Je connais depuis longtemps le site Have I Been Pwned (HIBP) . Certes, jusqu'à récemment, il n'y était jamais allé. J'ai toujours eu deux mots de passe. L'un d'eux a été utilisé à plusieurs reprises pour le courrier poubelle et quelques comptes sur des sites étranges. Mais j'ai dû refuser, car le courrier a été piraté. Et pour être honnête, je suis reconnaissant au pirate informatique parce que cet événement m'a fait revoir mes mots de passe - la façon dont je les utilise et les stocke.Bien sûr, j'ai changé de mot de passe sur tous les comptes où il y avait un mot de passe compromis. Ensuite, je me suis demandé si le mot de passe divulgué se trouvait dans la base de données HIBP. Je ne voulais pas entrer le mot de passe sur le site, j'ai donc téléchargé la base de données (pwned-passwords-sha1-ordered-by-count-v5) La base est très impressionnante. Il s'agit d'un fichier texte de 22,8 Go avec un ensemble de hachages SHA-1, un dans chaque ligne avec un compteur, combien de fois le mot de passe avec ce hachage s'est produit dans les fuites. J'ai trouvé le SHA-1 de mon mot de passe fissuré et j'ai essayé de le trouver.Contenu
[G] représentant
Nous avons un fichier texte avec un hachage dans chaque ligne. Le meilleur endroit où aller est probablement grep.grep -m 1 '^XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX' pwned-passwords-sha1-ordered-by-count-v5.txtMon mot de passe était en haut de la liste avec une fréquence de plus de 1500 fois, donc ça craint vraiment. En conséquence, les résultats de la recherche sont revenus presque instantanément.Mais tout le monde n'a pas des mots de passe faibles. Je voulais vérifier combien de temps il faudrait pour trouver le pire des cas - le dernier hachage du fichier:time grep -m 1 '^4541A1E4605EEBF3F4C166329C18502DF75D348A' pwned-passwords-sha1-ordered-by-count-v5.txtRésultat: 33,35s user 23,39s system 41% cpu 2:15,35 totalc'est triste. Après tout, comme mon courrier a été piraté, je voulais vérifier la présence de tous mes anciens et nouveaux mots de passe dans la base de données. Mais un grep de deux minutes ne vous permet tout simplement pas de le faire confortablement. Bien sûr, je pourrais écrire un script, l'exécuter et faire une promenade, mais ce n'est pas une option. Je voulais trouver une meilleure solution et apprendre quelque chose.Structure de Trie
La première idée était d'utiliser une structure de données trie. La structure semble idéale pour stocker les hachages SHA-1. L'alphabet est petit, donc les nœuds seront également petits, tout comme le fichier résultant. Peut-être qu'il tient même dans la RAM? La recherche de clés doit être très rapide.J'ai donc mis en place cette structure. Il a ensuite pris les 1 000 000 premiers hachages de la base de données source pour créer le fichier résultant et vérifier si tout se trouve dans le fichier créé.Oui, je pouvais tout trouver dans le fichier, donc la structure fonctionnait bien. Le problème était différent.Le fichier résultant a été publié au format 2283686592B (2,2 Go). Ce n'est pas bien. Comptons et voyons ce qui se passe. Un nœud est une structure simple de seize valeurs 32 bits. Les valeurs sont des "pointeurs" vers les nœuds suivants avec le symbole de hachage SHA-1 spécifié. Ainsi, un nœud prend 16 * 4 octets = 64 