Des milliers de managers des bureaux de vente à travers le pays enregistrent chaque jour des dizaines de milliers de contacts dans notre système CRM - des faits de communication avec des clients potentiels ou déjà en collaboration avec nous. Et pour ce client, vous devez d'abord trouver, et de préférence très rapidement. Et cela se produit le plus souvent par nom. Par conséquent, il n'est pas surprenant qu'en analysant à nouveau les demandes «lourdes» sur l'une des bases de données les plus chargées - notre propre compte VLSI d'entreprise , j'ai trouvé «en haut» une demande de recherche «rapide» par nom des cartes d'entreprise. De plus, une enquête plus approfondie a révélé un exemple intéressant d' optimisation puis de dégradation des performancesdemande dans son affinement ultérieur par plusieurs équipes, chacune agissant uniquement par bonne volonté.0: que voulait l'utilisateur
[KDPV d'ici ]Qu'est-ce que l'utilisateur veut généralement dire quand il fait une recherche «rapide» par nom? Presque jamais cela ne s'avère être une recherche «honnête» sur une sous-chaîne du type ... LIKE '%%'- car alors non seulement et , mais même obtenir le résultat . L'utilisateur implique au niveau du ménage que vous lui fournirez une recherche au début d'un mot dans le titre et montrerez plus pertinent ce qui commence par la saisie. Et faites-le presque instantanément - avec une entrée interlinéaire.''' '''' '1: limiter la tâche
Et plus encore, une personne n'entrera pas spécifiquement de ' 'sorte que vous devez rechercher chaque préfixe de mot. Non, il est beaucoup plus facile pour l'utilisateur de répondre à un indice rapide pour le dernier mot que de «manquer» délibérément les précédents - voyez comment fonctionne n'importe quel moteur de recherche.En général, formuler correctement les exigences d'un problème représente plus de la moitié de la solution. Parfois, une analyse minutieuse du cas d'utilisation peut considérablement affecter le résultat .Que fait le développeur abstrait?1.0: moteur de recherche externe
Oh, la recherche est difficile, je ne veux rien faire du tout - donnons-la aux devops! Qu'ils nous déploient un moteur de recherche externe par rapport à la base de données: Sphinx, ElasticSearch, ... Uneoption fonctionnelle, quoique longue, en termes de synchronisation et de rapidité de changement. Mais pas dans notre cas, puisque la recherche n'est effectuée pour chaque client que dans le cadre de ses données de compte. Et les données ont une variabilité assez élevée - et si le gestionnaire a maintenant inséré la carte ' ', alors au bout de 5 à 10 secondes, il peut déjà se rappeler qu'il a oublié d'indiquer l'e-mail et que vous souhaitez le trouver et le corriger.Par conséquent, recherchons «directement dans la base de données» . Heureusement, PostgreSQL nous permet de le faire, et pas seulement une option - nous les considérerons.1.1: sous-chaîne «honnête»
Nous nous accrochons au mot «sous-chaîne». Mais exactement pour la recherche d'index par sous-chaîne (et même par des expressions régulières!) Il existe un excellent module pg_trgm ! Alors seulement, il sera nécessaire de trier correctement.Essayons de prendre une plaque pour la simplicité du modèle:CREATE TABLE firms(
id
serial
PRIMARY KEY
, name
text
);
Nous y remplissons 7,8 millions d'enregistrements d'organisations réelles et indexons:CREATE EXTENSION pg_trgm;
CREATE INDEX ON firms USING gin(lower(name) gin_trgm_ops);
Regardons les 10 premières entrées pour la recherche interligne:SELECT
*
FROM
firms
WHERE
lower(name) ~ ('(^|\s)' || '')
ORDER BY
lower(name) ~ ('^' || '') DESC
, lower(name)
LIMIT 10;
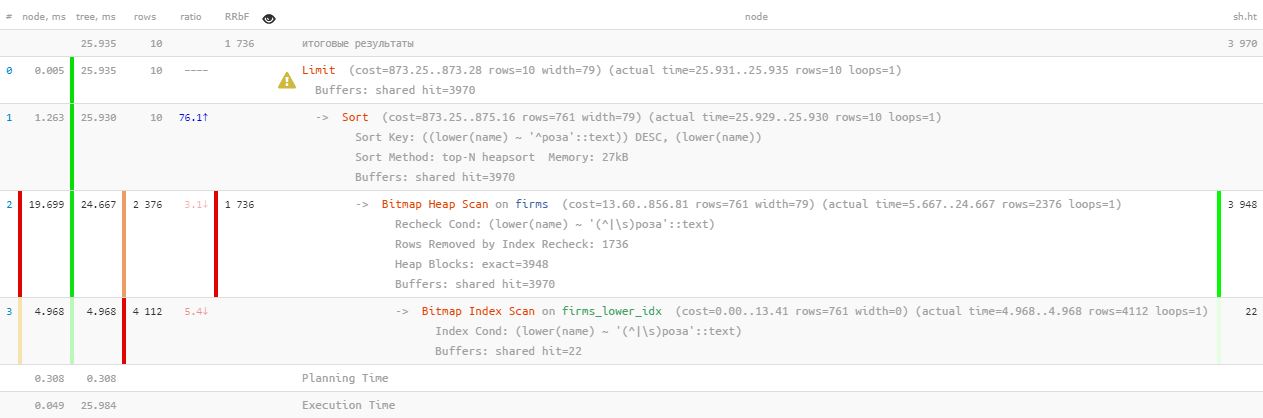 [jetez un oeil à expliquez.tensor.ru]Eh bien, c'est ... 26 ms, 31 Mo de données lues et plus de 1,7 Ko d'enregistrements filtrés - pour 10 personnes. Les frais généraux sont trop élevés, est-il possible d'être plus efficace?
[jetez un oeil à expliquez.tensor.ru]Eh bien, c'est ... 26 ms, 31 Mo de données lues et plus de 1,7 Ko d'enregistrements filtrés - pour 10 personnes. Les frais généraux sont trop élevés, est-il possible d'être plus efficace?1.2: recherche de texte? c'est FTS!
En effet, PostgreSQL fournit un mécanisme très puissant pour la recherche en texte intégral ( recherche en texte intégral ), y compris la possibilité de préfixer la recherche. Excellente option, même les extensions n'ont pas besoin d'être installées! Essayons:CREATE INDEX ON firms USING gin(to_tsvector('simple'::regconfig, lower(name)));
SELECT
*
FROM
firms
WHERE
to_tsvector('simple'::regconfig, lower(name)) @@ to_tsquery('simple', ':*')
ORDER BY
lower(name) ~ ('^' || '') DESC
, lower(name)
LIMIT 10;
 [regardez expliquez.tensor.ru]Ici, la parallélisation de l'exécution des requêtes nous a un peu aidés, réduisant le temps de moitié à 11 ms . Oui, et nous avons dû lire 1,5 fois moins - seulement 20Mo . Et ici, plus petit est le mieux, car plus la quantité que nous soustrayons est élevée, plus les chances de manquer de cache sont élevées, et chaque page de données supplémentaire lue sur le disque est un «frein» potentiel pour la demande.
[regardez expliquez.tensor.ru]Ici, la parallélisation de l'exécution des requêtes nous a un peu aidés, réduisant le temps de moitié à 11 ms . Oui, et nous avons dû lire 1,5 fois moins - seulement 20Mo . Et ici, plus petit est le mieux, car plus la quantité que nous soustrayons est élevée, plus les chances de manquer de cache sont élevées, et chaque page de données supplémentaire lue sur le disque est un «frein» potentiel pour la demande.1.3: toujours comme?
La demande précédente est bonne pour tout le monde, mais seulement si vous la tirez cent mille fois par jour, 2 To de données lues s'exécuteront . Au mieux - de la mémoire, mais si vous n'êtes pas chanceux, alors à partir du disque. Essayons donc de le réduire.Rappelons que l'utilisateur veut voir d' abord "qui commence par ..." . C'est donc sous sa forme pure une recherche de préfixe avec text_pattern_ops! Et seulement si nous ne sommes "pas assez" jusqu'à 10 enregistrements requis, alors nous devrons les lire en utilisant la recherche FTS:CREATE INDEX ON firms(lower(name) text_pattern_ops);
SELECT
*
FROM
firms
WHERE
lower(name) LIKE ('' || '%')
LIMIT 10;
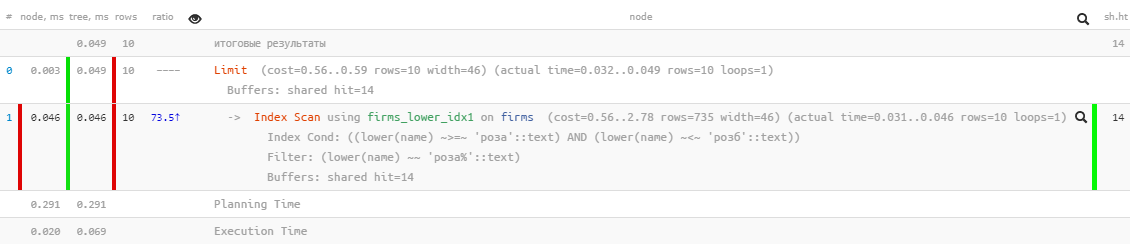 [regardez expliquez.tensor.ru]Excellentes performances - seulement 0,05 ms et un peu plus de 100 Ko de lecture! Seulement, nous avons oublié de trier par nom afin que l'utilisateur ne se perde pas dans les résultats:
[regardez expliquez.tensor.ru]Excellentes performances - seulement 0,05 ms et un peu plus de 100 Ko de lecture! Seulement, nous avons oublié de trier par nom afin que l'utilisateur ne se perde pas dans les résultats:SELECT
*
FROM
firms
WHERE
lower(name) LIKE ('' || '%')
ORDER BY
lower(name)
LIMIT 10;
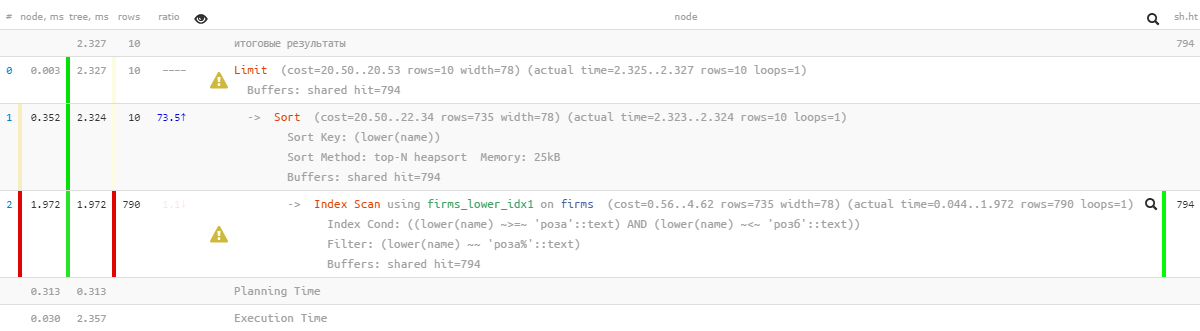 [regardez expliquez.tensor.ru]Oh, quelque chose n'est plus aussi joli - il semble qu'il y ait un index, mais le tri s'envole ... Il est, bien sûr, beaucoup plus efficace que la version précédente, mais ...
[regardez expliquez.tensor.ru]Oh, quelque chose n'est plus aussi joli - il semble qu'il y ait un index, mais le tri s'envole ... Il est, bien sûr, beaucoup plus efficace que la version précédente, mais ...1.4: «modifier avec un fichier»
Mais il existe un index qui vous permet de rechercher par plage, et il est normal d'utiliser le tri - btree normal !CREATE INDEX ON firms(lower(name));
Seule une demande devra être «montée manuellement»:SELECT
*
FROM
firms
WHERE
lower(name) >= '' AND
lower(name) <= ('' || chr(65535))
ORDER BY
lower(name)
LIMIT 10;
 [regardez expliquez.tensor.ru]Génial - les travaux de tri et la consommation des ressources restent "microscopiques", des milliers de fois plus efficaces que les FTS "purs" ! Il reste à collecter en une seule demande:
[regardez expliquez.tensor.ru]Génial - les travaux de tri et la consommation des ressources restent "microscopiques", des milliers de fois plus efficaces que les FTS "purs" ! Il reste à collecter en une seule demande:(
SELECT
*
FROM
firms
WHERE
lower(name) >= '' AND
lower(name) <= ('' || chr(65535))
ORDER BY
lower(name)
LIMIT 10
)
UNION ALL
(
SELECT
*
FROM
firms
WHERE
to_tsvector('simple'::regconfig, lower(name)) @@ to_tsquery('simple', ':*') AND
lower(name) NOT LIKE ('' || '%')
ORDER BY
lower(name) ~ ('^' || '') DESC
, lower(name)
LIMIT 10
)
LIMIT 10;
Je note que la deuxième sous-requête n'est exécutée que si la première renvoie moins que leLIMIT nombre de lignes attendu par la dernière . J'ai déjà écrit sur cette méthode d'optimisation des requêtes .Alors oui, nous avons maintenant btree et gin sur la table en même temps, mais statistiquement, il s'est avéré que moins de 10% des demandes atteignent le deuxième bloc . Autrement dit, avec des limitations typiques bien connues pour la tâche, nous avons pu réduire la consommation totale des ressources du serveur de près de mille fois!1.5 *: supprimer le fichier
Ci-dessus, LIKEnous avons été empêchés d'utiliser le mauvais type. Mais il peut être "mis sur le vrai chemin" en spécifiant l'instruction USING:La valeur par défaut est implicite ASC. De plus, vous pouvez spécifier le nom d'un opérateur de tri spécifique dans une phrase USING. L'opérateur de tri doit être un membre inférieur ou supérieur à une certaine famille d'opérateurs B-tree. ASCgénéralement équivalent USING <et DESCgénéralement équivalent USING >.
Dans notre cas, «moins» est ~<~:SELECT
*
FROM
firms
WHERE
lower(name) LIKE ('' || '%')
ORDER BY
lower(name) USING ~<~
LIMIT 10;
 [regardez expliquez.tensor.ru]
[regardez expliquez.tensor.ru]2: comment "aigrir" les demandes
Maintenant, nous laissons notre demande d '«insister» pendant six mois ou un an, et avec surprise, nous la trouvons à nouveau «en haut» avec des indicateurs du «pompage» quotidien total de la mémoire ( tampons partagés par coup ) en 5,5 To , c'est-à-dire encore plus qu'il ne l'était à l'origine.Non, bien sûr, notre entreprise a grandi et la charge a augmenté, mais pas tant! Donc, quelque chose est sale ici - découvrons-le.2.1: la naissance de la pagination
À un moment donné, une autre équipe de développement a voulu permettre de «sauter» dans le registre à partir d'une recherche rapide en indice avec les mêmes résultats, mais étendus. Et quel registre sans navigation de page? Foutons-le!( ... LIMIT <N> + 10)
UNION ALL
( ... LIMIT <N> + 10)
LIMIT 10 OFFSET <N>;
Maintenant, il était possible sans effort pour le développeur d'afficher le registre des résultats de recherche avec le chargement de "type-page".Bien sûr, en fait, pour chaque page de données suivante, de plus en plus sont lues (tout le temps précédent, que nous rejetons, plus la «queue» souhaitée) - c'est-à-dire qu'il s'agit d'un contre-motif sans ambiguïté. Et il serait plus correct de commencer la recherche à la prochaine itération à partir de la clé stockée dans l'interface, mais à ce sujet - une autre fois.2.2: envie d'exotisme
À un moment donné, le développeur a voulu diversifier la sélection résultante avec des données d'une autre table, dans ce but, la totalité de la demande précédente a été envoyée au CTE:WITH q AS (
...
LIMIT <N> + 10
)
SELECT
*
, (SELECT ...) sub_query
FROM
q
LIMIT 10 OFFSET <N>;
Et même ainsi - pas mal, car une sous-requête n'est calculée que pour 10 enregistrements retournés, sinon ...2.3: DISTINCT insignifiant et impitoyable
Quelque part dans le processus d'une telle évolution, une condition a été perdueNOT LIKE dans la 2e sous-requête . Il est clair qu'après cela, j'ai UNION ALLcommencé à renvoyer quelques enregistrements deux fois - d'abord trouvé au début de la ligne, puis à nouveau - au début du premier mot de cette ligne. Dans la limite, tous les enregistrements de la deuxième sous-requête pourraient coïncider avec les enregistrements de la première.Que fait un développeur au lieu de chercher une raison? .. Pas question!- doubler la taille des échantillons originaux
- mettez DISTINCT pour que nous n'obtenions que des instances uniques de chaque ligne
WITH q AS (
( ... LIMIT <2 * N> + 10)
UNION ALL
( ... LIMIT <2 * N> + 10)
LIMIT <2 * N> + 10
)
SELECT DISTINCT
*
, (SELECT ...) sub_query
FROM
q
LIMIT 10 OFFSET <N>;
Autrement dit, il est clair que le résultat, au final, est exactement le même, mais la chance de «voler» vers la deuxième sous-requête CTE est devenue beaucoup plus élevée, et sans cela, elle est clairement lue plus .Mais ce n'est pas la chose la plus triste. Étant donné que le développeur m'a demandé de sélectionner, DISTINCTnon pas par spécifique, mais immédiatement par tous les champs de l' enregistrement, le champ sub_query, le résultat de la sous-requête, y est également arrivé automatiquement. Maintenant, pour l'exécution DISTINCT, la base de données devait exécuter non pas 10 sous-requêtes, mais toutes <2 * N> + 10 !2.4: la coopération avant tout!
Ainsi, les développeurs ont vécu - ils ne se sont pas dérangés, car dans le registre, ils ont été "corrigés" à des valeurs N significatives avec un ralentissement chronique de la réception de chaque "page" suivante.Jusqu'à ce que les développeurs d'un autre service viennent à eux et ne souhaitent pas utiliser une méthode aussi pratique pour la recherche itérative - c'est-à-dire que nous prenons un morceau d'un échantillon, filtrons par conditions supplémentaires, dessinons le résultat, puis le morceau suivant (qui dans notre cas est atteint par augmenter N), et ainsi de suite jusqu'à ce que nous remplissions l'écran.En général, dans le spécimen capturé, N a atteint des valeurs de près de 17K , et en seulement 24 heures, au moins 4K de telles requêtes ont été exécutées "dans la chaîne". Le dernier d'entre eux a déjà été audacieusement scanné1 Go de mémoire à chaque itération ...