L'avènement de async / wait en C # a conduit à une redéfinition de la façon d'écrire du code parallèle simple et correct. Souvent, en utilisant la programmation asynchrone, les programmeurs non seulement ne résolvent pas les problèmes liés aux threads, mais en introduisent également de nouveaux. Les impasses et les vols ne vont nulle part - ils deviennent simplement plus difficiles à diagnostiquer. Dmitry Ivanov - Software Analysis TeamLead chez Huawei, un ancien développeur technologique JetBrains Rider et développeur du noyau ReSharper: structures de données, caches, multithreading, et un conférencier régulier à la conférence DotNext .Sous la cinématique - enregistrement vidéo et transcription textuelle du rapport de Dmitry de la conférence DotNext 2019 Piter.Nouvelle narration au nom de l'orateur.Dans le code multithread ou asynchrone, quelque chose se casse souvent. La raison pourrait être à la fois une impasse et une race. En règle générale, une course se bloque une fois sur mille, souvent pas localement, mais uniquement sur un serveur de build, et il faut plusieurs jours pour l'attraper. Je suis sûr que pour beaucoup, c'est une situation familière.De plus, en regardant du code asynchrone même par des développeurs expérimentés, je me surprends à penser que certaines choses peuvent être écrites trois fois plus rapidement et plus correctement.Cela suggère que le problème ne vient pas des personnes, mais de l'instrument. Les gens utilisent simplement l'outil et veulent qu'il résout leur problème. L'outil lui-même dispose d'un très grand nombre de capacités (parfois même superflues), de paramètres, d'un contexte implicite, ce qui conduit au fait qu'il est très facile à utiliser incorrectement. Essayons de comprendre comment utiliser async / wait et travailler avec une classe
Dmitry Ivanov - Software Analysis TeamLead chez Huawei, un ancien développeur technologique JetBrains Rider et développeur du noyau ReSharper: structures de données, caches, multithreading, et un conférencier régulier à la conférence DotNext .Sous la cinématique - enregistrement vidéo et transcription textuelle du rapport de Dmitry de la conférence DotNext 2019 Piter.Nouvelle narration au nom de l'orateur.Dans le code multithread ou asynchrone, quelque chose se casse souvent. La raison pourrait être à la fois une impasse et une race. En règle générale, une course se bloque une fois sur mille, souvent pas localement, mais uniquement sur un serveur de build, et il faut plusieurs jours pour l'attraper. Je suis sûr que pour beaucoup, c'est une situation familière.De plus, en regardant du code asynchrone même par des développeurs expérimentés, je me surprends à penser que certaines choses peuvent être écrites trois fois plus rapidement et plus correctement.Cela suggère que le problème ne vient pas des personnes, mais de l'instrument. Les gens utilisent simplement l'outil et veulent qu'il résout leur problème. L'outil lui-même dispose d'un très grand nombre de capacités (parfois même superflues), de paramètres, d'un contexte implicite, ce qui conduit au fait qu'il est très facile à utiliser incorrectement. Essayons de comprendre comment utiliser async / wait et travailler avec une classe Taskdans .NET.Plan
- Problèmes avec les approches résolues avec async / wait.
- Exemples de conception controversée.
- Une tâche de la vie réelle que nous allons résoudre de manière asynchrone.
Async / attente et problèmes à résoudre
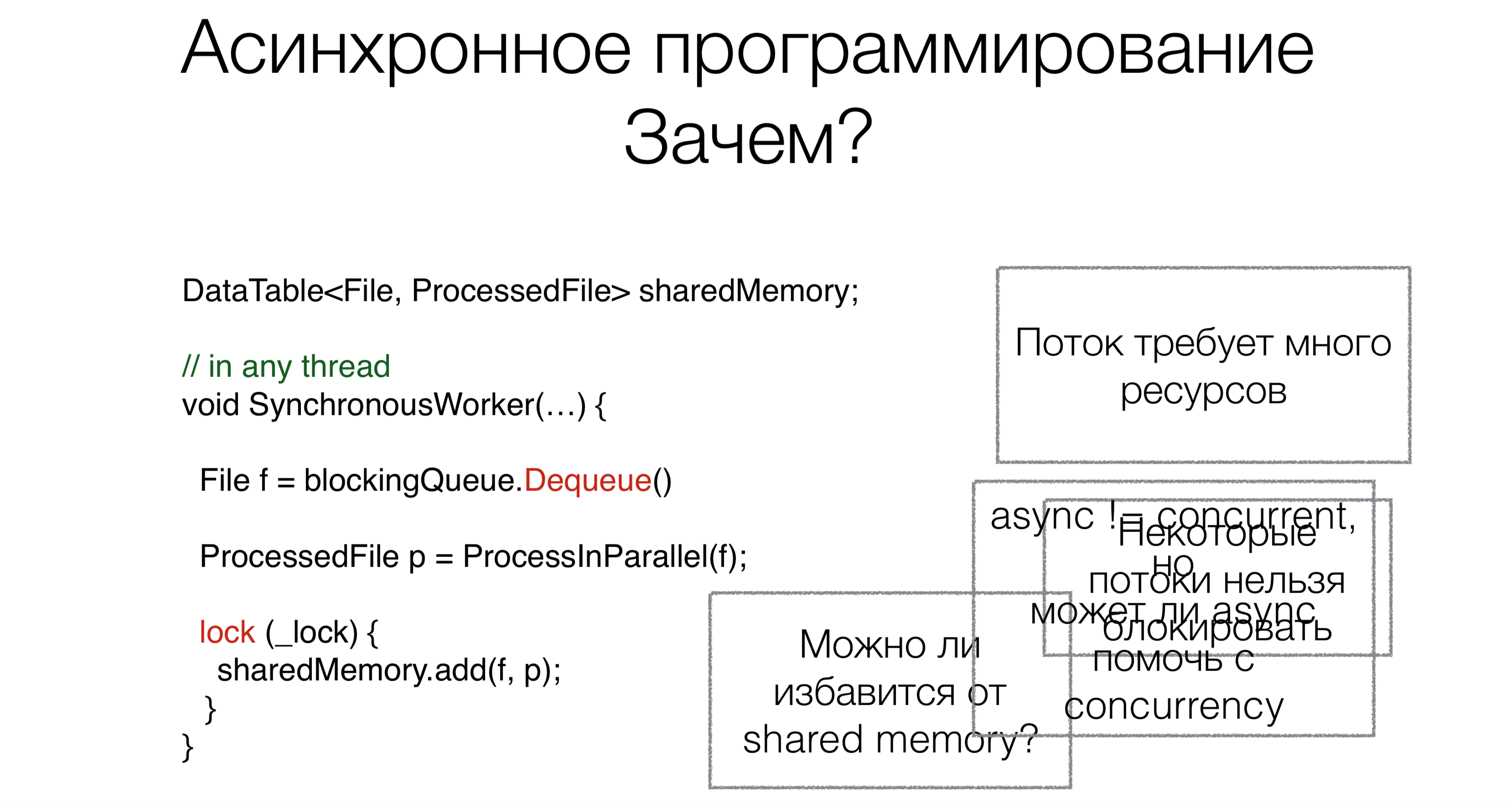 Pourquoi avons-nous besoin d'async / wait? Disons que nous avons du code qui fonctionne avec la mémoire partagée partagée.Au début du travail, nous lisons la demande, dans ce cas, le fichier de la file d'attente de blocage (par exemple, d'Internet ou du disque), en utilisant la demande de blocage Dequeue (les demandes de blocage seront marquées en rouge dans les images avec des exemples).Cette approche nécessite beaucoup de threads, et chaque thread nécessite des ressources, crée une charge sur le planificateur. Mais ce n'est pas le problème principal. Supposons que les utilisateurs puissent réécrire les systèmes d'exploitation afin que ces systèmes prennent en charge à la fois cent mille et un million de threads. Mais le principal problème est que certains threads ne peuvent tout simplement pas être pris. Par exemple, vous disposez d'un thread d'interface utilisateur. Il n'y a pas de cadres d'interface utilisateur adéquats normaux où l'accès aux données ne serait pas seulement à partir d'un seul thread, pour l'instant. Le thread d'interface utilisateur ne peut pas être bloqué. Et pour ne pas le bloquer, nous avons besoin d'un code asynchrone.Parlons maintenant de la deuxième tâche. Après avoir lu le fichier, il doit être traité d'une manière ou d'une autre. Nous le ferons en parallèle.Beaucoup d'entre vous ont entendu dire que le parallélisme n'est pas la même chose que l'asynchronie. Dans ce cas, la question se pose: l'asynchronie peut-elle aider à écrire du code parallèle plus compact, beau et plus rapide?La dernière tâche consiste à travailler avec la mémoire partagée. Avons-nous besoin de faire glisser ce mécanisme avec des verrous, la synchronisation vers du code asynchrone, ou cela peut-il être évité d'une manière ou d'une autre? Peut asynchroniser / attendre de l' aide à ce sujet?
Pourquoi avons-nous besoin d'async / wait? Disons que nous avons du code qui fonctionne avec la mémoire partagée partagée.Au début du travail, nous lisons la demande, dans ce cas, le fichier de la file d'attente de blocage (par exemple, d'Internet ou du disque), en utilisant la demande de blocage Dequeue (les demandes de blocage seront marquées en rouge dans les images avec des exemples).Cette approche nécessite beaucoup de threads, et chaque thread nécessite des ressources, crée une charge sur le planificateur. Mais ce n'est pas le problème principal. Supposons que les utilisateurs puissent réécrire les systèmes d'exploitation afin que ces systèmes prennent en charge à la fois cent mille et un million de threads. Mais le principal problème est que certains threads ne peuvent tout simplement pas être pris. Par exemple, vous disposez d'un thread d'interface utilisateur. Il n'y a pas de cadres d'interface utilisateur adéquats normaux où l'accès aux données ne serait pas seulement à partir d'un seul thread, pour l'instant. Le thread d'interface utilisateur ne peut pas être bloqué. Et pour ne pas le bloquer, nous avons besoin d'un code asynchrone.Parlons maintenant de la deuxième tâche. Après avoir lu le fichier, il doit être traité d'une manière ou d'une autre. Nous le ferons en parallèle.Beaucoup d'entre vous ont entendu dire que le parallélisme n'est pas la même chose que l'asynchronie. Dans ce cas, la question se pose: l'asynchronie peut-elle aider à écrire du code parallèle plus compact, beau et plus rapide?La dernière tâche consiste à travailler avec la mémoire partagée. Avons-nous besoin de faire glisser ce mécanisme avec des verrous, la synchronisation vers du code asynchrone, ou cela peut-il être évité d'une manière ou d'une autre? Peut asynchroniser / attendre de l' aide à ce sujet?Chemin vers async / attente
Regardons l'évolution de la programmation asynchrone en général dans le monde et en .NET.Rappeler
Void Foo(params, Action callback) {…}
Void OurMethod() {
…
Foo(params,() =>{
…
});
}
La programmation asynchrone a commencé par des rappels. Autrement dit, vous devez d'abord appeler une partie du code de manière synchrone et la seconde partie - de manière asynchrone. Par exemple, vous lisez un fichier et lorsque les données sont prêtes, elles vous seront livrées d'une manière ou d'une autre. Cette partie asynchrone est passée en rappel .Plus de rappels
void Foo(params, Action callback) {...}
void Bar(Action callback) {...}
void Baz(Action callback) {...}
void OurMethod() {
...
Foo(params, () => {
...
Bar(() => {
Baz(() => {
});
});
});
}
Ainsi, à partir d'un rappel, vous pouvez enregistrer un autre rappel , à partir duquel vous pouvez enregistrer un troisième rappel, et à la fin, tout se transforme en enfer de rappel .
Rappel: exceptions
void Foo(params, Action onSuccess, Action onFailure) {...}
void OurMethod() {
...
Foo(params, () => {
...
},
() => {
...
});
}
Comment travailler avec des exceptions? Par exemple, ReSharper, lorsqu'il répond séparément aux exceptions et à une bonne exécution, ne présente pas les plus beaux morceaux de code - il existe des rappels distincts pour une situation exceptionnelle et pour une continuation réussie. Le résultat est un tel enfer de rappel , mais pas linéaire, mais semblable à un arbre, ce qui peut être complètement déroutant. Dans .NET, la première approche de rappel est appelée le modèle de programmation asynchrone (APM). La méthode sera appelée
Dans .NET, la première approche de rappel est appelée le modèle de programmation asynchrone (APM). La méthode sera appelée AsyncCallback, qui est essentiellement la même que Action, mais l'approche a certaines caractéristiques. Tout d'abord, les méthodes doivent commencer par le mot «Begin» (la lecture d'un fichier est BeginRead), qui en renvoie AsyncResult. Lui-mêmeAsyncResult- Il s'agit d'un gestionnaire qui sait que l'opération est terminée et qui dispose d'un mécanisme WaitHandle. Vous WaitHandlepouvez attendre, en attendant que l'opération se termine de manière asynchrone. D'un autre côté, vous pouvez appeler EndOperation, c'est-à-dire créer EndReadet bloquer de manière synchrone (ce qui est très similaire à une propriété Task.Result).Cette approche pose un certain nombre de problèmes. Premièrement, cela ne nous protège pas de l' enfer des rappels . Deuxièmement, on ne sait pas trop quoi faire des exceptions. Troisièmement, il n'est pas clair sur quel thread ce rappel sera appelé - nous n'avons aucun contrôle sur l'appel. Quatrièmement, la question se pose, comment combiner des morceaux de code avec des rappels? Le deuxième modèle est appelé modèle asynchrone basé sur les événements. Il s'agit d'une approche de rappel réactif. L'idée de la méthode est que nous passons à la méthode
Le deuxième modèle est appelé modèle asynchrone basé sur les événements. Il s'agit d'une approche de rappel réactif. L'idée de la méthode est que nous passons à la méthode OperationNameAsyncun objet qui a l'événement Completed et que nous nous abonnions à cet événement. Comme vous l'avez remarqué, les BeginOperationNamemodifications sont apportées à OperationNameAsync. Une confusion peut se produire lorsque vous entrez dans la classe Socket, où deux modèles sont mélangés: ConnectAsyncet BeginConnect.Veuillez noter que vous devez appeler pour annuler OperationNameAsyncCancel. Comme dans .NET, cela ne se trouve nulle part ailleurs, généralement tout le monde envoie des CancellationToken s . Ainsi, si vous rencontrez accidentellement une méthode dans la bibliothèque qui se termine par Async, vous devez comprendre qu'elle ne retourne pas nécessairement Task, mais peut renvoyer une construction similaire. Considérez un modèle connu sous Java commeFutures , en JavaScript, en tant que promesses et en .NET, en tant que modèles asynchrones de tâches , en d'autres termes, «tâches». Cette méthode suppose que vous disposez d'un objet de calcul et que vous pouvez voir l'état de cet objet (en cours d'exécution ou terminé). Dans .NET, il existe une soi-disant
Considérez un modèle connu sous Java commeFutures , en JavaScript, en tant que promesses et en .NET, en tant que modèles asynchrones de tâches , en d'autres termes, «tâches». Cette méthode suppose que vous disposez d'un objet de calcul et que vous pouvez voir l'état de cet objet (en cours d'exécution ou terminé). Dans .NET, il existe une soi-disant RnToCompletionséparation pratique de deux états: le début de la tâche et l'achèvement de la tâche. Une erreur courante se produit lorsqu'une méthode est appelée sur une tâche IsCompletedqui renvoie une continuation non réussie, mais RnToCompletion, Canceledet Faulted. Ainsi, le résultat du clic sur «Annuler» dans l'application d'interface utilisateur devrait différer du retour d'exceptions (exécutions). Dans .NET, une distinction a été faite: si l'exécution est votre erreur que vous souhaitez sécuriser, alors Annuler- opération forcée.Dans .NET, un concept a également été introduit TaskScheduler- c'est une sorte d'abstraction au-dessus des threads qui indique où exécuter la tâche. Dans ce cas, le support d'annulation a été conçu au niveau de la conception. Presque toutes les opérations de la bibliothèque en .NET CancellationTokenpeuvent être passées. Cela ne fonctionne pas pour toutes les langues: par exemple, dans Kotlin, vous pouvez annuler la tâche, mais pas dans .NET. La solution peut être la répartition des responsabilités entre ceux qui annulent la tâche et la tâche elle-même. Lorsque vous recevez une tâche, vous ne pouvez pas l'annuler autrement qu'explicitement - vous devez la transmettre CancellationToken.Un objet spécial TaskCompletionSourevous permet d'adapter facilement les anciennes API associées au modèle asynchrone basé sur les événements ou au modèle de programmation asynchrone. Il y a un document que vous devez lire si vous programmez des tâches. Il décrit tous les accords concernant les tasas. Par exemple, toute méthode renvoyant la tâche doit la retourner dans un état en cours d'exécution, ce qui signifie qu'elle ne peut pas l'être Created, alors que toutes ces opérations doivent se terminer Async.Combiner les suites
Task ourMethod() {
return Task.RunSynchronously(() =>{
...
})
.ContinueWith(_ =>{
Foo();
})
.ContinueWith(_ =>{
Bar();
})
.ContinueWith(_ =>{
Baz();
})
}
Quant à la combinaison, compte tenu de l' enfer du rappel , elle peut apparaître sous une forme plus linéaire, malgré la présence de morceaux de code répétitif avec des changements minimes. Il semble que le code s'améliore de cette façon, mais il y a aussi des pièges ici.Démarrer et continuer les tâches
Task.Factory.StartNew(Action,
TaskCreationOptions,
TaskScheduler,
CancellationToken
)
Task.ContinueWith(Action<Task>,
TaskContinuationOptions,
TaskScheduler,
CancellationToken
)
Passons à trois paramètres lors du lancement de la tâche standard: les premiers sont les options de démarrage de la tâche, le second est schedulercelui sur lequel la tâche est lancée, et le troisième - CancellationToken. TaskScheduler indique où commence la tâche et est un objet que vous pouvez remplacer indépendamment. Par exemple, vous pouvez remplacer une méthode
TaskScheduler indique où commence la tâche et est un objet que vous pouvez remplacer indépendamment. Par exemple, vous pouvez remplacer une méthode Queue. Si vous le faites TaskSchedulerpour thread pool, la méthode Queueprend un thread thread poolet y envoie votre tâche.Si vous reprenez schedulerle thread principal, il place tout dans une file d'attente et les tâches sont exécutées séquentiellement sur le thread principal. Cependant, le problème est que dans .NET, vous pouvez exécuter une tâche sans passer TaskScheduler. La question se pose: comment alors .NET calcule-t-il la tâche qui lui a été transmise? Quand la tâche commence à l' StartNewintérieurAction, ThreadStatic. Currentexposé dans celui TaskSchedulerque nous lui avons donné.Cette conception semble plutôt controversée en raison du contexte implicite. Il y avait des cas où il TaskSchedulercontenait du code asynchrone qui héritait quelque part très profondément TaskScheduler.Currentet se chevauchait avec un autre ordonnanceur, ce qui entraînait des blocages. Dans ce cas, vous pouvez utiliser l'option TaskCreationOption.HideScheduler. Il s'agit d'une sonnette d'alarme qui indique que nous avons une option qui remplace le ThreadStaticparamètre.Tout est pareil avec les suites. La question se pose: d'où vient-elle TaskSchedulerpour les suites? Tout d'abord, il est pris dans la méthode dans laquelle vous avez commencé Continuation. Il est également TaskSchedulerextrait de ThreadStatic. Il est important que pour async / wait, les suites fonctionnent très différemment. Nous passons aux paramètres
Nous passons aux paramètres TaskCreationOptionset TaskContinuationOptions. Leur principal problème est qu'il y en a beaucoup. Certains de ces paramètres s'annulent, certains s'excluent mutuellement. Tous ces paramètres peuvent être utilisés dans toutes les combinaisons possibles, il est donc difficile de garder à l'esprit tout ce qui peut arriver avec le désir. Certaines de ces options fonctionnent de manière totalement incompréhensible. Par exemple, les paramètres
Par exemple, les paramètres ExecuteSynchronouslyet RunContinuationsAsynchronouslyreprésentent deux options d'application possibles, mais le fait que la poursuite soit lancée de manière synchrone ou asynchrone dépend de tant de choses que vous ignorez. Un autre exemple: nous avons lancé la tâche, lancé la continuation et donné simultanément deux paramètres
Un autre exemple: nous avons lancé la tâche, lancé la continuation et donné simultanément deux paramètresTaskContinuations.ExecuteSynchronously, après quoi ils ont commencé la suite de manière asynchrone. Sera-t-il exécuté dans la même pile où la tâche précédente se termine, ou sera-t-il transféré thread pool? Dans ce cas, il y aura une troisième option: cela dépend.
TaskCompletionSource
Considérez TaskCompletionSource. Lorsque vous créez une tâche, vous définissez son résultat SetResultpour adapter les modèles asynchrones précédents au monde de la tâche. Vous TaskCompletionSourcepouvez demander tcs.Task, et cette tâche entrera dans un état finishlorsque vous appelez tcs.SetResult. Cependant, si vous exécutez cela sur le pool de threads , vous obtiendrez un blocage . La question est, pourquoi si nous n’écrivions rien, même de manière synchrone? Nous créons
Nous créons TaskCompletionSource, commençons une nouvelle tâche et nous avons un deuxième thread qui démarre quelque chose dans cette tâche. Il va plus loin et tombe dans l'attente pour une centaine de millisecondes. Ensuite, notre fil principal - vert - attend et c'est tout. Il libère la pile, la pile se bloque, attendant d'être appelée dans une suite surtask.Waitlorsqu'il est tcsexposé.Dans le fil bleu, nous arrivons à tcs, puis le plus intéressant. Sur la base de considérations internes à .NET, il TaskCompletionSourcepense que la poursuite de cela tcspeut être effectuée de manière synchrone, c'est-à-dire directement sur la même pile, puis cela task.Waitest effectué de manière synchrone sur la même pile. C'est très étrange, malgré le fait que nous n'avons même écrit nulle part ExecuteSynchronously. C'est probablement le problème avec le mélange de code synchrone et asynchrone. Un autre problème avec cela
Un autre problème avec cela TaskCompletionSourceest que lorsque nous appelons SetResultsous le verrou , vous ne pouvez pas appeler de code arbitraire, car sous le verrou, vous ne pouvez faire qu'une petite activité granulaire. Courez sous certaines actions, il est impossible de venir d'où ils viennent. Comment résoudre ce problème?var tcs = new TaskCompletionSource<int>(
TaskContinuationsOptions.RunContinuationsAsynchronously
) ;
lock(mylock)
{
tcs.SetResult(O);
});
Cela TaskCompletionSourcevaut la peine d'être utilisé uniquement pour l'adaptation du code non Task dans les bibliothèques. Presque tout le reste peut être résolu en attendant. Dans ce cas, il est toujours fortement recommandé de prescrire le paramètre "TaskCompletionSource.RunContinuationsAsynchronously" . Vous devez presque toujours exécuter une continuation de manière asynchrone. Dans ce cas, vous tcs.SetResultavez quelque chose sous lequel rien ne sera lancé. Pourquoi la poursuite doit-elle être effectuée de manière synchrone? Parce qu'il
Pourquoi la poursuite doit-elle être effectuée de manière synchrone? Parce qu'il RunContinuationsAsynchronouslyfait référence aux éléments suivants ContinueWith, et non aux nôtres. Pour établir un lien avec le nôtre, vous devez écrire ce qui suit: Cet exemple montre comment les paramètres ne sont pas intuitifs, comment ils se croisent les uns avec les autres, comment ils introduisent une complexité cognitive - c'est si difficile à écrire.