octets. Ça semble un peu? Mais si vous y réfléchissez, un nœud représente un caractère dans un hachage. Ainsi, dans le pire des cas, le hachage SHA-1 prendra 40 * 64 octets = 2560 octets. C'est bien pire, par exemple, une représentation textuelle d'un hachage qui ne prend que 40 octets.La structure trie a l'avantage de réutiliser les nœuds. Si vous avez deux mots aaaet abb, le nœud des premiers caractères est réutilisé, car les caractères sont les mêmes - a.Revenons à notre problème. Calculons le nombre de nœuds stockés dans le fichier résultant: file_size / node_size = 2283686592 / 64 = 35682603Voyons maintenant combien de nœuds seront créés dans le pire des cas à partir d'un million de hachages: 1000000 * 40 = 40000000Ainsi, la structure du trie ne réutilise que des 40000000 - 35682603 = 4317397nœuds, ce qui représente 10,8% du pire des scénarios.Avec de tels indicateurs, le fichier résultant pour l'ensemble de la base de données HIBP prendrait 1421513361920 octets (1,02 To). Je n'ai même pas assez de disque dur pour vérifier la vitesse de recherche des clés.Ce jour-là, j'ai découvert que la structure du trie ne convient pas aux données relativement aléatoires.Cherchons une autre solution.Recherche binaire
Les hachages SHA-1 ont deux fonctionnalités intéressantes: ils sont comparables les uns aux autres et ils sont tous de la même taille.Grâce à cela, nous pouvons traiter la base de données HIBP d'origine et créer un fichier à partir des valeurs SHA-1 triées.Mais comment trier un fichier de 22 Go?Question. Pourquoi trier le fichier source? HIBP renvoie un fichier avec des chaînes déjà triées par hachage.
Réponse. Je n'y ai tout simplement pas pensé. À ce moment, je ne connaissais pas le fichier trié.Tri
Trier tous les hachages en RAM n'est pas une option, je n'ai pas beaucoup de RAM. La solution était la suivante:- Divisez un gros fichier en plus petits qui tiennent dans la RAM.
- Téléchargez des données à partir de petits fichiers, triez-les en RAM et réécrivez-les dans des fichiers.
- Combinez tous les petits fichiers triés en un seul grand.
Avec un gros fichier trié, vous pouvez rechercher notre hachage en utilisant une recherche binaire. L'accès au disque dur est important. Calculons le nombre de hits nécessaires dans une recherche binaire: log2(555278657) = 29.048636703930 hits. Pas si mal.Au premier stade, l'optimisation peut être effectuée. Convertissez les hachages de texte en données binaires. Cela réduira de moitié la taille des données obtenues: de 22 à 11 Go. Bien.Pourquoi revenir en arrière?
À ce moment, j'ai réalisé que vous pouvez faire plus intelligemment. Que faire si vous ne combinez pas de petits fichiers en un seul grand, mais effectuez une recherche binaire dans de petits fichiers triés en RAM? Le problème est de savoir comment trouver le fichier souhaité dans lequel rechercher la clé. La solution est très simple. Nouvelle approche:- Créez 256 fichiers avec les noms "00" ... "FF".
- Lorsque vous lisez des hachages à partir d'un fichier volumineux, écrivez des hachages commençant par «00 ..» dans un fichier appelé «00», des hachages commençant par «01 ..» - dans un fichier «01» et ainsi de suite.
- Téléchargez des données à partir de petits fichiers, triez-les en RAM et réécrivez-les dans des fichiers.
