Mi-2018, Sports.ru a pensé à passer à un nouvel éditeur de texte WYSIWYG pour les publications des utilisateurs. Depuis juin 2019, l'éditeur est en mode bêta. Pendant ce temps, nous avons résolu de nombreux problèmes liés à la fois à la conception de l'architecture de l'ensemble du service et à l'implémentation de l'éditeur lui-même dans le navigateur basé sur la bibliothèque ProseMirror , et avons décidé de partager notre expérience.
Table des matières
1. Introduction1.1. Pourquoi avez-vous eu besoin de WYSIWYG1.2. Description de la tâche des développeurs2. Comment choisir l'outil3. Que s'est-il passé?3.1. Architecture de service3.2. Quels sont les défis4. Résultats du test bêta1. Introduction
1.1. Pourquoi avez-vous eu besoin de WYSIWYG
Sports.ru est un média sur le sport avec un public de 20 millions d'utilisateurs par mois. Nos principales différences par rapport aux médias classiques sont la communauté et l' UGC . Le contenu utilisateur - évaluations, commentaires, chats, publications - complète non seulement la valeur éditoriale, mais crée également une plate-forme permettant aux utilisateurs d'interagir les uns avec les autres. Chaque mois, nos utilisateurs écrivent près de 10 000 messages. Les meilleurs d'entre eux sont soumis à la page principale du site avec les éditoriaux, envoyés aux applications mobiles, aux réseaux sociaux. Le contenu utilisateur représente environ 40% de toutes les lectures sur les pages Sports.ru.Nous voulons être la plate-forme la plus pratique pour les auteurs sportifs, pour aider à créer du contenu et à le livrer à un public intéressé. 10 ans, nous avons utilisé l'éditeur TinyMCE- et finalement il est devenu obsolète, il a cessé de convenir à la fois à l'équipe et aux utilisateurs habitués aux éditeurs modernes.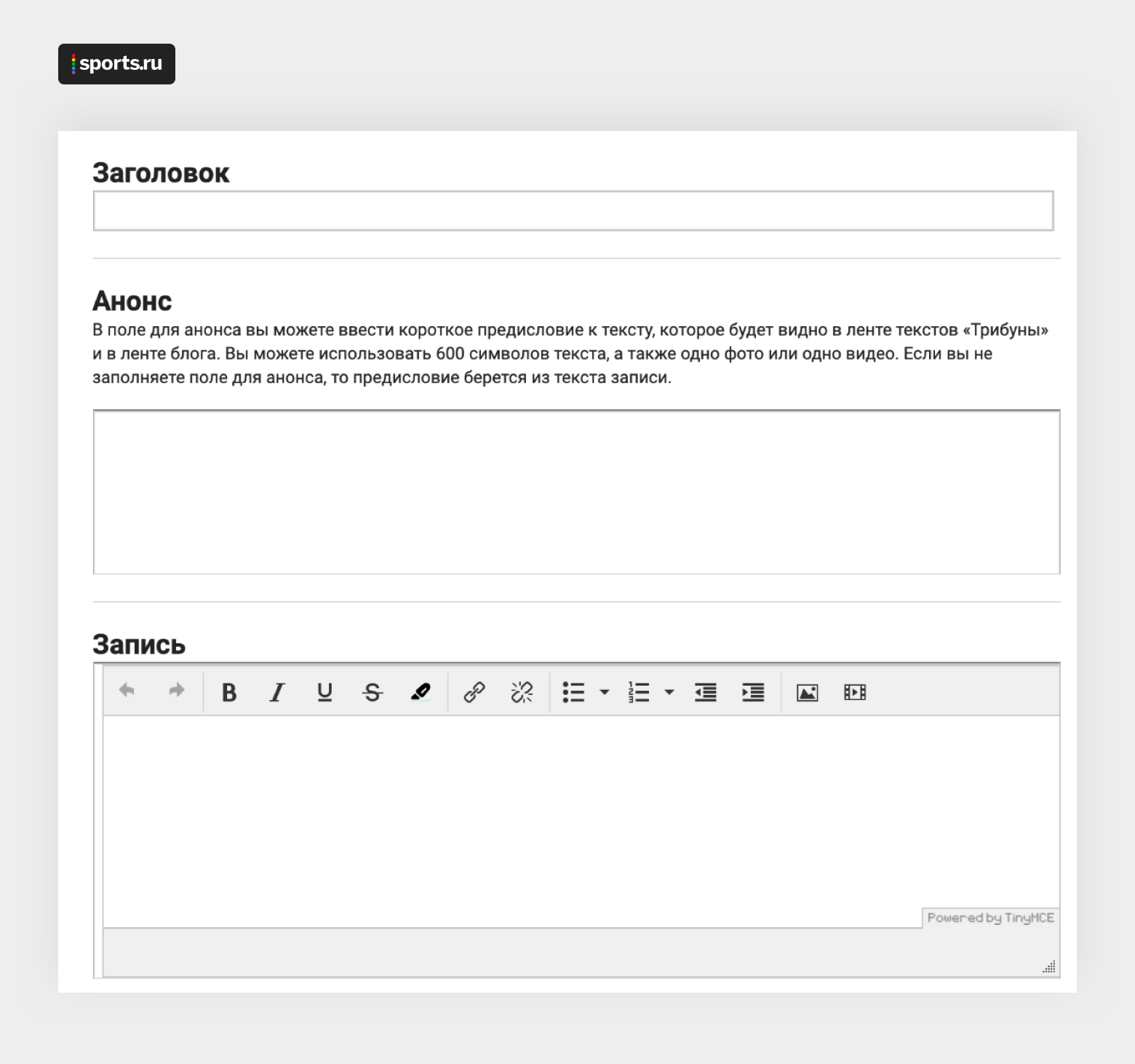 Figure. 1. L'interface de l'ancien éditeur basé sur TinyMCEDes auteurs de blogs ont régulièrement reçu les plaintes suivantes:
Figure. 1. L'interface de l'ancien éditeur basé sur TinyMCEDes auteurs de blogs ont régulièrement reçu les plaintes suivantes:- J'ai écrit pendant longtemps, puis j'ai accidentellement fermé l'onglet et tout a disparu;
- écrire de longs textes est très gênant;
- Il est gênant que pour insérer chaque image, vous devez d'abord la télécharger sur l'hébergement d'images.
L'équipe avait également ses propres plaintes:- dans TinyMCE, vous ne pouvez pas télécharger d'images directement à partir d'un fichier, vous pouvez uniquement attacher des liens vers des images, et en raison du fait que les utilisateurs n'ont pas pu télécharger des images vers notre stockage, si des liens vers eux sont morts, nous ne pourrions rien faire à ce sujet;
- les possibilités d'édition et de mise en forme du texte ne sont pas équilibrées. D'une part, il n'y avait pas assez de styles, par exemple, pour les en-têtes internes dans le texte. D'un autre côté, il était possible d'utiliser les outils disponibles dans n'importe quelle combinaison. En conséquence, les messages ne semblaient pas uniformes (sur Sports.ru, les travaux ont commencé sur la mise en œuvre du système de conception et les messages des utilisateurs devraient être conformes à celui-ci);
- le contenu est créé et stocké en HTML, il est donc difficile de gérer les styles dans les publications sur différents clients et de simplement modifier la disposition des publications.
Voici une histoire sur la façon dont nous avons résolu le problème de la création d'un nouvel éditeur sur le côté frontal. Certes, il y aura aussi quelque chose au sujet du produit, de la conception et des composants de backend, car sans cela, il sera difficile de comprendre pourquoi une décision particulière a été prise à l'avant.1.2. Description de la tâche des développeurs
En bref, la thèse dont nous nous sommes d'abord inspirés: bloguer sur Sports.ru est une douleur. En principe, il serait possible de ne pas créer un nouvel éditeur, mais simplement d'ajouter la sauvegarde automatique et la possibilité de télécharger des photos sur votre propre stockage - et la plupart des plaintes des utilisateurs et des employés disparaîtraient. Mais je ne voulais toujours pas soutenir l'outil sur les anciennes technologies, mais créer un nouvel éditeur moderne que nous pouvons facilement développer et faire évoluer.En plus de l'interface peu pratique, l'un des principaux problèmes techniques de l'ancien éditeur était que le contenu de la publication était immédiatement enregistré sous forme de chaîne HTML et que les modifications de l'apparence de la publication nécessitaient l'intervention de développeurs principaux ou étaient mises en œuvre au moment de l'exécution sur le client (par exemple, le placement des blocs d'annonces). dans le corps du message). Notre tâche, entre autres, était de séparer les données de leur présentation et, par conséquent, de laisser la disposition et l'interface dans le code client, et de travailler avec les données dans le code serveur.Comme modèle, nous avons pris Medium , espionnant parfois les idées de Google Doc . En plus de résoudre les problèmes déjà identifiés, nous avons décidé d'ajouter plusieurs nouvelles fonctionnalités qui rendraient l'utilisation de l'éditeur plus confortable:- WYSIWYG, .. what you see is what you get (. « , », ), , . , ;
- ( , , , , ; , ) .
Dans le même temps, l'éditeur lui-même n'aurait pas dû être lié aux fonctionnalités de Sports.ru, car Sports.ru, bien que le projet phare de notre société, ne soit toujours pas le seul. La société développe également le média sportif international Tribuna , un réseau social pour les amateurs de paris Betting Insider , et a récemment lancé son propre studio de production engagé dans des projets publicitaires. Développer un éditeur en ligne coûte assez cher pour ne pas vouloir réutiliser ce code sur un autre site avec une composition et des styles différents, avec son propre ensemble d'outils pour l'édition et la mise en forme.Nous avons beaucoup de contenu texte, et avant de commencer à travailler sur la création d'un nouvel éditeur de publication, nous avons réfléchi à la façon dont ce contenu devrait être stocké. TinyMCE ne nous a pas laissé le choix et le contenu devait être stocké uniquement en HTML, ce qui, comme mentionné ci-dessus, ne convenait pas à l'équipe. En conséquence, nous avons mis au point notre propre format de stockage des données texte qui répond à nos exigences, et nous l'avons appelé corps structuré.Le corps structuré est un tableau d'objets qui reflète la structure du contenu. Dans ce cas, le contenu est divisé en éléments qui sont des blocs indépendants, par exemple, paragraphe, liste, image. Un élément stocke des informations sur son type et ses propriétés. Par exemple, le bloc de sous-titres décrit le titre dans le texte, il doit contenir le texte et les champs de niveau. En conséquence, le texte contient le texte de cette rubrique et le niveau contient le niveau (de 1 à 4). Un corps structuré, composé d'un en-tête de deuxième niveau, pourrait ressembler, par exemple, à ceci:const structuredBody = [
{
type: 'subtitle',
value: {
text: ' ',
level: 2,
},
},
];
La transition vers un corps structuré nous a permis d'entamer le processus de séparation de la logique métier, des données et de leur présentation. En fin de compte, nous voulons que le serveur et les clients n'échangent que des données. Et comment et pourquoi afficher ces données à l'utilisateur final, chaque client le déterminera indépendamment.Le contenu au format corps formatd est stocké dans JSON, et pour valider son contenu, nous avons créé un schéma JSON appelé schéma de corps structuré. Ce diagramme décrit tous les éléments valides et leurs propriétés. Ainsi, nous pouvons être sûrs que partout où un corps structuré est nécessaire, un ensemble de clés et de valeurs est utilisé.De plus, cela permet à différentes équipes d'utiliser les mêmes services pour traiter du contenu dans ce format. Par exemple, un service pour générer du HTML à partir d'un corps structuré pour afficher du contenu ou un éditeur pour créer du contenu. Cela réduit considérablement le coût de développement et de prise en charge de l'ensemble des services liés à la création et à l'affichage de contenu.Il a été supposé que le nouvel éditeur devrait accepter le contenu d'entrée et de sortie exclusivement dans le format de corps structuré. Et ici, il fallait prendre en compte le point subtil: puisque auparavant les messages étaient immédiatement enregistrés en HTML, cette chaîne HTML de la base de données était transmise au client pour affichage (ci-après, par le client, nous entendons uniquement le navigateur, sauf indication contraire). Maintenant, nous voulons stocker le contenu de toutes les publications dans le corps structuré, mais les clients ne peuvent traiter que du HTML. Ainsi, parallèlement à la tâche de passer à un nouvel éditeur, la tâche d'implémenter une nouvelle façon pour les clients d'afficher les articles à lire directement à partir du corps structuré se poursuit simultanément. Nous avons décidé qu'il vaut mieux manger un éléphant au coup par coup, donc vous devez d'abord abandonner complètement TinyMCE, et ensuite seulement adopter la logique d'affichage des messages à lire. De plus,tous les anciens messages n'ont pas réussi à traduire le contenu dans un nouveau format, ce qui signifie que ces messages seront toujours stockés uniquement en HTML et il est nécessaire qu'ils conservent également la possibilité de lire.Total: une partie des articles (tous les nouveaux et anciens qui ont été transférés avec succès vers le nouveau format) seront stockés dans deux formats - HTML et corps structuré - jusqu'à ce que la nouvelle logique d'affichage pour la lecture soit mise en œuvre, et le reste (la plupart des anciens et très très anciens) messages) resteront uniquement en HTML.2. Comment choisir un outil
Nous devions réaliser la possibilité de modifier et de créer un article sur le client, en tenant compte des caractéristiques et des limitations ci-dessus. Comme toujours, vous pouvez prendre une solution toute faite ou vous pouvez proposer la vôtre.Pour commencer, nous avons examiné ce que sont les bibliothèques prêtes à l'emploi pour créer des éditeurs WYSIWYG et si elles nous conviennent. Nous nous sommes installés sur Slate , Draft.js et ProseMirror .En plus de stocker du contenu dans une structure de données, le moment critique pour nous a également été la possibilité de travailler avec Vue ou JS pur, car nous avions déjà commencé à déplacer le site vers une nouvelle pile technologique utilisant Vue + Vuex. De plus, je voudrais étendre les capacités de la bibliothèque terminée avec l'aide de nouveaux modules (tiers ou auto-écrits) si nécessaire.Languette. 1. Comparaison des bibliothèques examinées par les paramètres les plus importants pour Sports.ru Comme vous pouvez le voir dans le tableau, ProseMirror a pleinement respecté nos exigences, nous n'avons donc plus envisagé l'idée d'écrire notre propre bibliothèque pour éditer le contenu du texte, mais nous avons commencé à étudier cette bibliothèque plus en détail. Il y a encore une plume assez populaire , qui n'est pas entrée dans notre comparaison juste parce que nous l'avons honnêtement oublié au stade de la sélection d'un outil. Selon nos principales exigences, cela passe également, mais il en est ainsi. Nous avons déjà parlé de ce qu'est ProseMirror et comment travailler avec lui dans un autre article .
Comme vous pouvez le voir dans le tableau, ProseMirror a pleinement respecté nos exigences, nous n'avons donc plus envisagé l'idée d'écrire notre propre bibliothèque pour éditer le contenu du texte, mais nous avons commencé à étudier cette bibliothèque plus en détail. Il y a encore une plume assez populaire , qui n'est pas entrée dans notre comparaison juste parce que nous l'avons honnêtement oublié au stade de la sélection d'un outil. Selon nos principales exigences, cela passe également, mais il en est ainsi. Nous avons déjà parlé de ce qu'est ProseMirror et comment travailler avec lui dans un autre article .3. Que s'est-il passé
3.1. Architecture de service
L'éditeur de contenu lui-même sur le client est loin d'être tout. Vous devez placer l'éditeur dans un projet existant, l'afficher quelque part sur la page Web et également envisager une interaction avec le backend, résoudre le problème de la prise en charge simultanée de deux éditeurs (vous ne pouviez pas immédiatement abandonner l'ancien) et stocker le contenu dans deux formats (HTML et structuré corps).Toutes ces tâches peuvent être divisées en celles liées au frontend, au backend et à leur intégration. Nous sommes principalement concernés par les problèmes de front-end et d'intégration, bien que nous mentionnions également quelques aspects importants des tâches back-end.Les services frontaux pour l'éditeur peuvent être divisés en plusieurs niveaux:- page Web pour créer et éditer une publication;
- Vue-app, . , , Vue, -, , , , .., , , ;
- WYSIWYG- ProseMirror, Vue. , , ;
- SB2HTML – HTML structured body, . , structured body – , . , , , . Sports.ru HTML structured body, - HTML . HTML Node.Js, JS- .
Le processus d'enregistrement du message est illustré à la Fig. 2. Le contenu du message au format de corps structuré et ses métadonnées sont transférés au backend. Le backend envoie du contenu au service SB2HTML, reçoit le code HTML prêt dans la réponse, met tout cela dans la base de données et indique au client que la publication a été enregistrée avec succès, ou signale une erreur.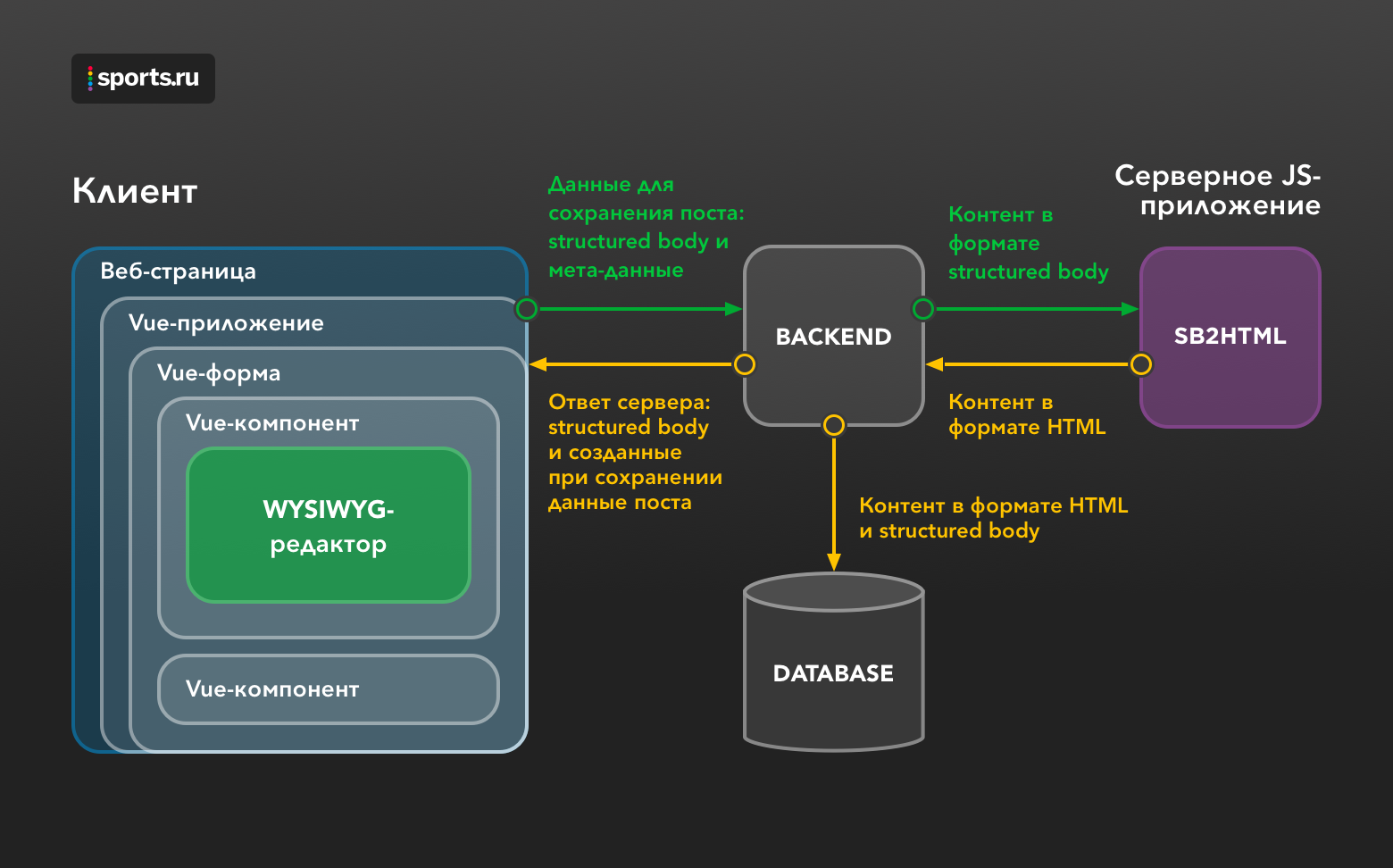 Figure. 2. Schéma d'enregistrement d'une publication lors de la création ou de la modification dans un éditeur WYSIWYG
Figure. 2. Schéma d'enregistrement d'une publication lors de la création ou de la modification dans un éditeur WYSIWYG3.2. Quelles difficultés avez-vous rencontrées?
Les difficultés sont nombreuses, elles surgissent constamment et souvent dans les moments les plus inattendus.Comme nous l'avons déjà dit, l'éditeur de contenu est situé à l'intérieur du formulaire, ce qui vous permet de saisir les données supplémentaires nécessaires à la création d'une publication, telles que le titre, l'annotation, etc. Pour l'annotation, il devrait être possible de télécharger des images à partir d'un fichier et via un lien depuis Internet. Mais pour le contenu, nous voulons également charger des images à partir d'un fichier et par référence, en outre, selon les mêmes règles. Et ici, nous sommes confrontés à un dilemme: d'une part, le contenu du message est isolé du formulaire externe lors de l'édition et est servi par les outils ProseMirror, mais d'autre part, je veux observer le principe DRYet ne dupliquez pas le même code. Nous avons résolu ce problème comme suit: nous avons décrit le chargement d'images comme un ensemble de méthodes dans un objet au niveau du formulaire Vue et passé cet objet comme l'un des paramètres au constructeur de l'éditeur WYSIWYG.Les entités qui décrivent le contenu - Node et Fragment - sont définies dans le modèle ProseMirror. Cependant, seuls les index sont utilisés pour une transaction afin de déterminer la plage de caractères à laquelle cette transaction est appliquée (les index sont comptés à la fois depuis le début du document et depuis le début du nœud parent). L'indexation des caractères est l'un des concepts centraux de ProseMirror, mais lors de l'édition et de la mise en forme du texte, il est beaucoup plus pratique de penser aux entités du modèle ProseMirror. En conséquence, pour un travail confortable avec le contenu, nous avons écrit nos assistants pour simplifier l'interaction avec un document pour les transactions. Après le début de notre travail, la bibliothèque tiptap est apparue , qui est un ensemble d'aides similaires.Le problème suivant était qu'au stade de la création du schéma, nous nous sommes rendu compte que nous avions déjà un format interne approuvé pour stocker le contenu - un corps structuré qui répond à nos besoins, et ProseMirror stocke le contenu dans son propre format dans une histoire. Le passage au format ProseMirror était difficile et peu pratique. Nous nous sommes retrouvés dans une situation où les données dans un format arrivent au client via l'API, et un autre doit être affiché. Une situation similaire se produit lorsqu'il est nécessaire d'enregistrer du contenu modifié ou créé. Pour ce faire, nous avons implémenté un convertisseur qui convertit les formats dans les deux sens. Ils ont écrit un test simple pour lui, qui prend le contenu d'un article au format corps formatd, le traduit au format ProseMirror, puis revient et compare déjà la version originale avec celle reçue. Cela s'est avéré rapidement et facilement.Plus tard, au fur et à mesure que le schéma des documents a changé et, en règle générale, est devenu plus compliqué, il est devenu clair que le moindre changement pouvait entraîner des erreurs dans l'éditeur, et un tel test semble donner une très mauvaise couverture. En conséquence, j'ai dû écrire des tests sur presque toutes les combinaisons de nœuds et de marques sur deux petites méthodes de conversion. Maintenant, sans ces tests, il est impossible de déterminer si le prochain changement de circuit cassera quelque chose ou non.Le problème suivant est à nouveau lié au besoin de compatibilité descendante des anciennes et nouvelles technologies. Notre éditeur WYSIWYG est implémenté uniquement dans les navigateurs (ordinateur de bureau et, bientôt, mobile). En conséquence, pour l'édition de contenu sur le client est donné en JSON dans le corps structuré de format, cependant, la lecture des messages dans les navigateurs est effectuée uniquement à partir de HTML. Dans le même temps, la plupart des applications mobiles sont déjà passées à l'affichage de messages d'utilisateurs directement à partir d'un corps structuré.Pour les applications mobiles, il était nécessaire de prévoir le cas où le client ne peut pas traiter certains éléments du corps structuré. Par exemple, si un nouvel élément est ajouté au corps structuré, dont l'affichage n'est implémenté que dans une version plus récente de l'application. Étant donné que tous les utilisateurs ne mettent pas à jour leurs applications en même temps, il était nécessaire de fournir un plan «B» pour les anciennes versions: au lieu de créer du HTML à partir d'un corps structuré, insérez un fragment HTML prêt à l'emploi pour l'élément souhaité. La présence de fragments HTML pour chaque élément n'était pas prévue dans le schéma de corps structuré, car l'idée même de cette structure était de refuser de stocker des données en HTML. Mais à la fin, nous sommes arrivés à la conclusion que nous avons besoin de deux schémas de corps structurés - un pour l'affichage et un pour l'édition. Les différences entre les régimes sontque le corps structuré pour l'édition ne contient que le contenu de l'article, et pour l'affichage nous ajoutons quelques éléments supplémentaires. En particulier, un fragment HTML pour chaque élément est créé lorsqu'un message est enregistré dans le service SB2HTML et est ajouté uniquement au corps structuré pour afficher le message. De plus, le corps structuré affiche également de l'espace publicitaire dans le contenu à afficher.Lorsque nous ouvrons du contenu pour le modifier dans un navigateur, nous ne pouvons pratiquement pas rencontrer d'élément inconnu, car tous les articles sont créés et affichés de la même manière. Mais ils ont décidé de prévoir un tel cas pour l'avenir également. Pour ce faire, nous avons ajouté un élément stub par défaut au schéma ProseMirror. Nous avons nommé cet élément unsupportedBlock. Le talon apparaît à la place d'un élément non pris en charge. Nous l'avons stylisé comme un rectangle gris avec du texte indiquant que cet élément n'est pas pris en charge et ne peut pas être modifié. Lorsqu'un article est enregistré, un tel élément reste inchangé dans le corps structuré. L'utilisateur peut modifier son emplacement par rapport à d'autres éléments, mais le contenu interne d'un élément inconnu ne peut pas être modifié ou modifié. Cependant, l'utilisateur peut supprimer un tel élément, puis, bien sûr,il ne sera pas enregistré dans le document final.Tous les problèmes décrits étaient liés aux difficultés de mise en œuvre de l'éditeur WYSIWYG lui-même. Mais alors qu'il existait en mode bêta, nous ne pouvions pas abandonner l'ancien éditeur sur TinyMCE et avons été obligés de prendre en charge les deux éditeurs, offrant une compatibilité descendante entre eux. Par exemple, vous pouvez créer un article dans l'éditeur WYSIWYG, l'enregistrer, le modifier dans TinyMCE, l'enregistrer, l'ouvrir à nouveau dans WYSIWYG, etc. Par conséquent, lors de l'ouverture dans WYSIWYG, nous avons vu le même contenu que dans la sauvegarde précédente dans TinyMCE. Pour implémenter la compatibilité descendante, il était nécessaire de soumettre du contenu HTML à TinyMCE, que nous avons déjà appris à créer à partir d'un corps structuré et à enregistrer dans la base de données lors de l'enregistrement de la publication. Et lors de l'enregistrement d'une publication via TinyMCE, le contenu créé sur le serveur est exécuté via le service HTML2SB,en conséquence, nous pouvons enregistrer à la fois du HTML frais et un corps structuré.HTML2SB est l'opposé de ce que fait SB2HTML, c'est-à-dire qu'il convertit le contenu HTML en corps structuré. Chronologiquement, ce service est apparu plus tôt que toute autre chose, car avant la création de l'éditeur WYSIWYG, la seule façon d'obtenir du contenu de publication au format de corps structuré était l'analyse directe à partir de HTML. HTML2SB faisait partie de l'infrastructure backend autour de l'éditeur de publication, mais après avoir abandonné TinyMCE, il n'était plus nécessaire.4. Résultats bêta
Maintenant, l'éditeur WYSIWYG est disponible pour tous les utilisateurs en version bêta, et deviendra bientôt l'éditeur principal des articles Sports.ru. Nous avons déjà reçu un outil pour créer et éditer des articles qui répond à la plupart de nos exigences:- l'interface de l'éditeur est devenue claire, concise et moderne, la rédaction de longs articles est devenue beaucoup plus facile;
- Vous pouvez maintenant télécharger des images à partir d'un fichier et par un lien qui sont immédiatement placés dans notre référentiel;
- ajouté la possibilité d'intégrer les intégrations des principaux réseaux sociaux et sites d'hébergement vidéo;
- nettoyé les styles de mise en forme du texte;
- les applications mobiles sont déjà passées à l'affichage de publications à partir d'un corps structuré et peuvent définir leurs propres styles de contenu.
Bien sûr, l'éditeur n'est pas encore complètement débogué, nous détectons périodiquement de nouveaux bugs. Les mises à jour suivantes arrivent:- sauvegarde automatique;
- Version WYSIWYG pour les utilisateurs avec des droits étendus (administrateurs, éditeurs à temps plein);
- créer et modifier des articles à partir de navigateurs mobiles;
- Messages sur l'édition parallèle d'un document par plusieurs utilisateurs;
- pourboires et intégration;
- widgets statistiques pour les équipes sportives, les matchs et les alignements.
Au moment d'écrire ces lignes, plus de 13000 articles ont déjà été publiés via la version bêta de l'éditeur, ce qui représente environ 20% du nombre total de textes utilisateur sur Sports.ru pour la période de juin 2019 à février 2020 inclus. La part des articles créés et publiés par le nouvel éditeur augmente régulièrement.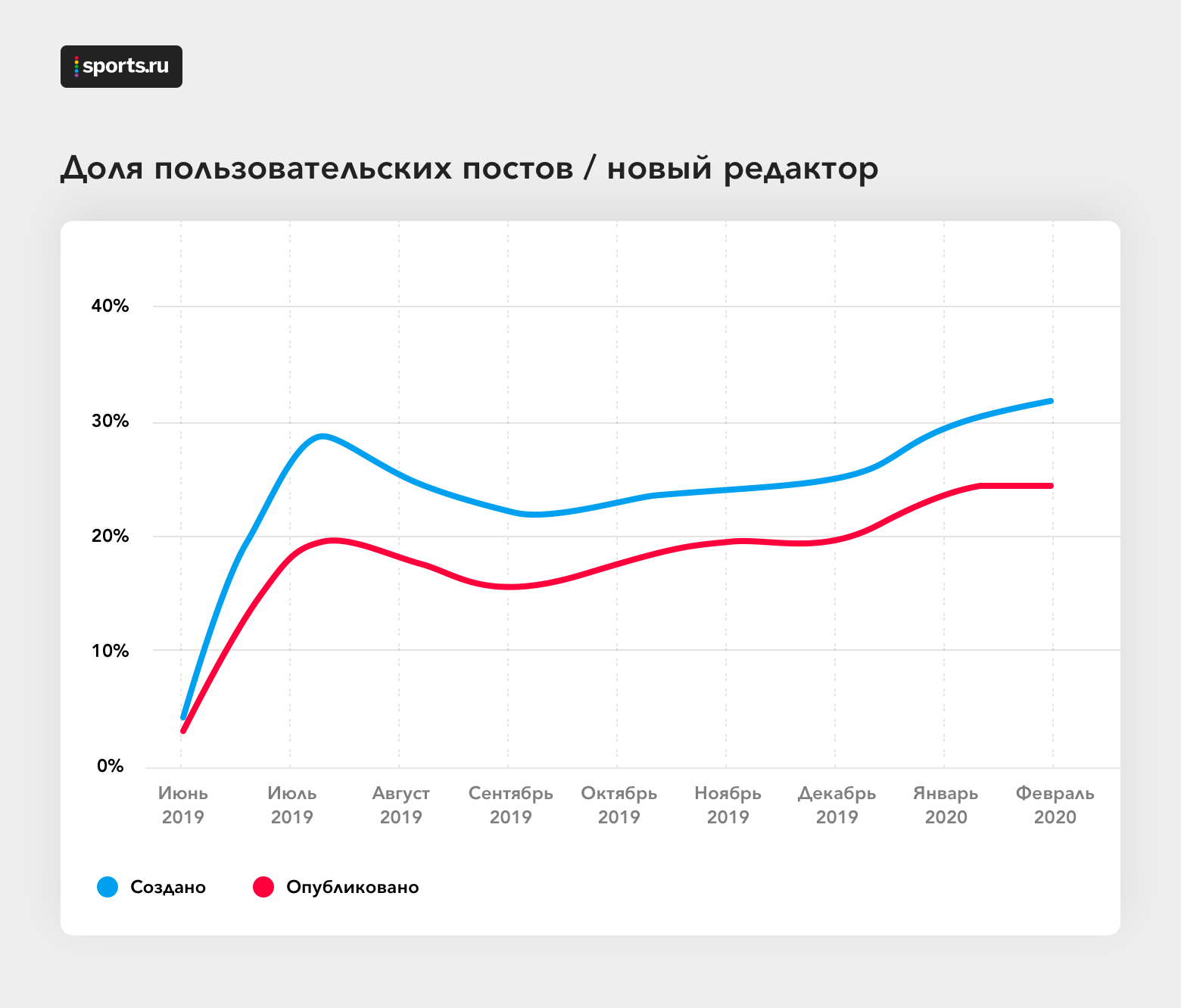 Figure. 3. La proportion de messages d'utilisateurs créés et publiés dans le nouvel éditeurIl semble que la croissance organique de la part des publications d'utilisateurs créées et publiées via le nouvel éditeur soit un signe que les utilisateurs sont satisfaits de la mise à jour, ce qui est également confirmé par les commentaires lors de l'annonce de son lancement en bêta-test (certains d'entre eux sont illustrés sur la figure 4). Par conséquent, dans les mois à venir, nous prévoyons de transférer complètement la création de messages vers le nouvel éditeur, afin de nous concentrer uniquement sur son support et son développement. Au fait, quelle fonctionnalité ajouteriez-vous à notre éditeur WYSIWYG?
Figure. 3. La proportion de messages d'utilisateurs créés et publiés dans le nouvel éditeurIl semble que la croissance organique de la part des publications d'utilisateurs créées et publiées via le nouvel éditeur soit un signe que les utilisateurs sont satisfaits de la mise à jour, ce qui est également confirmé par les commentaires lors de l'annonce de son lancement en bêta-test (certains d'entre eux sont illustrés sur la figure 4). Par conséquent, dans les mois à venir, nous prévoyons de transférer complètement la création de messages vers le nouvel éditeur, afin de nous concentrer uniquement sur son support et son développement. Au fait, quelle fonctionnalité ajouteriez-vous à notre éditeur WYSIWYG? Figure. 4. Commentaires des utilisateurs dans un article avec l'annonce de la mise à jour de l'éditeur WYSIWYG
Figure. 4. Commentaires des utilisateurs dans un article avec l'annonce de la mise à jour de l'éditeur WYSIWYG