Les rapports de couverture modernes sont dans certains cas plutôt inutiles, et les méthodes pour les mesurer ne conviennent principalement qu'aux développeurs. Vous pouvez toujours connaître le pourcentage de couverture ou afficher le code qui n'a pas été utilisé lors des tests, mais que faire si vous voulez de la visibilité, de la simplicité et de l'automatisation? Sous la coupe - vidéo et transcription d'un rapport d'Artem Eroshenko de Qameta Software de la conférence Heisenbug . Il a présenté plusieurs solutions simples et élégantes développées qui aident l'équipe Yandex.Verticals à évaluer la couverture des tests rédigés par les ingénieurs d'automatisation des tests. Artem vous dira comment trouver rapidement ce qui est couvert, comment couvert, quels tests ont réussi et voir instantanément les rapports visuels.Je m'appelle Artyom Eroshenko eroshenkoam, Je fais de l'automatisation des tests depuis plus de 10 ans. J'étais responsable de l'automatisation des tests, responsable de l'équipe de développement d'outils, développeur d'outils.En ce moment je suis consultant dans le domaine de l'automatisation des tests, je travaille avec plusieurs entreprises avec lesquelles nous construisons des processus.Je suis également développeur et gestionnaire secret d'Allure Report. Nous avons récemment corrigé une chose sympa : maintenant dans JUnit 5, il y a des fixtures.
Sous la coupe - vidéo et transcription d'un rapport d'Artem Eroshenko de Qameta Software de la conférence Heisenbug . Il a présenté plusieurs solutions simples et élégantes développées qui aident l'équipe Yandex.Verticals à évaluer la couverture des tests rédigés par les ingénieurs d'automatisation des tests. Artem vous dira comment trouver rapidement ce qui est couvert, comment couvert, quels tests ont réussi et voir instantanément les rapports visuels.Je m'appelle Artyom Eroshenko eroshenkoam, Je fais de l'automatisation des tests depuis plus de 10 ans. J'étais responsable de l'automatisation des tests, responsable de l'équipe de développement d'outils, développeur d'outils.En ce moment je suis consultant dans le domaine de l'automatisation des tests, je travaille avec plusieurs entreprises avec lesquelles nous construisons des processus.Je suis également développeur et gestionnaire secret d'Allure Report. Nous avons récemment corrigé une chose sympa : maintenant dans JUnit 5, il y a des fixtures.Cadre Atlas
Mon développement est le Framework Atlas . Si quelqu'un a commencé à automatiser en 2012, alors que les pilotes Web Java commençaient à peine, à ce moment-là, j'ai créé une bibliothèque open source appelée HTML Elements .Html Elements a sa suite et repense dans la bibliothèque Atlas, qui est construite sur des interfaces: il n'y a pas de classes en tant que telles, pas de champs, une bibliothèque très pratique, légère et facilement extensible. Si vous avez envie de le comprendre, vous pouvez lire l' article ou consulter le rapport .Mon rapport est consacré au problème de l'automatisation des tests et principalement aux revêtements. Comme arrière-plan, je voudrais me référer à la façon dont les processus de test sont organisés dans Yandex.Verticals.Comment fonctionne l'automatisation dans les verticales?
L'équipe d'automatisation des tests de Yandex.Verticals ne compte que quatre personnes qui automatisent quatre services: Yandex.Avto, Work, Real Estate et Parts. Autrement dit, il s'agit d'une petite équipe d'automatiseurs qui font beaucoup. Nous automatisons l'API, l'interface Web, les applications mobiles, etc. Au total, nous avons quelque part environ 15,5 mille tests qui sont effectués à différents niveaux.La stabilité des tests dans l'équipe est d'environ 97%, bien que certains de mes collègues disent environ 99%. Une telle stabilité élevée est obtenue précisément grâce à de courts tests sur des technologies très natives. En règle générale, nos tests prennent environ 15 minutes, ce qui est très volumineux, et nous les exécutons dans environ 800 threads. Autrement dit, nous avons 800 navigateurs démarrant en même temps - un tel test de résistance de nos tests. Comme fer, nous utilisons le sélénoïde (Aerokube). Vous pouvez en savoir plus sur les tests d'automatisation dans Yandex.Verticals en regardant mon rapport 2017, qui est toujours pertinent.Une autre caractéristique de notre équipe est que nous automatisons tout , y compris les testeurs manuels, qui contribuent grandement au développement de l'automatisation des tests. Pour eux, nous organisons des écoles, leur enseignons des tests, apprenons à rédiger des tests pour l'API, l'interface Web, et souvent ils aident à accompagner les tests. Ainsi, les gars qui sont responsables de la libération eux-mêmes peuvent immédiatement corriger le test, si nécessaire.Dans Verticals, les développeurs de tests écrivent des tests, et ils sont tellement passionnés par le développement de tests qu'ils nous rivalisent. Vous pouvez en savoir plus sur ce processus dans le rapport «Le cycle complet de test des applications React», où Alexei Androsov et Natalya Stus expliquent comment ils écrivent des tests unitaires sur Puppeteer en parallèle avec nos tests Java de bout en bout.Les ingénieurs d'automatisation des tests rédigent également des tests dans notre équipe. Mais souvent, nous développons de nouvelles approches pour les optimiser. Par exemple, nous avons implémenté des tests de capture d'écran, des tests via moki, une réduction des tests. En général, notre domaine est principalement développeur de logiciels en test (SDET), nous sommes plus sur la façon d'écrire des tests, et la base de test est partiellement remplie par nous et est prise en charge par des testeurs manuels.Les développeurs nous aident également, et c'est cool.
Le problème qui se pose dans ces processus est que nous ne comprenons pas toujours ce qui est déjà couvert et ce qui ne l'est pas. À travers 15 000 tests, il n'est pas toujours clair de savoir exactement ce que nous vérifions. Cela est particulièrement vrai dans le contexte de la communication avec les gestionnaires, qui, bien sûr, ne testent pas, mais surveillent et posent des questions. En particulier, si la question se pose de savoir si un bouton particulier a été testé dans l'interface ou le flux, il est difficile de répondre, car vous devez accéder au code de test et consulter ces informations.Qu'est-ce qui est testé et qu'est-ce qui ne l'est pas?
Si vous avez de nombreux tests dans différentes langues et que vous êtes écrit par des personnes ayant divers degrés de formation, alors tôt ou tard la question se pose, ces tests ne sont-ils pas du tout entrecoupés? Dans le contexte de ce problème, la question de la couverture devient particulièrement pertinente. Je décrirai trois sujets clés:- Façons de mesurer efficacement la couverture.
- Couverture pour les tests API.
- Couverture pour les tests Web.
Tout d'abord, déterminons qu'il existe deux façons de couvrir: la couverture des exigences et la couverture du code produit.Comment la couverture des besoins est mesurée
Considérez la couverture des exigences en utilisant auto.ru comme exemple. Au lieu du testeur auto.ru, je ferais ce qui suit. Tout d'abord, je recherche sur Google et je trouve immédiatement un tableau des exigences spéciales. C'est la base de la couverture des exigences.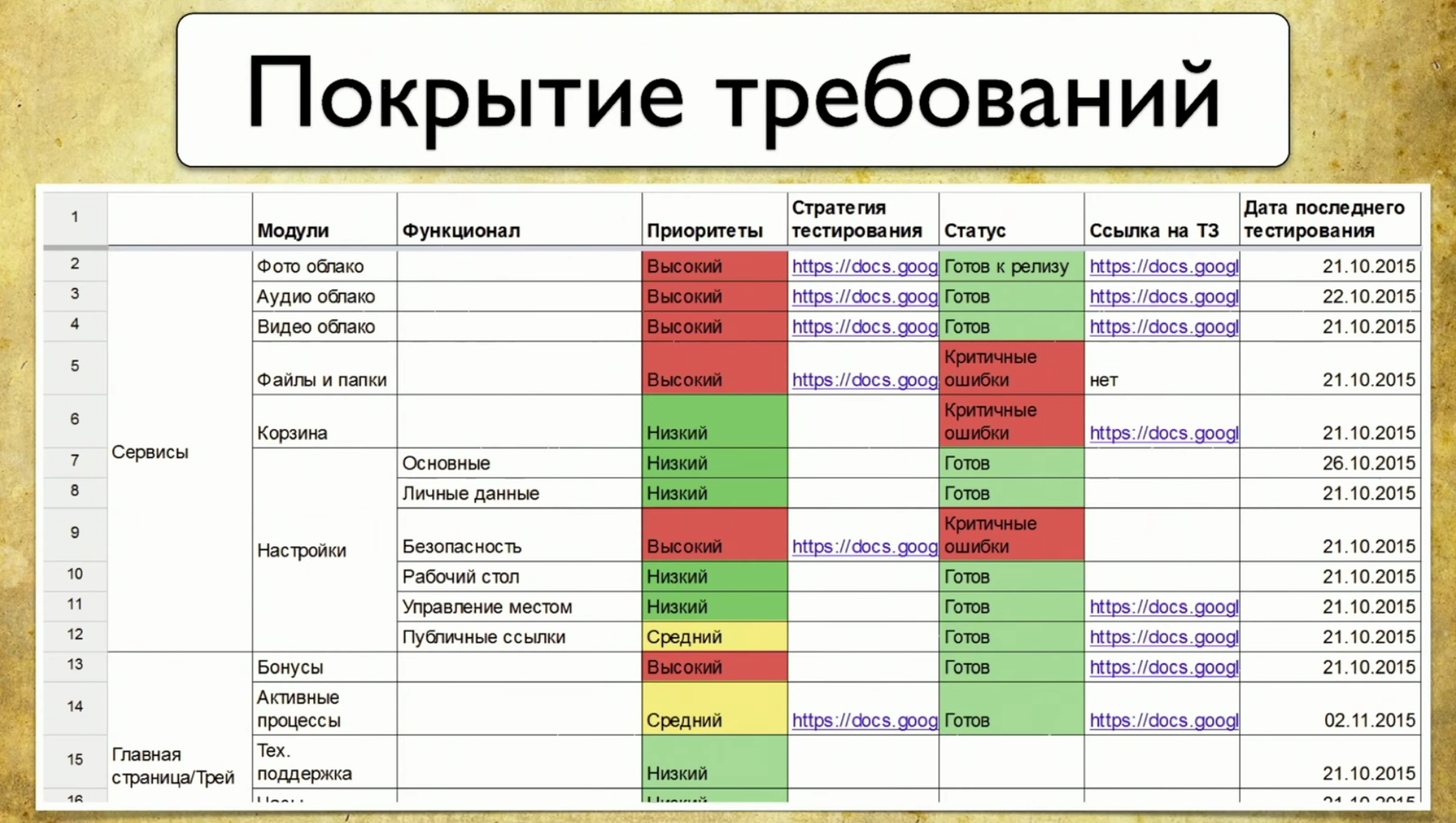 Dans ce tableau, les noms des exigences sont écrits à gauche. Dans ce cas: compte, annonces, vérification et paiement, c'est-à-dire vérification de l'annonce. En général, c'est la couverture. Le détail de la partie gauche dépend du niveau du testeur. Par exemple, les ingénieurs de Google ont 49 types de revêtements qui sont testés à différents niveaux.Le côté droit du tableau contient les attributs des exigences. Nous pouvons utiliser n'importe quoi sous forme d'attributs, par exemple: priorité, couverture et état. Cela peut être la date de la dernière version.
