services. La fréquence de la tâche peut être définie par une période de temps. Par exemple, 10 m signifie une fois toutes les dix minutes. Ou crontab-style "* / 5 * * * *" - toutes les cinq minutes complètes. Les tâches TaskA et TaskC sont associées à la ressource DbCon1, qui est de type Clickhouse. Voyons à quoi ressemblera la configuration:
Nous avons trois tâches. Deux d'entre eux sont de type Requête - Requête SQL. L'un est de type Garcon - il s'agit d'une tâche personnalisée qui va à l'un de nos services. La fréquence de la tâche peut être définie par une période de temps. Par exemple, 10 m signifie une fois toutes les dix minutes. Ou crontab-style "* / 5 * * * *" - toutes les cinq minutes complètes. Les tâches TaskA et TaskC sont associées à la ressource DbCon1, qui est de type Clickhouse. Voyons à quoi ressemblera la configuration:tasks:
- name: TaskA
type: Query
resources: DbCon1
period: 1m
config:
query: SELECT COUNT(*) FROM ticks
gauge: metric_count{table="ticks"}
- name: TaskB
type: Garcon
period: 10m
config:
url: "http://hostname:9003/api/v1/orders/backups/"
gauge: backup_ago
- name: TaskC
type: Query
period: "*/5 * * * *"
resources: DbCon1
config:
query: SELECT now() - toDateTime(time_msc/1000)
FROM deals WHERE trade_server= 'Real'
ORDER BY deal DESC LIMIT 1
gauge: orders_lag
resources:
- name: DbCon1
type: Clickhouse
config:
host: clickhouse.env
port: 9000
user: readonly
password: "***"
database: data
results:
common_labels:
env="prod"
task_types_paths:
- "./tasks"
Le chemin d'accès "./tâches" est le chemin d'accès aux tâches personnalisées. En particulier, le type de tâche Garcon y est défini. Dans cet article, j'omettre le moment de créer mes types de tâches.À la suite du lancement du service Nerve avec une telle configuration, dans l'interface utilisateur Web, il sera possible de surveiller la façon dont les tâches sont accomplies: Et les mesures at / metrics pour la collecte seront disponibles:
Et les mesures at / metrics pour la collecte seront disponibles: Type de tâche de requête le plus souvent utilisé dans notre équipe. Par conséquent, nous avons étendu ses capacités de travail avec GROUP BY et les modèles. Ces mécanismes permettent de collecter de nombreuses informations sur les données avec une seule demande à la fois:
Type de tâche de requête le plus souvent utilisé dans notre équipe. Par conséquent, nous avons étendu ses capacités de travail avec GROUP BY et les modèles. Ces mécanismes permettent de collecter de nombreuses informations sur les données avec une seule demande à la fois: la tâche TradesLag collectera le délai maximum pour chaque serveur de trading pour obtenir un ordre fermé dans la table des transactions toutes les cinq minutes, en prenant en compte uniquement les ordres clôturés au cours des deux dernières heures.Quelques mots sur la mise en œuvre. Nerve est une application LoC multi-thread python3 ~ 3k qui est facile à exécuter via Docker, en la complétant avec une configuration de tâche.
la tâche TradesLag collectera le délai maximum pour chaque serveur de trading pour obtenir un ordre fermé dans la table des transactions toutes les cinq minutes, en prenant en compte uniquement les ordres clôturés au cours des deux dernières heures.Quelques mots sur la mise en œuvre. Nerve est une application LoC multi-thread python3 ~ 3k qui est facile à exécuter via Docker, en la complétant avec une configuration de tâche.Qu'est-il arrivé
Avec nerf, nous avons obtenu ce que nous voulions. En ce moment, en plus de notre équipe, d'autres équipes d'Exness ont montré de l'intérêt pour lui. Il tourne environ 40 tâches avec une fréquence de 30 secondes à un jour. Nerve recueille environ 500 mesures sur nos données. L'ajout de nouvelles mesures prend 5 à 10 minutes. Le flux complet de travail avec les métriques ressemble à ceci: nerf → prometheus → Victoria Metrics → tableaux de bord Grafana → Alertes dans PagerDuty.Avec nerf, nous avons également commencé à collecter des mesures commerciales: nous sélectionnons périodiquement les événements bruts dans le système commercial pour évaluer les conditions commerciales.Merci, citoyen Khabrovsk, d'avoir lu mon article jusqu'au bout. Je prévois votre question: où est le lien vers github? La réponse est la suivante: nous n'avons pas encore posté de nerf en Open Source. Cela nécessite un travail supplémentaire de notre part pour améliorer la documentation et terminer quelques fonctionnalités. Si cet article est bien reçu par la communauté, cela nous donnera une incitation supplémentaire à partager notre développement avec vous!Bon à tous!