Cet exemple montre comment les paramètres ne sont pas intuitifs, comment ils se croisent les uns avec les autres, comment ils introduisent une complexité cognitive - c'est si difficile à écrire.Hiérarchie parent-enfant
Task.Factory.StartNew(() =>
{
Task.Factory.StartNew(() => {
})
})
.ContinueWith(...)
Il existe d'autres options d'utilisation des paramètres. Par exemple, une hiérarchie parent-enfant apparaît lorsque vous lancez une tâche et en exécutez une autre sous celle-ci. Dans ce cas, si vous écrivez ContinueWith, vous ContinueWithn'attendrez pas la tâche lancée à l'intérieur.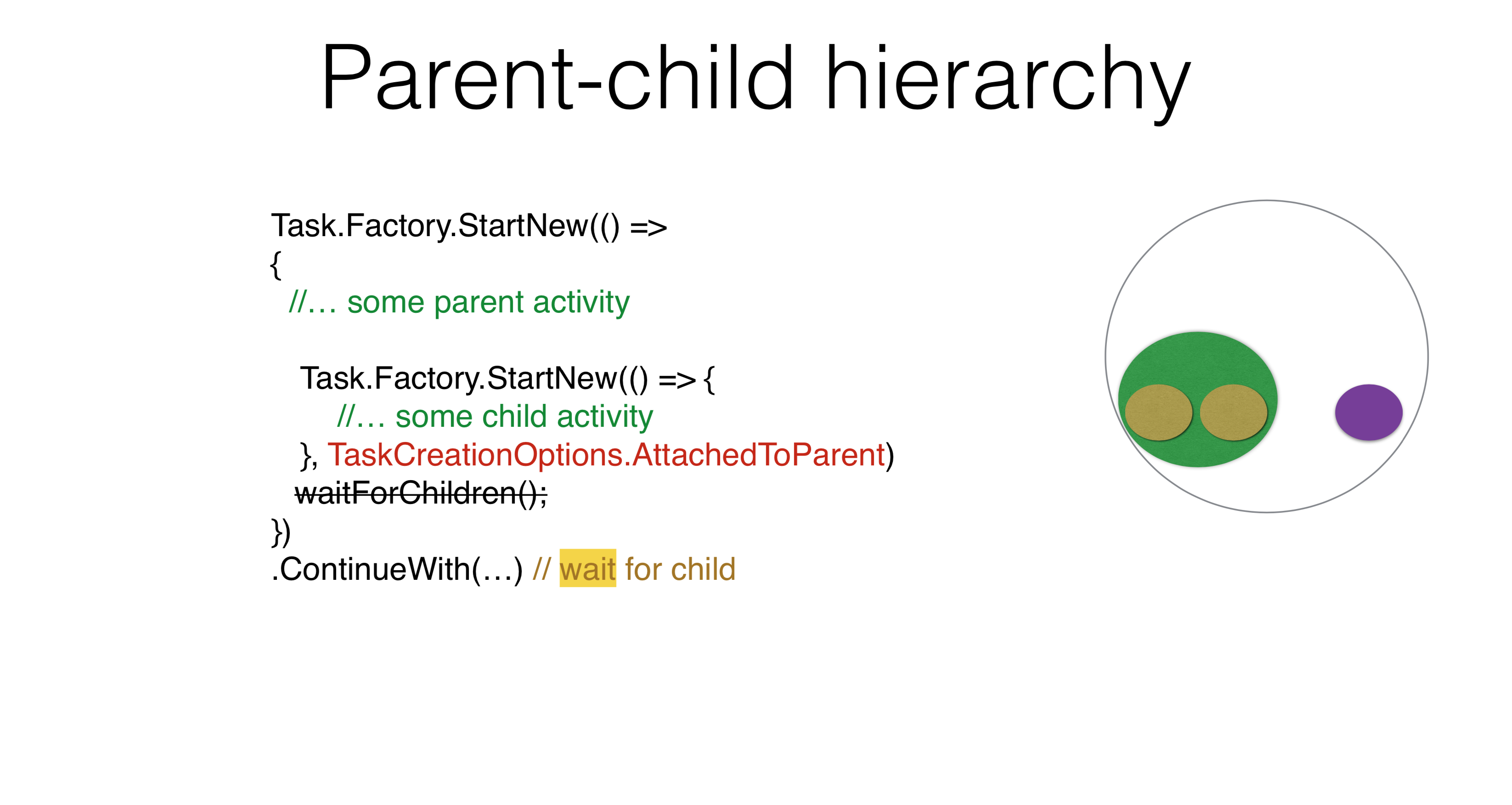 Si vous écrivez
Si vous écrivez TaskCreationOptions.AttachedToParent, cela ContinueWithattendra. Vous pouvez utiliser cette propriété dans vos produits. Je pense que tout le monde peut trouver un exemple dans lequel il y a une hiérarchie de tâches, la tâche attendant la sous-tâche et la sous-tâche pour ses sous-tâches. Pas besoin d'écrire n'importe où WaitForChildren, cette attente se produit de manière asynchrone. En d'autres termes, le corps de la tâche parent se termine et, après cela, la tâche parent n'est pas considérée comme terminée, ne démarre pas ses continuations tant que les tâches enfants ne fonctionnent pas.Task.Factory.StartNew(() =>
{
Foo();
})
.ContinueWith(...)
void Foo() {
Task.Factory.StartNew(() => {
}, TaskCreationOptions.AttachedToParent);
}
Il peut y avoir un problème dans lequel la tâche est transférée quelque part ThreadStatic, puis tout ce que vous avez commencé AttachedToParentsera ajouté à cette tâche parent, qui est une alarme.Task.Factory.StartNew(() =>
{
Foo();
}, TaskCreationOptions.DenyChildAttach)
.ContinueWith(...)
void Foo() {
Task.Factory.StartNew(() => {
}, TaskCreationOptions.AttachedToParent);
}
D'un autre côté, il existe une option qui annule l'option précédente DenyChildAttach. Une telle application se produit assez souvent.Task.Run(() =>
{
Foo();
})
.ContinueWith(...)
void Foo() {
Task.Factory.StartNew(() => {
}, TaskCreationOptions.AttachedToParent);
}
Il convient de rappeler que Task.Runc'est la façon standard de démarrer, ce qui implique par défaut DenyChildAttach.Le contexte implicite que vous mettez vous ThreadStaticajoute de la complexité. Vous ne comprenez pas comment fonctionne la tâche, car vous devez connaître le contexte. Un autre problème qui peut survenir est lié à l'état inactif de async / wait. C'est parce que dans async / attendent, vous n'avez pas de tâches, mais des actions. La poursuite n'est pas une tâche honnête, mais une action. Lorsque vous écrivez du code asynchrone / attendent, vous n'avez pas besoin de l'utiliser AttachedToParent, car vous liez explicitement les tâches à attendre, et c'est la bonne approche. Vous avez six options pour démarrer une continuation. Vous avez lancé la tâche, lancé
Vous avez six options pour démarrer une continuation. Vous avez lancé la tâche, lancéContinueWith. Question: Quel statut aura cette continuation? Il y a cinq réponses possibles:- la poursuite générale se terminera avec succès; RunToCompletion se produira;
- la tâche sera erronée;
- l'annulation aura lieu;
- la tâche n'atteindra pas son terme du tout, elle sera dans une sorte de vide;
- option - "dépend".
 Dans ce cas, la tâche sera dans l'état «annulé», bien que nulle part le mot «annulé» ne soit mentionné. Ici, nous jetons la réception et ne faisons rien. Le problème est que lorsque vous lisez le code de quelqu'un d'autre avec beaucoup d'options - même si vous connaissiez ces options il y a 10 minutes - vous oubliez toujours ce qui se passe ici. Alors n'écrivez pas.
Dans ce cas, la tâche sera dans l'état «annulé», bien que nulle part le mot «annulé» ne soit mentionné. Ici, nous jetons la réception et ne faisons rien. Le problème est que lorsque vous lisez le code de quelqu'un d'autre avec beaucoup d'options - même si vous connaissiez ces options il y a 10 minutes - vous oubliez toujours ce qui se passe ici. Alors n'écrivez pas.Annulation
Task.Factory.StartNew(() =>
{
throw new OperationCanceledException();
});
Failed
Le troisième paramètre au début de la tâche est la kancellation. Vous écrivez OperationCanceledException, c'est-à-dire une action spéciale qui met la tâche à l'état «Annulé». Dans ce cas, la tâche sera dans l'état "Échec", car tous ne OperationCanceledExceptionsont pas égaux.Task.Factory.StartNew(() =>
{
throw new OperationCanceledException(cancellationToken);
}, cancellationToken);
Canceled
Pour que la tâche soit en mesure de le faire Canceled, vous devez la jeter OperationCanceledExceptionavec son CancellationToken. En réalité, vous ne faites jamais explicitement cela, mais faites-le de cette façon:Task.Factory.StartNew(() =>
{
cancellationToken.ThrowIfCancellationRequested();
}, cancellationToken);
Canceled
Est-il nécessaire de distinguer CancellationToken? Quelque part à l'intérieur de la tâche, vous vérifiez que quelqu'un vous a supprimé: annulation du lancer, puis la tâche passe à l'état Canceled. Ou quelqu'un a cliqué sur «Annuler» au moment de l'exécution et a annulé la tâche. Notre pratique chez JetBrains suggère que vous n'avez pas besoin de faire la distinction entre ces jetons. Si vous obtenez une OperationCanceledException - un type spécial qui se produit lorsqu'une annulation s'est produite, vous pouvez la distinguer. Dans ce cas, il vous suffit de terminer la tâche normalement, de ne pas vous connecter et lorsque vous recevez l'exécution - connectez-vous.Pile profonde
Task.Factory.StartNew(() =>
{
Foo();
}, cancellationToken);
void Foo() {
Bar() {
...
Baz() {
}
}
}
Disons que vous avez une pile profonde. C'est CancellationTokenle seul paramètre explicite dont nous avons discuté. Elle doit être transmise partout dans absolument toutes les hiérarchies. Que dois-je faire si, en présence d'une hiérarchie profonde, vous devez annuler votre tâche quelque part, au niveau le plus bas, pour rejeter la réception? Il y a une astuce si spéciale que nous utilisons. Il est appelé AsyncLocal.static AsyncLocal<Cancelation> asyncLocalCancellation;
Task.Factory.StartNew(() =>
{
asyncLocalCancellation.Set(cancellationToken)
Foo();
}, cancellationToken);
void Foo() {
async Bar() {
...
Baz() {
asyncLocalCancellation.Value.CheckForInterrupt();
}
}
}
C'est la même chose que, ThreadStaticseul celui spécial ThreadLocalqui survit aux trajets de code asynchrone / attente. Étant donné que votre code est asynchrone et que vous avez cette annulation, vous l'avez insérée AsyncLocal, et quelque part à un niveau profond, vous pouvez dire " CheckForInterrupt Throw If Cancellation Requested". Encore une fois, c'est le seul paramètre CancellationTokenqui doit complètement enduire le code entier, mais, à mon avis, pour la plupart des tâches, vous avez juste besoin de savoir ce qui s'est passé OperationCanceledException, et de cela en tirer une conclusion qui indique: Annulé ou Échoué.Complexité cognitive
Task.Factory.StartNew(Action,
TaskCreationOptions,
TaskScheduler,
CancellationToken
)
JetBrains.Lifetimes
lifetime.Start(TaskScheduler, Action)
lifetime.StartMainRead(Action)
lifetime.StartMainWrite(TaskScheduler, Action)
lifetime.StartBackgroundRead(TaskScheduler, Action)
Plus le code est difficile à lire lors du démarrage de la tâche, plus le risque d'erreur est élevé. En regardant le code après un an, vous oublierez ce qu'il fait, car il y a un grand nombre de paramètres. Mais nous avons la bibliothèque JetBrains.Lifetimes , qui offre des durées de vie modernes, un CancellationToken bien optimisé, avec lequel la méthode Start a été réécrite et le problème avec la répétition de morceaux de code a été résolu, comme avec Task.Factory.StartNewet TaskCreationOptions.Il existe un petit nombre de planificateurs qui vous permettent de planifier une tâche sur le thread principal avec un verrou en lecture. Autrement dit, le verrou de lecture n'est pas quelque chose que vous choisissez explicitement, c'est un planificateur spécial qui planifie votre code sur le thread principal avec un verrou de lecture, ainsi que le thread principal avec verrouillage en écriture, le thread d'arrière-plan - et maintenant les méthodes deviennent très simples pour démarrer la lecture aléatoire. Dans le même temps, les durées de vie s'annulent automatiquement AsyncLocal, ce qui simplifie considérablement le code. Voyons comment async / wait résout ces problèmes et quels problèmes ils introduisent.Dans cet exemple, une partie du code est exécutée de manière synchrone, puis attend et code asynchrone. Premièrement, il est bon qu’il y ait beaucoup moins de morceaux de code répétitifs ( plaque de chaudière ). Deuxièmement, il est bon que le code asynchrone soit très similaire au code synchrone, c'est exactement à cela que sert async / attente . Vous pouvez écrire de manière asynchrone de la même manière que vous avez écrit de manière synchrone, sans prendre de threads.Dans ce cas, que déploiera le compilateur? Le code synchrone s'exécutera de manière synchrone, après quoi la tâche s'exécutera de manière synchrone
Voyons comment async / wait résout ces problèmes et quels problèmes ils introduisent.Dans cet exemple, une partie du code est exécutée de manière synchrone, puis attend et code asynchrone. Premièrement, il est bon qu’il y ait beaucoup moins de morceaux de code répétitifs ( plaque de chaudière ). Deuxièmement, il est bon que le code asynchrone soit très similaire au code synchrone, c'est exactement à cela que sert async / attente . Vous pouvez écrire de manière asynchrone de la même manière que vous avez écrit de manière synchrone, sans prendre de threads.Dans ce cas, que déploiera le compilateur? Le code synchrone s'exécutera de manière synchrone, après quoi la tâche s'exécutera de manière synchrone InnerAsync, d'où vient l'objet GetAwaiter spécial. Dans ce cas, nous sommes intéressés TaskAwaiter. Vous pouvez écrire votre serveur pour absolument n'importe quel objet. Par conséquent, nous attendons que la tâche soit terminée InnerAsyncet exécutée de manière synchrone continuationCode. Si la tâche ne s'est pas terminée, alors continuationCode est planifié sur le planificateur de contexte . Il se peut que, même si vous avez écrit attendre , absolument tout sera appelé de manière synchrone.async Task MyFuncAsync() {