Dans ce tableau, les noms des exigences sont écrits à gauche. Dans ce cas: compte, annonces, vérification et paiement, c'est-à-dire vérification de l'annonce. En général, c'est la couverture. Le détail de la partie gauche dépend du niveau du testeur. Par exemple, les ingénieurs de Google ont 49 types de revêtements qui sont testés à différents niveaux.Le côté droit du tableau contient les attributs des exigences. Nous pouvons utiliser n'importe quoi sous forme d'attributs, par exemple: priorité, couverture et état. Cela peut être la date de la dernière version. Ainsi, certaines données apparaissent dans le tableau. Vous pouvez utiliser des outils professionnels pour gérer une table d'exigences, par exemple, TestRail.Il y a des informations sur l'arborescence à droite: les dossiers indiquent quelles exigences nous avons, comment elles peuvent être couvertes. Il y a des cas de test et ainsi de suite.
Ainsi, certaines données apparaissent dans le tableau. Vous pouvez utiliser des outils professionnels pour gérer une table d'exigences, par exemple, TestRail.Il y a des informations sur l'arborescence à droite: les dossiers indiquent quelles exigences nous avons, comment elles peuvent être couvertes. Il y a des cas de test et ainsi de suite. Dans les verticales, ce processus ressemble à ceci: un testeur manuel décrit les exigences et les cas de test, puis les transmet à l'automatisation des tests, et l'outil automatisé écrit du code pour ces tests. De plus, plus tôt, nous avons reçu des cas de test détaillés dans lesquels le testeur manuel décrivait la structure entière. Ensuite, quelqu'un a fait un commit sur le github, et le test a commencé à être bénéfique.Quels sont les avantages et les inconvénients de cette approche? Le plus est que cette approche répond à nos questions. Si le gestionnaire demande ce que nous avons couvert, j'ouvrirai la tablette et montrerai quelles fonctionnalités sont couvertes. En revanche, ces exigences doivent toujours être tenues à jour et elles deviennent obsolètes très rapidement.Lorsque vous avez 15 000 tests, regarder TestRail, c'est comme regarder une étoile dans l'espace: elle a explosé pendant longtemps, et la lumière vous a atteint tout à l'heure. Vous regardez le cas de test actuel, et il est déjà obsolète depuis longtemps et irrévocablement.Ce problème est difficile à résoudre. Pour nous, ce sont généralement deux mondes différents: il y a un monde d'automatisation qui tourne selon ses propres lois, où chaque test qui échoue est immédiatement corrigé, et il y a un monde de tests manuels et de cartes d'exigences. Le mur entre eux est impénétrable, sauf si vous utilisez Allure Server. Nous venons maintenant de résoudre ce problème pour eux.Le troisième point des «avantages et inconvénients» est la nécessité d'un travail manuel. Dans un nouveau projet, vous devez recréer une carte des exigences, écrire tous les cas de test, etc. Cela nécessite toujours un travail manuel, et c'est en fait très triste.
Dans les verticales, ce processus ressemble à ceci: un testeur manuel décrit les exigences et les cas de test, puis les transmet à l'automatisation des tests, et l'outil automatisé écrit du code pour ces tests. De plus, plus tôt, nous avons reçu des cas de test détaillés dans lesquels le testeur manuel décrivait la structure entière. Ensuite, quelqu'un a fait un commit sur le github, et le test a commencé à être bénéfique.Quels sont les avantages et les inconvénients de cette approche? Le plus est que cette approche répond à nos questions. Si le gestionnaire demande ce que nous avons couvert, j'ouvrirai la tablette et montrerai quelles fonctionnalités sont couvertes. En revanche, ces exigences doivent toujours être tenues à jour et elles deviennent obsolètes très rapidement.Lorsque vous avez 15 000 tests, regarder TestRail, c'est comme regarder une étoile dans l'espace: elle a explosé pendant longtemps, et la lumière vous a atteint tout à l'heure. Vous regardez le cas de test actuel, et il est déjà obsolète depuis longtemps et irrévocablement.Ce problème est difficile à résoudre. Pour nous, ce sont généralement deux mondes différents: il y a un monde d'automatisation qui tourne selon ses propres lois, où chaque test qui échoue est immédiatement corrigé, et il y a un monde de tests manuels et de cartes d'exigences. Le mur entre eux est impénétrable, sauf si vous utilisez Allure Server. Nous venons maintenant de résoudre ce problème pour eux.Le troisième point des «avantages et inconvénients» est la nécessité d'un travail manuel. Dans un nouveau projet, vous devez recréer une carte des exigences, écrire tous les cas de test, etc. Cela nécessite toujours un travail manuel, et c'est en fait très triste.Comment la couverture du code est mesurée
Une alternative à cette approche est la couverture du code. Cela semble être la solution à notre problème. Voici à quoi ressemble la couverture du code produit: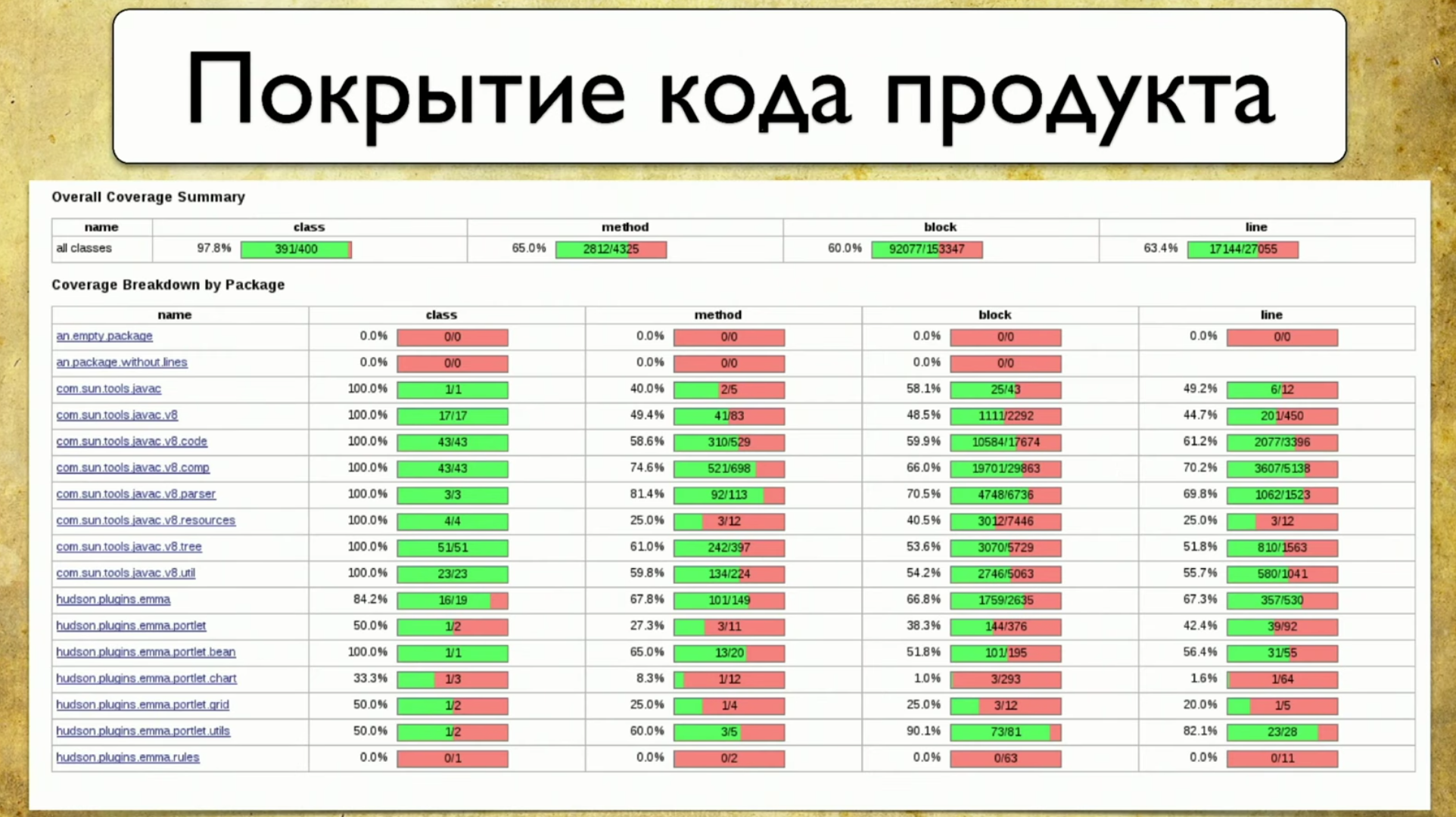 elle reflète la couverture de l'emballage, ou plutôt une petite partie de ce que le produit a réellement. Le package est écrit sur la gauche, comme les fonctionnalités ont été écrites auparavant. Autrement dit, notre revêtement est finalement attaché à des choses tangibles, dans ce cas - Package. Les attributs sont écrits à droite: couverture par classe, couverture par méthodes, couverture par blocs de code et couverture par lignes de code.Le processus de collecte de la couverture consiste à comprendre quelle ligne de code le test a réussi et laquelle n'a pas réussi. Il s'agit d'une tâche assez simple, mais récemment très pertinente.
elle reflète la couverture de l'emballage, ou plutôt une petite partie de ce que le produit a réellement. Le package est écrit sur la gauche, comme les fonctionnalités ont été écrites auparavant. Autrement dit, notre revêtement est finalement attaché à des choses tangibles, dans ce cas - Package. Les attributs sont écrits à droite: couverture par classe, couverture par méthodes, couverture par blocs de code et couverture par lignes de code.Le processus de collecte de la couverture consiste à comprendre quelle ligne de code le test a réussi et laquelle n'a pas réussi. Il s'agit d'une tâche assez simple, mais récemment très pertinente.La première mention de la couverture du code remonte à 1963, mais de sérieux progrès dans ce sens n'apparaissent que maintenant.
Nous avons donc un test qui interagit avec le système. Peu importe la façon dont il interagit avec elle: via le front-end, l'API ou se glisse directement dans le back-end - nous supposerons simplement que nous l'avons.Ensuite, l'instrumentation doit être effectuée. Il s'agit d'un processus qui vous permet de comprendre quelles lignes de code ont été vérifiées et lesquelles ne l'ont pas été. Vous n'avez pas besoin de l'étudier en détail, il vous suffit de rechercher le nom de votre framework sur lequel vous écrivez, disons Spring , puis l' instrumentation et la couverture - ces trois mots vous aideront à comprendre comment cela se fait.Lorsque vos tests vérifient quelle ligne de code le test a atteint et laquelle ne l'a pas atteint, ils enregistrent des fichiers avec des informations sur les lignes couvertes. Sur la base de ces informations, vous disposez de données.Quels sont les avantages et les inconvénients de la couverture du code?
Couverture du code J'appellerais immédiatement un moins . Vous ne viendrez pas chez le manager, vous ne montrerez pas cette plaque et vous ne direz pas que tout le monde a automatisé, car ces données ne peuvent pas être lues, il vous demandera de renvoyer des données claires que vous pourrez rapidement consulter et tout comprendre.Rapport de couverture du code plus proche du développement. Il ne peut pas être utilisé comme une approche normale pour fournir toutes les données à une équipe si nous voulons que toute l'équipe puisse regarder. L'avantage de cette approche est qu'elle fournit toujours des données pertinentes. Vous n'avez pas à faire beaucoup de travail, tout est automatisé pour vous. Branchez simplement la bibliothèque, vos couvertures commencent à décoller - et c'est vraiment cool.Un autre avantage de cette approche est qu'elle ne nécessite qu'une personnalisation. Il n'y a rien de spécial à faire là-bas - venez avec une instruction spécifique, ajustez la couverture et cela fonctionne automatiquement.La couverture des exigences vous permet d'identifier les exigences non satisfaites, mais ne permet pas d'évaluer l'exhaustivité par rapport au code. Par exemple, vous avez commencé à écrire une nouvelle fonctionnalité «autorisation», entrez simplement la «fonctionnalité d'autorisation», vous commencez à lancer des cas de test dessus. Vous ne pouvez pas voir immédiatement cette couverture dans le code, même si vous écrivez une nouvelle classe, il n'y aura toujours pas d'informations - il y a un écart. En revanche, il s'agit d'une exigence d'autorisation, même lorsqu'elle sera déjà mise en œuvre, lorsque vous comptez sur la couverture, cette partie ne peut pas être pertinente, elle doit être tenue à jour manuellement.Par conséquent, nous avons eu une idée: que faire si nous tirons le meilleur parti de tout le monde? Pour que la couverture réponde à nos questions, elle était toujours pertinente et ne nécessitait qu'une personnalisation. Il suffit de regarder le revêtement sous un angle différent, c'est-à-dire de prendre un autre système comme base du revêtement. Dans le même temps, assurez-vous qu'il est collecté de manière entièrement automatique et apporte un tas d'avantages. Et pour cela, nous allons entrer dans la couverture des tests API.
L'avantage de cette approche est qu'elle fournit toujours des données pertinentes. Vous n'avez pas à faire beaucoup de travail, tout est automatisé pour vous. Branchez simplement la bibliothèque, vos couvertures commencent à décoller - et c'est vraiment cool.Un autre avantage de cette approche est qu'elle ne nécessite qu'une personnalisation. Il n'y a rien de spécial à faire là-bas - venez avec une instruction spécifique, ajustez la couverture et cela fonctionne automatiquement.La couverture des exigences vous permet d'identifier les exigences non satisfaites, mais ne permet pas d'évaluer l'exhaustivité par rapport au code. Par exemple, vous avez commencé à écrire une nouvelle fonctionnalité «autorisation», entrez simplement la «fonctionnalité d'autorisation», vous commencez à lancer des cas de test dessus. Vous ne pouvez pas voir immédiatement cette couverture dans le code, même si vous écrivez une nouvelle classe, il n'y aura toujours pas d'informations - il y a un écart. En revanche, il s'agit d'une exigence d'autorisation, même lorsqu'elle sera déjà mise en œuvre, lorsque vous comptez sur la couverture, cette partie ne peut pas être pertinente, elle doit être tenue à jour manuellement.Par conséquent, nous avons eu une idée: que faire si nous tirons le meilleur parti de tout le monde? Pour que la couverture réponde à nos questions, elle était toujours pertinente et ne nécessitait qu'une personnalisation. Il suffit de regarder le revêtement sous un angle différent, c'est-à-dire de prendre un autre système comme base du revêtement. Dans le même temps, assurez-vous qu'il est collecté de manière entièrement automatique et apporte un tas d'avantages. Et pour cela, nous allons entrer dans la couverture des tests API.API de couverture de test
Quelle est la base de la couverture? Pour ce faire, nous utilisons Swagger - c'est l'API de documentation. Maintenant, je ne peux pas imaginer mon travail sans Swagger, c'est un outil que j'utilise constamment pour les tests. Si vous n'utilisez pas Swagger, je vous recommande fortement de visiter le site et de vous familiariser. Vous y verrez immédiatement un exemple d'utilisation très intuitif et compréhensible.En fait, Swagger est la documentation générée par votre service. Il contient:- Liste des demandes.
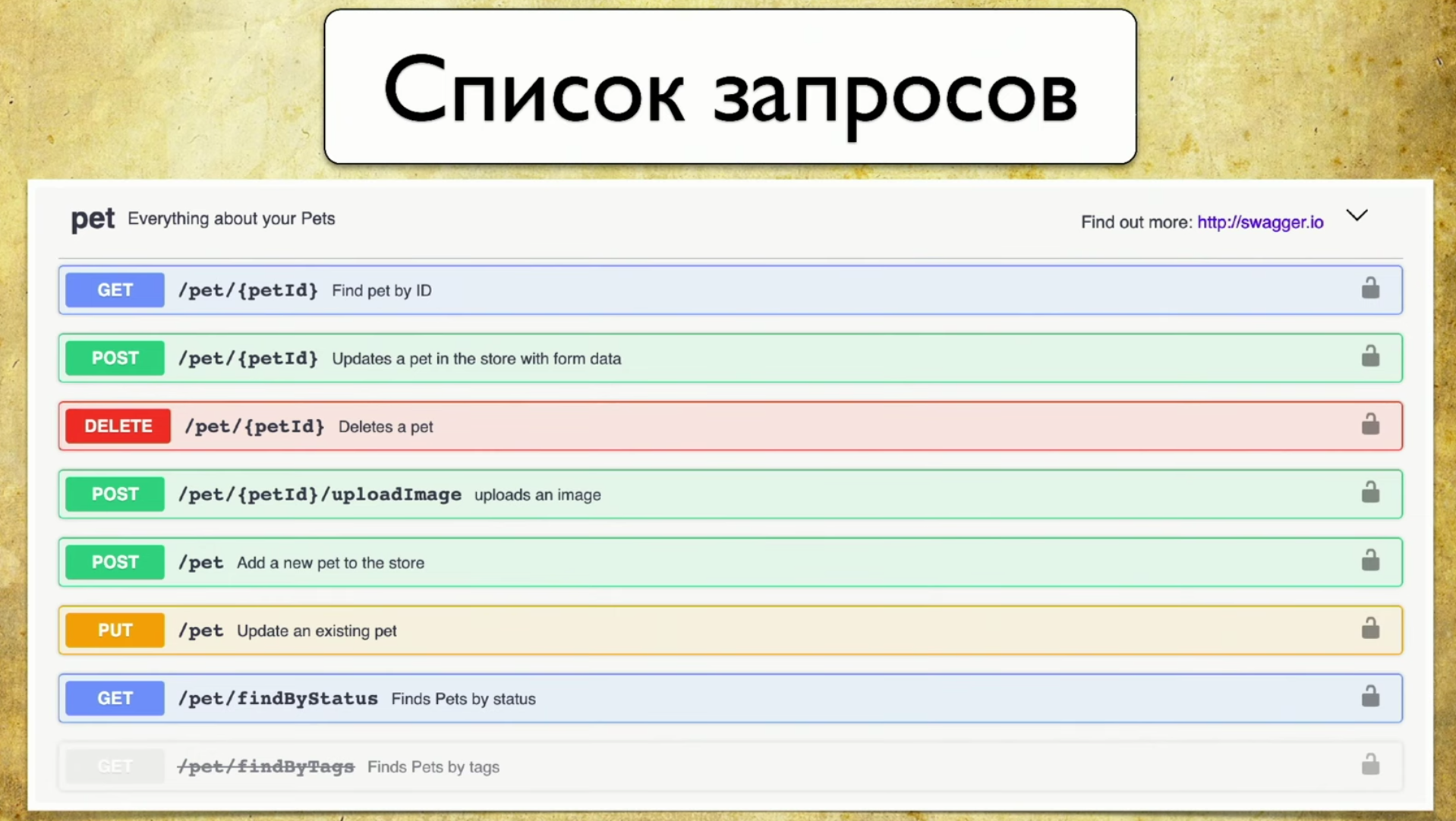
- Demander des paramètres: il n'est pas nécessaire de tirer le développeur et de demander quels sont les paramètres.
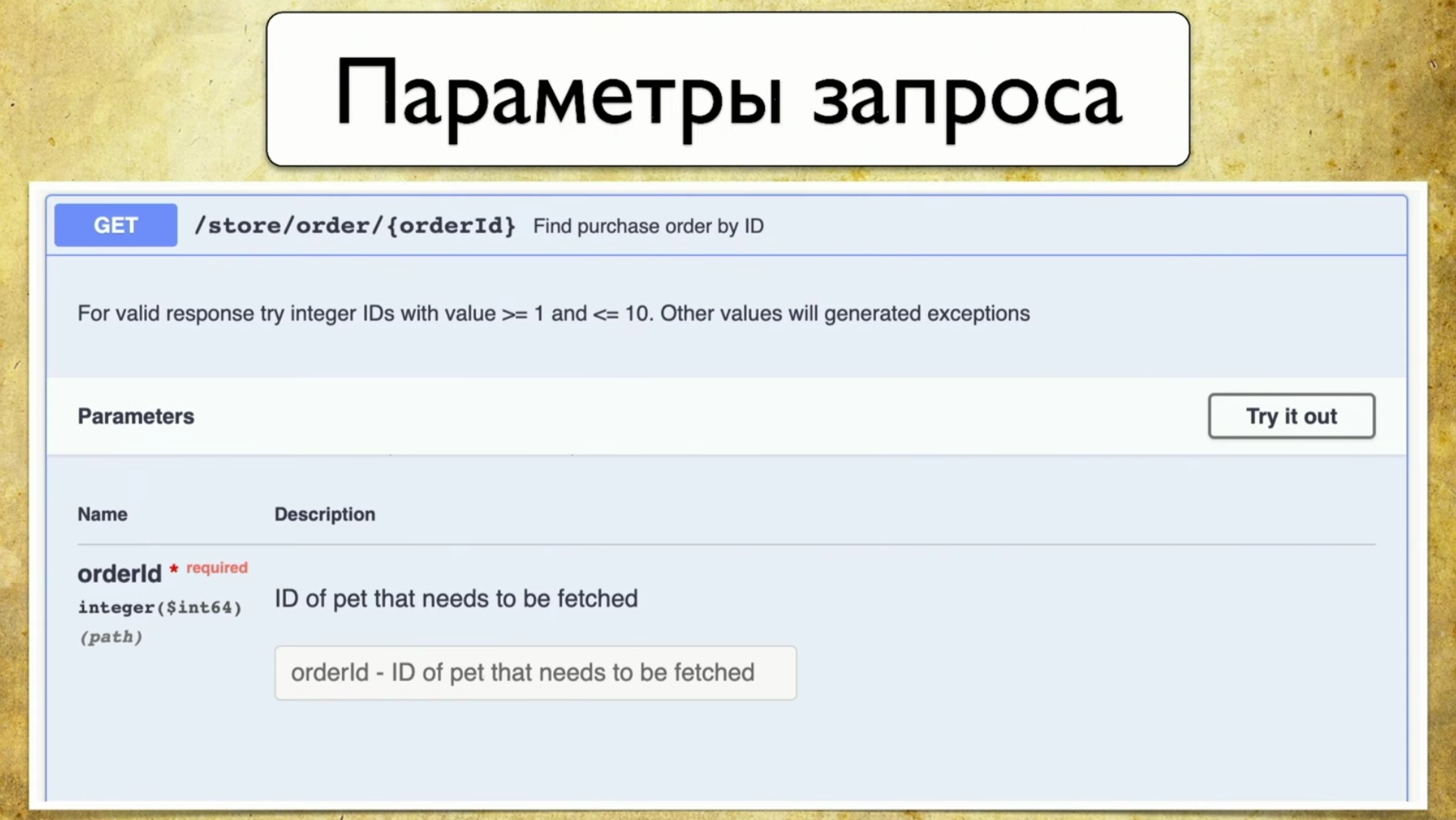
- Codes de réponse

Le principe de fonctionnement de Swagger est la génération. Peu importe le framework que vous utilisez. Disons que Spring or Go Server, vous utilisez le composant Swagger Codegen et générez swagger.json . Il s'agit d'une spécification, sur la base de laquelle une belle interface utilisateur est ensuite dessinée.Il est important pour nous que swagger.json soit utilisé : son support est disponible pour toutes les langues largement utilisées.Nous avons la spécification Open API swagger.json . Il ressemble à ceci: Les requêtes ressemblent à ceci: résumé, description, codes de réponse et un "handle" (chemin: / utilisateurs). Il y a aussi des informations sur le paramètre de requête: tout est structuré, il y a un paramètre d'ID utilisateur, il est dans le chemin où il est nécessaire, une telle description et type - entier.
Les requêtes ressemblent à ceci: résumé, description, codes de réponse et un "handle" (chemin: / utilisateurs). Il y a aussi des informations sur le paramètre de requête: tout est structuré, il y a un paramètre d'ID utilisateur, il est dans le chemin où il est nécessaire, une telle description et type - entier. Il y a des codes de réponse, ils sont aussi tous documentés:
Il y a des codes de réponse, ils sont aussi tous documentés: Et l'idée nous est venue: nous avons un service que Swagger génère, et nous voulions garder le même Swagger dans les tests pour pouvoir les comparer plus tard. En d'autres termes, lorsque les tests s'exécutent, ils génèrent exactement le même Swagger, nous le jetons au Swagger Diff, nous comprenons quels paramètres, poignées, codes d'état que nous avons vérifiés, etc. C'est la même instrumentation, la même couverture, que finalement dans les exigences que nous comprenons.
Et l'idée nous est venue: nous avons un service que Swagger génère, et nous voulions garder le même Swagger dans les tests pour pouvoir les comparer plus tard. En d'autres termes, lorsque les tests s'exécutent, ils génèrent exactement le même Swagger, nous le jetons au Swagger Diff, nous comprenons quels paramètres, poignées, codes d'état que nous avons vérifiés, etc. C'est la même instrumentation, la même couverture, que finalement dans les exigences que nous comprenons.Mais que faire si vous construisez un diff?
Nous nous sommes tournés vers la bibliothèque de différences Swagger , ce dont nous avons besoin pour cela. Son principe de fonctionnement est quelque chose comme ceci: vous avez la version 1.0, avec l'API version 1.1, ils génèrent tous les deux swagger.json , puis vous les lancez sur Swagger diff et voyez le résultat.Le résultat ressemble à ceci: vous disposez d'informations indiquant, par exemple, un nouveau stylo. Vous avez également des informations sur ce qui est supprimé. Cela signifie qu'il est temps de supprimer les tests, ils ne sont plus pertinents. Avec l'apparition d'informations sur les changements, les paramètres changent également, il est donc évident que vos tests tomberont à ce moment-là.Nous avons aimé cette idée et nous avons commencé à la mettre en œuvre. Comme nous avons décidé de le faire: nous avons un Swagger «de référence» qui génère à partir du code du développeur, nous avons également des tests d'API qui généreront notre Swagger, et nous les différencierons.Nous effectuons donc des tests pour le service: nous avons Rest Assured , qui accède lui-même aux services sur l'API. Et nous l'instruisons. Il existe une approche: vous pouvez créer des filtres, la demande y est envoyée - et il enregistre directement les informations sur la demande sous la forme de swagger.json .Voici tout le code que nous avions besoin d'écrire, il y avait 69-70 lignes - c'est un code très simple.
vous disposez d'informations indiquant, par exemple, un nouveau stylo. Vous avez également des informations sur ce qui est supprimé. Cela signifie qu'il est temps de supprimer les tests, ils ne sont plus pertinents. Avec l'apparition d'informations sur les changements, les paramètres changent également, il est donc évident que vos tests tomberont à ce moment-là.Nous avons aimé cette idée et nous avons commencé à la mettre en œuvre. Comme nous avons décidé de le faire: nous avons un Swagger «de référence» qui génère à partir du code du développeur, nous avons également des tests d'API qui généreront notre Swagger, et nous les différencierons.Nous effectuons donc des tests pour le service: nous avons Rest Assured , qui accède lui-même aux services sur l'API. Et nous l'instruisons. Il existe une approche: vous pouvez créer des filtres, la demande y est envoyée - et il enregistre directement les informations sur la demande sous la forme de swagger.json .Voici tout le code que nous avions besoin d'écrire, il y avait 69-70 lignes - c'est un code très simple. Le plus drôle, c'est que nous avons utilisé le client natif pour Swagger, a écrit juste là. Nous n'avions même pas besoin de créer nos binaires, nous venons de remplir la spécification Swagger.
Le plus drôle, c'est que nous avons utilisé le client natif pour Swagger, a écrit juste là. Nous n'avions même pas besoin de créer nos binaires, nous venons de remplir la spécification Swagger. Nous avons eu beaucoup de fichiers .json avec lesquels nous devions faire quelque chose - ils ont écrit un agrégateur Swagger. Il s'agit d'un programme très simple qui fonctionne selon le principe suivant:
Nous avons eu beaucoup de fichiers .json avec lesquels nous devions faire quelque chose - ils ont écrit un agrégateur Swagger. Il s'agit d'un programme très simple qui fonctionne selon le principe suivant:- Elle répond à une nouvelle demande, si elle n'est pas dans notre base de données, ajoute-t-elle.
- Elle répond à la demande, il a un nouveau paramètre - ajoute.
- Même chose avec les codes d'état.
Ainsi, nous obtenons des informations sur tous les stylos, paramètres et codes d'état que nous avons utilisés. De plus, vous pouvez collecter ici les données avec lesquelles ces demandes ont été effectuées: nom d'utilisateur, identifiants de connexion, etc. Nous n'avons pas encore compris comment utiliser ces informations, car tout est généré avec nous, mais vous pouvez comprendre avec quels paramètres certaines demandes ont été appelées.Donc, nous étions presque à un jet de pierre de la victoire, mais en conséquence, nous avons refusé Swagger Diff, car cela fonctionne dans un concept légèrement différent - dans le concept de différentiel.
Swagger Diff dit ce qui a changé, pas ce qui est couvert, mais nous voulions afficher le résultat de la couverture. Il y a beaucoup de données supplémentaires, il stocke des informations sur la description, le résumé et d'autres méta-informations, mais nous ne disposons pas de ces informations. Et quand nous faisons Diff, ils nous écrivent que "ce stylo n'a pas de description", mais il n'existait pas.Propre rapport
Nous avons fait notre implémentation, et cela fonctionne comme suit: nous avons de nombreux fichiers provenant d'autotests, nous avons l'API du service Swagger, et nous générons un rapport sur cette base.Un rapport simple ressemble à ceci: vous pouvez voir ci-dessus des informations sur le nombre total de plumes (349), des informations sur celles qui sont entièrement couvertes (chaque paramètre, code d'état, etc.). Vous pouvez choisir vos propres critères, par exemple, couvrir plusieurs paramètres.Il y a également des informations ici que 40% sont partiellement couverts - cela signifie que nous avons déjà des tests pour ces stylos, mais certaines choses ne sont pas encore couvertes, et vous devez y regarder attentivement. La couverture vide est également reflétée.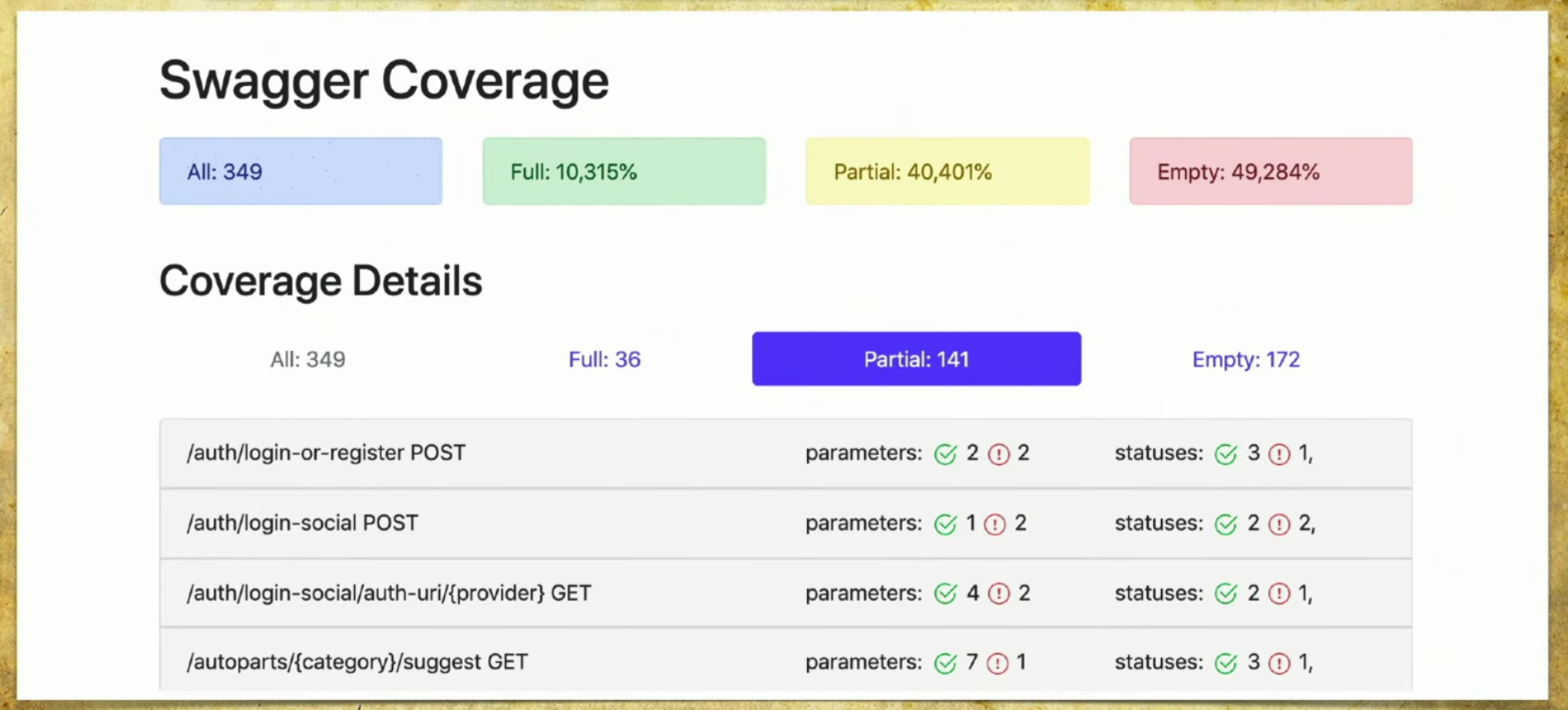 Passons en revue les onglets. Ceci est une couverture complète , nous voyons tous les paramètres que nous avons, qui sont couverts, les codes d'état et ainsi de suite.
Passons en revue les onglets. Ceci est une couverture complète , nous voyons tous les paramètres que nous avons, qui sont couverts, les codes d'état et ainsi de suite.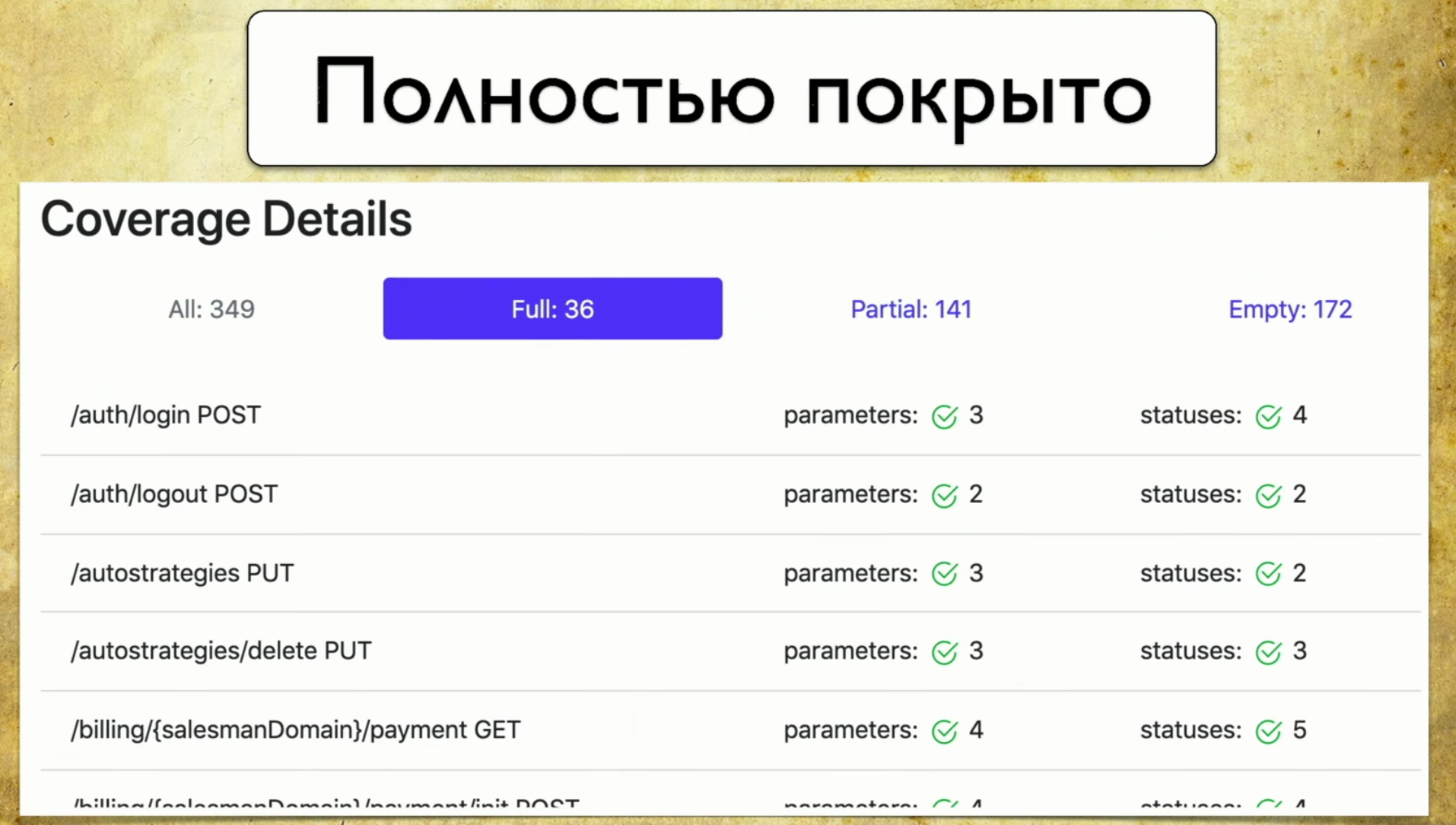 Ensuite, nous avons une couverture partielle . Nous voyons que sur la poignée de connexion sociale, un paramètre est couvert, et deux ne le sont pas. Et nous pouvons l'étendre et voir quels paramètres spécifiques et codes d'état sont couverts. Et en ce moment cela devient très pratique pour le développeur: les versions de l'application roulent très rapidement, et on peut souvent oublier certains paramètres.
Ensuite, nous avons une couverture partielle . Nous voyons que sur la poignée de connexion sociale, un paramètre est couvert, et deux ne le sont pas. Et nous pouvons l'étendre et voir quels paramètres spécifiques et codes d'état sont couverts. Et en ce moment cela devient très pratique pour le développeur: les versions de l'application roulent très rapidement, et on peut souvent oublier certains paramètres. Cet outil vous permet d'être toujours en forme et de comprendre ce que nous avons partiellement couvert, quel paramètre est oublié, etc.Dernier - Gloire de la honte, nous devons encore le faire. Lorsque vous regardez cette page et voyez Vider là: 172 - vos mains tombent, puis vous commencez à enseigner aux testeurs manuels comment écrire des autotests, c'est le point.
Cet outil vous permet d'être toujours en forme et de comprendre ce que nous avons partiellement couvert, quel paramètre est oublié, etc.Dernier - Gloire de la honte, nous devons encore le faire. Lorsque vous regardez cette page et voyez Vider là: 172 - vos mains tombent, puis vous commencez à enseigner aux testeurs manuels comment écrire des autotests, c'est le point.
Quel avantage avons-nous obtenu lorsque nous avons déployé notre solution?
Tout d'abord, nous avons commencé à écrire des tests de manière plus significative. Nous comprenons que nous testons, et en même temps, nous avons deux stratégies. Tout d'abord, nous automatisons quelque chose qui n'est pas là lorsque des testeurs manuels viennent et disent que pour un service particulier, il est essentiel qu'une demande soit exécutée au moins une fois, et nous ouvrons Empty.La deuxième option - nous n'oublions pas les queues. Comme je l'ai dit, les API seront publiées très rapidement, il peut y avoir des sorties deux ou trois fois par jour. Certains paramètres y sont constamment ajoutés: dans cinq mille tests, il est impossible de comprendre ce qui est vérifié et ce qui ne l'est pas. Par conséquent, c'est la seule façon de choisir consciemment une stratégie de test et au moins de faire quelque chose.Le troisième bénéfice est un processus entièrement automatique. Nous avons emprunté l'approche, et l'automatisation fonctionne: nous n'avons rien à faire, tout est collecté automatiquement.Idées de développement
Premièrement, je ne veux vraiment pas conserver le deuxième rapport, mais je veux l'intégrer dans Swagger UI. Voici mon «rapport Photoshop Edition» préféré: une puce que j'ai développée récemment. Voici immédiatement des informations sur les paramètres que nous avons testés et qui ne le sont pas. Et ce serait cool de donner ces informations tout de suite avec Swagger. Par exemple, le front-end peut voir par lui-même quels paramètres n'ont pas été testés, hiérarchiser et décider que même s'ils n'ont pas besoin d'être pris en compte dans le développement, on ne sait pas dans quelle mesure ils fonctionnent. Ou le backend écrit un nouveau stylo, voit du rouge et donne un coup de pied aux testeurs pour que tout soit vert. C'est assez facile à faire, on va dans ce sens.La deuxième idée est de soutenir d'autres outils. En fait, je ne veux pas écrire de filtres pour des implémentations spécifiques: pour Java, Python, etc. Il y a une idée de faire une sorte de proxy qui passera toutes les demandes par lui-même et enregistrera les informations Swagger pour lui-même. Ainsi, nous aurons une bibliothèque universelle qui peut être utilisée quelle que soit la langue que vous utilisez.La troisième idée de développement est l'intégration avec Allure Report. Je le vois comme ceci:
Par exemple, le front-end peut voir par lui-même quels paramètres n'ont pas été testés, hiérarchiser et décider que même s'ils n'ont pas besoin d'être pris en compte dans le développement, on ne sait pas dans quelle mesure ils fonctionnent. Ou le backend écrit un nouveau stylo, voit du rouge et donne un coup de pied aux testeurs pour que tout soit vert. C'est assez facile à faire, on va dans ce sens.La deuxième idée est de soutenir d'autres outils. En fait, je ne veux pas écrire de filtres pour des implémentations spécifiques: pour Java, Python, etc. Il y a une idée de faire une sorte de proxy qui passera toutes les demandes par lui-même et enregistrera les informations Swagger pour lui-même. Ainsi, nous aurons une bibliothèque universelle qui peut être utilisée quelle que soit la langue que vous utilisez.La troisième idée de développement est l'intégration avec Allure Report. Je le vois comme ceci: En règle générale, lorsque le paramètre est «testé», cela ne nous dit pas toujours comment il est testé. Et je veux pointer sur ce paramètre et voir les étapes spécifiques du test.
En règle générale, lorsque le paramètre est «testé», cela ne nous dit pas toujours comment il est testé. Et je veux pointer sur ce paramètre et voir les étapes spécifiques du test.Couverture des tests Web
Le point suivant dont je veux parler est la couverture des tests Web. La couverture est basée sur le site que vous testez, en écrivant des tests sur le site. Mais vous pouvez en faire une interface Web pour votre couverture. Par exemple, cela ressemblera à ceci: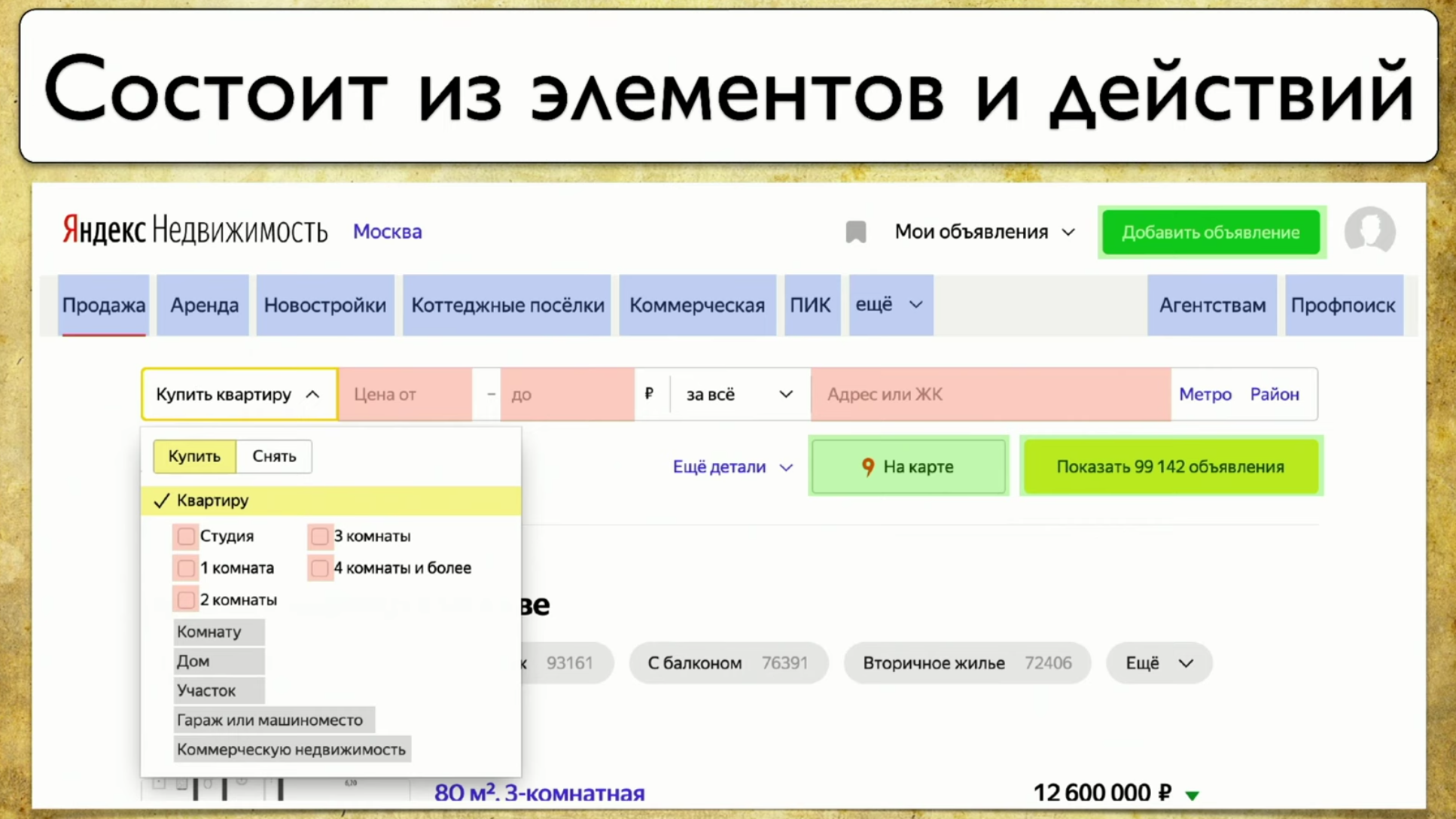 Si vous regardez votre site - il s'agit d'un ensemble d'éléments et de façons d'interagir avec eux. Voici une description complète: "un élément est un moyen d'interagir avec lui". Vous pouvez cliquer sur le lien, vous pouvez copier le texte, vous pouvez mettre quelque chose en entrée. Le site dans son ensemble se compose d'éléments et de modes d'interaction:
Si vous regardez votre site - il s'agit d'un ensemble d'éléments et de façons d'interagir avec eux. Voici une description complète: "un élément est un moyen d'interagir avec lui". Vous pouvez cliquer sur le lien, vous pouvez copier le texte, vous pouvez mettre quelque chose en entrée. Le site dans son ensemble se compose d'éléments et de modes d'interaction: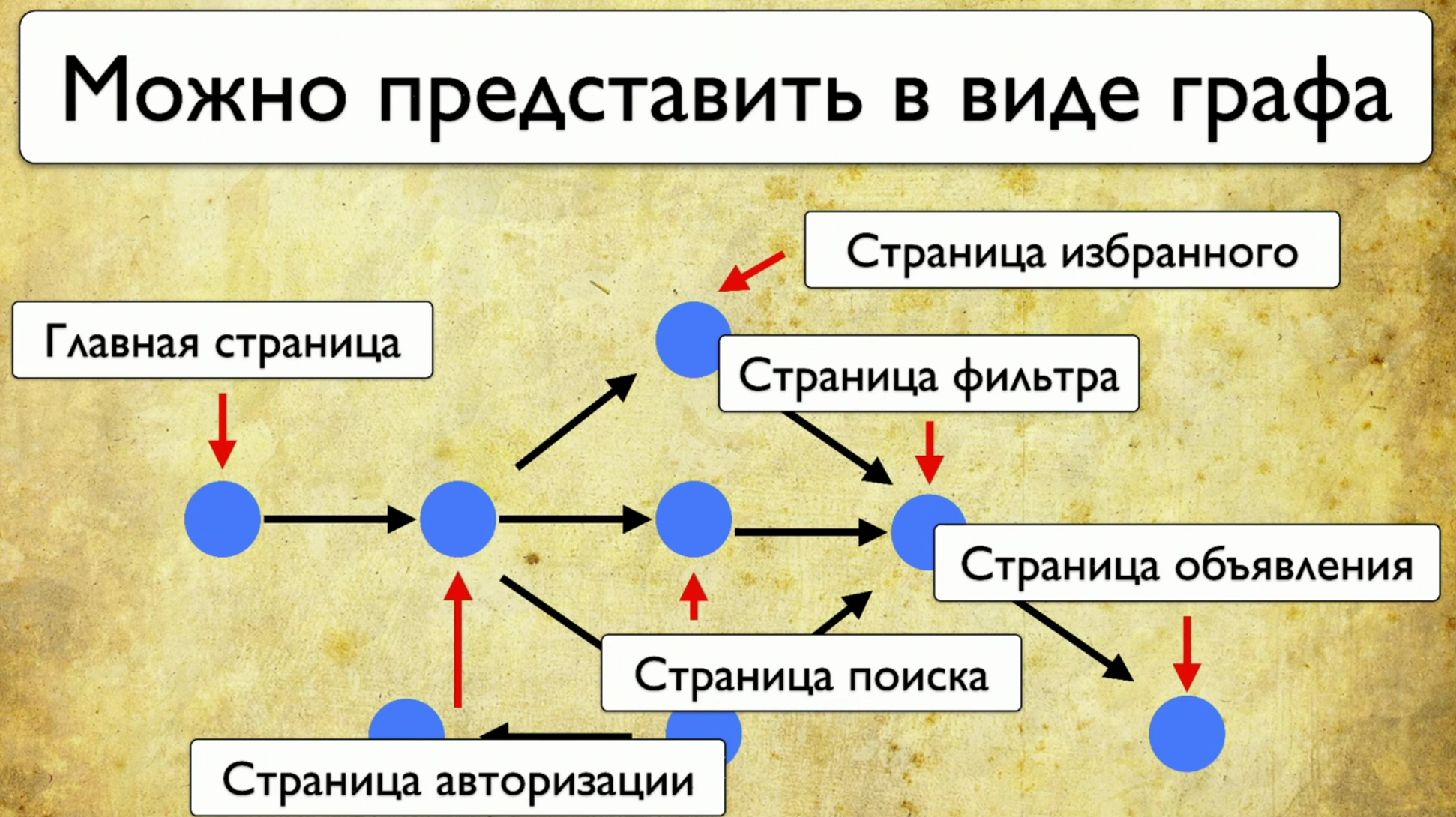 comment les tests s'exécutent: ils commencent à un moment donné, puis, par exemple, remplissent un formulaire, par exemple un formulaire d'autorisation, puis se dispersent sur d'autres pages, puis un autre sur un autre et se terminent .Si le gestionnaire demande si un bouton particulier est en cours de test, mais cette question est difficile à répondre: vous devez ouvrir le code ou aller à TestRail, alors je veux voir cette solution au problème:
comment les tests s'exécutent: ils commencent à un moment donné, puis, par exemple, remplissent un formulaire, par exemple un formulaire d'autorisation, puis se dispersent sur d'autres pages, puis un autre sur un autre et se terminent .Si le gestionnaire demande si un bouton particulier est en cours de test, mais cette question est difficile à répondre: vous devez ouvrir le code ou aller à TestRail, alors je veux voir cette solution au problème: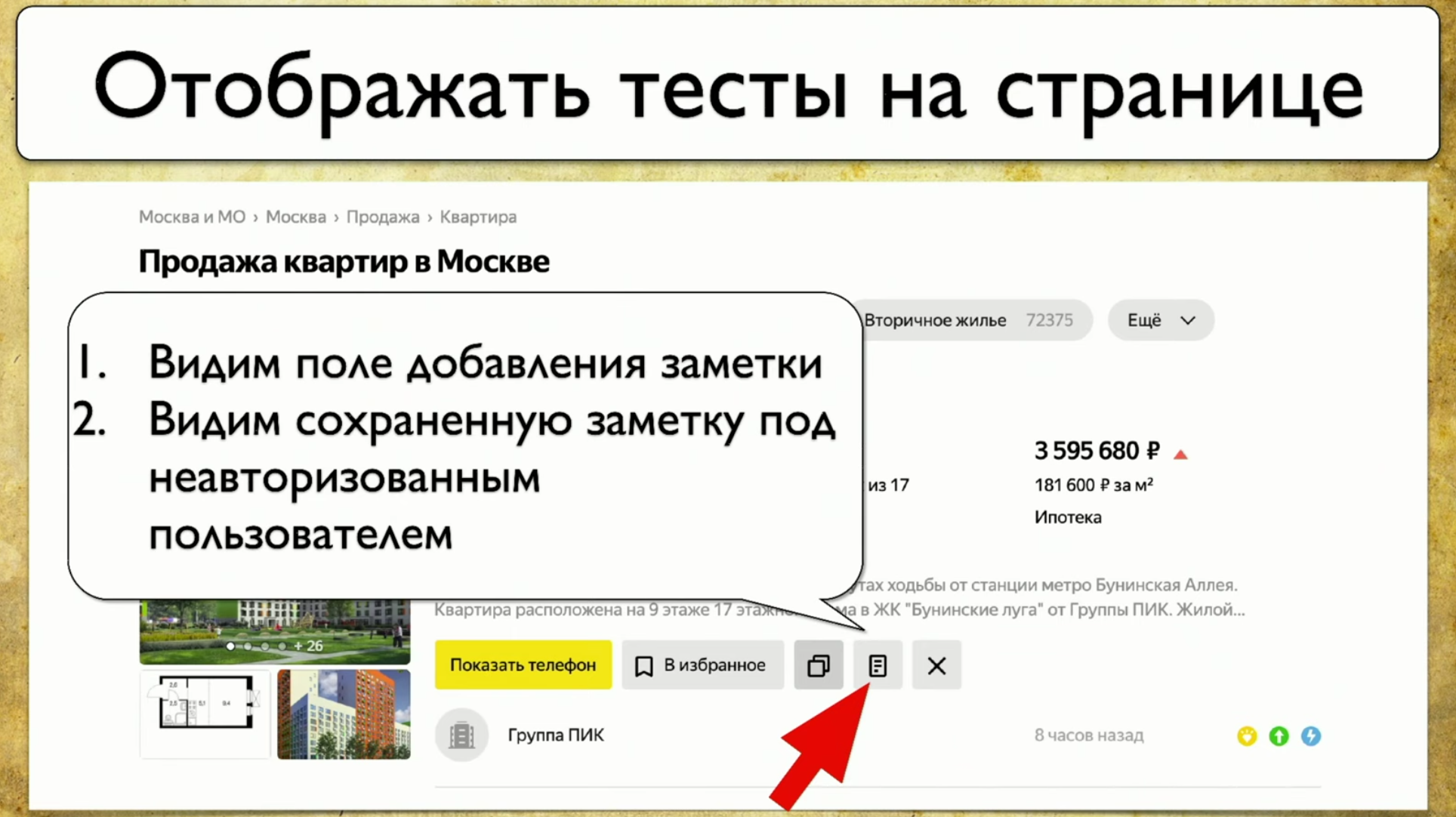 je veux pointer sur cet élément et voir tous les tests que nous avons sur cet article. S'il existait un tel instrument, je serais heureux. Lorsque nous avons commencé à réfléchir à cette idée, nous avons d'abord examiné Yandex.Metrica. Ils ont en fait à peu près les mêmes fonctionnalités qu'une carte de liens. Une bonne idée.L'essentiel est qu'ils sont mis en évidence exactement comme s'ils donnaient déjà les informations dont nous avons besoin. Ils disent: "Ici, nous avons passé ce lien 14 fois", ce qui en traduction dans la langue de test signifie: "14 tests ont été testés dans ce lien" et en quelque sorte l'ont traversé. Mais ce lien rouge a pris jusqu'à 120 tests, quels tests intéressants!Vous pouvez dessiner toutes sortes de tendances, ajouter des méta-informations, mais que se passe-t-il si nous prenons tout cela et dessinons du point de vue des tests? Donc, nous avons une tâche: pointer un élément et obtenir une note avec une liste de tests.
je veux pointer sur cet élément et voir tous les tests que nous avons sur cet article. S'il existait un tel instrument, je serais heureux. Lorsque nous avons commencé à réfléchir à cette idée, nous avons d'abord examiné Yandex.Metrica. Ils ont en fait à peu près les mêmes fonctionnalités qu'une carte de liens. Une bonne idée.L'essentiel est qu'ils sont mis en évidence exactement comme s'ils donnaient déjà les informations dont nous avons besoin. Ils disent: "Ici, nous avons passé ce lien 14 fois", ce qui en traduction dans la langue de test signifie: "14 tests ont été testés dans ce lien" et en quelque sorte l'ont traversé. Mais ce lien rouge a pris jusqu'à 120 tests, quels tests intéressants!Vous pouvez dessiner toutes sortes de tendances, ajouter des méta-informations, mais que se passe-t-il si nous prenons tout cela et dessinons du point de vue des tests? Donc, nous avons une tâche: pointer un élément et obtenir une note avec une liste de tests. Pour mettre en œuvre cela, vous devez cliquer sur l'icône, puis écrire une note, et c'est tout notre test. Nous utilisons Atlas chez nous, et l'intégration jusqu'à présent n'est qu'avec lui.Atlas ressemble à ceci:
Pour mettre en œuvre cela, vous devez cliquer sur l'icône, puis écrire une note, et c'est tout notre test. Nous utilisons Atlas chez nous, et l'intégration jusqu'à présent n'est qu'avec lui.Atlas ressemble à ceci:SearchPage.open ();
SearchPage.offersList().should(hasSizeGreaterThan(0));
Nous voulons qu'au moins un résultat soit affiché, sinon nous ne le testerons pas. Ensuite, nous déplaçons le curseur sur l'élément, puis nous cliquons dessus.searchPage.offer(FIRST).moveCursor();
searchPage.offer(FIRST).actionBar().note().click();
Ensuite, nous enregistrons en entrée User_Text et le soumettons.searchPage.offer(FIRST).addNoteInput().sendKeys(USER_TEXT);
searchPage.offer(FIRST).saveNote().click();
Après cela, nous vérifions que le texte est exactement celui qui aurait dû être. searchPage.offer(FIRST).addNoteInput().should(hasValue(USER_TEXT));
Les tests s'exécutent dans un navigateur, Atlas est un proxy pour ce test, nous appliquons ici la même approche que tout le monde utilise lors de la collecte de couverture: nous allons faire un localisateur avec .json. Nous y enregistrerons des informations sur toutes les ouvertures de page, toutes les itérations avec des éléments, qui ont soumis, qui a envoyé la clé, qui ont cliqué, quels ID, etc. - nous garderons un journal complet.Ensuite, nous attachons ce journal à Allure sous la forme de chaque test, et lorsque nous avons beaucoup de locators.json , nous générons meta.json . Le schéma est le même pour tous les éléments.Nous avons un plugin pour Google Chrome. Nous voulions prendre une décision sous la forme d'un plugin. J'ai spécialement fait une capture d'écran de la courbe afin qu'un détail important soit visible sur le chemin de la diapositive vers locators.json . Si vous avez généré un rapport maintenant, il existe une carte de couverture pour aujourd'hui. Si vous prenez le rapport des deux semaines précédentes et le collez ici, une carte de couverture pour la période d'il y a deux semaines apparaîtra. Vous avez une machine à remonter le temps!Cependant, lorsque vous branchez ce plugin, il dessine une interface peu conviviale.
Si vous avez généré un rapport maintenant, il existe une carte de couverture pour aujourd'hui. Si vous prenez le rapport des deux semaines précédentes et le collez ici, une carte de couverture pour la période d'il y a deux semaines apparaîtra. Vous avez une machine à remonter le temps!Cependant, lorsque vous branchez ce plugin, il dessine une interface peu conviviale. Chaque élément a un certain nombre de tests qui le traversent: il est clair que 40 tests passent par «acheter un appartement», l'en-tête est testé un test à la fois, c'est cool, et l'option «appartement» est également affichée. Vous obtenez une carte de couverture complète.Si vous survolez un élément, il prendra les données et imprimera vos vrais tests depuis votre tms, Allure Board et ainsi de suite. Le résultat est une information complète sur ce qui est testé et comment.Veuillez noter qu'à partir de chaque test, vous pouvez échouer directement dans le rapport Allure.
Chaque élément a un certain nombre de tests qui le traversent: il est clair que 40 tests passent par «acheter un appartement», l'en-tête est testé un test à la fois, c'est cool, et l'option «appartement» est également affichée. Vous obtenez une carte de couverture complète.Si vous survolez un élément, il prendra les données et imprimera vos vrais tests depuis votre tms, Allure Board et ainsi de suite. Le résultat est une information complète sur ce qui est testé et comment.Veuillez noter qu'à partir de chaque test, vous pouvez échouer directement dans le rapport Allure. Lorsque vous ouvrez quelque chose, il charge de nouveaux sélecteurs: si vous avez des tests qui passent par ces sélecteurs et que vous avez fait quelque chose avec le site, il traitera et affichera l'image entière.
Lorsque vous ouvrez quelque chose, il charge de nouveaux sélecteurs: si vous avez des tests qui passent par ces sélecteurs et que vous avez fait quelque chose avec le site, il traitera et affichera l'image entière.Quel est le profit?
Dès que nous avons mis en œuvre cette approche simple, alors, principalement, nous avons commencé à comprendre ce que nous avons testé dans les tests.
Maintenant, n'importe qui peut entrer et trouver n'importe quel "fil" qui mène au script. Par exemple, vous supposez que vous devez tester le paiement. Le paiement, évidemment, passe par le bouton de paiement: cliquez - tous les tests qui passent par le bouton de paiement apparaissent. C'est bon! Vous allez dans l'un d'eux et regardez le script.De plus, vous comprenez ce qui a été testé auparavant. Nous générons un fichier statique, vous pouvez spécifier le chemin vers celui-ci et indiquer quels tests étaient il y a deux semaines. Si le responsable dit qu'il y a un bug dans la production et demande si nous avons testé telle ou telle fonctionnalité il y a quelques semaines, vous prenez le rapport Allure, disons, par exemple, que vous ne l'avez pas testé.Un autre bénéfice est l'examen après avoir testé l'automatisation. Avant cela, nous avions un examen avant de tester l'automatisation, vous pouvez maintenant faire vos tests exactement comme vous les voyez. Si vous vouliez faire un test - terminé, avez pris une branche, lancé Allure, laissé tomber le lien vers le plug-in vers un testeur manuel et demandé à voir les tests. C'est exactement le processus qui vous permettra de renforcer la stratégie Agile: le chef d'équipe fait une revue de code, et les testeurs manuels font vos tests (scripts).Un autre avantage de cette approche est les éléments fréquemment utilisés. Si nous remplaçons ce bloc, dans lequel il y a 87 tests, alors tous tomberont. Vous commencez à comprendre à quel point vos tests sont flasques. Et si le bloc "prix à partir de" est annulé, alors ça va, un test tombera, une personne le corrigera. Si vous modifiez le bloc avec 87 tests, la couverture s'affaissera considérablement, car 87 tests ne passeront pas et ne vérifieront aucun résultat. Ce bloc nécessite une attention accrue. Ensuite, vous devez dire au développeur que ce bloc doit être avec un ID, car s'il part, tout s'effondrera.
Et si le bloc "prix à partir de" est annulé, alors ça va, un test tombera, une personne le corrigera. Si vous modifiez le bloc avec 87 tests, la couverture s'affaissera considérablement, car 87 tests ne passeront pas et ne vérifieront aucun résultat. Ce bloc nécessite une attention accrue. Ensuite, vous devez dire au développeur que ce bloc doit être avec un ID, car s'il part, tout s'effondrera.Comment pouvez-vous vous développer davantage?
Par exemple, vous pouvez suivre la voie du développement de la prise en charge d'autres outils, par exemple, pour Selenide. Je voudrais même prendre en charge non pas un séléniure spécifique, mais une implémentation de pilote qui vous permettra de collecter des localisateurs, quel que soit l'outil que vous utilisez. Ce proxy vide les informations puis les affiche.Une autre idée est d'afficher le résultat du test actuel. Par exemple, il est pratique de jeter immédiatement une telle image à un testeur manuel: vous n'avez pas à penser aux tests qui ont échoué, car vous pouvez aller sur le site, cliquer sur le test et le passer à la main sans vérifier les autres tests. C'est facile, vous pouvez récupérer ces informations auprès d'Allure et les dessiner ici.Vous pouvez également ajouter le score total, car tout le monde aime les graphiques, car je veux traiter des tests en double qui sont très similaires les uns aux autres, dont la partie centrale est la même, et le début et la queue ont un peu changé.
vous n'avez pas à penser aux tests qui ont échoué, car vous pouvez aller sur le site, cliquer sur le test et le passer à la main sans vérifier les autres tests. C'est facile, vous pouvez récupérer ces informations auprès d'Allure et les dessiner ici.Vous pouvez également ajouter le score total, car tout le monde aime les graphiques, car je veux traiter des tests en double qui sont très similaires les uns aux autres, dont la partie centrale est la même, et le début et la queue ont un peu changé. Je voudrais également voir immédiatement le nombre de sélecteurs en double. S'il est élevé, sur cette page, vous devez effectuer une refactorisation et exécuter des tests, sinon ils tomberont dans un ensemble trop volumineux. Il en va de même pour le nombre d'éléments avec lesquels nous avons interagi. Ceci est un symptôme courant. Cependant, dès que vous interagissez avec la page, la figure sautera en raison de nouveaux éléments et du nombre total de cas de test, vous devez donc ajouter une sorte d'analyse, ce ne sera pas superflu.Vous pouvez également ajouter la distribution des tests par couches, car vous voulez voir non seulement que nous avons ces tests, mais tous les types de tests qui sont sur cette page, éventuellement même des tests manuels.Ainsi, s'il existe des tests Java et des tests sur Puppeteer qu'une autre équipe écrit, nous pouvons regarder une page spécifique et dire immédiatement où nos tests se croisent. Autrement dit, nous parlerons la même langue avec eux et nous n'aurons pas besoin de collecter ces informations petit à petit. Si nous avons un outil qui montre tout dans l'interface Web, la tâche de comparer les tests en Java et Puppeteer ne semble plus insoluble.Enfin, parlons de la stratégie générale. Nous avons déjà parlé des types de couverture, nommés deux, avec un troisième type de revêtement, que nous avons utilisé en conséquence. Nous avons donc pris et examiné ce problème sous un angle différent.
Je voudrais également voir immédiatement le nombre de sélecteurs en double. S'il est élevé, sur cette page, vous devez effectuer une refactorisation et exécuter des tests, sinon ils tomberont dans un ensemble trop volumineux. Il en va de même pour le nombre d'éléments avec lesquels nous avons interagi. Ceci est un symptôme courant. Cependant, dès que vous interagissez avec la page, la figure sautera en raison de nouveaux éléments et du nombre total de cas de test, vous devez donc ajouter une sorte d'analyse, ce ne sera pas superflu.Vous pouvez également ajouter la distribution des tests par couches, car vous voulez voir non seulement que nous avons ces tests, mais tous les types de tests qui sont sur cette page, éventuellement même des tests manuels.Ainsi, s'il existe des tests Java et des tests sur Puppeteer qu'une autre équipe écrit, nous pouvons regarder une page spécifique et dire immédiatement où nos tests se croisent. Autrement dit, nous parlerons la même langue avec eux et nous n'aurons pas besoin de collecter ces informations petit à petit. Si nous avons un outil qui montre tout dans l'interface Web, la tâche de comparer les tests en Java et Puppeteer ne semble plus insoluble.Enfin, parlons de la stratégie générale. Nous avons déjà parlé des types de couverture, nommés deux, avec un troisième type de revêtement, que nous avons utilisé en conséquence. Nous avons donc pris et examiné ce problème sous un angle différent.D'une part, il y a une couverture qui a été lancée depuis 1963, d'autre part, il y a des testeurs manuels qui ont l'habitude de vivre dans un monde plus réel que le code. Il ne reste plus qu'à combiner ces deux approches.
Les personnes intéressées peuvent toujours rejoindre notre communauté. Voici deux référentiels de nos gars qui traitent du problème de couverture: