Pandas n'a pas besoin d'être présenté: c'est aujourd'hui le principal outil d'analyse des données en Python. Je travaille comme spécialiste de l'analyse de données, et malgré le fait que j'utilise des pandas tous les jours, je ne cesse d'être surpris par la diversité des fonctionnalités de cette bibliothèque. Dans cet article, je veux parler de cinq fonctions pandas peu connues que j'ai récemment apprises et que j'utilise maintenant de manière productive.Pour les débutants: Pandas est une boîte à outils hautes performances pour l'analyse de données en Python avec des structures de données simples et pratiques. Le nom vient du concept de «données de panel», un terme économétrique qui se réfère aux données sur les observations des mêmes sujets sur différentes périodes de temps.Ici vous pouvez télécharger le Notebook Jupyter avec des exemples de l'article.1. Plages de dates [Plages de dates]
Souvent, vous devez spécifier des plages de dates lors de la demande de données à partir d'une API externe ou d'une base de données. Les pandas ne nous laisseront pas de problèmes. Juste pour ces cas, il y a la fonction data_range , qui retourne un tableau de dates augmenté de jours, mois, années, etc.Disons que nous avons besoin d'une plage de dates par jour:date_from = "2019-01-01"
date_to = "2019-01-12"
date_range = pd.date_range(date_from, date_to, freq="D")
date_range
 Nous transformerons le généré de
Nous transformerons le généré de date_rangeen paires de dates «du» et «au», qui peuvent être transférées à la fonction correspondante.for i, (date_from, date_to) in enumerate(zip(date_range[:-1], date_range[1:]), 1):
date_from = date_from.date().isoformat()
date_to = date_to.date().isoformat()
print("%d. date_from: %s, date_to: %s" % (i, date_from, date_to))
1. date_from: 2019-01-01, date_to: 2019-01-02
2. date_from: 2019-01-02, date_to: 2019-01-03
3. date_from: 2019-01-03, date_to: 2019-01-04
4. date_from: 2019-01-04, date_to: 2019-01-05
5. date_from: 2019-01-05, date_to: 2019-01-06
6. date_from: 2019-01-06, date_to: 2019-01-07
7. date_from: 2019-01-07, date_to: 2019-01-08
8. date_from: 2019-01-08, date_to: 2019-01-09
9. date_from: 2019-01-09, date_to: 2019-01-10
10. date_from: 2019-01-10, date_to: 2019-01-11
11. date_from: 2019-01-11, date_to: 2019-01-12
2. Fusionner avec l'indicateur source [Fusionner avec l'indicateur]
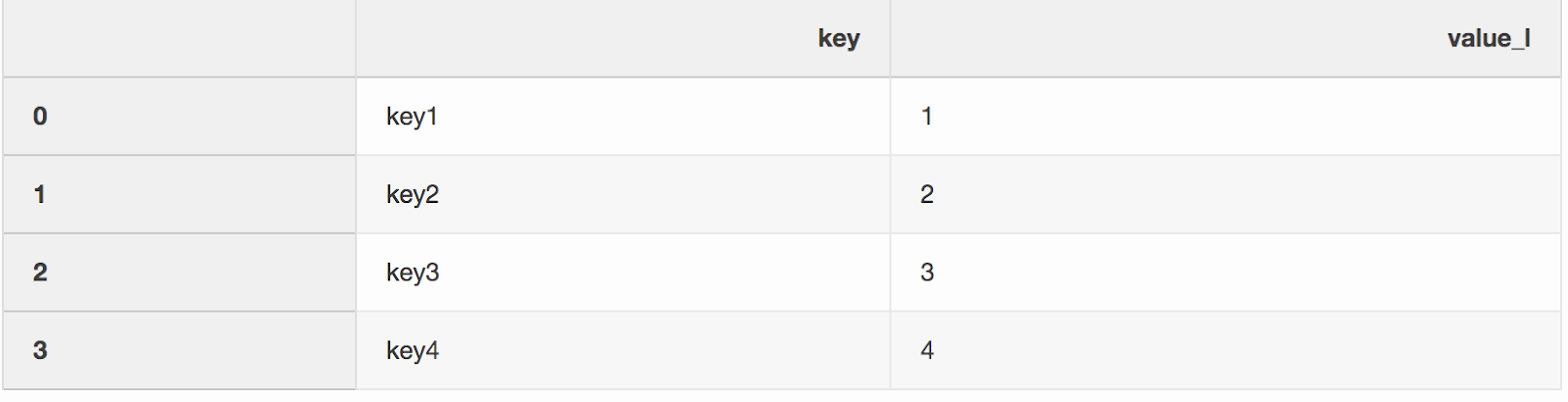
La fusion de deux jeux de données est, curieusement, le processus de combinaison de deux jeux de données en un dont les lignes sont mappées en fonction de colonnes ou de propriétés communes.L'un des deux arguments de la fonction de fusion, que j'ai en quelque sorte manqué, est indicator. L '«indicateur» ajoute une colonne _mergeau DataFrame qui indique d'où vient la ligne, de gauche, de droite ou des deux DataFrames. Une colonne _mergepeut être très utile lorsque vous travaillez avec de grands ensembles de données pour vérifier que la fusion est correcte.left = pd.DataFrame({"key": ["key1", "key2", "key3", "key4"], "value_l": [1, 2, 3, 4]})
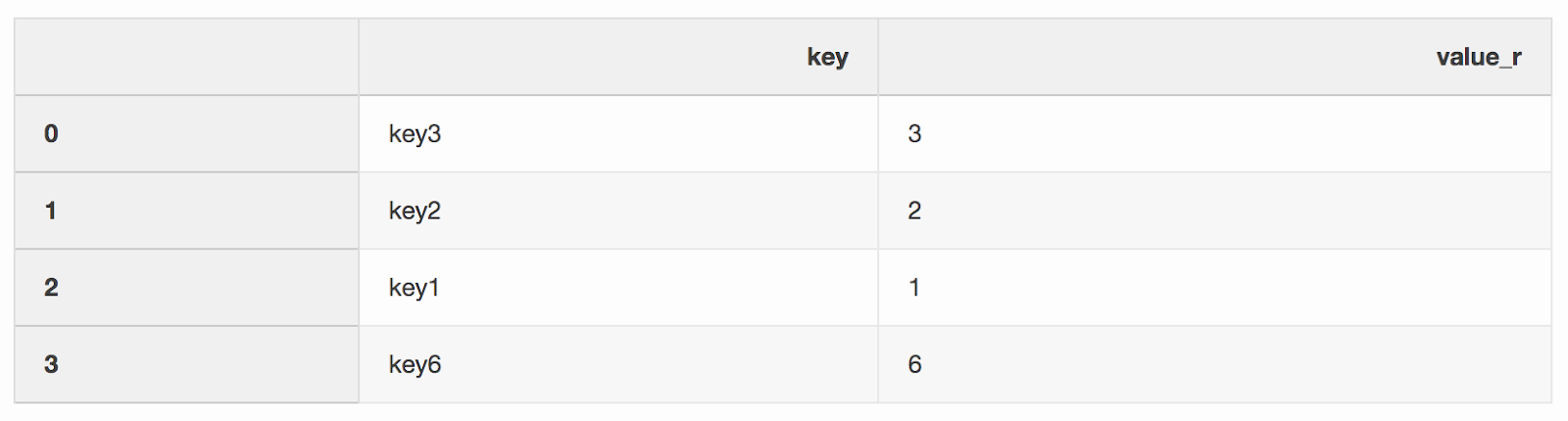
right = pd.DataFrame({"key": ["key3", "key2", "key1", "key6"], "value_r": [3, 2, 1, 6]})
df_merge = left.merge(right, on='key', how='left', indicator=True)
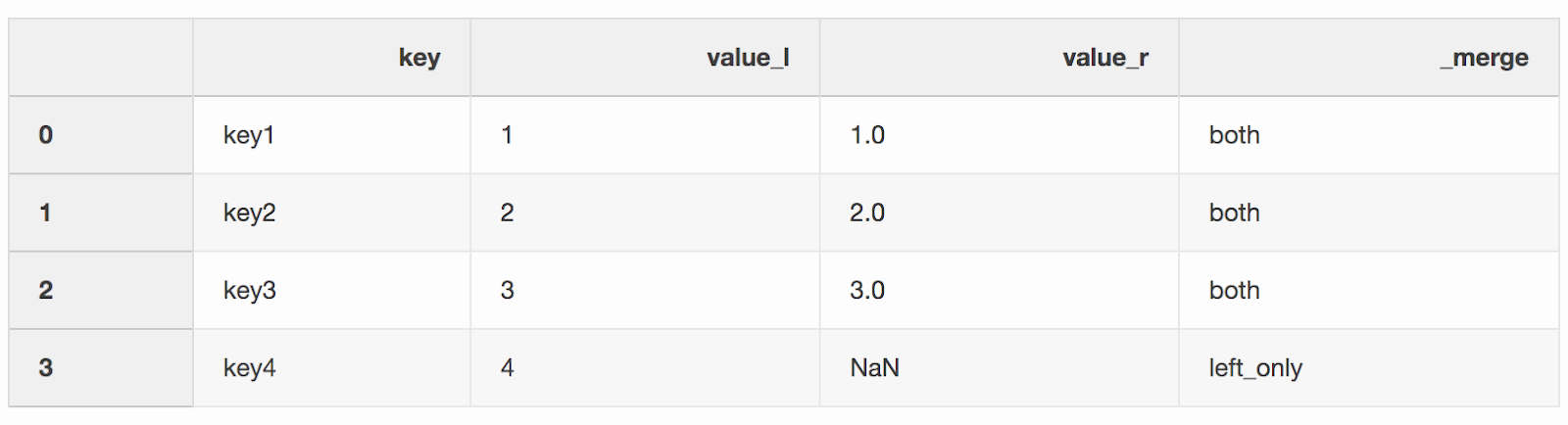 La colonne
La colonne _mergepeut être utilisée pour vérifier si le nombre correct de lignes contenant des données provient des deux DataFrames.df_merge._merge.value_counts()
both 3
left_only 1
right_only 0
Name: _merge, dtype: int64
3. Fusionner par la valeur la plus proche [Fusion la plus proche]
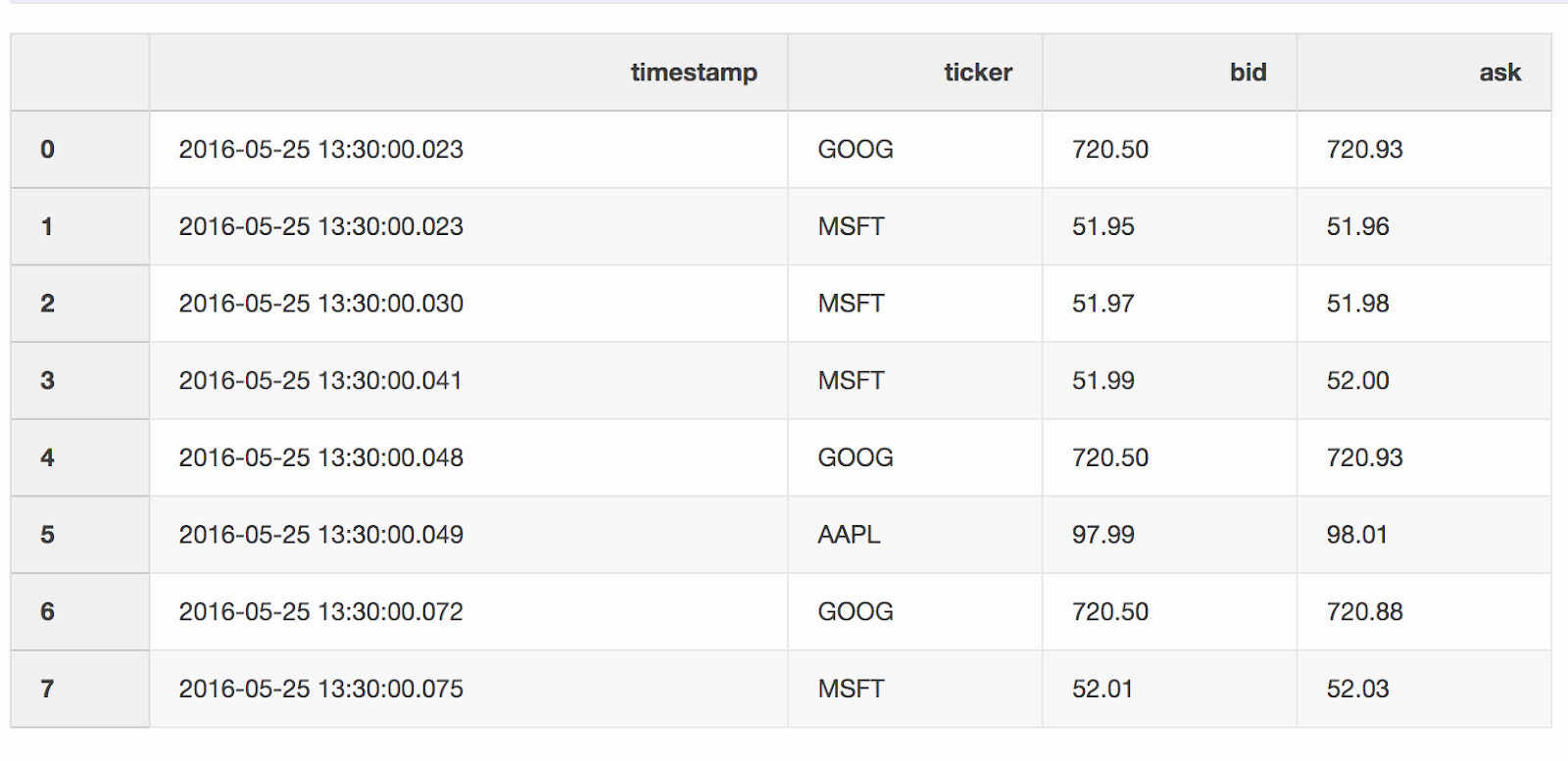
Lorsque vous travaillez avec des données financières, telles que des crypto-monnaies et des titres, il peut être nécessaire de comparer les devis (changements de prix) avec les transactions. Disons que nous voulons combiner chaque transaction avec un devis mis à jour quelques millisecondes avant la transaction. Pandas a une fonction merge_asofgrâce à laquelle il est possible de combiner DataFrames par la valeur de clé la plus proche ( timestampdans notre cas). Les ensembles de données avec des devis et des offres sont tirés de l' exemple des pandas .DataFrame quotes(«devis») contient les changements de prix pour différents stocks. En règle générale, il y a beaucoup plus de devis que d'offres.quotes = pd.DataFrame(
[
["2016-05-25 13:30:00.023", "GOOG", 720.50, 720.93],
["2016-05-25 13:30:00.023", "MSFT", 51.95, 51.96],
["2016-05-25 13:30:00.030", "MSFT", 51.97, 51.98],
["2016-05-25 13:30:00.041", "MSFT", 51.99, 52.00],
["2016-05-25 13:30:00.048", "GOOG", 720.50, 720.93],
["2016-05-25 13:30:00.049", "AAPL", 97.99, 98.01],
["2016-05-25 13:30:00.072", "GOOG", 720.50, 720.88],
["2016-05-25 13:30:00.075", "MSFT", 52.01, 52.03],
],
columns=["timestamp", "ticker", "bid", "ask"],
)
quotes['timestamp'] = pd.to_datetime(quotes['timestamp'])
 DataFrame
DataFrame tradescontient des offres pour différents stocks.trades = pd.DataFrame(
[
["2016-05-25 13:30:00.023", "MSFT", 51.95, 75],
["2016-05-25 13:30:00.038", "MSFT", 51.95, 155],
["2016-05-25 13:30:00.048", "GOOG", 720.77, 100],
["2016-05-25 13:30:00.048", "GOOG", 720.92, 100],
["2016-05-25 13:30:00.048", "AAPL", 98.00, 100],
],
columns=["timestamp", "ticker", "price", "quantity"],
)
trades['timestamp'] = pd.to_datetime(trades['timestamp'])
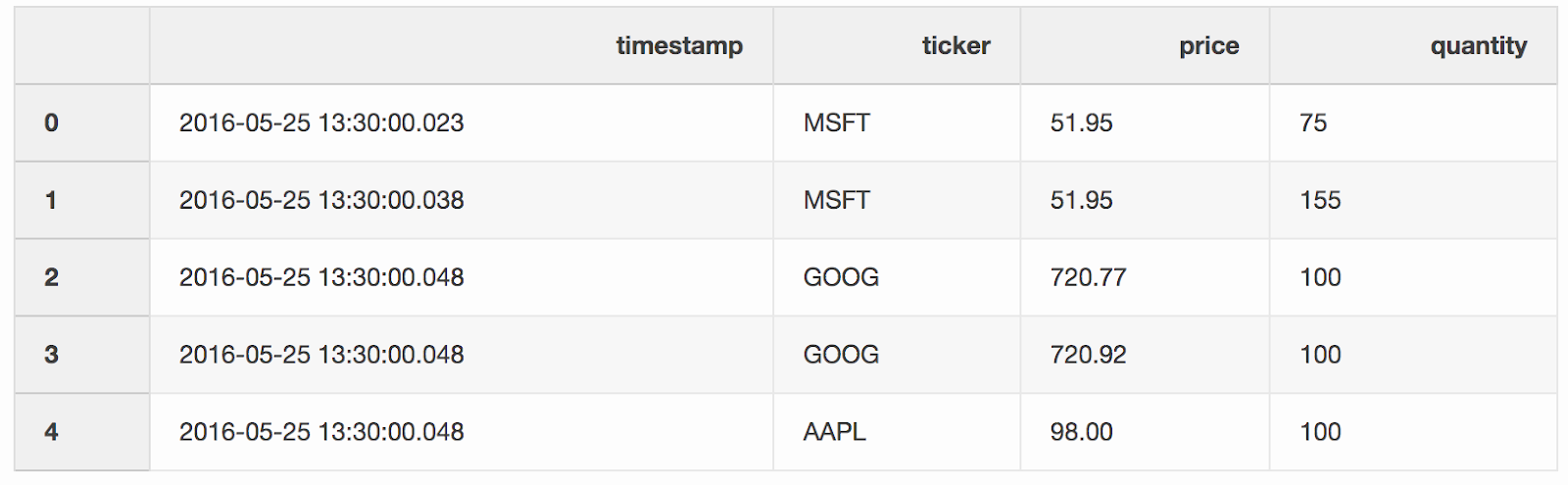 Nous fusionnons les transactions et les cotations par tickers (un instrument coté, comme les actions), à condition que la
Nous fusionnons les transactions et les cotations par tickers (un instrument coté, comme les actions), à condition que la timestampdernière cotation soit inférieure de 10 ms à la transaction. Si le devis est apparu avant la transaction pendant plus de 10 ms, l'offre (le prix que l'acheteur est prêt à payer) et la demande (le prix auquel le vendeur est prêt à vendre) pour ce devis seront null(ticker AAPL dans cet exemple).pd.merge_asof(trades, quotes, on="timestamp", by='ticker', tolerance=pd.Timedelta('10ms'), direction='backward')

4. Création d'un rapport Excel
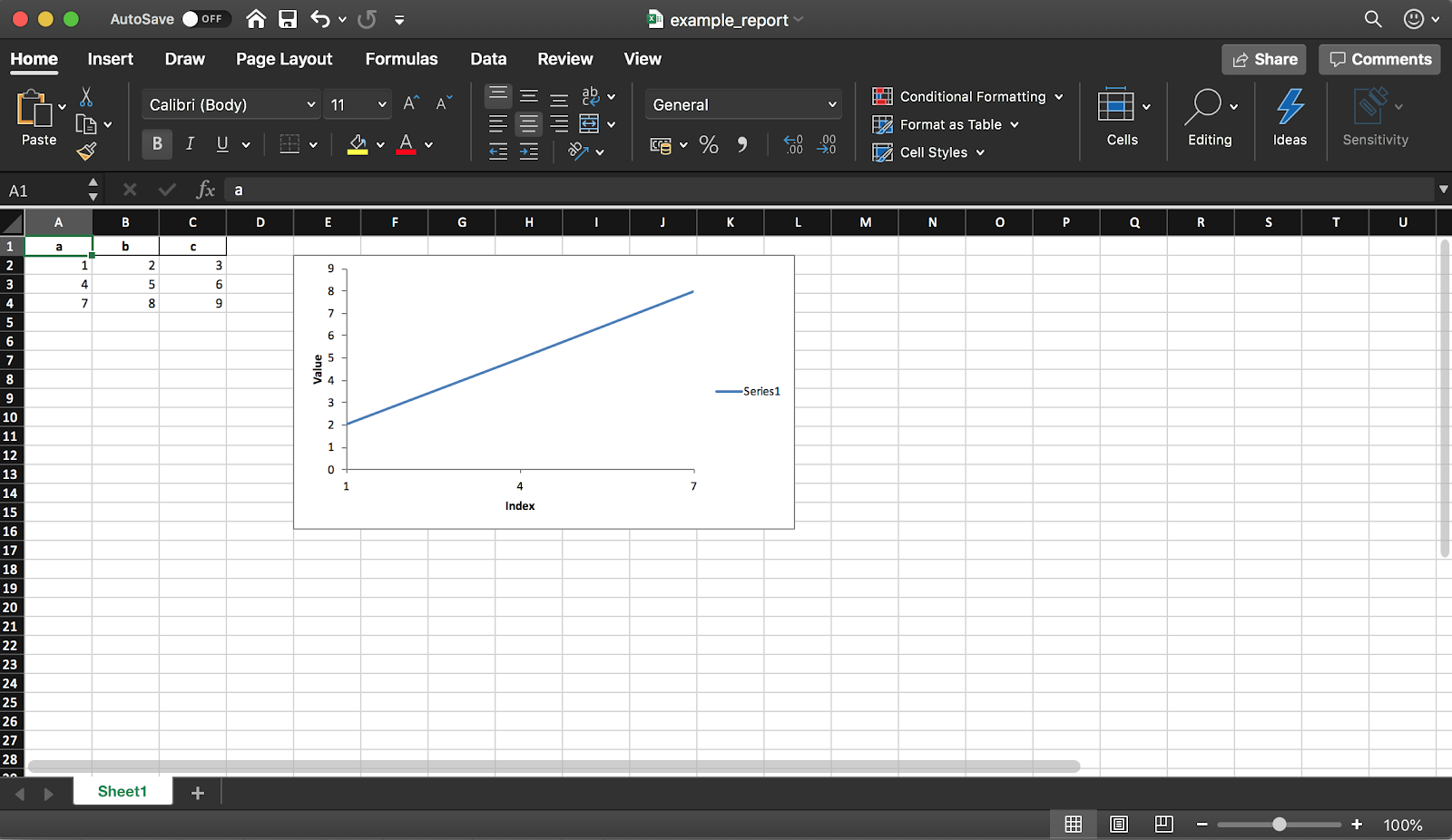 Pandas (avec la bibliothèque XlsxWriter) vous permet de créer un rapport Excel à partir d'un DataFrame. Cela vous fait gagner beaucoup de temps - plus besoin d'exporter un DataFrame vers CSV et de formater manuellement vers Excel. Toutes sortes de diagrammes , etc. sont également disponibles .
Pandas (avec la bibliothèque XlsxWriter) vous permet de créer un rapport Excel à partir d'un DataFrame. Cela vous fait gagner beaucoup de temps - plus besoin d'exporter un DataFrame vers CSV et de formater manuellement vers Excel. Toutes sortes de diagrammes , etc. sont également disponibles .df = pd.DataFrame(pd.np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]]), columns=["a", "b", "c"])
L'extrait de code ci-dessous crée un tableau au format Excel. Décommentez la ligne pour l'enregistrer dans un fichier writer.save().report_name = 'example_report.xlsx'
sheet_name = 'Sheet1'
writer = pd.ExcelWriter(report_name, engine='xlsxwriter')
df.to_excel(writer, sheet_name=sheet_name, index=False)
Comme mentionné précédemment, en utilisant la bibliothèque, vous pouvez également ajouter des graphiques au rapport. Vous devez définir le type de graphique (linéaire dans notre exemple) et la plage de données pour celui-ci (la plage de données doit être dans le tableau Excel).
workbook = writer.book
worksheet = writer.sheets[sheet_name]
chart = workbook.add_chart({'type': 'line'})
chart.add_series({
'categories': [sheet_name, 1, 0, 3, 0],
'values': [sheet_name, 1, 1, 3, 1],
})
chart.set_x_axis({'name': 'Index', 'position_axis': 'on_tick'})
chart.set_y_axis({'name': 'Value', 'major_gridlines': {'visible': False}})
worksheet.insert_chart('E2', chart)
writer.save()
5. Économisez de l'espace disque
Le travail sur un grand nombre de projets d'analyse de données laisse généralement une marque sous la forme d'une grande quantité de données traitées provenant de diverses expériences. Le SSD de l'ordinateur portable se remplit assez rapidement. Pandas vous permet de compresser des données tout en enregistrant des données sur le disque, puis de les relire à partir d'un format compressé.Créez un grand DataFrame avec des nombres aléatoires.df = pd.DataFrame(pd.np.random.randn(50000,300))
 Si vous l'enregistrez au format CSV, le fichier occupera près de 300 Mo sur votre disque dur.
Si vous l'enregistrez au format CSV, le fichier occupera près de 300 Mo sur votre disque dur.df.to_csv('random_data.csv', index=False)
Un argument compression='gzip'réduit la taille du fichier à 136 Mo.df.to_csv('random_data.gz', compression='gzip', index=False)
Un fichier compressé est lu de la même manière qu'un fichier normal, nous ne perdons donc aucune fonctionnalité.df = pd.read_csv('random_data.gz')
Conclusion
Ces petites astuces ont augmenté la productivité de mon travail quotidien avec les pandas. J'espère que vous avez appris de cet article certaines fonctionnalités utiles qui vous aideront également à devenir plus productif.Quelle est votre astuce préférée avec les pandas?