 Bonjour à tous!Engagé dans des tests de performance. Et j'aime vraiment configurer la surveillance et profiter des métriques dans Grafana . Et la norme de stockage des métriques dans les outils de chargement est InfluxDB . Dans InfluxDB, vous pouvez enregistrer des métriques à partir d'outils populaires tels que:En travaillant avec des outils de test de performances et leurs métriques, j'ai accumulé une sélection de recettes de programmation pour le bundle de Grafana et InfluxDB . Je propose de considérer un problème intéressant qui se pose lorsqu'il existe une métrique avec deux balises ou plus. Je pense que ce n'est pas rare. Et dans le cas général, la tâche ressemble à ceci: calculer la métrique totale pour un groupe, qui est divisée en sous-groupes .
Bonjour à tous!Engagé dans des tests de performance. Et j'aime vraiment configurer la surveillance et profiter des métriques dans Grafana . Et la norme de stockage des métriques dans les outils de chargement est InfluxDB . Dans InfluxDB, vous pouvez enregistrer des métriques à partir d'outils populaires tels que:En travaillant avec des outils de test de performances et leurs métriques, j'ai accumulé une sélection de recettes de programmation pour le bundle de Grafana et InfluxDB . Je propose de considérer un problème intéressant qui se pose lorsqu'il existe une métrique avec deux balises ou plus. Je pense que ce n'est pas rare. Et dans le cas général, la tâche ressemble à ceci: calculer la métrique totale pour un groupe, qui est divisée en sous-groupes .Il y a trois options:
- Juste le montant regroupé par balise Type
- Chemin Grafana. Nous utilisons une pile de valeurs
- Somme des sommets avec sous-requête
Comment tout a commencé
Configuration de la surveillance du MBean JVM à l'aide de Jolokia , Telegraf , InfluxDB et Grafana . Et il a visualisé les métriques par pools de mémoire - combien de mémoire est allouée par chaque pool de mémoire dans HEAP et au-delà.Graphiques sur les pools de mémoire JVM et l'activité du garbage collector de 13h00 de la veille à 01h00 de la nuit du jour (période de 12 heures). Ici vous pouvez voir que les pools de mémoire sont divisés en deux groupes: HEAP et NON_HEAP . Et que vers 17h00 il y avait la collecte des ordures, après quoi la taille des pools de mémoire a diminué: Pour métriques recueillir sur les pools de mémoire, je a précisé les paramètres suivants dans le Telegraf fichier de configuration : telegraf.conf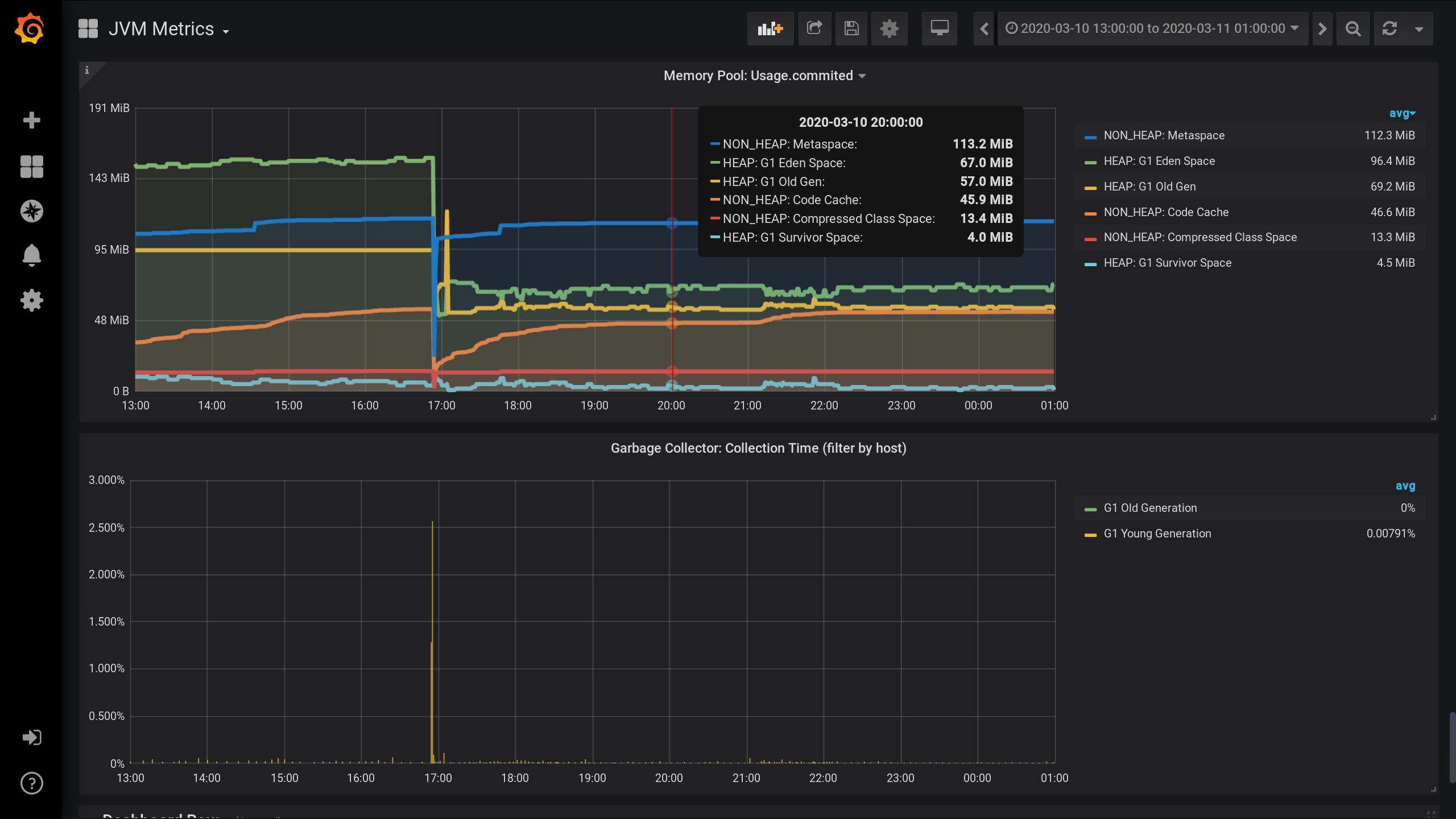
[outputs.influxdb]
urls = ["http://influxdb_server:8086"]
database = "telegraf"
username = "login-InfluxDb"
password = "*****"
retention_policy = "month"
influx_uint_support = false
[agent]
collection_jitter = "2s"
interval = "2s"
precision = "s"
[[inputs.jolokia2_agent]]
username = "login-Jolokia"
password = "*****"
urls = ["http://127.0.0.1:7777/jvm-service"]
[[inputs.jolokia2_agent.metric]]
paths = ["Usage","PeakUsage","CollectionUsage","Type"]
name = "java_memory_pool"
mbean = "java.lang:name=*,type=MemoryPool"
tag_keys = ["name"]
[[processors.converter]]
[processors.converter.fields]
integer = ["CollectionUsage.*", "PeakUsage.*", "Usage.*"]
tag = ["Type"]
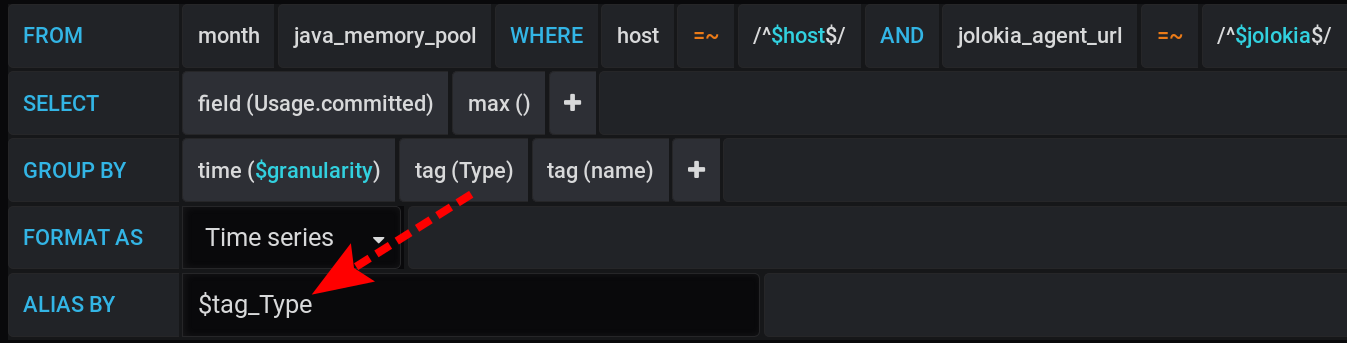
Et dans Grafana, j'ai construit une demande à InfluxDB pour afficher dans les graphiques la valeur métrique maximale Usage.Committedpour une période de temps avec un pas $granularity(1m) et regroupée par deux balises Type(HEAP ou NON_HEAP) et name(Metaspace, G1 Old Gen, ...): La même demande sous forme de texte, en tenant compte de toutes les variables de Grafana (attention à l'échappement des valeurs des variables avec - c'est important pour que la requête fonctionne correctement):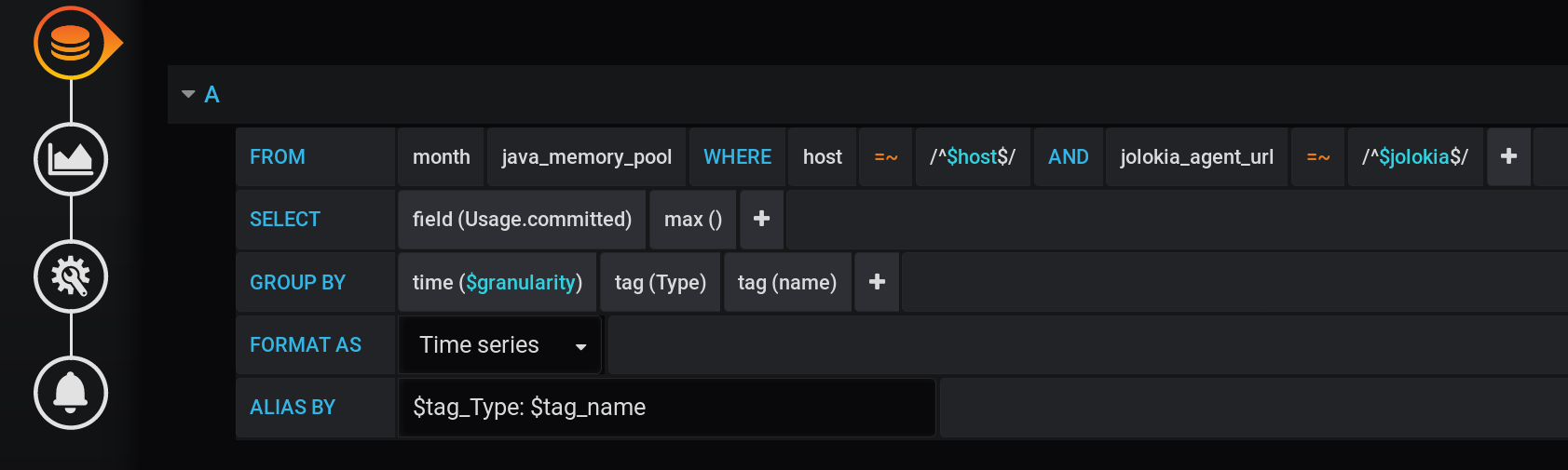
:regexSELECT max("Usage.committed")
FROM "telegraf"."month"."java_memory_pool"
WHERE
host =~ /^${host:regex}$/ AND
jolokia_agent_url =~ /^${jolokia:regex}$/ AND
$timeFilter
GROUP BY
"Type", "name", time($granularity)
La même requête sous forme de texte, en tenant compte des valeurs spécifiques des variables Grafana :SELECT max("Usage.committed")
FROM "telegraf"."month"."java_memory_pool"
WHERE
host =~ /^serverName$/ AND
jolokia_agent_url =~ /^http:\/\/127\.0\.0\.1:7777\/jvm-service$/ AND
time >= 1583834400000ms and time <= 1583877600000ms
GROUP BY
"Type", "name", time(1m)
Le regroupement par heure GROUP BY time($granularity)ou GROUP BY time(1m)permet de réduire le nombre de points sur le graphique. Pour une durée de 12 heures et un pas de regroupement de 1 minute, on obtient: 12 x 60 = 720 fois soit 721 points (le dernier point avec une valeur nulle).N'oubliez pas que 721 est le nombre attendu de points en réponse aux demandes à InfluxDB avec les paramètres actuels pour l'intervalle de temps (12 heures) et l'étape de regroupement (1 minute).
Pool de
mémoire NON_HEAP: Metaspace (bleu) est en tête de la consommation de mémoire à 20h00. Et selon HEAP: G1 Old Gen (jaune), il y a eu une petite surtension locale à 17h03. Et au moment de 20h00, au total, tous les pools NON_HEAP ont laissé 172,5 MiB (113,2 + 45,9 + 13,4) et les pools HEAP 128 MiB (67 + 57 + 4).
N'oubliez pas les valeurs de 20:00: pools NON_HEAP 172,5 MiB et pools HEAP 128 MiB . Nous nous concentrerons sur ces valeurs à l'avenir.
Dans le contexte de Type : nom , nous avons facilement obtenu la valeur métrique.Dans le contexte de la balise de nom uniquement , la valeur métrique est également facile à obtenir, car tous les noms des pools de mémoire sont uniques et il suffit de ne laisser le regroupement des résultats que par nom .La question demeure: comment obtenir quelle taille est allouée pour tous les pools HEAP et tous les pools NON_HEAP au total?
1. Juste le montant regroupé par balise Type
1.1. Somme regroupée par balise
La première solution qui peut vous venir à l'esprit est de regrouper les valeurs par la balise Type et de calculer la somme des valeurs dans chaque groupe. Une telle requête ressemblera à ceci: Une représentation textuelle d'une demande de calcul de somme regroupée par balise Type avec toutes les variables Grafana :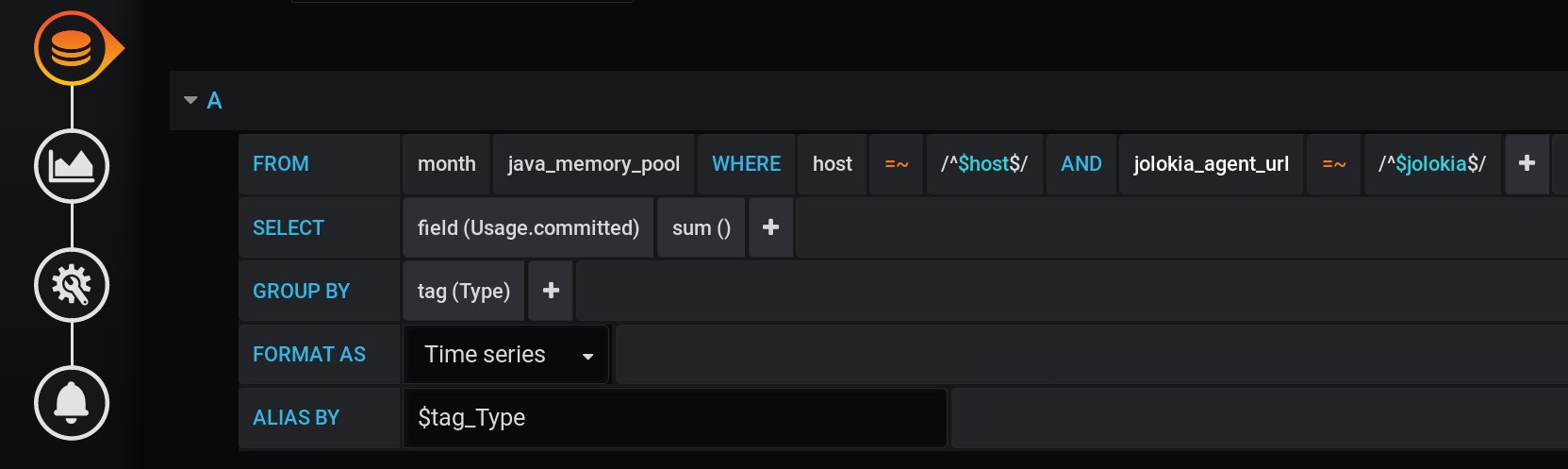
SELECT sum("Usage.committed")
FROM "telegraf"."month"."java_memory_pool"
WHERE
host =~ /^${host:regex}$/ AND
jolokia_agent_url =~ /^${jolokia:regex}$/ AND
$timeFilter
GROUP BY
"Type"
Il s'agit d'une requête valide, mais elle ne renverra que deux points: la somme sera calculée avec le regroupement uniquement par la balise Type avec deux valeurs (HEAP et NON_HEAP). Nous ne verrons même pas le calendrier. Il y aura deux points autonomes avec une énorme somme de valeurs (plus de 3 TiB): Une telle somme ne convient pas, une ventilation en intervalles de temps est nécessaire.
1.2. Montant groupé par tag par minute
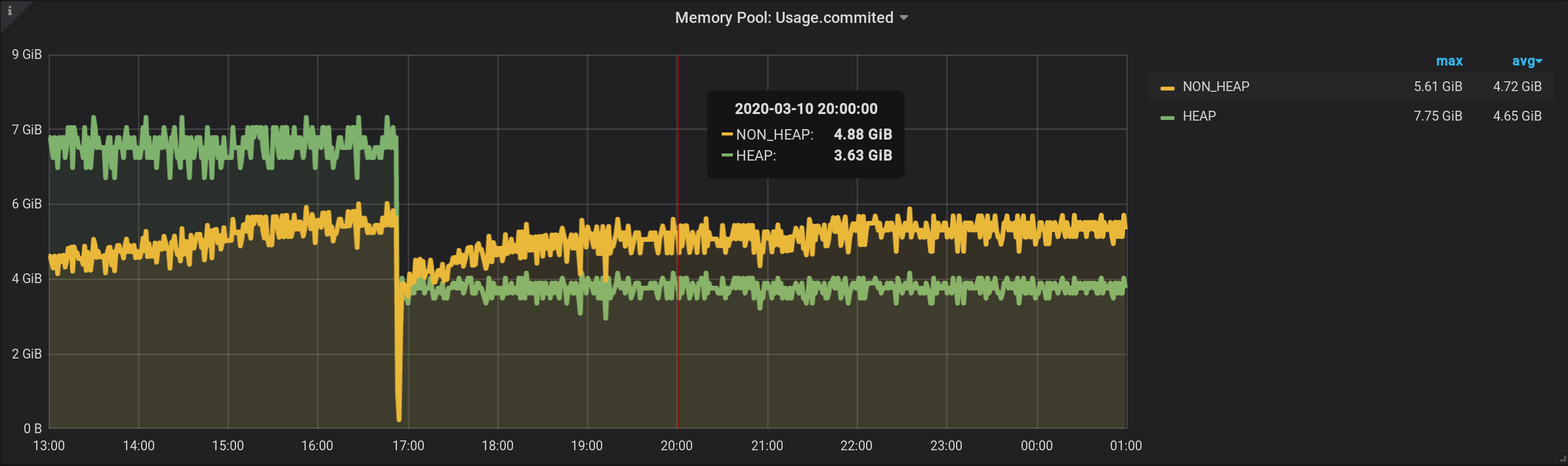
Dans la requête d'origine, nous avons regroupé les mesures selon un intervalle de granularité $ personnalisé . Faisons le regroupement maintenant par un intervalle personnalisé.Cette requête se révélera, elle a ajouté GROUP BY time($granularity): Nous obtenons des valeurs gonflées, au lieu de 172,5 Mio par NON_HEAP, nous voyons 4,88 Gio: Étant donné que les mesures sont envoyées à InfluxDB une fois toutes les 2 secondes (voir telegraf.conf ci-dessus), la somme des lectures en une minute ne donnera pas le montant dans le moment, et la somme de trente de ces montants. Nous ne pouvons pas non plus diviser le résultat par la constante 30 . Étant donné que $ granularity est un paramètre, il peut être défini sur 1 minute et 10 minutes. Et la valeur du montant va changer.
1.3. Tag groupé par seconde
Afin d'obtenir correctement la valeur métrique pour l'intensité de collecte métrique actuelle (2 secondes), vous devez calculer le montant pour un intervalle fixe qui ne dépasse pas l'intensité de collecte métrique.Essayons d'afficher les statistiques avec un regroupement en quelques secondes. Ajouter au GROUP BYregroupement time(1s): Avec une si petite granularité, nous obtenons un grand nombre de points pour notre intervalle de temps de 12 heures (12 heures * 60 minutes * 60 secondes = 43 200 intervalles, 43 201 points par ligne, dont le dernier est nul): 43 201 points dans chaque ligne du graphique. Il y a tellement de points qu'InfluxDB formera une réponse pendant longtemps, Grafana prendra une réponse plus longtemps, puis le navigateur attirera un si grand nombre de points pendant longtemps.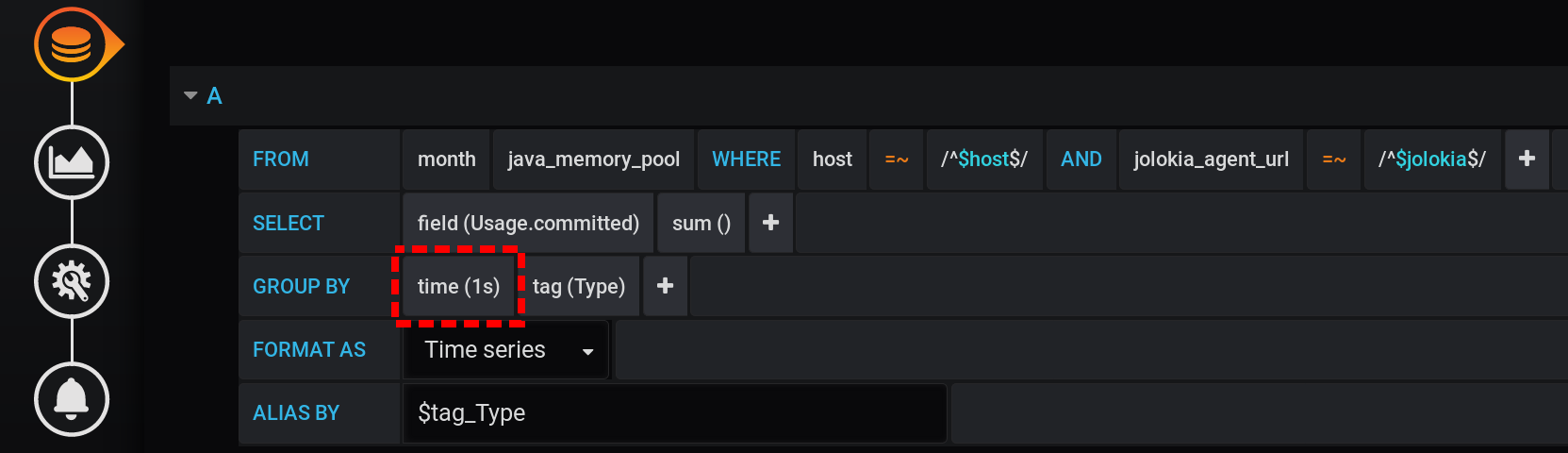