synchronousCode();
await InnerAsync();
await Task.Yield();
continuationCode();
}
Il y a une astuce Task.Yield- c'est une tâche spéciale qui garantit que son serveur ne vous reviendra pas toujours IsCompleted. Par conséquent, continuationil ne sera pas appelé de manière synchrone à cet endroit. Pour un thread d'interface utilisateur, cela peut être important car vous ne prenez pas ce thread pendant une longue période. Comment choisir un fil pour la suite? La philosophie asynchrone / attendre est la suivante: vous écrivez du code asynchrone de la même manière que synchrone. Si vous avez un pool de threads , cela ne fait aucune différence pour vous - continuationCode sera exécuté sur un autre thread. Indépendamment du fait qu'elle ait été
Comment choisir un fil pour la suite? La philosophie asynchrone / attendre est la suivante: vous écrivez du code asynchrone de la même manière que synchrone. Si vous avez un pool de threads , cela ne fait aucune différence pour vous - continuationCode sera exécuté sur un autre thread. Indépendamment du fait qu'elle ait été InnerAsyncterminée lorsque vous avez dit attendre ou non, vous avez besoin de tout pour exécuter sur le thread d'interface utilisateur.Le mécanisme de tâche en attente est le suivant: il est pris static, il est appeléSynchronizationContextet à partir de là est créé TaskScheduler. SynchronizationContext est une chose avec la méthode Post, qui est très similaire à la méthode Queue. En fait TaskScheduler, ce qui était plus tôt, il prend simplement SynchronizationContextet à travers Post effectue sa tâche.async Task MyFuncAsync() {
synchronousCode();
await InnerAsync().ConfigureAwait(false);
continuationCode();
}
Il existe un moyen de modifier ce comportement à l'aide d'un paramètre ContinueOnCapturedContext. L'API la plus dégoûtante de .NET est appelée ConfigureAwait. Dans ce cas, l'API crée un serveur d'attente spécial, différent de TaskAwaitercelui qui décale la suite, il s'exécute sur le même thread, dans le même contexte dans lequel la méthode s'est terminée InnerAsync et où la tâche s'est terminée.async Task MyFuncAsync() {
synchronousCode();
await InnerAsync().ConfigureAwait(continueOnCapturedContext: false);
continuationCode();
}
Il y a une quantité insensée de conseils sur Internet: si vous avez un blocage , veuillez salir tout votre code ConfigureAwait et tout ira bien. C'est la mauvaise façon. ConfigureAwaitpeut être utilisé dans les cas où vous souhaitez améliorer légèrement les performances, ou à la fin de la méthode, dans certaines méthodes de bibliothèque.Deadlocks
async Task MyFuncAsync() {
synchronousCode();
await Task.Delay(10).ConfigureAwait(continueOnCapturedContext: false);
continuationCode();
}
myFuncAsync().Wait()
Il s'agit d'une impasse classique . Sur le thread d'interface utilisateur, ils ont attendu dix secondes et l'ont fait Wait. En raison de ce que vous avez fait Wait, il continuationCodene sera jamais lancé, il Waitne reviendra donc jamais. Tout cela a lieu au tout début.async Task OnBluttionClick() {
int v = Button.Text.ParseInt();
await Task.Delay(10).ConfigureAwait(continueOnCapturedContext: false);
Button.Text.Set((v+1).ToString());
}
myFuncAsync().Wait()
Imaginez qu'il s'agit d'une véritable activité. Nous avons cliqué sur le bouton, l'avons pris Button.ParseInt, fait attendre , écrit ConfigureAwaitNous avons dit: "Veuillez ne pas fermer notre flux d'interface utilisateur, effectuez la suite." Le problème est que nous voulons que la deuxième partie après soit ConfigureAwaitégalement exécutée sur le thread d'interface utilisateur, car c'est la philosophie de l' attente . Autrement dit, votre code asynchrone ressemble au code synchrone et s'exécute dans le même contexte. Dans ce cas, bien sûr, il y aura une erreur. De plus, Button.Text.Setil peut y avoir un certain nombre d'appels de méthode qui prennent également en compte leur contexte. que-faire dans cette situation? Tu peux le faire:async Task MyFuncAsync() {
synchronousCode();
await Task.Delay(10).ConfigureAwait(continueOnCapturedContext: false);
continuationCode();
}
PumpUntil(() => task.IsCompleted);
Avec un thread d'interface utilisateur, vous devez interdire de le faire Waitsur les threads qui ont une file d'attente de messages commune. Au lieu de faire Waitou d'écrire ConfigureAwait, vous pouvez pomper cette file d'attente de messages, et en même temps, le continuum sera également pompé. Si vous ne pouvez pas mélanger du code synchrone et asynchrone, vous ne devez pas les mélanger. Mais parfois, cela ne peut être évité.Par exemple, vous avez un ancien code, et vous devez les mélanger, puis vous pompez le flux d'interface utilisateur. Visual Studio pompe le fil de l'interface utilisateur sur les attentes, il a même SynchronizationContextun peu changé. Si vous accédez à WaitHandle sur l'un d'eux Wait, lorsque vous raccrochez, votre flux d'interface utilisateur est pompé. Ainsi, ils choisissent entre les blocages et les races en faveur de la race s.Pumpuntil- Il s'agit d'une API non idéale, c'est-à-dire que lorsque vous effectuez une continuité aléatoire dans un endroit arbitraire, il peut y avoir des nuances. Il n'y a malheureusement pas d'autre moyen. Mélangez les codes synchrones et asynchrones. Si quoi que ce soit, l'ensemble du Rider est ainsi arrangé dans les anciens endroits, donc parfois il y a aussi des nuances.Changer le contexte
async Task MyFuncAsync() {
synchronousCode();
await myTaskScheduler;
continuationCode();
}
Il existe une autre façon intéressante d'utiliser async / wait . Vous pouvez écrire Awaitersur scheduleret sauter sur les filets. J'ai lu des articles dans Visual Studio, ils ont écrit pendant très longtemps qu'il n'était pas bon de faire des allers-retours au milieu de la méthode, mais maintenant ils le font eux-mêmes. Visual Studio possède une API qui saute sur les threads via les planificateurs. Pour une utilisation normale, ce n'est pas bon.Concurrence structurée
async Task MyFuncAsync() {
synchronousCode();
await Task.Factory.StartNew(() => {...}, myTaskScheduler);
continuationCode();
}
Pour une immersion pratique dans le nouveau contexte et un retour à l'ancien, une certaine concurrence structurelle, ou parallélisme structurel, devrait être établie. Par exemple, dans les années 60, l'opérateur GoTo était considéré comme nuisible car il violait la structure. C'est donc ici. Sauter sur les fils viole la structure. Étonnamment, l'utilisation d'une machine d'état asynchrone semble être une bonne solution. Autrement dit, lorsque votre structure habituelle est violée, vous sautez sur GoTo, vous pouvez violer la structure des threads: attendez , mélangez -la avec des balises. Il s'agit d'une situation extrêmement étrange et rare lorsque vous devez le faire. Pourtant, c'est mieux quand attendre revient dans le même contexte. Ainsi, le pool de threads n'aura pas le même thread, mais le même contexte qu'il était à l'origine.Comportement séquentiel
Pourquoi attendre n'est-il pas la même chose que l'exécution parallèle? Attendre l'exécution est une exécution séquentielle. Dans ce cas, nous commençons la première tâche, l'attendons, démarrons la deuxième tâche - nous attendons. Nous n'avons aucun parallélisme. Pour la plupart des utilisations, le parallélisme n'est pas nécessaire. Le parallélisme lui-même est plus complexe que la séquence. Le code série est plus simple que parallèle, c'est un axiome. Mais parfois, vous devez exécuter quelque chose en code parallèle, et vous le faites comme ceci:async Task MyAsync() {
var task1 = StartTask1Async();
await task1;
var task2 = StartTask2Async();
await task2;
}
Comportement simultané
async Task MyAsync() {
var task1 = StartTask1Async();
var task2 = StartTask2Async();
await task1;
await task2;
}
Ici, les tâches commencent en parallèle. Il est clair que les méthodes peuvent renvoyer la tâche immédiatement dans un état en cours d'exécution, il n'y aura donc pas de parallélisme. Disons que les deux lancent une exécution. Et vous avez attendu la première tâche, puis la première attente a décollé. Autrement dit, dès que vous avez écrit await task1, vous avez décollé et n'avez pas traité exception task2. Fait intéressant, il s'agit d'un code absolument valide. Et c'est ce code qui a conduit .NET au fait que dans la version 4.5, le comportement de travail avec les exécutions a changé.Gestion des exceptions
async Task MyAsync() {
var task1 = StartTask1Async();
var task2 = StartTask2Async();
await task1;
await task2;
}
Auparavant, les exécutions non gérées jetaient simplement le processus, et si vous n’avez pas détecté d’exécution UnobservedExceptionHandler( staticvous pouvez également en attacher certaines à des planificateurs), ce processus n’a pas été exécuté. Maintenant, c'est un code absolument valide. Bien que .NET ait modifié son comportement, il a conservé le paramètre pour renvoyer le comportement dans la direction opposée.async Task MyAsync(CancellationToken cancellationToken) {
await SomeTask1 Async(cancellationToken);
await Some Task2Async( cancellation Token);
}
try {
await MyAsync( cancellation Token);
} catch (OperationException e) {
} catch (Exception e) {
log.Error(e);
}
Voyez comment se déroule le traitement de l'exécution. Les CancellationToken-s doivent être transmis, il faut "enduire" CancellationToken-s de tout le code. Le comportement normal d'Async est que vous ne vérifiez nulle part Task.Status ancellationToken, vous travaillez avec du code asynchrone de la même manière qu'avec Synchrone. Autrement dit, dans le cas d'une annulation, vous obtenez une exécution, et dans ce cas, vous ne faites rien lorsque vous la recevez OperationCanceledException.La différence entre le statut Annulé et En panne est que vous n'avez pas reçu OperationCanceledException, mais l'exécution habituelle. Et dans ce cas, nous pouvons le promettre, il vous suffit d'obtenir une exécution et de tirer des conclusions sur cette base. Si vous aviez démarré la tâche explicitement, via Task, vous auriez volé AggregateException. Et en async, dans le cas où ils AggregateExceptionlancent toujours la toute première exécution qui s'y trouvait (dans ce cas - OperationCanceled).En pratique
Méthode synchrone
DataTable<File, ProcessedFile> sharedMemory;
void SynchronousWorker(...) {
File f = blockingQueue.Dequeue();
ProcessedFile p = ProcessInParallel(f);
lock (_lock) {
sharedMemory.add(f, p);
}
}
Par exemple, un démon fonctionne dans ReSharper - un éditeur qui teinte le fichier pour vous. Si le fichier est ouvert dans l'éditeur, une activité le place dans une file d'attente de blocage. Notre processus workerlit à partir de là, après quoi il effectue un tas de tâches différentes avec ce fichier, le teint, analyse, construit, après quoi ces fichiers sont ajoutés sharedMemory. Avec un sharedMemoryverrou, d'autres mécanismes fonctionnent déjà avec lui.Méthode asynchrone
Lors de la réécriture du code en asynchrone, nous le remplacerons tout d'abord voidpar async Task. Assurez-vous d'écrire le mot «Async» à la fin. Toutes les méthodes asynchrones doivent se terminer par Async - c'est une convention.DataTable<File, ProcessedFile> sharedMemory;
async Task WorkerAsync(...) {
File f = blockingQueue.Dequeue();
ProcessedFile p = ProcessInParallel(f);
lock (_lock) {
sharedMemory.add(f, p);
}
}
Après cela, vous devez faire quelque chose avec le nôtre blockingQueue. De toute évidence, s'il existe une primitive synchrone, il doit y avoir une primitive asynchrone. Cette primitive est appelée canal: les canaux qui vivent dans le package
Cette primitive est appelée canal: les canaux qui vivent dans le package System.Threading.Channels. Vous pouvez créer des canaux et des files d'attente, limités et illimités, que vous pouvez attendre de manière asynchrone. De plus, vous pouvez créer un canal avec une valeur "zéro", c'est-à-dire qu'il n'aura pas du tout de tampon. Ces canaux sont appelés canaux de rendez-vous et sont activement promus à Go et Kotlin. Et en principe, s'il est possible d'utiliser des canaux en code asynchrone, c'est un très bon schéma. Autrement dit, nous changeons la file d'attente pour le canal où il existe des méthodes ReadAsyncet WriteAsync.ProcessInParallel est un tas de code parallèle qui fait le traitement d'un fichier et le transforme enProcessedFile. L'async peut-il nous aider à écrire un code non asynchrone, mais parallèle plus compact?Simplifiez le code parallèle
Le code peut être réécrit de cette façon:DataTable<File, ProcessedFile> sharedMemory;
async Task WorkerAsync(...) {
File f = await channel.ReadAsync();
ProcessedFile p = await ProcessInParallelAsync(f);
lock (_lock) {
sharedMemory.add(f, p);
}
}
 À quoi ressemblent-ils
À quoi ressemblent-ils ProcessInParallel? Par exemple, nous avons un fichier. Tout d'abord, nous le décomposons en lexèmes, et nous pouvons avoir deux tâches en parallèle: construire des caches de recherche et construire un arbre de syntaxe. Après cela vient la tâche de «rechercher les erreurs sémantiques». Il est important ici que toutes ces tâches forment un graphe acyclique dirigé. Autrement dit, vous pouvez exécuter certaines parties dans des threads parallèles, d'autres non, et il existe évidemment des dépendances qui doivent attendre d'autres tâches. Vous obtenez un graphique de ces tâches, vous voulez en quelque sorte les disperser le long des fils. Est-il possible de l'écrire magnifiquement, sans erreurs? Dans notre code, ce problème a été résolu plusieurs fois, à chaque fois d'une manière différente. Cela se produit rarement lorsque ce code est écrit sans erreur. Nous définissons ce graphique de tâches comme suit: disons que chaque tâche a d'autres tâches dont elle dépend, puis en utilisant le dictionnaire ExecuteBefore nous écrivons le squelette de notre méthode.
