 Bonjour, je m'appelle Andrey Schukin, j'aide les grandes entreprises à migrer leurs services et systèmes vers le cloud CROC. En collaboration avec des collègues de Southbridge, qui organise des cours Kubernetes au centre de formation Slerm, nous avons récemment organisé un webinaire pour nos clients.J'ai décidé de prendre des documents d'une excellente conférence de Pavel Selivanov et d'écrire un article pour ceux qui commencent tout juste à travailler avec des outils de provisioning cloud et ne savent pas par où commencer. Par conséquent, je vais parler de la pile de technologies utilisées dans notre formation et notre production de CROC Cloud. Parlons des approches modernes de la gestion de l'infrastructure, d'un tas de composants Packer, Terraform et Ansible, ainsi que de l'outil Kubeadm avec lequel nous allons installer.Sous la coupe, il y aura beaucoup de texte et de configurations. Il y a beaucoup de matériel, j'ai donc ajouté la navigation post. Nous avons également préparé un petit référentiel où nous avons mis tout ce dont nous avions besoin pour notre déploiement de formation.Ne donnez pas de noms aux poulets.Les gâteaux au four sont plus sains que les frits.Nous allumons le four. PackerTerraform - infrastructure en tant que codeLancez lastructure du cluster Terraform KubernetesKubeadmRepository avec tous les fichiers
Bonjour, je m'appelle Andrey Schukin, j'aide les grandes entreprises à migrer leurs services et systèmes vers le cloud CROC. En collaboration avec des collègues de Southbridge, qui organise des cours Kubernetes au centre de formation Slerm, nous avons récemment organisé un webinaire pour nos clients.J'ai décidé de prendre des documents d'une excellente conférence de Pavel Selivanov et d'écrire un article pour ceux qui commencent tout juste à travailler avec des outils de provisioning cloud et ne savent pas par où commencer. Par conséquent, je vais parler de la pile de technologies utilisées dans notre formation et notre production de CROC Cloud. Parlons des approches modernes de la gestion de l'infrastructure, d'un tas de composants Packer, Terraform et Ansible, ainsi que de l'outil Kubeadm avec lequel nous allons installer.Sous la coupe, il y aura beaucoup de texte et de configurations. Il y a beaucoup de matériel, j'ai donc ajouté la navigation post. Nous avons également préparé un petit référentiel où nous avons mis tout ce dont nous avions besoin pour notre déploiement de formation.Ne donnez pas de noms aux poulets.Les gâteaux au four sont plus sains que les frits.Nous allumons le four. PackerTerraform - infrastructure en tant que codeLancez lastructure du cluster Terraform KubernetesKubeadmRepository avec tous les fichiersNe donnez pas de noms aux poulets
 Il existe de nombreux concepts différents de gestion des infrastructures. L'un d'eux s'appelle Pets vs. Le bétail, c'est-à-dire "les animaux de compagnie contre le bétail". Ce concept décrit deux approches opposées de l'infrastructure.Imaginez que nous avons un chien préféré. Nous prenons soin d'elle, l'emmenons chez le vétérinaire, peignons la fourrure, et en général, elle est unique parmi de nombreux autres chiens.Dans un autre cas, nous avons un poulailler. Nous prenons également soin des poulets, nourrissons, chauffons et essayons de créer les conditions les plus confortables. Néanmoins, les poulets sont une ressource plutôt sans visage pour nous, qui remplit sa fonction de ponte, et au mieux nous les désignons comme "ce noir en poudre qui picore toujours le ciment". Si le poulet cesse de pondre des œufs ou se casse la patte, il est fort probable qu'il nous fournira simplement un délicieux bouillon pour le déjeuner. En fait, nous ne nous soucions pas du sort d'un poulet en particulier, mais du poulailler dans son ensemble en tant que chaîne de production.En informatique, une approche similaire a commencé à être appliquée dès l'apparition des outils qui abaissaient le seuil d'entrée pour les ingénieurs et permettaient de déployer et de maintenir des clusters complexes en mode entièrement automatique.Auparavant, nous avions un petit nombre de serveurs qui étaient surveillés, réglés manuellement et entretenus de toutes les manières possibles. Lors de la surveillance, les journaux des serveurs Cthulhu, Aylith et Dagon ont clignoté. Traditions.Ensuite, la virtualisation est fermement entrée dans nos vies, et les noms des œuvres de Lovecraft et Star Trek ont cédé la place au «vlg-vlt-vault01.company.ru» plus utilitaire. Il y a beaucoup de serveurs, mais nous avons quand même augmenté les services plus ou moins manuellement, éliminant les problèmes sur chaque machine si nécessaire.Désormais, l'approche de la maintenance de l'infrastructure coïncide complètement avec la programmation. Nous ajoutons un autre niveau d'abstraction et cessons de nous soucier des nœuds individuels. Chacun a un index sans visage au lieu d'un nom, et en cas de problème, la machine virtuelle tue et monte simplement à partir de l'instantané de travail. Il existe des outils qui vous permettent de mettre en œuvre cette approche. Dans notre cas, le premier outil est le CROC Cloud, le second est Terraform.
Il existe de nombreux concepts différents de gestion des infrastructures. L'un d'eux s'appelle Pets vs. Le bétail, c'est-à-dire "les animaux de compagnie contre le bétail". Ce concept décrit deux approches opposées de l'infrastructure.Imaginez que nous avons un chien préféré. Nous prenons soin d'elle, l'emmenons chez le vétérinaire, peignons la fourrure, et en général, elle est unique parmi de nombreux autres chiens.Dans un autre cas, nous avons un poulailler. Nous prenons également soin des poulets, nourrissons, chauffons et essayons de créer les conditions les plus confortables. Néanmoins, les poulets sont une ressource plutôt sans visage pour nous, qui remplit sa fonction de ponte, et au mieux nous les désignons comme "ce noir en poudre qui picore toujours le ciment". Si le poulet cesse de pondre des œufs ou se casse la patte, il est fort probable qu'il nous fournira simplement un délicieux bouillon pour le déjeuner. En fait, nous ne nous soucions pas du sort d'un poulet en particulier, mais du poulailler dans son ensemble en tant que chaîne de production.En informatique, une approche similaire a commencé à être appliquée dès l'apparition des outils qui abaissaient le seuil d'entrée pour les ingénieurs et permettaient de déployer et de maintenir des clusters complexes en mode entièrement automatique.Auparavant, nous avions un petit nombre de serveurs qui étaient surveillés, réglés manuellement et entretenus de toutes les manières possibles. Lors de la surveillance, les journaux des serveurs Cthulhu, Aylith et Dagon ont clignoté. Traditions.Ensuite, la virtualisation est fermement entrée dans nos vies, et les noms des œuvres de Lovecraft et Star Trek ont cédé la place au «vlg-vlt-vault01.company.ru» plus utilitaire. Il y a beaucoup de serveurs, mais nous avons quand même augmenté les services plus ou moins manuellement, éliminant les problèmes sur chaque machine si nécessaire.Désormais, l'approche de la maintenance de l'infrastructure coïncide complètement avec la programmation. Nous ajoutons un autre niveau d'abstraction et cessons de nous soucier des nœuds individuels. Chacun a un index sans visage au lieu d'un nom, et en cas de problème, la machine virtuelle tue et monte simplement à partir de l'instantané de travail. Il existe des outils qui vous permettent de mettre en œuvre cette approche. Dans notre cas, le premier outil est le CROC Cloud, le second est Terraform.Les gâteaux au four sont plus sains que frits
 Dans la gestion des infrastructures, il existe un contraste entre les deux approches Fried vs Cuit, c'est-à-dire «frit contre cuit».L'approche de Fried implique que vous avez une image vanilla du système d'exploitation, par exemple, CentOS 7. Ensuite, après le déploiement du système d'exploitation, nous utilisons le système de gestion de la configuration afin d'amener le système à l'état cible. Par exemple, en utilisant Ansible, Chef, Puppet ou SaltStack.Tout fonctionne bien, surtout quand il n'y a pas beaucoup de serveurs. Lorsqu'un déploiement massif est nécessaire, nous sommes confrontés à des problèmes de performances. Des centaines de serveurs commencent à dévorer de manière synchrone les ressources réseau, le CPU, la RAM et les IOPS dans le processus de déploiement de nombreux nouveaux packages. De plus, ce processus peut être retardé assez longtemps. Bref, le circuit est absolument opérationnel, mais pas si intéressant du point de vue de la minimisation des temps d'arrêt lors d'accidents.L'approche Baked implique que vous avez des images OS prêtes à l'emploi sur lesquelles vous avez déjà installé tous les packages nécessaires, configuré la configuration et tout le reste. À la sortie, nous avons un modèle d'instantané abstrait, affiné pour les performances de certaines fonctions. Le déploiement de l'infrastructure à partir de ces images cuites prend beaucoup moins de temps et réduit les temps d'arrêt au minimum. Une idéologie très similaire est utilisée dans les images Docker multicouches, dans lesquelles personne ne se tape inutilement les mains. Cloué le conteneur - en a soulevé un nouveau.
Dans la gestion des infrastructures, il existe un contraste entre les deux approches Fried vs Cuit, c'est-à-dire «frit contre cuit».L'approche de Fried implique que vous avez une image vanilla du système d'exploitation, par exemple, CentOS 7. Ensuite, après le déploiement du système d'exploitation, nous utilisons le système de gestion de la configuration afin d'amener le système à l'état cible. Par exemple, en utilisant Ansible, Chef, Puppet ou SaltStack.Tout fonctionne bien, surtout quand il n'y a pas beaucoup de serveurs. Lorsqu'un déploiement massif est nécessaire, nous sommes confrontés à des problèmes de performances. Des centaines de serveurs commencent à dévorer de manière synchrone les ressources réseau, le CPU, la RAM et les IOPS dans le processus de déploiement de nombreux nouveaux packages. De plus, ce processus peut être retardé assez longtemps. Bref, le circuit est absolument opérationnel, mais pas si intéressant du point de vue de la minimisation des temps d'arrêt lors d'accidents.L'approche Baked implique que vous avez des images OS prêtes à l'emploi sur lesquelles vous avez déjà installé tous les packages nécessaires, configuré la configuration et tout le reste. À la sortie, nous avons un modèle d'instantané abstrait, affiné pour les performances de certaines fonctions. Le déploiement de l'infrastructure à partir de ces images cuites prend beaucoup moins de temps et réduit les temps d'arrêt au minimum. Une idéologie très similaire est utilisée dans les images Docker multicouches, dans lesquelles personne ne se tape inutilement les mains. Cloué le conteneur - en a soulevé un nouveau.Nous démarrons le four. Emballeur
 Dans notre infrastructure, nous utilisons plusieurs produits Hashicorp, dont certains se sont avérés extrêmement réussis. Commençons notre magie avec la préparation et la cuisson d'une image à l'aide de l'outil Packer.Packer utilise un modèle JSON, c'est-à-dire des fichiers de modèle qui contiennent une description de ce qui doit être obtenu en tant que machine virtuelle (VM) «cuite». Après avoir créé le modèle, le fichier est transféré vers Packer et les autorisations nécessaires pour créer le serveur dans le cloud sont configurées.Packer vous permet de générer des VM localement dans KVM, VirtualBox, Vagrant, AWS, GCP, Alibaba Cloud, OpenStack, etc. Il est pratique de travailler avec Packer dans le cloud CROC, car il implémente des interfaces AWS, c'est-à-dire tous les outils qui sont écrits pour AWS, travaillez avec le CROC Cloud.Après avoir défini les modèles nécessaires, Packer lève VM CROC dans le Cloud, attend qu'il démarre, puis le «fournisseur» entre dans le travail - provisioner: un utilitaire qui doit terminer la préparation de l'image. Dans notre cas, il s'agit d'Ansible, bien que Packer puisse fonctionner avec d'autres options.Lorsque la machine virtuelle est prête, Packer crée son image et la place dans le cloud CROC afin que d'autres machines virtuelles puissent être lancées à partir de la même image.
Dans notre infrastructure, nous utilisons plusieurs produits Hashicorp, dont certains se sont avérés extrêmement réussis. Commençons notre magie avec la préparation et la cuisson d'une image à l'aide de l'outil Packer.Packer utilise un modèle JSON, c'est-à-dire des fichiers de modèle qui contiennent une description de ce qui doit être obtenu en tant que machine virtuelle (VM) «cuite». Après avoir créé le modèle, le fichier est transféré vers Packer et les autorisations nécessaires pour créer le serveur dans le cloud sont configurées.Packer vous permet de générer des VM localement dans KVM, VirtualBox, Vagrant, AWS, GCP, Alibaba Cloud, OpenStack, etc. Il est pratique de travailler avec Packer dans le cloud CROC, car il implémente des interfaces AWS, c'est-à-dire tous les outils qui sont écrits pour AWS, travaillez avec le CROC Cloud.Après avoir défini les modèles nécessaires, Packer lève VM CROC dans le Cloud, attend qu'il démarre, puis le «fournisseur» entre dans le travail - provisioner: un utilitaire qui doit terminer la préparation de l'image. Dans notre cas, il s'agit d'Ansible, bien que Packer puisse fonctionner avec d'autres options.Lorsque la machine virtuelle est prête, Packer crée son image et la place dans le cloud CROC afin que d'autres machines virtuelles puissent être lancées à partir de la même image.Structure Base.json
Au début du fichier, il y a une section dans laquelle les variables sont déclarées:Divulgacher"variables" : {
"source_ami_name": "{{env SOURCE_AMI_NAME}}",
"ami_name": "{{env AMI_NAME}}",
"instance_type": "{{env INSTANCE_TYPE}}",
"kubernetes_version": "{{env KUBERNETES_VERSION}}",
"docker_version": "{{env DOCKER_VERSION}}",
"subnet_id": "",
"availability_zone": "",
},
L'ensemble principal de ces variables sera défini à partir du fichier settings.json. Et ces variables qui changent fréquemment sont plus pratiques à définir à partir de la console lors du démarrage de Packer et de la création d'une nouvelle image.Voici la section Builders:Divulgacher"builders" : [
{
"type": "amazon-ebs",
"region": "croc",
"skip_region_validation": true,
"custom_endpoint_ec2": "https://api.cloud.croc.ru",
"source_ami": "",
"source_ami_filter": {
"filters": {
"name": "{{user `source_ami_name`}}"
"state": "available",
"virtualization-type": "kvm-virtio"
},
...
Les nuages cibles et la méthode de démarrage de la machine virtuelle sont décrits ici. Veuillez noter que dans ce cas, le type amazon-ebs est déclaré, mais pour le fonctionnement de Packer avec le CROC Cloud, l'adresse correspondante dans custom_endpoint_ec2 est définie. Notre infrastructure dispose d'une API qui est presque entièrement compatible avec Amazon Web Services, donc si vous avez des développements prêts à l'emploi pour cette plate-forme, vous n'aurez pour la plupart à spécifier qu'un point d'entrée d'API personnalisé - api.cloud.croc.ru dans notre exemple.Il convient de noter séparément la section source_ami_filter. Ici, l'image initiale de la VM est définie, dans laquelle les modifications nécessaires seront apportées. Cependant, Packer nécessite une AMI pour cette image, c'est-à-dire son identifiant aléatoire. Étant donné que cet identifiant est rarement connu à l'avance et change à chaque mise à jour, l'AMI source n'est pas définie comme une valeur spécifique, mais comme une variable source_ami_filter. Dans ce cas, le paramètre déterminant du filtre est le nom de l'image. Ce nom est défini dans les variables via le fichier settings.json.Ensuite, les paramètres de la VM sont définis: le type d'instance, le processeur, la taille de la mémoire, l'espace alloué, etc. sont spécifiés:Divulgacher"instance_type": "{{user `instance_type`}}",
"launch_block_device_mappings": [
{
"device_name": "disk1",
"volume_type": "io1",
"volume_size": "8",
"iops": "1000",
"delete_on_termination": "true"
}
],
Voici les paramètres de connexion à cette machine virtuelle dans base.json:Divulgacher"availability_zone": "{{user `availability_zone`}}",
"subnet_id": "{{user `subnet_id`}}",
"associate_public_ip_address": true,
"ssh_username": "ec2-user",
"ami_name": "{{user `ami_name`}}"
Il est important de noter ici le paramètre subnet_id. Il doit être défini manuellement, car sans spécifier le sous-réseau VM dans le CROC Cloud, il est impossible de créer.Un autre paramètre qui nécessite une préparation préalable est associ_public_ip_address. Vous devez sélectionner une adresse IP blanche, car après avoir créé le VM Packer commencera à appliquer les paramètres nécessaires via Ansible. Dans ce cas, Ansible se connecte à la machine virtuelle via SSH, ce qui nécessite une adresse IP blanche ou un VPN.La dernière section est les Provisioners:Divulgacher"provisioners": [
{
"type": "ansible",
"playbook_file": "playbook.yml",
"extra_arguments": [
"--extra-vars",
"kubernetes_version={{user `kubernetes_version`}}",
"--extra-vars",
"docker_version={{user `docker_version`}}"
]
}
]
Ce sont les fournisseurs, c'est-à-dire les utilitaires avec lesquels Packer configure le serveur. Dans ce cas, un fournisseur de type ansible est utilisé. Voici le paramètre playbook_file, qui définit les rôles Ansible et les hôtes sur lesquels les rôles spécifiés seront appliqués. Des options supplémentaires extra_arguments sont présentées ci-dessous, qui, au démarrage d'Ansible, transmettent les versions de Kubernetes et Docker.Préparation du CROC Cloud
 En plus de nos fichiers de configuration, nous devons faire quelques choses depuis le côté du panneau de contrôle du cloud pour que toute la magie fonctionne. Nous devons sélectionner une IP blanche et créer un sous-réseau de travail, que nous utiliserons lors du déploiement.
En plus de nos fichiers de configuration, nous devons faire quelques choses depuis le côté du panneau de contrôle du cloud pour que toute la magie fonctionne. Nous devons sélectionner une IP blanche et créer un sous-réseau de travail, que nous utiliserons lors du déploiement.- Cliquez sur Mettre en surbrillance l'adresse. Packer trouvera automatiquement l'adresse IP blanche souhaitée.
- Cliquez sur Créer un sous-réseau et spécifiez un sous-réseau et un masque.
- Copiez l'ID de sous-réseau.
- Insérez cette valeur dans le paramètre subnet_id de la commande de démarrage Packer.
 Exécutez ensuite Packer. Il trouve l'image de la machine virtuelle d'origine, la déploie dans le cloud CROC et y exécute le rôle Ansible. La nouvelle VM est visible dans le CROC Cloud dans la section "Instances".
Exécutez ensuite Packer. Il trouve l'image de la machine virtuelle d'origine, la déploie dans le cloud CROC et y exécute le rôle Ansible. La nouvelle VM est visible dans le CROC Cloud dans la section "Instances".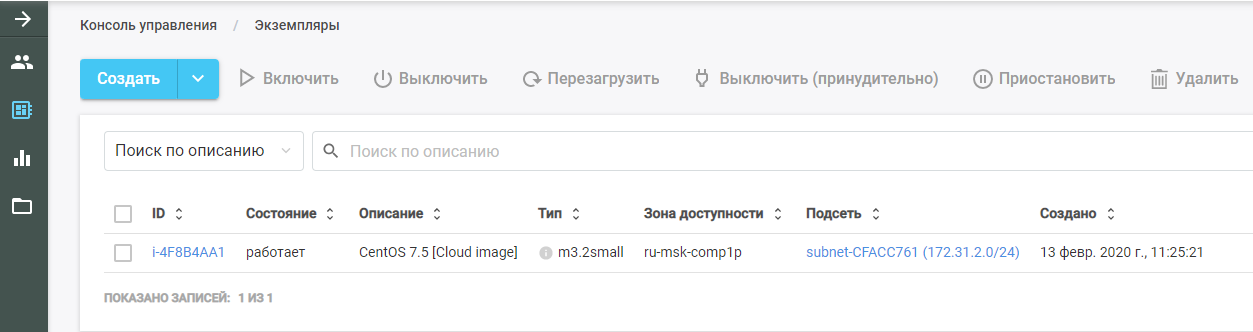
 Après avoir terminé le travail, Packer supprime la machine virtuelle du cloud et laisse une image prête à l'emploi à sa place, qui se trouve dans la section "Modèles". L'ensemble de l'infrastructure Kubernetes sera créée à partir de cette image.
Après avoir terminé le travail, Packer supprime la machine virtuelle du cloud et laisse une image prête à l'emploi à sa place, qui se trouve dans la section "Modèles". L'ensemble de l'infrastructure Kubernetes sera créée à partir de cette image.Ansible
Comme mentionné précédemment, le paramètre playbook est passé dans les paramètres du fournisseur Ansible. Le fichier playbook.yml lui-même ressemble à ceci:- hosts: all
become: true
roles:
| - base
Le fichier transfère à Ansible que sur tous les hôtes il est nécessaire de remplir le rôle de base. S'il existe d'autres rôles, vous pouvez les ajouter au même fichier qu'une liste.Le rôle de base vous permet d'obtenir un cluster prêt à l'emploi avec une seule commande. Le fichier main.yml montre ce que fait exactement ce rôle:- Ajoute un référentiel Docker au modèle système.
- Ajoute le référentiel Kubernetes au modèle système.
- Installe les packages nécessaires.
- Crée un répertoire pour configurer le démon Docker.
- Configure la machine en fonction du fichier de configuration daemon.json.j2.
- Charge le noyau br_netfilter.
- Inclut les options nécessaires pour br_netfilter.
- Comprend les composants Docker et Kubelet.
- Exécute Docker dans VM.
- Exécute une commande qui télécharge les images Docker nécessaires au fonctionnement de Kubernetes.
Dans ce cas, les packages installés sont définis dans le fichier main.yml du répertoire vars. Dans notre cas, nous installons le package docker-ce, ainsi que les trois packages nécessaires au fonctionnement de Kubernetes: kubelet, kubeadm et kubectl.Terraform - l'infrastructure comme code
 Terraform est un outil très fonctionnel de HashiCorp pour l'orchestration cloud. Il possède son propre langage HCL spécifique, qui est souvent utilisé dans d'autres produits de la société, par exemple, dans HashiCorp Vault et Consul.Le principe de base est similaire à tous les systèmes de gestion de configuration. Vous indiquez simplement l'état cible dans le format souhaité et le système calcule l'algorithme pour y parvenir. Une autre chose est que, contrairement au même Ansible, qui fonctionne comme une boîte noire sur les playbooks complexes, Terraform peut émettre un plan d'actions futures sous une forme pratique pour l'analyse. Ceci est important lors de la planification de changements d'infrastructure complexes. Après avoir planifié les actions nécessaires, exécutez la commande terraform apply et Terraform déploiera l'infrastructure décrite dans les fichiers.Comme Packer, cet outil prend en charge AWS, GCP, Alibaba Cloud, Azure, OpenStack, VMware, etc.
Terraform est un outil très fonctionnel de HashiCorp pour l'orchestration cloud. Il possède son propre langage HCL spécifique, qui est souvent utilisé dans d'autres produits de la société, par exemple, dans HashiCorp Vault et Consul.Le principe de base est similaire à tous les systèmes de gestion de configuration. Vous indiquez simplement l'état cible dans le format souhaité et le système calcule l'algorithme pour y parvenir. Une autre chose est que, contrairement au même Ansible, qui fonctionne comme une boîte noire sur les playbooks complexes, Terraform peut émettre un plan d'actions futures sous une forme pratique pour l'analyse. Ceci est important lors de la planification de changements d'infrastructure complexes. Après avoir planifié les actions nécessaires, exécutez la commande terraform apply et Terraform déploiera l'infrastructure décrite dans les fichiers.Comme Packer, cet outil prend en charge AWS, GCP, Alibaba Cloud, Azure, OpenStack, VMware, etc.Nous décrivons le projet
Le répertoire Terraform contient un ensemble de fichiers avec l'extension .tf. Ces fichiers décrivent les composants de l'infrastructure avec lesquels nous travaillerons. Divisez le projet en modules fonctionnels. Une telle structure facilite le contrôle des versions et l'assemblage de chaque projet à partir de blocs pratiques prêts à l'emploi. Pour notre option, la structure suivante convient:- main.tf
- network.tf
- security_groups.tf
- master.tf
- master.tpl
Structure du fichier Main.tf
Commençons par le fichier main.tf, dans lequel l'accès au cloud est configuré. En particulier, plusieurs paramètres sont annoncés qui configurent Terraform pour fonctionner avec le CROC Cloud:provider "aws" {
endpoints {
ec2 = "https://api.cloud.croc.ru"
}
De plus, le fichier décrit que Terraform doit créer indépendamment une clé privée et télécharger sa partie publique sur tous les serveurs. La clé privée elle-même est émise à la fin de Terraform:resource "tls_private_key" "ssh" {
algorithm = "RSA"
}
resource "aws_key_pair" "kube" {
key_name = "terraform"
public_key = "${tls_private_key.ssh.public_key_openssh}"
}
output "ssh" {
value = "${tls_private_key.ssh.private_key_pem}"
}
La structure du fichier network.tf
Ce fichier décrit les composants réseau nécessaires pour démarrer la machine virtuelle:Divulgacherdata "aws_availability_zones" "az" {
state = "available"
}
resource "aws_vpc" "kube" {
cidr_block = "${var.vpc_cidr}"
}
resource "aws_eip" "master" {
count = "1"
vpc = true
}
resource "aws_subnet" "private" {
vpc_id = "${aws_vpc.kube.id}"
count = "${length(data.aws_availability_zones.az.names)}"
cidr_block = "${var.private_subnet_cidr_list[count.index]}"
availability_zone = "${data.aws_availability_zones.az.names[count.index]}"
}
Terraform utilise deux types de composants:- ressource - ce qui doit être créé;
- données - ce que vous devez obtenir.
Dans ce cas, le paramètre de données indique que Terraform doit recevoir les zones de disponibilité du cloud spécifié, qui sont à l'état disponible.La première ressource de paramètre décrit la création d'un cloud privé virtuel et le paramètre suivant décrit la création d'une adresse IP élastique. Pour le cluster Kubernetes, nous commandons cette adresse IP via Terraform.De plus, dans chacune des zones d'accessibilité, et au moment où CROC dispose de deux services cloud, son propre sous-réseau est créé. Une ressource de type aws_subnet est déclarée et l'ID de aws_vpc généré est transmis dans le cadre de ce paramètre. Mais, puisque l'ID de cette ressource est encore inconnu, nous spécifions le paramètre aws_vpc.kube.id, qui fait référence à la ressource créée et substitue la valeur du champ ID.Étant donné que le nombre de sous-réseaux créés est déterminé par le nombre de zones de disponibilité du cloud et que ce nombre peut changer au fil du temps, ce paramètre est spécifié via la variable de longueur (data.aws_availability_zones.az.names), c'est-à-dire la longueur de la liste des zones d'accès reçues via le paramètre de données.Les deux derniers paramètres sont cidr_block (le sous-réseau alloué) et la zone de disponibilité dans laquelle ce sous-réseau est créé. Le dernier paramètre est également défini via une variable qui prend une valeur dans la liste de données en fonction de l'index de la boucle déclaré par [count.index] .Structure du fichier Security_groups.tf
Les groupes de sécurité sont une sorte de pare-feu pour les clouds, qui peuvent être créés non pas à l'intérieur de la machine virtuelle elle-même, mais par le cloud. Dans ce cas, le pare-feu décrit deux règles.La première règle crée un groupe de sécurité appelé kube. Ce groupe de sécurité est nécessaire pour autoriser tout le trafic sortant des nœuds Kubernetes, permettant aux nœuds d'accéder librement à Internet. Le trafic entrant vers les nœuds Kubernetes à partir des sous-réseaux des nœuds eux-mêmes est également autorisé. Ainsi, les nœuds Kubernetes peuvent fonctionner entre eux sans restrictions.La deuxième règle crée le groupe de sécurité ssh. Il permet la connexion SSH depuis n'importe quelle adresse IP vers le port 22 de la machine virtuelle du cluster Kubernetes:Divulgacherresource "aws_security_group" "kube" {
vpc_id = "${aws_vpc.kube.id}"
name = "kubernetes"
# Allow all outbound
egress {
from_port = 0
to_port = 0
protocol = "-1"
cidr_blocks = ["0.0.0.0/0"]
}
# Allow all internal
ingress {
from_port = 0
to_port = 0
protocol = "-1"
cidr_blocks = ["${var.vpc_cidr}"]
}
}
resource "aws_security_group" "ssh" {
vpc_id = "${aws_vpc.kube.id}"
name = "ssh"
# Allow all inbound
ingress {
from_port = 22
to_port = 22
protocol = "tcp"
cidr_blocks = ["0.0.0.0/0"]
}
}
Noeud maître. Structure du fichier Master.tf
Le fichier master.tf décrit la création de plusieurs modèles et instances. En particulier, une instance maître Kubernetes est en cours de création.La variable ami définit l'AMI de l'image source pour la machine virtuelle. Ce qui suit décrit le type de machine virtuelle et le sous-réseau dans lequel elle est créée. Lors de la définition d'un sous-réseau, un cycle est à nouveau utilisé pour créer des machines virtuelles dans chaque zone de disponibilité.Ensuite, les groupes de sécurité utilisés et la clé spécifiée dans le fichier main.tf sont déclarés. Le champ user_data contient l'exécution d'un ensemble de scripts cloud-init, dont les résultats seront implémentés dans la VM:Divulgacherresource "aws_instance" "master" {
count = "1"
ami = "${var.kubernetes_ami}"
instance_type = "c3.large"
disable_api_termination = false
instance_initiated_shutdown_behavior = "terminate"
source_dest_check = false
subnet_id = "${aws_subnet.private.*.id[count.index % length(data.aws_availability_zones.az.names)]}"
associate_public_ip_address = true
vpc_security_group_ids = [
"${aws_security_group.ssh.id}",
"${aws_security_group.kube.id}",
]
key_name = "${aws_key_pair.kube.key_name}"
user_data = "${data.template_cloudinit_config.master.rendered}"
monitoring = "true"
}
Noeud maître. Cloud init
Cloud-init est un outil que Canonical développe. Il vous permet d'exécuter automatiquement dans une infrastructure cloud un certain ensemble de commandes après le démarrage d'une machine virtuelle. Terraform dispose de mécanismes pour l' intégrer à l'aide de modèles .Puisqu'il est impossible de "cuire" tout ce qui est nécessaire dans la VM, après avoir démarré, selon son type, elle doit soit rejoindre le cluster Kubernetes soit initialiser le cluster Kubernetes. Dans le modèle de fichier cloud-init appelé master.tpl, plusieurs actions sont effectuées.1. Les fichiers de configuration pour Kubeadm sont enregistrés:#cloud-config
write_files:
- path: etc/kubernetes/kubeadm.conf
owner: root:root
content:
...
2. Un ensemble de commandes est exécuté:- l'adresse IP de l'assistant est écrite dans le fichier de configuration généré;
- le maître du cluster Kubernetes est initialisé avec la commande kubeadm init;
- dans le cluster Kubernetes, le réseau de calques Calico est installé avec la commande kubectl apply.
runcmd:
- sed -i "s/CONTROL_PLANE_IP/$(curl http://169.254.169.254/latest/meta-data-local-ipv4)/g" /etc/kubernetes/kubeadm.conf
- kubeadm init --config /etc/kubernetes/kubeadm.conf
- mkdir -p $HOME/.kube
- sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
- sudo chown $(id -u):$(id -g) $HOME/.kube/config
- kubectl apply -f https://docs.projectcalico.org/v3.8/manifests/calico.yaml
Après avoir exécuté les commandes lors du démarrage de la machine virtuelle, un cluster Kubernetes fonctionnel est obtenu à partir d'un nœud maître. Les nœuds restants rejoindront ce nœud maître.Noeuds ordinaires. node.tf
Le fichier node.tf est similaire au fichier master.tf. Des ressources sont également créées ici, qui dans ce cas sont appelées nœud. La seule différence est que le nœud maître est créé dans une seule instance, et le nombre de nœuds de travail créés est défini via la variable nodes_count:resource "aws_instance" "node" {
count = "${var.nodes_count}"
ami = "${var.kubernetes_ami}"
instance_type = "c3.large"
Le fichier cloud-init pour les nœuds de travail exécute une seule commande - kubeadm join. Cette commande attache la machine terminée au cluster Kubernetes à l'aide du jeton d'autorisation que nous envoyons.Lancer Terraform
Au lancement, Terraform utilise plusieurs modules:- Module AWS
- module de modèle;
- Module TLS responsable de la génération des clés.
Ces modules doivent être installés sur la machine locale:terraform init terraform/
Avec cette commande, le répertoire dans lequel se trouvent tous les fichiers nécessaires est indiqué. Lors de l'initialisation, Terraform télécharge tous les modules spécifiés, après quoi vous devez exécuter la commande terraform plan:terraform plan -var-file terraform/vars/dev.tfvars terraform/
Veuillez noter qu'en plus du répertoire avec les fichiers Terraform, le fichier var est indiqué, qui contient les valeurs des variables utilisées dans les fichiers Terraform. Le répertoire vars peut contenir plusieurs fichiers .tfvars, ce qui vous permet de gérer différents types d'infrastructures avec un seul ensemble de fichiers Terraform.Le fichier dev.tfvars lui-même contient les variables importantes suivantes:- Kubernetes_version (version installable de Kubernetes);
- Kubernetes_ami (image AMI créée par Packer).
Après avoir défini les valeurs nécessaires des variables, exécutez la commande terraform plan, après quoi Terraform présentera une liste d'actions nécessaires pour atteindre l'état décrit dans les fichiers Terraform.Après avoir vérifié cette liste, appliquez les modifications proposées: àterraform apply -auto-approve -var-file terraform/vars/dev.tfvars terraform/partir de la commande terraform plan, elle se distingue par la présence d'une clé - auto-approuver, ce qui élimine la nécessité de confirmer les modifications apportées. Vous pouvez omettre cette clé, mais chaque action devra ensuite être confirmée manuellement.Structure du cluster Kubernetes
 Le cluster Kubernetes se compose d'un nœud maître qui exécute des fonctions de gestion et de nœuds de travail qui exécutent les applications installées dans le cluster.Quatre composants sont installés sur le nœud maître qui assurent le fonctionnement de ce système:
Le cluster Kubernetes se compose d'un nœud maître qui exécute des fonctions de gestion et de nœuds de travail qui exécutent les applications installées dans le cluster.Quatre composants sont installés sur le nœud maître qui assurent le fonctionnement de ce système:- ETCD, c'est-à-dire la base de données Kubernetes
- Serveur API, à travers lequel nous stockons des informations dans Kubernetes et en obtenons des informations;
- Gestionnaire de contrôleur
- Planificateur
Deux composants supplémentaires sont installés sur les nœuds de travail:- Kube-proxy (responsable de la génération des règles de réseau dans le cluster Kubernetes);
- Kubelet (responsable de l'envoi de la commande au démon Docker pour exécuter des applications dans le cluster Kubernetes).
Entre les nœuds, le plug-in de réseau Calico fonctionne.Diagramme de flux de travail de cluster
, Kubernetes replicaset.
- API-, ETCD. .
- API- .
- Controller-manager API- , «», .
- Scheduler . ETCD API-.
- Kubelet API- Docker .
- Docker .
- Kubelet API- , .
, Kubernetes , . , , YAML-. , , API-. .
Kubeadm
 Le dernier élément à mentionner est Kubeadm. Le déploiement d'un nouveau cluster Kubernetes est toujours un processus minutieux. À chaque étape, il existe des risques d'erreurs dues au facteur humain, et de nombreuses tâches sont tout simplement très routinières et longues. Par exemple, verser des certificats pour le chiffrement TLS entre les nœuds et les maintenir à jour. C'est là que les utilitaires pour l'automatisation de base des modèles viennent à la rescousse. L'astuce de Kubeadm est qu'il est officiellement certifié pour fonctionner avec Kubernetes.Il vous permet de:
Le dernier élément à mentionner est Kubeadm. Le déploiement d'un nouveau cluster Kubernetes est toujours un processus minutieux. À chaque étape, il existe des risques d'erreurs dues au facteur humain, et de nombreuses tâches sont tout simplement très routinières et longues. Par exemple, verser des certificats pour le chiffrement TLS entre les nœuds et les maintenir à jour. C'est là que les utilitaires pour l'automatisation de base des modèles viennent à la rescousse. L'astuce de Kubeadm est qu'il est officiellement certifié pour fonctionner avec Kubernetes.Il vous permet de:- Installer, configurer et exécuter tous les principaux composants du cluster
- gérer les certificats, y compris les faire pivoter et en écrire de nouveaux;
- gérer les versions des composants du cluster (mise à niveau et rétrogradation).
En même temps, Kubeadm n'est pas un système de gestion de cluster Kubernetes complet, mais est une sorte de bloc de construction qui vous permet de configurer Kubernetes sur le nœud sur lequel l'utilitaire Kubeadm s'exécute. Cela signifie qu'un système d'orchestration est nécessaire pour exécuter toutes les machines virtuelles nécessaires, les configurer et exécuter Kubeadm sur tous les nœuds. C'est à ces fins que Terraform est utilisé.Référentiel avec tous les fichiers
Ici, nous mettons tous les fichiers et configurations au même endroit, afin que cela vous soit plus pratique. Si vous n'avez pas de cloud privé à portée de main, mais que vous souhaitez passer par toutes ces étapes vous-même et tester le déploiement dans la pratique, écrivez-nous à cloud@croc.ru.Nous vous donnerons une version de démonstration pour les tests et vous conseillerons sur tous les problèmes.Et bientôt, il y aura un nouveau Slurm , où vous pourrez créer votre propre cluster. Le code promo CROC a une remise de 10%.Pour ceux qui travaillent déjà avec Kubernetes, il existe un cours avancé . La remise est la même.Chers collègues, Habraparser rompt le balisage du code. Veuillez prendre la source de GitHub à partir du lien ci-dessus.