Tout est très simple. De plus, une autre option d'optimisation apparaît. Si le hachage est stocké dans le fichier "00", alors nous savons qu'il commence par "00". Si le hachage est stocké dans le fichier "F2", il commence par "F2". Ainsi, lors de l'écriture de hachages dans de petits fichiers, nous pouvons omettre le premier octet de chaque hachage! Cela représente 5% de toutes les données. 555 Mo sont enregistrés au total.Parallélisme
La séparation en fichiers plus petits offre une autre opportunité d'optimisation. Les fichiers sont indépendants les uns des autres, nous pouvons donc les trier en parallèle. Nous nous souvenons que tous vos processeurs aiment transpirer en même temps;)Ne sois pas un salaud égoïste
Lorsque j'ai implémenté la solution ci-dessus, j'ai réalisé que d'autres personnes avaient probablement un problème similaire. Beaucoup d'autres téléchargent et recherchent également la base de données HIBP. J'ai donc décidé de partager mon travail.Avant cela, j'ai à nouveau révisé mon approche et trouvé quelques problèmes que je voudrais résoudre avant de publier le code et les outils sur Github.Premièrement, en tant qu'utilisateur final, je ne voudrais pas utiliser un outil qui crée beaucoup de fichiers étranges avec des noms étranges, dans lesquels on ne sait pas ce qui est stocké, etc.Eh bien, cela peut être résolu en combinant les fichiers "00" .. "FF" dans un gros fichier.Malheureusement, avoir un seul gros fichier pour le tri pose un nouveau problème. Et si je veux insérer un hachage dans ce fichier? Un seul hachage. Ce n'est que 20 octets. Oh, le hachage commence par "000000000 ..". D'accord. Libérons de l'espace pour cela en déplaçant 11 Go d'autres hachages ...Vous comprenez quel est le problème. L'insertion de données au milieu d'un fichier n'est pas l'opération la plus rapide.Un autre inconvénient de cette approche est que vous devez à nouveau stocker les premiers octets - il s'agit de 555 Mo de données.Enfin, la recherche binaire sur les données stockées sur votre disque dur est beaucoup plus lente que l'accès à la RAM. Je veux dire, c'est 30 lectures de disque contre 0 lecture de disque.B3
Encore. Ce que nous avons et ce que nous voulons réaliser.Nous avons 11 Go de valeurs binaires. Toutes les valeurs sont comparables et ont la même taille. Nous voulons savoir si une clé particulière est présente dans les données stockées, et voulons également changer la base de données. Et pour que tout fonctionne rapidement.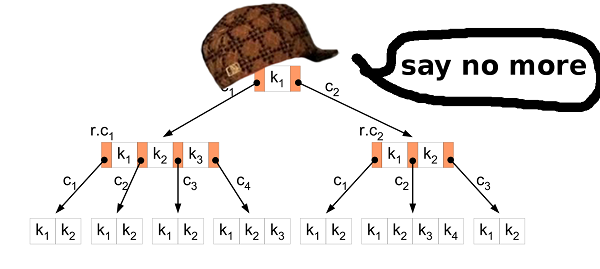 B-arbre? DroiteL'arbre B vous permet de minimiser l'accès au disque lors de la recherche, de la modification, etc. Il a beaucoup plus de fonctionnalités, mais nous avons besoin de ces deux.
B-arbre? DroiteL'arbre B vous permet de minimiser l'accès au disque lors de la recherche, de la modification, etc. Il a beaucoup plus de fonctionnalités, mais nous avons besoin de ces deux.Tri par insertion
La première étape consiste à convertir les données du fichier source HIBP en B-tree. Cela signifie que vous devez extraire tous les hachages tour à tour et les insérer dans la structure. L'algorithme d'insertion habituel convient pour cela. Mais dans notre cas, vous pouvez faire mieux.L'insertion d'un grand nombre de données brutes dans un arbre B est un scénario bien connu. Les sages ont inventé une meilleure approche pour cela que l'insert habituel. Tout d'abord, vous devez trier les données. Cela peut être fait comme décrit ci-dessus (divisez le fichier en plus petits et triez-les dans la RAM). Insérez ensuite les données dans l'arborescence.Dans l'algorithme habituel, si vous trouvez le nœud feuille où vous souhaitez insérer la valeur et qu'il est rempli, vous créez un nouveau nœud (à droite) et répartissez uniformément les valeurs entre les deux nœuds, à gauche et à droite (plus une valeur va au nœud parent mais ce n'est pas important ici). En bref, les valeurs du nœud gauche sont toujours inférieures aux valeurs de droite. Le fait est que lorsque vous insérez les données triées, vous savez que les petites valeurs ne seront plus insérées dans l'arborescence, donc plus aucune valeur n'ira au nœud de gauche. Le nœud gauche reste à moitié vide tout le temps. De plus, si vous insérez suffisamment de valeurs, vous pouvez constater que le nœud droit est plein, vous devez donc déplacer la moitié des valeurs vers le nouveau nœud droit. Le nœud divisé reste à moitié vide, comme dans le cas précédent. Etc…En conséquence, après toutes les insertions, vous obtenez un arbre dans lequel presque tous les nœuds sont à moitié vides. Ce n'est pas une utilisation très efficace de l'espace. On peut faire mieux.Séparé ou non?