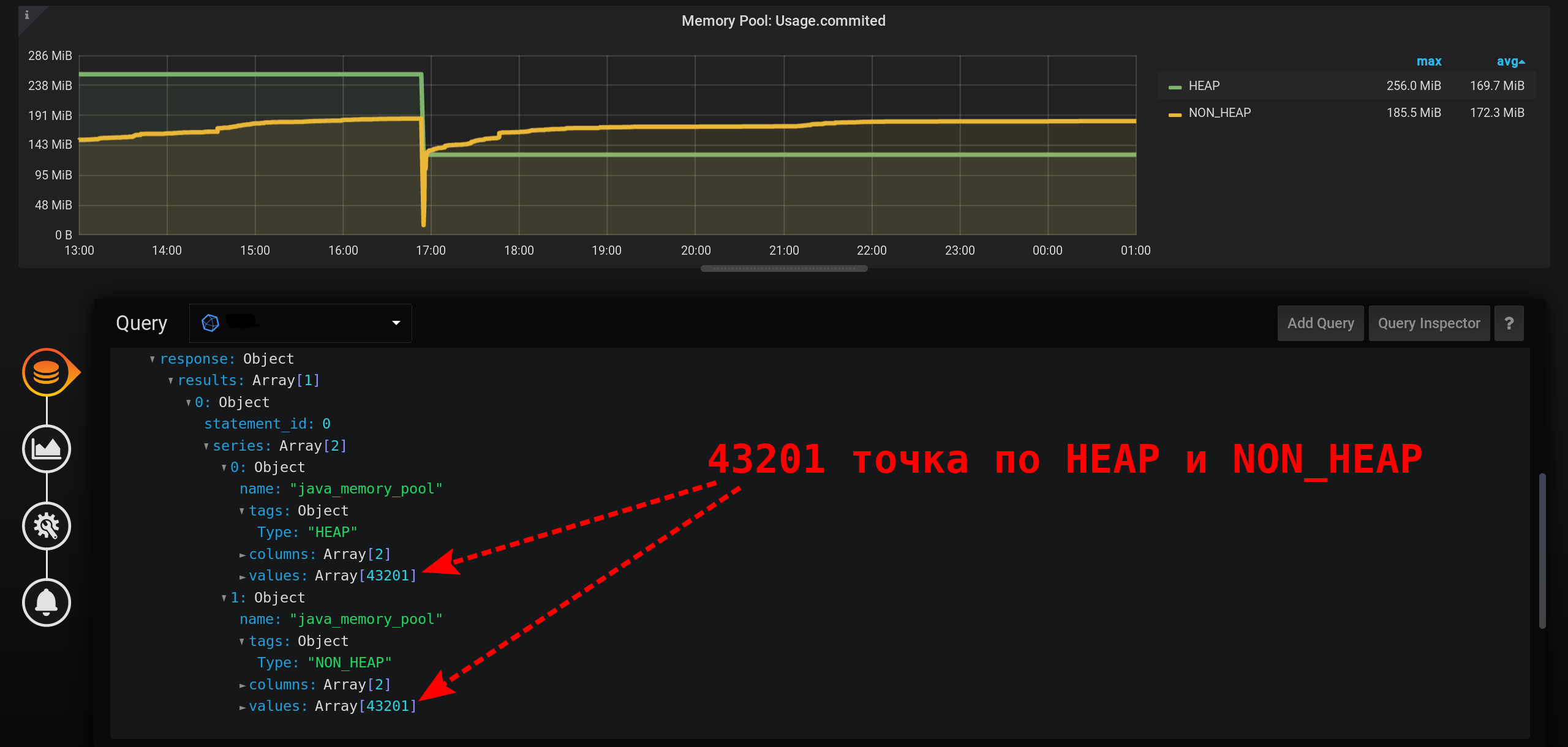 Et pas à chaque seconde, il y a des points: les mesures ont été collectées toutes les 2 secondes, et regroupées par seconde, ce qui signifie que chaque deuxième point sera nul. Pour voir une ligne fluide, configurez la connexion des valeurs non vides. Sinon, nous ne verrons pas les graphiques: auparavant, Grafana était tel que le navigateur se bloquait lors du dessin d'un grand nombre de points. Maintenant, la version de Grafana a la possibilité de dessiner plusieurs dizaines de milliers de points: le navigateur saute simplement certains d'entre eux, dessine un graphique en utilisant les données amincies. Mais le graphique est lissé. Les sommets sont affichés comme des sommets moyens.
Et pas à chaque seconde, il y a des points: les mesures ont été collectées toutes les 2 secondes, et regroupées par seconde, ce qui signifie que chaque deuxième point sera nul. Pour voir une ligne fluide, configurez la connexion des valeurs non vides. Sinon, nous ne verrons pas les graphiques: auparavant, Grafana était tel que le navigateur se bloquait lors du dessin d'un grand nombre de points. Maintenant, la version de Grafana a la possibilité de dessiner plusieurs dizaines de milliers de points: le navigateur saute simplement certains d'entre eux, dessine un graphique en utilisant les données amincies. Mais le graphique est lissé. Les sommets sont affichés comme des sommets moyens.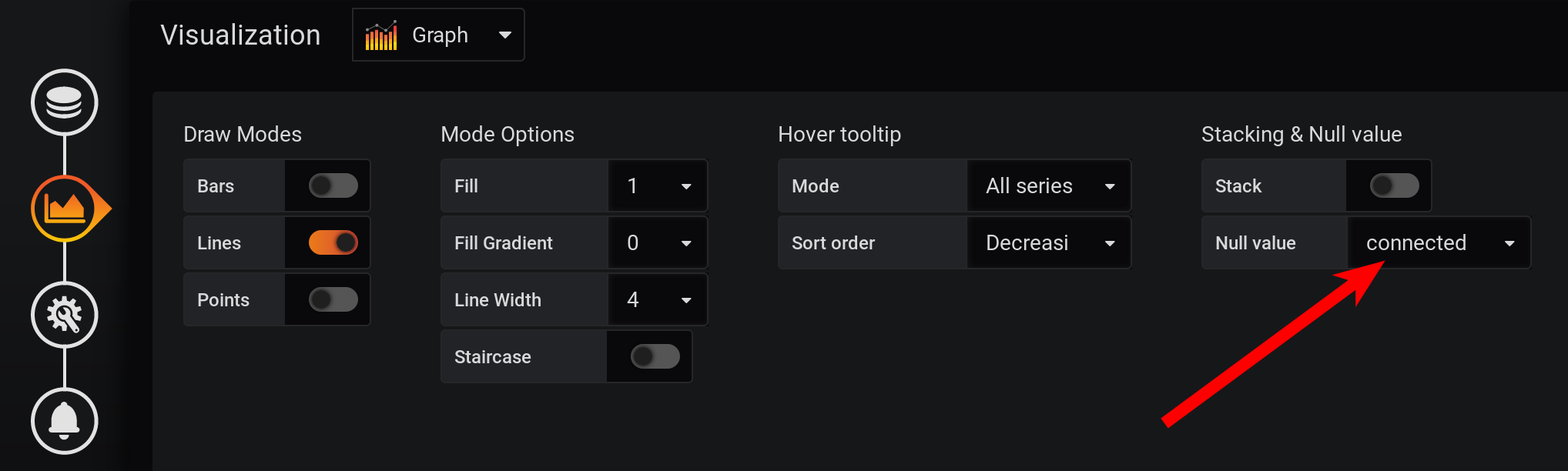 Par conséquent, il y a un graphique, il est affiché avec précision, les mesures à 20h00 sont calculées correctement, les mesures dans la légende du graphique sont calculées correctement. Mais le graphique est lissé: les rafales n'y sont pas visibles avec une précision de 1 seconde. En particulier, la surtension HEAP à 17:03 a disparu du graphique, le graphique HEAP est très lisse: le moins dans les performances se manifestera clairement sur un intervalle de temps plus long. Si vous essayez de construire un graphique en un mois (720 heures), et non en 12 heures, alors tout gèlera avec une si petite granularité (1 seconde), il y aura trop de points. Et il y a un moins en l'absence de pics, un paradoxe - en raison de la grande précision d'obtention des métriques, nous obtenons une faible précision de leur affichage .
Par conséquent, il y a un graphique, il est affiché avec précision, les mesures à 20h00 sont calculées correctement, les mesures dans la légende du graphique sont calculées correctement. Mais le graphique est lissé: les rafales n'y sont pas visibles avec une précision de 1 seconde. En particulier, la surtension HEAP à 17:03 a disparu du graphique, le graphique HEAP est très lisse: le moins dans les performances se manifestera clairement sur un intervalle de temps plus long. Si vous essayez de construire un graphique en un mois (720 heures), et non en 12 heures, alors tout gèlera avec une si petite granularité (1 seconde), il y aura trop de points. Et il y a un moins en l'absence de pics, un paradoxe - en raison de la grande précision d'obtention des métriques, nous obtenons une faible précision de leur affichage .
2. Chemin Grafana. Nous utilisons une pile de valeurs
Il n'a pas été possible de créer une solution simple et productive avec InfluxDB et le concepteur de requêtes Grafana . Nous essaierons uniquement d'utiliser les outils Grafana pour résumer les métriques affichées dans le graphique d'origine. Et oui, c'est possible!2.1. Il suffit de faire une info-bulle Hover / valeur empilée: cummulative
Nous laisserons la demande de choix des métriques inchangée, la même que dans la section «Comment tout a commencé»: les métriques seront regroupées par type et nom . Mais nous afficherons uniquement la balise Type dans les noms des graphiques : Et dans les paramètres de visualisation, nous regrouperons les métriques par piles Grafana : Tout d'abord, ajoutez la séparation de deux balises en deux piles A et B différentes, afin que leurs valeurs ne se croisent pas: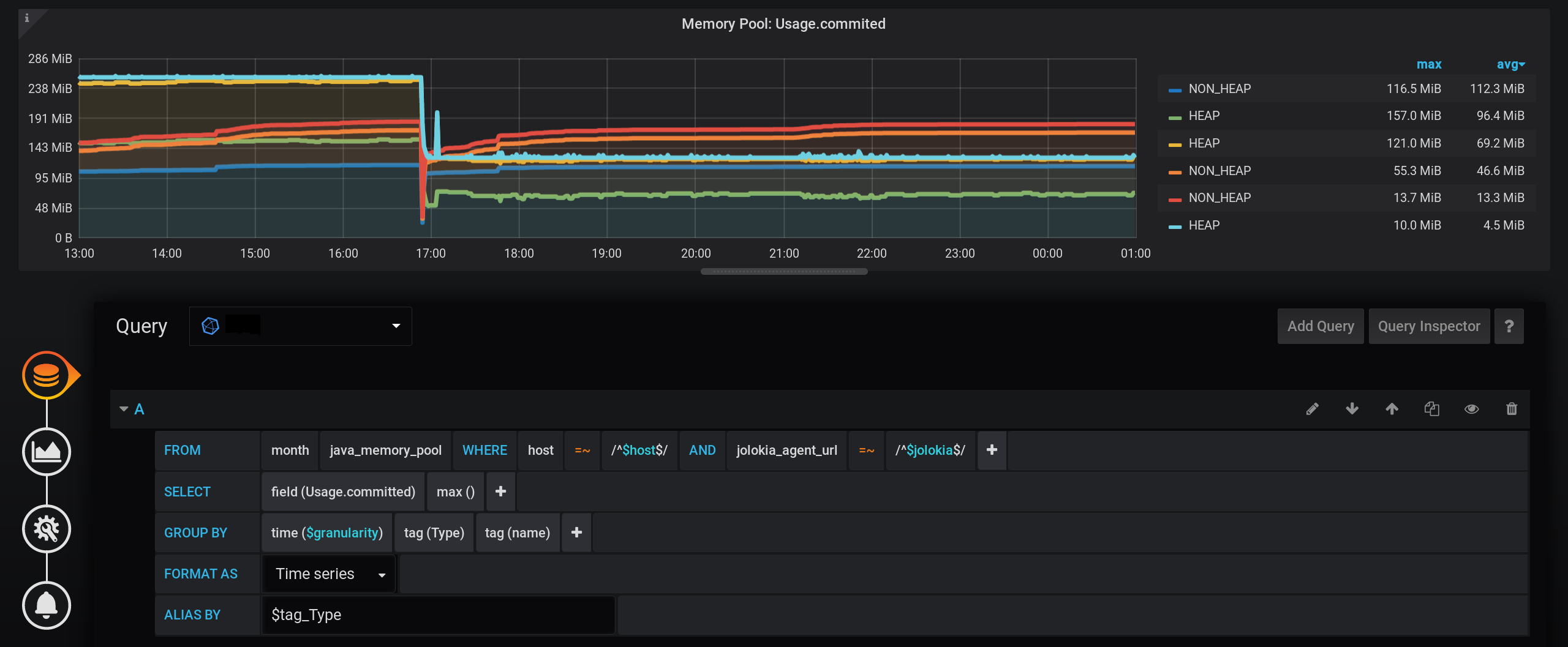
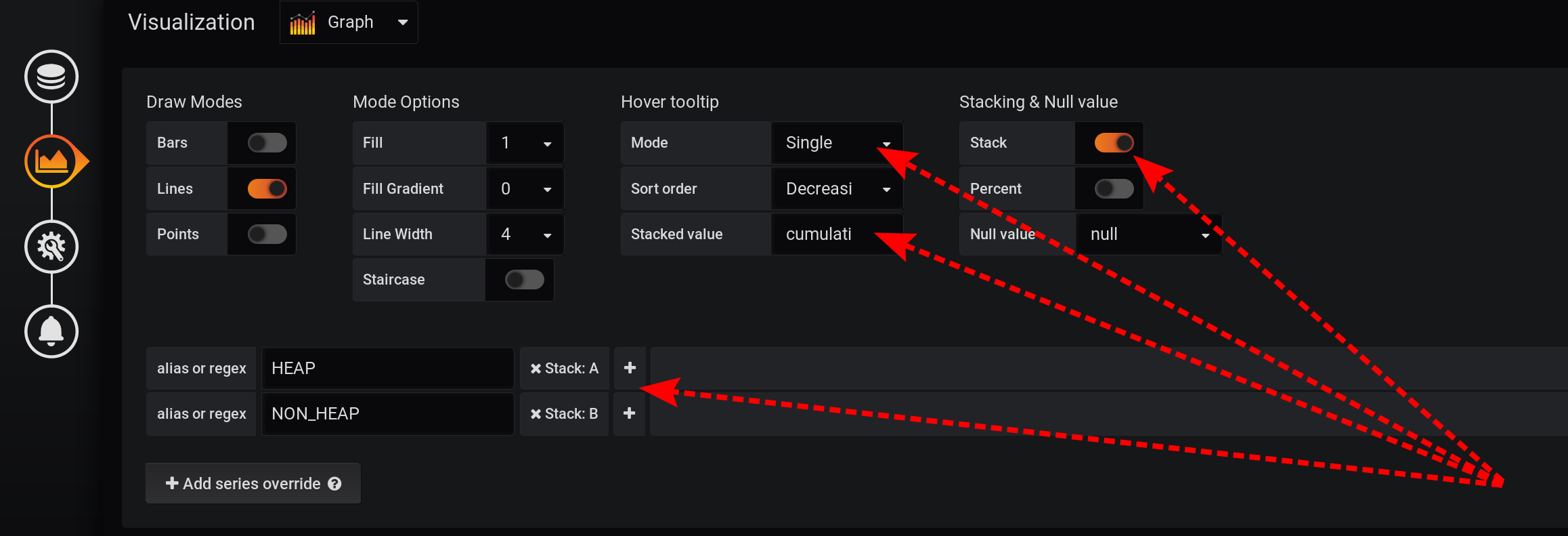
- Ajouter un remplacement de série / HEAP / Stack : A
- Ajouter un remplacement de série / NON_HEAP / Stack : B
Configurez ensuite la visualisation des métriques pour afficher les valeurs totales dans une info-bulle avec des graphiques:- Stacking & Null value / Stack : On
- Info-bulle de survol / valeur empilée : cumulatif
- Infobulle / mode de survol : simple
En raison des différentes fonctionnalités de Grafana, vous devez effectuer des actions dans cet ordre. Si vous modifiez l'ordre des actions ou laissez certains champs avec des paramètres par défaut, quelque chose ne fonctionnera pas:- Stack A B Stacking & Null value / Stack: On, ;
- Hover tooltip / Mode , Single, Hover tooltip .
Et maintenant, nous voyons beaucoup de lignes, telles que nous-mêmes. Mais! Si vous survolez le NON_HEAP le plus haut , l'info-bulle affichera la somme des valeurs de tous les NON_HEAP . Le montant est considéré comme vrai, déjà par Grafana signifie : Et si vous survolez le graphique le plus haut avec le nom HEAP , nous verrons le montant par HEAP . Le graphique s'affiche correctement. Même la surtension HEAP à 17 h 03 est visible: officiellement, la tâche est terminée. Mais il y a des inconvénients - de nombreux graphiques supplémentaires sont affichés. Vous devez placer le curseur tout en haut. Et dans la légende du graphique, non cumulative, mais des valeurs individuelles sont affichées, de sorte que la légende est devenue inutile.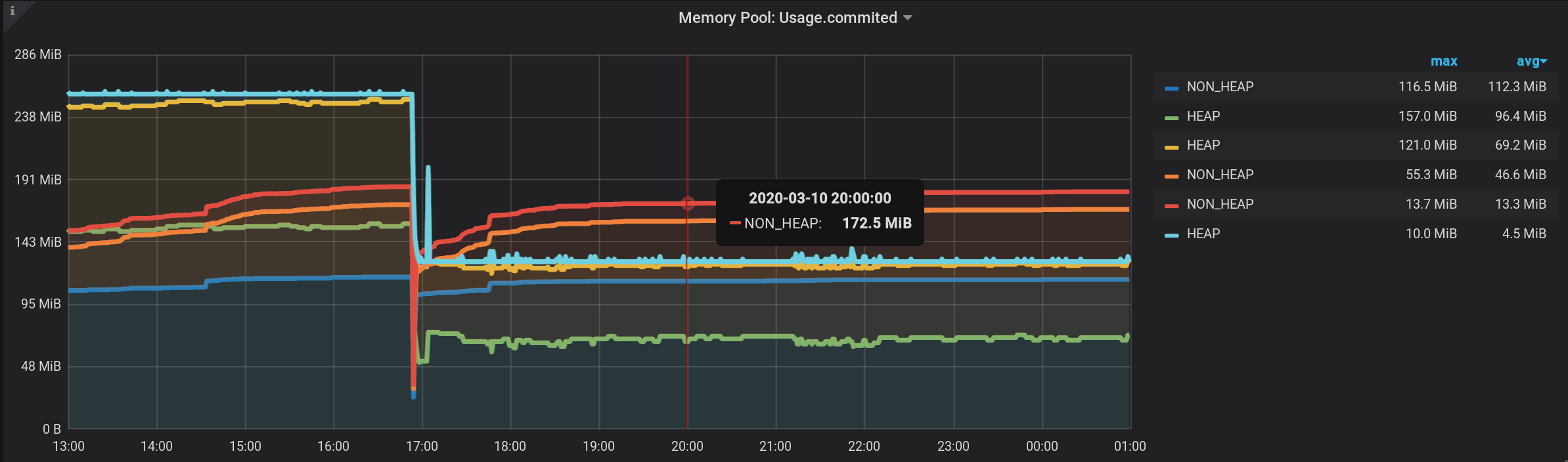
2.2. Valeur empilée: cumulative avec masquage des lignes intermédiaires
Corrigeons le premier inconvénient de la solution précédente: assurez-vous que les graphiques supplémentaires ne sont pas affichés.Pour ça:- Ajoutez de nouvelles mesures avec un nom différent et une valeur 0 aux résultats.
- Ajoutez de nouvelles mesures à la pile A et à la pile B , en haut de la pile.
- Cacher de l'écran - les lignes originales de HEAP et NON_HEAP .
Nous en ajoutons deux nouveaux après la requête principale: la requête B pour la réception d'une série avec les valeurs 0 et le nom [NON_HEAP] et la requête C pour la réception d'une série avec les valeurs 0 et le nom [HEAP] . Pour obtenir 0, nous prenons dans chaque groupe de temps la première valeur du champ «Usage.committed» et la soustrayons: first («Usage.committed») - first («Usage.committed») - nous obtenons un 0 stable. Les noms des graphiques sont modifiés sans perte de sens en raison des crochets: [NON_HEAP] et [HEAP] : [HEAP] et HEAP sont combinés en pile A , et cache aussi tous HEAP . [NON_HEAP]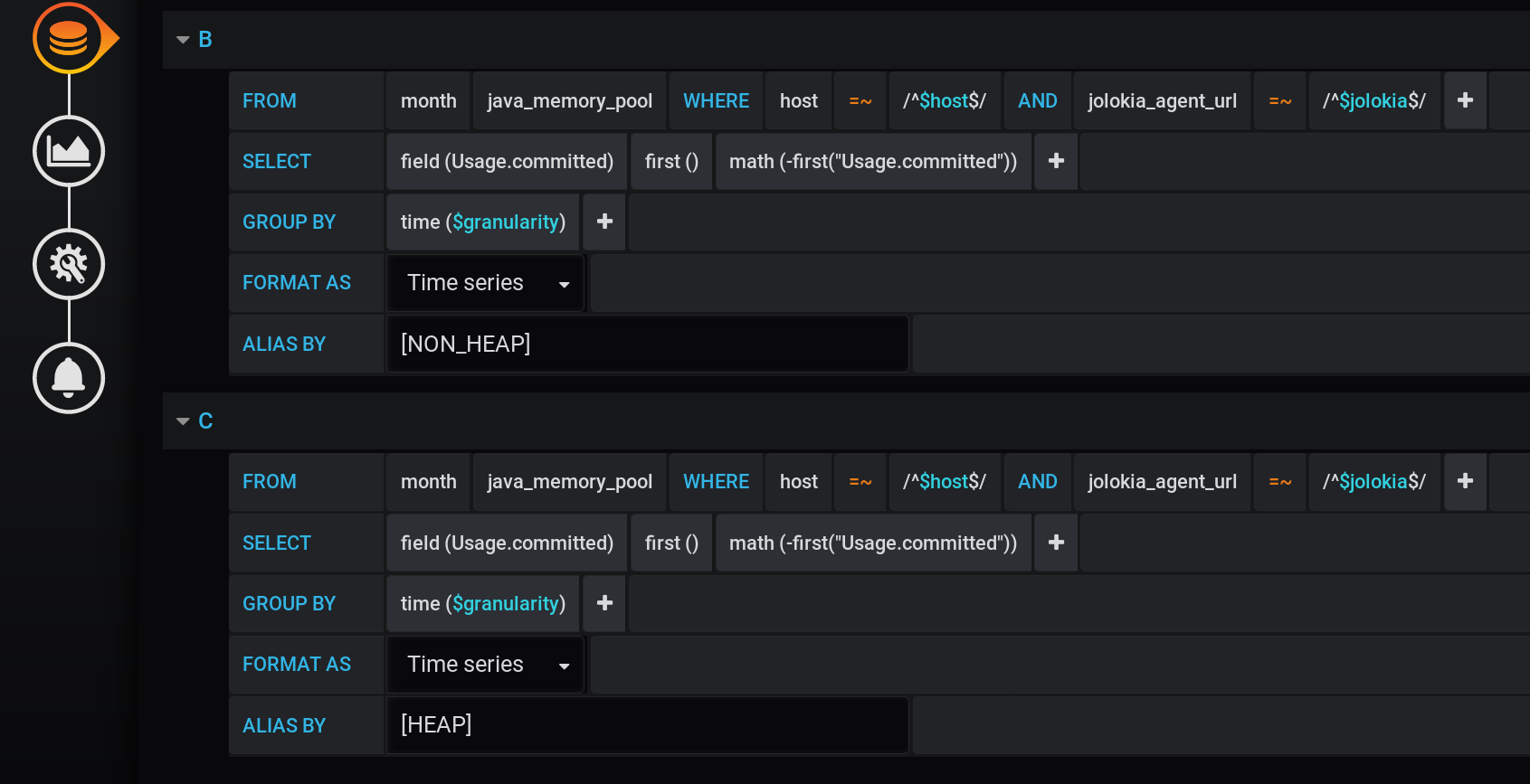 et combiner NON_HEAP dans Stack B et cacher NON_HEAP : Obtenez le
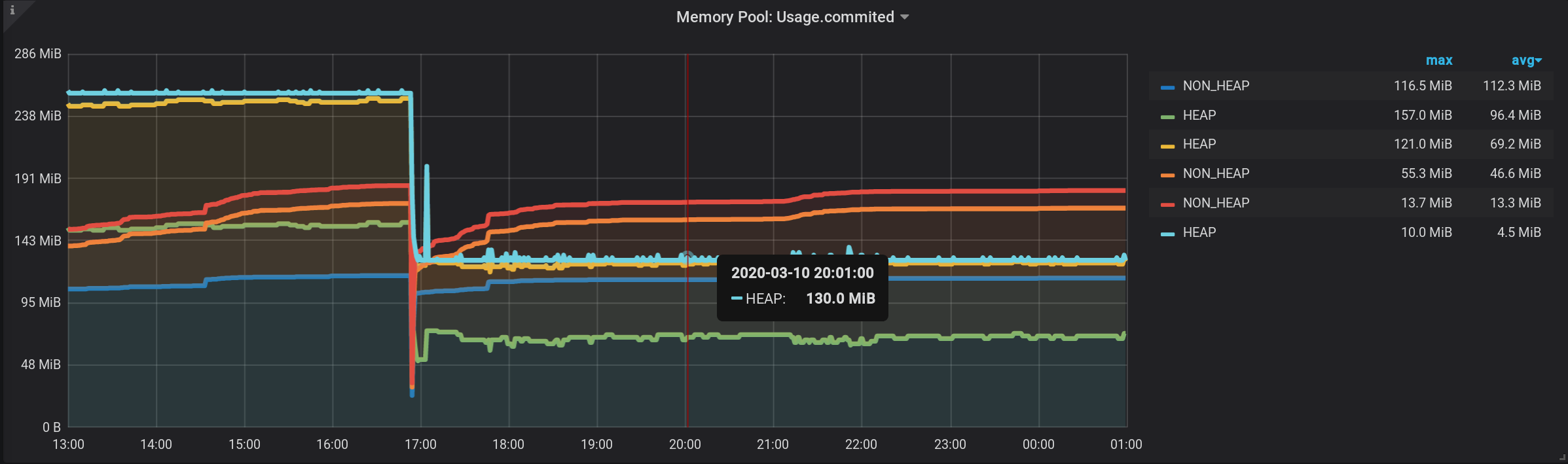
montant exact par [NON_HEAP] dans l'info - bulle au survol de la carte: Obtenez le montant exact par [HEAP] dans l'info - bulle au survol de la carte. Et même toutes les rafales sont visibles: Et le planning se forme rapidement. Mais la légende affiche toujours 0, la légende est devenue inutile. Tout a fonctionné! Le vrai contournement passe par les piles de Grafana . C'est pour cette raison que l'article a été ajouté à la catégorie Programmation anormale .
et combiner NON_HEAP dans Stack B et cacher NON_HEAP : Obtenez le
montant exact par [NON_HEAP] dans l'info - bulle au survol de la carte: Obtenez le montant exact par [HEAP] dans l'info - bulle au survol de la carte. Et même toutes les rafales sont visibles: Et le planning se forme rapidement. Mais la légende affiche toujours 0, la légende est devenue inutile. Tout a fonctionné! Le vrai contournement passe par les piles de Grafana . C'est pour cette raison que l'article a été ajouté à la catégorie Programmation anormale .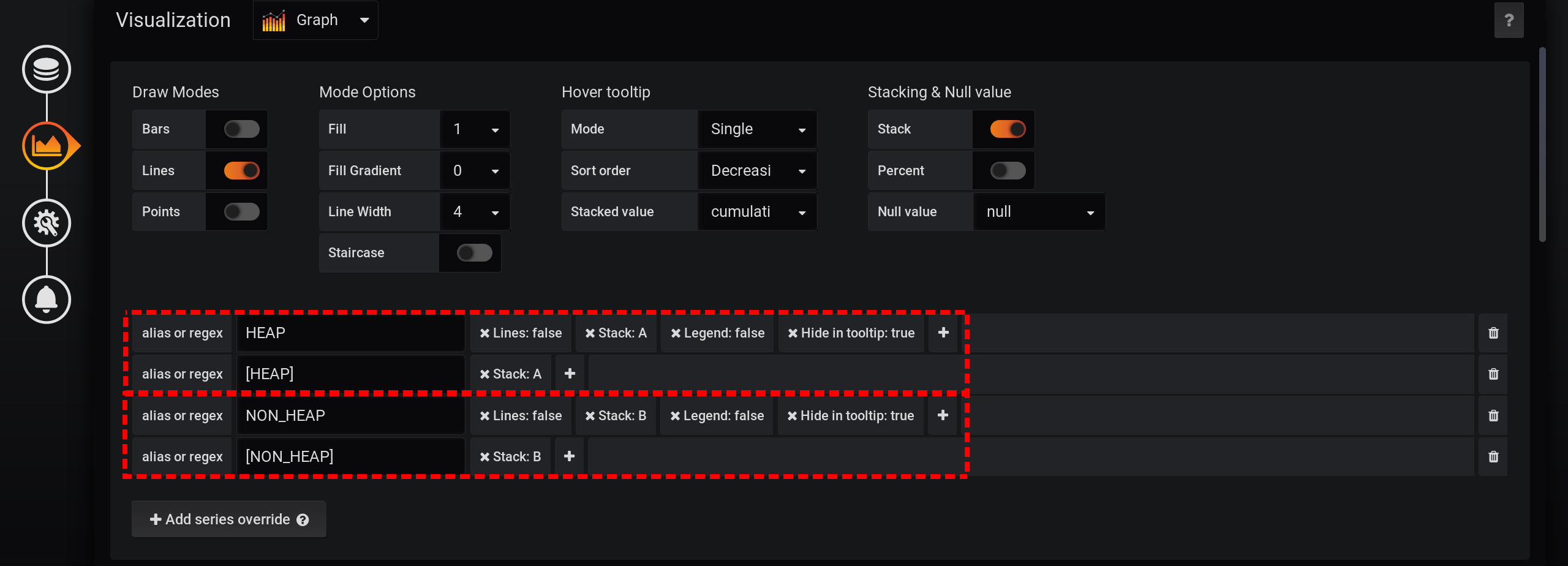


3. La somme des sommets avec la sous-requête
Puisque nous nous sommes déjà engagés dans la voie d'une programmation anormale avec un tas de Grafana et InfluxDB , continuons. Faisons en sorte qu'InfluxDB retourne un petit nombre de points et faisons apparaître la légende.3.1 Somme des incréments de la somme cumulée des maxima
Explorons les possibilités d' InfluxDB . Auparavant, j'ai souvent aidé en prenant le dérivé du montant cumulé, nous allons donc essayer d'appliquer cette approche maintenant. Passons au mode d'édition manuelle des requêtes: Faisons une telle requête:
SELECT sum("U") FROM (
SELECT non_negative_difference(cumulative_sum(max("Usage.committed"))) AS "U"
FROM "month"."java_memory_pool"
WHERE
(
"host" =~ /^${host:regex}$/ AND
"jolokia_agent_url" =~ /^${jolokia:regex}$/
) AND
$timeFilter
GROUP BY time($granularity), "Type", "name"
)
GROUP BY "Type", time($granularity)
Ici, la valeur maximale de la métrique dans le groupe par le temps est prise et la somme de ces valeurs à partir du moment où la référence commence, regroupées par les balises Type et name . En conséquence, à chaque instant du temps , il y aura une somme de toutes les indications par type ( HEAP ou NON_HEAP ) avec séparation par nom du pool, mais pas 30 valeurs sont additionnées, comme ce fut le cas dans la version 1.2, mais une seule est le maximum.Et si nous prenons l'incrément non_negative_difference d' un tel montant cumulé pour la dernière étape, nous obtenons la somme de tous les pools de données regroupés par type et balises de nom au moment où l'intervalle de temps a commencé.Maintenant, pour obtenir le montant par balise uniquementTapez , sans regroupement par balise de nom , vous devez effectuer une demande de niveau supérieur avec des paramètres de regroupement similaires, mais sans regroupement par nom .À la suite d'une requête aussi complexe, nous obtenons la somme de tous les types.Horaire parfait. La somme des maxima est calculée correctement. Il existe une légende avec les valeurs correctes, non nulles. Dans l'info-bulle, vous pouvez afficher toutes les métriques, pas seulement Single. Même les rafales HEAP s'affichent : Une chose mais - la demande s'est avérée difficile: la somme de l'incrément de la somme cumulée des maxima avec une modification du niveau de regroupement.
3.2 Somme des sommets avec changement de niveau de regroupement
Pouvez-vous faire quelque chose de plus simple que dans la version 3.1? La boîte de Pandore est déjà ouverte, nous sommes passés en mode d'édition de requête manuelle.On soupçonne que le fait de recevoir une augmentation du montant cumulé conduit à un effet nul - l'un éteint l'autre. Débarrassez-vous de non_negative_difference (cumulative_sum (...)) .Simplifiez la demande.On laisse simplement la somme des maxima, avec une diminution du niveau de regroupement:SELECT sum("A")
FROM (
SELECT max("Usage.committed") as "A"
FROM "month"."java_memory_pool"
WHERE
(
"host" =~ /^${host:regex}$/ AND
"jolokia_agent_url" =~ /^${jolokia:regex}$/
) AND
$timeFilter
GROUP BY time($granularity), "Type", "name"
)
WHERE $timeFilter
GROUP BY time($granularity), "Type"
Il s'agit d'une requête simple et rapide qui ne renvoie que 721 points par série en 12 heures, lorsqu'elle est regroupée par minutes: 12 (heures) * 60 (minutes) = 720 intervalles, 721 points (dernier vide). Veuillez noter que le filtre horaire est dupliqué. C'est dans la sous-requête et dans la demande de regroupement: Sans $ timeFilter, dans la demande de regroupement externe, le nombre de points retournés ne sera pas de 721 en 12 heures, mais plus. Puisque la sous-requête est regroupée pour l'intervalle de ... à , et le regroupement d'une demande externe sans filtre sera pour l'intervalle de ... maintenant . Et si à Grafana un intervalle de temps qui ne dure pas X heures est sélectionné (pas tel que to = now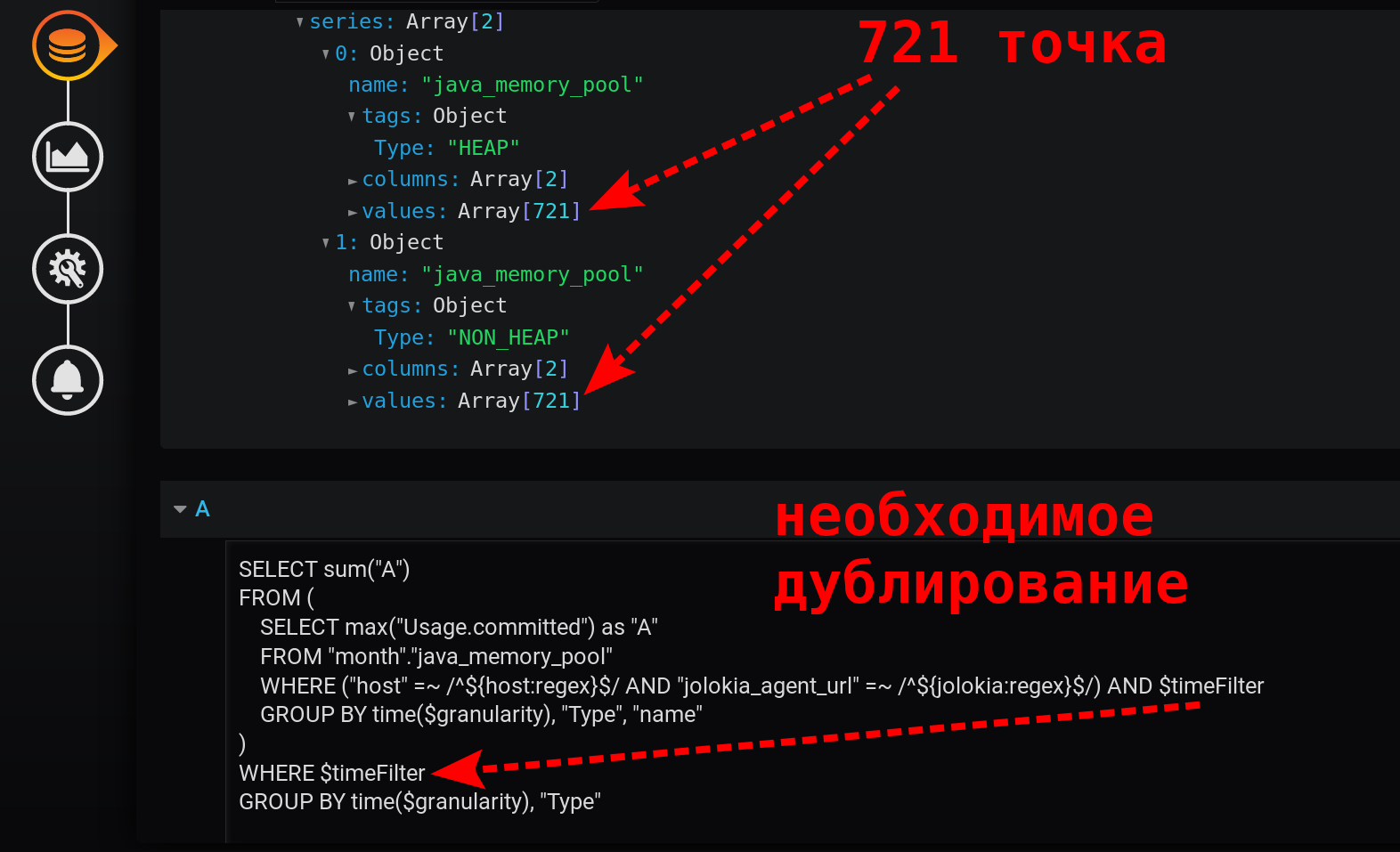 ), mais pour l'intervalle du passé ( à < maintenant ), des points vides avec une valeur nulle à la fin de la sélection apparaîtront.Le graphique résultant s'est avéré être simple, rapide et correct. Avec une légende qui affiche des métriques récapitulatives. Avec info-bulle pour plusieurs lignes à la fois. Et aussi avec l'affichage de toutes les rafales de valeurs: Le résultat est atteint!
), mais pour l'intervalle du passé ( à < maintenant ), des points vides avec une valeur nulle à la fin de la sélection apparaîtront.Le graphique résultant s'est avéré être simple, rapide et correct. Avec une légende qui affiche des métriques récapitulatives. Avec info-bulle pour plusieurs lignes à la fois. Et aussi avec l'affichage de toutes les rafales de valeurs: Le résultat est atteint!Références (au lieu de références)
Distributions des outils utilisés dans l'article:Documentation sur les capacités des outils utilisés dans l'article:La combinaison de Grafana et InfluxDB doit être bien connue des ingénieurs de test de performance. Et dans ce bundle, de nombreuses tâches simples sont très intéressantes et ne peuvent pas toujours être résolues par des méthodes de programmation normales.Parfois , les compétences de programmation anormales peuvent être nécessaires avec les Grafana caractéristiques et les subtilités de la InfluxDB requête langage .Dans l'article, des mesures ont été prises en compte pour quatre options d'implémentation de la sommation d'une métrique regroupée par une balise, mais qui a plusieurs balises. La tâche était intéressante. Et il existe de nombreuses tâches de ce type.Je prépare un rapport sur les subtilités de la programmation avec Grafana et InfluxDB. Je publierai périodiquement des documents sur ce sujet. En attendant, je serai heureux de vos questions sur l'article actuel.