 En octobre de l'année dernière, la première conférence sur le cloud Yandex Yandex Scale a eu lieu. Il a annoncé le lancement de nombreux nouveaux services, y compris Yandex IoT Core, qui vous permet d'échanger des données avec des millions d'appareils IoT.Dans cet article, je vais vous expliquer pourquoi Yandex IoT Core est nécessaire et comment il fonctionne, ainsi que comment il peut interagir avec d'autres services Yandex.Cloud. Vous en apprendrez sur l'architecture, les subtilités de l'interaction des composants et les caractéristiques de la mise en œuvre des fonctionnalités - tout cela vous aidera à optimiser l'utilisation de ces services.Tout d'abord, rappelons les principaux avantages des clouds publics et de la PaaS - réduire le temps et les coûts de développement, ainsi que les coûts de support et d'infrastructure, ce qui est également pertinent pour les projets IoT. Mais il existe quelques fonctionnalités utiles moins évidentes que vous pouvez obtenir dans le cloud. Cette mise à l'échelle efficace et cette tolérance aux pannes sont des aspects importants lorsque vous travaillez avec des appareils, en particulier dans les projets d'infrastructure d'informations critiques.Une mise à l'échelle efficace est la capacité d'augmenter ou de diminuer librement le nombre d'appareils sans rencontrer de problèmes techniques et voir un changement prévisible du coût du système après les changements.La tolérance aux pannes est l'assurance que les services sont conçus et déployés de manière à garantir les meilleures performances possibles même en cas de défaillance de certaines ressources.Entrons maintenant dans les détails.
En octobre de l'année dernière, la première conférence sur le cloud Yandex Yandex Scale a eu lieu. Il a annoncé le lancement de nombreux nouveaux services, y compris Yandex IoT Core, qui vous permet d'échanger des données avec des millions d'appareils IoT.Dans cet article, je vais vous expliquer pourquoi Yandex IoT Core est nécessaire et comment il fonctionne, ainsi que comment il peut interagir avec d'autres services Yandex.Cloud. Vous en apprendrez sur l'architecture, les subtilités de l'interaction des composants et les caractéristiques de la mise en œuvre des fonctionnalités - tout cela vous aidera à optimiser l'utilisation de ces services.Tout d'abord, rappelons les principaux avantages des clouds publics et de la PaaS - réduire le temps et les coûts de développement, ainsi que les coûts de support et d'infrastructure, ce qui est également pertinent pour les projets IoT. Mais il existe quelques fonctionnalités utiles moins évidentes que vous pouvez obtenir dans le cloud. Cette mise à l'échelle efficace et cette tolérance aux pannes sont des aspects importants lorsque vous travaillez avec des appareils, en particulier dans les projets d'infrastructure d'informations critiques.Une mise à l'échelle efficace est la capacité d'augmenter ou de diminuer librement le nombre d'appareils sans rencontrer de problèmes techniques et voir un changement prévisible du coût du système après les changements.La tolérance aux pannes est l'assurance que les services sont conçus et déployés de manière à garantir les meilleures performances possibles même en cas de défaillance de certaines ressources.Entrons maintenant dans les détails.Architecture de script IoT
Voyons d'abord à quoi ressemble l'architecture globale du script IoT. On y distingue deux grandes parties:
On y distingue deux grandes parties:- Le premier est la livraison des données au stockage et la livraison des commandes aux appareils. Lorsque vous créez un système IoT, cette tâche doit être résolue dans tous les cas, quel que soit le projet que vous réalisez.
- Le second travaille avec les données reçues. Tout est similaire à tout autre projet basé sur l'analyse et la visualisation d'ensembles de données. Vous disposez d'un référentiel avec un tableau initial d'informations, avec lequel travailler vous permettra de réaliser votre tâche.
La première partie est approximativement la même dans tous les systèmes IoT: elle est construite sur des principes généraux et s'inscrit dans un scénario commun adapté à la plupart des systèmes IoT.La deuxième partie est presque toujours unique en termes de fonctions exécutées, bien qu'elle soit construite sur des composants standard. Dans le même temps, sans système d'interaction avec le matériel de haute qualité, tolérant aux pannes et évolutif, l'efficacité de la partie analytique de l'architecture est réduite à presque zéro, car il n'y a tout simplement rien à analyser.C'est pourquoi l'équipe Yandex.Cloud a tout d'abord décidé de se concentrer sur la création d'un écosystème de services pratique qui fournirait rapidement, efficacement et de manière fiable des données des appareils aux stockages, et vice versa - envoyer des commandes aux appareils. Pour résoudre ces problèmes, nous travaillons sur la fonctionnalité et l'intégration de Yandex IoT Core, des fonctions Yandex et des services de stockage de données dans le Cloud:
Pour résoudre ces problèmes, nous travaillons sur la fonctionnalité et l'intégration de Yandex IoT Core, des fonctions Yandex et des services de stockage de données dans le Cloud:- Le service Yandex IoT Core est un courtier MQTT évolutif à sécurité intégrée avec un ensemble de fonctions utiles supplémentaires.
- Le service Yandex Cloud Functions est représentatif de la direction prometteuse sans serveur et vous permet d'exécuter votre code en tant que fonction dans un environnement sûr, tolérant aux pannes et évolutif automatiquement sans créer ni entretenir de machines virtuelles.
- Le stockage d'objets Yandex est un stockage efficace de tableaux de données volumineux et convient parfaitement aux enregistrements d'archives «historiques».
- , , Yandex Managed Service for ClickHouse, «» . «» , , , .
Si les services de stockage et d'analyse de données sont des services `` à usage général '' qui ont déjà été beaucoup écrits, alors Yandex IoT Core et son interaction avec Yandex Cloud Functions posent généralement beaucoup de questions, en particulier pour les personnes qui commencent tout juste à comprendre l'Internet des objets et les technologies cloud. Et puisque ces services offrent une tolérance aux pannes et une mise à l'échelle du travail avec les appareils, nous verrons d'abord ce qu'ils ont sous le capot.Comment fonctionne Yandex IoT Core
Yandex IoT Core est un service de plateforme spécialisé pour l'échange de données bidirectionnel entre le cloud et les appareils exécutant le protocole MQTT. En fait, ce protocole est devenu la norme pour le transfert de données vers l'IoT. Il utilise le concept de files d'attente nommées (rubriques), où, d'une part, vous pouvez écrire des données, et d'autre part, les recevoir de manière asynchrone en vous abonnant aux événements de cette file d'attente.Le service Yandex IoT Core est multi-locataire, ce qui signifie une seule entité accessible à tous les utilisateurs. Autrement dit, tous les appareils et tous les utilisateurs interagissent avec la même instance de service.Cela permet, d'une part, d'assurer l'uniformité du travail pour tous les utilisateurs, d'autre part, une mise à l'échelle efficace et une tolérance aux pannes, afin de maintenir une connexion avec un nombre illimité d'appareils et de traiter une quantité illimitée de données en volume et en vitesse.Il s'ensuit que le service doit avoir à la fois des mécanismes de redondance et la capacité de gérer de manière flexible les ressources utilisées - afin de répondre aux changements de charge.De plus, la multi-location nécessite une logique particulière de partage des droits d'accès aux rubriques MQTT.Voyons comment cela est mis en œuvre.Comme de nombreux autres services Yandex.Cloud, Yandex IoT Core est logiquement divisé en deux parties - Plan de contrôle et Plan de données: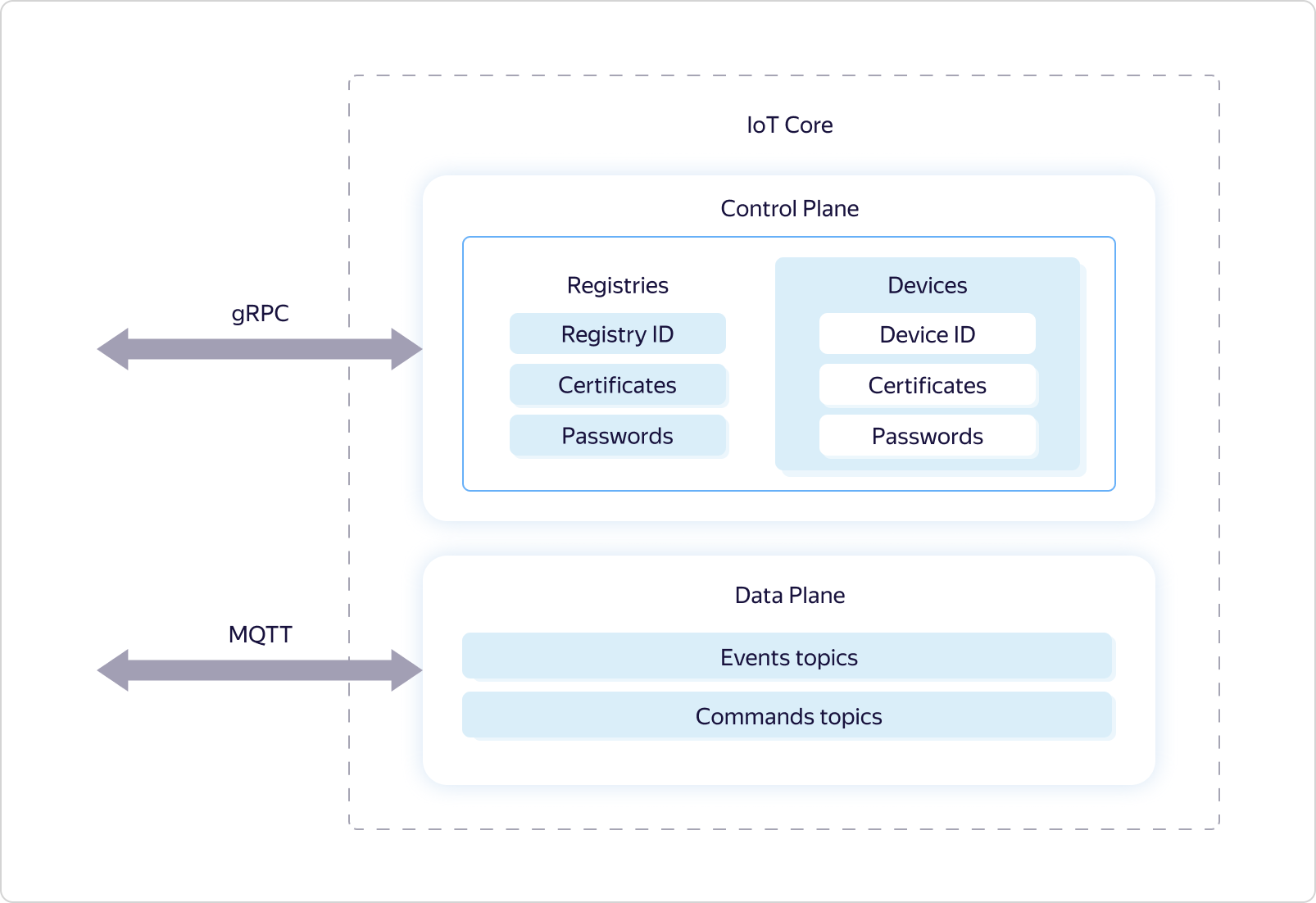 Data Plane est responsable de la logique de fonctionnement sous le protocole MQTT, et Control Plane est responsable de la délimitation des droits d'accès à certains sujets et utilise le registre et le périphérique des entités logiques à cette fin.
Data Plane est responsable de la logique de fonctionnement sous le protocole MQTT, et Control Plane est responsable de la délimitation des droits d'accès à certains sujets et utilise le registre et le périphérique des entités logiques à cette fin. Chaque utilisateur de Yandex.Cloud peut avoir plusieurs registres, chacun pouvant contenir son propre sous-ensemble d'appareils.L'accès aux rubriques est fourni comme suit: Les
Chaque utilisateur de Yandex.Cloud peut avoir plusieurs registres, chacun pouvant contenir son propre sous-ensemble d'appareils.L'accès aux rubriques est fourni comme suit: Les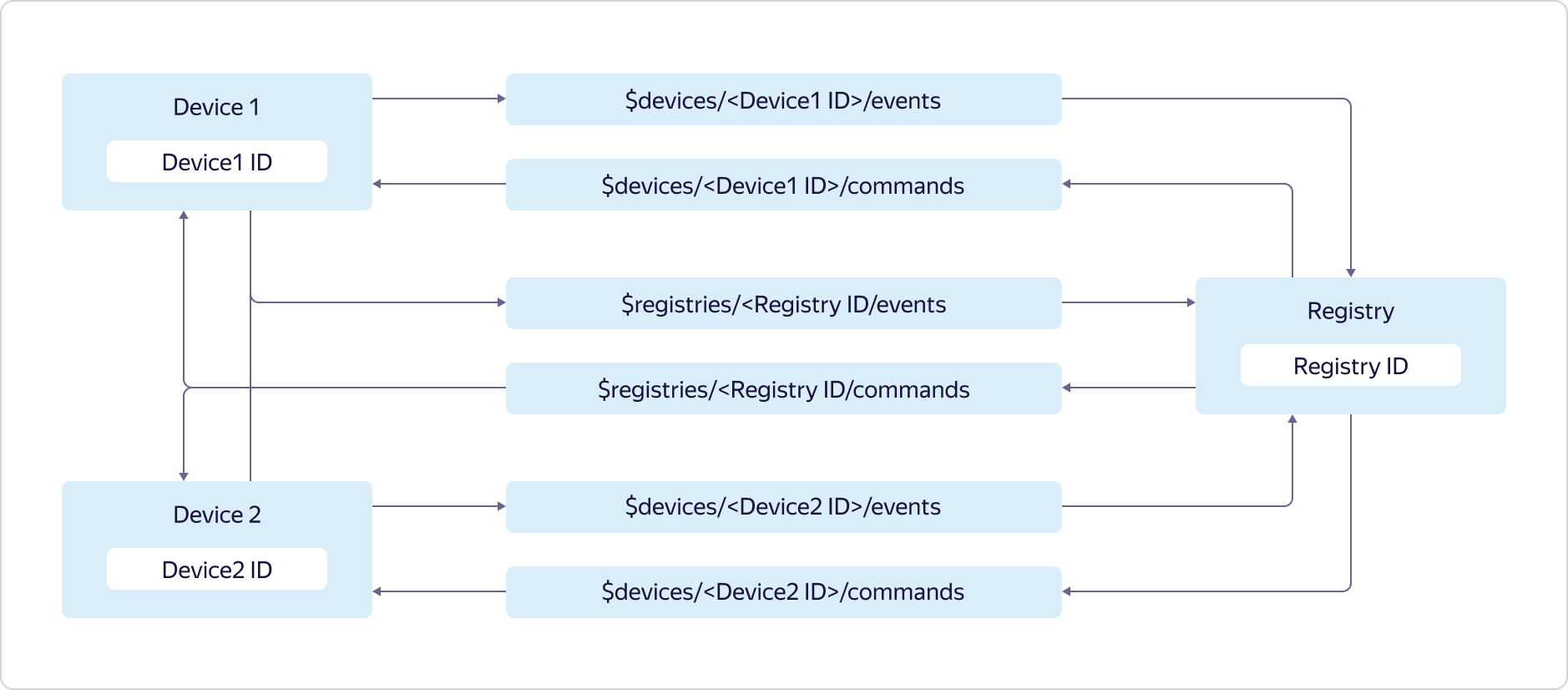 appareils peuvent envoyer des données uniquement à leur rubrique d'événements et à la rubrique d'événements de registre:
appareils peuvent envoyer des données uniquement à leur rubrique d'événements et à la rubrique d'événements de registre:$devices/<Device1 ID>/events
$registries/<Registry ID>/events
et abonnez-vous aux messages de votre rubrique de commandes et rubrique de commandes de registre:$devices/<Device1 ID>/commands
$registries/<Registry ID>/commands
Le registre peut envoyer des données à toutes les rubriques des commandes de périphérique et à la rubrique des commandes de registre:$devices/<Device1 ID>/commands
$devices/<Device2 ID>/commands
$registries/<Registry ID>/commands
et abonnez-vous aux messages de tous les sujets des événements de périphérique et du sujet des événements de registre:$devices/<Device1 ID>/events
$devices/<Device2 ID>/events
$registries/<Registry ID>/events
Pour fonctionner avec toutes les entités décrites ci-dessus, Data Plane possède un protocole gRPC et un protocole REST, en fonction desquels l'accès est implémenté via la console GUI de Yandex.Cloud et l'interface de ligne de commande CLI.Quant au Data Plane, il prend en charge la version 3.1.1 du protocole MQTT. Cependant, il existe plusieurs fonctionnalités:- Lors de la connexion, assurez-vous d'utiliser TLS.
- Seule la connexion TCP est prise en charge. WebSocket n'est pas encore disponible.
- L'autorisation est disponible à la fois par login et mot de passe (où login est le périphérique ou l'ID de registre, et les mots de passe sont définis par l'utilisateur), et à l'aide de certificats.
- L'indicateur Conserver n'est pas pris en charge lors de l'utilisation du courtier MQTT qui enregistre le message marqué avec l'indicateur et l'envoie la prochaine fois que vous vous abonnez à la rubrique.
- La session persistante n'est pas prise en charge, dans laquelle le courtier MQTT enregistre des informations sur le client (périphérique ou registre) pour faciliter la reconnexion.
- Avec l'abonnement et la publication, seuls les deux premiers niveaux de service sont pris en charge:
- QoS0 - Au plus une fois. Il n'y a pas de garantie de livraison, mais il n'y a pas de nouvelle livraison du même message.
- QoS1 - Au moins une fois. La livraison est garantie, mais il est possible de recevoir à nouveau le même message.
Pour simplifier la connexion à Yandex IoT Core, nous ajoutons régulièrement de nouveaux exemples pour différentes plateformes et langues à notre référentiel sur GitHub, et décrivons également des scripts dans la documentation.L'architecture du service ressemble à ceci: La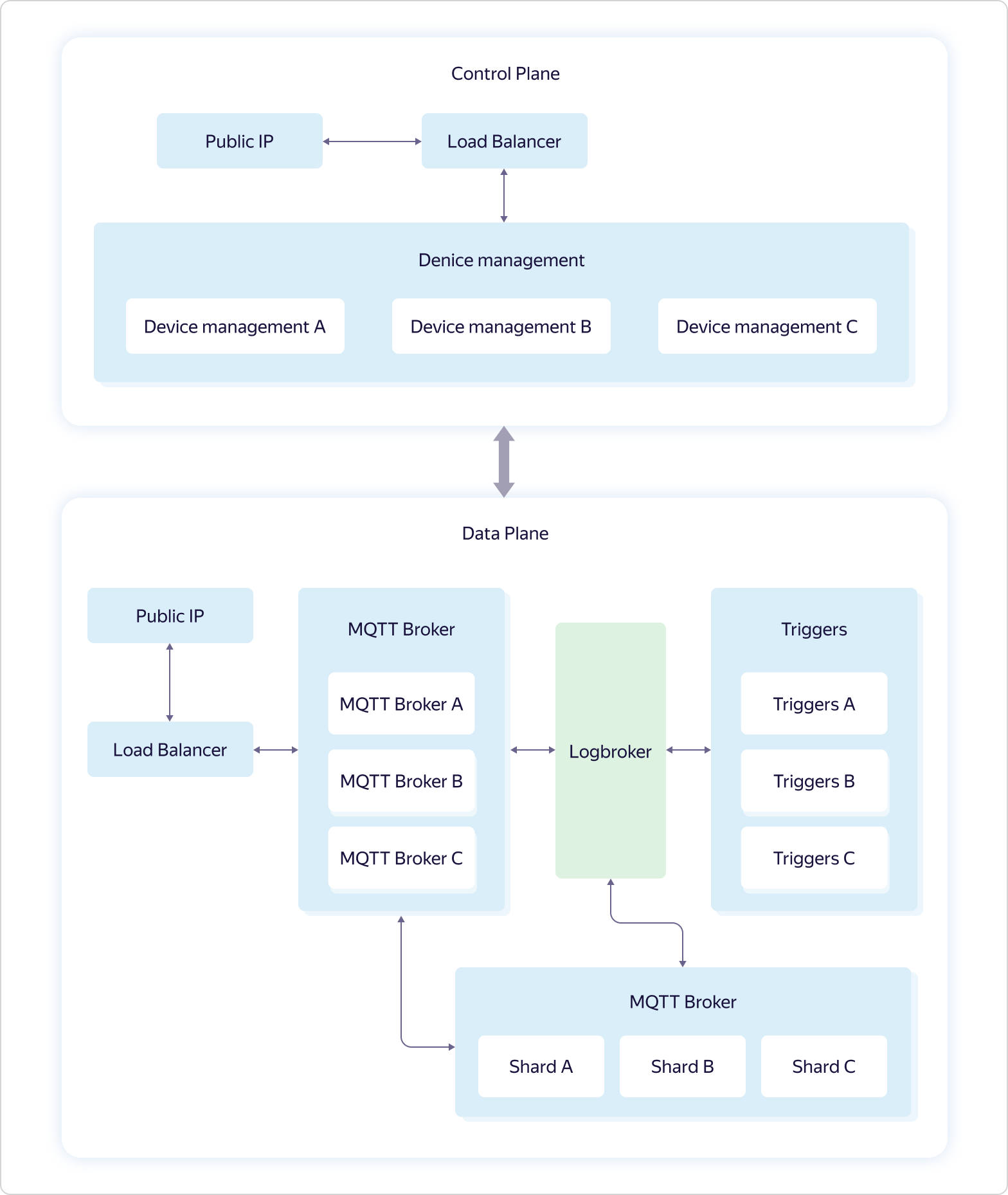 logique métier du service comprend quatre parties:
logique métier du service comprend quatre parties:- Device management — . Control Plane.
- MQTT Broker — MQTT-. Data Plane.
- Triggers — Yandex Cloud Functions. Data Plane.
- Shards — MQTT- . Data Plane.
Toute interaction avec le «monde extérieur» passe par des équilibreurs de charge. De plus, conformément à la philosophie du dogfooding, Yandex Load Balancer est utilisé, disponible pour tous les utilisateurs de Yandex.Cloud.Chaque partie de la logique métier se compose de plusieurs ensembles de trois machines virtuelles - une dans chaque zone de disponibilité (dans les schémas A, B et C). Les machines virtuelles sont exactement les mêmes que tous les utilisateurs de Yandex.Cloud. Lorsque la charge augmente, la mise à l'échelle se fait à l'aide de l'ensemble complet - trois machines sont ajoutées à la fois dans le cadre d'une partie de la logique métier. Cela signifie que si un ensemble de trois machines MQTT Broker ne peut pas gérer la charge, un autre ensemble de trois machines MQTT Broker sera ajouté, tandis que la configuration des autres parties de la logique métier restera la même.Et seul Logbroker n'est pas accessible au public. Il s'agit d'un service pour un fonctionnement à sécurité intégrée efficace avec des flux de données. Il est basé sur Apache Kafka, mais il a de nombreuses autres fonctions utiles: il implémente des processus de reprise après sinistre (y compris une seule sémantique lorsque vous avez une garantie de livraison de message sans duplication) et des processus de service (tels que la réplication entre centres, la distribution de données clusters de calcul), et dispose également d'un mécanisme de distribution uniforme et non dupliquée des données entre les abonnés au flux - une sorte d'équilibreur de charge.Les fonctions de gestion des appareils dans Control Plane sont décrites ci-dessus. Mais avec Data Plane, tout est beaucoup plus intéressant.Chaque instance de MQTT Broker fonctionne indépendamment et ne sait rien des autres instances. Toutes les données reçues (publiées par les clients) sont envoyées par les courtiers à Logbroker, d'où elles sont récupérées par Shards and Triggers. Et c'est dans les fragments que la synchronisation se produit entre les instances des courtiers. Les fragments connaissent tous les clients MQTT et la répartition de leurs abonnements (abonnement) entre les instances des courtiers MQTT et déterminent où envoyer les données reçues.Par exemple, le client MQTT A est abonné au sujet à partir du courtier A et le client MQTT B est abonné au même sujet à partir du courtier B. Si le client MQTT C effectue la publication sur le même sujet, mais au courtier C, le fragment transfère les données de courtier C aux courtiers A et B, à la suite de quoi les données seront reçues par le client MQTT A et le client MQTT B.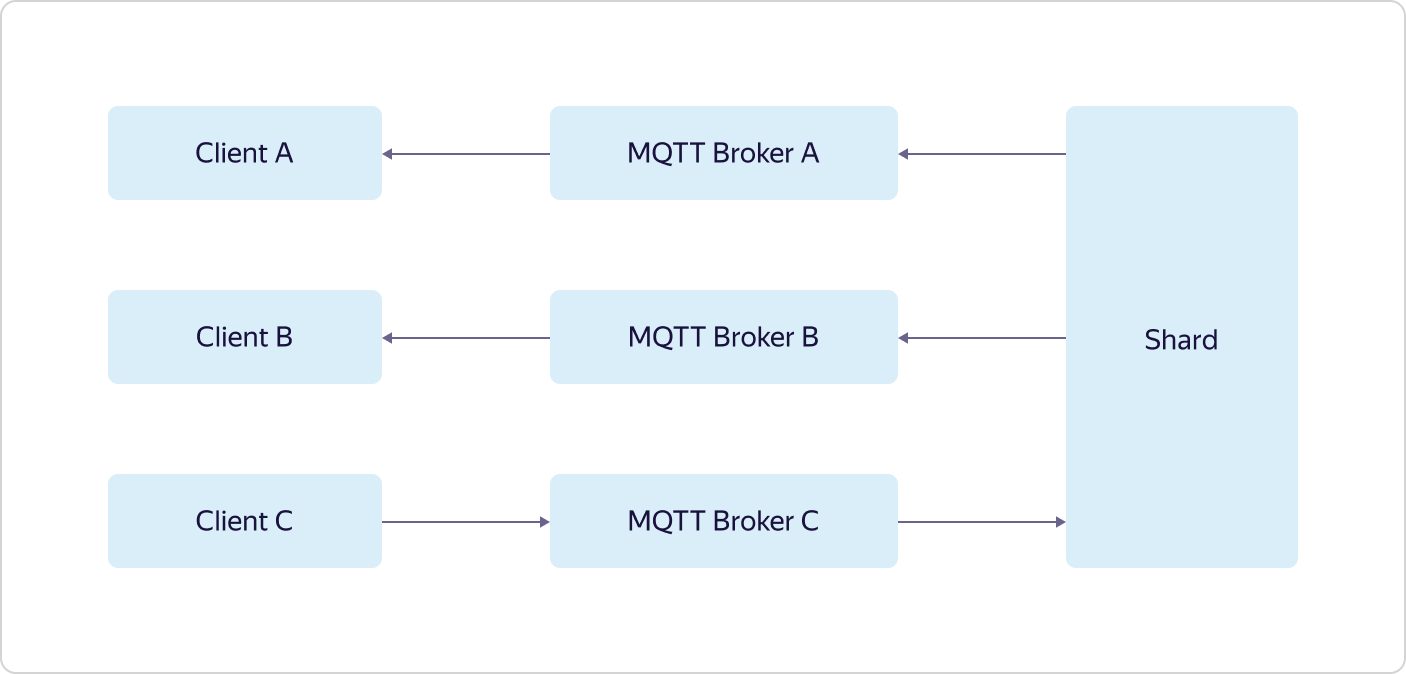 La dernière partie de la logique métier, Déclencheurs, reçoit également toutes les données reçues des clients MQTT et, si elles sont configurées par l'utilisateur, les transfère aux déclencheurs du service Yandex Cloud Functions.Comme vous pouvez le voir, Yandex IoT Core a une architecture et une logique de travail assez compliquées, qui sont difficiles à répéter sur les installations locales. Cela lui permet de résister à la perte de deux des trois zones de disponibilité, et de travailler sur un nombre illimité de connexions et des volumes de données illimités.De plus, toute cette logique est cachée à l'utilisateur «sous le capot», mais de l'extérieur, tout semble très simple - comme si vous travaillez avec un seul courtier MQTT.
La dernière partie de la logique métier, Déclencheurs, reçoit également toutes les données reçues des clients MQTT et, si elles sont configurées par l'utilisateur, les transfère aux déclencheurs du service Yandex Cloud Functions.Comme vous pouvez le voir, Yandex IoT Core a une architecture et une logique de travail assez compliquées, qui sont difficiles à répéter sur les installations locales. Cela lui permet de résister à la perte de deux des trois zones de disponibilité, et de travailler sur un nombre illimité de connexions et des volumes de données illimités.De plus, toute cette logique est cachée à l'utilisateur «sous le capot», mais de l'extérieur, tout semble très simple - comme si vous travaillez avec un seul courtier MQTT.Déclencheurs et fonctions cloud Yandex
Yandex Cloud Functions est un représentant des services dits "sans serveur" (sans serveur) dans Yandex.Cloud. L'essence principale de ces services est que l'utilisateur ne passe pas son temps à configurer, déployer et faire évoluer l'environnement pour exécuter du code, mais ne s'occupe que de la chose la plus précieuse pour lui - écrire le code lui-même qui effectue la tâche nécessaire. Dans le cas des fonctions, il s'agit du code dit sans état atomique qui peut être déclenché par un événement. «Atomique» et «sans état» signifient que ce code doit effectuer une tâche relativement petite mais intégrale, tandis que le code ne doit utiliser aucune variable afin de stocker des valeurs entre les appels.Il existe plusieurs façons d'appeler des fonctions: un appel HTTP direct, un appel avec minuterie (cron) ou un abonnement à un événement. Comme ce dernier, le service prend déjà en charge l'abonnement aux files d'attente de messages (Yandex Message Queue), les événements générés par le service de stockage d'objets et (le plus utile pour le scénario IoT) l'abonnement aux messages dans Yandex IoT Core.Malgré le fait que vous pouvez travailler avec Yandex IoT Core à l'aide de n'importe quel client compatible MQTT, Yandex Cloud Functions est l'un des moyens les plus optimaux et pratiques pour recevoir et traiter des données. La raison en est très simple. Une fonction peut être appelée sur chaque message entrant de n'importe quel appareil, et les fonctions seront exécutées en parallèle les unes aux autres (en raison de l'atomicité et de l'approche sans état), et le nombre de leurs appels changera naturellement à mesure que le nombre de messages entrants provenant des appareils changera. Ainsi, l'utilisateur peut ignorer complètement les problèmes de mise en place de l'infrastructure et, de plus, contrairement aux mêmes machines virtuelles, le paiement n'aura lieu que pour le travail réellement effectué.Cela vous permettra d'économiser considérablement à faible charge et d'obtenir un coût clair et prévisible avec la croissance.Le mécanisme d'appel des fonctions sur les événements (abonnement aux événements) est appelé déclencheur (Trigger). Son essence est illustrée dans le diagramme: Un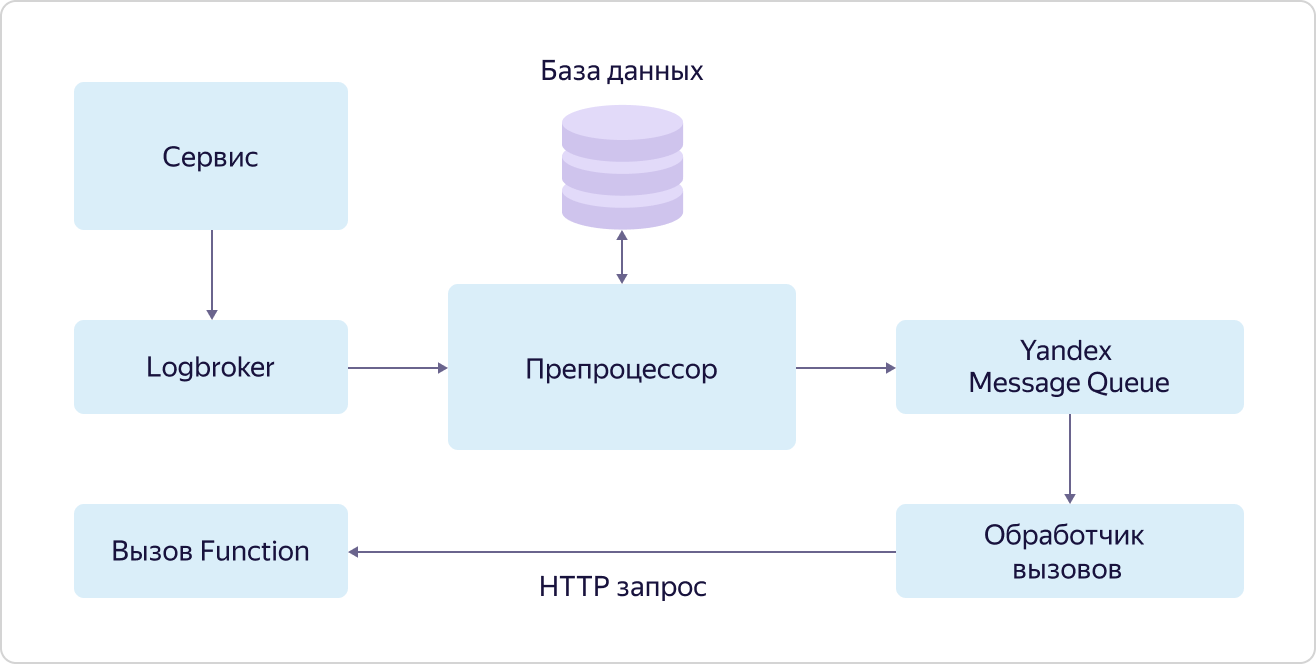 service qui génère des événements pour appeler des fonctions les place dans une file d'attente dans Logbroker. Dans le cas de Yandex IoT Core, les déclencheurs de Data Plane le font. De plus, ces événements sont pris par le préprocesseur, qui recherche un enregistrement dans la base de données pour cet événement indiquant la fonction à appeler. Si une telle entrée est trouvée, le préprocesseur place les informations sur l'appel de fonction (ID de fonction et paramètres d'appel) dans la file d'attente du service Yandex Message Queue, d'où le gestionnaire d'appel la récupère. Le gestionnaire, à son tour, envoie une demande HTTP pour appeler la fonction au service Yandex Cloud Functions.Dans le même temps, encore une fois, conformément à la philosophie dogfooding, le service Yandex Message Queue, accessible à tous les utilisateurs, est utilisé et les fonctions sont appelées exactement de la même manière que tout autre utilisateur peut appeler leurs fonctions.Disons quelques mots sur Yandex Message Queue. Bien qu'il s'agisse d'un service de file d'attente, comme Logbroker, il existe une différence significative entre eux. Lors du traitement des messages des files d'attente, le gestionnaire informe la file d'attente qu'elle est terminée et que le message peut être supprimé. Il s'agit d'un mécanisme de fiabilité important dans de tels services, mais il complique la logique de travail avec les messages.Yandex Message Queue vous permet de «paralléliser» le traitement de chaque message dans la file d'attente. En d'autres termes, le message de la file d'attente en cours de traitement ne bloque pas la possibilité qu'un autre "thread" récupère l'événement suivant de la file d'attente pour traitement. C'est ce qu'on appelle la simultanéité au niveau du message.Et LogBroker fonctionne sur les groupes de messages, et tant que le groupe entier n'est pas traité, le groupe suivant ne peut pas être récupéré pour traitement. Cette approche est appelée concurrence au niveau de la partition.Et c'est précisément l'utilisation de Yandex Message Queue qui vous permet de traiter rapidement et efficacement en parallèle un grand nombre de demandes pour appeler une fonction pour les événements d'un service particulier.Bien que les déclencheurs soient une unité indépendante distincte, ils font partie du service Yandex Cloud Functions. Il nous suffit de comprendre exactement comment les fonctions sont appelées.
service qui génère des événements pour appeler des fonctions les place dans une file d'attente dans Logbroker. Dans le cas de Yandex IoT Core, les déclencheurs de Data Plane le font. De plus, ces événements sont pris par le préprocesseur, qui recherche un enregistrement dans la base de données pour cet événement indiquant la fonction à appeler. Si une telle entrée est trouvée, le préprocesseur place les informations sur l'appel de fonction (ID de fonction et paramètres d'appel) dans la file d'attente du service Yandex Message Queue, d'où le gestionnaire d'appel la récupère. Le gestionnaire, à son tour, envoie une demande HTTP pour appeler la fonction au service Yandex Cloud Functions.Dans le même temps, encore une fois, conformément à la philosophie dogfooding, le service Yandex Message Queue, accessible à tous les utilisateurs, est utilisé et les fonctions sont appelées exactement de la même manière que tout autre utilisateur peut appeler leurs fonctions.Disons quelques mots sur Yandex Message Queue. Bien qu'il s'agisse d'un service de file d'attente, comme Logbroker, il existe une différence significative entre eux. Lors du traitement des messages des files d'attente, le gestionnaire informe la file d'attente qu'elle est terminée et que le message peut être supprimé. Il s'agit d'un mécanisme de fiabilité important dans de tels services, mais il complique la logique de travail avec les messages.Yandex Message Queue vous permet de «paralléliser» le traitement de chaque message dans la file d'attente. En d'autres termes, le message de la file d'attente en cours de traitement ne bloque pas la possibilité qu'un autre "thread" récupère l'événement suivant de la file d'attente pour traitement. C'est ce qu'on appelle la simultanéité au niveau du message.Et LogBroker fonctionne sur les groupes de messages, et tant que le groupe entier n'est pas traité, le groupe suivant ne peut pas être récupéré pour traitement. Cette approche est appelée concurrence au niveau de la partition.Et c'est précisément l'utilisation de Yandex Message Queue qui vous permet de traiter rapidement et efficacement en parallèle un grand nombre de demandes pour appeler une fonction pour les événements d'un service particulier.Bien que les déclencheurs soient une unité indépendante distincte, ils font partie du service Yandex Cloud Functions. Il nous suffit de comprendre exactement comment les fonctions sont appelées. Toutes les demandes d'appeler des fonctions (externes et internes) tombent dans l'équilibreur de charge, qui les distribue aux routeurs dans différentes zones d'accès (AZ), plusieurs éléments sont déployés dans chaque zone. Lors de la réception d'une demande, le routeur va d'abord au service Identity and Access Manager (IAM) pour s'assurer que la source de la demande a le droit d'appeler cette fonction. Il se tourne ensuite vers le planificateur et demande sur quel travailleur exécuter la fonction. Worker est une machine virtuelle avec un runtime personnalisé de fonctions isolées. De plus, le routeur, ayant reçu du planificateur l'adresse du travailleur sur lequel exécuter la fonction, envoie une commande à ce travailleur pour démarrer la fonction avec certains paramètres.D'où vient le travailleur? C'est là que toute la magie sans serveur se produit. Les planificateurs, analysant la charge (le nombre et la durée des fonctions), gèrent (démarrent et arrêtent) les machines virtuelles avec un runtime particulier. NodeJS et Python sont désormais pris en charge. Et ici, un paramètre est extrêmement important - la vitesse de lancement des fonctions. L'équipe de développement des services a fait un excellent travail, et maintenant la machine virtuelle démarre dans un maximum de 250 ms, tout en utilisant l'environnement le plus sécurisé pour isoler les fonctions les unes des autres - la virtualisation QEMU, qui exécute tout Yandex. Cloud. Dans le même temps, s'il existe déjà un travailleur actif pour la demande entrante, la fonction démarre presque instantanément.Et, conformément à la même approche dogfooding, le Load Balancer utilise un service public accessible à tous les utilisateurs, et le travailleur, le planificateur et le routeur sont des machines virtuelles ordinaires, les mêmes que tous les utilisateurs.Ainsi, la tolérance aux pannes du service est implémentée au niveau de l'équilibreur de charge et de la redondance des composants clés du système (routeur et ordonnanceur), et la mise à l'échelle se produit en raison du déploiement ou de la réduction du nombre de travailleurs. De plus, chaque zone d'accessibilité fonctionne indépendamment, ce qui permet de survivre à la perte de même deux des trois zones.
Toutes les demandes d'appeler des fonctions (externes et internes) tombent dans l'équilibreur de charge, qui les distribue aux routeurs dans différentes zones d'accès (AZ), plusieurs éléments sont déployés dans chaque zone. Lors de la réception d'une demande, le routeur va d'abord au service Identity and Access Manager (IAM) pour s'assurer que la source de la demande a le droit d'appeler cette fonction. Il se tourne ensuite vers le planificateur et demande sur quel travailleur exécuter la fonction. Worker est une machine virtuelle avec un runtime personnalisé de fonctions isolées. De plus, le routeur, ayant reçu du planificateur l'adresse du travailleur sur lequel exécuter la fonction, envoie une commande à ce travailleur pour démarrer la fonction avec certains paramètres.D'où vient le travailleur? C'est là que toute la magie sans serveur se produit. Les planificateurs, analysant la charge (le nombre et la durée des fonctions), gèrent (démarrent et arrêtent) les machines virtuelles avec un runtime particulier. NodeJS et Python sont désormais pris en charge. Et ici, un paramètre est extrêmement important - la vitesse de lancement des fonctions. L'équipe de développement des services a fait un excellent travail, et maintenant la machine virtuelle démarre dans un maximum de 250 ms, tout en utilisant l'environnement le plus sécurisé pour isoler les fonctions les unes des autres - la virtualisation QEMU, qui exécute tout Yandex. Cloud. Dans le même temps, s'il existe déjà un travailleur actif pour la demande entrante, la fonction démarre presque instantanément.Et, conformément à la même approche dogfooding, le Load Balancer utilise un service public accessible à tous les utilisateurs, et le travailleur, le planificateur et le routeur sont des machines virtuelles ordinaires, les mêmes que tous les utilisateurs.Ainsi, la tolérance aux pannes du service est implémentée au niveau de l'équilibreur de charge et de la redondance des composants clés du système (routeur et ordonnanceur), et la mise à l'échelle se produit en raison du déploiement ou de la réduction du nombre de travailleurs. De plus, chaque zone d'accessibilité fonctionne indépendamment, ce qui permet de survivre à la perte de même deux des trois zones.Liens utiles
En conclusion, je souhaite vous donner quelques liens qui vous permettront d'étudier plus en détail les services: