Le canari est un petit oiseau qui chante constamment. Ces oiseaux sont sensibles au méthane et au monoxyde de carbone. Même à partir d'une petite concentration de gaz en excès dans l'air, ils perdent connaissance ou meurent. Les mineurs d'or et les mineurs ont pris des oiseaux pour proies: pendant que les canaris chantent, vous pouvez travailler, si vous la fermez, il y a du gaz dans la mine et il est temps de partir. Les mineurs ont sacrifié un petit oiseau pour sortir vivant des mines. Une pratique similaire s'est retrouvée en informatique. Par exemple, dans la tâche standard de déploiement d'une nouvelle version d'un service ou d'une application en production avec des tests avant cela. L'environnement de test peut être trop cher, les tests automatisés ne couvrent pas tout ce que nous souhaitons et il est risqué de tester et de sacrifier la qualité. Dans de tels cas, l'approche Canary Deployment aide, lorsqu'un peu de trafic de production réel est lancé sur une nouvelle version. L'approche permet de tester en toute sécurité la nouvelle version pour la production, en sacrifiant de petites choses pour un gros objectif. Plus en détail, comment fonctionne l'approche, ce qui est utile et comment la mettre en œuvre, dira Andrey Markelov (Andrey_V_Markelov), en utilisant un exemple d'implémentation chez Infobip.Andrey Markelov , ingénieur logiciel leader chez Infobip, développe des applications Java en finance et télécommunications depuis 11 ans. Il développe des produits Open Source, participe activement à la communauté Atlassian et écrit des plugins pour les produits Atlassian. Évangéliste Prométhée, Docker et Redis.
Une pratique similaire s'est retrouvée en informatique. Par exemple, dans la tâche standard de déploiement d'une nouvelle version d'un service ou d'une application en production avec des tests avant cela. L'environnement de test peut être trop cher, les tests automatisés ne couvrent pas tout ce que nous souhaitons et il est risqué de tester et de sacrifier la qualité. Dans de tels cas, l'approche Canary Deployment aide, lorsqu'un peu de trafic de production réel est lancé sur une nouvelle version. L'approche permet de tester en toute sécurité la nouvelle version pour la production, en sacrifiant de petites choses pour un gros objectif. Plus en détail, comment fonctionne l'approche, ce qui est utile et comment la mettre en œuvre, dira Andrey Markelov (Andrey_V_Markelov), en utilisant un exemple d'implémentation chez Infobip.Andrey Markelov , ingénieur logiciel leader chez Infobip, développe des applications Java en finance et télécommunications depuis 11 ans. Il développe des produits Open Source, participe activement à la communauté Atlassian et écrit des plugins pour les produits Atlassian. Évangéliste Prométhée, Docker et Redis.À propos d'Infobip
Il s'agit d'une plate-forme mondiale de télécommunications qui permet aux banques, aux détaillants, aux magasins en ligne et aux sociétés de transport d'envoyer des messages à leurs clients par SMS, push, lettres et messages vocaux. Dans une telle entreprise, la stabilité et la fiabilité sont importantes pour que les clients reçoivent les messages à temps.Infobip IT Infrastructure en chiffres:- 15 centres de données dans le monde;
- 500 services uniques en opération;
- 2500 instances de services, ce qui est bien plus que des équipes;
- 4,5 To de trafic mensuel;
- 4,5 milliards de numéros de téléphone;
L'entreprise se développe et avec elle le nombre de sorties. Nous réalisons 60 versions par jour , car les clients veulent plus de fonctionnalités et de capacités. Mais c'est difficile - il y a beaucoup de services, mais peu d'équipes. Vous devez écrire rapidement du code qui devrait fonctionner en production sans erreurs.Communiqués
Une version typique avec nous va comme ça. Par exemple, il existe des services A, B, C, D et E, chacun d'eux est développé par une équipe distincte.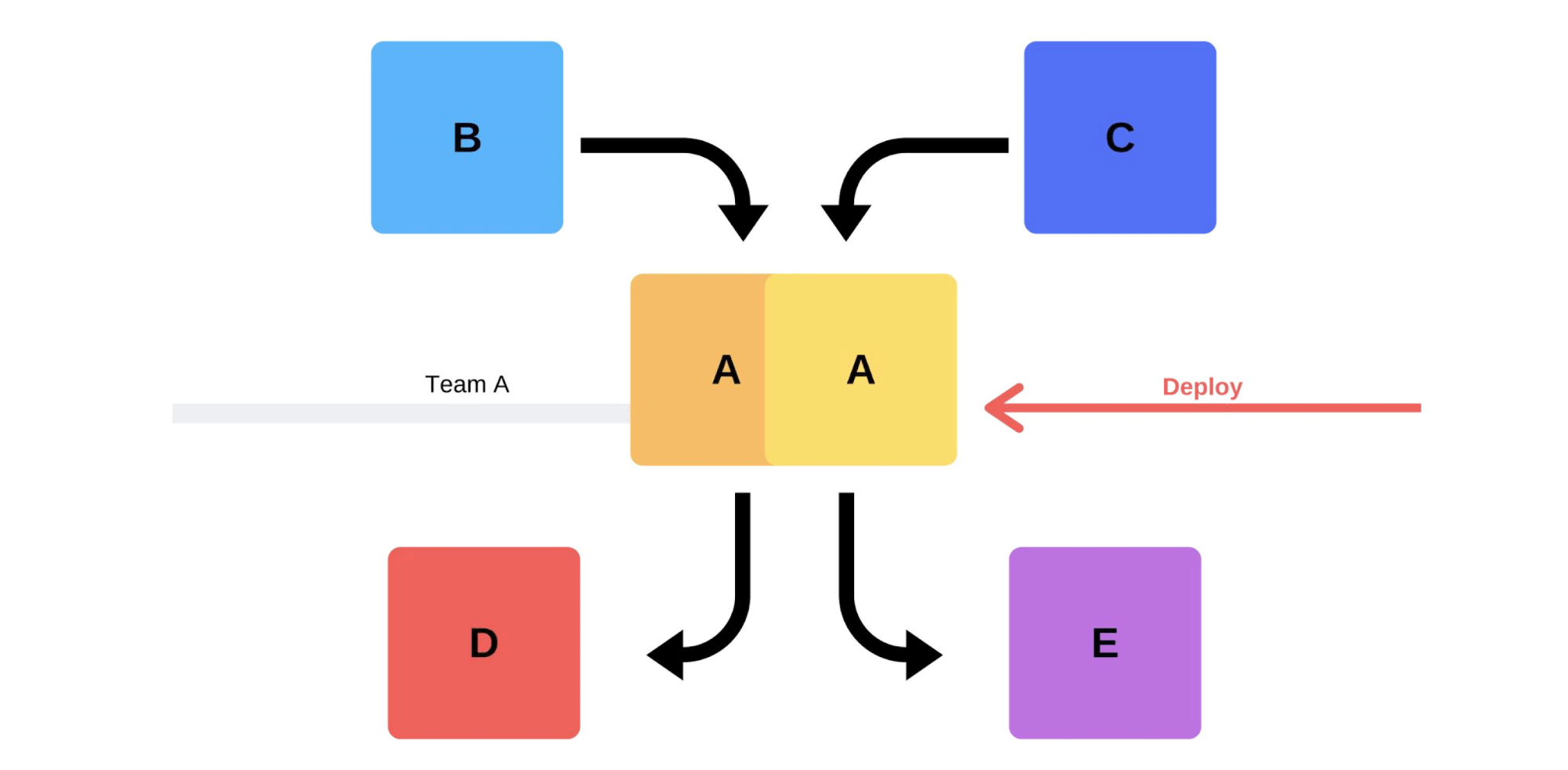 À un moment donné, l'équipe de service A décide de déployer une nouvelle version, mais les équipes de service B, C, D et E ne le savent pas. Il existe deux options pour l'arrivée de l'équipe de service A.Réalisera une version incrémentielle: elle remplacera d'abord une version, puis la seconde.
À un moment donné, l'équipe de service A décide de déployer une nouvelle version, mais les équipes de service B, C, D et E ne le savent pas. Il existe deux options pour l'arrivée de l'équipe de service A.Réalisera une version incrémentielle: elle remplacera d'abord une version, puis la seconde. Mais il y a une deuxième option: l'équipe trouvera des capacités et des machines supplémentaires , déploiera une nouvelle version, puis commutera le routeur, et la version commencera à travailler sur la production.
Mais il y a une deuxième option: l'équipe trouvera des capacités et des machines supplémentaires , déploiera une nouvelle version, puis commutera le routeur, et la version commencera à travailler sur la production. Dans tous les cas, il y aura presque toujours des problèmes après le déploiement, même si la version est testée. Vous pouvez le tester avec vos mains, il peut être automatisé, vous ne pouvez pas le tester - des problèmes surviendront dans tous les cas. Le moyen le plus simple et le plus correct de les résoudre est de revenir à la version de travail. Ce n'est qu'alors que vous pourrez gérer les dommages, les causes et les corriger.Alors que voulons-nous?Nous n'avons pas besoin de problèmes. Si les clients les trouvent plus rapidement que nous, cela nuira à notre réputation. Par conséquent, nous devons trouver les problèmes plus rapidement que les clients . En étant proactif, nous minimisons les dommages.Dans le même temps, nous voulons accélérer le déploiementafin que cela se fasse rapidement, facilement, par lui-même et sans stress de la part de l'équipe. Les ingénieurs, ingénieurs DevOps et programmeurs doivent être protégés - la sortie de la nouvelle version est stressante. Une équipe n'est pas un consommable, nous nous efforçons d' utiliser rationnellement les ressources humaines .
Dans tous les cas, il y aura presque toujours des problèmes après le déploiement, même si la version est testée. Vous pouvez le tester avec vos mains, il peut être automatisé, vous ne pouvez pas le tester - des problèmes surviendront dans tous les cas. Le moyen le plus simple et le plus correct de les résoudre est de revenir à la version de travail. Ce n'est qu'alors que vous pourrez gérer les dommages, les causes et les corriger.Alors que voulons-nous?Nous n'avons pas besoin de problèmes. Si les clients les trouvent plus rapidement que nous, cela nuira à notre réputation. Par conséquent, nous devons trouver les problèmes plus rapidement que les clients . En étant proactif, nous minimisons les dommages.Dans le même temps, nous voulons accélérer le déploiementafin que cela se fasse rapidement, facilement, par lui-même et sans stress de la part de l'équipe. Les ingénieurs, ingénieurs DevOps et programmeurs doivent être protégés - la sortie de la nouvelle version est stressante. Une équipe n'est pas un consommable, nous nous efforçons d' utiliser rationnellement les ressources humaines .Problèmes de déploiement
Le trafic client est imprévisible . Il est impossible de prédire quand le trafic client sera minime. Nous ne savons pas où et quand les clients commenceront leurs campagnes - peut-être ce soir en Inde et demain à Hong Kong. Compte tenu de la grande différence de temps, un déploiement même à 2 heures du matin ne garantit pas que les clients ne souffriront pas.Problèmes de fournisseur . Les messagers et les fournisseurs sont nos partenaires. Parfois, ils ont des plantages qui provoquent des erreurs lors du déploiement de nouvelles versions.Équipes réparties . Les équipes qui développent le côté client et le backend sont dans des fuseaux horaires différents. Pour cette raison, ils ne peuvent souvent pas s'entendre entre eux.Les centres de données ne peuvent pas être répétés sur scène. Il y a 200 racks dans un centre de données - répéter cela dans le bac à sable ne fonctionnera même pas approximativement.Les temps d'arrêt ne sont pas autorisés! Nous avons un niveau d'accessibilité acceptable (budget d'erreur) lorsque nous travaillons 99,99% du temps, par exemple, et les pourcentages restants sont «le droit de faire des erreurs». Il est impossible d'atteindre une fiabilité à 100%, mais il est important de surveiller en permanence les temps d'arrêt et les temps d'arrêt.Solutions classiques
Écrivez du code sans bugs . Quand j'étais un jeune développeur, les managers m'ont approché avec une demande de sortie sans bugs, mais ce n'est pas toujours possible.Écrivez des tests . Les tests fonctionnent, mais parfois ce n'est pas du tout ce que veut l'entreprise. Gagner de l'argent n'est pas une tâche test.Test sur scène . Au cours des 3,5 années de mon travail chez Infobip, je n'ai jamais vu un état de la scène coïncider au moins partiellement avec la production. Nous avons même essayé de développer cette idée: nous avons d'abord eu une scène, puis une pré-production, puis une pré-production pré-production. Mais cela n'a pas aidé non plus - ils n'ont même pas coïncidé en termes de pouvoir. Avec stage, nous pouvons garantir les fonctionnalités de base, mais nous ne savons pas comment cela fonctionnera sous des charges.La libération est faite par le développeur.C'est une bonne pratique: même si quelqu'un change le nom d'un commentaire, il l'ajoute immédiatement à la production. Cela permet de développer la responsabilité et de ne pas oublier les modifications apportées.Il y a aussi des difficultés supplémentaires. Pour un développeur, cela est stressant - passez beaucoup de temps à tout vérifier manuellement.Versions convenues . Cette option propose généralement la gestion: "Soyons d'accord que vous testerez et ajouterez de nouvelles versions chaque jour." Cela ne fonctionne pas: il y a toujours une équipe qui attend tout le monde ou vice versa.
Nous avons même essayé de développer cette idée: nous avons d'abord eu une scène, puis une pré-production, puis une pré-production pré-production. Mais cela n'a pas aidé non plus - ils n'ont même pas coïncidé en termes de pouvoir. Avec stage, nous pouvons garantir les fonctionnalités de base, mais nous ne savons pas comment cela fonctionnera sous des charges.La libération est faite par le développeur.C'est une bonne pratique: même si quelqu'un change le nom d'un commentaire, il l'ajoute immédiatement à la production. Cela permet de développer la responsabilité et de ne pas oublier les modifications apportées.Il y a aussi des difficultés supplémentaires. Pour un développeur, cela est stressant - passez beaucoup de temps à tout vérifier manuellement.Versions convenues . Cette option propose généralement la gestion: "Soyons d'accord que vous testerez et ajouterez de nouvelles versions chaque jour." Cela ne fonctionne pas: il y a toujours une équipe qui attend tout le monde ou vice versa.Tests de fumée
Une autre façon de résoudre nos problèmes de déploiement. Voyons comment fonctionnent les tests de fumée dans l'exemple précédent, lorsque l'équipe A souhaite déployer une nouvelle version.Tout d'abord, l'équipe déploie une instance en production. Les messages envoyés à l'instance à partir de simulations simulent le trafic réel afin qu'il corresponde au trafic quotidien normal. Si tout va bien, l'équipe bascule la nouvelle version sur le trafic utilisateur.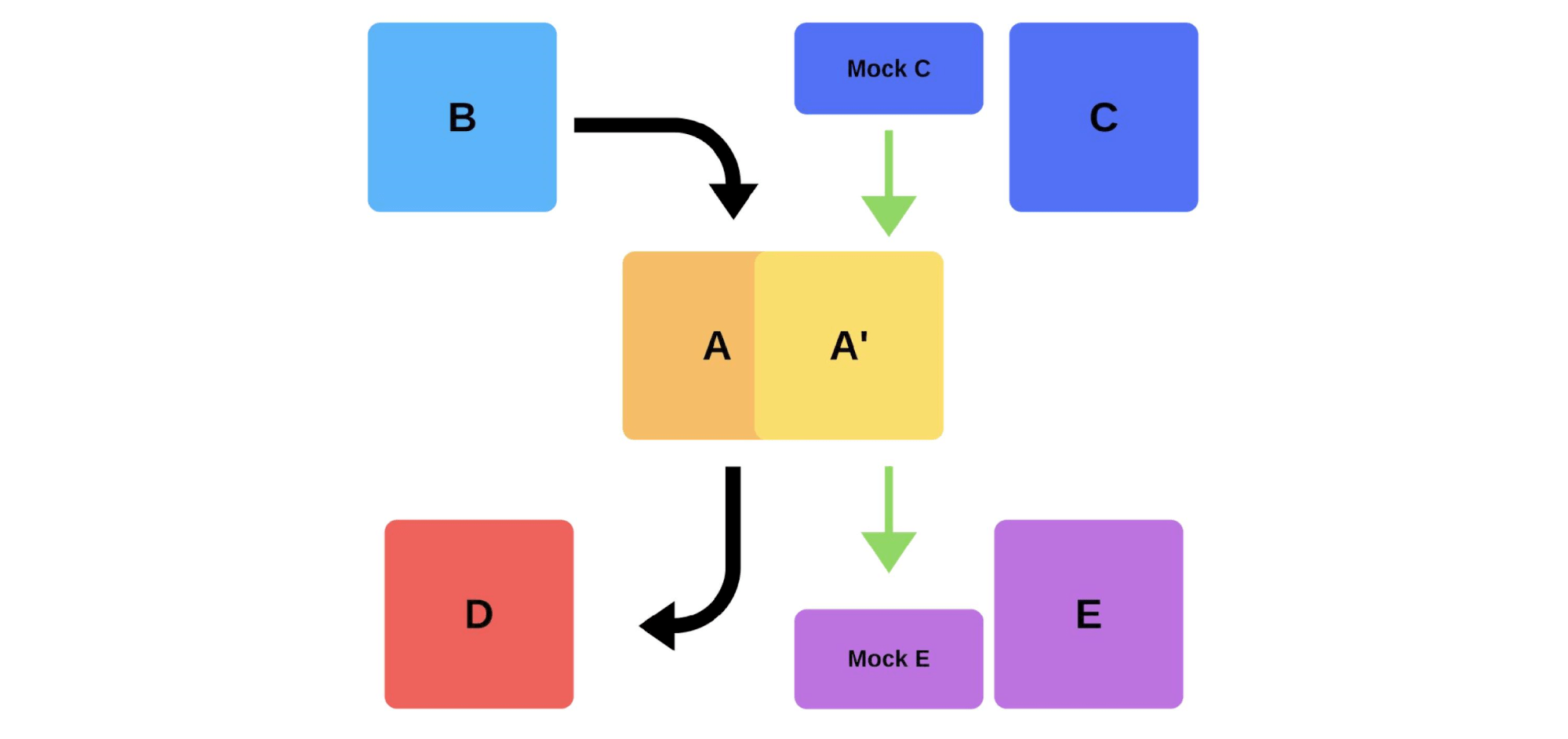 La deuxième option consiste à déployer avec du fer supplémentaire. L'équipe le teste pour la production, puis le commute, et tout fonctionne.
La deuxième option consiste à déployer avec du fer supplémentaire. L'équipe le teste pour la production, puis le commute, et tout fonctionne. Inconvénients des tests de fumée:
Inconvénients des tests de fumée:- Les tests ne sont pas fiables. Où obtenir le même trafic que pour la production? Vous pouvez l'utiliser hier ou il y a une semaine, mais cela ne coïncide pas toujours avec l'actuel.
- C'est difficile à maintenir. Vous devrez prendre en charge les comptes de test, les réinitialiser constamment avant chaque déploiement, lorsque les enregistrements actifs sont envoyés au référentiel. C'est plus difficile que d'écrire un test dans votre bac à sable.
Le seul bonus ici est que vous pouvez vérifier les performances .Libérations des Canaries
En raison des défauts des tests de fumée, nous avons commencé à utiliser des dégagements de canaris.Une pratique similaire à la façon dont les mineurs utilisaient les canaris pour indiquer les niveaux de gaz se sont retrouvés en informatique. Nous lançons un peu de trafic de production réel vers la nouvelle version , tout en essayant de respecter le SLA (Service Level Agreement). Le SLA est notre «droit de faire des erreurs», que nous pouvons utiliser une fois par an (ou pour une autre période). Si tout se passe bien, ajoutez plus de trafic. Sinon, nous retournerons les versions précédentes.
Mise en œuvre et nuances
Comment avons-nous implémenté les versions Canaries? Par exemple, un groupe de clients envoie des messages via notre service.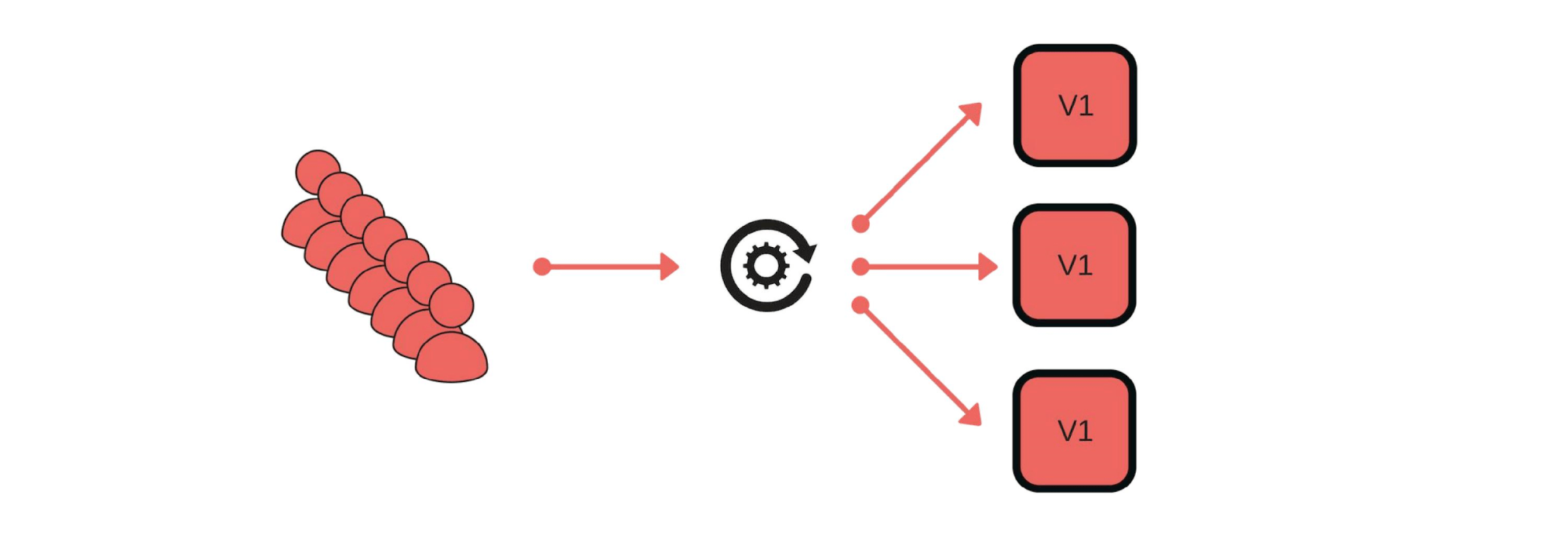 Le déploiement se déroule comme suit: supprimez un nœud de sous l'équilibreur (1), changez la version (2) et démarrez séparément du trafic (3).
Le déploiement se déroule comme suit: supprimez un nœud de sous l'équilibreur (1), changez la version (2) et démarrez séparément du trafic (3). En général, tout le monde dans le groupe sera content, même si un utilisateur n'est pas content. Si tout va bien - changez toutes les versions.
En général, tout le monde dans le groupe sera content, même si un utilisateur n'est pas content. Si tout va bien - changez toutes les versions. Je vais montrer schématiquement à quoi il ressemble pour les microservices dans la plupart des cas.Il existe Service Discovery et deux autres services: S1N1 et S2. Le premier service (S1N1) notifie la découverte de service au démarrage et la découverte de service s'en souvient. Le deuxième service avec deux nœuds (S2N1 et S2N2) notifie également Service Discovery au démarrage.
Je vais montrer schématiquement à quoi il ressemble pour les microservices dans la plupart des cas.Il existe Service Discovery et deux autres services: S1N1 et S2. Le premier service (S1N1) notifie la découverte de service au démarrage et la découverte de service s'en souvient. Le deuxième service avec deux nœuds (S2N1 et S2N2) notifie également Service Discovery au démarrage.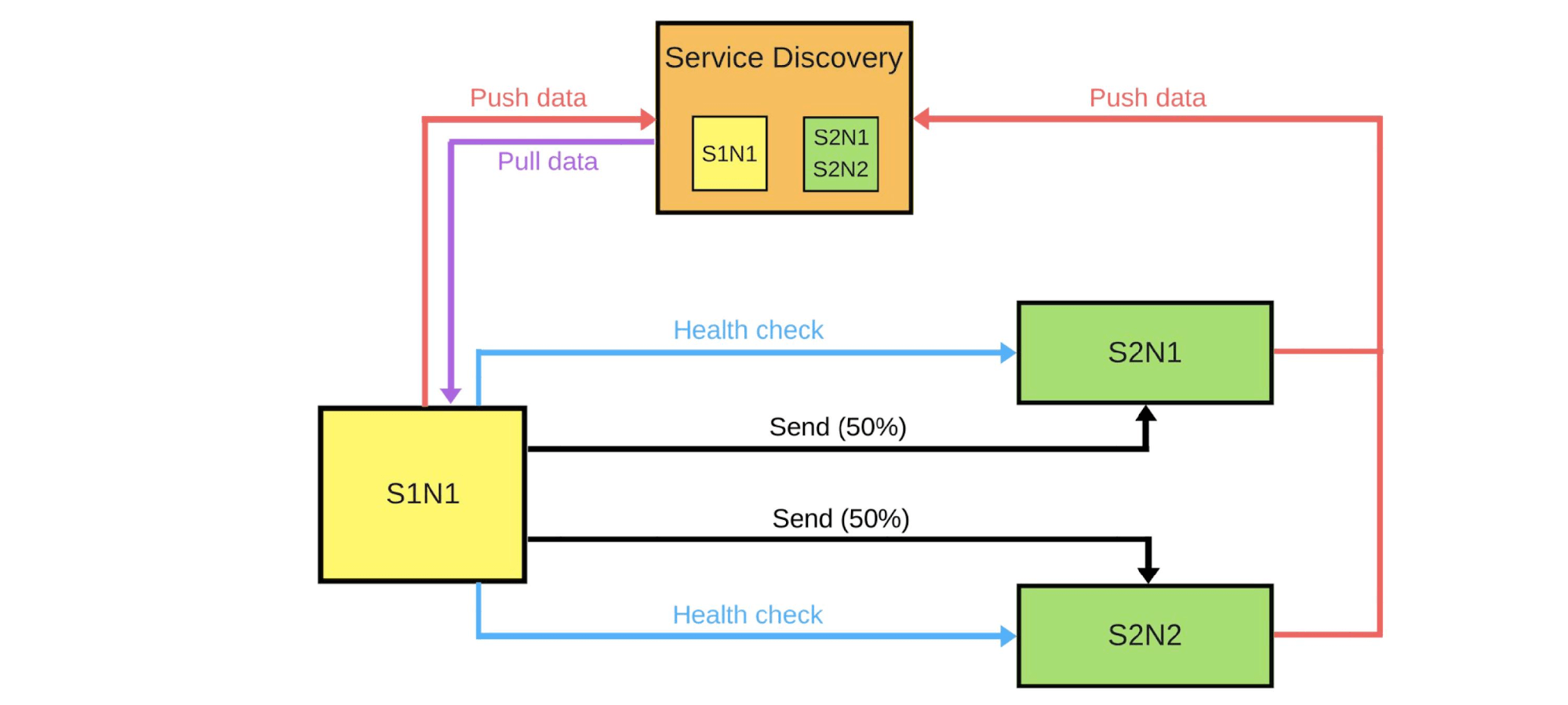 Le deuxième service pour le premier fonctionne comme un serveur. Le premier demande des informations sur ses serveurs à Service Discovery, et lorsqu'il les reçoit, il les recherche et les vérifie («bilan de santé»). Lorsqu'il vérifiera, il leur enverra des messages.Lorsque quelqu'un souhaite déployer une nouvelle version du deuxième service, il indique à Service Discovery que le deuxième nœud sera un nœud canari: moins de trafic lui sera envoyé, car il sera déployé maintenant. Nous supprimons le nœud canari sous l'équilibreur et le premier service ne lui envoie pas de trafic.
Le deuxième service pour le premier fonctionne comme un serveur. Le premier demande des informations sur ses serveurs à Service Discovery, et lorsqu'il les reçoit, il les recherche et les vérifie («bilan de santé»). Lorsqu'il vérifiera, il leur enverra des messages.Lorsque quelqu'un souhaite déployer une nouvelle version du deuxième service, il indique à Service Discovery que le deuxième nœud sera un nœud canari: moins de trafic lui sera envoyé, car il sera déployé maintenant. Nous supprimons le nœud canari sous l'équilibreur et le premier service ne lui envoie pas de trafic.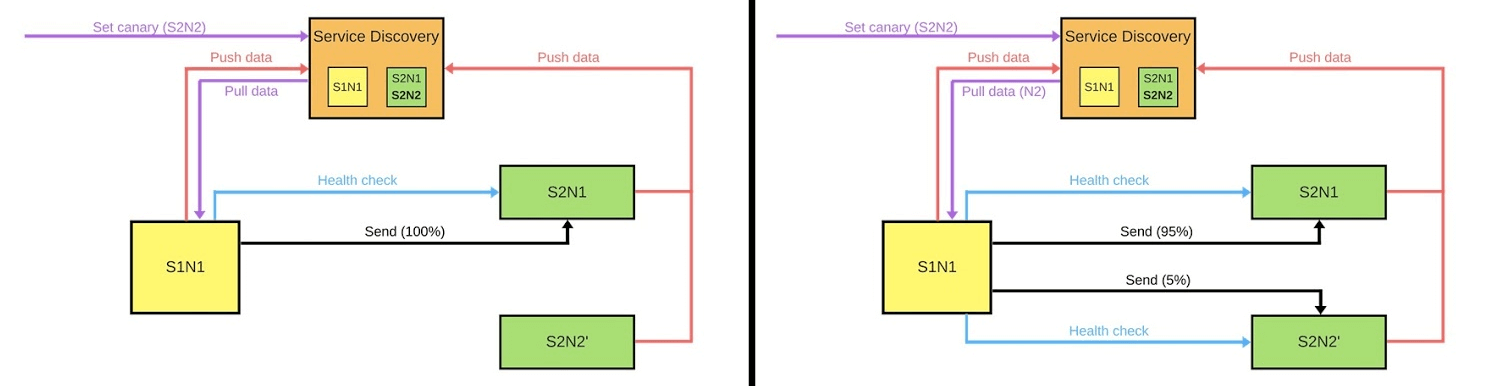 Nous changeons la version et Service Discovery sait que le deuxième nœud est maintenant canari - vous pouvez lui donner moins de charge (5%). Si tout va bien, changez de version, renvoyez la charge et travaillez.Pour mettre en œuvre tout cela, nous avons besoin de:
Nous changeons la version et Service Discovery sait que le deuxième nœud est maintenant canari - vous pouvez lui donner moins de charge (5%). Si tout va bien, changez de version, renvoyez la charge et travaillez.Pour mettre en œuvre tout cela, nous avons besoin de:- équilibrage;
- , , , ;
- , , ;
- — (deployment pipeline).
 C'est la première chose à laquelle nous devons penser. Il existe deux stratégies d'équilibrage.L'option la plus simple est lorsqu'un nœud est toujours canari . Ce nœud obtient toujours moins de trafic et nous commençons à le déployer. En cas de problème, nous comparerons son travail au déploiement et pendant celui-ci. Par exemple, s'il y a 2 fois plus d'erreurs, les dégâts ont augmenté 2 fois.Le nœud Canary est défini pendant le processus de déploiement . Lorsque le déploiement se termine et que nous en supprimons le statut du nœud canari, l'équilibre du trafic sera rétabli. Avec moins de voitures, nous obtenons une distribution honnête.
C'est la première chose à laquelle nous devons penser. Il existe deux stratégies d'équilibrage.L'option la plus simple est lorsqu'un nœud est toujours canari . Ce nœud obtient toujours moins de trafic et nous commençons à le déployer. En cas de problème, nous comparerons son travail au déploiement et pendant celui-ci. Par exemple, s'il y a 2 fois plus d'erreurs, les dégâts ont augmenté 2 fois.Le nœud Canary est défini pendant le processus de déploiement . Lorsque le déploiement se termine et que nous en supprimons le statut du nœud canari, l'équilibre du trafic sera rétabli. Avec moins de voitures, nous obtenons une distribution honnête.surveillance
La pierre angulaire des sorties canaries. Nous devons comprendre exactement pourquoi nous faisons cela et quelles mesures nous voulons collecter.Exemples de mesures que nous collectons de nos services.- , . , . , .
- (latency). , .
- (throughput).
- .
- 95% .
- -: . , , .
Exemples de mesures dans les systèmes de surveillance les plus courants.Compteur Il s'agit d'une valeur croissante, par exemple, le nombre d'erreurs. Il est facile d'interpoler cette métrique et d'étudier le graphique: hier, il y a eu 2 erreurs, et aujourd'hui 500, puis quelque chose s'est mal passé.Le nombre d'erreurs par minute ou par seconde est l'indicateur le plus important qui peut être calculé à l'aide de Counter. Ces données donnent une idée claire du fonctionnement du système à distance. Regardons un exemple de graphique du nombre d'erreurs par seconde pour deux versions d'un système de production. Il y avait peu d'erreurs dans la première version; l'audit n'a peut-être pas fonctionné. Dans la deuxième version, tout est bien pire. Nous pouvons dire avec certitude qu'il y a des problèmes, nous devons donc restaurer cette version.Jauge.Les mesures sont similaires à Counter, mais nous enregistrons des valeurs qui peuvent augmenter ou diminuer. Par exemple, le temps d'exécution de la requête ou la taille de la file d'attente.Le graphique montre un exemple de temps de réponse (latence). Le graphique montre que les versions sont similaires, vous pouvez travailler avec elles. Mais si vous regardez de plus près, vous remarquerez comment la quantité change. Si le temps d'exécution des demandes augmente lorsque des utilisateurs sont ajoutés, il est immédiatement clair qu'il y a des problèmes - ce n'était pas le cas auparavant.
Il y avait peu d'erreurs dans la première version; l'audit n'a peut-être pas fonctionné. Dans la deuxième version, tout est bien pire. Nous pouvons dire avec certitude qu'il y a des problèmes, nous devons donc restaurer cette version.Jauge.Les mesures sont similaires à Counter, mais nous enregistrons des valeurs qui peuvent augmenter ou diminuer. Par exemple, le temps d'exécution de la requête ou la taille de la file d'attente.Le graphique montre un exemple de temps de réponse (latence). Le graphique montre que les versions sont similaires, vous pouvez travailler avec elles. Mais si vous regardez de plus près, vous remarquerez comment la quantité change. Si le temps d'exécution des demandes augmente lorsque des utilisateurs sont ajoutés, il est immédiatement clair qu'il y a des problèmes - ce n'était pas le cas auparavant. Sommaire L'un des indicateurs les plus importants pour les entreprises est le centile. La métrique montre que dans 95% des cas, notre système fonctionne comme nous le voulons. Nous pouvons nous réconcilier s'il y a des problèmes quelque part, parce que nous comprenons la tendance générale à savoir à quel point tout est bon ou mauvais.
Sommaire L'un des indicateurs les plus importants pour les entreprises est le centile. La métrique montre que dans 95% des cas, notre système fonctionne comme nous le voulons. Nous pouvons nous réconcilier s'il y a des problèmes quelque part, parce que nous comprenons la tendance générale à savoir à quel point tout est bon ou mauvais.Outils
ELK Stack . Vous pouvez implémenter Canary en utilisant Elasticsearch - nous y écrivons des erreurs lorsque des événements se produisent. Il suffit d' appeler l'API, vous pouvez obtenir des erreurs à tout moment, et de le comparer avec des segments précédents: GET /applg/_cunt?q=level:errr.Prométhée. Il s'est bien montré dans Infobip. Il vous permet d'implémenter des métriques multidimensionnelles car des étiquettes sont utilisées.Nous pouvons utiliser level, instance, servicepour les combiner dans un seul système. En l'utilisant offset, vous pouvez voir, par exemple, la valeur d'il y a une semaine avec une seule commande GET /api/v1/query?query={query}, où {query}:rate(logback_appender_total{
level="error",
instance=~"$instance"
}[5m] offset $offset_value)
Analyse de version
Il existe plusieurs stratégies de version.Voir les métriques des nœuds canaris uniquement. Une des options les plus simples: déployer une nouvelle version et étudier uniquement le travail. Mais si l'ingénieur à ce moment-là commence à étudier les journaux, rechargeant constamment et nerveusement les pages, cette solution n'est pas différente des autres.Un nœud canari est comparé à tout autre nœud . Il s'agit d'une comparaison avec d'autres instances qui s'exécutent sur un trafic complet. Par exemple, si avec un petit trafic les choses sont pires, ou pas meilleures que dans des cas réels, alors quelque chose ne va pas.Un nœud canari est comparé à lui-même dans le passé. Les nœuds attribués au canari peuvent être comparés aux données historiques. Par exemple, si il y a une semaine, tout allait bien, alors nous pouvons nous concentrer sur ces données afin de comprendre la situation actuelle.Automatisation
Nous voulons libérer les ingénieurs des comparaisons manuelles, il est donc important de mettre en œuvre l'automatisation. Le processus de pipeline de déploiement ressemble généralement à ceci:- nous commençons;
- retirer le nœud sous l'équilibreur;
- définir le nœud canari;
- allumez déjà l'équilibreur avec un trafic limité;
- comparer.
 À ce stade, nous implémentons une comparaison automatique . À quoi cela peut ressembler et pourquoi c'est mieux que de vérifier après le déploiement, nous allons considérer l'exemple de Jenkins.Ceci est le pipeline vers Groovy.
À ce stade, nous implémentons une comparaison automatique . À quoi cela peut ressembler et pourquoi c'est mieux que de vérifier après le déploiement, nous allons considérer l'exemple de Jenkins.Ceci est le pipeline vers Groovy.while (System.currentTimeMillis() < endCanaryTs) {
def isOk = compare(srv, canary, time, base, offset, metrics)
if (isOk) {
sleep DEFAULT SLEEP
} else {
echo "Canary failed, need to revert"
return false
}
}
Ici, dans le cycle que nous avons défini, nous allons comparer le nouveau nœud pendant une heure. Si le processus canari n'a pas encore terminé le processus, nous appelons la fonction. Elle signale que tout va bien ou non: def isOk = compare(srv, canary, time, base, offset, metrics).Si tout va bien - sleep DEFAULT SLEEPpar exemple, pendant une seconde, et continuez. Sinon, nous quittons - le déploiement a échoué.Description de la métrique. Voyons à quoi pourrait ressembler une fonction comparesur l'exemple de DSL.metric(
'errorCounts',
'rate(errorCounts{node=~"$canaryInst"}[5m] offset $offset)',
{ baseValue, canaryValue ->
if (canaryValue > baseValue * 1.3) return false
return true
}
)
Supposons que nous comparons le nombre d'erreurs et que nous voulons connaître le nombre d'erreurs par seconde au cours des 5 dernières minutes.Nous avons deux valeurs: les nœuds de base et les canaris. La valeur du nœud canari est celle actuelle. De base - baseValueest la valeur de tout autre nœud non canarien. Nous comparons les valeurs entre elles selon la formule que nous fixons en fonction de notre expérience et de nos observations. Si la valeur est canaryValuemauvaise, le déploiement a échoué et nous annulons.Pourquoi tout cela est-il nécessaire?L'homme ne peut pas vérifier des centaines et des milliers de mesuressurtout pour le faire rapidement. Une comparaison automatique permet de vérifier toutes les mesures et vous alerte rapidement des problèmes. Le temps de notification est critique: si quelque chose s'est produit au cours des 2 dernières secondes, les dégâts ne seront pas aussi importants que s'ils se sont produits il y a 15 minutes. Jusqu'à ce que quelqu'un remarque un problème, écrit le support et nous pouvons perdre des clients pour annuler le support.Si le processus s'est bien passé et que tout va bien, nous déploierons automatiquement tous les autres nœuds. Les ingénieurs ne font rien pour le moment. Ce n'est que lorsqu'ils exécutent Canary qu'ils décident des mesures à prendre, de la durée de la comparaison, de la stratégie à utiliser. S'il y a des problèmes, nous restaurons automatiquement le nœud canari, travaillons sur les versions précédentes et corrigeons les erreurs que nous avons trouvées. Par métriques, ils sont faciles à trouver et à voir les dégâts de la nouvelle version.
S'il y a des problèmes, nous restaurons automatiquement le nœud canari, travaillons sur les versions précédentes et corrigeons les erreurs que nous avons trouvées. Par métriques, ils sont faciles à trouver et à voir les dégâts de la nouvelle version.Obstacles
Bien sûr, la mise en œuvre n'est pas facile. Tout d'abord, nous avons besoin d'un système de surveillance commun . Les ingénieurs ont leurs propres paramètres, le support et les analystes en ont différents, et l'entreprise en a le troisième. Un système commun est une langue commune parlée par les entreprises et le développement.Il est nécessaire de vérifier en pratique la stabilité des métriques. La vérification permet de comprendre quel est l'ensemble minimal de mesures nécessaires pour garantir la qualité .Comment y parvenir? N'utilisez pas le service canari au moment du déploiement . Nous ajoutons un certain service sur l'ancienne version, qui à tout moment pourra prendre n'importe quel nœud alloué, réduire le trafic sans déploiement. Après avoir comparé: nous étudions les erreurs et recherchons cette ligne lorsque nous atteignons la qualité.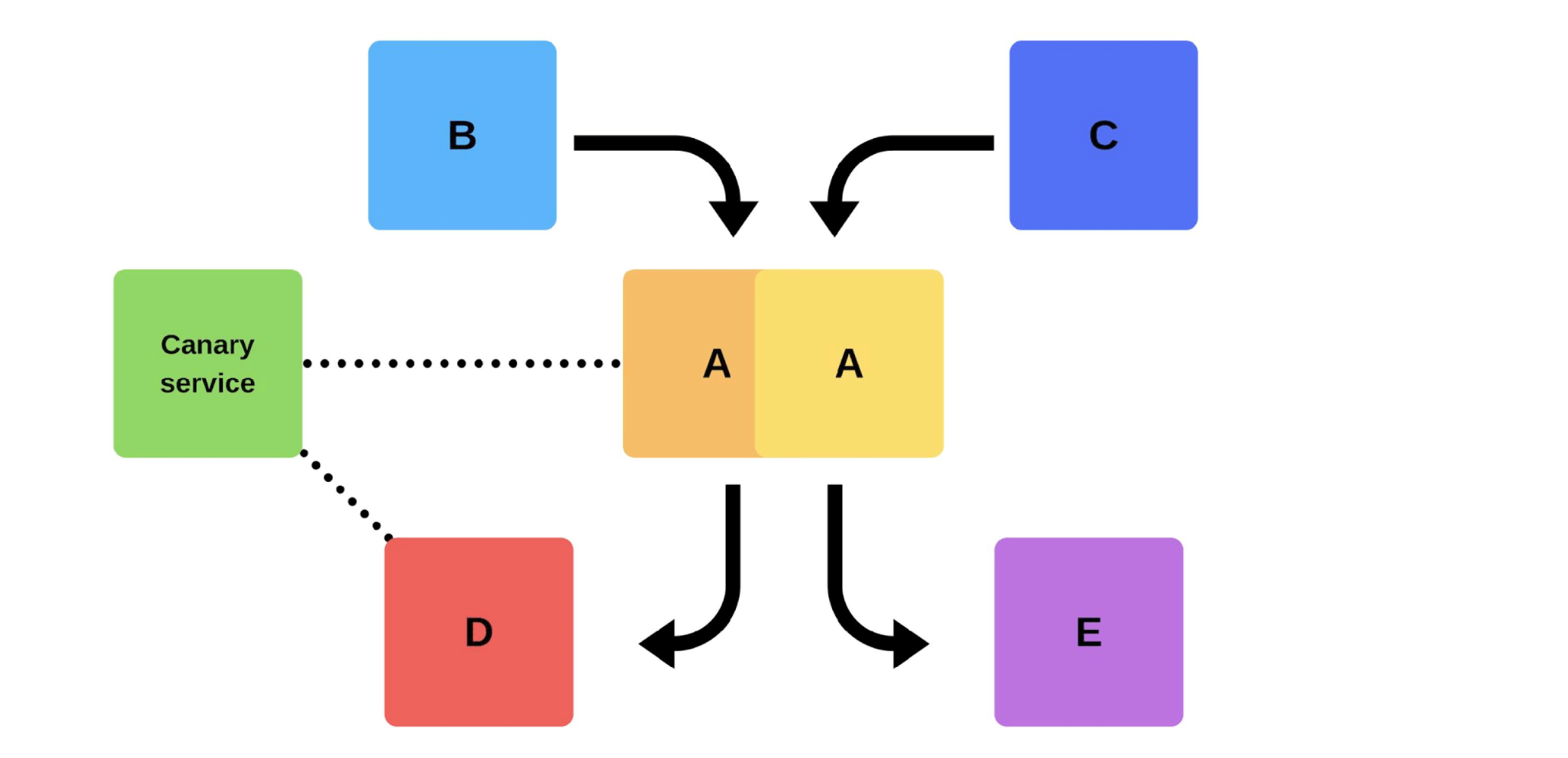
Quel avantage avons-nous tiré des sorties de canaris
Minimisé le pourcentage de dommages causés par les bogues. La plupart des erreurs de déploiement se produisent en raison de l'incohérence de certaines données ou de la priorité. Ces erreurs sont devenues beaucoup plus petites, car nous pouvons résoudre le problème dans les premières secondes.Optimisé le travail des équipes. Les débutants ont le «droit de se tromper»: ils peuvent se déployer en production sans crainte d'erreurs, une initiative supplémentaire apparaît, une incitation au travail. S'ils cassent quelque chose, ce ne sera pas critique et la mauvaise personne ne sera pas renvoyée.Déploiement automatisé . Ce n'est plus un processus manuel, comme auparavant, mais un véritable processus automatisé. Mais cela prend plus de temps.Mesures importantes mises en évidence. Toute l'entreprise, à commencer par les entreprises et les ingénieurs, comprend ce qui est vraiment important dans notre produit, à savoir, par exemple, le flux sortant et l'afflux d'utilisateurs. Nous contrôlons le processus: nous testons des métriques, en introduisons de nouvelles, voyons comment les anciennes fonctionnent pour construire un système qui rendra l'argent plus productif.Nous avons de nombreuses pratiques et systèmes sympas qui nous aident. Malgré cela, nous nous efforçons d'être des professionnels et de faire notre travail efficacement, que nous ayons un système qui nous aidera ou non.— TechLead Conf. , , — .
TechLead Conf 8 9 . , , — , .