Avec le traitement complexe de grands ensembles de données (différents processus ETL : importations, conversions et synchronisation avec une source externe), il est souvent nécessaire de «mémoriser» temporairement et de traiter immédiatement quelque chose de volumineux.Une tâche typique de ce type ressemble généralement à ceci: "Ici, le service comptable a téléchargé les derniers paiements reçus de la banque cliente , nous devons les télécharger rapidement sur le site Web et les lier aux comptes"Mais lorsque le volume de ce "quelque chose" commence à être mesuré en centaines de mégaoctets, et le service Cela devrait continuer à fonctionner avec la base en mode 24x7, il existe de nombreux effets secondaires qui vont ruiner votre vie.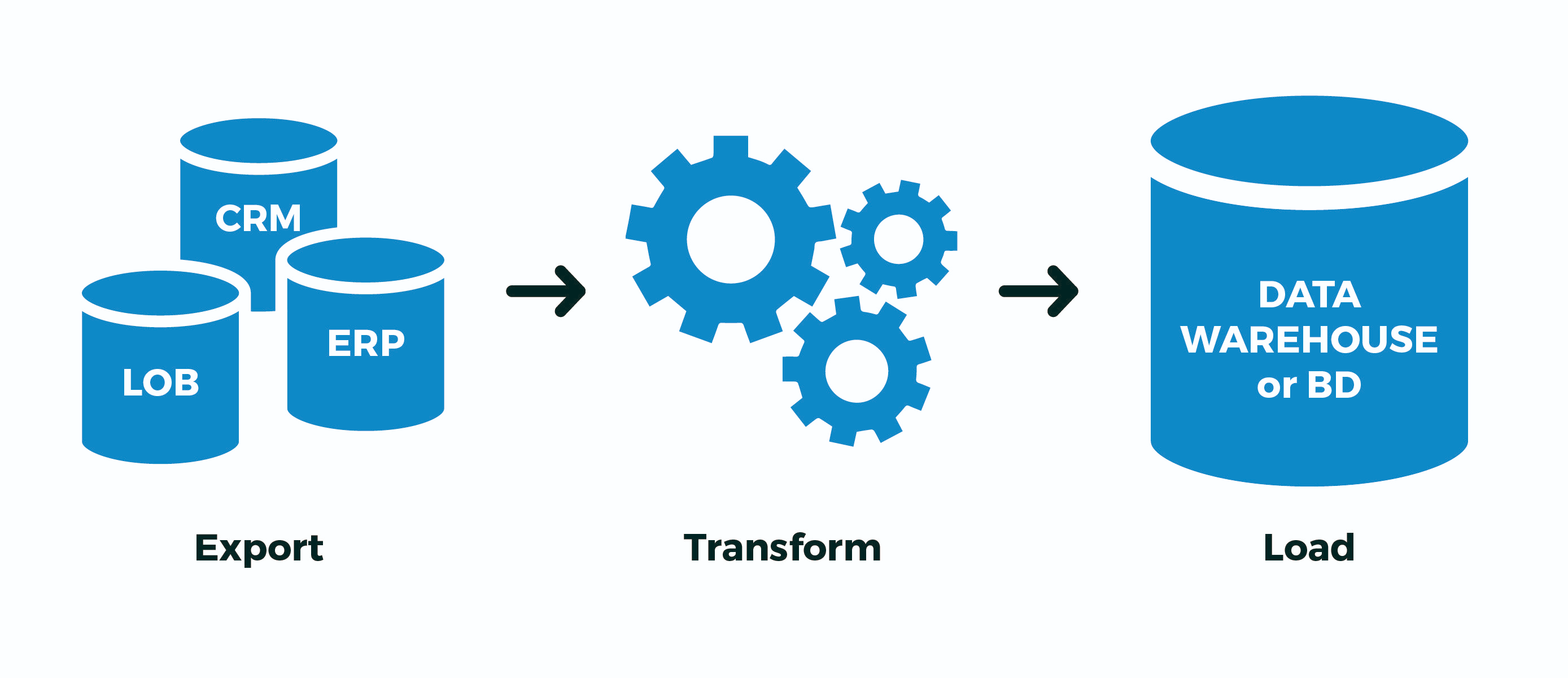 Pour y faire face dans PostgreSQL (et pas seulement dans celui-ci), vous pouvez utiliser certaines options d'optimisation qui vous permettront de traiter plus rapidement et avec moins de ressources.
Pour y faire face dans PostgreSQL (et pas seulement dans celui-ci), vous pouvez utiliser certaines options d'optimisation qui vous permettront de traiter plus rapidement et avec moins de ressources.1. Où expédier?
Tout d'abord, décidons où nous pouvons télécharger les données que nous voulons «traiter».1.1. Tables temporaires (TABLE TEMPORAIRE)
En principe, pour PostgreSQL, les tables temporaires sont les mêmes tables que les autres. Par conséquent, les superstitions comme «tout y est stocké uniquement en mémoire, mais cela peut se terminer» sont incorrectes . Mais il existe plusieurs différences importantes.Espace de noms propre pour chaque connexion à la base de données
Si deux connexions tentent d'établir en même temps CREATE TABLE x, quelqu'un obtiendra définitivement une erreur d' objets DB non uniques .Mais si les deux essaient de s'exécuter , les deux le feront normalement et chacun recevra sa propre copie de la table. Et il n'y aura rien de commun entre eux.CREATE TEMPORARY TABLE x"Autodestruction" avec déconnexion
Lorsque vous fermez la connexion, toutes les tables temporaires sont automatiquement supprimées, il DROP TABLE xn'y a donc aucun sens à exécuter "manuellement" , sauf ...Si vous travaillez via pgbouncer en mode transaction , la base de données continue de supposer que cette connexion est toujours active, et cette temporaire la table existe toujours.Par conséquent, une tentative de recréation à partir d'une autre connexion à pgbouncer entraînera une erreur. Mais cela peut être contourné en profitant . Certes, il vaut mieux ne pas le faire, car vous pourrez alors découvrir «soudainement» les données laissées par le «propriétaire précédent». Au lieu de cela, il est préférable de lire le manuel et de voir que lors de la création du tableau, il est possible d'ajouterCREATE TEMPORARY TABLE IF NOT EXISTS xON COMMIT DROP - c'est-à-dire que lorsque la transaction est terminée, le tableau sera automatiquement supprimé.Non réplication
Étant donné que seule une jointure particulière appartient, les tables temporaires ne sont pas répliquées. Mais cela élimine la nécessité de double-écrire les données en tas + WAL, donc INSERT / UPDATE / DELETE est beaucoup plus rapide.Mais comme la table temporaire est toujours une table «presque ordinaire», elle ne peut pas non plus être créée sur la réplique. Du moins pour l'instant, bien que le patch correspondant existe depuis longtemps.1.2. Tables non enregistrées (TABLEAU NON LOGGÉ)
Mais que faire, par exemple, si vous avez une sorte de processus ETL encombrant qui ne peut pas être implémenté dans une seule transaction, et que vous avez toujours pgbouncer en mode transaction ? ..Ou le flux de données est si grand qu'il n'y a pas assez de bande passante par connexion à partir de la base de données (lecture, un processus sur la CPU)? ..Ou certaines opérations vont-elles de manière asynchrone dans différentes connexions? ..Il n'y a qu'une seule option - pour créer temporairement une table non temporaire . Pun, ouais. C'est à dire:- créé «ses» tables avec des noms au maximum aléatoires afin de ne croiser avec personne
- Extraire : y versait des données d'une source externe
- Transformer : transformé, rempli dans les principaux champs de liaison
- Charge : données finies versées dans les tables cibles
- "mes" tables supprimées
Et maintenant - une mouche dans la pommade. En fait, toute l'écriture dans PostgreSQL se produit deux fois - d' abord dans le WAL , puis dans le corps de la table / de l'index. Tout cela est fait pour prendre en charge ACID et la visibilité correcte des données entre les transactions COMMITimbriquées et ROLLBACKimbriquées.Mais nous n'en avons pas besoin! Nous avons tout le processus ou réussi, ou non . Peu importe le nombre de transactions intermédiaires qu'il contient - nous ne souhaitons pas «continuer le processus à partir du milieu», surtout quand on ne sait pas où il se trouvait.Pour ce faire, les développeurs de PostgreSQL ont introduit la version 9.1, comme les tables non journalisées (UNLOGGED) :. , , (. 29), . , ; . , . , , .
En bref, ce sera beaucoup plus rapide , mais si le serveur de base de données "plante" - ce sera désagréable. Mais à quelle fréquence cela se produit-il, et votre processus ETL sait-il comment le modifier correctement «à partir du milieu» après la «revitalisation» de la base de données? ..Sinon, et le cas ci-dessus est similaire au vôtre - utilisez UNLOGGED, mais n'incluez jamais cet attribut sur de vraies tables des données qui vous sont chères.1.3. ON COMMIT {SUPPRIMER DES RANGS | LAISSEZ TOMBER}
Cette conception permet lors de la création d'une table de définir un comportement automatique à la fin de la transaction.À propos J'ai déjà écrit ci-dessus, cela génère , mais la situation est plus intéressante - ici, elle est générée . Étant donné que toute l'infrastructure de stockage de la méta description de la table temporaire est exactement la même que celle habituelle, la création et la suppression constantes de tables temporaires entraînent un fort "gonflement" des tables système pg_class, pg_attribute, pg_attrdef, pg_depend, ... Imaginez maintenant que vous avez un travailleur sur la ligne la connexion à la base de données, qui ouvre chaque seconde une nouvelle transaction, crée, remplit, traite et supprime la table temporaire ... Les déchets dans les tables système s'accumulent en excès, ce qui représente des freins supplémentaires lors de chaque opération.ON COMMIT DROPDROP TABLEON COMMIT DELETE ROWSTRUNCATE TABLEEn général, non! Dans ce cas, il est beaucoup plus efficace CREATE TEMPORARY TABLE x ... ON COMMIT DELETE ROWSde la retirer du cycle de transaction - puis au début de chaque nouvelle transaction, la table existera déjà (enregistrer l'appel CREATE), mais elle sera vide , grâce à TRUNCATE(nous avons également enregistré l'appel) à la fin de la transaction précédente.1.4. COMME ... INCLUANT ...
J'ai mentionné au début que l'un des cas d'utilisation typiques des tables temporaires était divers types d'importations - et le développeur copie-colle avec lassitude la liste des champs de la table cible dans la déclaration de son temporaire ...Mais la paresse est le moteur du progrès! Par conséquent, la création d'une nouvelle table «sur le modèle» peut être beaucoup plus simple:CREATE TEMPORARY TABLE import_table(
LIKE target_table
);
Étant donné que vous pouvez ensuite ajouter de nombreuses données à ce tableau, les recherches ne seront jamais rapides. Mais il existe une solution traditionnelle contre cela: les index! Et, oui, une table temporaire peut également avoir des index .Comme, souvent, les indices souhaités coïncident avec les indices de la table cible, vous pouvez simplement écrire . Si vous avez également besoin de -values (par exemple, pour remplir les valeurs de clé primaire), vous pouvez utiliser . Eh bien, ou tout simplement - - cela copiera les valeurs par défaut, les index, les contraintes ... Mais ici, vous devez comprendre que si vous avez créé une table d'importation tout de suite avec des index, les données seront remplies plus longtempsLIKE target_table INCLUDING INDEXESDEFAULTLIKE target_table INCLUDING DEFAULTSLIKE target_table INCLUDING ALLque si vous remplissez tout d'abord, puis faites rouler les indices - regardez comme un exemple de la façon dont pg_dump le fait .Dans l'ensemble, RTFM !2. Comment écrire?
Je dirai simplement - utilisez COPY-stream au lieu de "packs" INSERT, accélération parfois . Vous pouvez même directement à partir d'un fichier pré-généré.3. Comment gérer?
Alors, laissez notre introduction ressembler à ceci:- vous avez dans votre base de données une plaque avec les données client pour 1M d'enregistrements
- chaque jour, le client vous envoie une nouvelle «image» complète
- par expérience, vous savez que pas plus de 10 000 enregistrements changent de temps en temps
Un exemple classique d'une telle situation est la base de données KLADR - il y a beaucoup d'adresses, mais dans chaque téléchargement hebdomadaire de modifications (changement de nom des colonies, associations de rues, apparition de nouvelles maisons), il y en a très peu, même à l'échelle nationale.3.1. Algorithme de synchronisation complet
Par souci de simplicité, disons que vous n'avez même pas besoin de restructurer les données - il suffit de mettre le tableau sous la bonne forme, c'est-à-dire:- supprimer tout ce qui n'est plus
- mettre à jour tout ce qui était déjà, et vous devez mettre à jour
- insérer tout ce qui n'a pas été
Pourquoi dans cet ordre cela vaut-il la peine de faire des opérations? Parce que c'est ainsi que la taille de la table augmente de manière minimale ( rappelez-vous MVCC! ).SUPPRIMER DE dst
Non, bien sûr, vous ne pouvez effectuer que deux opérations:- supprimer (
DELETE) du tout - collez tout à partir d'une nouvelle image
Mais en même temps, grâce à MVCC, la taille de la table augmentera exactement deux fois ! Obtenez + 1M d'enregistrements d'image dans le tableau en raison de la mise à jour 10K - redondance moyenne ...TRUNCATE dst
Un développeur plus expérimenté sait que toute la plaque peut être nettoyée à peu de frais:- clear (
TRUNCATE) toute la table - collez tout à partir d'une nouvelle image
La méthode est efficace, parfois elle est tout à fait applicable , mais il y a un problème ... Nous injecterons 1M d'enregistrements, donc nous ne pouvons pas nous permettre de laisser la table vide pendant tout ce temps (comme cela se passera sans encapsuler dans une seule transaction).Ce qui signifie:- nous commençons une longue transaction
TRUNCATEimpose AccessExclusive -Lock- nous faisons l'insert depuis longtemps, et tout le monde en ce moment ne peut même pas
SELECT
Quelque chose ne va pas ...ALTER TABLE ... RENAME ... / DROP TABLE ...
En option, remplissez tout dans une nouvelle table séparée, puis renommez-la simplement en l'ancienne. Quelques petites choses désagréables:- AccessExclusive aussi , bien que beaucoup moins de temps
- tous les plans / statistiques de requête de cette table sont réinitialisés, il est nécessaire de conduire ANALYSER
- toutes les clés étrangères (FK) se cassent sur la table
Il y avait un correctif WIP de Simon Riggs, qui suggérait de faire une ALTERopération pour remplacer le corps de la table au niveau du fichier, sans toucher aux statistiques et FK, mais n'a pas collecté le quorum.SUPPRIMER, METTRE À JOUR, INSÉRER
Nous nous arrêtons donc sur une version non bloquante de trois opérations. Presque trois ... Comment le faire le plus efficacement possible?
BEGIN;
CREATE TEMPORARY TABLE tmp(
LIKE dst INCLUDING INDEXES
) ON COMMIT DROP;
COPY tmp FROM STDIN;
DELETE FROM
dst D
USING
dst X
LEFT JOIN
tmp Y
USING(pk1, pk2)
WHERE
(D.pk1, D.pk2) = (X.pk1, X.pk2) AND
Y IS NOT DISTINCT FROM NULL;
UPDATE
dst D
SET
(f1, f2, f3) = (T.f1, T.f2, T.f3)
FROM
tmp T
WHERE
(D.pk1, D.pk2) = (T.pk1, T.pk2) AND
(D.f1, D.f2, D.f3) IS DISTINCT FROM (T.f1, T.f2, T.f3);
INSERT INTO
dst
SELECT
T.*
FROM
tmp T
LEFT JOIN
dst D
USING(pk1, pk2)
WHERE
D IS NOT DISTINCT FROM NULL;
COMMIT;
3.2. Importer le post-traitement
Dans le même KLADER, tous les enregistrements modifiés doivent en outre être soumis à un post-traitement - normaliser, mettre en surbrillance les mots clés et apporter aux structures nécessaires. Mais comment savoir exactement ce qui a changé , sans compliquer le code de synchronisation, idéalement sans le toucher du tout?Si seul votre processus a un accès en écriture au moment de la synchronisation, vous pouvez utiliser un déclencheur qui collectera toutes les modifications pour nous:
CREATE TABLE kladr(...);
CREATE TABLE kladr_house(...);
CREATE TABLE kladr$log(
ro kladr,
rn kladr
);
CREATE TABLE kladr_house$log(
ro kladr_house,
rn kladr_house
);
CREATE OR REPLACE FUNCTION diff$log() RETURNS trigger AS $$
DECLARE
dst varchar = TG_TABLE_NAME || '$log';
stmt text = '';
BEGIN
IF TG_OP = 'UPDATE' THEN
IF NEW IS NOT DISTINCT FROM OLD THEN
RETURN NEW;
END IF;
END IF;
stmt = 'INSERT INTO ' || dst::text || '(ro,rn)VALUES(';
CASE TG_OP
WHEN 'INSERT' THEN
EXECUTE stmt || 'NULL,$1)' USING NEW;
WHEN 'UPDATE' THEN
EXECUTE stmt || '$1,$2)' USING OLD, NEW;
WHEN 'DELETE' THEN
EXECUTE stmt || '$1,NULL)' USING OLD;
END CASE;
RETURN NEW;
END;
$$ LANGUAGE plpgsql;
Maintenant, nous pouvons imposer des déclencheurs (ou les activer ALTER TABLE ... ENABLE TRIGGER ...) avant de démarrer la synchronisation :CREATE TRIGGER log
AFTER INSERT OR UPDATE OR DELETE
ON kladr
FOR EACH ROW
EXECUTE PROCEDURE diff$log();
CREATE TRIGGER log
AFTER INSERT OR UPDATE OR DELETE
ON kladr_house
FOR EACH ROW
EXECUTE PROCEDURE diff$log();
Et puis tranquillement à partir des tables de journal, nous extrayons toutes les modifications dont nous avons besoin et les exécutons via des gestionnaires supplémentaires.3.3. Importer des ensembles associés
Ci-dessus, nous avons considéré les cas où les structures de données de la source et du récepteur coïncident. Mais que se passe-t-il si le déchargement d'un système externe a un format différent de la structure de stockage dans notre base de données?Prenons l'exemple du stockage des clients et de leurs comptes, l'option plusieurs-à-un classique:CREATE TABLE client(
client_id
serial
PRIMARY KEY
, inn
varchar
UNIQUE
, name
varchar
);
CREATE TABLE invoice(
invoice_id
serial
PRIMARY KEY
, client_id
integer
REFERENCES client(client_id)
, number
varchar
, dt
date
, sum
numeric(32,2)
);
Mais le déchargement d'une source externe nous vient sous la forme de "tout en un":CREATE TEMPORARY TABLE invoice_import(
client_inn
varchar
, client_name
varchar
, invoice_number
varchar
, invoice_dt
date
, invoice_sum
numeric(32,2)
);
De toute évidence, les données client peuvent être dupliquées de cette manière, et l'enregistrement principal est le «compte»:0123456789;;A-01;2020-03-16;1000.00
9876543210;;A-02;2020-03-16;666.00
0123456789;;B-03;2020-03-16;9999.00
Pour le modèle, insérez simplement nos données de test, mais n'oubliez pas - COPYplus efficacement!INSERT INTO invoice_import
VALUES
('0123456789', '', 'A-01', '2020-03-16', 1000.00)
, ('9876543210', '', 'A-02', '2020-03-16', 666.00)
, ('0123456789', '', 'B-03', '2020-03-16', 9999.00);
Premièrement, nous sélectionnons les «coupes» auxquelles nos «faits» se réfèrent. Dans notre cas, les comptes se réfèrent aux clients:CREATE TEMPORARY TABLE client_import AS
SELECT DISTINCT ON(client_inn)
client_inn inn
, client_name "name"
FROM
invoice_import;
Afin d'associer correctement les comptes aux identifiants clients, nous devons d'abord découvrir ou générer ces identifiants. Ajoutez des champs pour eux:ALTER TABLE invoice_import ADD COLUMN client_id integer;
ALTER TABLE client_import ADD COLUMN client_id integer;
Nous utiliserons la méthode de synchronisation des tables avec la petite correction décrite ci-dessus - nous ne mettrons à jour ni ne supprimerons rien dans la table cible, car l'importation de clients se fait uniquement par ajout:
UPDATE
client_import T
SET
client_id = D.client_id
FROM
client D
WHERE
T.inn = D.inn;
WITH ins AS (
INSERT INTO client(
inn
, name
)
SELECT
inn
, name
FROM
client_import
WHERE
client_id IS NULL
RETURNING *
)
UPDATE
client_import T
SET
client_id = D.client_id
FROM
ins D
WHERE
T.inn = D.inn;
UPDATE
invoice_import T
SET
client_id = D.client_id
FROM
client_import D
WHERE
T.client_inn = D.inn;
En fait, tout - invoice_importmaintenant nous avons rempli le champ de communication client_idavec lequel nous allons insérer le compte.