Le dernier article a examiné comment obtenir des informations sur les instruments financiers. Ensuite, plusieurs articles seront publiés sur ce qui peut initialement être fait avec les données obtenues, comment analyser et élaborer une stratégie. Les matériaux sont basés sur des publications dans des sources étrangères et des cours sur l'une des plateformes en ligne.Cet article explique comment calculer la rentabilité, la volatilité et construire l'un des principaux indicateurs.import pandas as pd
import yfinance as yf
import numpy as np
import matplotlib.pyplot as plt
sber = yf.download('SBER.ME','2016-01-01')
Rentabilité
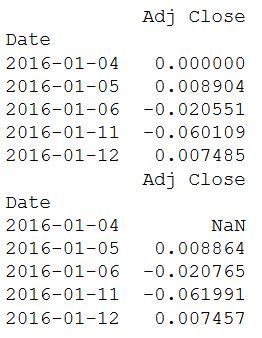
Cette valeur représente la variation en pourcentage de la valeur de l'action pour un jour de bourse. Il ne prend pas en compte les dividendes et commissions. Il est facile de calculer en utilisant la fonction pct_change () du package Pandas.En règle générale, la rentabilité des journaux est utilisée, car elle vous permet de mieux comprendre et étudier les changements au fil du temps.
daily_close = sber[['Adj Close']]
daily_pct_change = daily_close.pct_change()
daily_pct_change.fillna(0, inplace=True)
print(daily_pct_change.head())
daily_log_returns = np.log(daily_close.pct_change()+1)
print(daily_log_returns.head())
 Afin de connaître la rentabilité hebdomadaire et / ou mensuelle des données obtenues, utilisez la fonction resample ().
Afin de connaître la rentabilité hebdomadaire et / ou mensuelle des données obtenues, utilisez la fonction resample ().
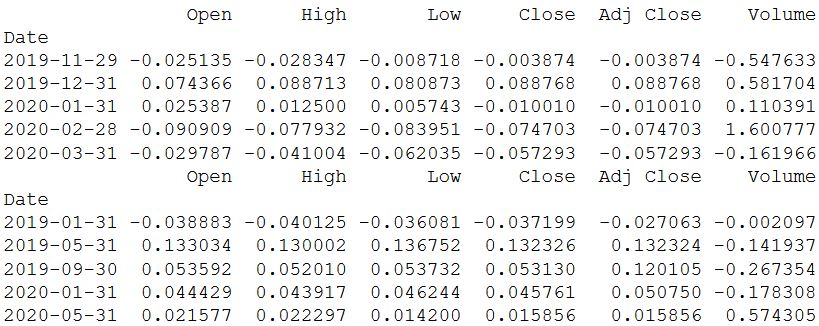
monthly = sber.resample('BM').apply(lambda x: x[-1])
print(monthly.pct_change().tail())
quarter = sber.resample("4M").mean()
print(quarter.pct_change().tail())
 La fonction pct_change () est pratique à utiliser, mais masque à son tour comment la valeur est obtenue. Un calcul similaire, qui aidera à comprendre le mécanisme, peut être effectué en utilisant shift () à partir du package à partir du package Pandas. Le cours de clôture quotidien est divisé par le cours passé (décalé d'un) et une unité est soustraite de la valeur reçue. Mais il y a un inconvénient mineur - la première valeur en conséquence est NA.Le calcul de la rentabilité est basé sur la formule:
La fonction pct_change () est pratique à utiliser, mais masque à son tour comment la valeur est obtenue. Un calcul similaire, qui aidera à comprendre le mécanisme, peut être effectué en utilisant shift () à partir du package à partir du package Pandas. Le cours de clôture quotidien est divisé par le cours passé (décalé d'un) et une unité est soustraite de la valeur reçue. Mais il y a un inconvénient mineur - la première valeur en conséquence est NA.Le calcul de la rentabilité est basé sur la formule: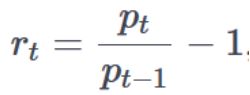 où, p est le prix, t est l'instant de temps et r est la rentabilité.Ensuite, un diagramme de répartition de la rentabilité est construit et les principales statistiques sont calculées:
où, p est le prix, t est l'instant de temps et r est la rentabilité.Ensuite, un diagramme de répartition de la rentabilité est construit et les principales statistiques sont calculées:
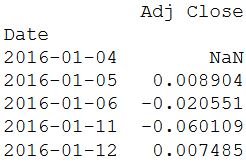
daily_pct_change = daily_close / daily_close.shift(1) - 1
print(daily_pct_change.head())
daily_pct_change.hist(bins=50)
plt.show()
print(daily_pct_change.describe())
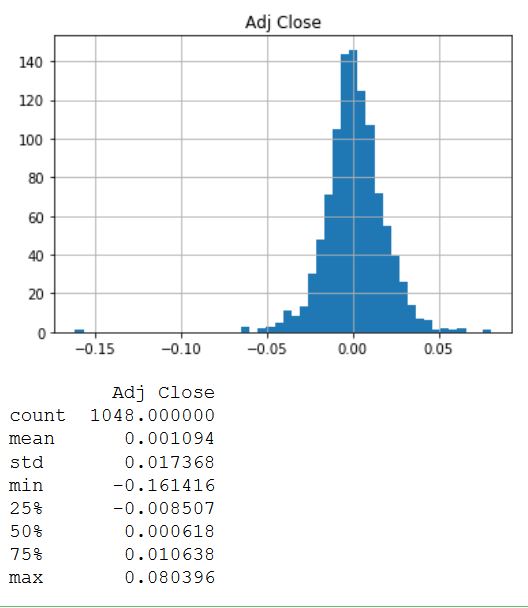 La distribution semble très symétrique et normalement distribuée autour d'une valeur de 0,00. Pour obtenir d'autres valeurs statistiques, la fonction description () est utilisée. En conséquence, on constate que la valeur moyenne est légèrement supérieure à zéro, et l'écart-type est presque 0,02.
La distribution semble très symétrique et normalement distribuée autour d'une valeur de 0,00. Pour obtenir d'autres valeurs statistiques, la fonction description () est utilisée. En conséquence, on constate que la valeur moyenne est légèrement supérieure à zéro, et l'écart-type est presque 0,02.Rendement cumulatif
Les rendements quotidiens cumulatifs sont utiles pour déterminer la valeur d'un investissement sur une période de temps spécifiée. Il peut être calculé comme indiqué dans le code ci-dessous.
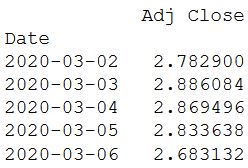
cum_daily_return = (1 + daily_pct_change).cumprod()
print(cum_daily_return.tail())
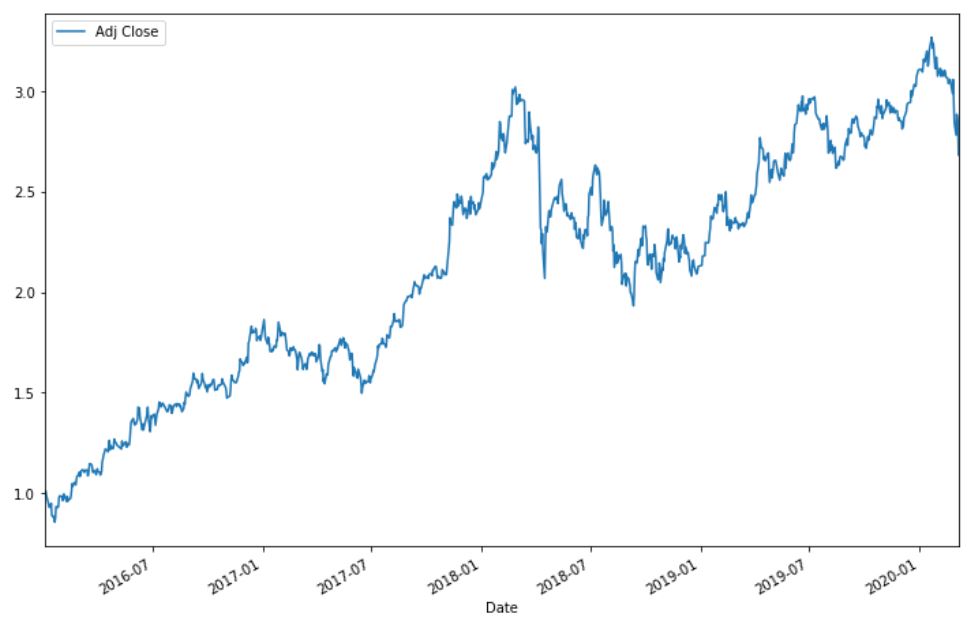
cum_daily_return.plot(figsize=(12,8))
plt.show()
 Vous pouvez recalculer le rendement sur la période mensuelle:
Vous pouvez recalculer le rendement sur la période mensuelle:
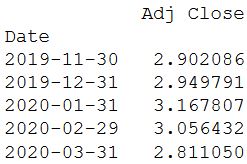
cum_monthly_return = cum_daily_return.resample("M").mean()
print(cum_monthly_return.tail())
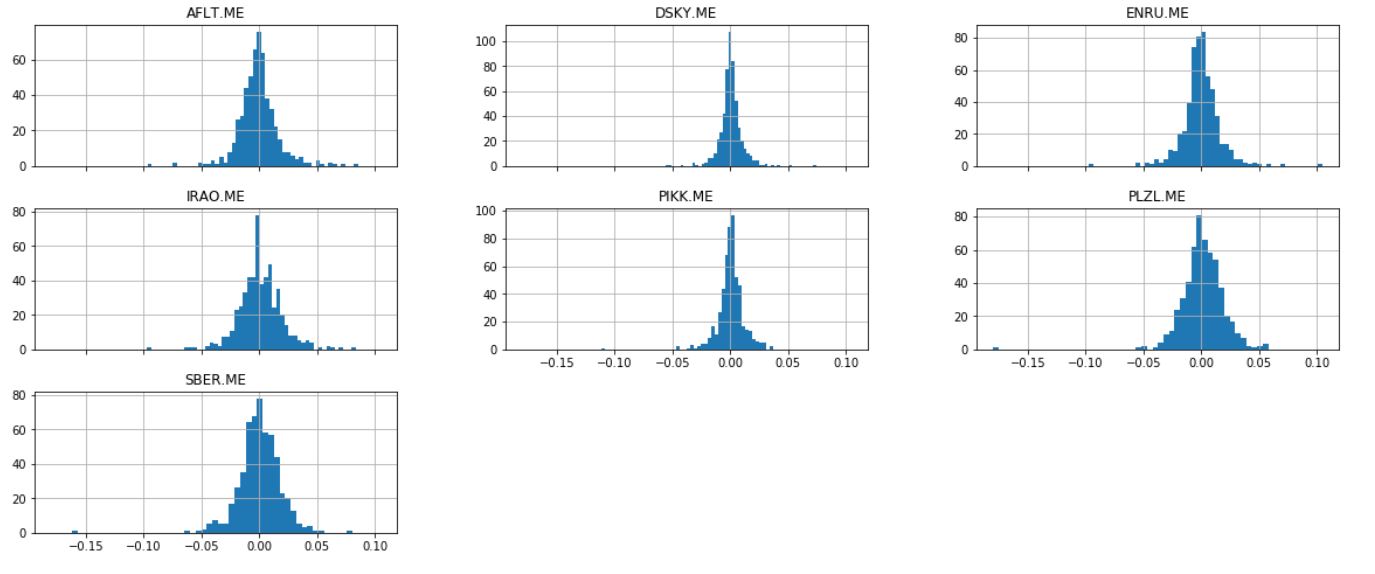
 Savoir comment calculer les rendements est précieux lors de l'analyse des stocks. Mais il est encore plus précieux par rapport aux autres stocks.Prenez quelques actions (leur choix est complètement aléatoire) et construisez leur graphique.
Savoir comment calculer les rendements est précieux lors de l'analyse des stocks. Mais il est encore plus précieux par rapport aux autres stocks.Prenez quelques actions (leur choix est complètement aléatoire) et construisez leur graphique.ticker = ['AFLT.ME','DSKY.ME','IRAO.ME','PIKK.ME', 'PLZL.ME','SBER.ME','ENRU.ME']
stock = yf.download(ticker,'2018-01-01')
daily_pct_change = stock['Adj Close'].pct_change()
daily_pct_change.hist(bins=50, sharex=True, figsize=(20,8))
plt.show()
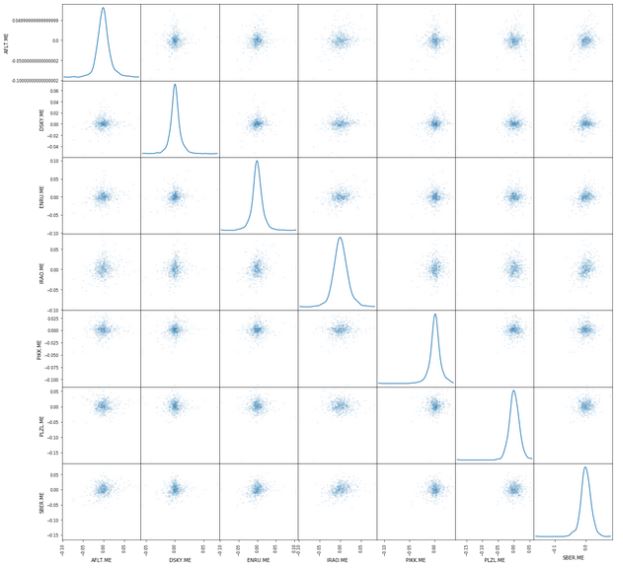
 Un autre graphique utile est la matrice de dispersion. Il peut être facilement construit en utilisant la fonction scatter_matrix (), qui fait partie de la bibliothèque pandas. Daily_pct_change est utilisé comme arguments et le paramètre Kernel Density Estimation est défini. De plus, vous pouvez définir la transparence à l'aide du paramètre alpha et la taille du graphique à l'aide du paramètre figsize.
Un autre graphique utile est la matrice de dispersion. Il peut être facilement construit en utilisant la fonction scatter_matrix (), qui fait partie de la bibliothèque pandas. Daily_pct_change est utilisé comme arguments et le paramètre Kernel Density Estimation est défini. De plus, vous pouvez définir la transparence à l'aide du paramètre alpha et la taille du graphique à l'aide du paramètre figsize.from pandas.plotting import scatter_matrix
scatter_matrix(daily_pct_change, diagonal='kde', alpha=0.1,figsize=(20,20))
plt.show()
 C'est tout pour le moment. Le prochain article couvrira le calcul de la volatilité, la moyenne et l'utilisation de la méthode des moindres carrés.
C'est tout pour le moment. Le prochain article couvrira le calcul de la volatilité, la moyenne et l'utilisation de la méthode des moindres carrés.