Dans le cas de l'insertion de données triées, vous pouvez apporter une petite modification à l'algorithme d'insertion. Si le nœud dans lequel vous souhaitez coller la valeur est plein, ne le cassez pas. Créez simplement un nouveau nœud vide et collez la valeur dans le nœud parent. Ensuite, lorsque vous insérez les valeurs suivantes (qui sont plus grandes que les précédentes), vous les insérez dans un nouveau nœud vide.Pour conserver les propriétés de l'arbre B, après toutes les insertions, il est nécessaire de trier les nœuds les plus à droite de chaque couche de l'arbre (sauf la racine) et de diviser uniformément les valeurs de ce nœud extrême et de son voisin gauche. Vous obtenez donc le plus petit arbre possible.Propriétés de l'arborescence HIBP
Lors de la conception d'un arbre B, vous devez sélectionner son ordre. Il montre combien de valeurs peuvent être stockées dans un nœud, ainsi que le nombre d'enfants que le nœud peut avoir. En manipulant ce paramètre, nous pouvons manipuler la hauteur de l'arbre, la taille binaire du nœud, etc.Dans HIBP, nous avons des 555278657hachages. Supposons que nous voulons un arbre de trois hauteurs (nous n'avons donc pas besoin de plus de trois opérations de lecture pour vérifier la présence d'un hachage). Nous devons trouver une valeur de M telle que logM(555278657) < 3. J'ai choisi 1024. Ce n'est pas la plus petite valeur possible, mais cela permet d'insérer plus de hachages et de conserver la hauteur de l'arbre.Fichier de sortie
Le fichier source HIBP a une taille de 22,8 Go. Le fichier de sortie avec l'arborescence B est de 12,4 Go. Il faut environ 11 minutes pour le créer sur ma machine (Intel Core i7-6700, 3,4 GHz, 16 Go de RAM), disque dur (pas SSD).Repères
L'option B-tree montre un assez bon résultat:| | temps [μs] | % |
| -----------------: | ------------: | ------------: |
| okon | 49 | 100 |
| grep '^ hash' | 135'350'000 | 276'224'489 |
| grep | 135'480'000 | 276'489'795 |
| C ++ ligne par ligne | 135'720'201 | 276'980'002 |
okon - bibliothèque et CLI
Comme je l'ai dit, je voulais partager mon travail avec le monde. J'ai implémenté une bibliothèque et une interface de ligne de commande pour traiter la base de données HIBP et rechercher rapidement les hachages. La recherche est si rapide qu'elle peut, par exemple, être intégrée dans un gestionnaire de mots de passe et donner un retour à l'utilisateur à chaque pression sur une touche. Il existe de nombreuses utilisations possibles.La bibliothèque a une interface C, elle peut donc être utilisée presque partout. CLI est une CLI. Vous pouvez simplement construire et exécuter (:Le code est dans mon référentiel .Avertissement: okon ne fournit pas encore d'interface pour insérer des valeurs dans l'arbre B créé. Il ne peut traiter que le fichier HIBP, créer un arbre B et le rechercher. Ces fonctions fonctionnent assez bien, j'ai donc décidé de partager le code et de continuer à travailler sur l'insertion et d'autres fonctions possibles.Liens et discussion
Merci d'avoir lu
(: