Bonjour, je voudrais aujourd'hui vous parler de mon expérience dans l'analyse des actions Sberbank. Parfois, ils montrent des dynamiques légèrement différentes - il est devenu intéressant pour moi d'analyser le mouvement de leurs citations.Dans cet exemple, nous téléchargerons des devis sur le site Web de Finam. Lien pour télécharger la Sberbank régulière .Pour les opérations sur colonnes, j'utiliserai des pandas, pour la visualisation de matplotlib.Nous importons:import pandas as pd
import matplotlib.pyplot as plt
Pour empêcher la réduction des tables, vous devez supprimer les restrictions:pd.set_option('display.max_columns', None)
pd.set_option('display.expand_frame_repr', False)
pd.set_option('max_colwidth', 80)
pd.set_option('max_rows', 6000)
Lire les données de stock
df = pd.read_csv("SBER_190101_200105.csv",sep=';', header=0, index_col='<DATE>', parse_dates=True)
(spécifiez le séparateur, où se trouvent les noms des colonnes, quelle colonne sera l'index, activez l'analyse de la date).Indiquez également le tri:df = df.sort_values(by='<DATE>')
Nous affichons nos données:print(df)
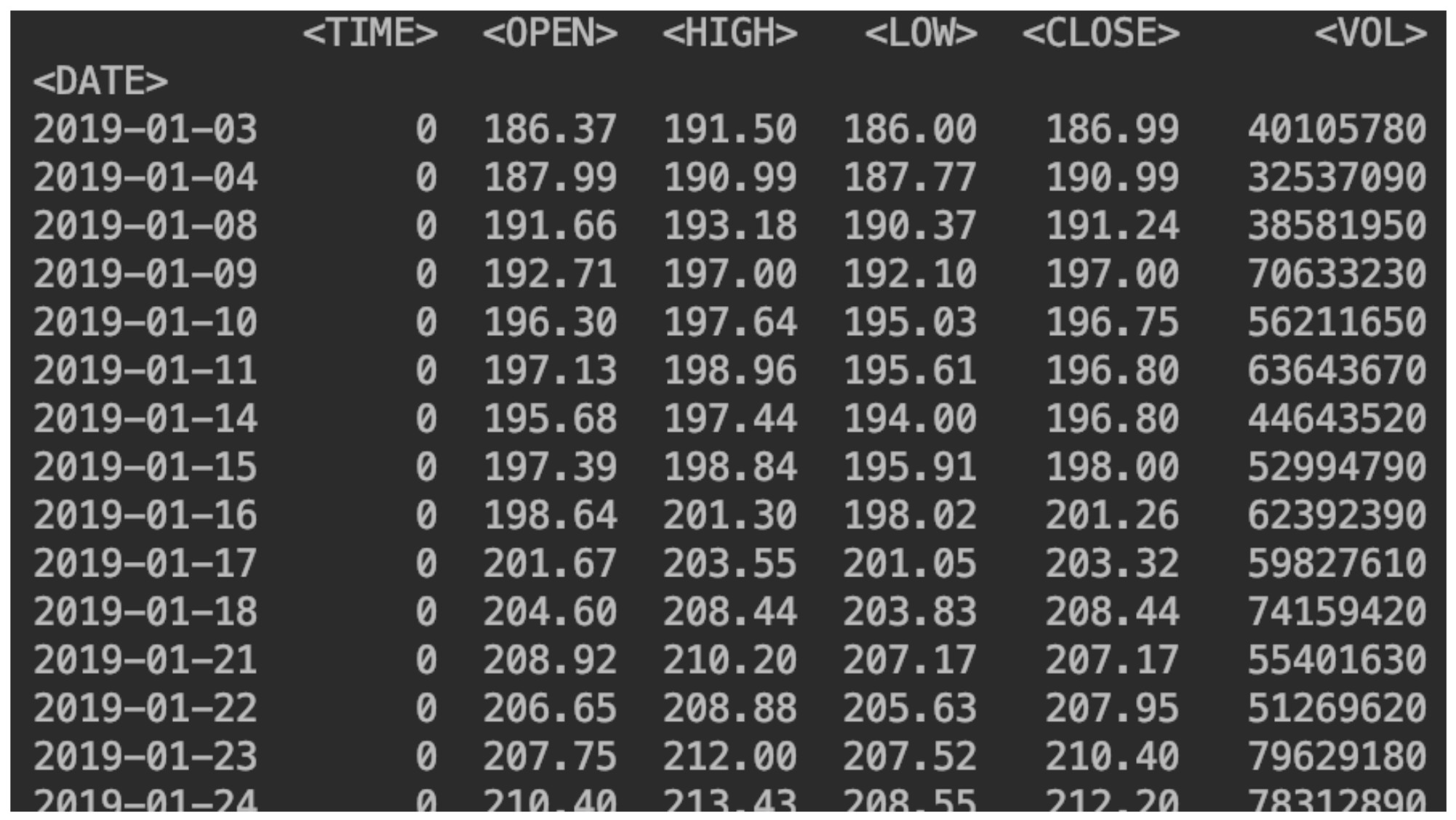 Ajouter une colonne avec un changement de prix
Ajouter une colonne avec un changement de prixdf['returns']=(df['<CLOSE>']/df['<CLOSE>'].shift(1))-1
Il est donc possible de dériver exactement le pourcentage:df['returns_pers']=((df['<CLOSE>']/df['<CLOSE>'].shift(1))-1)*100

Ajouter un deuxième partage
Faites-le exactement de la même manière.df2 = pd.read_csv("SBERP_190101_200105.csv",sep=';', header=0, index_col='<DATE>', parse_dates=True)
df = df.sort_values(by='<DATE>')
df2['returns_pers']=((df2['<CLOSE>']/df2['<CLOSE>'].shift(1))-1)*100
df2['returns']=(df2['<CLOSE>']/df2['<CLOSE>'].shift(1))-1
print(df2)
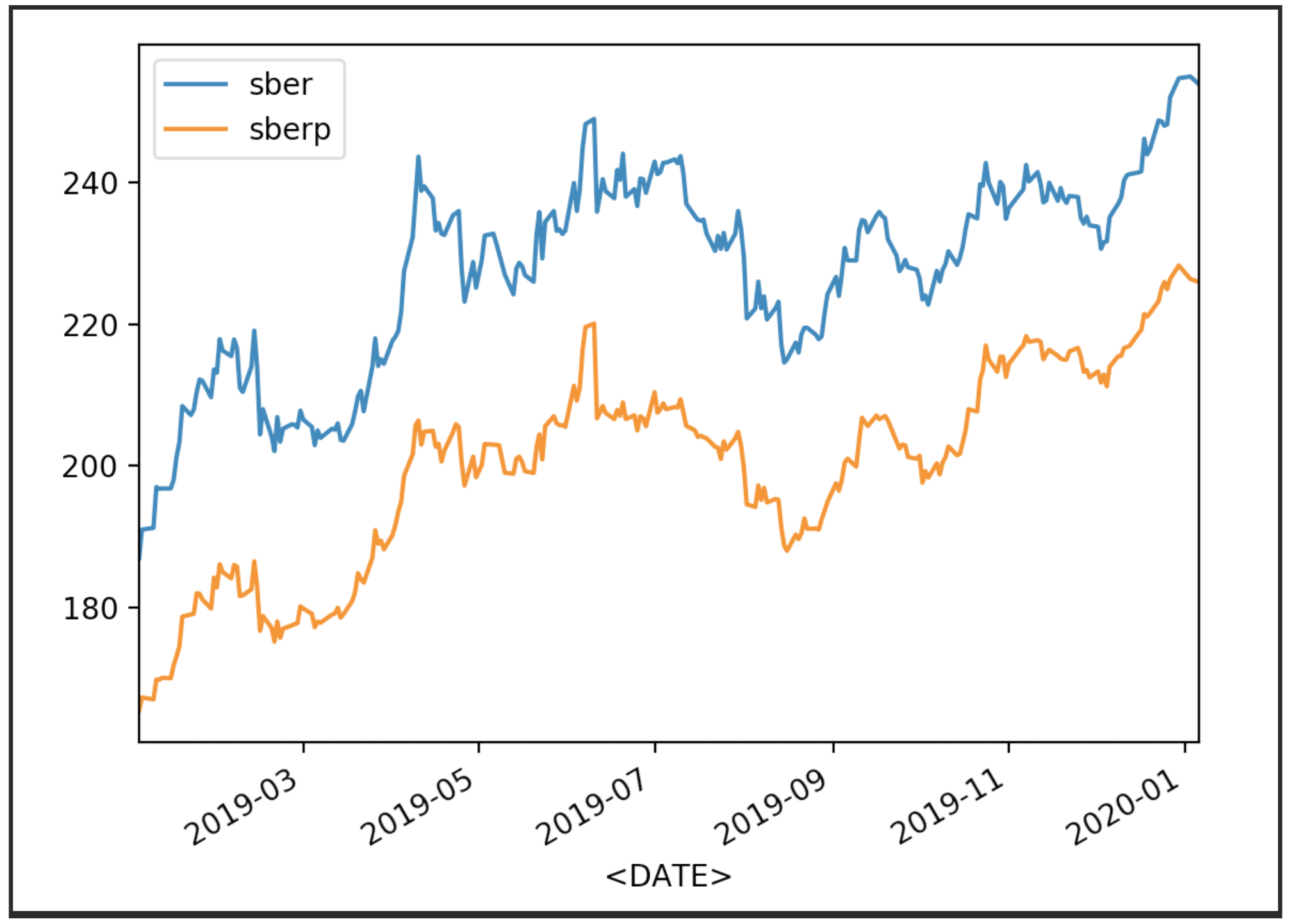
Nous visualisons nos cotations boursières
df['<CLOSE>'].plot(label='sber')
df2['<CLOSE>'].plot(label='sberp')
plt.legend()
plt.show()
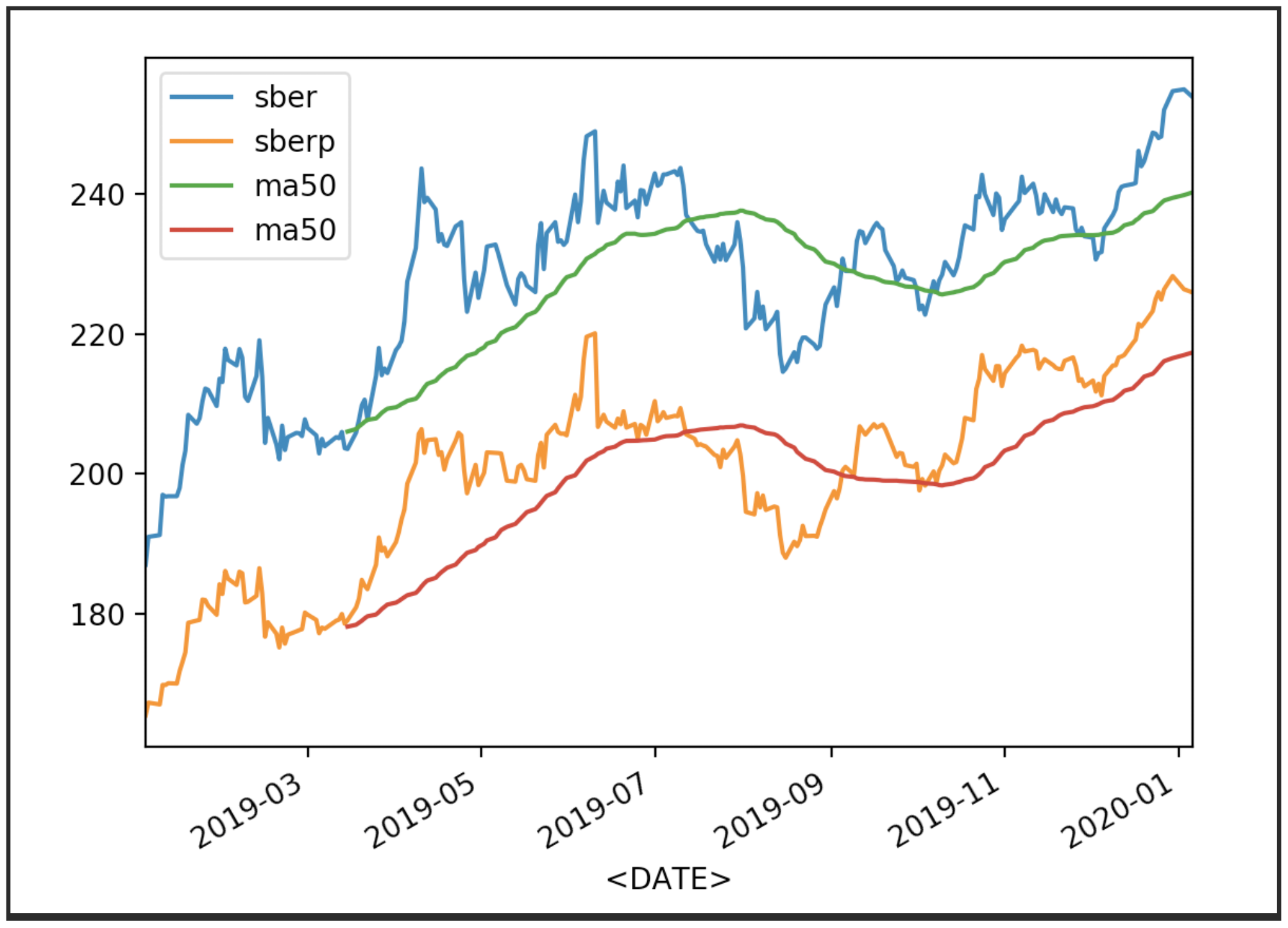
 Affichez maintenant les devis avec leur moyenne (MA 50):
Affichez maintenant les devis avec leur moyenne (MA 50):df['<CLOSE>'].plot(label='sber')
df2['<CLOSE>'].plot(label='sberp')
df['ma50'] = df['<OPEN>'].rolling(50).mean().plot(label='ma50')
df2['ma50'] = df2['<OPEN>'].rolling(50).mean().plot(label='ma50')
plt.legend()
plt.show()
 D'autres moyennes peuvent également être affichées.
D'autres moyennes peuvent également être affichées.df['<CLOSE>'].plot(label='sber')
df2['<CLOSE>'].plot(label='sberp')
df['ma100'] = df['<OPEN>'].rolling(100).mean().plot(label='ma100')
df2['ma100'] = df2['<OPEN>'].rolling(100).mean().plot(label='ma100')
plt.legend()
plt.show()
 Nous allons maintenant afficher le chiffre d'affaires des actions:ajoutez également le nom de l'axe Yet la taille de la toile
Nous allons maintenant afficher le chiffre d'affaires des actions:ajoutez également le nom de l'axe Yet la taille de la toiledf['total_trade'] = df['<OPEN>']*df['<VOL>']
df2['total_trade'] = df2['<OPEN>']*df2['<VOL>']
df['total_trade'].plot(label='sber',figsize=(16,8))
df2['total_trade'].plot(label='sberp',figsize=(16,8))
plt.legend()
plt.ylabel('Total Traded')
plt.show()

Analyse de corrélation
Examinons maintenant de plus près la corrélation. un tableau matricielnous y aidera. Créez un nouveau tableau avec des colonnes pour les deux actions et donnez-leur des noms.all_sber = pd.concat([df['<OPEN>'],df2['<OPEN>']],axis=1)
all_sber.columns = ['sber_open','sberp_open']
print(all_sber)
 Maintenant, nous importons le calendrier nécessaire
Maintenant, nous importons le calendrier nécessairefrom pandas.plotting import scatter_matrix
Et sortez-le:scatter_matrix(all_sber,figsize=(8,8),alpha=0.2,hist_kwds={'bins':100});
plt.show()
Il convient de préciser que nous devons ajouter de la transparence (alpha = 0,2) pour voir le chevauchement des points.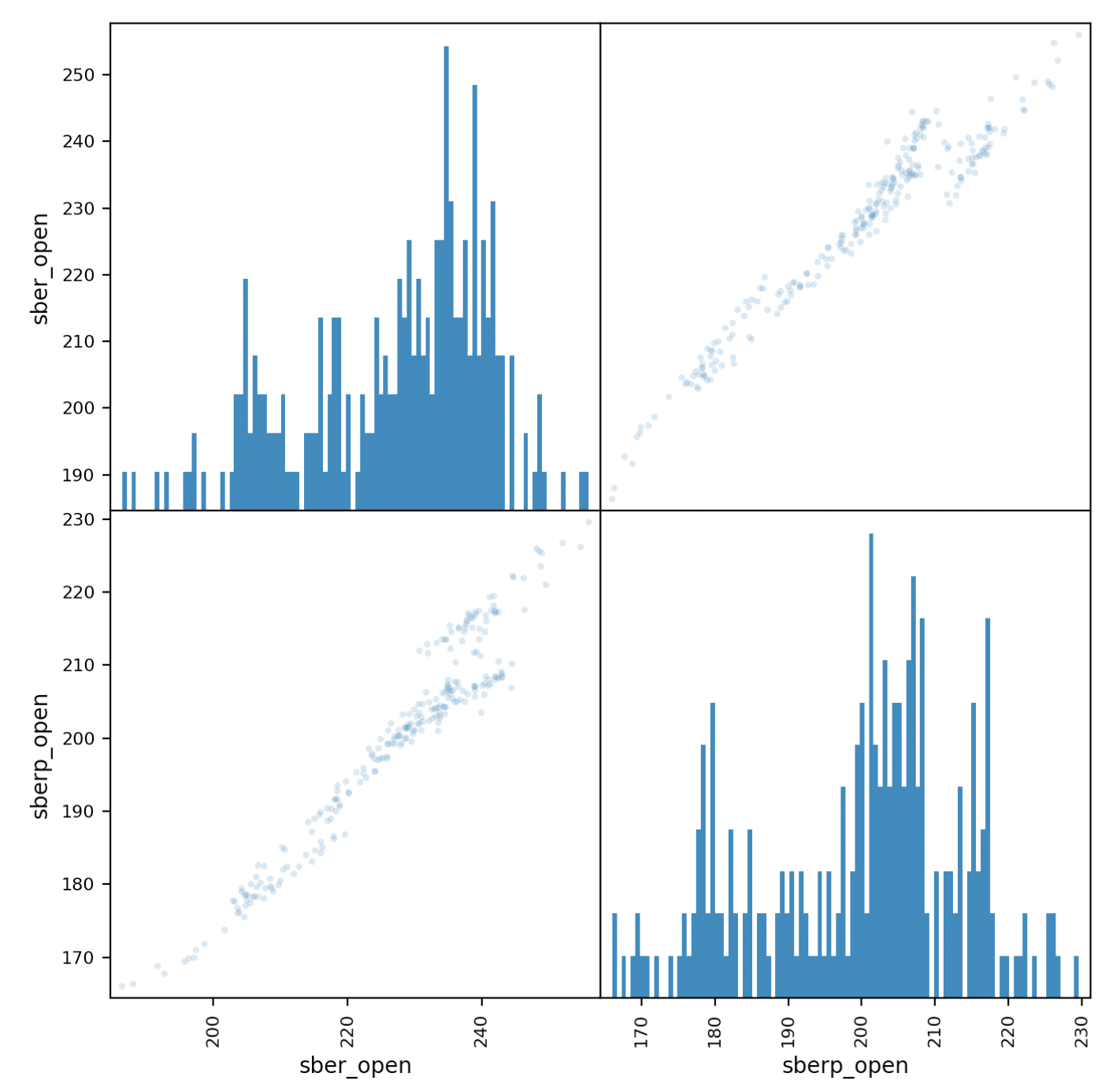 Si les points «vont» le long de la diagonale, une corrélation est observée.
Si les points «vont» le long de la diagonale, une corrélation est observée.Évaluation de la volatilité des titres
df['returns_pers'].plot(label='sber')
df2['returns_pers'].plot(label='sberp')
plt.legend()
plt.show()
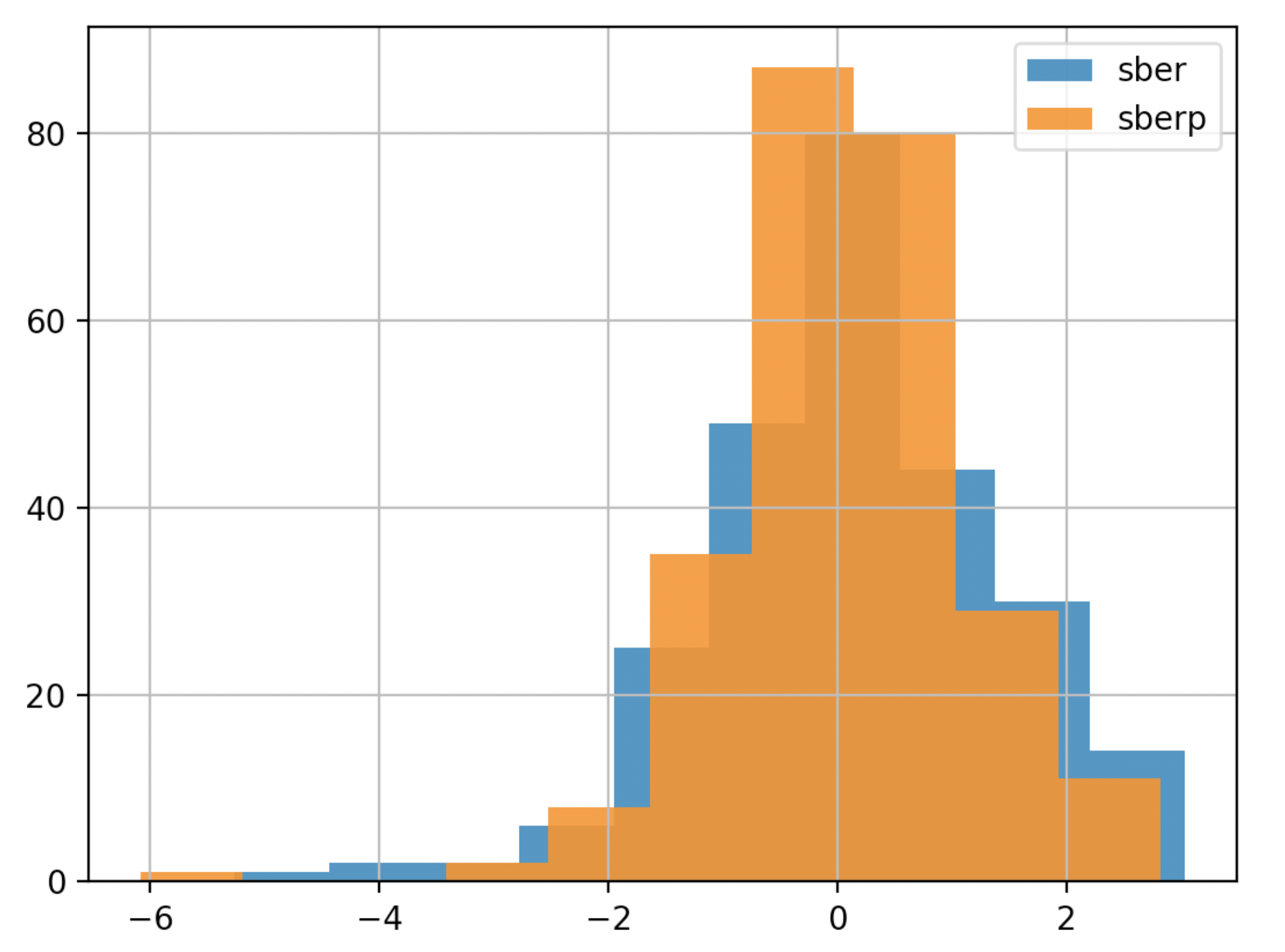
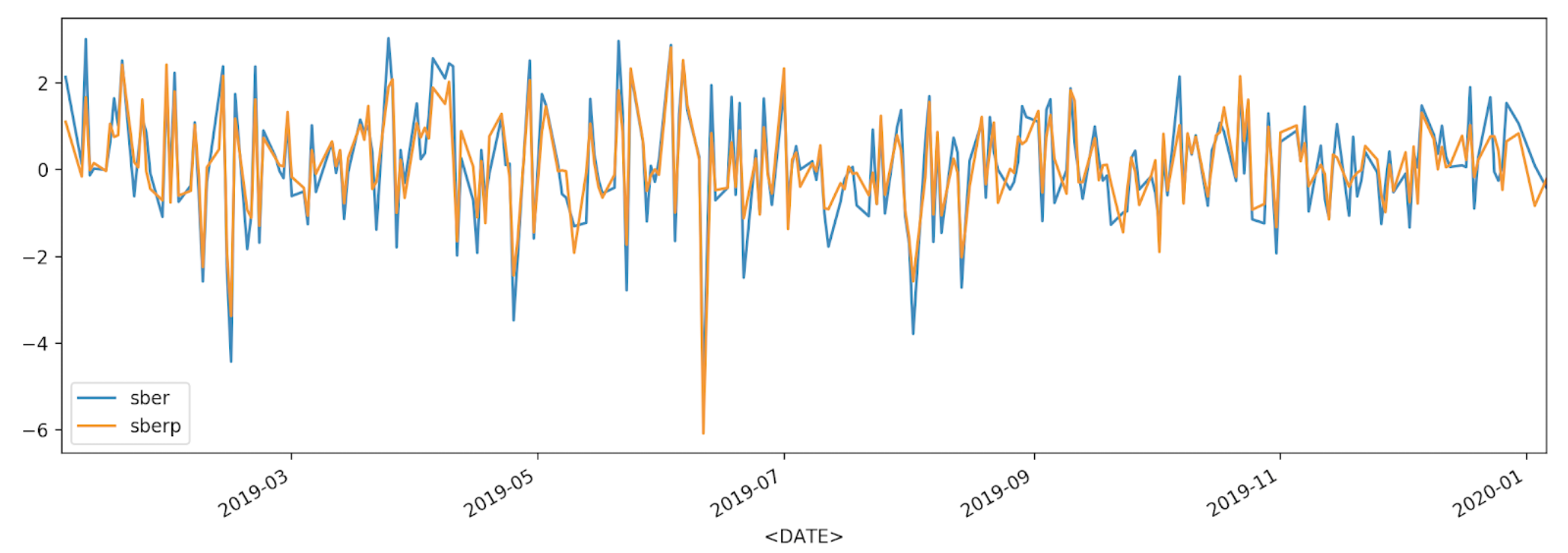 Pour une meilleure compréhension, nous afficherons la volatilité sur un autre graphique - un histogramme
Pour une meilleure compréhension, nous afficherons la volatilité sur un autre graphique - un histogrammedf['returns_pers'].hist(bins=100,label='sber',alpha=0.5)
df2['returns_pers'].hist(bins=100,label='sberp',alpha=0.5)
plt.legend()
plt.show()
 Pour conclure plus rapidement, vous pouvez simplifier le planning (nous rendrons le graphique moins détaillé et moins transparent):
Pour conclure plus rapidement, vous pouvez simplifier le planning (nous rendrons le graphique moins détaillé et moins transparent):df['returns_pers'].hist(bins=10,label='sber',alpha=0.9)
df2['returns_pers'].hist(bins=10,label='sberp',alpha=0.9)
plt.legend()
plt.show()
Analyse des revenus accumulés
Maintenant, nous dérivons le pourcentage de variation de la valeur des actions.Pour ce faire, entrez la colonne avec le revenu accumulé.df['Cumulative Return'] = (1+ df['returns']).cumprod()
df2['Cumulative Return'] = (1+ df2['returns']).cumprod()
print(df)
print(df2)
df['Cumulative Return'].plot(label='sber')
df2['Cumulative Return'].plot(label='sberp')
plt.legend()
plt.show()
 Sur les graphiques, nous pouvons voir les intervalles de temps où l'un des stocks est sous-estimé ou réévalué par rapport à l'autre. Dans les circonstances actuelles (ceteris paribus, veuillez noter), cela nous aidera à choisir un titre à évaluer lorsque la capitalisation de Sberbank baisse.
Sur les graphiques, nous pouvons voir les intervalles de temps où l'un des stocks est sous-estimé ou réévalué par rapport à l'autre. Dans les circonstances actuelles (ceteris paribus, veuillez noter), cela nous aidera à choisir un titre à évaluer lorsque la capitalisation de Sberbank baisse.