Une traduction de l'article a été préparée spécialement pour les étudiants du cours Java Developer .
En tant que développeurs, nous devons souvent faire face au code hérité, qui est difficile à maintenir. Vous savez à quel point il est difficile de comprendre une logique simple dans un grand code spaghetti alambiqué. Améliorer le code ou développer de nouvelles fonctionnalités devient un cauchemar pour le développeur.L'un des principaux objectifs de la conception de logiciels est la facilité de maintenance. Un code mal entretenu devient difficile à gérer. Il est non seulement difficile à mettre à l'échelle, mais il devient difficile d'attirer de nouveaux développeurs.Dans le monde informatique, les choses évoluent rapidement. Si vous êtes invité à implémenter de toute urgence de nouvelles fonctionnalités ou si vous souhaitez passer d'une base de données relationnelle à NoSQL, quelle sera votre première réaction? Une bonne couverture des tests augmente la confiance des développeurs quant à l'absence de problèmes avec la nouvelle version. Cependant, si votre logique métier est liée à la logique de l'infrastructure, il peut y avoir des problèmes avec ses tests.
Une bonne couverture des tests augmente la confiance des développeurs quant à l'absence de problèmes avec la nouvelle version. Cependant, si votre logique métier est liée à la logique de l'infrastructure, il peut y avoir des problèmes avec ses tests. Pourquoi moi?Mais il y a assez de discours vides, regardons l'architecture hexagonale. L'utilisation de ce modèle vous aidera à améliorer la maintenabilité, la testabilité et d'autres avantages.
Pourquoi moi?Mais il y a assez de discours vides, regardons l'architecture hexagonale. L'utilisation de ce modèle vous aidera à améliorer la maintenabilité, la testabilité et d'autres avantages.Introduction à l'architecture hexagonale
Le terme architecture hexagonale (architecture hexagonale, hexagonale) a été inventé en 2006 par Alistair Cockburn. Ce style architectural est également appelé architecture de ports et d'adaptateurs . En termes simples, les composants de votre application interagissent via de nombreux points de terminaison (ports). Pour traiter les demandes, vous devez disposer d'adaptateurs correspondant aux ports.Ici, vous pouvez faire une analogie avec les ports USB de l'ordinateur. Vous pouvez les utiliser si vous disposez d'un adaptateur compatible (chargeur ou lecteur flash). Cette architecture peut être représentée schématiquement comme un hexagone avec une logique métier au centre (au cœur), entourée des objets avec lesquels elle interagit et des composants qui la contrôlent, fournissant des données d'entrée.Dans la vie réelle, les utilisateurs, les appels d'API, les scripts automatisés et les tests unitaires interagissent et fournissent des informations à votre application. Si votre logique métier est mélangée à une logique d'interface utilisateur, vous rencontrerez de nombreux problèmes. Par exemple, il sera difficile de basculer la saisie de données de l'interface utilisateur vers des tests unitaires.L'application interagit également avec des objets externes tels que des bases de données, des files d'attente de messages, des serveurs Web (via des appels API HTTP), etc. Si nécessaire, migrez la base de données ou téléchargez des données dans un fichier, vous devriez pouvoir le faire sans affecter l'entreprise. logique.Comme son nom l'indique, « ports et adaptateurs », il existe des «ports» par lesquels l'interaction se produit et les «adaptateurs» sont des composants qui traitent les entrées des utilisateurs et les convertissent en «langue» du domaine. Les adaptateurs encapsulent la logique d'interaction avec des systèmes externes, tels que les bases de données, les files d'attente de messages, etc., et facilitent la communication entre la logique métier et les objets externes.Le diagramme ci-dessous montre les couches dans lesquelles l'application est divisée.
Cette architecture peut être représentée schématiquement comme un hexagone avec une logique métier au centre (au cœur), entourée des objets avec lesquels elle interagit et des composants qui la contrôlent, fournissant des données d'entrée.Dans la vie réelle, les utilisateurs, les appels d'API, les scripts automatisés et les tests unitaires interagissent et fournissent des informations à votre application. Si votre logique métier est mélangée à une logique d'interface utilisateur, vous rencontrerez de nombreux problèmes. Par exemple, il sera difficile de basculer la saisie de données de l'interface utilisateur vers des tests unitaires.L'application interagit également avec des objets externes tels que des bases de données, des files d'attente de messages, des serveurs Web (via des appels API HTTP), etc. Si nécessaire, migrez la base de données ou téléchargez des données dans un fichier, vous devriez pouvoir le faire sans affecter l'entreprise. logique.Comme son nom l'indique, « ports et adaptateurs », il existe des «ports» par lesquels l'interaction se produit et les «adaptateurs» sont des composants qui traitent les entrées des utilisateurs et les convertissent en «langue» du domaine. Les adaptateurs encapsulent la logique d'interaction avec des systèmes externes, tels que les bases de données, les files d'attente de messages, etc., et facilitent la communication entre la logique métier et les objets externes.Le diagramme ci-dessous montre les couches dans lesquelles l'application est divisée. L'architecture hexagonale distingue trois couches dans une application: domaine, application et infrastructure:
L'architecture hexagonale distingue trois couches dans une application: domaine, application et infrastructure:- Domaine . La couche contient la logique métier principale. Il n'a pas besoin de connaître les détails de la mise en œuvre des couches extérieures.
- Application . Une couche agit comme un pont entre les couches d'un domaine et de l'infrastructure.
- Infrastructure . La mise en œuvre de l'interaction du domaine avec le monde extérieur. Les couches intérieures lui ressemblent comme une boîte noire.
Selon cette architecture, deux types de participants interagissent avec l'application: primaire (pilote) et secondaire (piloté). Les acteurs clés envoient des demandes et gèrent l'application (par exemple, les utilisateurs ou les tests automatisés). Les secondaires fournissent l'infrastructure de communication avec le monde extérieur (ce sont des adaptateurs de base de données, des clients TCP ou HTTP).Cela peut être représenté comme suit: Le côté gauche de l'hexagone se compose de composants qui fournissent une entrée pour le domaine (ils «contrôlent» l'application), et le côté droit se compose de composants qui sont contrôlés par notre application.
côté gauche de l'hexagone se compose de composants qui fournissent une entrée pour le domaine (ils «contrôlent» l'application), et le côté droit se compose de composants qui sont contrôlés par notre application.Exemple
Concevons une application qui stockera les critiques de films. L'utilisateur doit pouvoir envoyer une demande avec le nom du film et obtenir cinq critiques aléatoires.Pour plus de simplicité, nous allons réaliser une application console avec stockage de données en RAM. La réponse à l'utilisateur sera affichée sur la console.Nous avons un utilisateur (utilisateur) qui envoie une demande à l'application. Ainsi, l'utilisateur devient un «manager» (chauffeur). L'application doit pouvoir recevoir des données de tout type de stockage et afficher les résultats sur la console ou dans un fichier. Les objets gérés (pilotés) seront «l'entrepôt de données» ( IFetchMovieReviews) et «l'imprimante de réponse» ( IPrintMovieReviews).La figure suivante montre les principaux composants de notre application.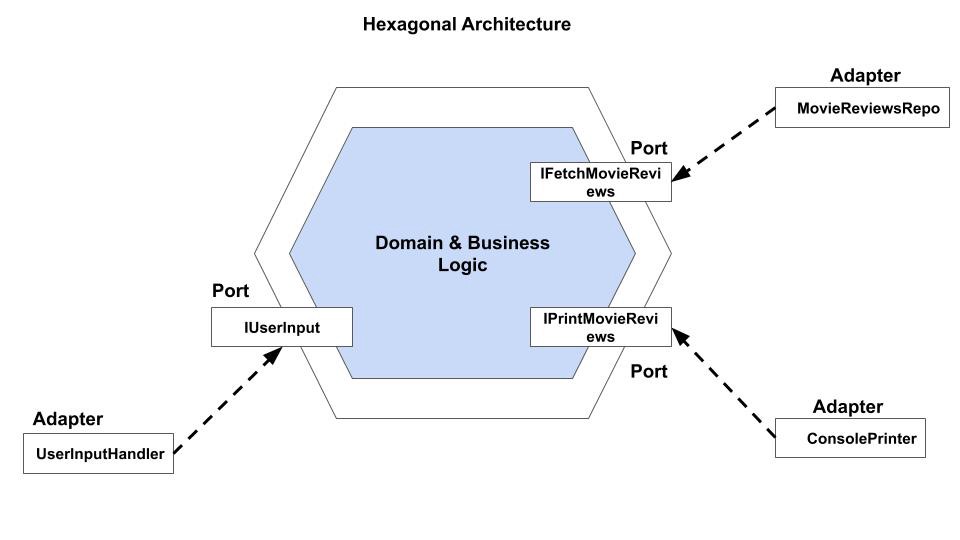 À gauche, les composants qui fournissent la saisie de données dans l'application. À droite, les composants qui vous permettent d'interagir avec la base de données et la console.Regardons le code d'application.Port de contrôle
À gauche, les composants qui fournissent la saisie de données dans l'application. À droite, les composants qui vous permettent d'interagir avec la base de données et la console.Regardons le code d'application.Port de contrôlepublic interface IUserInput {
public void handleUserInput(Object userCommand);
}
Ports géréspublic interface IFetchMovieReviews {
public List<MovieReview> fetchMovieReviews(MovieSearchRequest movieSearchRequest);
}
public interface IPrintMovieReviews {
public void writeMovieReviews(List<MovieReview> movieReviewList);
}
Adaptateurs de port gérés Lesfilms seront obtenus à partir du référentiel de films (MovieReviewsRepo). Afficher les critiques de films sur la console sera une classe ConsolePrinter. Implémentons les deux interfaces ci-dessus.public class ConsolePrinter implements IPrintMovieReviews {
@Override
public void writeMovieReviews(List<MovieReview> movieReviewList) {
movieReviewList.forEach(movieReview -> {
System.out.println(movieReview.toString());
});
}
}
public class MovieReviewsRepo implements IFetchMovieReviews {
private Map<String, List<MovieReview>> movieReviewMap;
public MovieReviewsRepo() {
initialize();
}
public List<MovieReview> fetchMovieReviews(MovieSearchRequest movieSearchRequest) {
return Optional.ofNullable(movieReviewMap.get(movieSearchRequest.getMovieName()))
.orElse(new ArrayList<>());
}
private void initialize() {
this.movieReviewMap = new HashMap<>();
movieReviewMap.put("StarWars", Collections.singletonList(new MovieReview("1", 7.5, "Good")));
movieReviewMap.put("StarTreck", Arrays.asList(new MovieReview("1", 9.5, "Excellent"), new MovieReview("1", 8.5, "Good")));
}
}
Domaine
La tâche principale de notre application est de traiter les demandes des utilisateurs. Vous devez obtenir les films, les traiter et transférer les résultats sur «l'imprimante». Pour le moment, nous n'avons qu'une seule fonctionnalité: la recherche de films. Pour traiter les demandes des utilisateurs, nous utiliserons l'interface standard Consumer.Regardons la classe principale MovieApp.public class MovieApp implements Consumer<MovieSearchRequest> {
private IFetchMovieReviews fetchMovieReviews;
private IPrintMovieReviews printMovieReviews;
private static Random rand = new Random();
public MovieApp(IFetchMovieReviews fetchMovieReviews, IPrintMovieReviews printMovieReviews) {
this.fetchMovieReviews = fetchMovieReviews;
this.printMovieReviews = printMovieReviews;
}
private List<MovieReview> filterRandomReviews(List<MovieReview> movieReviewList) {
List<MovieReview> result = new ArrayList<MovieReview>();
for (int index = 0; index < 5; ++index) {
if (movieReviewList.size() < 1)
break;
int randomIndex = getRandomElement(movieReviewList.size());
MovieReview movieReview = movieReviewList.get(randomIndex);
movieReviewList.remove(movieReview);
result.add(movieReview);
}
return result;
}
private int getRandomElement(int size) {
return rand.nextInt(size);
}
public void accept(MovieSearchRequest movieSearchRequest) {
List<MovieReview> movieReviewList = fetchMovieReviews.fetchMovieReviews(movieSearchRequest);
List<MovieReview> randomReviews = filterRandomReviews(new ArrayList<>(movieReviewList));
printMovieReviews.writeMovieReviews(randomReviews);
}
}
Nous définissons maintenant une classe CommandMapperModelqui mappera les commandes aux gestionnaires.public class CommandMapperModel {
private static final Class<MovieSearchRequest> searchMovies = MovieSearchRequest.class;
public static Model build(Consumer<MovieSearchRequest> displayMovies) {
Model model = Model.builder()
.user(searchMovies)
.system(displayMovies)
.build();
return model;
}
}
Adaptateurs de port de contrôle
L'utilisateur interagira avec notre système via l'interface IUserInput. L'implémentation utilisera ModelRunneret déléguera l'exécution.public class UserCommandBoundary implements IUserInput {
private Model model;
public UserCommandBoundary(IFetchMovieReviews fetchMovieReviews, IPrintMovieReviews printMovieReviews) {
MovieApp movieApp = new MovieApp(fetchMovieReviews, printMovieReviews);
model = CommandMapperModel.build(movieApp);
}
public void handleUserInput(Object userCommand) {
new ModelRunner().run(model)
.reactTo(userCommand);
}
}
Voyons maintenant l'utilisateur qui utilise l'interface ci-dessus.public class MovieUser {
private IUserInput userInputDriverPort;
public MovieUser(IUserInput userInputDriverPort) {
this.userInputDriverPort = userInputDriverPort;
}
public void processInput(MovieSearchRequest movieSearchRequest) {
userInputDriverPort.handleUserInput(movieSearchRequest);
}
}
application
Ensuite, créez une application console. Les adaptateurs gérés sont ajoutés en tant que dépendances. L'utilisateur créera et enverra une demande à l'application. L'application recevra des données, traitera et affichera une réponse à la console.public class Main {
public static void main(String[] args) {
IFetchMovieReviews fetchMovieReviews = new MovieReviewsRepo();
IPrintMovieReviews printMovieReviews = new ConsolePrinter();
IUserInput userCommandBoundary = new UserCommandBoundary(fetchMovieReviews, printMovieReviews);
MovieUser movieUser = new MovieUser(userCommandBoundary);
MovieSearchRequest starWarsRequest = new MovieSearchRequest("StarWars");
MovieSearchRequest starTreckRequest = new MovieSearchRequest("StarTreck");
System.out.println("Displaying reviews for movie " + starTreckRequest.getMovieName());
movieUser.processInput(starTreckRequest);
System.out.println("Displaying reviews for movie " + starWarsRequest.getMovieName());
movieUser.processInput(starWarsRequest);
}
}
Ce qui peut être amélioré, changé
- Dans notre implémentation, vous pouvez facilement passer d'un magasin de données à un autre. L'implémentation du stockage peut être injectée dans le code sans changer la logique métier. Par exemple, vous pouvez transférer des données de la mémoire vers une base de données en écrivant un adaptateur de base de données.
- Au lieu de sortir sur la console, vous pouvez implémenter une «imprimante», qui écrira des données dans un fichier. Dans une telle application multicouche, il devient plus facile d'ajouter des fonctionnalités et de corriger des bogues.
- Pour tester la logique métier, vous pouvez écrire des tests complexes. Les adaptateurs peuvent être testés isolément. Ainsi, il est possible d'augmenter la couverture globale des tests.
Conclusion
On peut noter les avantages suivants de l'architecture hexagonale:- Accompagnement - Couches à couplage lâche et indépendantes. Il devient facile d'ajouter de nouvelles fonctionnalités à une couche sans affecter les autres couches.
- Testabilité - les tests unitaires sont écrits de manière simple et rapide. Vous pouvez écrire des tests pour chaque couche à l'aide d'objets de stub qui simulent des dépendances. Par exemple, nous pouvons supprimer la dépendance à la base de données en créant un entrepôt de données en mémoire.
- Adaptabilité - la logique métier principale devient indépendante des changements dans les objets externes. Par exemple, si vous devez migrer vers une autre base de données, nous n'avons pas besoin de modifier le domaine. Nous pouvons créer un adaptateur approprié pour la base de données.
Références
C'est tout. Rendez-vous sur le parcours !