Il y a quelques mois, nous avons annoncé expliquer.tensor.ru , un service public d'analyse et de visualisation des plans de requête PostgreSQL.Au cours du passé, vous l'avez déjà utilisé plus de 6000 fois, mais l'une des fonctions pratiques pourrait passer inaperçue - ce sont des indices structurels qui ressemblent à ceci: écoutez-les et vos demandes "deviendront lisses et soyeuses". :)Mais sérieusement, bon nombre des situations qui rendent la demande lente et «gloutonne» en termes de ressources sont typiques et peuvent être reconnues par la structure et les données du plan .Dans ce cas, chaque développeur individuel n'aura pas à chercher seul une option d'optimisation, en s'appuyant uniquement sur son expérience - nous pouvons lui dire ce qui se passe ici, quelle pourrait être la raison et comment aborder la solution . Ce que nous avons fait.
écoutez-les et vos demandes "deviendront lisses et soyeuses". :)Mais sérieusement, bon nombre des situations qui rendent la demande lente et «gloutonne» en termes de ressources sont typiques et peuvent être reconnues par la structure et les données du plan .Dans ce cas, chaque développeur individuel n'aura pas à chercher seul une option d'optimisation, en s'appuyant uniquement sur son expérience - nous pouvons lui dire ce qui se passe ici, quelle pourrait être la raison et comment aborder la solution . Ce que nous avons fait. Examinons de plus près ces cas - comment ils sont déterminés et quelles recommandations ils conduisent.Pour une meilleure compréhension du sujet, vous pouvez d'abord écouter le bloc correspondant de mon rapport sur PGConf.Russia 2020 , puis seulement passer à une analyse détaillée de chaque exemple:
Examinons de plus près ces cas - comment ils sont déterminés et quelles recommandations ils conduisent.Pour une meilleure compréhension du sujet, vous pouvez d'abord écouter le bloc correspondant de mon rapport sur PGConf.Russia 2020 , puis seulement passer à une analyse détaillée de chaque exemple:# 1: index "sous-tri"
Quand surgit
Montrez la dernière facture du client "LLC Bell".Comment reconnaître
-> Limit
-> Sort
-> Index [Only] Scan [Backward] | Bitmap Heap Scan
Recommandations
Utilisez l'index utilisé pour trier les champs .Exemple:CREATE TABLE tbl AS
SELECT
generate_series(1, 100000) pk
, (random() * 1000)::integer fk_cli;
CREATE INDEX ON tbl(fk_cli);
SELECT
*
FROM
tbl
WHERE
fk_cli = 1
ORDER BY
pk DESC
LIMIT 1;
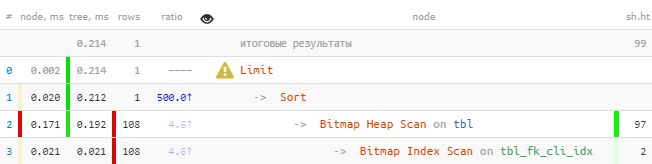 [regardez expliquez.tensor.ru] Vouspouvez immédiatement remarquer que l'index a soustrait plus de 100 entrées, qui ont ensuite été triées, puis la seule a été laissée.Nous fixons:
[regardez expliquez.tensor.ru] Vouspouvez immédiatement remarquer que l'index a soustrait plus de 100 entrées, qui ont ensuite été triées, puis la seule a été laissée.Nous fixons:DROP INDEX tbl_fk_cli_idx;
CREATE INDEX ON tbl(fk_cli, pk DESC);
 [regardez expliquez.tensor.ru]Même avec un échantillon aussi primitif - 8,5 fois plus rapide et 33 fois moins de lectures . L'effet sera d'autant plus visible que vous aurez de «faits» pour chaque valeur
[regardez expliquez.tensor.ru]Même avec un échantillon aussi primitif - 8,5 fois plus rapide et 33 fois moins de lectures . L'effet sera d'autant plus visible que vous aurez de «faits» pour chaque valeur fk.Je note qu'un tel index ne fonctionnera pas comme "préfixe" pas pire que le précédent pour les autres requêtes avec fk, où pkil n'y a pas eu de tri et il n'y en a pas (pour plus de détails, voir mon article sur la recherche d'index inefficaces ). En particulier, il fournira un support normal pour une clé étrangère explicite dans ce domaine.# 2: intersection d'index (BitmapAnd)
Quand surgit
Afficher tous les contrats du client LLC Kolokolchik conclus au nom de NAO Buttercup.Comment reconnaître
-> BitmapAnd
-> Bitmap Index Scan
-> Bitmap Index Scan
Recommandations
Créez un index composite pour les champs à la fois à partir de la source ou développez l'un des champs existants à partir du second.Exemple:CREATE TABLE tbl AS
SELECT
generate_series(1, 100000) pk
, (random() * 100)::integer fk_org
, (random() * 1000)::integer fk_cli;
CREATE INDEX ON tbl(fk_org);
CREATE INDEX ON tbl(fk_cli);
SELECT
*
FROM
tbl
WHERE
(fk_org, fk_cli) = (1, 999);
 [regardez expliquez.tensor.ru]Correct:
[regardez expliquez.tensor.ru]Correct:DROP INDEX tbl_fk_org_idx;
CREATE INDEX ON tbl(fk_org, fk_cli);
 [regardez expliquez.tensor.ru]Ici, le gain est moindre, car Bitmap Heap Scan est assez efficace en soi. Mais toujours 7 fois plus rapides et 2,5 fois moins de lectures .
[regardez expliquez.tensor.ru]Ici, le gain est moindre, car Bitmap Heap Scan est assez efficace en soi. Mais toujours 7 fois plus rapides et 2,5 fois moins de lectures .# 3: Pool d'index (BitmapOr)
Quand surgit
Affichez les 20 premières demandes de traitement «propres» ou non affectées, et leur priorité.Comment reconnaître
-> BitmapOr
-> Bitmap Index Scan
-> Bitmap Index Scan
Recommandations
Utilisez UNION [ALL] pour combiner des sous-requêtes pour chacun des blocs de conditions OR.Exemple:CREATE TABLE tbl AS
SELECT
generate_series(1, 100000) pk
, CASE
WHEN random() < 1::real/16 THEN NULL
ELSE (random() * 100)::integer
END fk_own;
CREATE INDEX ON tbl(fk_own, pk);
SELECT
*
FROM
tbl
WHERE
fk_own = 1 OR
fk_own IS NULL
ORDER BY
pk
, (fk_own = 1) DESC
LIMIT 20;
 [regardez expliquez.tensor.ru]Correct:
[regardez expliquez.tensor.ru]Correct:(
SELECT
*
FROM
tbl
WHERE
fk_own = 1
ORDER BY
pk
LIMIT 20
)
UNION ALL
(
SELECT
*
FROM
tbl
WHERE
fk_own IS NULL
ORDER BY
pk
LIMIT 20
)
LIMIT 20;
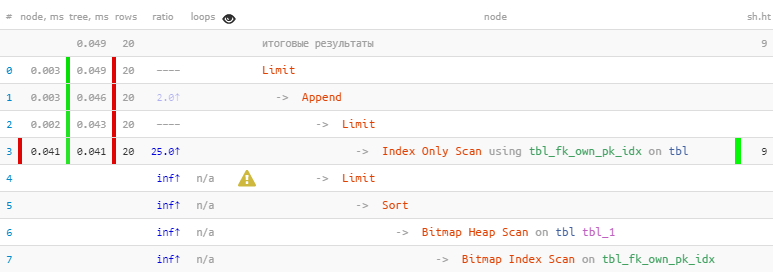 [regardez expliquez.tensor.ru]Nous avons profité du fait que les 20 enregistrements nécessaires ont été immédiatement reçus dans le premier bloc, donc le second, avec le Bitmap Heap Scan le plus «cher», n'a même pas été effectué - en conséquence , 22 fois plus rapide, dans 44 fois moins de lectures !
[regardez expliquez.tensor.ru]Nous avons profité du fait que les 20 enregistrements nécessaires ont été immédiatement reçus dans le premier bloc, donc le second, avec le Bitmap Heap Scan le plus «cher», n'a même pas été effectué - en conséquence , 22 fois plus rapide, dans 44 fois moins de lectures !Une histoire plus détaillée sur cette méthode d'optimisation à l' aide d'exemples spécifiques peut être trouvée dans les articles de PostgreSQL Antipatterns: JOIN JOIN et OR nuisibles et PostgreSQL Antipatterns: un récit sur le raffinement itératif de la recherche par nom, ou «Optimisation ici et là» .
Une version généralisée de la sélection ordonnée par plusieurs clés (et pas seulement par la paire const / NULL) a été envisagée dans l'article SQL HowTo: nous écrivons la boucle while directement dans la requête, ou «Elementary three-way» .
# 4: lire beaucoup d'excès
Quand surgit
En règle générale, cela se produit si vous souhaitez «attacher un autre filtre» à une demande existante."Et vous n'avez pas la même chose, mais avec des boutons de nacre ?" film "Diamond Hand"
Par exemple, en modifiant la tâche ci-dessus, affichez les 20 premières applications «critiques» les plus anciennes pour le traitement, quel que soit leur objectif.Comment reconnaître
-> Seq Scan | Bitmap Heap Scan | Index [Only] Scan [Backward]
&& 5 × rows < RRbF -- >80%
&& loops × RRbF > 100 -- 100
Recommandations
Créez un index personnalisé [plus] avec une clause WHERE ou incluez des champs supplémentaires dans l'index.Si la condition de filtre est «statique» pour vos tâches - c'est-à-dire qu'elle n'implique pas d'élargir la liste de valeurs à l'avenir - il est préférable d'utiliser l'index WHERE. Différents statuts booléens / enum entrent bien dans cette catégorie.
Si la condition de filtre peut prendre différentes valeurs , il est préférable d'étendre l'index avec ces champs - comme dans la situation avec BitmapAnd ci-dessus.
Exemple:CREATE TABLE tbl AS
SELECT
generate_series(1, 100000) pk
, CASE
WHEN random() < 1::real/16 THEN NULL
ELSE (random() * 100)::integer
END fk_own
, (random() < 1::real/50) critical;
CREATE INDEX ON tbl(pk);
CREATE INDEX ON tbl(fk_own, pk);
SELECT
*
FROM
tbl
WHERE
critical
ORDER BY
pk
LIMIT 20;
 [regardez expliquez.tensor.ru]Correct:
[regardez expliquez.tensor.ru]Correct:CREATE INDEX ON tbl(pk)
WHERE critical;
 [regardezexpliquez.tensor.ru ] Comme vous pouvez le voir, le filtrage a complètement disparu du plan, et la demande est devenue 5 fois plus rapide .
[regardezexpliquez.tensor.ru ] Comme vous pouvez le voir, le filtrage a complètement disparu du plan, et la demande est devenue 5 fois plus rapide .# 5: Table clairsemée
Quand surgit
Diverses tentatives pour créer leur propre file d'attente de tâches de traitement lorsqu'un grand nombre de mises à jour / suppressions d'enregistrements sur la table conduisent à une situation d'un grand nombre d'enregistrements "morts".Comment reconnaître
-> Seq Scan | Bitmap Heap Scan | Index [Only] Scan [Backward]
&& loops × (rows + RRbF) < (shared hit + shared read) × 8
-- 1KB
&& shared hit + shared read > 64
Recommandations
Effectuez manuellement VACUUM [FULL] manuellement ou réalisez des tests fréquents sous vide adéquats en affinant ses paramètres, y compris pour une table spécifique .Dans la plupart des cas, ces problèmes sont causés par des requêtes mal structurées lors d'appels à partir de la logique métier, telles que celles abordées dans PostgreSQL Antipatterns: combat des hordes de «morts» .
Mais vous devez comprendre que même VACUUM FULL peut ne pas toujours aider. Pour de tels cas, vous devez vous familiariser avec l'algorithme de l'article DBA: lorsque VACUUM passe, nous nettoyons la table manuellement .
# 6: lecture à partir du milieu de l'index
Quand surgit
Il semble qu’ils n’aient pas beaucoup lu, et tous par index, et qu’ils n’aient rien filtré de plus - mais de toute façon, beaucoup plus de pages ont été lues que nous le souhaiterions.Comment reconnaître
-> Index [Only] Scan [Backward]
&& loops × (rows + RRbF) < (shared hit + shared read) × 8
-- 1KB
&& shared hit + shared read > 64
Recommandations
Examinez attentivement la structure de l'index utilisé et les champs clés spécifiés dans la demande - très probablement, une partie de l'index n'est pas spécifiée . Très probablement, vous devrez créer un index similaire, mais sans champs de préfixe ou apprendre à itérer sur leurs valeurs .Exemple:CREATE TABLE tbl AS
SELECT
generate_series(1, 100000) pk
, (random() * 100)::integer fk_org
, (random() * 1000)::integer fk_cli;
CREATE INDEX ON tbl(fk_org, fk_cli);
SELECT
*
FROM
tbl
WHERE
fk_cli = 999
LIMIT 20;
 [regardez expliquez.tensor.ru]Il semble que tout va bien, même par index, mais d'une manière suspecte - pour chacun des 20 enregistrements lus, j'ai dû soustraire 4 pages de données, 32 Ko par enregistrement - n'est-ce pas en gras? Oui, et le nom de l'index est suggestif. Nous fixons:
[regardez expliquez.tensor.ru]Il semble que tout va bien, même par index, mais d'une manière suspecte - pour chacun des 20 enregistrements lus, j'ai dû soustraire 4 pages de données, 32 Ko par enregistrement - n'est-ce pas en gras? Oui, et le nom de l'index est suggestif. Nous fixons:tbl_fk_org_fk_cli_idxCREATE INDEX ON tbl(fk_cli);
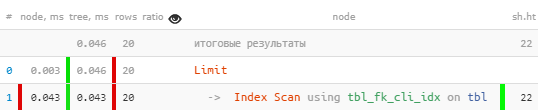 [regardez expliquez.tensor.ru]Soudain - 10 fois plus rapide et 4 fois moins lu !
[regardez expliquez.tensor.ru]Soudain - 10 fois plus rapide et 4 fois moins lu !D'autres exemples de situations d'utilisation inefficace des index peuvent être vus dans l'article DBA: Find Useless Indexes .
# 7: CTE × CTE
Quand surgit
Dans la requête, nous avons tapé les CTE «gras» de différentes tables, puis décidé de faire entre eux JOIN.Le cas est pertinent pour les versions inférieures à v12 ou les demandes de WITH MATERIALIZED.Comment reconnaître
-> CTE Scan
&& loops > 10
&& loops × (rows + RRbF) > 10000
-- CTE
Recommandations
Analysez soigneusement la demande - le CTE est-il nécessaire ici ? Si tout de même, alors appliquez le "déchirement" dans hstore / json selon le modèle décrit dans PostgreSQL Antipatterns: frappez le dictionnaire avec un JOIN lourd .# 8: échange sur disque (écrit temporairement)
Quand surgit
Le traitement ponctuel (tri ou personnalisation) d'un grand nombre d'enregistrements ne rentre pas dans la mémoire allouée à cet effet.Comment reconnaître
-> *
&& temp written > 0
Recommandations
Si la quantité de mémoire utilisée par l'opération ne dépasse pas largement la valeur définie du paramètre work_mem , cela vaut la peine de l'ajuster. Vous pouvez immédiatement dans la configuration pour tout le monde, mais vous pouvez passer SET [LOCAL]pour une demande / transaction spécifique.Exemple:SHOW work_mem;
SELECT
random()
FROM
generate_series(1, 1000000)
ORDER BY
1;
 [regardez expliquez.tensor.ru]Correct:
[regardez expliquez.tensor.ru]Correct:SET work_mem = '128MB';
 [regardezexpliquez.tensor.ru ] Pour des raisons évidentes, si seulement la mémoire est utilisée, pas un disque, alors la requête sera exécutée beaucoup plus rapidement. Dans le même temps, une partie de la charge du disque dur est également supprimée.Mais vous devez comprendre qu'allouer beaucoup de mémoire ne fonctionne pas toujours non plus - ce ne sera pas suffisant pour tout le monde.
[regardezexpliquez.tensor.ru ] Pour des raisons évidentes, si seulement la mémoire est utilisée, pas un disque, alors la requête sera exécutée beaucoup plus rapidement. Dans le même temps, une partie de la charge du disque dur est également supprimée.Mais vous devez comprendre qu'allouer beaucoup de mémoire ne fonctionne pas toujours non plus - ce ne sera pas suffisant pour tout le monde.# 9: Statistiques non pertinentes
Quand surgit
Ils se sont déversés beaucoup à la fois dans la base de données, mais n'ont pas réussi à les chasser ANALYZE.Comment reconnaître
-> Seq Scan | Bitmap Heap Scan | Index [Only] Scan [Backward]
&& ratio >> 10
Recommandations
Faites de même ANALYZE.Cette situation est décrite plus en détail dans PostgreSQL Antipatterns: les statistiques sont partout .
# 10: «quelque chose s'est mal passé»
Quand surgit
Il y avait une attente d'un verrou imposé par une demande concurrente, ou il n'y avait pas suffisamment de ressources matérielles CPU / hyperviseur.Comment reconnaître
-> *
&& (shared hit / 8K) + (shared read / 1K) < time / 1000
-- RAM hit = 64MB/s, HDD read = 8MB/s
&& time > 100ms -- ,
Recommandations
Utilisez un système externe pour surveiller le serveur pour les verrous ou la consommation anormale de ressources. A propos de notre version de l'organisation de ce processus pour des centaines de serveurs, nous en avons déjà parlé ici et ici .