Des centaines, des milliers et, dans certains services, des millions de files d'attente, à travers lesquelles une énorme quantité de données passe, tournent sous le capot de notre produit. Tout cela doit être traité d'une manière magique et ne pas être abattu. Dans cet article, je vous dirai quelles approches architecturales nous utilisons à la maison, ayant une pile technologique assez modeste et n'ayant pas un petit centre de données dans notre «garde-manger».
Qu'avons-nous?
Donc, d'une part, nous avons une pile technologique bien connue: Nginx, PHP, PostgreSQL, Redis. D'un autre côté, des dizaines de milliers d'événements se produisent dans notre système chaque minute et, au pic, il peut atteindre des centaines de milliers d'événements. Afin de clarifier ce que sont ces événements et comment nous devons y répondre, je ferai une petite digression sur le produit, après quoi je vous dirai comment nous avons développé le système d'automatisation basé sur les événements.ManyChat est une plateforme d'automatisation marketing. Le propriétaire de la page Facebook peut la connecter à notre plateforme et configurer l'automatisation de l'interaction avec ses abonnés (en d'autres termes, créer un chat bot). L'automatisation consiste généralement en de nombreuses chaînes d'interactions qui peuvent ne pas être interconnectées. Au sein de ces chaînes d'automatisation, certaines actions peuvent se produire avec l'abonné, par exemple, en attribuant une étiquette spécifique dans le système ou en affectant / modifiant la valeur d'un champ dans la carte d'un abonné. Ces données vous permettent en outre de segmenter l'audience et de créer une interaction plus pertinente avec les abonnés de la page.Nos clients souhaitaient vraiment une automatisation basée sur les événements - la possibilité de personnaliser l'exécution d'une action lorsqu'un événement spécifique est déclenché au sein de l'abonné (par exemple, le balisage).Puisqu'un événement déclencheur peut fonctionner à partir de différentes chaînes d'automatisation, il est important qu'il y ait un seul point de configuration pour toutes les actions basées sur les événements du côté client, et de notre côté traitement, il devrait y avoir un seul bus qui traite le changement dans le contexte de l'abonné à partir de différents points d'automatisation.Dans notre système, il existe un bus commun par lequel passent tous les événements survenant avec les abonnés. C'est plus de 500 millions d'événements par jour. Leur traitement est assez délicat - il s'agit d'un enregistrement dans l'entrepôt de données, de sorte que le propriétaire de la page a la possibilité de voir historiquement tout ce qui est arrivé à ses abonnés.Il semblerait que pour mettre en œuvre un système basé sur les événements, nous ayons déjà tout, et il nous suffit d'intégrer notre logique métier dans le traitement d'un bus d'événements commun. Mais nous avons certaines exigences pour notre nouveau système:- Nous ne voulons pas obtenir des performances dégradées dans le traitement du bus d'événements principal
- Il est important pour nous de maintenir l'ordre de traitement des messages dans le nouveau système, car cela peut être lié à la logique métier du client qui configure l'automatisation
- Évitez l'effet des voisins bruyants lorsque des pages actives avec un grand nombre d'abonnés obstruent la file d'attente et bloquent le traitement des événements des "petites" pages
Si nous intégrons le traitement de notre logique dans le traitement d'un bus d'événements commun, nous obtiendrons une dégradation sérieuse des performances, car nous devrons vérifier la conformité de chaque événement avec l'automatisation configurée. Dans le cadre de la configuration de l'automatisation, certains filtres peuvent être appliqués (par exemple, démarrer l'automatisation lorsqu'un événement est déclenché uniquement pour les clientes de plus de 30 ans). Autrement dit, lors du traitement des événements dans le bus principal, une énorme quantité de demandes supplémentaires à la base de données sera traitée, et une logique plutôt lourde commencera également à comparer le contexte actuel de l'abonné avec les paramètres d'automatisation. Cette option ne nous convient pas, nous sommes donc allés plus loin.
Organisation d'une cascade de files d'attente
Étant donné que notre logique métier associée au système basé sur les événements est très bien séparable de la logique de traitement des événements du bus principal, nous décidons de placer les types d'événements dont nous avons besoin depuis le bus partagé dans une file d'attente distincte pour un traitement ultérieur dans un flux de données séparé. Ainsi, nous supprimons le problème associé à la dégradation des performances dans le traitement du bus d'événements principal.Au même stade, nous décidons de ce qu'il serait cool de transférer des événements vers la prochaine file d'attente en cascade pour placer ces événements dans des files d'attente distinctes pour chaque bot. Ainsi, isoler l'activité de chaque bot dans le cadre de son tour, ce qui nous permet de résoudre le problème lié à l'effet des voisins bruyants.Notre diagramme de flux de données ressemble maintenant à ceci: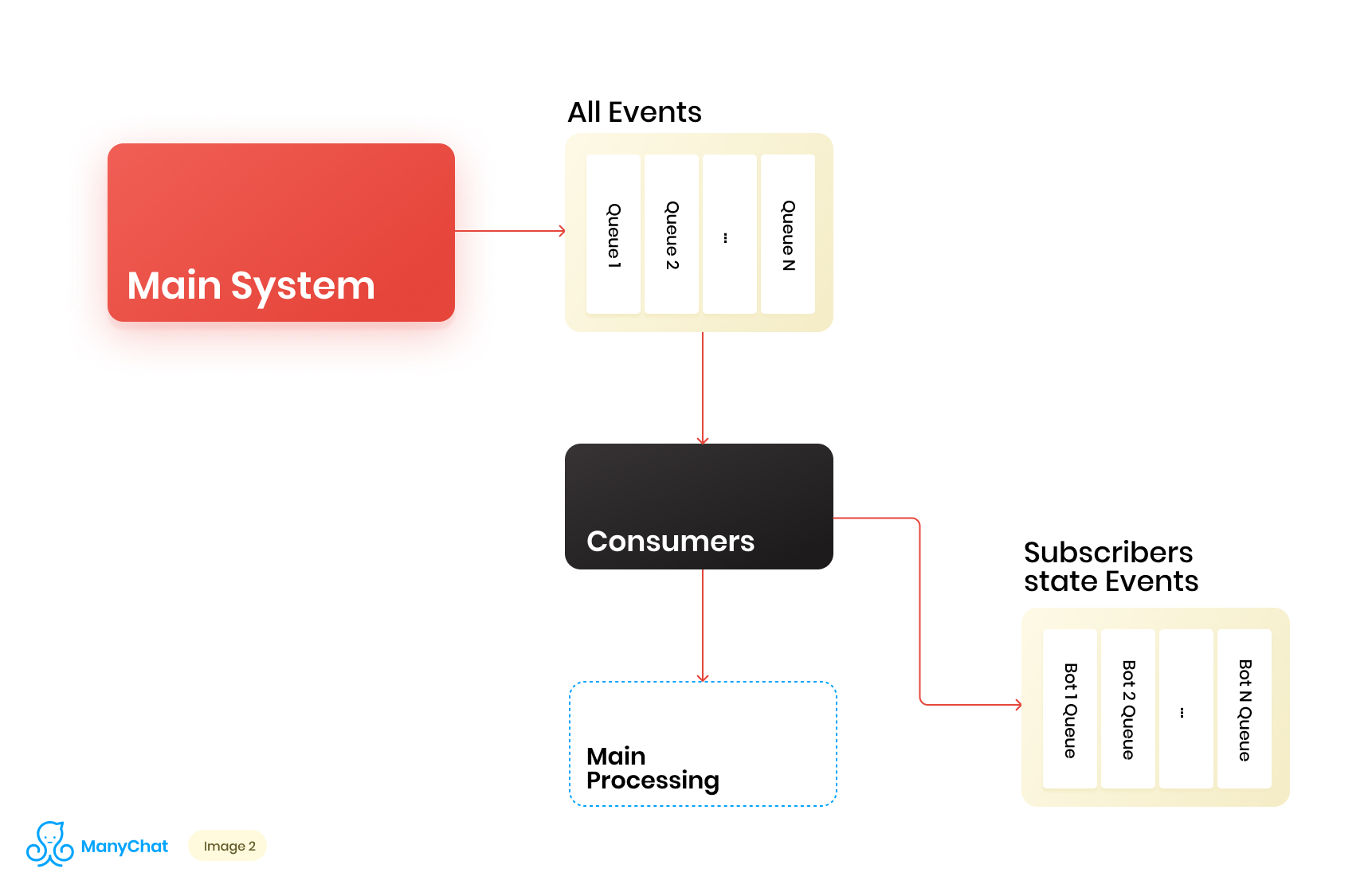 Cependant, pour que ce schéma fonctionne, nous devons résoudre le problème du traitement de nouvelles files d'attente.Il y a plus de 1 million de pages connectées (bots) sur notre plate-forme, ce qui signifie que nous pouvons potentiellement obtenir ~ 1 million de files d'attente dans notre schéma, uniquement au niveau de la couche basée sur les événements. D'un point de vue technique, cela ne nous fait pas peur. En tant que serveur de file d'attente, nous utilisons Redis avec ses types de données standard, tels que LIST, SORTED SET et autres. Cela signifie qui chaque file d'attente est la structure de données standard pour Redis en RAM, qui peut être créée ou supprimée à la volée, ce qui nous permet de gérer facilement et de manière flexible le grand nombre de files d'attente dans notre système. Je parlerai plus en détail de l'utilisation de Redis comme serveur de files d'attente avec des détails techniques dans un article séparé, mais pour l'instant, revenons à notre architecture.Il est clair que chaque bot a une activité différente et que la probabilité d'obtenir 1 million de files d'attente dans l'état «besoin de traiter maintenant» est extrêmement faible. Mais à un moment donné, il est tout à fait possible que nous ayons quelques dizaines de milliers de files d'attente actives qui nécessitent un traitement. Le nombre de ces files d'attente est en constante évolution. Ces files d'attente elles-mêmes changent également, certaines sont complètement soustraites et supprimées, certaines sont créées dynamiquement et remplies d'événements pour le traitement. En conséquence, nous devons trouver un moyen efficace de les gérer.
Cependant, pour que ce schéma fonctionne, nous devons résoudre le problème du traitement de nouvelles files d'attente.Il y a plus de 1 million de pages connectées (bots) sur notre plate-forme, ce qui signifie que nous pouvons potentiellement obtenir ~ 1 million de files d'attente dans notre schéma, uniquement au niveau de la couche basée sur les événements. D'un point de vue technique, cela ne nous fait pas peur. En tant que serveur de file d'attente, nous utilisons Redis avec ses types de données standard, tels que LIST, SORTED SET et autres. Cela signifie qui chaque file d'attente est la structure de données standard pour Redis en RAM, qui peut être créée ou supprimée à la volée, ce qui nous permet de gérer facilement et de manière flexible le grand nombre de files d'attente dans notre système. Je parlerai plus en détail de l'utilisation de Redis comme serveur de files d'attente avec des détails techniques dans un article séparé, mais pour l'instant, revenons à notre architecture.Il est clair que chaque bot a une activité différente et que la probabilité d'obtenir 1 million de files d'attente dans l'état «besoin de traiter maintenant» est extrêmement faible. Mais à un moment donné, il est tout à fait possible que nous ayons quelques dizaines de milliers de files d'attente actives qui nécessitent un traitement. Le nombre de ces files d'attente est en constante évolution. Ces files d'attente elles-mêmes changent également, certaines sont complètement soustraites et supprimées, certaines sont créées dynamiquement et remplies d'événements pour le traitement. En conséquence, nous devons trouver un moyen efficace de les gérer.Traitement d'un énorme pool de files d'attente
Nous avons donc un tas de files d'attente. À chaque instant, il peut y avoir un montant aléatoire. Une condition importante pour le traitement de chaque file d'attente, qui a été mentionnée au début de son article, est que les événements de chaque page doivent être traités de manière strictement séquentielle. Cela signifie qu'à un moment donné, chaque file d'attente ne peut pas être traitée par plusieurs travailleurs afin d'éviter des problèmes de concurrence.Mais faire le rapport des files d'attente aux gestionnaires 1: 1 est une tâche douteuse. Le nombre de files d'attente change constamment, à la fois vers le haut et vers le bas. Le nombre de gestionnaires en cours d'exécution n'est pas non plus infini, au moins nous avons une limitation de la part du système d'exploitation et du matériel, et nous ne voudrions pas que les travailleurs restent inactifs dans les files d'attente vides. Pour résoudre le problème d'interaction entre les gestionnaires et les files d'attente, nous avons implémenté un système à tour de rôle pour traiter notre pool de files d'attente.Et ici, la ligne de contrôle est venue à notre secours. Lorsque l'événement est transféré du bus partagé vers la file d'attente basée sur les événements d'un bot particulier, nous mettons également l'identifiant de cette file d'attente de bot dans la file d'attente de contrôle. La file d'attente de contrôle stocke uniquement les identificateurs des files d'attente qui se trouvent dans le pool et doivent être traitées. Seules des valeurs uniques sont stockées dans la file d'attente de contrôle, c'est-à-dire que le même identifiant de file d'attente de robots ne sera stocké qu'une seule fois dans la file d'attente de contrôle, quel que soit le nombre de fois qu'il y est écrit. Sur Redis, cela est implémenté à l'aide de la structure de données SORTED SET.De plus, nous pouvons distinguer un certain nombre de travailleurs, dont chacun recevra de la file d'attente de contrôle son identifiant de la file d'attente de robots pour traitement. Ainsi, chaque travailleur traitera indépendamment le bloc de la file d'attente qui lui est assigné, après avoir traité le bloc, retourner l'identifiant de la file d'attente traitée au contrôle, le renvoyant ainsi à notre round robin. L'essentiel est de ne pas oublier de fournir le tout avec des verrous, afin que deux travailleurs ne puissent pas traiter la même file d'attente de robots en parallèle. Cette situation est possible si l'identifiant du bot entre dans la file d'attente de contrôle alors qu'il est déjà en cours de traitement par le travailleur. Pour les verrous, nous utilisons également Redis comme clé: magasin de valeurs avec TTL.Lorsque nous prenons une tâche avec un identifiant de file d'attente de bot de la file d'attente de contrôle, nous mettons un verrou TTL sur la file d'attente prise et commençons à la traiter. Si l'autre consommateur prend la tâche avec la file d'attente qui est déjà en cours de traitement à partir de la file d'attente de contrôle, il ne pourra pas se verrouiller, retourner la tâche dans la file d'attente de contrôle et recevoir la tâche suivante. Après avoir traité la file d'attente des robots par le consommateur, il supprime le verrou et passe à la file d'attente de contrôle pour la tâche suivante.Le schéma final est le suivant:
Lorsque l'événement est transféré du bus partagé vers la file d'attente basée sur les événements d'un bot particulier, nous mettons également l'identifiant de cette file d'attente de bot dans la file d'attente de contrôle. La file d'attente de contrôle stocke uniquement les identificateurs des files d'attente qui se trouvent dans le pool et doivent être traitées. Seules des valeurs uniques sont stockées dans la file d'attente de contrôle, c'est-à-dire que le même identifiant de file d'attente de robots ne sera stocké qu'une seule fois dans la file d'attente de contrôle, quel que soit le nombre de fois qu'il y est écrit. Sur Redis, cela est implémenté à l'aide de la structure de données SORTED SET.De plus, nous pouvons distinguer un certain nombre de travailleurs, dont chacun recevra de la file d'attente de contrôle son identifiant de la file d'attente de robots pour traitement. Ainsi, chaque travailleur traitera indépendamment le bloc de la file d'attente qui lui est assigné, après avoir traité le bloc, retourner l'identifiant de la file d'attente traitée au contrôle, le renvoyant ainsi à notre round robin. L'essentiel est de ne pas oublier de fournir le tout avec des verrous, afin que deux travailleurs ne puissent pas traiter la même file d'attente de robots en parallèle. Cette situation est possible si l'identifiant du bot entre dans la file d'attente de contrôle alors qu'il est déjà en cours de traitement par le travailleur. Pour les verrous, nous utilisons également Redis comme clé: magasin de valeurs avec TTL.Lorsque nous prenons une tâche avec un identifiant de file d'attente de bot de la file d'attente de contrôle, nous mettons un verrou TTL sur la file d'attente prise et commençons à la traiter. Si l'autre consommateur prend la tâche avec la file d'attente qui est déjà en cours de traitement à partir de la file d'attente de contrôle, il ne pourra pas se verrouiller, retourner la tâche dans la file d'attente de contrôle et recevoir la tâche suivante. Après avoir traité la file d'attente des robots par le consommateur, il supprime le verrou et passe à la file d'attente de contrôle pour la tâche suivante.Le schéma final est le suivant: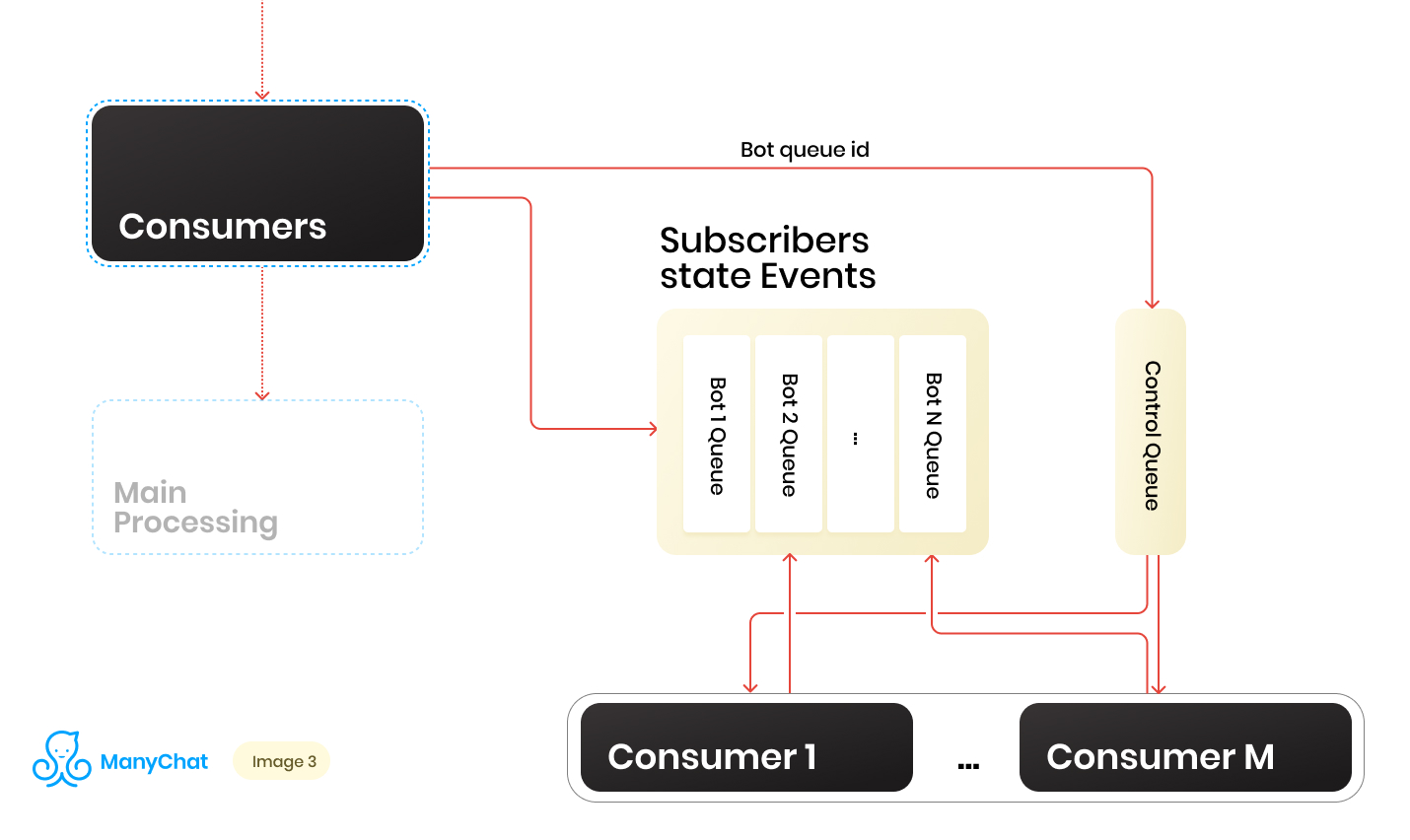 En conséquence, avec le schéma actuel, nous avons résolu les principaux problèmes identifiés:
En conséquence, avec le schéma actuel, nous avons résolu les principaux problèmes identifiés:- Dégradation des performances dans le bus d'événements principal
- Violation de gestion des événements
- L'effet des voisins bruyants
Comment gérer la charge dynamique?
Le schéma fonctionne, mais nous y avons un nombre fixe de consommateurs pour un nombre dynamique de files d'attente. Evidemment, avec cette approche, on va s'affaisser dans le traitement des files d'attente à chaque fois que leur nombre augmente fortement. Il semble que ce serait bien que nos travailleurs démarrent ou s'éteignent dynamiquement en cas de besoin. Ce serait également bien si cela ne compliquait pas considérablement le processus de déploiement du nouveau code. À de tels moments, les mains sont très pressantes d'aller écrire à votre gestionnaire de processus. À l'avenir, nous l'avons fait, mais cette histoire est différente.En pensant, nous avons décidé, pourquoi ne pas utiliser à nouveau tous les outils familiers et familiers. Nous avons donc obtenu notre API interne, qui fonctionnait sur un ensemble standard de NGINX + PHP-FPM. En conséquence, nous pouvons remplacer notre pool fixe de travailleurs par des API, et laisser NGINX + PHP-FPM résoudre et gérer les travailleurs nous-mêmes, et il nous suffit d'avoir entre la file d'attente de contrôle et notre API interne un seul consommateur de contrôle, qui enverra des identificateurs de file d'attente à notre API à traitement, et la file d'attente elle-même sera traitée dans le travailleur généré par PHP-FPM.Le nouveau schéma était le suivant: Il est beau, mais notre consommateur de contrôle fonctionne dans un seul thread et notre API fonctionne de manière synchrone. Cela signifie que le consommateur se bloque à chaque fois pendant que PHP-FPM broie une file d'attente. Cela ne nous convient pas.
Il est beau, mais notre consommateur de contrôle fonctionne dans un seul thread et notre API fonctionne de manière synchrone. Cela signifie que le consommateur se bloque à chaque fois pendant que PHP-FPM broie une file d'attente. Cela ne nous convient pas.Rendre notre API asynchrone
Mais que se passe-t-il si nous pouvions envoyer une tâche à notre API et la laisser y mettre à jour la logique métier, et notre consommateur de contrôle suivra la tâche suivante dans la file d'attente de contrôle, après quoi elle sera ramenée dans l'API, etc. À peine dit que c'était fait.L'implémentation prend quelques lignes de code, et la preuve de concept ressemble à ceci:class Api {
public function actionDoSomething()
{
$data = $_POST;
$this->dropFPMSession();
}
protected function dropFPMSession()
{
ignore_user_abort(true);
ob_end_flush();
flush();
@session_write_close();
fastcgi_finish_request();
}
}
Dans la méthode dropFPMSession (), nous rompons la connexion avec le client, lui donnant une réponse de 200, après quoi nous pouvons effectuer toute logique lourde en post-traitement. Le client dans notre cas est le consommateur de contrôle. Il est important pour lui de disperser rapidement les tâches de la file d'attente de contrôle dans le traitement sur l'API et de savoir que la tâche a atteint l'API.En utilisant cette approche, nous avons décollé un tas de maux de tête associés au contrôle dynamique des consommateurs et à leur mise à l'échelle automatique.Plus évolutif
En conséquence, l'architecture de notre sous-système a commencé à se composer de trois couches: couche de données, processus et API interne. Dans le même temps, les informations transitent par tous les flux de données concernant le bot auquel l'événement / la tâche traité appartient. De toute évidence, nous pouvons utiliser notre identifiant de clé / bot pour le partage, tout en continuant de faire évoluer notre système horizontalement.Si nous imaginons notre architecture comme une unité solide, cela ressemblera à ceci: après avoir augmenté le nombre de ces unités, nous pouvons placer un équilibreur mince devant elles, qui dispersera nos événements / tâches dans les unités nécessaires, en fonction de la clé de partitionnement.
avoir augmenté le nombre de ces unités, nous pouvons placer un équilibreur mince devant elles, qui dispersera nos événements / tâches dans les unités nécessaires, en fonction de la clé de partitionnement. Ainsi, nous obtenons une grande marge pour la mise à l'échelle horizontale de notre système.Lors de la mise en œuvre de la logique métier, vous ne devez pas oublier le concept de sécurité des threads, sinon vous pouvez obtenir des résultats inattendus.Un tel schéma avec des cascades de files d'attente et la suppression de la logique métier lourde dans le traitement asynchrone est utilisé dans plusieurs parties du système depuis plus de deux ans. La charge pendant cette période pour chacun des sous-systèmes a augmenté des dizaines de fois, et la mise en œuvre proposée nous permet d'évoluer facilement et rapidement. Dans le même temps, nous continuons à travailler sur notre pile principale, sans l'élargir avec de nouveaux outils / langages et sans augmenter, surchargeant ainsi l'introduction et le support de nouveaux outils.
Ainsi, nous obtenons une grande marge pour la mise à l'échelle horizontale de notre système.Lors de la mise en œuvre de la logique métier, vous ne devez pas oublier le concept de sécurité des threads, sinon vous pouvez obtenir des résultats inattendus.Un tel schéma avec des cascades de files d'attente et la suppression de la logique métier lourde dans le traitement asynchrone est utilisé dans plusieurs parties du système depuis plus de deux ans. La charge pendant cette période pour chacun des sous-systèmes a augmenté des dizaines de fois, et la mise en œuvre proposée nous permet d'évoluer facilement et rapidement. Dans le même temps, nous continuons à travailler sur notre pile principale, sans l'élargir avec de nouveaux outils / langages et sans augmenter, surchargeant ainsi l'introduction et le support de nouveaux outils.