Nous définissons ce graphique de tâches comme suit: disons que chaque tâche a d'autres tâches dont elle dépend, puis en utilisant le dictionnaire ExecuteBefore nous écrivons le squelette de notre méthode.Solutions squelettes
Dictionary<Action<ProcessedFile>, Action<ProcessedFile>[]> ExecuteBefore; async Task<ProcessedFile> ProcessInParallelAsync() {
var res = new ProcessedFile();
return res;
}
Si vous résolvez ce problème de front, vous devez effectuer un tri topologique de ce graphique. Prenez ensuite une tâche qui n'a pas de tâches dépendantes, exécutez-la, analysez la structure sous un verrou, voyez quelles tâches n'en ont pas. Courez, dispersez-les d'une manière ou d'une autre Task Runner. Nous l'écrivons un peu plus compact: tri topologique du graphe + exécution de telles tâches sur différents threads.Async paresseux
Dictionary<Action<ProcessedFile>, Action<ProcessedFile>[]> ExecuteBefore;
async Task<ProcessedFile> ProcessInParallelAsync() {
var res = new ProcessedFile();
var lazy = new Dictionary<Action<ProcessedFile>, Lazy<Task>>();
foreach ((action, beforeList) in ExecuteBefore)
lazy[action] = new Lazy<Task>(async () =>
{
await Task.WhenAll(beforeList.Select(b => lazy[b].Value))
await Task.Yield();
action(res);
}
await Task.WhenAll(lazy.Values.Select(l => l.Value))
return res;
}
Il y a un modèle appelé Async Lazy. Nous créons les nôtres ProcessedFilesur lesquelles différentes actions doivent être exécutées. Créons un dictionnaire: nous allons formater chacune de nos étapes (Action ProcessedFile) dans une tâche, ou plutôt dans Lazy from Task et parcourir le graphique d'origine. La variable actionaura l' action elle - même , et dans beforeList - les actions qui doivent être effectuées avant la nôtre. Créez ensuite à Lazypartir de action. Nous écrivons dans Task await. Ainsi, nous attendons toutes les tâches qui doivent être accomplies avant lui. Dans beforeList, sélectionnez celui Lazyqui se trouve dans ce dictionnaire.Veuillez noter qu'ici, rien ne sera exécuté de manière synchrone, donc ce code ne tombera pas ItemNotFoundException in Dictionary. Nous réalisons toutes les tâches qui étaient avant les nôtres, effectuant une recherche par actionLazy Task. Ensuite, nous exécutons notre action. En fin de compte, il vous suffit de demander à chaque tâche de démarrer, sinon vous ne savez jamais si quelque chose n'a pas commencé. Dans ce cas, rien n'a commencé. Voilà la solution. Cette méthode est écrite en 10 minutes, c'est absolument évident.Ainsi, le code asynchrone a pris notre décision, il occupait initialement quelques écrans avec un code concurrentiel complexe. Ici, il est absolument cohérent. Je ne l'utilise même pas ConcurrentDictionary, j'utilise l'habituel Dictionary, car nous n'y écrivons rien de manière compétitive. Il existe un code cohérent et cohérent. Nous résolvons magnifiquement le problème de l'écriture de code parallèle en utilisant async-s , ce qui signifie - sans bugs.Débarrassez-vous des verrous
DataTable<File, ProcessedFile> sharedMemory;
async Task WorkerAsync(...) {
File f = await channel.ReadAsync();
ProcessedFile p = await ProcessInParallelAsync(f);
lock (_lock) {
sharedMemory.add(f, p);
}
}
Vaut-il la peine de retirer async et ces verrous? Il existe maintenant toutes sortes de verrous asynchrones, des sémaphores asynchrones, c'est-à-dire une tentative d'utilisation des primitives qui sont en code synchrone et asynchrone. Ce concept semble être faux, car avec le verrou, vous protégez quelque chose contre l'exécution parallèle. Notre tâche est de traduire l'exécution parallèle en séquentielle, car c'est plus facile. Et si c'est plus facile, il y a moins d'erreurs.Channel<Pair<File, ProcessedFile>> output;
async Task WorkerAsync(...) {
File f = await channel.ReadAsync();
ProcessedFile p = await ProcessInParallelAsync(f);
await output.WriteAsync();
}
Nous pouvons créer un canal et y mettre quelques fichiers et fichiers traités, et ReadAsyncune autre procédure traitera ce canal et le fera séquentiellement. Le verrou lui-même, en plus de protéger la structure, linéarise essentiellement l'accès, un endroit où tous les fils de fils consécutifs deviennent parallèles. Et nous remplaçons cela explicitement par le canal. L'architecture est la suivante: les travailleurs reçoivent des fichiers
L'architecture est la suivante: les travailleurs reçoivent des fichiers inputet les envoient quelque part au processeur, qui traite également tout séquentiellement, il n'y a pas de parallélisme. Le code semble beaucoup plus simple. Je comprends que tout ne peut pas être fait de cette façon. Une telle architecture, lorsque vous pouvez créer des canaux de données, ne fonctionne pas toujours. Il se peut que vous ayez un deuxième canal qui entre dans votre processeur et qu'un graphique dirigé acyclique ne soit pas formé à partir des canaux, mais un graphique avec des cycles. C'est un exemple que Roman Elizarov a déclaré à KotlinConf en 2018. Il a écrit un exemple sur Kotlin avec ces canaux, et il y avait des cycles là-bas, et cet exemple a été arrêté. Le problème était que si vous avez de tels cycles dans un graphique, alors tout devient plus compliqué dans le monde asynchrone. Les interblocages asynchrones sont mauvais en ce sens qu'ils sont beaucoup plus difficiles à résoudre que les synchrones lorsque vous avez une pile de threads, et il est clair de quoi il s'agit. C'est donc un outil qui doit être utilisé correctement.
Il se peut que vous ayez un deuxième canal qui entre dans votre processeur et qu'un graphique dirigé acyclique ne soit pas formé à partir des canaux, mais un graphique avec des cycles. C'est un exemple que Roman Elizarov a déclaré à KotlinConf en 2018. Il a écrit un exemple sur Kotlin avec ces canaux, et il y avait des cycles là-bas, et cet exemple a été arrêté. Le problème était que si vous avez de tels cycles dans un graphique, alors tout devient plus compliqué dans le monde asynchrone. Les interblocages asynchrones sont mauvais en ce sens qu'ils sont beaucoup plus difficiles à résoudre que les synchrones lorsque vous avez une pile de threads, et il est clair de quoi il s'agit. C'est donc un outil qui doit être utilisé correctement.Sommaire
- Évitez la synchronisation en code asynchrone.
- Le code série est plus simple que parallèle.
- Le code asynchrone peut être simple et utiliser un minimum de paramètres et un contexte implicite qui modifient son comportement.
Si vous avez développé l'habitude d'écrire du code synchrone, et même si le code asynchrone est très similaire au code synchrone, n'y faites pas glisser de primitives, ce à quoi vous êtes habitué en code synchrone async mutex. Utilisez des flux, si possible, et d'autres primitives de passage de message .Le code série est plus simple que parallèle. Si vous pouvez écrire votre architecture de façon à ce qu'elle apparaisse séquentiellement, sans exécuter de code parallèle ni verrouiller, alors écrivez l'architecture séquentiellement.Et la dernière chose que nous avons vue à partir d'un grand nombre d'exemples de tâches. Lorsque vous concevez votre système, essayez de vous fier moins au contexte implicite. Le contexte implicite conduit à une mauvaise compréhension de ce qui se passe dans le code, et vous pouvez oublier les problèmes implicites dans un an. Et si une autre personne travaille sur ce code et y refait quelque chose, cela peut entraîner des difficultés que vous connaissiez autrefois, et le nouveau programmeur ne le sait pas à cause du contexte implicite. En conséquence, une mauvaise conception est caractérisée par un grand nombre de paramètres, leur combinaison et leur contexte implicite.Que lire
-10 . DotNext .